En este capítulo, A06:2025 – Diseño inseguro – Insecure Design, , vas a adentrarte en uno de los conceptos más transformadores y esenciales del desarrollo moderno: la seguridad desde el diseño. A medida que las aplicaciones se vuelven más complejas, distribuidas y expuestas, ya no alcanza con “arreglar vulnerabilidades”. La seguridad debe pensarse, planificarse y estructurarse antes de escribir una sola línea de código.
A lo largo de este recorrido vas a aprender:
- Cómo ha evolucionado el OWASP Top 10, en especial la categoría A06: Insecure Design, y por qué hoy es una de las raíces más frecuentes de compromisos reales.
- Por qué la seguridad no es un parche, sino una decisión de arquitectura, cultura y proceso.
- Cómo identificar errores de diseño que no son bugs de código, sino fallas profundas en la lógica, reglas de negocio o flujos críticos.
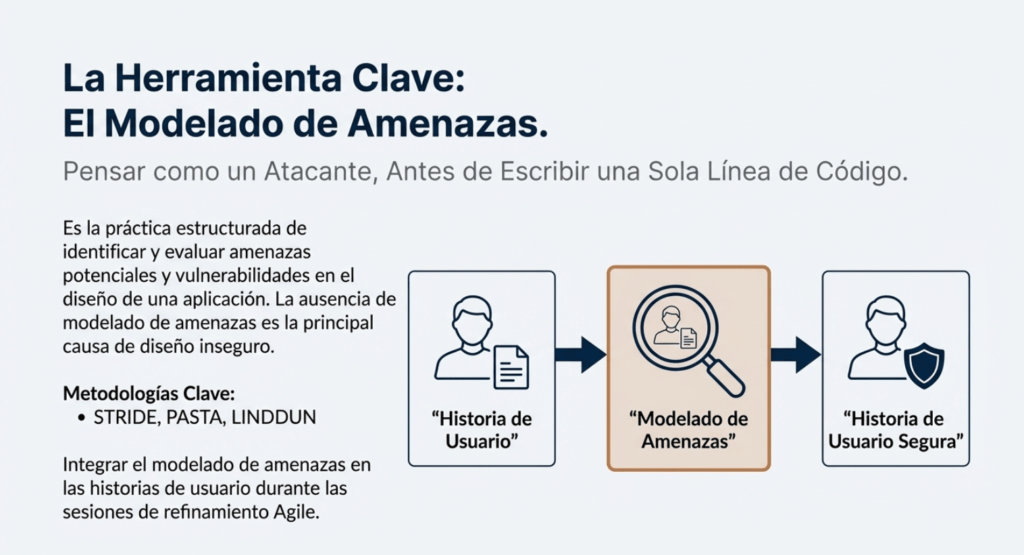
- El rol indispensable del modelado de amenazas, STRIDE, PASTA, LINDDUN y otros enfoques para anticiparte a ataques antes de que existan.
- Cómo documentar y defender arquitecturas modernas como microservicios, APIs distribuidas y cloud-native.
- De qué forma implementar un ciclo de vida de desarrollo seguro (SDLC), incorporando threat modeling, requisitos de seguridad, límites de confianza y análisis de superficie de ataque.
- Qué son los patrones de seguridad, cómo se construyen y cómo te permiten reutilizar soluciones robustas en diferentes proyectos.
- Cómo aplicar seguridad en entornos Agile sin frenar la entrega, usando barandillas, controles incrementales y gobernanza práctica.
- Casos reales, errores comunes, escenarios de abuso y ejemplos concretos de cómo un atacante piensa, explota y rompe diseños deficientes.
Este capítulo es un punto de inflexión: marca la diferencia entre desarrollar funcionalidad…
y diseñar sistemas que sobreviven al mundo real.
A06:2025 Diseño Inseguro – Arquitectura Frágil, Brechas Predecibles
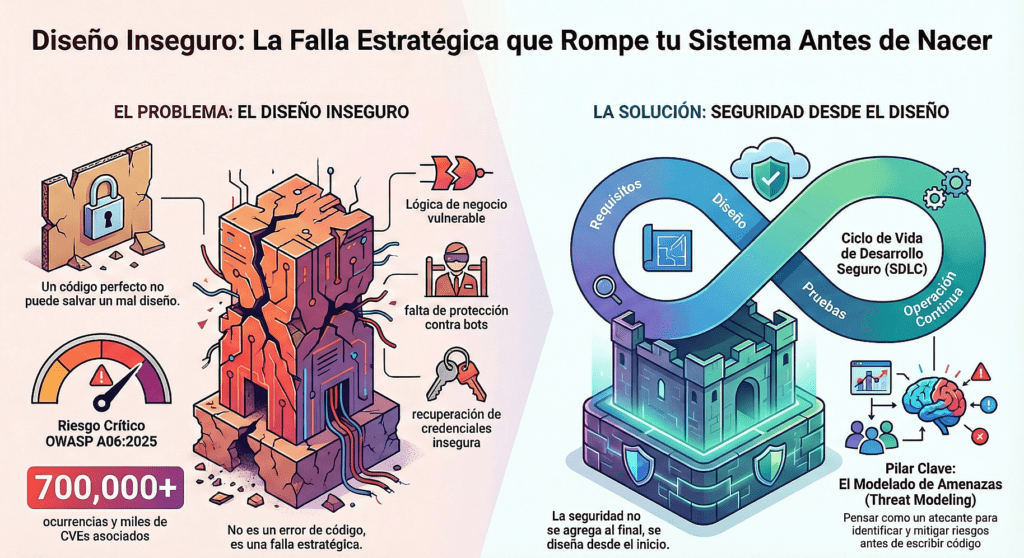
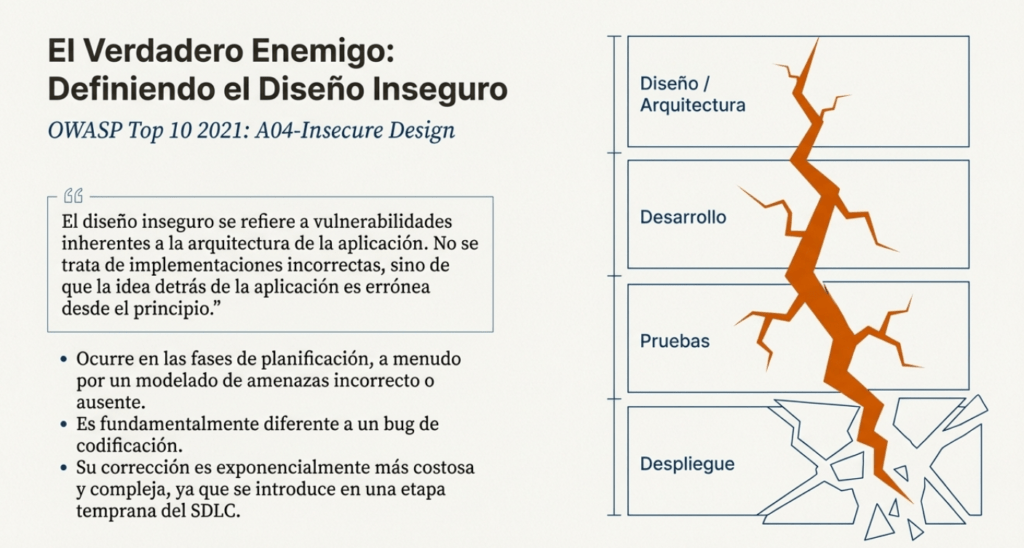
Cuando hablamos de diseño inseguro, no estamos hablando de bugs, de malas prácticas de codificación ni de errores de configuración. Estamos hablando de sistemas que ya nacieron rotos. Arquitecturas que fueron concebidas sin considerar las amenazas, sin entender los riesgos y, peor aún, sin la menor intención de resistir una agresión deliberada. Y lo más preocupante es que este no es un problema menor: es una de las categorías más peligrosas del OWASP Top 10.
Te lo digo como alguien que ha visto cómo se comprometen sistemas enteros sin necesidad de un 0-day. Bastó con seguir los flujos de negocio, entender qué decisiones de diseño fueron tomadas a ciegas, y ahí estaba el agujero. Porque el diseño inseguro no es un fallo técnico. Es un error estratégico. Es una deuda que se asume desde el día uno y que se paga con datos robados, reputación destruida y sistemas colapsados.
La diferencia entre diseño inseguro e implementación insegura es brutal. Podés tener el mejor código del mundo, limpio, eficiente, probado. Pero si el sistema está mal diseñado, si no hay controles donde debe haberlos, si los límites de confianza no están claros, si la lógica de negocio tiene huecos, ese código es una fachada. Una pintura bonita en una pared de cartón.
El diseño inseguro se da cuando nunca se pensó en qué podía salir mal. Cuando el modelado de amenazas brilla por su ausencia, cuando nadie se sentó a pensar qué debería pasar si un atacante fuerza un flujo de negocio, si falsifica una identidad, si abusa de la lógica o fuerza condiciones inesperadas. No diseñar con la amenaza en mente es como construir una casa sin puertas ni cerraduras, esperando que nadie entre porque «es una zona tranquila».
La categoría A06:2025 del OWASP pone esto en evidencia con ejemplos concretos y cifras demoledoras. Más de 700 mil ocurrencias documentadas. Miles de CVEs asociados. Un promedio de impacto altísimo. Y, lo más alarmante, una tasa de cobertura bajísima en muchas organizaciones. Porque este no es un problema que se detecte con un escáner. No salta en un test unitario. No lo ve el QA. Lo ve el atacante. Y lo aprovecha.
Uno de los escenarios clásicos es la lógica de recuperación de credenciales. Sistemas que todavía, en 2025, permiten recuperar una cuenta respondiendo preguntas triviales. Otro, más sutil pero igual de peligroso, es la falta de control de flujo en lógicas de negocio complejas: descuentos mal aplicados, validaciones salteadas, límites que no se respetan. Todo eso es terreno fértil para ataques sin siquiera romper el código. Solo hay que pensar mejor que quien lo diseñó.
Y después está el problema de los bots. Sistemas que nacen sin ningún tipo de defensa contra automatización maliciosa, que permiten abusar de recursos, de compras, de stock, porque nadie pensó que alguien podría automatizar ese flujo. Y entonces aparecen los scripts que barren con todo, revenden, colapsan sistemas, y lo único que queda es el caos.
El diseño seguro, en cambio, se construye con tres pilares: una recopilación clara de requisitos (que incluya seguridad desde el inicio), un proceso de diseño que priorice la resiliencia frente a amenazas reales, y un ciclo de vida que mantenga esa seguridad viva a lo largo del tiempo.
Esto no se trata de «meter seguridad después». Se trata de pensar como un atacante desde el día uno. De integrar el modelado de amenazas en las historias de usuario. De revisar cada flujo con los ojos de alguien que busca romperlo. De validar las suposiciones, de identificar los estados de error, de documentar todo lo que se espera que ocurra y todo lo que no debe pasar nunca.
El diseño seguro tampoco se trata de herramientas. No vas a arreglar esto instalando un plugin o activando un checkbox. Se trata de disciplina. De cultura. De incluir a especialistas en seguridad desde el principio. De usar patrones de diseño seguros. De tener una biblioteca de componentes pavimentados, auditados, probados. De segregar responsabilidades, capas, usuarios, inquilinos. De validar todo, todo el tiempo.
El modelo de madurez SAMM de OWASP es una guía potente para lograr esto. Pero no alcanza con leerlo. Hay que aplicarlo. Hay que evaluar constantemente la arquitectura, identificar dónde se están tomando atajos, dónde los controles no están alineados al riesgo, dónde la superficie de ataque crece sin control.
Diseñar de forma segura no es más caro. Es más barato a largo plazo. Porque arreglar un diseño inseguro después de la puesta en producción es como querer reforzar la estructura de un edificio cuando ya está habitado. Se puede, pero es doloroso, costoso y siempre vas a dejar algo sin cubrir.
Un buen diseño anticipa las amenazas. Define límites claros. Minimiza el acceso. Reduce la superficie expuesta. Permite auditar. Hace difícil hacer las cosas mal. Obliga a los atacantes a encontrar nuevos caminos. Y cuando los encuentran, los limita, los aísla, los desacopla.
Un mal diseño, en cambio, deja puertas abiertas. Confía ciegamente. Mezcla responsabilidades. Acepta datos sin validar. Depende de la suerte. Y la suerte no es estrategia de seguridad. Así que si estás diseñando una aplicación, no empieces por el stack. No empieces por el framework. Empezá por entender qué vas a proteger, contra quién, y con qué herramientas. Empezá por definir los riesgos. Por identificar los activos. Por mapear los flujos de datos. Por dibujar los límites de confianza. Por pensar como un atacante.
Porque te aseguro esto: si vos no lo hacés, alguien más lo va a hacer por vos. Y cuando lo haga, ya va a ser tarde. El diseño inseguro no se parchea. Se previene. Y prevenir empieza con una decisión: diseñar bien o dejarse romper.

OWASP TOP 10
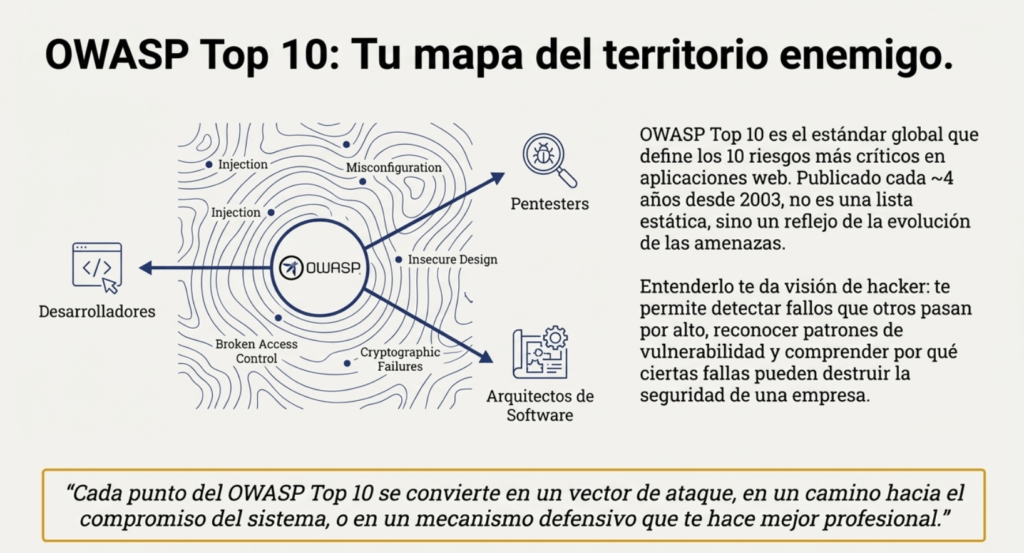
OWASP es popular por publicar el TOP 10 Owasp Web cada cuatro años. Este es un documento que lista los diez riesgos más críticos en aplicaciones web, con el objetivo de ayudar a las organizaciones a identificar y mitigar las vulnerabilidades asociadas con estos riesgos. https://owasp.org/Top10/es/ Cada uno de estos riesgos representa una debilidad común y significativa que a menudo se puede explotar para comprometer la seguridad de una aplicación web. OWASP proporciona información detallada sobre posibles vulnerabilidades y técnicas de ataque para cada riesgo.
El Top 10 de OWASP es una lista que se actualiza periódicamente de los riesgos de seguridad de las aplicaciones web más críticos. Lo mantiene el Proyecto Abierto de Seguridad de Aplicaciones Web (OWASP), una organización sin fines de lucro centrada en mejorar la seguridad de las aplicaciones web. Sirve como una valiosa guía para que los desarrolladores, los expertos en pruebas de penetración de aplicaciones web y las organizaciones comprendan y prioricen los riesgos de seguridad comunes en las aplicaciones web.
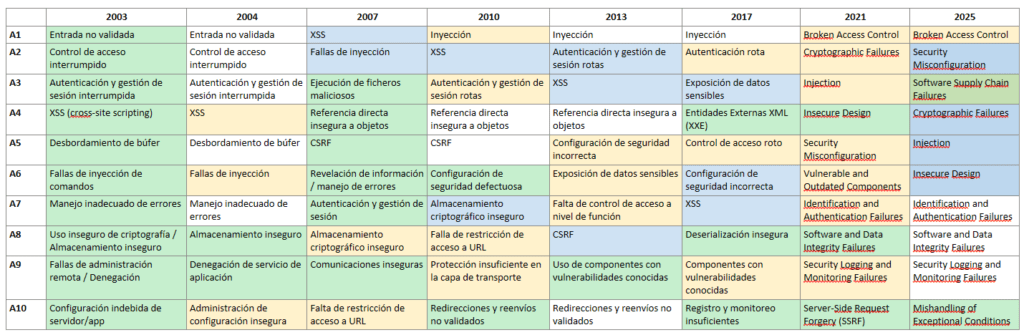
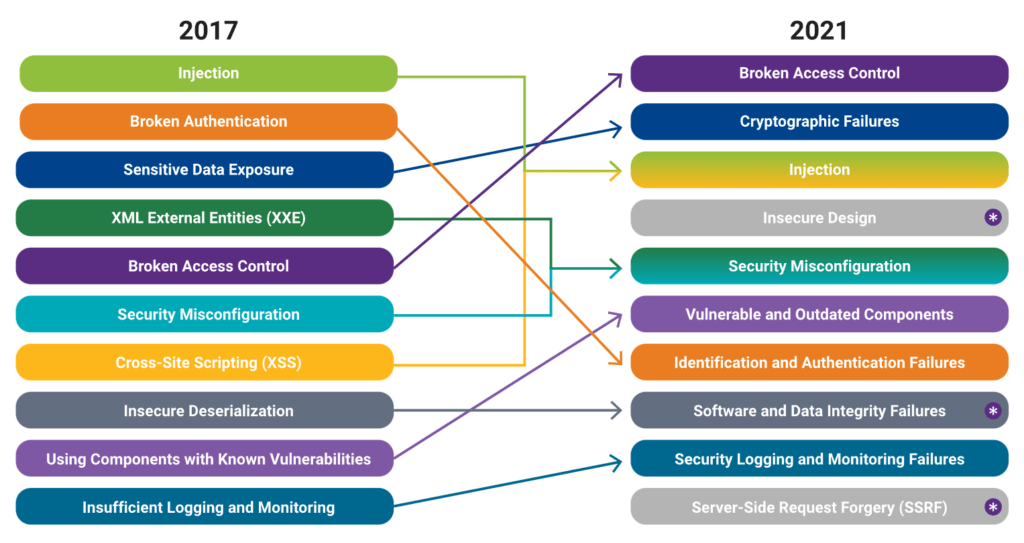
El Top 10 de OWASP es una lista conocida de los diez riesgos de seguridad de aplicaciones web más críticos. Se actualiza periódicamente para garantizar que refleje el panorama actual de amenazas y los desafíos de seguridad en constante evolución que enfrentan las aplicaciones web. La primera versión del Top 10 de OWASP se publicó en 2003. Su objetivo era crear conciencia sobre los riesgos comunes de seguridad de las aplicaciones web y ayudar a los desarrolladores a priorizar los esfuerzos de seguridad. La lista incluía riesgos como secuencias de comandos entre sitios (XSS), inyección de SQL y problemas de gestión de sesiones. Cada lanzamiento del Top 10 de OWASP se basa en las versiones anteriores, mejorando su precisión, relevancia y practicidad.
