
Las aplicaciones web tienen una arquitectura compleja que incluye varios componentes. Cada componente desempeña un papel importante. Para los usuarios, todo el proceso es sencillo, pero todo lo importante ocurre entre bastidores. Cada vez que un usuario envía una solicitud, esta se envía al servidor, que la procesa para realizar todas las acciones necesarias. Posteriormente, la respuesta se envía al navegador para proporcionar el resultado al usuario. Sin embargo, los sitios web se diferencian de las aplicaciones web en varios aspectos. Este artículo explica todo sobre la Arquitectura y componentes de aplicaciones web.
¿Qué son las aplicaciones web?
Son programas de software que se ejecutan en servidores web y son accesibles a través de internet mediante navegadores web. Están diseñadas para proporcionar una funcionalidad interactiva y dinámica a los usuarios, permitiéndoles realizar diversas tareas, acceder a información e interactuar. Las aplicaciones web se han convertido en una parte integral del uso moderno de internet e impulsan una amplia gama de servicios y actividades en línea. Algunos ejemplos de aplicaciones web incluyen:
- Plataformas de redes sociales (por ejemplo, Linkedin, X)
- Servicios de correo electrónico en línea (por ejemplo, Gmail, Outlook)
- Sitios web de comercio electrónico (por ejemplo, Amazon, eBay)
- Herramientas de productividad basadas en la nube (por ejemplo, Google Workspace, Microsoft Office 365)
¿Cómo funcionan las aplicaciones web?
- Arquitectura cliente-servidor: Las aplicaciones web siguen el modelo cliente-servidor, donde la lógica y los datos de la aplicación se alojan en un servidor web y los usuarios acceden a ellos mediante navegadores web en sus dispositivos.
- Interfaz de usuario (IU): La interfaz de usuario de las aplicaciones web suele presentarse mediante una combinación de HTML (lenguaje de marcado de hipertexto), CSS (hojas de estilo en cascada) y JavaScript para crear interfaces dinámicas e interactivas.
- Conectividad a Internet: Las aplicaciones web requieren una conexión a Internet para que los usuarios accedan a ellas. Los usuarios interactúan con la aplicación enviando solicitudes al servidor, que procesa esas solicitudes y devuelve las respuestas adecuadas
- Compatibilidad entre plataformas: Las aplicaciones web son accesibles desde diferentes dispositivos y sistemas operativos sin necesidad de instalación ni software específico, lo que las hace independientes de la plataforma.
- Sin estado: HTTP, el protocolo utilizado para la comunicación entre navegadores web y servidores, no tiene estado. Las aplicaciones web deben gestionar las sesiones y el estado de los usuarios para recordar las interacciones de los usuarios y garantizar la continuidad
Arquitectura de aplicaciones web
La arquitectura de aplicaciones web se refiere a la estructura y organización de los componentes y las tecnologías utilizadas para crear una aplicación web. Cualquier software de aplicación que se ejecuta en un servidor web y sus respuestas se proporcionan al usuario mediante una interfaz de navegador. A diferencia de los programas en el equipo, las aplicaciones web no se ejecutan en ningún sistema operativo del dispositivo. La arquitectura de una aplicación web define la interacción entre los sistemas, las aplicaciones y los componentes de las bases de datos. Cada vez que un usuario envía una solicitud para abrir una página web, el servidor envía el archivo al navegador.
Posteriormente, utiliza los archivos para mostrar la página y el usuario puede interactuar con ella. La funcionalidad de una aplicación web es similar a la de un sitio web, pero la diferencia radica en el análisis del código. En una aplicación web, el código puede tener o no especificaciones para la respuesta, dependiendo de la entrada recibida por el usuario. Por esta razón, la arquitectura de una aplicación web incluye subcomponentes y aplicaciones externas.
En términos más simples, una arquitectura de aplicación web es un marco estructural que determina la interacción entre diferentes componentes web (cliente y servidor). Define cómo interactúan las diferentes partes de la aplicación entre sí para ofrecer su funcionalidad, gestionar las solicitudes de los usuarios y administrar los datos. Una arquitectura de aplicación web bien diseñada es crucial para garantizar la escalabilidad, la facilidad de mantenimiento y la seguridad. Antes de realizar una evaluación de seguridad en una aplicación web, es de vital importancia saber cómo funcionan las aplicaciones web con respecto a la arquitectura subyacente. Este conocimiento le proporcionará una mejor comprensión de dónde y cómo identificar y explotar posibles vulnerabilidades o configuraciones incorrectas en las aplicaciones web.
Modelo cliente-servidor
Las aplicaciones web generalmente se basan en el modelo cliente-servidor. En esta arquitectura, la aplicación se divide en dos componentes principales:
Cliente:
El cliente representa la interfaz de usuario y la interacción del usuario con la aplicación web. Es el front-end de la aplicación al que los usuarios acceden a través de sus navegadores web. El cliente es responsable de mostrar las páginas, gestionar la entrada del usuario y enviar solicitudes al servidor para datos o acciones.
Servidor:
El servidor representa el back-end de la aplicación web. Procesa las solicitudes del cliente, ejecuta la lógica empresarial de la aplicación, se comunica con bases de datos y otros servicios, y genera respuestas para ser enviadas de vuelta al cliente. Particularmente un servidor web es una máquina que tiene hardware y software, y que hace uso de HTTP y otros protocolos para responder a las solicitudes de los usuarios en un sitio web o una aplicación web. La función principal de un servidor web es almacenar el contenido del sitio web, incluido texto, código, imágenes, vídeos, etc. y mostrarlos a los usuarios finales cuando lo soliciten.
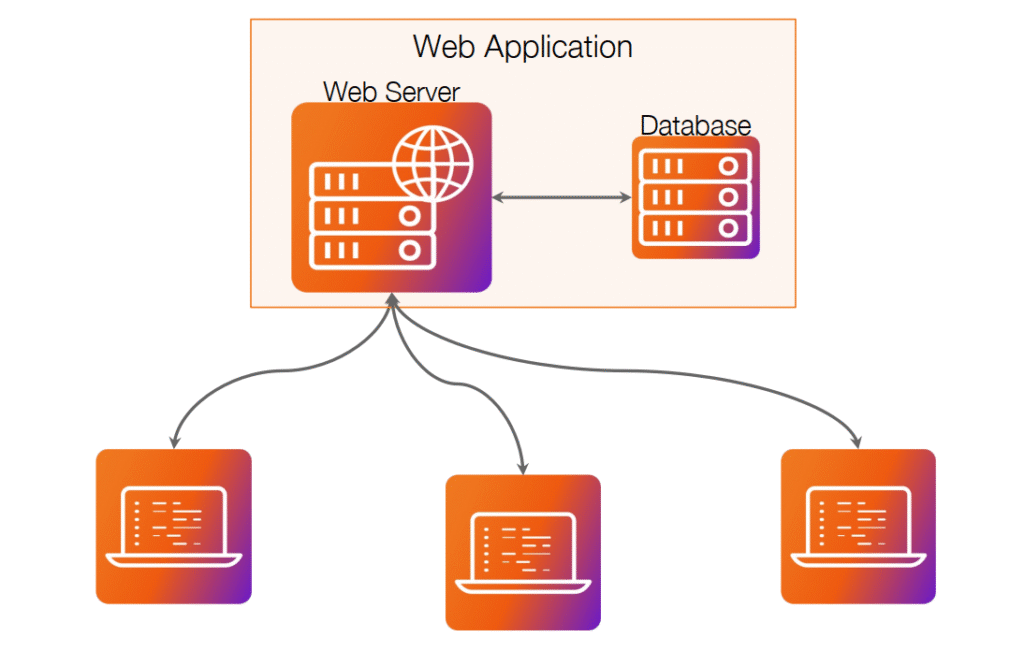
La imagen representa la estructura fundamental de una aplicación web, mostrando cómo se comunican sus distintos componentes principales: los usuarios, el servidor web y la base de datos. En la parte superior se encuentra la Web Application, compuesta por dos elementos esenciales:
- Web Server: es el encargado de recibir las solicitudes de los usuarios a través del navegador (HTTP/HTTPS), procesarlas y devolver una respuesta. Aquí se ejecuta la lógica de la aplicación, como la validación de datos, la autenticación de usuarios o la generación dinámica de contenido.
- Database: es el sistema que almacena y gestiona la información que utiliza la aplicación, como usuarios, contraseñas, registros, transacciones o configuraciones. El servidor web se comunica con la base de datos mediante consultas para leer o modificar datos según la petición del usuario.
En la parte inferior de la imagen se representan los clientes o usuarios finales, que acceden a la aplicación a través de sus navegadores o dispositivos. Cada cliente envía peticiones al servidor web, el cual procesa la información y devuelve los resultados.
Las flechas indican el flujo de comunicación:
- Los usuarios envían solicitudes HTTP hacia el servidor web.
- El servidor interpreta la petición y, si es necesario, consulta o modifica datos en la base de datos.
- Finalmente, el servidor genera una respuesta (por ejemplo, una página HTML, un JSON o un mensaje de error) y la envía de vuelta al usuario.