Evolución de OWASP TOP 10
En el momento de crear este artículo coexiste las dos versiones 2021/2025.
⚪No cambia
🟡Fusionado
🔵Cambia de posición
🟢Nuevo
La evolución de A06:2025 – Insecure Design: el renacimiento de la seguridad desde la arquitectura
La incorporación y consolidación de Insecure Design (Diseño Inseguro) dentro del OWASP Top 10 representa uno de los cambios más significativos y profundos en la historia del análisis de riesgos de aplicaciones web. A diferencia de vulnerabilidades clásicas como Injection, Broken Authentication o Misconfiguration, esta categoría no apunta a un fallo técnico puntual, sino a un problema cultural, estructural y metodológico en el desarrollo de software. Insecure Design refleja el reconocimiento de que muchas de las vulnerabilidades más graves no nacen en el código, sino en la arquitectura conceptual que define cómo ese código debería comportarse. Su presencia en A06:2025 muestra la madurez de la industria hacia una visión más estratégica de la seguridad.
Históricamente, OWASP centró su atención en vulnerabilidades técnicas específicas: inyecciones, configuraciones incorrectas, errores criptográficos, validación deficiente. Durante las primeras ediciones entre 2003 y 2013, casi todas las categorías estaban orientadas a fallas que podían detectarse mediante escaneo, revisión manual o pentesting. En esa época, se pensaba que la seguridad era principalmente un problema de implementación: si un desarrollador cometía un error al validar un input o al construir una consulta SQL, la aplicación podía comprometerse. Sin embargo, con el paso del tiempo, OWASP comenzó a detectar patrones que no se explicaban solo por errores en el código. Había vulnerabilidades que surgían incluso cuando el código estaba “bien escrito” porque el diseño general de la aplicación era inseguro desde su origen.
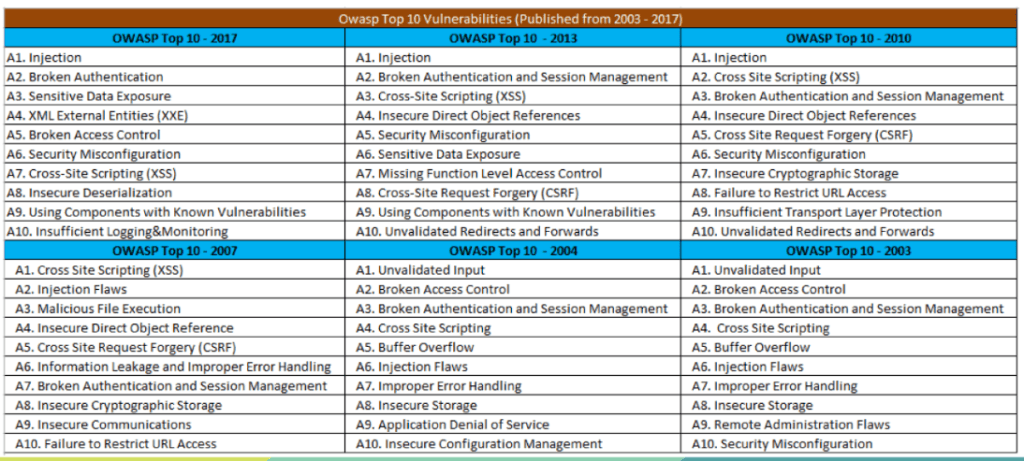
Este cambio conceptual comenzó a madurar en OWASP Top 10 – 2017, cuando OWASP introdujo la idea de que muchas vulnerabilidades tienen raíces arquitectónicas profundas. Pero no fue hasta 2021, con la introducción formal de la categoría A04:2021 – Insecure Design, que OWASP reconoció explícitamente que la seguridad no es solo una cuestión de implementación, sino de pensar y planificar correctamente antes de codificar. Esta categoría generó un impacto fuerte porque señalaba algo incómodo: gran parte de las organizaciones no integra prácticas de seguridad durante la fase de diseño y arquitectura, sino que intenta “parchar” vulnerabilidades después de que el sistema ya está construido.
La evolución continúa con OWASP Top 10 – 2025, donde Insecure Design se posiciona como A06, consolidándose como uno de los pilares centrales del modelo moderno de riesgos. La categoría abarca fallas sistémicas como:
- Lógicas de negocio vulnerables por diseño.
- Modelos de autorización mal definidos.
- Ausencia de controles de seguridad en la arquitectura.
- Falta de separación entre componentes críticos.
- Diseños que confían en el cliente.
- Modelos de threat modeling inexistentes o incompletos.
- Falta de mecanismos para mitigar ataques previstos.
- Dependencias excesivas sin validación de seguridad.
- Flujos internos inseguros que permiten bypass de controles.
- Insuficiente consideración de abuso (abuse cases).
A diferencia de otras vulnerabilidades, Insecure Design no puede parchearse con un fix puntual. Si un sistema está mal diseñado, toda la estructura puede ser insegura. Y este es precisamente uno de los motivos por los que OWASP le da un lugar tan prominente: representa un tipo de riesgo que no puede detectarse únicamente con herramientas de análisis estático o pentesting, sino que requiere una revisión profunda del modelo conceptual de la aplicación.
OWASP TOP 10 2021
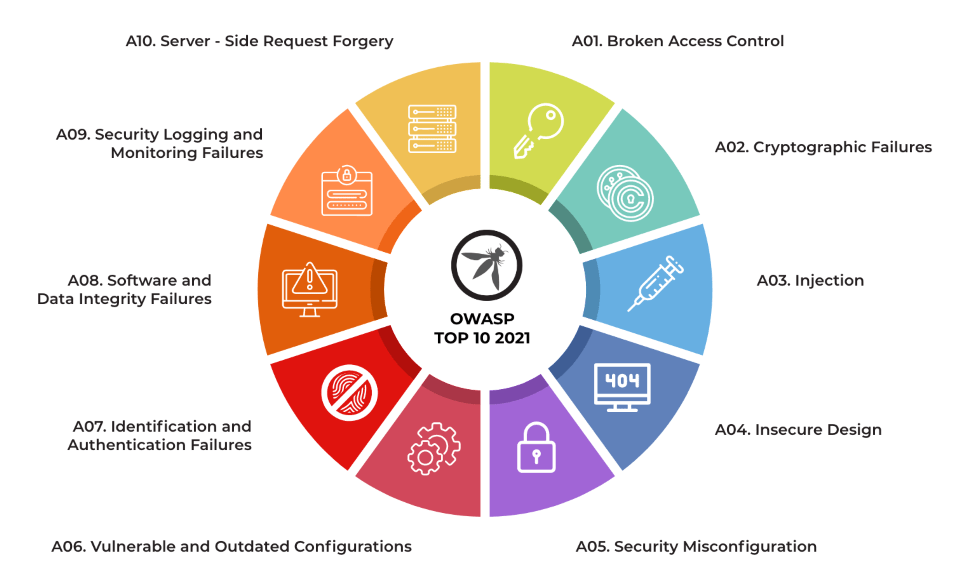
La industria también comenzó a comprender que muchos de los ataques modernos —incluso los más sofisticados— no explotan vulnerabilidades técnicas aisladas, sino errores de diseño. Por ejemplo:
- Ataques de abuso lógico (comprar un producto a precio negativo, saltar pasos de compra, manipular flujos).
- Saltos de autorización no debidos a código mal escrito sino a flujos mal concebidos.
- APIs que permiten enumeración por diseño.
- Sistemas que exponen metadata sensible porque fueron concebidos sin threat modeling.
- Aplicaciones que implementan seguridad reactiva, no preventiva.
OWASP reconoce en 2025 que la principal causa de diseño inseguro es la ausencia de threat modeling estructurado. Muchas organizaciones todavía desarrollan siguiendo metodologías rápidas, impulsadas por presión comercial, sin contemplar el impacto de amenazas realistas. El código se escribe antes de entender qué proteger, por qué protegerlo y cómo podría ser atacado. Las métricas comerciales predominan sobre la seguridad y el diseño queda relegado. A06:2025 es, por tanto, un llamado a cambiar la cultura de desarrollo: la seguridad debe estar integrada desde la concepción del software, no después.
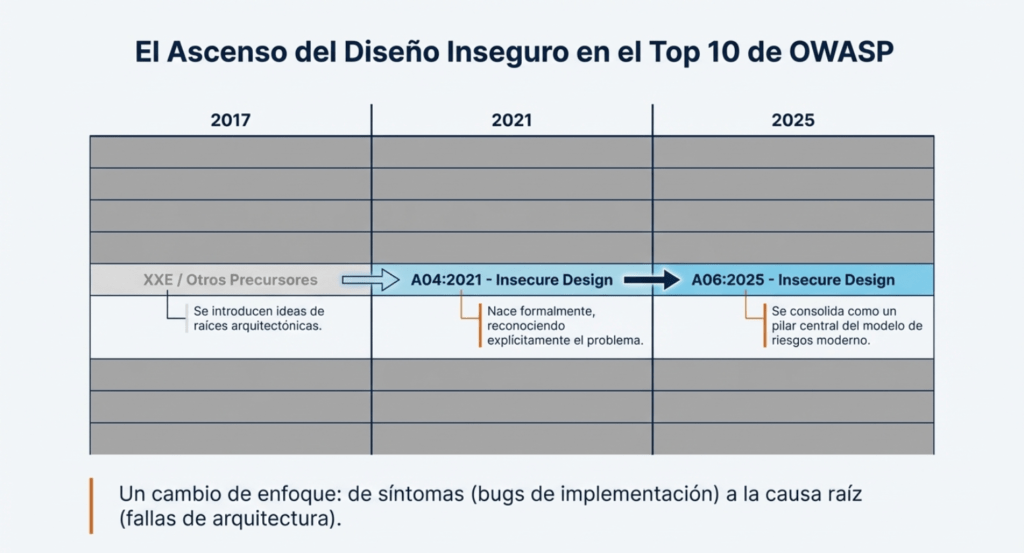
OWASP TOP 10 2025
En la lista de los Diez Principales para 2025, se han incorporado dos categorías nuevas y una consolidada. Esta versión según OWASP está centrada en la causa raíz, más que en los síntomas, en la medida de lo posible. Dada la complejidad de la ingeniería y la seguridad del software, resulta prácticamente imposible crear diez categorías sin cierto grado de superposición.
Otro factor clave en esta categoría es el auge de los ataques automatizados y el elevado nivel de creatividad de los adversarios. Los sistemas actuales deben anticipar no solo casos de uso, sino también casos de abuso. La mayoría de los desarrolladores piensa en flujos ideales: un usuario legítimo realiza acciones legítimas siguiendo pasos previstos. Pero un atacante analizará cada elemento del diseño para encontrar formas de manipular, romper o subvertir la lógica del sistema. En este sentido, Insecure Design obliga a pensar como atacante desde la fase de arquitectura, no como un ejercicio complementario.
En 2025, Insecure Design ya no es simplemente una categoría más: es una categoría transversal, ya que un diseño inseguro puede habilitar fallos criptográficos, inyecciones, problemas de autorización, filtraciones de datos e incluso fallas en la cadena de suministro. Es un multiplicador de riesgos. Cuando el diseño es débil, cada parte del sistema se vuelve susceptible. Esto convierte a A06:2025 en una categoría estratégica: la que, si se aborda correctamente, puede prevenir la mayoría de las demás.
En resumen, la evolución de Insecure Design desde 2003 hasta 2025 muestra un desplazamiento del enfoque clásico de la seguridad —centrado en arreglar errores de código— hacia un modelo holístico donde la arquitectura, la lógica de negocio, los flujos internos y los casos de abuso deben ser analizados antes de escribir una sola línea de código. Su consolidación en el puesto A06:2025 significa que la industria finalmente reconoce que la seguridad no puede improvisarse después: debe diseñarse. Y debe diseñarse bien.
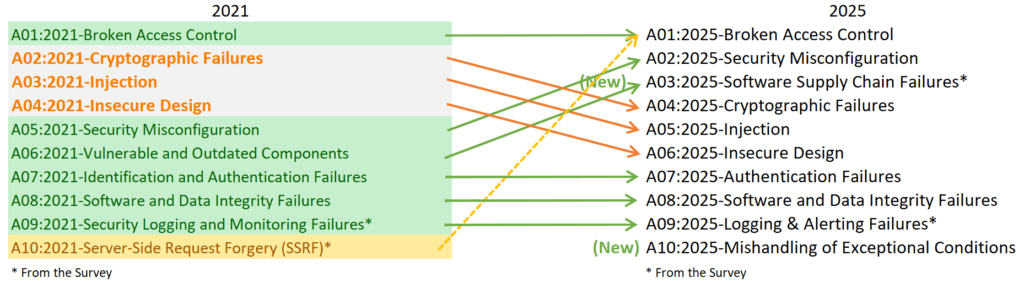
A06:2025 Diseño inseguro
El Diseño Inseguro baja dos puestos, del 4.º al 6.º, superando a la categoría A02:2025 (Configuración incorrecta de seguridad) y A03:2025 (Fallo en la cadena de suministro de software) . Esta categoría, introducida en 2021, ha permitido observar mejoras notables en el sector en lo que respecta al modelado de amenazas y un mayor énfasis en el diseño seguro. Esta categoría se centra en los riesgos relacionados con fallos de diseño y arquitectura, con un mayor uso del modelado de amenazas, patrones de diseño seguro y arquitecturas de referencia. Esto incluye fallos en la lógica de negocio de una aplicación, como la falta de definición de cambios de estado no deseados o inesperados dentro de ella. Como comunidad, debemos ir más allá del «desplazamiento a la izquierda» en el ámbito de la codificación para precodificar actividades como la redacción de requisitos y el diseño de aplicaciones, que son fundamentales para los principios de Seguridad por Diseño (p. ej., véase » Establecer un programa moderno de AppSec: Fase de planificación y diseño «). Las enumeraciones de debilidad común (CWE) notables incluyen CWE-256: almacenamiento desprotegido de credenciales, CWE-269 administración incorrecta de privilegios, CWE-434 carga sin restricciones de archivo con tipo peligroso, CWE-501: violación del límite de confianza y CWE-522: credenciales insuficientemente protegidas.
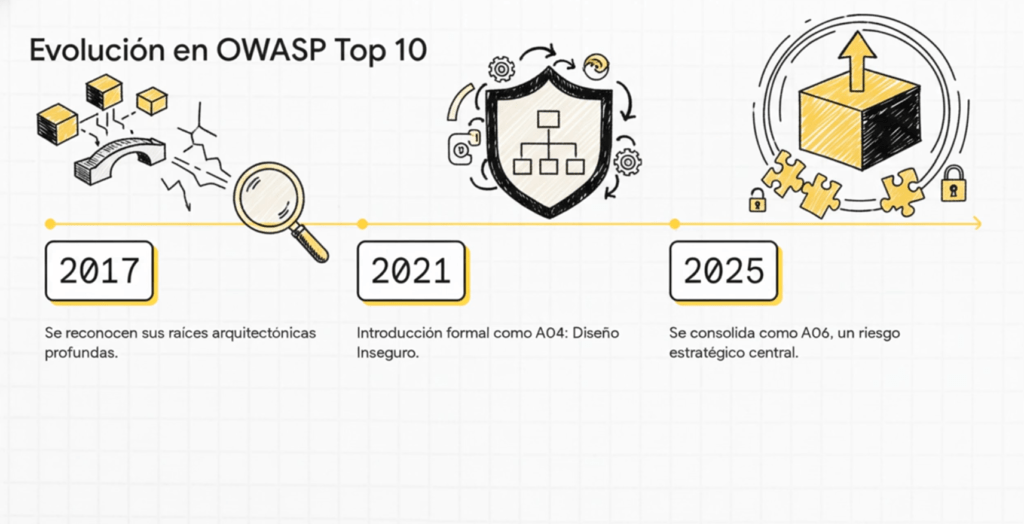
Tabla de puntuación.
| CWE mapeados | Tasa máxima de incidencia | Tasa de incidencia promedio | Cobertura máxima | Cobertura promedio | Exploit ponderado promedio | Impacto ponderado promedio | Total de ocurrencias | Total de CVEs |
| 39 | 22,18% | 1,86% | 88,76% | 35,18% | 6.96 | 4.05 | 729.882 | 7.647 |

Descripción.
El diseño inseguro es una categoría amplia que representa diferentes debilidades, expresadas como un diseño de control ineficaz o ausente. No es la causa de las demás diez categorías de riesgo principales. Cabe destacar que existe una diferencia entre el diseño inseguro y la implementación insegura. Distinguimos entre fallas de diseño y defectos de implementación por una razón: tienen diferentes causas, ocurren en diferentes momentos del proceso de desarrollo y requieren diferentes soluciones. Un diseño seguro puede presentar defectos de implementación que generen vulnerabilidades susceptibles de ser explotadas. Un diseño inseguro no se puede solucionar con una implementación perfecta, ya que nunca se crearon los controles de seguridad necesarios para defenderse de ataques específicos. Uno de los factores que contribuye al diseño inseguro es la falta de un perfil de riesgos empresariales inherente al software o sistema en desarrollo y, por lo tanto, la imposibilidad de determinar el nivel de seguridad requerido.
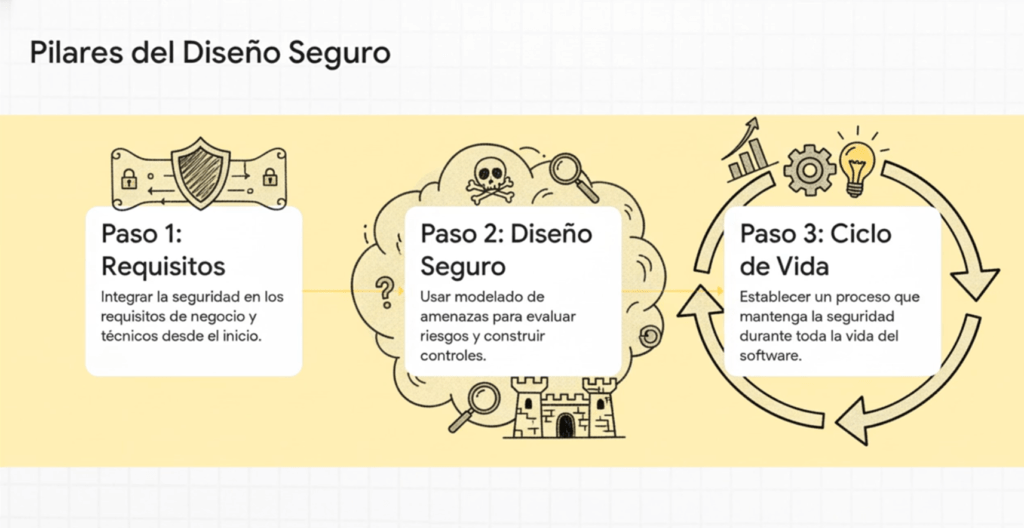
Tres partes clave para tener un diseño seguro son:
- Recopilación de requisitos y gestión de recursos
- Creando un diseño seguro
- Tener un ciclo de vida de desarrollo seguro
Requisitos y gestión de recursos
Recopile y negocie con la empresa los requisitos de negocio para una aplicación, incluyendo los requisitos de protección relativos a la confidencialidad, integridad, disponibilidad y autenticidad de todos los activos de datos, así como la lógica de negocio prevista. Considere la exposición de su aplicación y si necesita segregación de usuarios (más allá de los necesarios para el control de acceso). Recopile los requisitos técnicos, incluyendo los de seguridad funcionales y no funcionales. Planifique y negocie el presupuesto que cubra todo el diseño, la construcción, las pruebas y la operación, incluyendo las actividades de seguridad.
Diseño seguro
El diseño seguro es una cultura y metodología que evalúa constantemente las amenazas y garantiza que el código esté diseñado y probado de forma robusta para prevenir métodos de ataque conocidos. El modelado de amenazas debe integrarse en las sesiones de refinamiento (o actividades similares); busque cambios en los flujos de datos y el control de acceso u otros controles de seguridad. Durante el desarrollo de la historia de usuario, determine el flujo correcto y los estados de fallo, y asegúrese de que las partes responsables e impactadas los comprendan y acuerden. Analice las suposiciones y condiciones para los flujos esperados y de fallo para garantizar que sigan siendo precisos y deseables. Determine cómo validar las suposiciones e implementar las condiciones necesarias para un comportamiento adecuado. Asegúrese de que los resultados se documenten en la historia de usuario. Aprenda de los errores y ofrezca incentivos positivos para promover mejoras. El diseño seguro no es un complemento ni una herramienta que se pueda añadir al software.

Ciclo de vida del desarrollo seguro
Un software seguro requiere un ciclo de vida de desarrollo seguro, un patrón de diseño seguro, una metodología de trabajo asfaltada, una biblioteca de componentes seguros, herramientas adecuadas, modelado de amenazas y análisis post-mortem de incidentes que se utilizan para mejorar el proceso. Contacte con sus especialistas en seguridad al inicio de un proyecto de software, durante todo el proyecto y para el mantenimiento continuo del software. Considere aprovechar el Modelo de Madurez de Garantía de Software (SAMM) de OWASP para estructurar sus iniciativas de desarrollo de software seguro.
Cómo prevenir.
- Establecer y utilizar un ciclo de vida de desarrollo seguro con profesionales de AppSec para ayudar a evaluar y diseñar controles relacionados con la seguridad y la privacidad.
- Establecer y utilizar una biblioteca de patrones de diseño seguros o componentes de carreteras pavimentadas
- Utilice el modelado de amenazas para partes críticas de la aplicación, como autenticación, control de acceso, lógica empresarial y flujos de claves.
- Integrar lenguaje y controles de seguridad en las historias de usuario
- Integre comprobaciones de plausibilidad en cada nivel de su aplicación (desde el frontend hasta el backend)
- Redacte pruebas unitarias y de integración para validar que todos los flujos críticos sean resistentes al modelo de amenazas. Recopile casos de uso y casos de uso indebido para cada nivel de su aplicación.
- Segregar capas de niveles en las capas del sistema y de la red, según las necesidades de exposición y protección
- Segregar a los inquilinos de forma sólida mediante diseño en todos los niveles
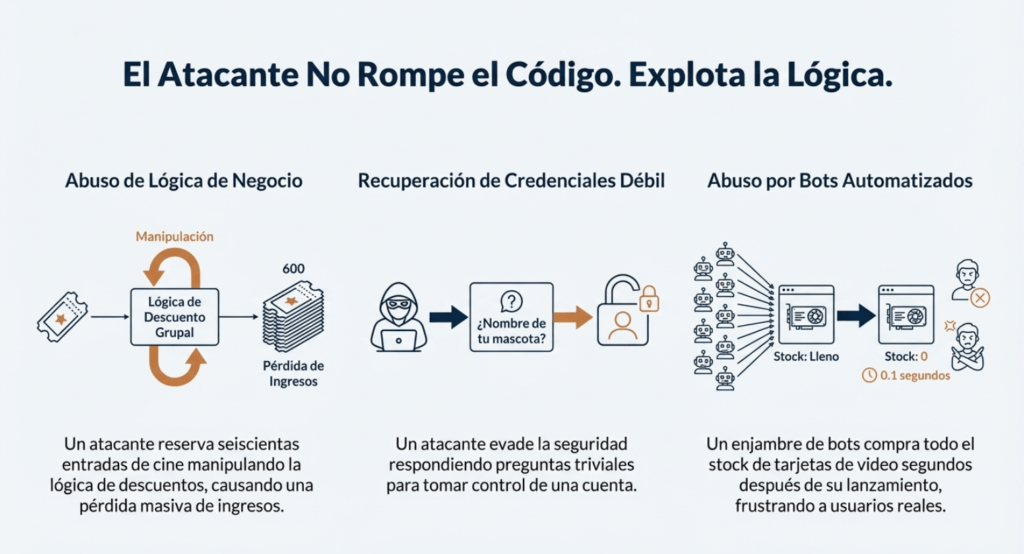
Ejemplos de escenarios de ataque.
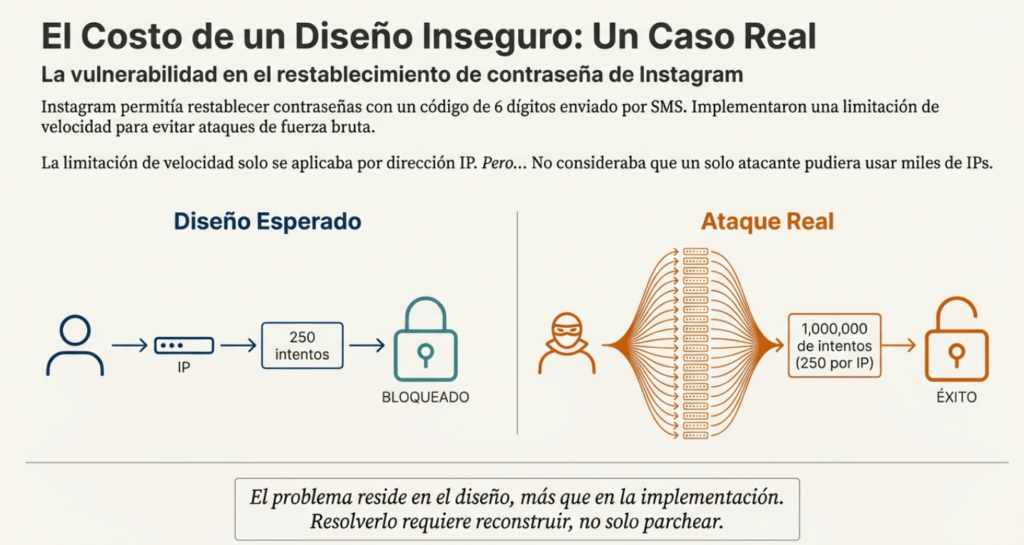
Escenario n.° 1: Un flujo de trabajo de recuperación de credenciales podría incluir preguntas y respuestas, lo cual está prohibido por NIST 800-63b, OWASP ASVS y OWASP Top 10. No se puede confiar en las preguntas y respuestas como
prueba de identidad, ya que más de una persona puede conocerlas. Esta funcionalidad debería eliminarse y reemplazarse con un diseño más seguro.
Escenario n.° 2: Una cadena de cines ofrece descuentos por reserva de grupo y tiene un máximo de quince asistentes antes de exigir un depósito. Los atacantes podrían modelar este flujo y comprobar si encuentran un vector de ataque en la lógica de negocio de la aplicación; por ejemplo, reservar seiscientas entradas y todos los cines a la vez en unas pocas solicitudes, lo que causaría una pérdida masiva de ingresos.
Escenario n.° 3: El sitio web de comercio electrónico de una cadena minorista no cuenta con protección contra bots administrados por revendedores que compran tarjetas de video de alta gama para revenderlas en sitios web de subastas. Esto genera una mala publicidad para los fabricantes de tarjetas de video y los propietarios de las cadenas minoristas, además de generar una mala relación con los aficionados que no pueden obtener estas tarjetas a ningún precio. Un diseño antibots cuidadoso y reglas de lógica de dominio, como las compras realizadas a los pocos segundos de estar disponibles, podrían identificar compras no auténticas y rechazar dichas transacciones.
ANTERIORMENTE A04:2021 – Insecure Design
Factores
| CWE mapeados | Tasa máxima de incidencia | Tasa de incidencia promedio | Exploit ponderado promedio | Impacto ponderado promedio | Cobertura máxima | Cobertura promedio | Total de ocurrencias | Total de CVEs |
| 40 | 24,19% | 3.00% | 6.46 | 6.78 | 77,25% | 42,51% | 262.407 | 2.691 |
Descripción general
Una nueva categoría para 2021 se centra en los riesgos relacionados con fallas de diseño y arquitectura, con un llamado a un mayor uso del modelado de amenazas, patrones de diseño seguro y arquitecturas de referencia. Como comunidad, necesitamos ir más allá del «desplazamiento a la izquierda» en el espacio de codificación para precodificar actividades críticas para los principios de Seguridad por Diseño. Entre las Enumeraciones de Debilidades Comunes (CWE) más destacadas se incluyen CWE-209: Generación de Mensaje de Error con Información Sensible , CWE-256: Almacenamiento de Credenciales sin Protección , CWE-501: Violación del Límite de Confianza y CWE-522: Credenciales con Protección Insuficiente .
Descripción
El diseño inseguro es una categoría amplia que representa diferentes debilidades, expresadas como un diseño de control ineficaz o ausente. No es la causa de las demás 10 categorías de riesgo principales. Existe una diferencia entre el diseño inseguro y la implementación insegura. Distinguimos entre fallas de diseño y defectos de implementación por una razón: tienen diferentes causas y soluciones. Un diseño seguro puede presentar defectos de implementación que generen vulnerabilidades susceptibles de ser explotadas. Un diseño inseguro no se puede solucionar con una implementación perfecta, ya que, por definición, nunca se crearon los controles de seguridad necesarios para defenderse de ataques específicos. Uno de los factores que contribuye al diseño inseguro es la falta de un perfil de riesgos empresariales inherente al software o sistema en desarrollo y, por lo tanto, la imposibilidad de determinar el nivel de seguridad requerido.
Abordar la seguridad desde el principio
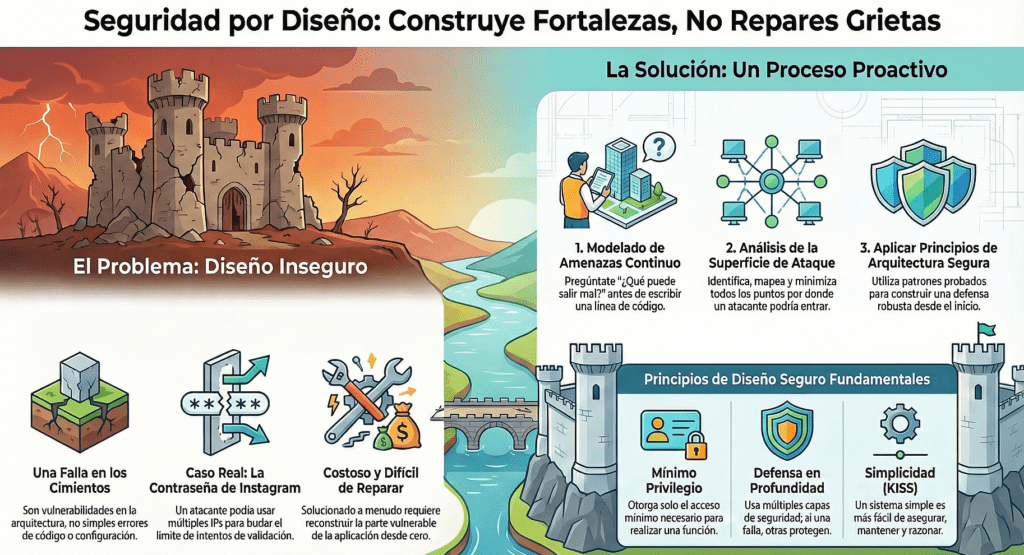
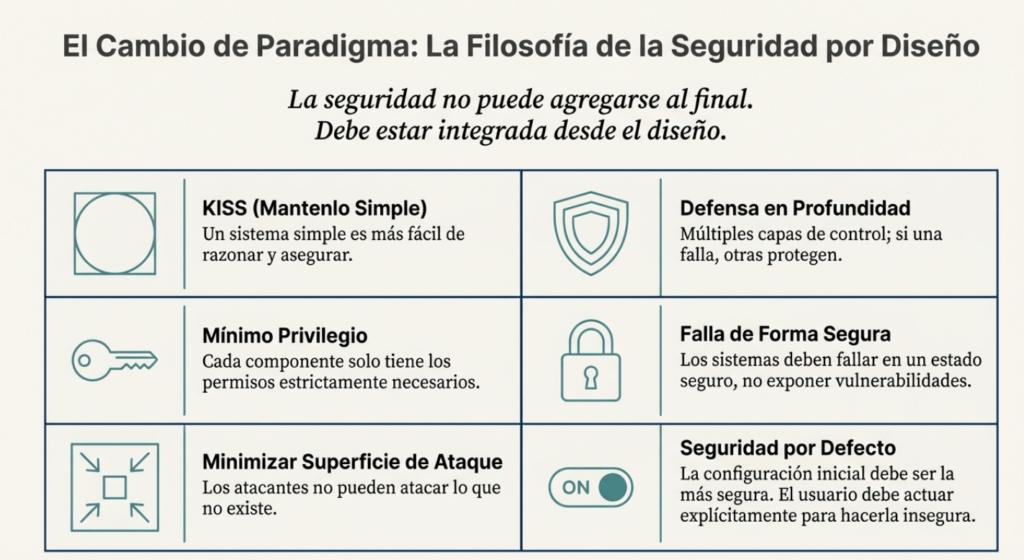
Diseñar aplicaciones seguras no es una etapa que se delega hacia el final del proyecto, ni tampoco es algo que se pueda resolver parcheando vulnerabilidades una vez que el sistema está en producción. Te puedo asegurar que si no pensás en la seguridad desde el primer boceto, lo más probable es que termines construyendo un castillo de arena con una sonrisa, esperando a que la próxima ola lo derribe. La seguridad se integra, no se agrega. Si no lo hacés así, cada nueva funcionalidad que implementes será una nueva puerta abierta, con más posibilidades de que alguien del otro lado la fuerce.
La arquitectura segura comienza por tomar decisiones conscientes. Mantené tu diseño simple. No por una cuestión estética, sino porque la simplicidad es uno de los aliados más potentes de la seguridad. Cuando todo es complejo, la visibilidad se pierde, el control se debilita y los errores se multiplican. El principio KISS —“Keep It Simple, Stupid”— no es solo un consejo de diseño, es una advertencia. Cada línea de código innecesaria, cada interacción sin sentido, es un lugar donde puede esconderse una vulnerabilidad.
También tenés que entender algo clave: los usuarios (y muchas veces, también los desarrolladores) no van a leer la documentación. La configuración por defecto tiene que ser segura. Punto. Si alguien quiere hacer algo inseguro, que lo haga sabiendo exactamente lo que está rompiendo. Y que quede rastro. Pero nunca dejes puertas abiertas por omisión.
La oscuridad no es defensa. El código ofuscado no detiene a nadie con un descompilador y tiempo libre. La “seguridad por oscuridad” es una falsa ilusión. Si un sistema es seguro solo porque nadie sabe cómo funciona, entonces no es seguro. El adversario puede y va a mirar dentro. Siempre asumí que el atacante tiene acceso total al código y a los binarios. Construí tu defensa con eso en mente.
Otro concepto que no se puede pasar por alto es la “superficie de ataque”. Cuanto más grande es, más puertas le estás dejando al atacante. Si tenés componentes innecesarios expuestos, si dejás paneles administrativos abiertos a la red pública, si exponés microservicios que nadie usa directamente, estás multiplicando tus puntos débiles. El atacante no puede explotar lo que no existe. Esto debería ser tu mantra.
Y por supuesto, nunca te olvides del principio de defensa en profundidad. No confíes en un único punto de control. Pensá siempre en qué pasa si ese control falla. ¿Qué puede pasar si alguien lo evade? ¿Qué se compromete? ¿Qué puede escalarse desde ahí? Diseñá como si asumieras que cada capa eventualmente va a fallar. Porque un día lo va a hacer.
El rol de los componentes de terceros
Mirá, no tenés que reinventar todo. No seas el tipo que implementa su propio algoritmo de hashing porque no confía en SHA-256. Hay miles de bibliotecas, frameworks y herramientas creadas, probadas, auditadas y mejoradas por especialistas en seguridad de todo el mundo. Usalas. Pero usalas bien.
Una biblioteca bien mantenida, con valores por defecto seguros, puede ahorrarte años de sufrimiento. No solo por el tiempo de implementación, sino por los errores que no vas a cometer. Esos errores ya los cometieron otros antes que vos, los descubrieron y los corrigieron. Vos solo tenés que pararte sobre esos hombros.
Pero no basta con usarlos. Hay que mantenerlos actualizados. Si estás usando una versión vulnerable de un framework, no importa lo bueno que sea: estás frito. Y no luches contra el framework. Si tenés que romperlo para que haga lo que necesitás, estás eligiendo mal. Elegí herramientas que se adapten a tu flujo de desarrollo y arquitectura, no que te obliguen a pelear contra ellas.