Este modelo refleja una arquitectura cliente-servidor, típica en la mayoría de las aplicaciones modernas. Entender esta estructura es clave para los profesionales de hacking ético y ciberseguridad, ya que permite identificar posibles puntos de ataque en cada capa: el cliente, el servidor y la base de datos.
Capas de arquitectura de aplicaciones web:
Toda arquitectura de aplicación web se basa en una arquitectura en capas. Sin embargo, todo depende de la escala de la aplicación. Las aplicaciones grandes pueden tener de cuatro a seis capas, mientras que las pequeñas pueden tener tres. Cada capa funciona de forma independiente y sus componentes son cerrados. A continuación, se presentan las cuatro capas más comunes de la arquitectura de aplicaciones web .
- Capa de presentación:
Esta capa facilita la comunicación entre el navegador y la interfaz de usuario de la aplicación, lo que facilita la interacción general del usuario. Cada capa de presentación se crea mediante JavaScript, HTML, CSS y sus frameworks. - Capa de negocio:
La capa de negocio ayuda a procesar las solicitudes del navegador, ejecuta la lógica de negocio de las solicitudes y la comparte con la capa anterior. Esta capa determina principalmente las reglas de negocio de la aplicación web. - Capa de acceso a datos:
Esta capa se utiliza para acceder a datos de XML, archivos binarios y otros tipos de almacenamiento. Además, facilita las operaciones de creación, lectura, actualización y eliminación. - Capa de Servicio de Datos:
La última capa es la capa de servicio de datos, que garantiza la seguridad de los datos y almacena todos los datos. Esta capa protege los datos separando la lógica de negocio de la aplicación del lado del cliente.
Servidor web
Un servidor web es un software que detecta conexiones entrantes y utiliza el protocolo HTTP para entregar contenido web a sus clientes. Los servidores web más comunes son Apache , Nginx, IIS y NodeJS. Un servidor web entrega archivos desde su directorio raíz, definido en la configuración del software. Por ejemplo, Nginx y Apache comparten la misma ubicación predeterminada: /var/www/html en sistemas operativos Linux , e IIS usa C:\inetpub\wwwroot en sistemas operativos Windows. Por ejemplo, si solicita el archivo http://www.example.com/picture.jpg , enviará el archivo /var/www/html/picture.jpg desde su disco duro local.
Cuando visitas un sitio web, el navegador ( como Firefox o Google Chrome ) realiza una solicitud a un servidor web solicitando información sobre la página que estás visitando. Este responderá con datos que el navegador utiliza para mostrarte la página; un servidor web es simplemente un equipo dedicado, ubicado en otra parte del mundo, que gestiona tus solicitudes.
Hay dos componentes principales que forman un sitio web:
- Front End (lado del cliente): la forma en que el navegador representa un sitio web.
- Back End (lado del servidor): un servidor que procesa la solicitud y devuelve una respuesta.
Hay muchos otros procesos involucrados cuando el navegador realiza una solicitud a un servidor web, pero por ahora, solo se necesita comprender que se realiza una solicitud a un servidor y este responde con datos que el navegador utiliza para brindar la información.
Comunicación entre un navegador (cliente) y un servidor web
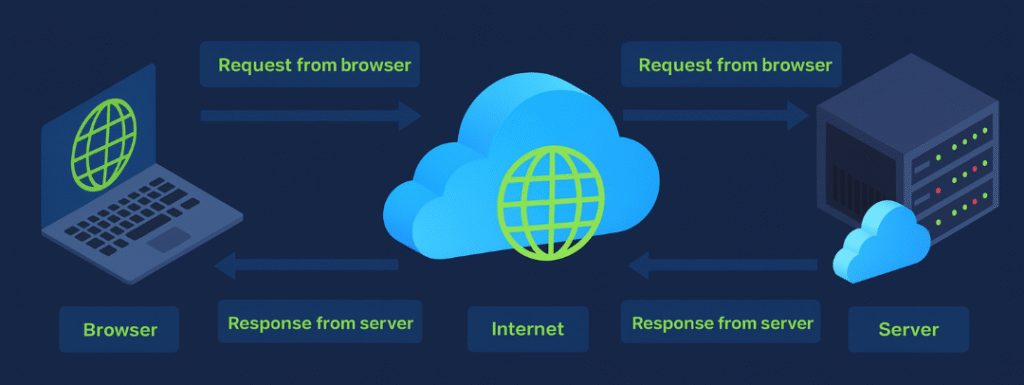
La imagen ilustra el proceso de comunicación entre un navegador (cliente) y un servidor web, mostrando cómo viajan las solicitudes y respuestas a través de Internet. Este intercambio es la base de toda interacción en la web.
- Request from browser (solicitud del navegador):
Cuando un usuario escribe una URL en su navegador o interactúa con una página, el navegador envía una solicitud HTTP o HTTPS hacia el servidor. Esta solicitud puede pedir una página HTML, una imagen, un archivo CSS, un script o cualquier recurso necesario para mostrar el sitio. - Internet (transporte de la solicitud):
La petición viaja a través de Internet, pasando por routers, firewalls y otros sistemas intermedios. Durante este proceso se utilizan protocolos como TCP/IP, DNS (para resolver nombres de dominio) y TLS/SSL (si la conexión es segura). - Server (procesamiento en el servidor):
El servidor recibe la solicitud, la interpreta y ejecuta el código necesario para generar una respuesta. Puede consultar una base de datos, validar credenciales o procesar datos del usuario antes de construir la respuesta. - Response from server (respuesta del servidor):
Una vez procesada la solicitud, el servidor envía la respuesta de vuelta al navegador, normalmente en formato HTML, JSON, XML u otro tipo de contenido. - Browser (renderizado de la respuesta):
El navegador recibe la respuesta y la muestra al usuario. En el caso de una página web, interpreta el HTML, aplica los estilos CSS, ejecuta el código JavaScript y presenta el resultado visual final.
Este ciclo de petición y respuesta se repite constantemente mientras navegamos por Internet. En el contexto de la ciberseguridad y el hacking ético, comprender este flujo es esencial: cada paso puede ser un punto potencial de ataque o vulnerabilidad (por ejemplo, interceptación de tráfico, inyección de código o manipulación de peticiones HTTP).
Componentes de la aplicación web
- Interfaz de usuario (IU): La interfaz de usuario es la presentación visual de la aplicación web que los usuarios ven e interactúan con ella. Incluye elementos como páginas web, formularios, menús, botones y otros componentes interactivos.
- Tecnologías del lado del cliente: Las tecnologías del lado del cliente, como HTML (lenguaje de marcado de hipertexto), CSS (hojas de estilo en cascada) y JavaScript, se utilizan para crear la interfaz de usuario y gestionar las interacciones directamente dentro del navegador web del usuario.
- Tecnologías del lado del servidor: Las tecnologías del lado del servidor, como los lenguajes de programación (por ejemplo, PHP, Python, Java, Ruby) y los marcos de trabajo, se utilizan para implementar la lógica empresarial de la aplicación, procesar las solicitudes de los clientes, acceder a las bases de datos y generar contenido dinámico para enviarlo de vuelta al cliente.
- Bases de datos: Las bases de datos se utilizan para almacenar y gestionar los datos de la aplicación web. Almacenan información del usuario, contenido, configuraciones y otros datos relevantes necesarios para el funcionamiento de la aplicación.
- Servidores web: Los servidores web gestionan la solicitud inicial de los clientes y sirven los componentes del lado del cliente, como archivos estáticos (HTML, CSS, JavaScript), a los usuarios.
- Servidores de aplicaciones: Un servidor de aplicaciones es una plataforma de software que proporciona la infraestructura y los servicios necesarios para desarrollar, ejecutar y administrar aplicaciones, actuando como un entorno de tiempo de ejecución para la lógica de negocio.
Hosts virtuales
Los servidores web pueden alojar varios sitios web con diferentes nombres de dominio; para ello, utilizan hosts virtuales. El software del servidor web comprueba el nombre de host solicitado en las cabeceras HTTP y lo compara con sus hosts virtuales (los hosts virtuales son simplemente archivos de configuración de texto). Si encuentra una coincidencia, se proporcionará el sitio web correcto. Si no encuentra ninguna coincidencia, se proporcionará el sitio web predeterminado.
Los hosts virtuales pueden tener su directorio raíz asignado a diferentes ubicaciones en el disco duro. Por ejemplo, one.com se asigna a /var/www/website_one y two.com a /var/www/website_two. No hay límite en la cantidad de sitios web diferentes que puedes alojar en un servidor web.
Contenido estático vs. contenido dinámico
El contenido estático, como su nombre indica, es contenido que nunca cambia. Ejemplos comunes son imágenes, JavaScript, CSS, etc., pero también puede incluir HTML que nunca cambia. Además, estos son archivos que se sirven directamente desde el servidor web sin modificaciones.