Las amenazas reales: casos y errores comunes
Uno de los errores más comunes que veo en sistemas reales es la implementación de seguridad basada en complejidad. El código es tan enmarañado que nadie sabe qué hace qué. Y entonces, un nuevo dev llega, necesita agregar una funcionalidad, mete mano donde no debe y… boom, IDOR. Control de acceso roto. El atacante explota la confusión.
Lo mismo pasa con componentes expuestos innecesariamente. ¿Tenés phpMyAdmin expuesto en un subdominio porque “nadie lo usa”? Bueno, el día que alguien escanee tu dominio y encuentre un CVE en esa versión, va a entrar, va a sacar tu base de datos completa y ni siquiera va a dejar rastro. Nadie lo usaba, nadie lo monitoreaba. La seguridad por abandono es suicidio.
Diseñá para la transparencia
No te compliques. No escondas cosas. Diseñá con la claridad en mente. Cuanto más sencillo sea tu sistema, más fácil va a ser entenderlo, mantenerlo y asegurar que está haciendo lo que tiene que hacer, y nada más. Y hacelo de forma que sea fácil hacer lo correcto. La opción por defecto tiene que ser segura. La configuración inicial tiene que ser segura. Las herramientas que das a otros desarrolladores tienen que empujarlos a trabajar de forma segura, aunque no tengan ni idea de seguridad.
Todo esto implica articular claramente los límites de confianza. ¿Qué componente confía en cuál? ¿Quién puede hacer qué? ¿Desde dónde? Si tenés esto bien definido, podés implementar controles como firewalls, validaciones, gateways. Y sobre todo, podés entender el impacto real si algo se rompe.
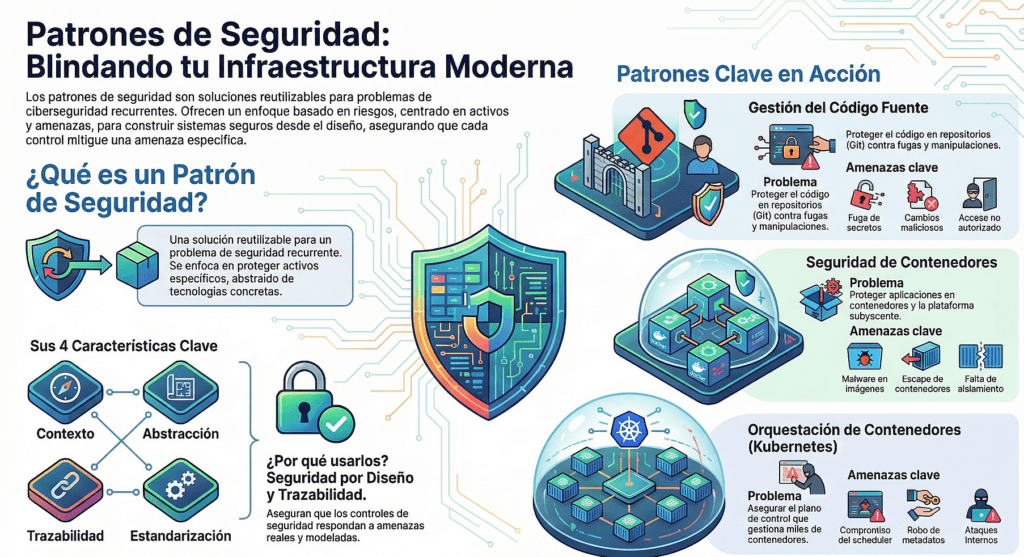
Patrones de arquitectura segura
No estás solo. Hay décadas de trabajo de expertos condensados en patrones de arquitectura segura. Usalos. No reinventes la solución si ya existe una bien probada. Elegí patrones que resuelvan problemas reales de seguridad, que no estén atados a una tecnología específica, y que sean reutilizables. Esto es diseño defensivo de verdad.
Los patrones ayudan a prevenir fallos lógicos, el tipo de bugs que no salta con un escáner de vulnerabilidades. Este enfoque ataca directamente al OWASP Top 10, especialmente al “Diseño inseguro”, que es uno de los problemas más jodidos de detectar y mitigar a posteriori.
Análisis de superficie de ataque
Hablemos claro. Si no sabés cuál es la superficie de ataque de tu sistema, estás volando a ciegas. La superficie de ataque es el conjunto de todas las formas en que un atacante puede interactuar con tu aplicación. Entradas, salidas, APIs, archivos, interfaces de usuario, cabeceras HTTP, puertos abiertos, todo.
Tenés que mapear eso. Entenderlo. Agruparlo. Saber cuáles son los puntos críticos, cuáles son los más expuestos, cuáles tienen más probabilidad de ser atacados. Y lo más importante: monitorear cómo cambia con el tiempo. Cada nuevo endpoint, cada nueva API, cada nuevo parámetro que exponés, es una expansión. Y esa expansión puede convertirte en un blanco más fácil.
Las herramientas existen: ZAP, ThreatMapper, Skipfish, w3af. Usalas para ver tu sistema desde la perspectiva de un atacante. Entendé qué datos son sensibles, qué endpoints son críticos, qué partes están bajo protección… y cuáles no.
Microservicios y la nube: el nuevo campo de batalla
Si trabajás con arquitectura de microservicios o aplicaciones nativas de la nube, tenés un problema adicional: los componentes están expuestos, desacoplados y a veces escalan solos. Un nuevo pod puede quedar expuesto por error. Una API mal configurada puede abrir acceso a todo el backend.
No importa cuán modular sea tu sistema: cada módulo visible desde el exterior es un objetivo. Y como están separados, los controles deben ser coherentes entre todos ellos. No sirve que uno tenga autenticación fuerte si el otro responde sin autenticación alguna. La consistencia es seguridad.
Gestión y evolución de la superficie de ataque
Este no es un trabajo que se hace una vez y ya está. Cada cambio en tu sistema puede introducir nuevas vulnerabilidades. Cambiar cómo gestionás sesiones, modificar autenticación, agregar un nuevo rol o endpoint, cambiar el modelo de acceso: todo eso modifica la superficie de ataque. Y tenés que volver a evaluar.
El modelo de acceso también tiene que estar claro: ¿es positivo o negativo? ¿Bloqueás por defecto y habilitás lo necesario, o hacés lo contrario? Porque si trabajás con un modelo negativo, tenés que ser extremadamente cuidadoso. Un descuido y le diste acceso de admin a quien no corresponde.
La seguridad no es un producto. Es un proceso continuo. Es una forma de pensar. Y si querés construir software que resista los embates del mundo real, tenés que incorporar esa mentalidad desde el primer diagrama, desde la primera línea de código.
Porque al final del día, el atacante va a llegar. La pregunta no es si, sino cuándo. Y cuando lo haga, la diferencia entre que encuentre una puerta abierta o se rompa los dientes contra tu defensa va a depender de cómo diseñaste tu sistema desde el principio.
Seguridad en arquitecturas de microservicios: referencia para documentar y defender sistemas distribuidos
El crecimiento imparable de los sistemas distribuidos, impulsado por la adopción masiva de arquitecturas de microservicios, nos obliga como profesionales a replantear completamente cómo pensamos la seguridad en nuestras aplicaciones. A diferencia del modelo monolítico, donde los puntos de control y los límites de confianza estaban centralizados, los microservicios fragmentan la lógica, dispersan los datos y multiplican la superficie de ataque. Este cambio de paradigma no es solo técnico: es una redefinición completa del terreno de juego para el diseño seguro.
La realidad es clara. Si no documentás y entendés a fondo la arquitectura distribuida de tu sistema, no podés protegerlo. Y no estoy hablando de hacer un diagrama bonito en draw.io. Hablo de mapear cada componente funcional, cada almacén de datos, cada cola de mensajes, cada servicio de infraestructura, y sobre todo, las relaciones que hay entre ellos. Es ahí donde vive el riesgo. Es ahí donde entran los atacantes.
Esta hoja de referencia que tenemos frente a nosotros no es simplemente un checklist para auditores. Es una herramienta táctica para ingenieros de seguridad, arquitectos y desarrolladores que quieren construir aplicaciones blindadas desde sus cimientos. Porque, en el mundo real, los microservicios no se caen porque alguien escribió mal un endpoint. Se caen porque nadie entendía cómo los servicios estaban conectados, qué datos se estaban exponiendo ni quién tenía permiso para hacer qué.
Documentar lo funcional, no solo lo técnico
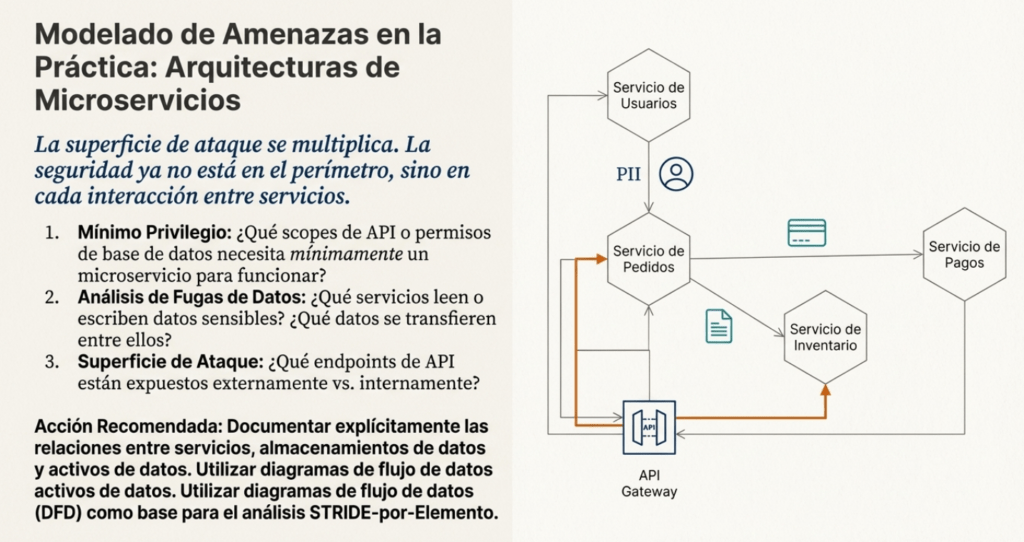
El primer paso que plantea este enfoque es identificar los servicios funcionales de la aplicación: cada microservicio que implementa lógica de negocio. Esto no es opcional. Tenés que saber qué hace cada servicio, quién lo mantiene, dónde está su código, cómo se accede a su API y qué necesita para operar. Porque un servicio sin definición clara es un vector de ataque esperando a ser explotado.
Pero esto no se queda solo en lo funcional. También tenés que mapear los servicios de infraestructura, que muchas veces son invisibles para los desarrolladores, pero críticos para la seguridad: autenticación, descubrimiento de servicios, monitoreo, logging. Cada uno debe tener su propia documentación, API, y libro de operaciones. Si perdés de vista un solo servicio de este tipo, podés estar dejando el corazón del sistema sin protección.
El punto ciego más común: los datos y su almacenamiento
¿Dónde viven los datos sensibles? ¿Quién los accede? ¿Cómo se almacenan? Estas preguntas no se responden con «están en la base de datos». Cada almacén (PostgreSQL, Redis, Cassandra) tiene características de seguridad específicas, y es fundamental entender qué activos están guardados ahí. Tenés que identificar cada activo, etiquetarlo con su nivel de sensibilidad (PII, confidencial, etc.), y mapear qué servicios tienen acceso, y con qué nivel de permisos. Esto es aplicar control de acceso mínimo en serio.
¿Y las colas de mensajes? ¿Quién publica? ¿Quién se suscribe? ¿Qué datos se transmiten por ahí? Cada mensaje que vuela en RabbitMQ o Kafka es una pieza de información que puede ser interceptada, manipulada o explotada. La comunicación asíncrona no es invisible para el atacante. Si no sabés qué datos viajan y cómo se protegen, no estás haciendo seguridad, estás apostando.
Relaciones: el mapa que revela los puntos débiles
Uno de los aportes más importantes de esta hoja de referencia es la idea de documentar las relaciones entre componentes. Esto no es simplemente listar servicios. Es trazar las conexiones explícitas: qué servicio accede a qué almacenamiento, quién llama a quién (sincrónicamente o por eventos), y qué datos circulan por ahí. Este mapa de relaciones es el blueprint del atacante. Si vos no lo tenés, él sí lo va a hacer. Y con él va a identificar los eslabones débiles.
Las relaciones «servicio-almacenamiento», «servicio-servicio» (REST, gRPC, SOAP), y «activo-almacenamiento» te permiten entender cómo fluyen los datos y dónde se puede cortar la cadena. Identificar mal estas relaciones es lo que lleva a errores como accesos no autorizados, fugas de datos, o privilegios excesivos.
Del mapeo al análisis: cómo extraer inteligencia de la documentación
Una vez que mapeaste todos estos componentes y sus relaciones, llega el momento de usar esa información de forma práctica. Este no es un ejercicio académico. Es un paso previo al modelado de amenazas, al diseño de pruebas de seguridad, a la implementación de controles. Con esto, podés responder a preguntas que no podías antes:
- ¿Qué servicios necesitan acceso real a qué datos?
- ¿Dónde estamos filtrando información sensible sin saberlo?
- ¿Qué endpoints tenemos que testear sí o sí durante una pentest?
- ¿Qué cambios recientes en el sistema alteraron los límites de confianza?
Y podés hacerlo de forma estructurada. Analizar la superficie de ataque usando la definición de APIs. Evaluar fugas de datos con los flujos «servicio a servicio». Justificar límites de confianza entendiendo cómo y dónde se almacenan y transmiten los datos sensibles.
Aplicación directa a estándares como OWASP ASVS
Todo este trabajo no es algo aislado ni teórico. Está alineado directamente con estándares como OWASP ASVS. La hoja de referencia te guía para cumplir con requisitos específicos del nivel 1 (arquitectura, modelado de amenazas, privilegios mínimos, identificación de datos sensibles, etc.). No necesitás reinventar los procesos, ya están definidos. Solo tenés que mapear tu sistema con inteligencia y conectar los puntos.
Por ejemplo:
- Para cumplir con el requisito 1.1.2 del ASVS (análisis de arquitectura), necesitás documentar los endpoints expuestos y sus relaciones.
- Para abordar 1.4.3 (mínimo privilegio), necesitás saber qué microservicio accede a qué datos, con qué nivel de permiso.
- Para cubrir 1.8.1 (identificación de datos sensibles), necesitás mapear tus activos y etiquetarlos correctamente.
Todo se encadena. Todo suma.
Más allá del mapeo: mantener la seguridad en el tiempo
Este enfoque no es solo útil para una auditoría puntual. Es una estrategia viva. La arquitectura de una app basada en microservicios cambia todo el tiempo: nuevos servicios, nuevas APIs, nuevas relaciones. Si no actualizás esta documentación con cada sprint, con cada merge, tu visión de seguridad queda obsoleta.
La seguridad no puede depender de la memoria tribal del equipo ni de los comentarios en los PR. Necesitás una fuente de verdad, clara, actualizada, versionada. Y esta hoja de referencia te da exactamente la estructura para construirla.
Dominá tu arquitectura antes de que lo hagan otros
Las arquitecturas de microservicios tienen ventajas evidentes en escalabilidad y despliegue. Pero en términos de seguridad, son una pesadilla si no se entienden y documentan en profundidad. No podés proteger lo que no ves. No podés defender lo que no entendés.
Esta hoja de referencia no es un adorno. Es una herramienta de combate. Es la forma en que tomás control de tu sistema, revelás los puntos débiles antes que lo haga un atacante, y construís defensas donde realmente importan.
Si querés hacer seguridad en serio en entornos modernos, este es el camino. Cualquier otra cosa es jugar con fuego. Y en este juego, el que no documenta… termina comprometido.
Diseño seguro de productos: cómo garantizar seguridad real desde el código hasta el despliegue
Si hay algo que aprendí es que los sistemas verdaderamente seguros no nacen de la casualidad ni de parches improvisados. Nacen del diseño. De una arquitectura pensada desde cero con principios de seguridad como cimiento, no como decoración tardía. Este documento que tenemos frente a nosotros no es una hoja de trucos: es un mapa de ruta. Uno que todo equipo de desarrollo serio debería seguir si quiere construir software que resista el tiempo, el abuso, y los ataques.
Hoy más que nunca, en un ecosistema donde cada producto es un enjambre de microservicios, APIs, infra como código, dependencias externas y despliegue continuo, la seguridad no puede depender de una revisión manual o de una auditoría de último momento. Tiene que estar integrada, automatizada y respaldada por principios sólidos.
Todo empieza en el inicio del producto
El primer error que cometen muchos equipos es pensar que la seguridad empieza cuando el producto ya está corriendo. Error fatal. La seguridad empieza en la concepción misma. ¿Qué va a hacer el producto? ¿A quién va a servir? ¿Qué datos va a manejar? ¿Qué riesgos trae todo eso? En ese punto ya tenés que empezar a tomar decisiones. Y esas decisiones tienen que estar sustentadas en modelado de amenazas, impacto de negocio, contexto de uso, y un análisis profundo del perfil de riesgo.
El inicio del producto define las bases. Si lo hacés mal, todo lo que venga después va a ser construir sobre una mina antipersonal. Y no hay framework que te salve cuando el diseño mismo está podrido.
Diseño de producto: el código es la consecuencia, no el comienzo
El diseño seguro de productos es un proceso continuo. Nunca se detiene. No se trata solo de elegir una buena librería para encriptar contraseñas o meter un escáner de vulnerabilidades en el pipeline. Se trata de tomar decisiones conscientes, iterativas, donde cada nueva función, cada refactor, cada despliegue, se hace bajo los mismos principios: minimizar superficie de ataque, aplicar privilegios mínimos, y fallar de forma segura.
Acá se ve la diferencia entre equipos que simplemente escriben código, y equipos que diseñan sistemas. Los primeros meten features hasta que explota. Los segundos piensan en amenazas, validan sus suposiciones y documentan sus límites de confianza.
Principios de seguridad: más que frases, son pilares
El principio de mínimo privilegio no es una recomendación: es una obligación. Si un componente o un usuario tiene acceso a más de lo que necesita, estás dándole al atacante una escalera al cielo. ¿Necesita escribir en la base? Perfecto, pero que no pueda leer otra tabla. ¿Necesita hacer login? Genial, pero que no pueda listar todos los usuarios. Cada permiso extra es un ataque posible.
La separación de funciones es el antídoto contra la corrupción interna y los errores fatales. El mismo sistema que valida no debe ser el que aplica. El que escribe no debería leer sin pasar por controles. Si todas las piezas del proceso están en manos de una sola parte, ya sea una persona o un módulo, estás invitando al desastre.
La defensa en profundidad es lo que te salva cuando todo lo demás falla. Y va a fallar, te lo aseguro. Lo que importa es que tengas más capas. Si el firewall cae, que el token expulse. Si el token se filtra, que el rate limit lo pare. Si el rate limit se rompe, que los logs lo registren. Cada capa es un freno. Cada una tiene que estar.
Y sobre todo: Zero Trust. Nunca confíes. Ni en tu red, ni en tus procesos, ni en tus usuarios, ni en tus propios servicios. La confianza se gana, y cada solicitud se valida. El atacante puede estar dentro, disfrazado de cliente. ¿Tenés pruebas de que no es así?
Áreas de enfoque: mirá el sistema completo
Uno de los errores más graves que veo en el diseño de productos es enfocarse solo en el código y olvidar el ecosistema. Pero el contexto es clave. ¿Dónde corre esta app? ¿Qué departamentos la usan? ¿Qué datos maneja? ¿Qué pasa si esos datos se filtran? ¿A quién afecta? Este análisis inicial puede parecer burocrático, pero te permite priorizar: a veces no necesitás criptografía de nivel militar, y otras veces lo que estás construyendo es una bomba si alguien mete mano.
Después están los componentes. ¿Qué librerías usás? ¿Qué servicios externos? ¿Quién los mantiene? ¿Qué licencia tienen? ¿Están actualizados? ¿Tienen historial de CVEs? ¿Se auditaron alguna vez? Tu aplicación es tan segura como su eslabón más débil. Y eso, muchas veces, es una dependencia.
Las conexiones son otra mina oculta. ¿Qué puertos están abiertos? ¿Qué bases se exponen? ¿Qué API externas estás tocando? ¿Estás enviando datos sensibles a terceros? Cada conexión debe estar documentada, securizada, y validada. Y si algo cambia, se revisa todo de nuevo.
El código habla. ¿Qué dice el tuyo?
Lo que realmente me importa es que el código sea seguro, desde la primera línea. ¿Validás entradas? ¿Manejás errores sin filtrar mensajes peligrosos? ¿Usás HTTPS siempre? ¿Cifrás los datos en tránsito y en reposo? ¿Tenés autenticación robusta? ¿Evitas secretos hardcodeados? ¿Auditás? ¿Testeás? ¿Actualizás tus librerías? ¿Tenés pruebas de seguridad automáticas? Si no podés responder “sí” a estas preguntas, tu sistema está en riesgo.
Y no alcanza con un solo “sí”. Tenés que hacerlo todo. Siempre. Porque una vulnerabilidad te rompe la fiesta. Y no hay excusa aceptable cuando un atacante te extrae la base por un error que podías haber evitado con un linternazo a tiempo.
Configuración: donde mueren muchas aplicaciones
Podés tener el mejor código del mundo, pero si tu app está mal configurada, estás muerto. Accesos mal definidos, puertos abiertos que no deberían estar, logs accesibles, secretos sin protección, configuraciones por defecto… he visto mil catástrofes por eso. Las configuraciones tienen que seguir el mismo patrón: mínimo privilegio, defensa en profundidad, seguridad por defecto, cifrado, actualizaciones y monitoreo. Sin eso, estás entregando tu sistema.
Infraestructura como código: la nueva frontera
Hoy en día, tu infraestructura también es código. Y eso significa que puede ser revisada, testeada, versionada, asegurada. El IaC no solo acelera despliegues, también permite integridad, reproducibilidad, y trazabilidad. Pero también puede ser un agujero de seguridad si no lo tratás con el mismo respeto que el resto del sistema.
Acá es donde entran las buenas prácticas: plugins de IDE para seguridad, modelado de amenazas, gestión de secretos bien hecha (nunca en git), análisis estático y dinámico, control de versiones, firma de artefactos, CI/CD con escáneres automáticos, y auditoría completa de todo lo que desplegás. El ecosistema es enorme. Jenkins, GitHub Actions, DefectDojo, Trivy, Falco, ELK, Prometheus, Grafana… herramientas sobran. Lo que falta es disciplina.
Y algo clave: inmutabilidad. Infraestructura que cambia en tiempo real es tierra fértil para errores y para persistencia de atacantes. Si algo necesita cambiar, lo destruís y lo creás de nuevo. Nada de meter mano por SSH a un container en producción. Eso es del siglo pasado.
El diseño seguro no es opcional
Hoy más que nunca, el diseño seguro no es una opción. Es la única forma viable de construir software que no termine siendo una pesadilla legal, económica y técnica. Cada decisión que tomás durante el diseño, la implementación y el despliegue tiene un impacto directo en la seguridad del producto. Si no estás integrando estos principios desde el día uno, estás dejando un futuro breach listo para explotar.
Diseñar de forma segura no te va a salvar de todos los ataques. Pero sí te va a permitir detectarlos antes, contenerlos mejor, y resistir lo suficiente como para recuperarte. En seguridad, la perfección no existe. Pero la preparación sí. Y eso empieza acá: con un diseño bien hecho.
Evaluación rápida de riesgos: cómo hackear tu propia arquitectura antes que lo hagan otros
Te voy a ser directo: si estás desarrollando un sistema, un servicio o una infraestructura y no estás haciendo un análisis de riesgos, estás jugando a la ruleta rusa con la seguridad. La Evaluación Rápida de Riesgos (ARR o RRA – Rapid Risk Assessment) es una de las herramientas más útiles y subestimadas que podés tener en tu arsenal. No reemplaza a una auditoría profunda, ni a un modelo de amenazas formal, ni a un pentest full scope… pero te da algo más valioso en etapas tempranas: perspectiva rápida, contexto, y decisiones concretas.
Te digo esto desde la experiencia: más vale una buena RRA de 30 minutos que mil excusas después de un incidente.
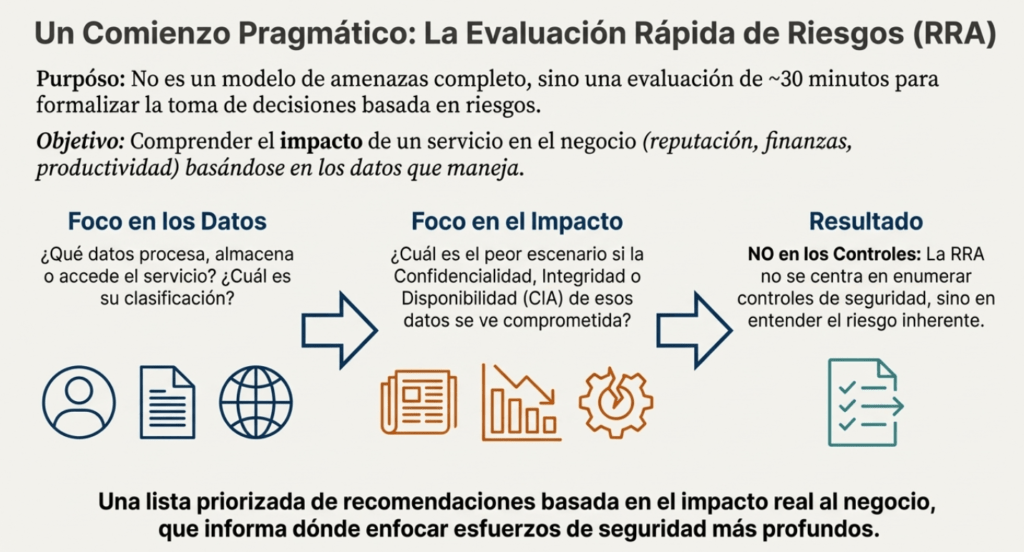
¿Qué es una RRA y por qué deberías usarla YA?
Una RRA no es una revisión de seguridad exhaustiva. Es una conversación con propósito. Un radar que se prende apenas el sistema empieza a tomar forma. Su objetivo no es encontrar cada vulnerabilidad ni auditar cada línea de código, sino entender lo esencial: ¿Qué estamos construyendo? ¿Qué riesgos asumimos? ¿Qué impacto tendría una falla? ¿Qué tan jodido puede ser si nos equivocamos?
No necesitás horas de análisis, ni herramientas sofisticadas. Necesitás 30-60 minutos, un equipo que entienda lo que está haciendo, y voluntad para hablar con crudeza. ¿Qué datos manejamos? ¿Qué pasa si se filtran? ¿Quién los puede tocar? ¿Qué pasa si este servicio se cae por 3 días?
Esto es lo que debería pasar ANTES de escribir una línea de código.
Qué hace única a una Evaluación Rápida de Riesgos
La clave de la RRA está en su simplicidad y enfoque. Es rápida. Es concisa. Se puede repetir cada vez que hay un cambio importante. Y está orientada a decisiones reales.
Esto es lo que hace:
- Te ayuda a entender qué datos maneja tu servicio.
- Te obliga a pensar en el impacto de un incidente (no la probabilidad, sino el daño real).
- Te da un marco para discutir lo que es prioritario asegurar ahora, no después.
- Te deja con recomendaciones accionables.
- Te permite educar a los responsables técnicos y funcionales sin tener que convertirlos en expertos en seguridad.
Y lo mejor: funciona. Porque, aunque parezca increíble, en muchos proyectos nadie se sienta a pensar seriamente en lo que puede salir mal hasta que es demasiado tarde. La RRA evita eso.
Cómo se ejecuta una RRA como un pro
Primero que nada, no hace falta tener una reunión multitudinaria. De hecho, lo ideal son dos o tres personas clave: alguien que conozca bien el servicio, un responsable técnico y, si se puede, un analista de seguridad que sepa dirigir la conversación.
Antes de la reunión:
- Confirmá que no exista ya una RRA previa.
- Tené listo un diagrama de flujo de datos.
- Traé información sobre los datos procesados: usuarios, credenciales, tokens, configuración, logs, lo que sea.
- Identificá al dueño del servicio. Esa persona es la que tiene que decir «esto es lo más importante».
Durante la reunión:
- Notas del servicio: ¿Qué hace el sistema? ¿Cómo se conecta con otros? ¿Qué tan crítico es? ¿Dónde vive?
- Diccionario de datos: ¿Qué datos se procesan? ¿Cuáles son sensibles? ¿Están cifrados? ¿Son públicos? ¿Confidenciales?
- Escenarios de amenaza: ¿Qué pasa si se filtran? ¿Y si se alteran? ¿Y si el servicio cae una semana?
- Impacto: ¿Reputacional? ¿Productividad? ¿Plata? ¿Compliance?
- Recomendaciones: ¿Qué podemos hacer ya para evitar el desastre? ¿Hace falta un pentest? ¿Un plan de respuesta? ¿Mejorar logs? ¿Limitar accesos?
Cosas que NO tenés que hacer en una RRA
Esto es importante. No te distraigas revisando controles específicos. No estás auditando si el servicio usa TLS correctamente o si tiene tests. Eso viene después. Tampoco te pierdas evaluando la probabilidad exacta de un ataque. Estás definiendo el terreno, no cazando intrusos aún.
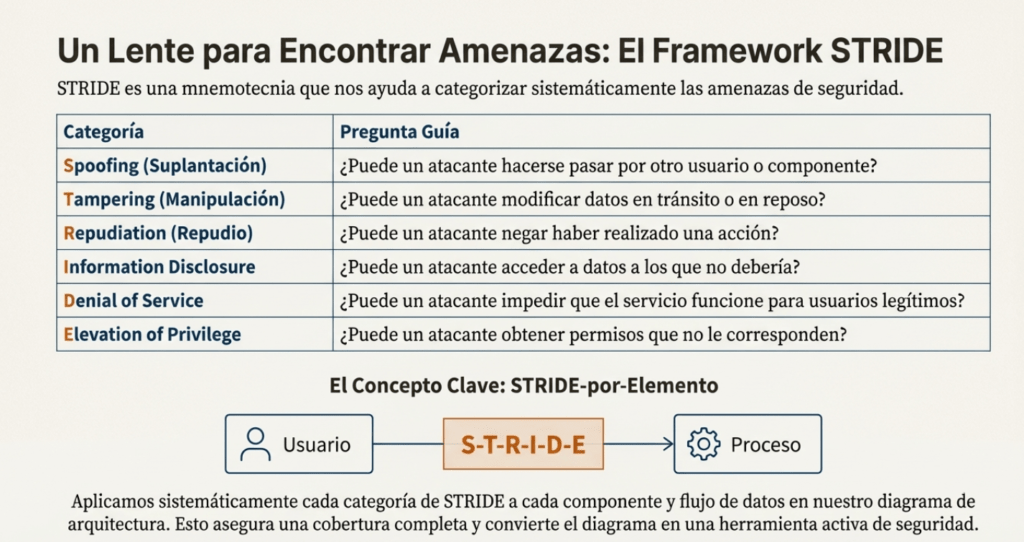
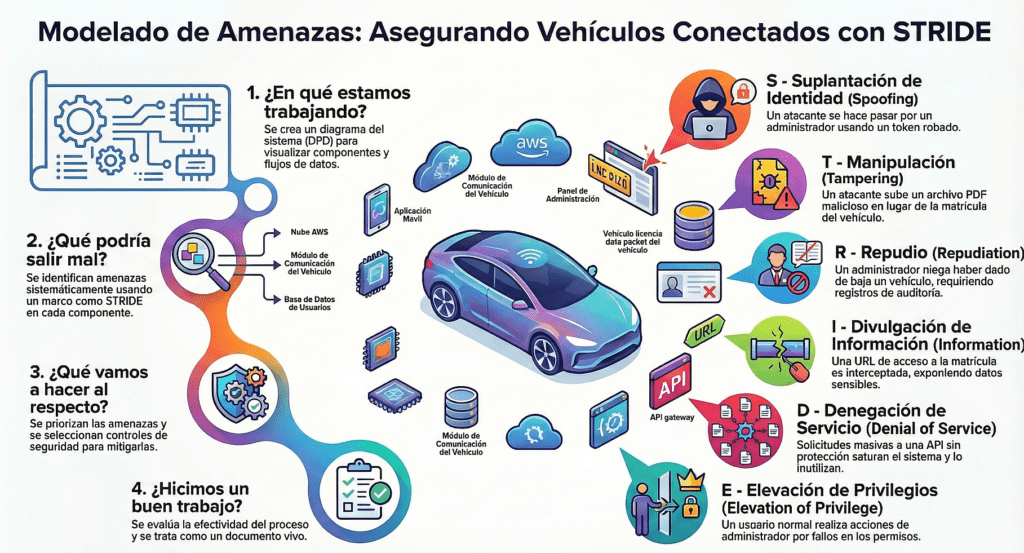
STRIDE por elemento: una forma simple de modelar amenazas
La metodología STRIDE (Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege) sigue vigente. Pero la versión por elemento la vuelve práctica. En vez de pensar en amenazas genéricas, mirás cada elemento del diagrama (componente, flujo de datos, almacenamiento) y le aplicás las categorías que le corresponden.
¿Tenés un flujo de datos? Pensá en Tampering, Disclosure y DoS.
¿Tenés un componente? Pensá en Spoofing, Elevation, Tampering.
No necesitás ser un experto para esto. Solo necesitás pensar en cómo puede romperse cada parte. Y una vez que lo ves, no podés dejar de verlo.
La metodología STRIDE/elemento termina creando una buena cantidad de amenazas, incluso para un componente con un diagrama relativamente pequeño como:
AWS y la seguridad como parte del diseño
Si tu arquitectura está en la nube —y hoy, casi todas lo están—, no podés ignorar los principios de AWS para diseño seguro:
- Plano de datos vs. plano de control: El plano de datos necesita alta disponibilidad. El de control puede tolerar más fallas. Separá responsabilidades.
- Automatización de seguridad: No escales seguridad manualmente. Integrala en CI/CD, con pruebas automáticas y políticas de acceso declarativas.
- Resiliencia por diseño: No basta con tener backups. Tenés que asumir fallas y recuperarte de ellas de forma automatizada.
- Evaluación constante: Seguridad no es una auditoría anual. Es parte del desarrollo. En cada commit. En cada despliegue. En cada nueva funcionalidad.
Cuando una RRA muestra impacto ALTO o MÁXIMO…
No lo ignores. Si detectás que un fallo podría afectar la reputación, generar costos altos, dejar a toda la empresa sin sistema… entonces el siguiente paso es obligatorio: modelo de amenazas completo y prueba de penetración.
Ese es el camino. Primero la RRA, después el modelo, después las pruebas.
Recomendaciones finales
La RRA no es un documento más. Es una brújula. Te muestra en qué dirección tenés que moverte. Y si la usás con honestidad, vas a descubrir vulnerabilidades estructurales que no saltaban en los tests automáticos. Porque esto no se trata solo de bugs, se trata de diseño, de decisiones estratégicas, de entender lo que estás exponiendo al mundo.
Y si no lo hacés vos, no te preocupes: tarde o temprano, alguien más va a hacer esa evaluación por vos. Y no va a venir con buenas intenciones.
¿Querés construir software seguro?
Hacete una RRA antes de escribir código.
Y volvé a hacerla cada vez que tu sistema cambie.
Es rápido. Es poderoso. Y puede salvar tu proyecto.
Evaluación de amenazas: cómo escalar la seguridad desde el código hasta la estrategia
Si algo tengo claro después tantos años en este juego, es que la seguridad real no empieza con un firewall ni con un escáner de puertos. Empieza en el diseño. Y uno de los pilares más críticos —pero muchas veces ignorados— de ese diseño seguro es la Evaluación de Amenazas (o AT, por Threat Assessment). Es el arte (y la ciencia) de anticiparse al ataque antes de que ocurra. De pensar como un atacante mientras todavía estás escribiendo los planos del sistema.
La Evaluación de Amenazas no se trata simplemente de identificar bugs, sino de entender cómo puede quebrarse tu software según su funcionalidad, su entorno y su propósito real. Porque no es lo mismo proteger una API interna de backoffice que un login público con acceso a datos personales. La diferencia está en la superficie de ataque, pero también en el contexto.
Una organización madura en seguridad hace esto de forma estructurada, continua y alineada con el negocio. Porque de nada sirve decir “hay un riesgo” si no podés demostrar qué impacto tiene sobre ingresos, reputación o cumplimiento legal. Por eso, todo modelo de amenazas bien hecho tiene que estar atado a decisiones estratégicas, y no aislado en una carpeta de seguridad que nadie abre.
Desde el caos hasta la automatización: los tres niveles de madurez
Lo interesante de este enfoque es que define un camino. No importa si tu empresa hoy no tiene nada implementado: podés empezar. La madurez viene en capas. Vamos desde lo básico —el máximo esfuerzo manual— hasta una seguridad automatizada, escalable y en tiempo real.