El contenido dinámico, por otro lado, es aquel que puede cambiar según las solicitudes. Por ejemplo, un blog. En su página principal, se mostrarán las últimas entradas. Si se crea una nueva entrada, la página principal se actualiza con ella. Otro ejemplo podría ser la página de búsqueda del blog. Según la palabra que busques, se mostrarán diferentes resultados.
Estos cambios en lo que ves se realizan en el backend mediante lenguajes de programación y scripting. Se llama backend porque todo lo que se hace se realiza en segundo plano. No puedes ver el código HTML de los sitios web y ver lo que sucede en el backend, mientras que el HTML es el resultado del procesamiento del backend. Todo lo que ves en tu navegador se llama frontend.
Procesamiento del lado del cliente
El procesamiento del lado del cliente implica la ejecución de tareas y cálculos en el dispositivo del usuario, normalmente dentro de su navegador web. El lado del cliente se refiere al extremo del usuario de la aplicación web, donde residen el navegador web y la interfaz de usuario.
El procesamiento del lado del cliente tiene algunas limitaciones. No es adecuado para gestionar operaciones sensibles o críticas, ya que puede ser fácilmente manipulado por usuarios o actores maliciosos. Características clave del procesamiento del lado del cliente:
- Interacción del usuario: El procesamiento del lado del cliente es ideal para tareas que requieren interacción y retroalimentación inmediatas del usuario, ya que no es necesario enviar datos de un lado a otro al servidor.
- Experiencia de usuario receptiva: Dado que el procesamiento se realiza localmente, las operaciones del lado del cliente pueden proporcionar una experiencia de usuario más fluida y receptiva.
- JavaScript: JavaScript es el lenguaje de programación principal utilizado para el procesamiento del lado del cliente. Permite a los desarrolladores manipular el contenido de la página web, gestionar las interacciones del usuario y realizar validaciones sin involucrar al servidor.
- Validación de datos: La validación del lado del cliente garantiza que la entrada del usuario cumpla con criterios específicos antes de enviarse al servidor, lo que reduce la necesidad de realizar solicitudes innecesarias al servidor
Procesamiento del lado del servidor
El procesamiento del lado del servidor implica la ejecución de tareas y cálculos en el servidor web, que es el equipo remoto donde se aloja la aplicación web. El lado del servidor se refiere al backend de la aplicación web, donde tienen lugar la lógica empresarial y el procesamiento de datos. Características clave del procesamiento del lado del servidor:
- Procesamiento de datos: El procesamiento del lado del servidor es ideal para tareas que implican el manejo de datos confidenciales, cálculos complejos e interacciones con bases de datos o servicios externos.
- Seguridad: Dado que el código del lado del servidor se ejecuta en un servidor confiable, es más seguro que el código del lado del cliente, que puede ser manipulado por los usuarios o interceptado por atacantes.
- Lenguajes del lado del servidor: Lenguajes de programación como PHP, Python, Java, Ruby y otros se utilizan comúnmente para el procesamiento del lado del servidor
- Almacenamiento de datos: El procesamiento del lado del servidor permite el almacenamiento y la gestión seguros de datos confidenciales en bases de datos u otros sistemas de almacenamiento.
Tecnologías de aplicaciones web
Comprender las tecnologías web es esencial para cualquier persona involucrada en el desarrollo, seguridad o pruebas de seguridad de aplicaciones web. Como pentester, interactuarás, evaluarás y explotarás con frecuencia las tecnologías subyacentes que conforman una aplicación web en su conjunto. Como resultado, necesitas tener una comprensión fundamental de qué tecnologías del lado del servidor y del lado del cliente conforman una aplicación web, cuáles son sus funcionalidades y cuándo y por qué se implementan.
Tecnologías del lado del cliente
HTML (lenguaje de marcado de hipertexto): HTML es el lenguaje de marcado utilizado para estructurar y definir el contenido de las páginas web. Proporciona la base para crear el diseño y la estructura de la interfaz de usuario.
CSS (hojas de estilo en cascada): CSS se utiliza para definir la presentación y el estilo de las páginas web. Permite a los desarrolladores controlar los colores, las fuentes, el diseño y otros aspectos visuales de la interfaz de usuario.
JavaScript: JavaScript es un lenguaje de scripting que permite la interactividad en aplicaciones web. Se utiliza para crear elementos UI dinámicos y responsivos, gestionar las interacciones del usuario y realizar validaciones del lado del cliente.
Cookies y almacenamiento local: las cookies y el almacenamiento local son mecanismos del lado del cliente para almacenar pequeñas cantidades de datos en el navegador del usuario. A menudo se utilizan para la gestión de sesiones y para recordar las preferencias del usuario.
Tecnologías del lado del servidor
Servidor web: el servidor web es responsable de recibir y responder a las solicitudes HTTP de los clientes (navegadores web). Aloja los archivos de la aplicación web, procesa las solicitudes y envía las respuestas a los clientes. (Apache2, Nginx, Microsoft IIS, etc.)
Servidor de aplicaciones: el servidor de aplicaciones ejecuta la lógica empresarial de la aplicación web. Procesa las solicitudes de los usuarios, accede a las bases de datos y realiza cálculos para generar contenido dinámico que el servidor web puede servir a los clientes.
Servidor de bases de datos: el servidor de bases de datos almacena y administra los datos de la aplicación web. Almacena información del usuario, contenido, configuraciones y otros datos relevantes necesarios para el funcionamiento de la aplicación. (MySQL, PostgreSQL, MSSQL, Oracle, etc.)
Lenguajes de script del lado del servidor: Los lenguajes de script del lado del servidor (p. ej., PHP, Python, Java, Ruby) se utilizan para gestionar el procesamiento del lado del servidor. Interactúan con bases de datos, realizan validaciones y generan contenido dinámico antes de enviarlo al cliente. No hay muchos límites para lo que un lenguaje de backend puede lograr, y estos son los que hacen que un sitio web sea interactivo para el usuario. Algunos ejemplos de estos lenguajes (sin ningún orden en particular :p) son PHP , Python , Ruby, NodeJS, Perl y muchos más. Estos lenguajes pueden interactuar con bases de datos, llamar a servicios externos , procesar datos del usuario y mucho más. Un ejemplo básico de PHP sería solicitar el sitio web http://example.com/index.php?name=adam
Comunicación y flujo de datos
Las aplicaciones web se comunican a través de internet mediante HTTP (Protocolo de transferencia de hipertexto). Cuando un usuario interactúa con la aplicación web haciendo clic en enlaces o enviando formularios, el cliente envía solicitudes HTTP al servidor. El servidor procesa estas solicitudes, interactúa con la base de datos si es necesario, realiza las acciones requeridas y genera una respuesta HTTP. La respuesta se envía de vuelta al cliente, que procesa el contenido y lo presenta al usuario.
Intercambio de datos:
- El intercambio de datos se refiere al proceso de intercambiar datos entre diferentes sistemas informáticos o aplicaciones, lo que les permite comunicarse y compartir información.
- Es un aspecto fundamental de la informática moderna, que permite la interoperabilidad y el intercambio de datos entre diversos sistemas, plataformas y tecnologías.
- El intercambio de datos implica la conversión de datos de un formato a otro, haciéndolos compatibles con el sistema receptor.
- Esto garantiza que el receptor pueda interpretar y utilizar los datos correctamente, independientemente de las diferencias en sus estructuras de datos, lenguajes de programación o sistemas operativos
Tecnologías de intercambio de datos
API (interfaces de programación de aplicaciones): las API permiten que diferentes sistemas de software interactúen e intercambien datos. Las aplicaciones web utilizan API para integrarse con servicios externos, compartir datos y proporcionar funcionalidades a otras aplicaciones
Protocolos de intercambio de datos
JSON (Notación de objetos JavaScript): JSON es un formato de intercambio de datos ligero y ampliamente utilizado, fácil de leer y escribir tanto para humanos como para máquinas. Se basa en la sintaxis de JavaScript y se utiliza principalmente para transmitir datos entre un servidor y una aplicación web como alternativa a XML.
XML (Lenguaje de marcado extensible): XML es un formato de intercambio de datos versátil que utiliza etiquetas para definir la estructura de los datos. Permite a los usuarios crear sus etiquetas personalizadas y definir estructuras de datos jerárquicas complejas. XML se utiliza comúnmente para archivos de configuración, servicios web e intercambio de datos entre diferentes sistemas
REST (Transferencia de Estado Representacional): REST es un estilo de arquitectura de software que utiliza métodos HTTP estándar (GET, POST, PUT, DELETE) para el intercambio de datos. Se utiliza ampliamente para crear API web que permiten a las aplicaciones interactuar e intercambiar datos a través de internet.
SOAP (Protocolo Simple de Acceso a Objetos): SOAP es un protocolo para intercambiar información estructurada en la implementación de servicios web. Utiliza XML como formato de intercambio de datos y proporciona un método estandarizado para la comunicación entre diferentes sistemas.
Tecnologías de seguridad
Mecanismos de autenticación y autorización: la autenticación verifica la identidad de los usuarios, mientras que la autorización controla el acceso a diferentes partes de la aplicación web según los roles y permisos del usuario.