Nivel 1: Recién salidos del cascarón
Acá estás con lo justo. Recién empezás a identificar amenazas de forma manual, con lo que podés. No hay herramientas, no hay procesos definidos, y cada proyecto arranca de cero. Las evaluaciones son esfuerzos puntuales, usando lluvia de ideas, algún diagrama suelto y una lista básica de amenazas genéricas. Lo hacés porque sabés que algo hay que hacer. Pero dependés mucho de la experiencia (o paranoia) del equipo.
En este estadio, el perfil de riesgo de la aplicación es apenas una idea. Se hace una estimación básica de impacto y probabilidad. No hay historial, no hay trazabilidad, no hay métricas. Pero es un primer paso. Algo que muchas organizaciones ni siquiera tienen.
Nivel 2: Escalando la seguridad como cultura
Cuando pasás al siguiente nivel, ya no evaluás una app por vez. Estás estandarizando todo: procesos, herramientas, capacitación. Tenés una forma clara y repetible de modelar amenazas. Ya no se improvisa. Se sistematiza.
El gran cambio acá es que el modelado deja de ser arte y empieza a ser ingeniería. Hay inventario de perfiles de riesgo. Se documenta. Se comparte con los stakeholders. Ya no es solo una preocupación de seguridad: producto, desarrollo y negocio están en la conversación.
La amenaza deja de ser una hipótesis y pasa a ser una variable en la planificación.
Nivel 3: Seguridad predictiva y automatizada
Y cuando llegás al nivel 3, jugás en otra liga. La evaluación de amenazas es proactiva. Se revisan periódicamente todos los perfiles de riesgo para mantenerlos alineados con el estado real del sistema. Acá ya se integra todo con CI/CD, se automatiza la detección de cambios relevantes y se reevalúa el modelo cuando el entorno cambia.
La metodología de modelado de amenazas se vuelve parte del ciclo de vida. No es un documento más: es una fuente viva de información que guía decisiones, previene incidentes y ajusta defensas.
La organización no solo entiende sus amenazas: las anticipa.
La importancia de alinear seguridad con decisiones técnicas
Uno de los errores más comunes que veo es tratar la seguridad como un checklist paralelo al desarrollo. Pero cuando modelás amenazas desde el diseño, todo cambia. Porque ese modelo te fuerza a contestar preguntas que muchas veces nadie se hace:
- ¿Quién puede tocar qué dato?
- ¿Qué pasa si este servicio cae?
- ¿Qué atacante tendría motivos para explotar esta debilidad?
- ¿Cómo se movería lateralmente en la arquitectura?
Y cuando respondés eso, tomás decisiones mejores. Cambiás APIs, ajustás roles, reestructurás almacenamiento, o incluso rediseñás flujos. Eso es lo que logra una buena evaluación de amenazas: moldea el sistema antes de que sea tarde.
Madurez no es tener una herramienta cara: es tener visión
Podés tener la mejor plataforma de seguridad del mercado y seguir en nivel 1 si no sabés usarla. La verdadera madurez viene con cultura. Con práctica. Con procesos vivos. Con equipos que entienden por qué hacen lo que hacen. Por eso siempre empujo a los equipos a que, aunque estén en pañales, arranquen el modelado de amenazas con lo que tienen. Aunque sea un post-it y un par de preguntas básicas.
Después se escala. Se sistematiza. Se automatiza.
Pero todo empieza con mirar tu propio sistema como si fueras tu peor enemigo.
Seguridad como diseño, no como emergencia
El modelado de amenazas no es opcional. No si querés construir algo que dure, que escale y que no termine en los titulares por un breach evitable. La evaluación de amenazas bien implementada transforma cómo diseñás software. Y, a medida que tu organización madura, pasa de ser un esfuerzo puntual a una defensa constante, inteligente y automatizada.
Empezá con lo que tenés. Pero empezá ya.
Antes de que otro lo haga por vos.
Arquitectura, diseño y modelado de amenazas según ASVS V1: el núcleo olvidado del software seguro
A esta altura ya deberías saberlo: la seguridad no es una fase. No se «agrega después», no se terceriza mágicamente con una herramienta, y no se soluciona con un parche. La seguridad se diseña. Se planifica. Se estructura. Y eso empieza en la arquitectura. Lo que plantea OWASP en el módulo V1 del ASVS (Application Security Verification Standard) es exactamente eso: convertir la arquitectura y el modelado de amenazas en el sistema nervioso de cualquier desarrollo moderno. Si vas en serio con la seguridad, este debería ser tu punto de partida.
He visto lo mismo en organizaciones chicas y grandes: todos quieren software seguro, pero pocos quieren pagar el costo de pensarlo bien desde el inicio. Entonces vamos a dejar esto claro: si tu arquitectura está improvisada, no importa cuánto pentesting hagas al final. Vas a perder.
Diagramas de flujo de datos
Toda la información recopilada nos permite modelar con precisión la aplicación mediante diagramas de flujo de datos ( DFD ). Los DFD nos permitirán comprender mejor la aplicación al proporcionar una representación visual de cómo procesa los datos.
Los flujos de datos muestran cómo fluyen los datos lógicamente a través de la aplicación, de principio a fin. Permiten identificar los componentes afectados en puntos críticos (p. ej., datos que entran o salen del sistema, almacenamiento de datos) y el flujo de control a través de estos componentes.
Los DFD se centran en cómo se mueven los datos a través de la aplicación y qué sucede con ellos a medida que lo hacen. Los DFD tienen una estructura jerárquica, por lo que pueden utilizarse para descomponer la aplicación en subsistemas y subsistemas de nivel inferior. El DFD de alto nivel nos permitirá aclarar el alcance de la aplicación que se modela. Las iteraciones de nivel inferior nos permitirán centrarnos en los procesos específicos involucrados en el procesamiento de datos específicos.
Existen diversos símbolos que se utilizan en los DFD para el modelado de amenazas. Estos se describen a continuación:
| Símbolo | Nombre | Descripción |
| Entidad externa | La forma de entidad externa se utiliza para representar cualquier entidad fuera de la aplicación que interactúa con la aplicación a través de un punto de entrada. | |
| Proceso | La forma del proceso representa una tarea que gestiona datos dentro de la aplicación. La tarea puede procesar los datos o realizar una acción basada en ellos. | |
| Proceso múltiple | La forma de proceso múltiple se utiliza para presentar un conjunto de subprocesos. El proceso múltiple puede desglosarse en sus subprocesos en otro DFD. | |
| Almacén de datos | La forma del almacén de datos se utiliza para representar las ubicaciones donde se almacenan los datos. Los almacenes de datos no modifican los datos, solo los almacenan. | |
| Flujo de datos | La forma del flujo de datos representa el movimiento de datos dentro de la aplicación. La dirección del movimiento de datos se representa mediante una flecha. | |
| Límite de privilegio | La forma del límite de privilegio (o límite de confianza) se utiliza para representar la variación en los niveles de confianza a medida que los datos fluyen a través de la aplicación. Los límites muestran cualquier punto donde cambie el nivel de confianza. |
Diagramas de ejemplo
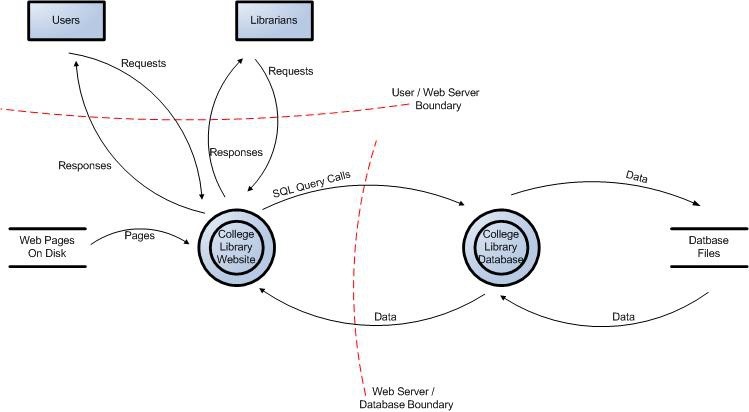
Figura 1: Diagrama de flujo de datos para el sitio web de la biblioteca universitaria.
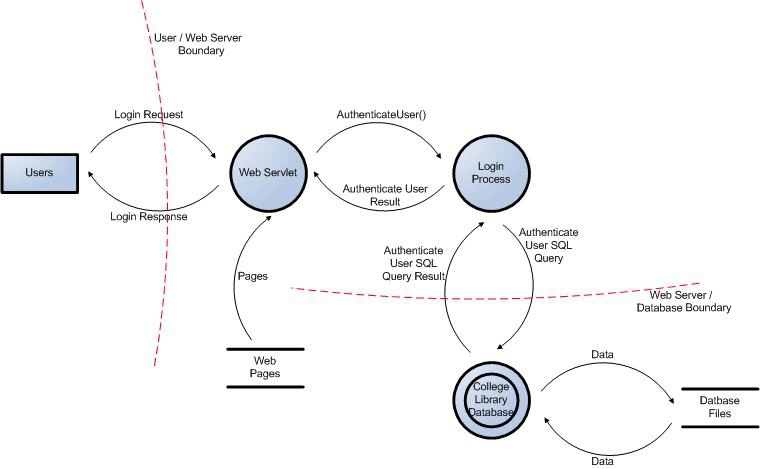
Figura 2: Diagrama de flujo de datos de inicio de sesión de usuario para el sitio web de la biblioteca universitaria.
La base: pensar como atacante desde la etapa de diseño
El módulo V1 del ASVS no es solo una checklist, es un cambio de mentalidad. Te obliga a encarar el diseño con un mindset ofensivo, a definir límites de confianza, analizar flujos, pensar en qué puede salir mal y dejar todo eso documentado. Y esto no se hace una vez. Se hace sprint a sprint, en cada release, en cada cambio.
Un SDLC moderno no es seguro si no integra modelado de amenazas desde la etapa de planificación. Y no hablo de STRIDE porque queda bien en presentaciones. Hablo de bajarlo a tierra: ¿cuál es el flujo más crítico de esta app? ¿Cómo lo podría romper alguien sin acceso? ¿Qué impacto real tendría si eso pasa?
Autenticación, control de acceso y privilegios: sin atajos
Uno de los errores más comunes que veo es pensar que con MFA ya está. Pero la arquitectura de autenticación real va mucho más allá. ¿Tus APIs internas están autenticadas? ¿Tenés rutas alternativas sin control? ¿Tus mecanismos de autenticación están estandarizados o tenés un Frankenstein de librerías y tokens mal manejados?
Cada componente del sistema debería autenticarse con privilegios mínimos. Y todo flujo de acceso tiene que pasar por el mismo mecanismo validado. Si tenés múltiples formas de validar identidades, estás abriendo puertas sin darte cuenta.
Y por favor: nunca pongas lógica de autorización en el cliente. Jamás.
Entrada, salida y validación: no todo se arregla con un WAF
Cuando se trata de entradas del usuario, serialización, validaciones y codificación de salida, hay que ser paranoico. La validación debe ocurrir en capas confiables, no en el frontend ni en middlewares random. Si deserializás contenido desde el cliente sin protección, estás abriendo la puerta a RCE como si fuera 2008.
Y cuando hagas output, hacelo justo antes del intérprete que lo va a consumir. Eso significa: codificás HTML antes del navegador, codificás SQL antes del motor, y así sucesivamente. Nada de «ya validé antes». Eso no alcanza. Nunca.
Criptografía: no cifres todo, pero tampoco seas negligente
Otro clásico: o se quiere cifrar hasta los logs del sistema, o directamente no se cifra nada. Ambas son malas ideas. Lo que propone el ASVS es sensato: clasificá tus datos, cifrá lo que realmente es sensible, y gestioná claves de forma profesional. ¿Qué significa eso? Que no guardás claves en variables de entorno planas, que no rotás contraseñas a mano, y que usás vaults seguros con un pipeline de rotación automatizado.
Y, más importante aún: las claves del cliente no sirven para proteger nada importante. No confíes en el browser ni en el móvil. Nunca.
La trinchera de verdad: logs, errores y auditoría
No es suficiente con tener logs. Tenés que tener logs consistentes, transportados de forma segura, y con trazabilidad completa. El código fuente tiene que estar versionado y controlado. Y si tenés procesos automatizados de build y deploy, que esos pipelines validen vulnerabilidades, componentes obsoletos y configuraciones inseguras.
¿Tu backend hace deserialización y lo desplegás sin sandbox? Te vas a prender fuego. Literal.
Modelado de amenazas: el corazón del diseño seguro
Ahora, si hay algo que realmente cambia la forma en la que pensás la seguridad de tu sistema, es el modelado de amenazas. Y no estoy hablando de un taller con post-its para cumplir con auditoría. Estoy hablando de usarlo como herramienta viva para tomar decisiones técnicas.
Un buen modelo de amenazas no solo te dice qué puede salir mal. Te ayuda a decidir si eso es aceptable, mitigable o inaceptable. Te obliga a preguntarte:
- ¿Qué estoy construyendo?
- ¿Qué puede salir mal?
- ¿Qué hago al respecto?
- ¿Hicimos un buen trabajo?
Y cada respuesta tiene impacto directo en la arquitectura, los flujos de negocio, los controles, y en última instancia, en la confianza que tu producto le da al usuario.
No es una tarea que hacés una vez y archivás. Es un proceso continuo, iterativo, que crece con el sistema. Cambiaste tecnología, agregaste una feature, tuviste un incidente: actualizás el modelo.

Análisis de amenazas
Se afirma con frecuencia que «un requisito previo para el análisis de amenazas es comprender la definición genérica de riesgo». Pero no es así. Se puede analizar qué puede salir mal sin poder medirlo ni cuantificarlo.
El análisis de amenazas consiste en identificar las amenazas a la aplicación e implica analizar cada aspecto de su funcionalidad, arquitectura y diseño. Es importante identificar y clasificar las posibles debilidades que podrían dar lugar a una vulnerabilidad.
Desde una perspectiva defensiva, la identificación de amenazas basada en la categorización del control de seguridad permite al analista de amenazas centrarse en vulnerabilidades específicas. Normalmente, el proceso de identificación de amenazas implica ciclos iterativos donde inicialmente se evalúan todas las posibles amenazas de la lista de amenazas aplicables a cada componente.
En la siguiente iteración, se analizan las amenazas con mayor profundidad, explorando las rutas de ataque, las causas raíz de la amenaza que se pretende explotar (p. ej., vulnerabilidades, representadas como bloques naranjas a continuación) y los controles de mitigación necesarios (p. ej., contramedidas, representadas como bloques verdes a continuación). Un árbol de amenazas, como el que se muestra a continuación, resulta útil para realizar dicho análisis.
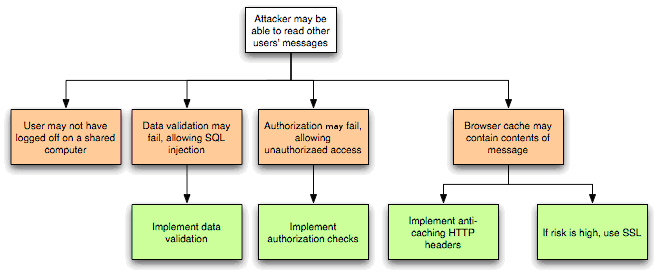
Figura 3: Diagrama de árbol de amenazas.
Una vez evaluadas las amenazas, vulnerabilidades y ataques comunes, un análisis de amenazas más preciso debe considerar los casos de uso y abuso. Mediante un análisis exhaustivo de los escenarios de uso, se pueden identificar las debilidades que podrían llevar a la materialización de una amenaza. También se deben identificar los casos de abuso. Estos casos pueden ilustrar cómo se podrían eludir las medidas de protección existentes o dónde existe una falta de dicha protección.
A continuación se muestra un gráfico de casos de uso y abuso para la autenticación:
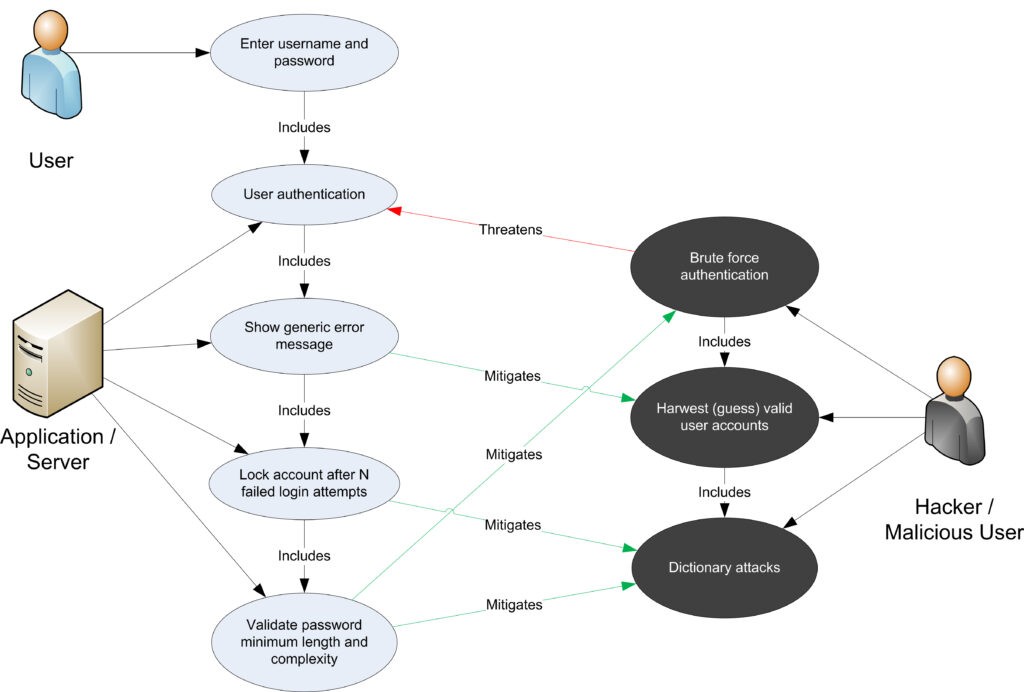
Figura 4: Casos de uso y mal uso
El resultado del análisis de amenazas es la determinación de los tipos de amenazas que afectan a cada componente del sistema descompuesto. Esto puede documentarse mediante una categorización de amenazas como STRIDE o ASF , el uso de árboles de amenazas para determinar cómo una vulnerabilidad puede exponer la amenaza, y casos de uso y abuso para validar aún más la ausencia de contramedidas de mitigación.