Cifrado (SSL/TLS): SSL (Secure Socket Layer) o TLS (Transport Layer Security) se utiliza para cifrar los datos transmitidos entre el cliente y el servidor, lo que garantiza una comunicación segura y la protección de los datos
Tecnologías externas
Bibliotecas y marcos de terceros: las aplicaciones web a menudo aprovechan bibliotecas y marcos de terceros para acelerar el desarrollo y acceder a funciones avanzadas
Balanceadores de carga
Cuando el tráfico de un sitio web aumenta considerablemente o se ejecuta una aplicación que requiere alta disponibilidad, es posible que un servidor web deje de funcionar. Los balanceadores de carga ofrecen dos funciones principales: garantizar que los sitios web con alto tráfico puedan gestionar la carga y proporcionar conmutación por error si un servidor deja de responder.
Cuando solicitas un sitio web con un balanceador de carga, este recibirá primero tu solicitud y la reenviará a uno de los múltiples servidores que lo respaldan. El balanceador utiliza diferentes algoritmos para decidir qué servidor es el más adecuado para procesar la solicitud. Algunos ejemplos de estos algoritmos son «round-robin» , que envía la solicitud a cada servidor por turno, o «weighted» , que verifica cuántas solicitudes está procesando un servidor y la envía al servidor con menos tráfico.
Los balanceadores de carga también realizan comprobaciones periódicas de cada servidor para garantizar su correcto funcionamiento; esto se denomina comprobación de estado . Si un servidor no responde correctamente, el balanceador de carga dejará de enviar tráfico hasta que vuelva a responder correctamente.
El efecto Slashdot
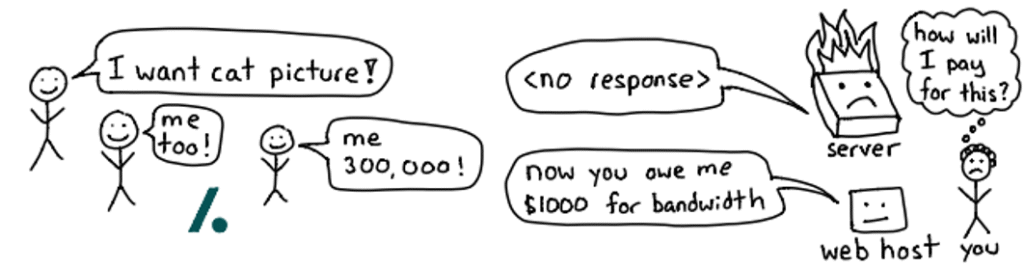
Cuando demasiada gente quiere ver tu foto de gato: el efecto Slashdot. La imagen ilustra lo que ocurre cuando un servidor recibe más tráfico del que puede manejar. Todo empieza de forma inocente: subís una foto, publicás un artículo o compartís un enlace, y de repente miles —o incluso cientos de miles— de personas intentan acceder al mismo tiempo.
Cada visitante genera una solicitud al servidor, y cuando esas solicitudes se multiplican, el servidor no logra responder a todas. Finalmente, se satura, se cuelga o deja de responder. A esto se lo conoce como el efecto Slashdot, en referencia al sitio web Slashdot.org, famoso en los años 2000 por colapsar páginas pequeñas cada vez que las mencionaba.
El resultado es que tu servidor:
- No puede responder a los usuarios legítimos.
- Consume más ancho de banda, generando costos adicionales con tu proveedor de hosting.
- Y en algunos casos, termina fuera de línea hasta que el tráfico disminuye o el servicio se reinicia.
Aunque en este ejemplo es un evento accidental (demasiada popularidad repentina), un escenario similar ocurre durante los ataques de denegación de servicio (DoS o DDoS), donde miles de equipos coordinados envían tráfico malicioso con el objetivo de derribar una web intencionalmente.
CDN (Redes de distribución de contenido)
Una CDN puede ser un excelente recurso para reducir el tráfico a un sitio web concurrido. Permite alojar archivos estáticos de su sitio web, como JavaScript, CSS, imágenes y vídeos, en miles de servidores en todo el mundo. Cuando un usuario solicita uno de los archivos alojados, la CDN determina la ubicación física del servidor más cercano y envía la solicitud allí, en lugar de enviarla al otro lado del mundo.
Las CDN se utilizan para distribuir contenido estático (por ejemplo, imágenes, archivos CSS, bibliotecas JavaScript) a múltiples servidores ubicados en todo el mundo, lo que mejora el rendimiento y la fiabilidad de la aplicación web.
Cómo una CDN salva tu servidor del colapso
En la imagen se muestra cómo una CDN (Content Delivery Network) puede evitar que un servidor se sobrecargue cuando recibe millones de solicitudes simultáneas, como en el ejemplo de la famosa foto del gato.
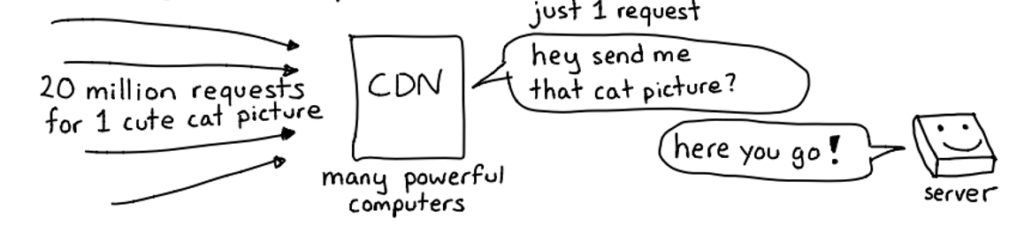
Sin una CDN, esas 20 millones de peticiones irían directamente al servidor original, consumiendo ancho de banda, sobrecargando los recursos y posiblemente provocando una caída del servicio.
Pero con una CDN en el medio, el proceso cambia radicalmente:
- Primera solicitud:
La CDN recibe una sola petición del servidor para obtener el contenido original (“Hey, mándame esa foto del gato”).
El servidor responde una única vez, entregando el archivo solicitado. - Cacheo y distribución:
La CDN guarda (cachea) una copia de ese contenido en sus múltiples servidores distribuidos geográficamente por todo el mundo. - Respuestas locales:
Cuando los usuarios vuelven a pedir la misma imagen, la CDN responde directamente desde el nodo más cercano, sin molestar al servidor principal.
De esta forma, millones de solicitudes se manejan sin colapsar el servidor de origen.
Gracias a esto:
- Se reduce drásticamente el uso de ancho de banda.
- El tiempo de carga para los usuarios es mucho menor.
- El servidor original permanece estable y protegido.
En resumen, una CDN actúa como una red de defensa y distribución, absorbiendo el tráfico masivo y entregando contenido de forma rápida y eficiente. Es una de las mejores prácticas tanto para rendimiento web como para seguridad frente a ataques DDoS.
Web Application Architecture
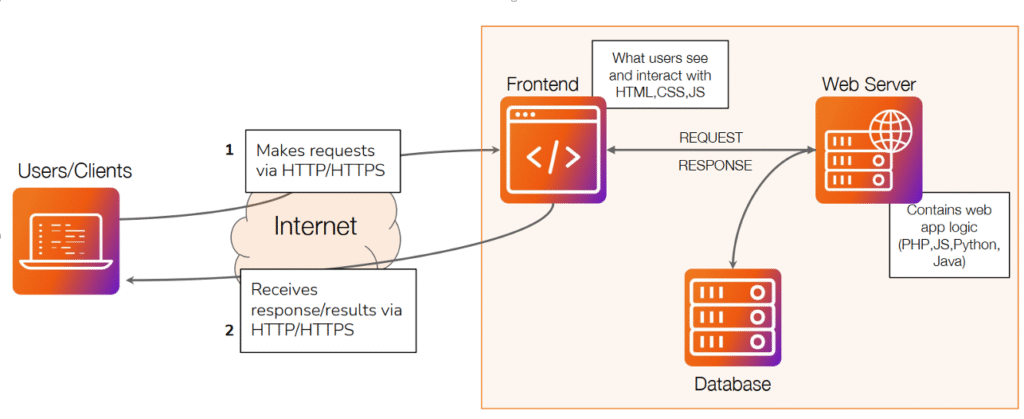
La imagen muestra la arquitectura básica de una aplicación web, explicando cómo se comunican sus distintos componentes para ofrecer una experiencia interactiva al usuario. En el extremo izquierdo aparecen los usuarios o clientes, que acceden a la aplicación mediante un navegador web o un dispositivo conectado. Estos usuarios envían solicitudes a través de los protocolos HTTP o HTTPS hacia el servidor, pasando por Internet. Cada solicitud (request) puede ser, por ejemplo, una acción como ingresar a una página, enviar un formulario o pedir información.
Una vez que la solicitud llega al sistema, interviene el frontend, que es la parte visual de la aplicación: lo que el usuario ve e interpreta a través de tecnologías como HTML, CSS y JavaScript. El frontend envía la petición al servidor web, donde se encuentra la lógica de la aplicación, desarrollada con lenguajes como PHP, JavaScript, Python o Java. Allí es donde realmente se procesan las acciones, se validan los datos y se ejecutan las reglas del negocio.
El servidor, a su vez, puede necesitar comunicarse con una base de datos para obtener, guardar o modificar información. Por ejemplo, al iniciar sesión, el servidor consulta la base de datos para verificar las credenciales del usuario. Luego, el servidor genera una respuesta y la envía de vuelta al frontend, que la traduce en algo visible e interactivo. Finalmente, el cliente recibe la información procesada en su navegador a través de la misma conexión HTTP/HTTPS.
En resumen, esta arquitectura representa el flujo clásico de comunicación en una aplicación web moderna: el usuario realiza una solicitud desde el navegador, el frontend la presenta y envía, el servidor web la procesa y, si es necesario, consulta la base de datos, devolviendo una respuesta dinámica que se renderiza en el navegador. Todo este proceso ocurre en segundos y constituye la base de cualquier aplicación web actual, desde un sitio informativo hasta plataformas complejas como redes sociales o servicios en la nube.
Cómo es renderizada una página web
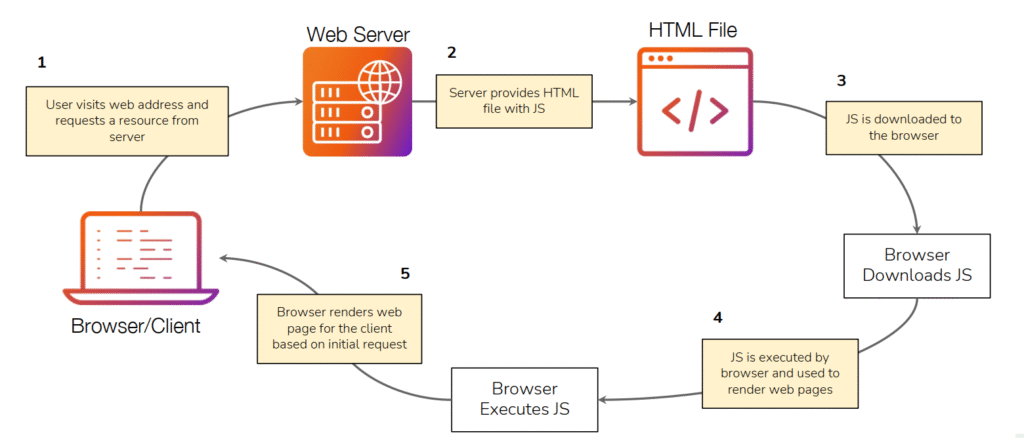
Podemos ver en la imagen el ciclo completo de cómo el navegador y el servidor trabajan juntos para mostrar una página web, explicando de manera clara el flujo de solicitudes y respuestas que ocurre cada vez que un usuario visita un sitio. Todo comienza cuando el usuario o cliente escribe una dirección web en su navegador o hace clic en un enlace (1). En ese momento, el navegador envía una solicitud al servidor web, pidiendo los recursos necesarios para mostrar la página. Este servidor almacena los archivos del sitio y se encarga de responder con los documentos solicitados.
En la siguiente etapa (2), el servidor web devuelve un archivo HTML que contiene la estructura básica de la página junto con referencias a otros recursos, como JavaScript (JS) o CSS. El navegador recibe ese archivo HTML y comienza a procesarlo.
Después (3), el navegador descarga los archivos JavaScript indicados dentro del HTML. Estos scripts contienen instrucciones que definen la lógica dinámica del sitio, permitiendo que la página sea interactiva y responda a las acciones del usuario.
Una vez descargados, el navegador ejecuta el código JavaScript (4). Este proceso puede modificar el contenido de la página, hacer que aparezcan nuevos elementos, conectarse nuevamente con el servidor para obtener más datos o reaccionar ante eventos como clics o desplazamientos.
Finalmente (5), el navegador renderiza la página web para mostrarla al usuario. Esto significa que combina el HTML, el CSS y el JavaScript ejecutado para construir visualmente la interfaz que el visitante ve en pantalla.
En resumen, esta imagen ilustra cómo una simple visita a un sitio web activa un proceso de comunicación entre el cliente y el servidor: el usuario solicita, el servidor responde con los archivos necesarios y el navegador interpreta y ejecuta esos recursos para renderizar la página final. Este ciclo ocurre en milisegundos, pero es la base fundamental del funcionamiento de toda aplicación o sitio web moderno.
Cómo analizan las respuestas los navegadores web
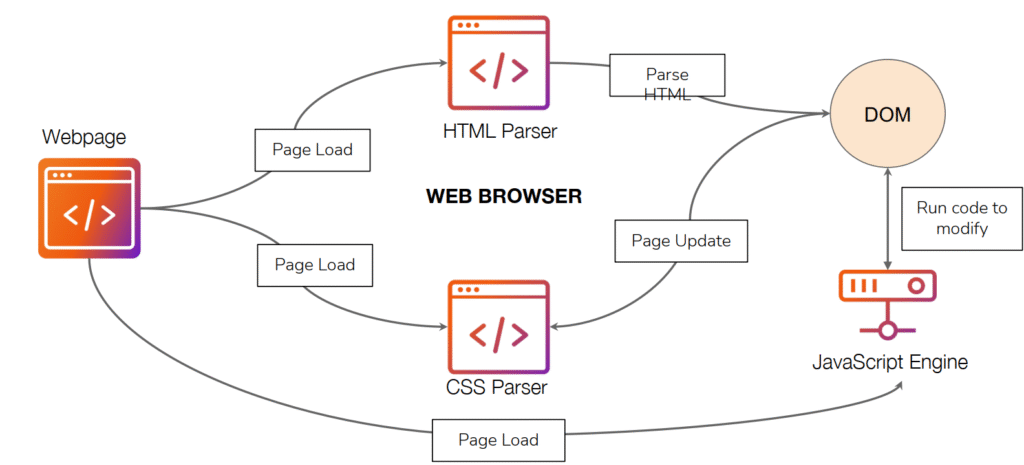
Podemos ver cómo un navegador web interpreta y procesa los diferentes componentes de una página web para mostrarla correctamente al usuario. Representa lo que ocurre detrás de escena cada vez que una página se carga, desde la lectura del código HTML y CSS hasta la ejecución del JavaScript que da vida a los elementos interactivos.
Todo comienza con la página web (webpage), que contiene el código fuente de la aplicación o del sitio. Cuando el navegador recibe ese código, entra en acción el HTML Parser, que se encarga de leer (“parsear”) el archivo HTML. Este proceso convierte las etiquetas HTML en una estructura jerárquica conocida como DOM (Document Object Model), una especie de “árbol” que representa todos los elementos visibles y su relación dentro de la página.
Mientras tanto, el navegador también utiliza el CSS Parser para analizar las hojas de estilo (CSS). Este componente define cómo deben verse los elementos del DOM: sus colores, tamaños, márgenes, tipografías y disposición visual. Una vez interpretado, el navegador actualiza la página aplicando el estilo correspondiente, dando forma a la interfaz que el usuario verá finalmente.
Por otro lado, entra en juego el motor de JavaScript (JavaScript Engine). Este motor ejecuta el código JS incluido en la página, permitiendo que la aplicación realice acciones dinámicas, como modificar el contenido del DOM, responder a eventos (clics, desplazamientos, formularios) o comunicarse con el servidor sin recargar toda la página. Gracias a esta ejecución, el JavaScript puede actualizar o manipular partes del DOM en tiempo real, mejorando la interactividad y la experiencia del usuario.
En resumen, la imagen representa cómo el navegador combina tres elementos fundamentales —HTML, CSS y JavaScript— para construir una página web. El HTML define la estructura, el CSS el estilo visual y el JavaScript la lógica interactiva. Todos trabajan en conjunto dentro del navegador para transformar el código recibido desde el servidor en una experiencia visual fluida y dinámica para el usuario final.
Descripción general de la aplicación web
Para explicar esto usare una analogía genial que da THM y que pronto veremos mejor al resolver un CTF. Consideremos una aplicación web como un planeta. Los astronautas viajan al planeta para explorar su superficie, de forma similar a cómo alguien usa un navegador web para explorar una aplicación web. Podemos imaginar el planeta entero como un servidor web con muchas cosas sucediendo bajo la superficie, pero normalmente solo podemos ver la superficie de las páginas web o aplicaciones. Ahora exploraremos los diversos componentes que conforman una aplicación web.
Los sitios web se crean principalmente utilizando:
- HTML, para construir sitios web y definir su estructura
- CSS, para hacer que los sitios web se vean bonitos agregando opciones de estilo
- JavaScript, implementa funciones complejas en páginas usando interactividad
Interfaz – Front End
El Front End puede considerarse similar a la superficie del planeta: las partes que un astronauta puede ver e interactuar con ellas según las leyes de la naturaleza. Una aplicación web permitiría la interacción del usuario, utilizando diversas tecnologías como HTML, CSS y JavaScript.