Clasificación de amenazas
Las amenazas se pueden clasificar según sus factores de riesgo. Al determinar el factor de riesgo que representan las diversas amenazas identificadas, es posible crear una lista priorizada de amenazas para respaldar una estrategia de mitigación de riesgos, como priorizar las amenazas que se deben mitigar primero. Se pueden utilizar diferentes factores de riesgo para clasificar las amenazas como de riesgo alto, medio o bajo. En general, los modelos de riesgo de amenazas utilizan diferentes factores para modelar los riesgos, como los que se muestran a continuación:
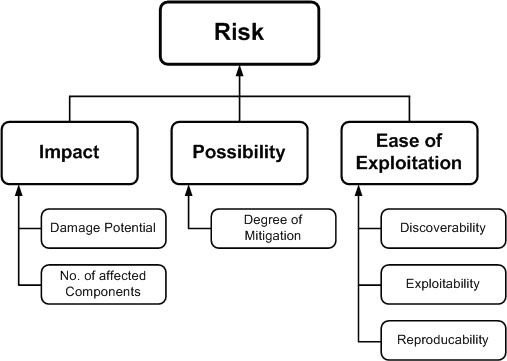
Figura 5: Clasificación de factores de riesgo.
Beneficios reales: no humo
Cuando modelás amenazas como se debe:
- Tomás decisiones con base en evidencia, no suposiciones.
- Podés justificar por qué se invierte tiempo o recursos en cierta defensa.
- Tenés una narrativa de seguridad coherente para mostrar al negocio, clientes o auditores.
- Mejorás la comunicación entre seguridad, desarrollo, producto y arquitectura.
Y sobre todo: reducís la probabilidad de tener que apagar incendios a las 3 AM por algo que podrías haber anticipado con una hora de análisis en diseño.
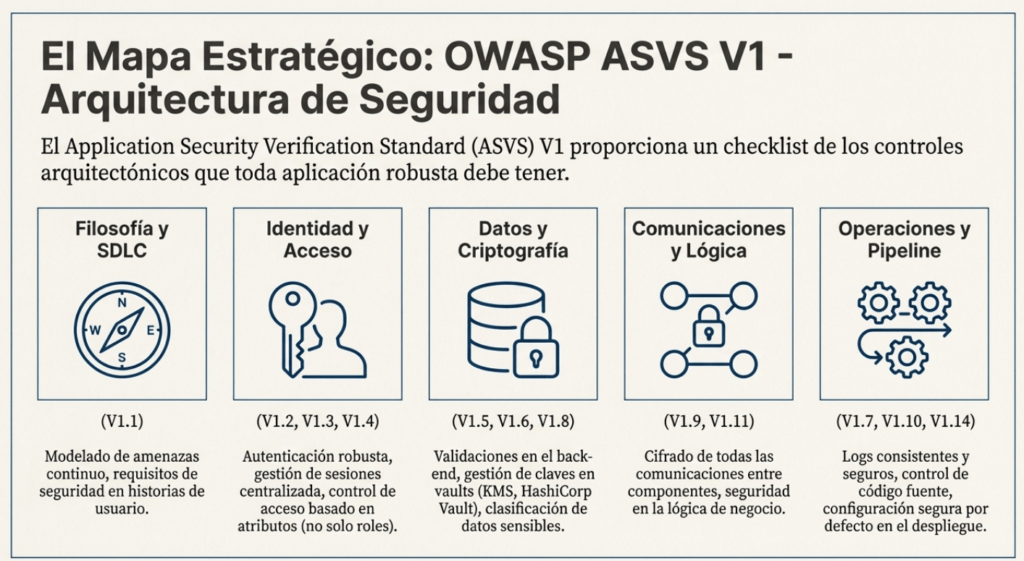
Checklist de implementación práctica según ASVS
Querés empezar ya. Esto es lo que tenés que tener implementado para alcanzar madurez L2 real en arquitectura segura:
- ✅ Ciclo de desarrollo con seguridad desde el inicio (V1.1.1)
- ✅ Modelado de amenazas regular y estructurado (V1.1.2)
- ✅ Autenticación robusta y monitoreada (V1.2)
- ✅ Control de acceso basado en atributos y contexto (V1.4)
- ✅ Validación y codificación del lado seguro (V1.5)
- ✅ Vaults seguros para secretos (V1.6)
- ✅ Logs estructurados, transportados y trazables (V1.7)
- ✅ Clasificación de datos sensibles y políticas aplicadas (V1.8)
- ✅ Canales cifrados con autenticación mutua (V1.9)
- ✅ Gestión segura del código fuente (V1.10)
- ✅ Lógica empresarial protegida contra race conditions (V1.11)
- ✅ Subida de archivos aislada y controlada (V1.12)
- ✅ Configuración segura, sin tecnologías obsoletas (V1.14)
Conclusión: arquitectura como arma, no como formalismo
Si tu arquitectura es segura, tu sistema puede fallar y seguir resistiendo. Si tu arquitectura es débil, podés tener el mejor código y aún así estar jodido. Lo que propone el ASVS en su módulo V1 no es un set de requisitos. Es una estrategia. Es el blueprint para hacer sistemas resilientes desde el diseño. No es glamour, es práctica. No es burocracia, es sobrevivencia.
Y si no lo haces vos, alguien más va a encontrar dónde te equivocaste. La diferencia es que vos lo hacés para prevenir. Ellos lo van a hacer para explotarte. Así que la próxima vez que te sientes a definir una arquitectura, preguntate esto:
¿Ya modelaste tus amenazas, o todavía estás cruzando los dedos?
El Modelado de Amenazas es El Arte de Prever Antes de Ser Atacado
Si sos desarrollador, arquitecto o parte de un equipo de seguridad, hay una verdad que no podés seguir ignorando: la seguridad no se repara, se diseña. Y en el núcleo de ese diseño está una de las herramientas más potentes (y subestimadas) del desarrollo seguro: el modelado de amenazas. Lejos de ser una moda o una actividad burocrática, el modelado de amenazas es una técnica estructurada que te permite pensar como atacante, identificar debilidades antes de que se conviertan en brechas y diseñar tu software para resistir agresiones en serio.
No hay mayor diferencia entre un sistema inseguro y uno resiliente que la calidad del análisis de amenazas previo al código.
¿Qué es el modelado de amenazas y por qué importa?
El modelado de amenazas es una técnica de ingeniería diseñada para identificar amenazas, ataques, vulnerabilidades y contramedidas desde el diseño de la aplicación. Te obliga a responder preguntas incómodas desde el minuto cero: ¿Qué puede salir mal? ¿Cómo explotaría este flujo alguien malintencionado? ¿Cuáles son los activos más valiosos que tengo que proteger?
Más allá de definir amenazas, el proceso también te guía en su mitigación y en la validación posterior. En otras palabras, te da una estrategia técnica, verificable y repetible para reducir el riesgo. Es parte del Secure Development Lifecycle (SDL), y deberías incorporarlo como parte fundamental de tus sprints.
Modelo de madurez de garantía de software
Nuestra misión es brindarle una forma eficaz y medible de analizar y mejorar su ciclo de vida de desarrollo seguro . SAMM abarca todo el ciclo de vida del software y es independiente de la tecnología y los procesos . Diseñamos SAMM para que sea evolutivo y esté basado en el riesgo , ya que no existe una fórmula única que funcione para todas las organizaciones.
Consulte el modelo OWASP SAMM v2 en línea :
El ciclo real del modelado de amenazas
Hay cinco pasos básicos que definen el proceso completo:
- Definir los requisitos de seguridad
- Crear un diagrama de aplicación o sistema
- Identificar amenazas (STRIDE, ATT&CK, etc.)
- Mitigar con controles efectivos
- Validar que las mitigaciones realmente funcionen
Este ciclo no es lineal. Se repite, se ajusta y se refina con cada release, cada cambio arquitectónico y cada incidente. Lo importante es que pase a formar parte del ADN de tu equipo de desarrollo, no como un hito aislado, sino como una práctica continua.
STRIDE y las 4 preguntas que te obligan a pensar como un atacante
Dos enfoques fundamentales para implementar modelado de amenazas:
- El clásico modelo STRIDE, desarrollado por Microsoft, categoriza las amenazas según el tipo de propiedad violada (autenticación, integridad, disponibilidad, etc.). Te da un marco práctico para analizar lo que realmente puede fallar.
- Las cuatro preguntas de Adam Shostack, un marco que te ancla a lo esencial:
- ¿En qué estamos trabajando?
- ¿Qué puede salir mal?
- ¿Qué vamos a hacer al respecto?
- ¿Hicimos un buen trabajo?
Combinás ambos y tenés un punto de partida brutalmente efectivo para cualquier análisis.
No todo es STRIDE: otras metodologías que valen la pena
El modelado de amenazas ha evolucionado, y hoy existen múltiples marcos adaptados a distintos contextos:
- PASTA (Process for Attack Simulation and Threat Analysis): más orientado al análisis de impacto en negocio y análisis dinámico de amenazas en contextos reales.
- LINDDUN: enfocado en privacidad. Útil si tratás datos personales, sensibles o cumplís con normativas como GDPR o HIPAA.
- RRA de Mozilla: una herramienta rápida y ágil para priorizar riesgos sin ahogarte en documentación.
Además, podés combinar estos enfoques con herramientas como MITRE ATT&CK, que te brinda inteligencia real sobre comportamientos de atacantes, para hacer tus modelos más ajustados a amenazas del mundo real.
¿Y qué frameworks de desarrollo seguro soportan esta práctica?
El ASVS (Application Security Verification Standard) y el OWASP SAMM (Software Assurance Maturity Model) lo dejan clarísimo: el modelado de amenazas es una práctica esencial en cualquier ciclo maduro de desarrollo seguro. De hecho, si querés alcanzar un nivel L2 o L3 de madurez en seguridad según estos estándares, no podés salteártelo.
SAMM incluso lo considera parte integral de la etapa de diseño, al lado de actividades como definición de requisitos de seguridad, arquitectura segura y validaciones automatizadas.
Beneficios reales: esto no es teoría, es ROI
Implementar modelado de amenazas bien hecho genera beneficios concretos:
- Detectás fallos críticos antes del desarrollo, cuando son baratos de corregir.
- Mejorás la calidad del diseño técnico con evidencia de riesgos.
- Estás más preparado para responder ante ataques reales.
- Tenés una narrativa sólida para auditores, clientes y reguladores.
- Facilitás la colaboración entre arquitectura, seguridad, desarrollo y negocio.
- Te volvés un desarrollador más completo. Punto.
En CMS, por ejemplo, lo integraron como parte del SDLC completo, lo combinan con herramientas de visualización como Mural, documentación como Confluence, y hasta sesiones colaborativas en Zoom con equipos distribuidos. ¿Resultado? Equipos que piensan antes de escribir código.
Herramientas para hacer esto bien (gratis y pagas)
No necesitás mil dólares al mes para arrancar con esto. Hay herramientas gratuitas que funcionan de maravilla:
- OWASP Threat Dragon: open source, multiplataforma, ideal para armar diagramas y amenazas asociadas.
- Herramienta de modelado de Microsoft: muy sólida, integra análisis automático con diagramas DFD y plantillas de amenazas.
- App.diagrams.net / Lucidchart: si ya sabés lo que estás haciendo, cualquier herramienta de diagramación te sirve.
Y si necesitás algo más enterprise:
- IriusRisk: automatiza modelos de amenazas en tiempo de diseño con recomendaciones incluidas.
- ThreatModeler: integración total con pipelines DevSecOps.
- Devici: apunta al concepto de Secure by Design desde el momento cero del proyecto.
Lo importante no es la herramienta, sino el proceso y la disciplina para aplicar esta práctica de forma recurrente.
El modelado de amenazas no es opcional
Podés tener el mejor WAF, el mejor equipo de SOC, un pentester brillante, pero si tu arquitectura tiene errores estructurales porque nadie se sentó a modelar amenazas… vas a caer igual.
El modelado de amenazas no es una moda. Es una forma profesional y proactiva de encarar la seguridad. Es una conversación entre desarrollo, negocio y arquitectura, impulsada por la pregunta más importante que un hacker se hace todos los días: ¿qué pasaría si…?
Así que la próxima vez que estés por diseñar un sistema, arrancar un sprint o diagramar una nueva funcionalidad, ya sabés qué hacer. No arranques hasta haber modelado tus amenazas.
Porque si vos no lo hacés, el atacante sí lo hará.
Y él no te va a dar tiempo para mitigarlo.
Modelado de amenazas: 12 métodos disponibles y cómo elegir el correcto
Conforme la complejidad de los sistemas aumenta y las amenazas se diversifican, el modelado de amenazas se convierte en una herramienta crítica para anticipar vectores de ataque, visualizar el riesgo en contexto y definir controles más precisos.
El problema: existen múltiples métodos. Y no hay uno “mejor” universalmente. Cada enfoque sirve para diferentes tipos de sistemas, equipos, y objetivos (técnicos, regulatorios o de negocio).
Este artículo resume los 12 métodos más reconocidos, con una guía clara sobre cuándo y por qué elegir cada uno.
¿Qué es el modelado de amenazas?
Modelar amenazas es crear una abstracción del sistema (cómo fluye la información, quién accede, qué partes están expuestas), definir actores maliciosos (y sus capacidades), y enumerar los posibles escenarios de ataque.
Este proceso permite:
- Visualizar puntos débiles antes de que sea tarde.
- Justificar decisiones de arquitectura y mitigación.
- Traducir riesgos técnicos en lenguaje de negocio.
- Cumplir requisitos regulatorios (HIPAA, GDPR, PCI-DSS, etc.).
Idealmente se realiza en fases tempranas del ciclo de desarrollo (SDLC), pero se puede aplicar en cualquier etapa — incluso como herramienta de revisión o post mortem.
12 Métodos de modelado de amenazas (resumen comparativo)
| Método | Enfoque principal | Mejor uso cuando… |
| STRIDE | Clasificación de amenazas | Estás modelando software tradicional con DFDs |
| PASTA | Riesgo & negocio | Necesitás alinear seguridad con objetivos estratégicos |
| LINDDUN | Privacidad | Procesás datos personales / regulaciones de privacidad |
| CVSS | Puntuación de vulnerabilidades | Ya tenés vulnerabilidades detectadas y querés priorizar |
| Árboles de ataque | Estructura lógica de ataques | Necesitás visualizar múltiples caminos de explotación |
| Persona non grata | Motivación del atacante | Buscás explorar abuso intencional del sistema |
| Tarjetas de seguridad | Ideación creativa | Quieren descubrir amenazas no obvias o no técnicas |
| hTMM | Híbrido & bajo costo | Equipos con menos experiencia buscan consistencia |
| TMM Cuantitativo | Medición y combinación | Integración formal con STRIDE/CVSS en sistemas complejos |
| Trike | Permisos y gestión de riesgo | Necesitás conectar actores, permisos y activos |
| VAST | Automatización & DevOps | Escalás seguridad en toda la organización |
| OCTAVE | Riesgo organizacional | Riesgos desde la perspectiva del negocio y compliance |
Profundizando en algunos enfoques
1. STRIDE (Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege)
- ¿Cuándo usarlo? Para aplicaciones con diagramas de flujo de datos (DFD).
- Ventajas: Fácil de enseñar, buen punto de partida.
- Limitaciones: Menos útil para privacidad, negocio o amenazas internas.
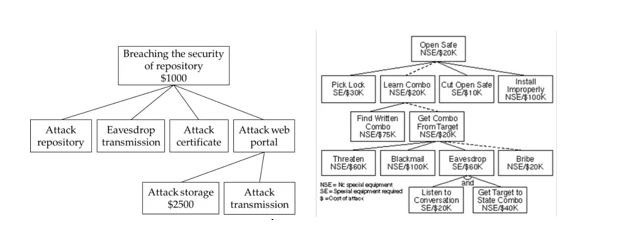
2. PASTA (Process for Attack Simulation and Threat Analysis)
- ¿Cuándo usarlo? En entornos con riesgo empresarial real y necesidad de priorización.
- Fuerte en: Integración con arquitectos, legales, compliance y CISO.
- Requiere: Participación multidisciplinaria.

3. LINDDUN
- Centrado en amenazas a la privacidad (identificación, vigilancia, correlación de datos, etc.).
- Ideal para cumplir GDPR o LGPD.
- Usa DFDs como STRIDE, pero analiza impactos sobre derechos individuales.
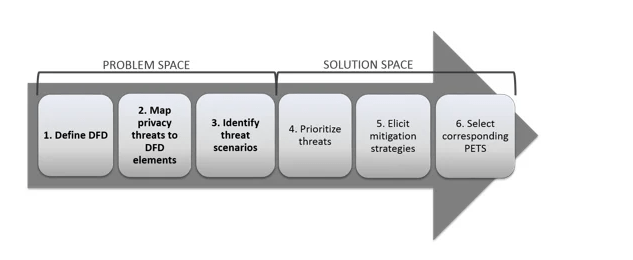
4. CVSS (Common Vulnerability Scoring System)
- No es un modelado de amenazas completo, pero es excelente para priorizar acciones una vez detectadas.
- Compatible con STRIDE, árboles de ataque y escáneres como Nessus o Qualys.
5. Árboles de ataque
- Visualmente poderoso. Muestra cómo un atacante puede alcanzar un objetivo desde múltiples caminos.
- Recomendado como complemento de cualquier otro método.
6. VAST
- Pensado para escalar el modelado de amenazas en toda una organización.
- Automatiza parte del análisis con herramientas como ThreatModeler.
- Compatible con CI/CD, DevSecOps y despliegue ágil.
Métodos centrados en el atacante o usuario
- Persona non grata (PNG): Exploración creativa del «mal uso» del sistema, desde la motivación del atacante. Útil en UX, productos, fintech, redes sociales.
- Tarjetas de seguridad: Método informal para sesiones de brainstorming. Divide amenazas por impacto humano, motivaciones, recursos y técnicas.
Métodos híbridos y avanzados
- hTMM: Mezcla PNG + tarjetas + evaluación sistemática. Útil para obtener resultados reproducibles y consistentes en poco tiempo.
- TMM Cuantitativo: Fusiona STRIDE, árboles de ataque y CVSS. Permite analizar interdependencias complejas en entornos ciberfísicos (IoT, industria 4.0, energía, transporte).
- Trike: Estructura el análisis a partir de roles, permisos y reglas CRUD. Fuerte en entornos con usuarios diversos y muchas reglas de acceso.
- OCTAVE: No es técnico, sino estratégico. Evalúa riesgos desde la organización. Muy útil para CISO y áreas de cumplimiento.