HTML (lenguaje de marcado de hipertexto)
Es un aspecto fundamental de las aplicaciones web. Se trata de un conjunto de instrucciones o código que indica al navegador web qué mostrar y cómo hacerlo. Podría compararse con los organismos simples que viven en el planeta; estos organismos tienen ADN, que es el código que explica cómo se forman los organismos simples.
CSS Las hojas de estilo en cascada
En aplicaciones web describen una apariencia estándar, como ciertos colores, tipos de texto y diseños. Siguiendo la analogía con el ADN, estas podrían compararse con las partes del ADN que describen el color, la forma, el tamaño y la textura de un organismo simple.
JS (JavaScript)
Forma parte del frontend de una aplicación web que permite una actividad más compleja en el navegador. Mientras que HTML puede considerarse un simple conjunto de instrucciones sobre qué mostrar, JavaScript es un conjunto de instrucciones más avanzado que permite tomar decisiones sobre qué mostrar. En la analogía del planeta, JavaScript puede considerarse el cerebro de un organismo avanzado, que permite tomar decisiones en función de qué y cómo interactúa algo con él.
El backend
El backend de una aplicación web son elementos que no se ven en un navegador, pero que son importantes para su funcionamiento. En un planeta, estos son los elementos no visuales: las estructuras que mantienen en pie un edificio, el aire y la gravedad que lo mantiene en pie.
Bases de datos
A menudo, los sitios web necesitan una forma de almacenar información para sus usuarios. Los servidores web pueden comunicarse con bases de datos para almacenar y recuperar datos. Las bases de datos pueden ir desde un simple archivo de texto hasta complejos clústeres de múltiples servidores que proporcionan velocidad y resiliencia. Encontrará algunas bases de datos comunes: MySQL, MSSQL, MongoDB, Postgres y más; cada una con sus características específicas.
Una base de datos es donde se puede almacenar, modificar y recuperar información. Una aplicación web podría querer almacenar y recuperar información sobre las preferencias de un visitante sobre qué mostrar o no; esto se almacenaría en una base de datos. Un planeta puede tener habitantes más avanzados que almacenan información sobre ubicaciones en mapas, escriben notas en un diario o guardan libros en una biblioteca y archivos en un archivador.
Existen muchos otros componentes de infraestructura que sustentan las aplicaciones web, como servidores web, servidores de aplicaciones, almacenamiento, diversos dispositivos de red y otro software que las respalda. En un planeta, estos son las carreteras existentes, los vehículos que circulan por ellas y el combustible que los impulsa.
¿Cuáles son los diferentes tipos de arquitectura de aplicaciones?
La complejidad de su aplicación y sus necesidades específicas determinarán la mejor arquitectura. A continuación, se presentan algunos modelos comunes de arquitectura de aplicaciones, cada uno con sus características únicas y casos de uso ideales.
1. Arquitectura monolítica
Este es un modelo tradicional donde toda la aplicación se construye como una sola unidad, integrando todos los componentes (interfaz de usuario, lógica de negocio y acceso a datos) e implementándolos juntos. Esta simplicidad facilita el desarrollo y el mantenimiento inicial de las aplicaciones monolíticas, ya que hay menos componentes móviles que gestionar.
Dicho esto, esta arquitectura no es eficaz para aplicaciones complejas. La falta de componentes independientes dificulta la actualización o el escalado de componentes individuales de forma independiente.
- Ideal para: aplicaciones pequeñas o productos mínimos viables (MVP) que no requieren un escalamiento extenso
- Ejemplos: catálogos de productos, aplicaciones de procesamiento de pagos, aplicaciones de pago.
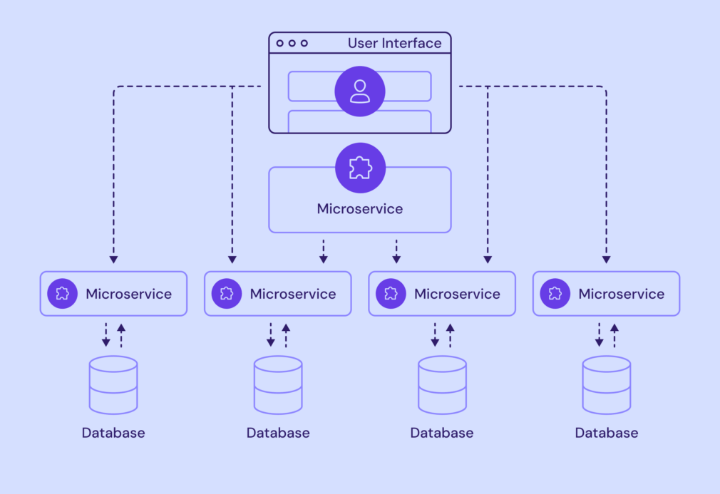
2. Arquitectura de microservicios
En la arquitectura de microservicios, la aplicación se divide en servicios más pequeños e independientes, cada uno con una función específica. Por ejemplo, una aplicación de banca en línea distribuye servicios como la gestión de cuentas, el procesamiento de transacciones y la atención al cliente en microservicios separados. Este enfoque permite a los desarrolladores actualizar o escalar servicios individuales sin afectar a toda la aplicación. Sin embargo, tenga en cuenta que cada microservicio suele administrar su propia base de datos, lo que puede generar problemas de integridad de los datos a medida que el sistema se vuelve más complejo.
- Ideal para: aplicaciones a gran escala con equipos de desarrollo independientes que requieren una entrega más rápida de funciones.
- Ejemplos: portales web de comercio electrónico, aplicaciones con múltiples funciones (función de búsqueda, etiquetado de contenido, recomendación personalizada)
3. Arquitectura sin servidor
Este tipo de arquitectura de aplicaciones es popular por su rentabilidad. El proveedor de la nube administra automáticamente los servidores y los escala según la demanda, por lo que solo pagas por lo que usas.
La desventaja es que el control y la flexibilidad pueden ser limitados. Esto también puede generar dependencia del proveedor, lo que significa que su aplicación queda vinculada a la infraestructura y las herramientas de un proveedor de nube específico.
- Ideal para: aplicaciones con cargas de trabajo impredecibles que requieren baja latencia
- Ejemplos: aplicaciones de aprendizaje automático, aplicaciones de juegos, servicios de transmisión de video
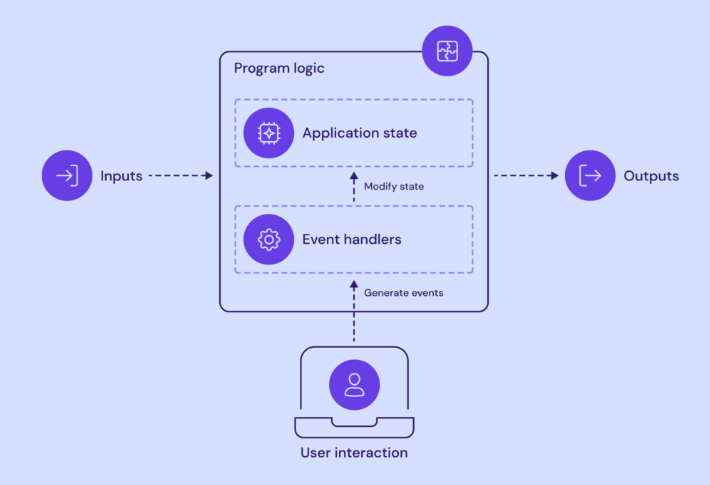
4. Arquitectura basada en eventos
Esta arquitectura implica la activación de los componentes necesarios cuando ocurre un evento en tiempo real. Permite que los sistemas reaccionen rápidamente a los cambios y brinden respuestas oportunas a los usuarios, lo que resulta ideal para aplicaciones que requieren procesamiento en tiempo real, como sistemas de monitoreo y detección de fraude.
Un desafío común que hay que anticipar es mantener el orden de los eventos. Dado que estos pueden ocurrir desordenadamente, la depuración y la monitorización pueden ser más complejas.
- Ideal para: aplicaciones y sistemas en tiempo real que necesitan responder a los eventos a medida que ocurren.
- Ejemplos: aplicaciones de chat, plataformas de compraventa de acciones, sistemas de seguimiento de paquetes.
5. Arquitectura en capas (n niveles)
En la arquitectura en capas, la aplicación se divide en capas, cada una de las cuales gestiona una función específica. La mayoría de las aplicaciones utilizan de tres a cinco capas; algunas de las más comunes son las de presentación, lógica de negocio y acceso a datos.
La separación facilita la gestión, actualización y resolución de problemas de partes de la aplicación de forma independiente. También permite escalar cada capa y reutilizar el código sin afectar la funcionalidad principal.
- Ideal para: aplicaciones empresariales que necesitan límites claros para gestionar la complejidad y los datos confidenciales.
- Ejemplos: aplicaciones bancarias, sistemas de comercio electrónico, aplicaciones empresariales.
6. Arquitectura orientada a servicios (SOA)
Este modelo es similar a los microservicios, pero suele implicar servicios más grandes y complejos. Se centra en la reutilización de los servicios en diferentes aplicaciones dentro de una organización.
Por ejemplo, en un sistema empresarial, departamentos como Recursos Humanos, Ventas y Finanzas pueden usar servicios compartidos para acceder a funcionalidades comunes, como registros de empleados o datos financieros.
- Ideal para: aplicaciones grandes a escala empresarial que requieren comunicación entre diferentes servicios en toda la organización.
- Ejemplos: gestión de relaciones con el cliente (CRM), software como servicio (SaaS)
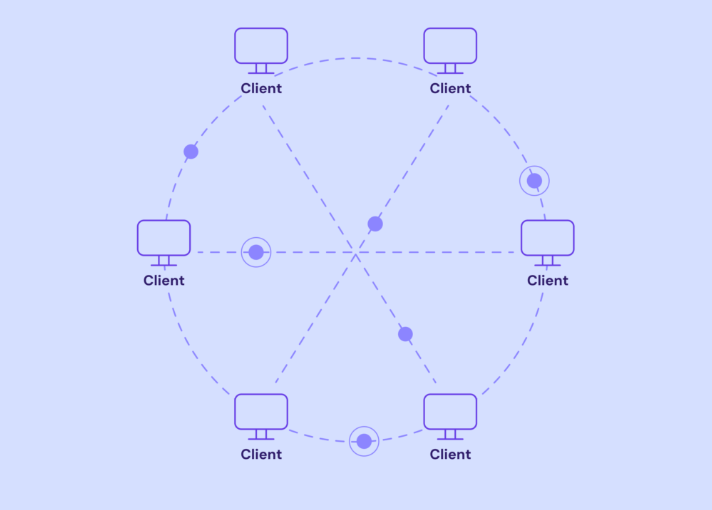
7. Arquitectura peer-to-peer (P2P)
En una arquitectura peer-to-peer, cada dispositivo o nodo actúa como cliente y servidor, compartiendo recursos directamente con otros. Esta estructura hace que el sistema sea más flexible y resistente a fallos de nodos, garantizando la disponibilidad continua incluso cuando algunos pares se desconectan.
- Ideal para: aplicaciones descentralizadas que necesitan comunicación directa entre usuarios.
- Ejemplos: aplicaciones para compartir archivos como BitTorrent
8. Arquitectura nativa de la nube
La arquitectura nativa de la nube está diseñada para entornos de nube, lo que permite que las aplicaciones aprovechen al máximo la escalabilidad, flexibilidad y disponibilidad de la nube. Los desarrolladores contenedorizan las aplicaciones nativas de la nube y las gestionan con herramientas como Kubernetes.
A diferencia de la arquitectura sin servidor, las aplicaciones nativas de la nube brindan a los desarrolladores más control sobre su infraestructura y estrategias de escalamiento.
- Ideal para: aplicaciones escalables y distribuidas que requieren recursos en la nube y se benefician del escalamiento automático y la alta disponibilidad.
- Ejemplos: plataformas para compartir imágenes, aplicaciones de colaboración
WAF (Web Application Firewall )
Es un componente opcional para aplicaciones web. Ayuda a filtrar las solicitudes peligrosas del servidor web y proporciona un elemento de protección. Esto podría considerarse similar a cómo la atmósfera de un planeta protege a sus habitantes de los dañinos rayos UV.
Existen muchos componentes involucrados en la entrega de una aplicación web. Los componentes front-end, como HTML, CSS y JavaScript, se centran en la experiencia dentro del navegador. Los componentes back-end, como el servidor web, la base de datos o el WAF, son el motor subyacente que permite el funcionamiento de la aplicación web.
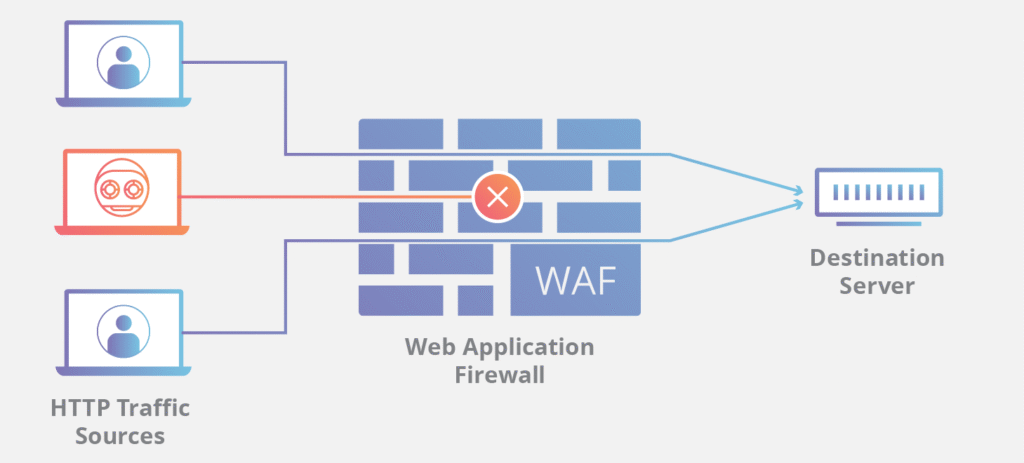
La imagen muestra el funcionamiento básico de un WAF, o Firewall de Aplicaciones Web, una herramienta diseñada para proteger a los servidores contra ataques web filtrando el tráfico HTTP antes de que llegue a la aplicación.
En un entorno normal, los usuarios legítimos (clientes reales) envían solicitudes a través de sus navegadores para acceder al sitio o aplicación. Sin embargo, entre ellos pueden aparecer agentes maliciosos o bots automatizados que intentan explotar vulnerabilidades como inyecciones SQL, XSS (Cross-Site Scripting) o intentos de fuerza bruta.
Un WAF se ubica entre tu solicitud web y el servidor web; su propósito principal es protegerlo de ataques de hackers o denegación de servicio. Analiza las solicitudes web en busca de técnicas de ataque comunes, independientemente de si provienen de un navegador real o de un bot. También verifica si se envía un número excesivo de solicitudes web mediante la limitación de velocidad, que solo permite una cierta cantidad de solicitudes por segundo desde una IP. Si una solicitud se considera un posible ataque, se descarta y nunca se envía al servidor web.
El WAF actúa como una barrera inteligente entre las fuentes de tráfico y el servidor de destino:
- Analiza cada solicitud HTTP o HTTPS en tiempo real.
- Detecta patrones sospechosos (por ejemplo, cadenas de código malicioso, consultas extrañas o comportamientos automatizados).
- Bloquea las peticiones peligrosas, permitiendo solo el tráfico legítimo hacia el servidor.
En la imagen se ve cómo el WAF intercepta el tráfico proveniente de distintas fuentes:
- Las solicitudes válidas de usuarios reales pasan sin problema.
- Las solicitudes maliciosas son detenidas antes de llegar al servidor.
Gracias a esto, el servidor puede concentrarse en procesar las peticiones seguras, evitando caídas, sobrecarga y daños potenciales en la base de datos o la aplicación. El uso de un WAF es fundamental para mitigar ataques como:
- Inyección SQL
- Cross-Site Scripting (XSS)
- File Inclusion
- Cross-Site Request Forgery (CSRF)
- Ataques de automatización o scraping masivo
En resumen, un Web Application Firewall no solo protege la infraestructura, sino que también mantiene la disponibilidad y la integridad de los servicios web.
Combinado con una CDN, un balanceador de carga y buenas prácticas de seguridad, se convierte en una de las defensas más efectivas contra ataques web modernos.
Cloudflare Web Application Firewall
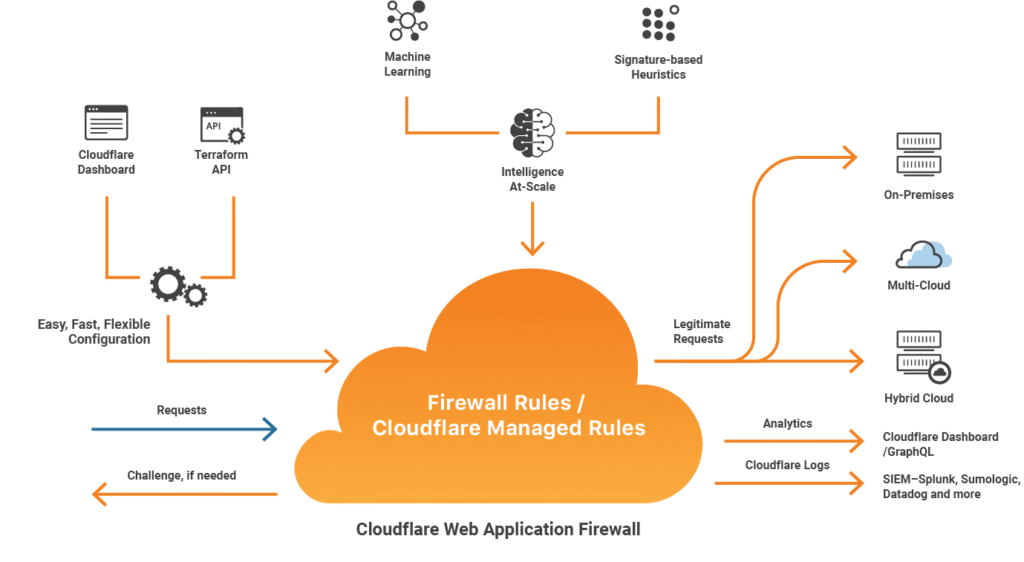
La imagen muestra la arquitectura y el flujo de funcionamiento del Cloudflare Web Application Firewall, una de las soluciones más avanzadas para la protección de aplicaciones web modernas. Este WAF combina reglas automáticas, aprendizaje automático (machine learning) y heurísticas basadas en firmas para identificar y bloquear amenazas antes de que lleguen al servidor.
1. Configuración flexible y automatizada
Cloudflare permite configurar el firewall desde su panel de control (Cloudflare Dashboard) o mediante API de Terraform, lo que facilita la integración con infraestructuras automatizadas. Esto brinda una administración rápida, escalable y adaptable a entornos en constante cambio.
2. Análisis inteligente del tráfico
Cada solicitud HTTP que llega a la aplicación pasa primero por las Firewall Rules / Cloudflare Managed Rules. Aquí se aplican varios niveles de análisis:
- Machine Learning: detecta comportamientos anómalos y patrones nuevos de ataque.
- Heurísticas basadas en firmas: reconocen amenazas conocidas (por ejemplo, payloads de inyección SQL o XSS).
- Inteligencia global: el sistema se alimenta de datos recopilados a escala mundial, mejorando la detección de ataques emergentes en tiempo real.
3. Filtrado y respuesta
- Las solicitudes legítimas se enrutan hacia los servidores de destino, que pueden estar on-premise, en multi-cloud o en infraestructura híbrida.
- Las solicitudes sospechosas o maliciosas son bloqueadas o desafiadas (challenge), solicitando, por ejemplo, una verificación CAPTCHA o una validación adicional.
4. Monitoreo y análisis
El WAF genera Cloudflare Logs y envía datos analíticos a herramientas como Splunk, Sumo Logic o Datadog, permitiendo a los equipos de seguridad centralizar eventos y realizar análisis forense o de comportamiento. Además, la información se visualiza en tiempo real desde el Cloudflare Dashboard o a través de consultas GraphQL.
En conjunto, el Cloudflare WAF no solo bloquea ataques conocidos, sino que aprende y evoluciona constantemente, ofreciendo una defensa dinámica frente a amenazas como inyecciones, bots, intentos de explotación de vulnerabilidades y ataques DDoS. Es una capa esencial dentro de una estrategia moderna de seguridad perimetral y zero trust.
Poniéndolo todo junto
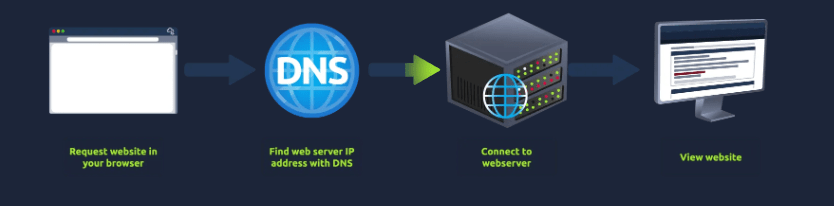
En los módulos anteriores, habrás aprendido que hay muchas cosas que suceden detrás de escena cuando solicitas una página web en tu navegador. En resumen, cuando accedes a un sitio web, tu equipo necesita conocer la dirección IP del servidor con el que se conecta; para ello, utiliza DNS . Tu ordenador se comunica con el servidor web mediante un conjunto especial de comandos llamado protocolo HTTP . El servidor web devuelve HTML, JavaScript, CSS, imágenes, etc., que tu navegador utiliza para formatear y mostrar el sitio web correctamente. También hay algunos otros componentes que ayudan a que la web funcione de manera más eficiente y brindan funciones adicionales.
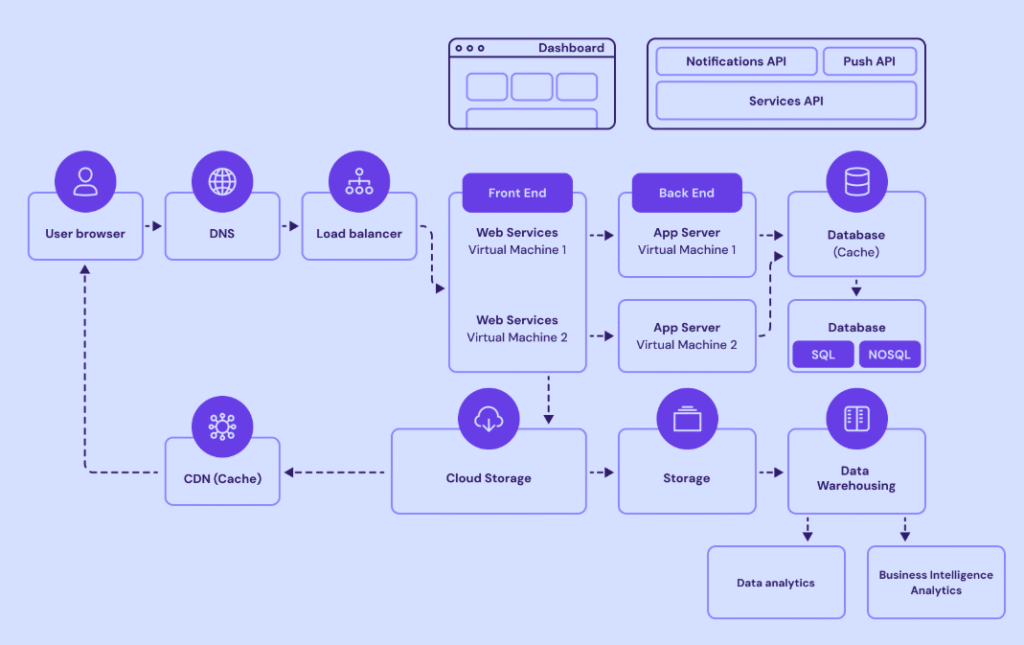
La imagen muestra una arquitectura distribuida típica en aplicaciones web de gran escala, donde cada componente cumple una función específica para garantizar rendimiento, disponibilidad y seguridad.
1. Usuario, DNS y balanceador de carga
Todo comienza con el navegador del usuario, que realiza una solicitud al DNS, el cual traduce el nombre de dominio a la dirección IP del servicio.
Luego, el Load Balancer (balanceador de carga) distribuye el tráfico entre varias máquinas virtuales para evitar sobrecarga en un solo servidor y asegurar continuidad incluso si uno falla.
2. Front-End (capa de presentación)
El Front End contiene los Web Services, alojados en máquinas virtuales independientes.
Esta capa gestiona las peticiones del usuario, la interfaz gráfica y las interacciones iniciales con la aplicación. Su objetivo es responder rápido y delegar las operaciones complejas al backend.
3. Back-End (lógica y procesamiento)
El Back End está compuesto por servidores de aplicación que ejecutan la lógica del negocio: autenticación, cálculos, reglas internas, API de servicios, etc.
Aquí se integran también las APIs de notificaciones, servicios o mensajes push, que comunican diferentes módulos de la aplicación.
4. Base de datos y almacenamiento
El Database puede incluir sistemas SQL (estructurados) o NoSQL (flexibles y de alta velocidad), y a menudo utiliza una capa de caché para acelerar respuestas.
Los datos se almacenan en Cloud Storage o en sistemas locales de Storage, y se replican en un Data Warehouse destinado al análisis y a la inteligencia de negocio (BI).
5. CDN y cacheo de contenido
La CDN (Content Delivery Network) almacena en caché los recursos estáticos (imágenes, archivos JS, CSS, etc.) en servidores distribuidos globalmente.
Esto reduce la carga en los servidores de aplicación y mejora la velocidad para los usuarios de distintas regiones.
6. Análisis y optimización
Los datos recopilados se envían a módulos de Data Analytics y Business Intelligence, donde se analizan patrones de uso, rendimiento y seguridad, permitiendo optimizar la infraestructura y anticipar incidentes.
Esta arquitectura combina eficiencia, escalabilidad y resiliencia, siendo el estándar en plataformas modernas. Además, desde la perspectiva del pentesting o la ciberseguridad, cada capa representa un punto de posible ataque: DNS spoofing, inyección en APIs, escalamiento en bases de datos o explotación de fallos en el balanceador de carga. Comprender esta estructura es esencial para proteger una aplicación de extremo a extremo.
Cuando leo http entiendo que es https, no tengo mucho conocimiento pero si aconsejan nunca conectarse con http.
Escribo según voy leyendo y ya me di cuenta que se habla también del protocolo https.
Esperaré a leerlo para entender sus diferencias.
Un contenido muy denso que hay que ir comprendiendo según se maneja. Dios ya no recuerdo ni la mitad de las siglas.