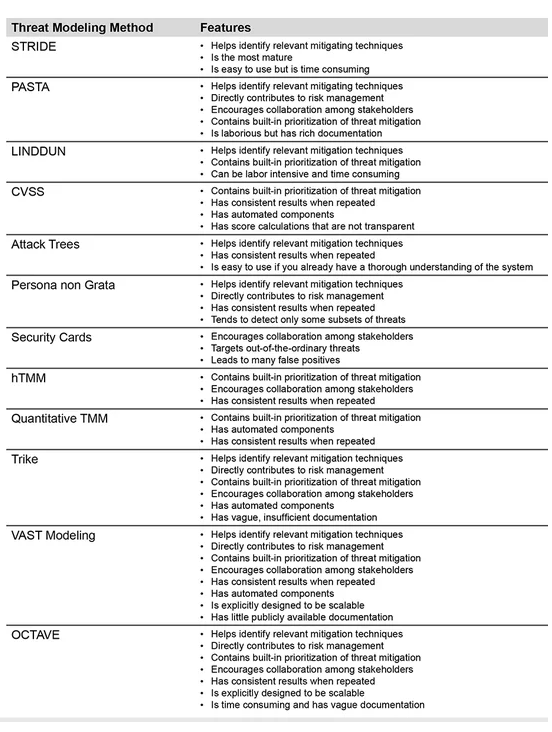
¿Qué método deberías usar?
La mejor elección depende del contexto. Algunas recomendaciones prácticas:
| Situación | Método sugerido |
| Proyecto tradicional en fase de diseño | STRIDE |
| App con datos personales / GDPR | LINDDUN |
| Sistema complejo con múltiples dependencias | PASTA + Árboles de ataque |
| Ambiente regulado (banca, salud, gobierno) | OCTAVE + CVSS |
| Proceso creativo o UX | PNG + Tarjetas |
| Equipos grandes en DevOps | VAST |
| Entornos industriales o IoT | TMM Cuantitativo + PASTA |
| Alta rotación de equipos | hTMM |
No existe un único camino para modelar amenazas. La clave está en elegir el método correcto para el momento, el equipo y el sistema. Muchas veces, la mejor solución es combinar varios enfoques: usar STRIDE para amenazas técnicas, LINDDUN para privacidad, CVSS para priorizar y PASTA para alinear con el negocio.
Lo importante es que el modelado de amenazas no sea un checkbox de cumplimiento, sino una herramienta viva, parte del ADN del diseño seguro.
Patrones de seguridad
Los patrones de seguridad son artefactos utilizados en ciberseguridad para la arquitectura y el diseño. Representan una solución definida y reutilizable para un problema recurrente en el ámbito de la ciberseguridad.
¿Qué es un patrón de seguridad?
Un patrón de seguridad normalmente se define por las siguientes cuatro características.
- Escrito en el contexto de un problema de seguridad y cómo afecta al activo.
- Abstraído de implementaciones de proveedores o tecnologías específicas.
- Mantiene la trazabilidad de los controles prescritos hasta las amenazas originales que se están mitigando.
- Estandarización de taxonomías de amenazas y controles para promover la reutilización.
Existen muchas variaciones de lo que representa un patrón de seguridad, incluidas definiciones de patrones de arquitectura de seguridad, patrones de diseño de seguridad y planos de seguridad.
Los patrones de seguridad normalmente se describen en un formato de plantilla que incluye la siguiente información:
- Problema: una descripción del problema de seguridad que aborda el patrón.
- Contexto: Una descripción del contexto en el que se aplica el patrón y los activos.
- Modelo de amenazas: identificar las amenazas a la ciberseguridad y cómo pueden afectar a los activos.
- Solución: Una descripción de la solución del patrón, incluidos sus componentes, interacciones y restricciones.
- Controles: Lista de controles que se aplican para mitigar las amenazas con ejemplos de cómo se aplica el control para ese activo.
Una selección de controles basada en el riesgo
Los marcos regulatorios y de cumplimiento se centran cada vez más en la aplicación de un enfoque basado en riesgos para la implementación de controles de seguridad. Es decir, evaluar los riesgos y seleccionar los controles adecuados.
Los patrones de seguridad proporcionan los medios para aplicar una selección basada en riesgos para determinar los controles de seguridad apropiados, con trazabilidad hasta las amenazas que están mitigando.
Seguridad por diseño
Los patrones de seguridad se utilizan a menudo como parte de la seguridad por diseño. Proporcionan un enfoque de diseño estandarizado que se centra en comprender el contexto de un problema, en lugar de simplemente prescribir una lista de controles.
La adopción de patrones de seguridad ha sido impulsada por una serie de factores, entre ellos:
- La creciente complejidad de las amenazas y ataques a la seguridad.
- La necesidad de demostrar trazabilidad de qué controles están mitigando qué amenazas.
- Auditabilidad dentro de los procesos de arquitectura de seguridad para la selección de controles necesarios para mitigar aquellas amenazas identificadas.
Alineación con los marcos de arquitectura
SABSA (Arquitectura de Seguridad Empresarial Aplicada de Sherwood)
El marco de SABSA contempla el uso de patrones de seguridad como parte de su metodología. La definición de patrones de seguridad no está explícitamente vinculada a SABSA, pero actúa como un artefacto dentro de las capas conceptual y lógica de la Matriz SABSA.
Los patrones de seguridad se pueden utilizar en todas las etapas del ciclo de vida de SABSA, desde la estrategia y la planificación hasta el diseño, la implementación y la operación.
¿Por qué utilizar patrones de seguridad?
Los patrones de seguridad son artefactos de diseño que representan una solución definida y reutilizable para problemas de seguridad recurrentes. Se centran en los activos y describen los controles de seguridad en el contexto de estos. Los patrones garantizan que los controles de seguridad identificados se basen en el modelado de amenazas asociado a la protección de los activos.
Hay muchas iniciativas diferentes que pueden impulsarle a escribir un patrón de seguridad, como por ejemplo:
- Riesgos o problemas de seguridad planteados por un equipo de proyecto que requieren mitigación.
- Preocupaciones de seguridad basadas en problemas identificados dentro de organizaciones similares.
- Nuevos productos o capacidades que se incorporan a su organización.
Las guías disponibles en securitypatterns.io proporcionan pasos para escribir y utilizar sus propios patrones de seguridad.
Siéntete libre de personalizar estas plantillas para tus propios fines (de hecho, te animamos a que lo hagas).
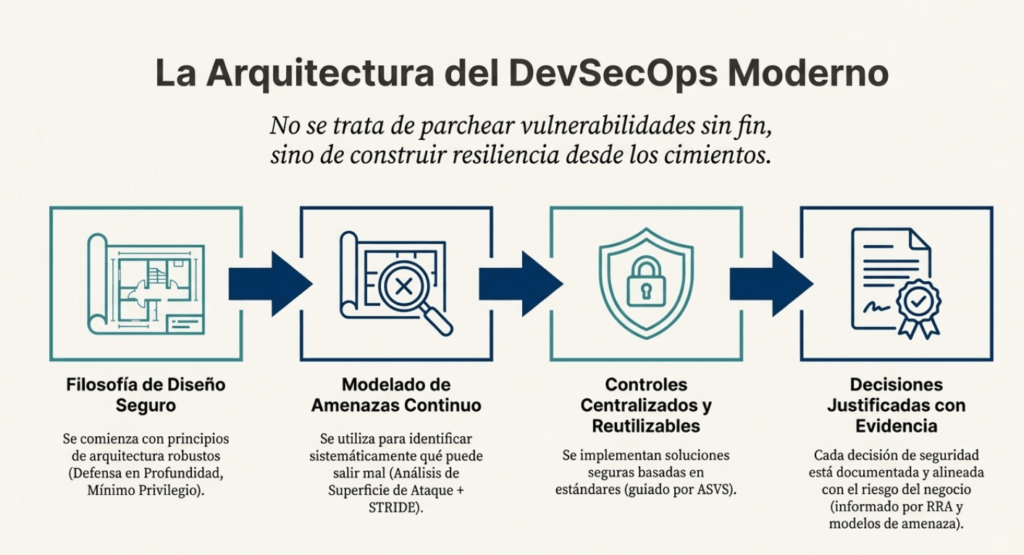
Cómo escribir un patrón de seguridad reutilizable: Guía práctica desde la trinchera
Hace años, cuando empecé a meterme más a fondo en arquitectura segura, me costaba encontrar una guía concreta sobre cómo construir patrones de seguridad aplicables a la realidad. No me refiero a los papers teóricos que suenan bien en conferencias, sino a documentos que puedas llevar al día a día del desarrollo. Esta guía la escribo desde la experiencia y el dolor: construir una arquitectura sólida que escale, que sea defensiva, entendible, y que se pueda replicar en otros proyectos.
Un patrón de seguridad, bien hecho, no es simplemente una receta de controles. Es un diseño reusable que parte de un problema real, lo contextualiza en activos específicos, analiza amenazas, mapea controles y los alinea con principios claros. No tiene sentido escribir un patrón para «cumplir con normas» si después nadie lo aplica. Esta guía busca lo contrario: que cada patrón que documentes tenga impacto, trazabilidad y sentido técnico real.
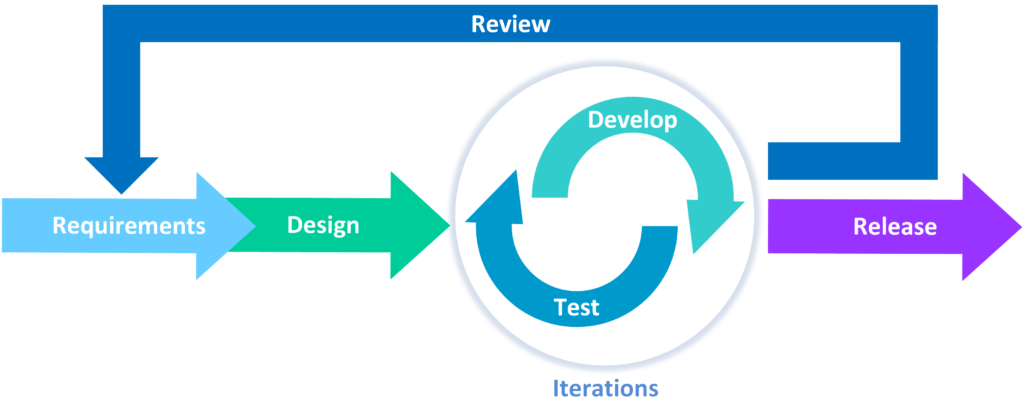
¿Por qué escribir patrones de seguridad?
Con la velocidad que tiene hoy el desarrollo, los sprints cortos, el push a producción constante, el concepto de «diseñar la seguridad antes de escribir código» se volvió más que una buena práctica, una necesidad. Pero el diseño sin repetibilidad es tiempo perdido.
Los patrones de seguridad permiten:
- Reutilizar análisis de amenazas.
- Justificar decisiones técnicas con contexto real.
- Alinear el diseño con normativas y controles de compliance.
- Agilizar discusiones con arquitectura, producto o incluso con legal.
- Evitar reinventar la rueda cada vez que aparece el mismo problema.
A diferencia de una política o un estándar (que muchas veces son copy-paste sin alma), un patrón conecta directamente amenazas, controles y activos. Esa trazabilidad es oro cuando necesitás defender una decisión técnica o responder frente a un auditor.
El patrón centrado en activos
Un patrón de seguridad tiene muchas formas. Puede ser centrado en procesos, en flujos, o incluso en interacciones humanas. Pero el enfoque más práctico que uso es el de patrón centrado en activos. Es decir, partimos de un activo tecnológico (por ejemplo: un repositorio de código, una base de datos, un servicio API) y diseñamos cómo protegerlo, considerando su contexto y las amenazas que le afectan.
Este enfoque tiene varias ventajas:
- Mantiene los patrones cercanos a la arquitectura técnica real.
- Facilita el modelado de amenazas.
- Alinea mejor con frameworks como NIST SP 800-53.
- Escala de forma más clara cuando tu stack cambia (multi-cloud, SaaS, híbrido).
Paso a paso para construir un patrón de seguridad
1. Definir el problema y el alcance
Todo arranca por acá. El error común es querer empezar definiendo controles sin entender el problema que estamos resolviendo.
Ejemplo concreto: si estás diseñando un patrón para proteger el código fuente, el problema podría ser algo así como «evitar que el código privado sea expuesto por error o atacado por actores internos o externos.»
Acá definís:
- El activo afectado (ej: repositorio Git).
- Los usuarios involucrados (ej: devs internos, terceros, público).
- Y las restricciones o requerimientos previos (ej: políticas internas, normativas como PCI-DSS, SOX).
Cuanto más claro sea este planteo, más fácil es el resto.
2. Investigación técnica y contextual
Una buena parte del tiempo en esta etapa la dedico a leer:
- Best practices del proveedor (GitHub, GitLab, Bitbucket…).
- Vulnerabilidades históricas (CVEs, ataques reales).
- Whitepapers técnicos.
- Benchmarks CIS si existen.
Acá vas recolectando:
- Amenazas posibles (exposición accidental, malware, etc).
- Controles sugeridos por el proveedor.
- Errores comunes que ya viste en otros entornos similares.
No te estreses con esto. El objetivo no es escribir un tratado de investigación, sino tener material sólido para sustentar tu diseño.
3. Inventario de activos
Una vez delimitado el problema, definís qué activos están en juego. Y esto lo hacés con lógica técnica.
Ejemplo:
- Repositorio Git (activo principal).
- Workstations de los devs.
- Servicios de integración (CI/CD).
- Aplicaciones conectadas (APIs que leen código, por ejemplo).
No te vayas al detalle ridículo. La clave es descomponer hasta donde puedas asignar amenazas y controles con sentido. Si un componente no tiene un control claro que lo proteja, probablemente está fuera de alcance.
4. Modelado de amenazas
Esta es la parte más desafiante, pero también donde más valor aportás como arquitecto de seguridad.
Yo uso un enfoque híbrido basado en PASTA, sin llegar al nivel 7 completo (que es más para análisis de riesgo en ejecución). Me quedo con los primeros pasos:
- ¿Qué amenazas afectan a cada activo?
- ¿Qué evento de amenaza representa?
- ¿Qué actor malicioso lo genera?
- ¿Qué impacto tendría?
Importantísimo: usá una taxonomía estándar de amenazas. No inventes nombres. Usá algo como MITRE ATT&CK, STRIDE o la taxonomía que uses en tu organización, pero mantené la consistencia.
Por ejemplo:
- TE-09: Exposición accidental de secretos en código fuente.
- TE-15: Manipulación de permisos de repositorios por usuarios internos.

5. Solución y estado objetivo
Acá bajás la idea de diseño que responde al problema. Qué arquitectura general se necesita. Qué decisiones técnicas se tomaron. Qué principios se aplican.
Uso siempre principios como los del Jericho Forum: separación por defecto, control basado en atributos, desconfianza del entorno, cifrado en tránsito y en reposo, etc.
Si tu organización tiene una arquitectura de referencia, este es el momento de alinearla. Diagramas simples ayudan mucho: flujos de interacción, zonas de confianza, ubicación de los controles.
6. Asignar controles
Este paso es donde se une todo: amenazas + activos + controles.

Uso el NIST SP 800-53 rev 5 como base para los objetivos de control, pero personalizo cada descripción al contexto del activo.
Ejemplo:
- Control SA-11 del NIST (Testing para desarrolladores) lo adapto así:
«Todo commit de código debe escanearse automáticamente para detectar secretos (API keys, tokens, passwords) antes de ser aceptado en el repositorio privado o publicado al público.»
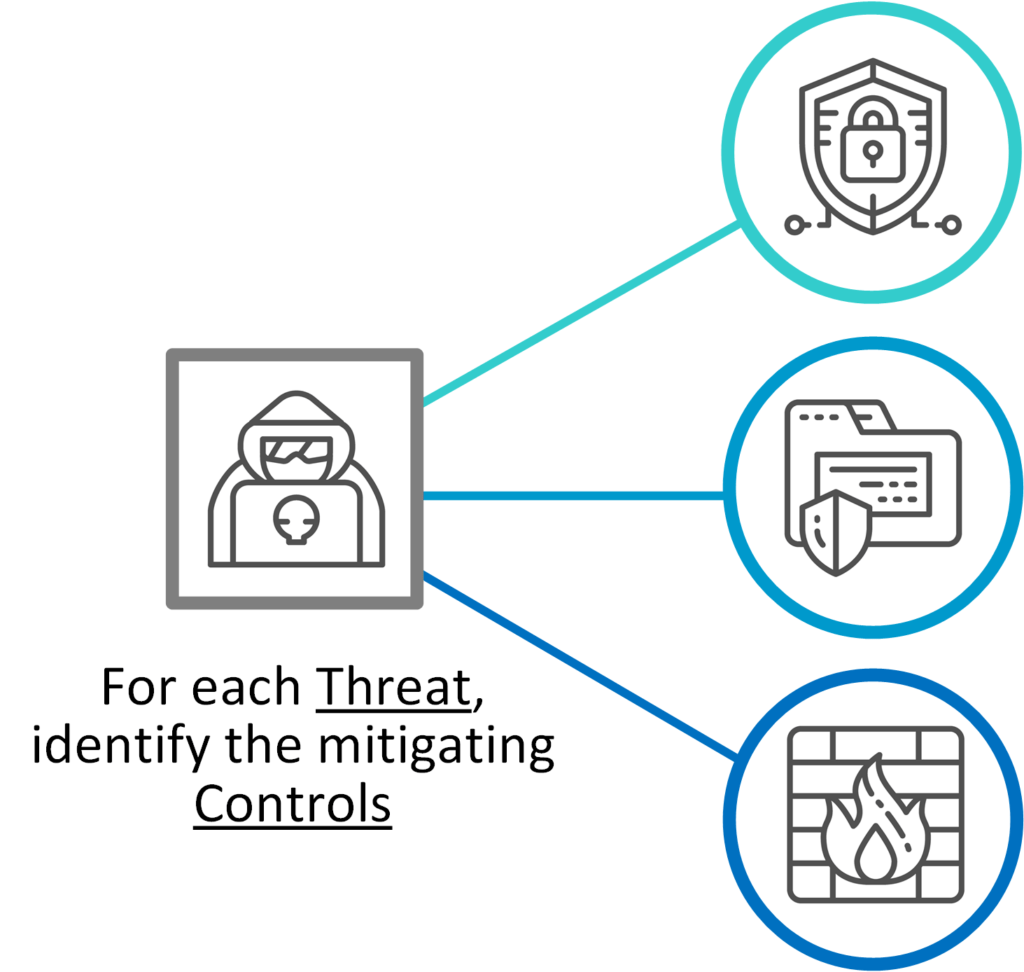
La idea no es copiar/pegar los controles del NIST. Es adaptarlos para que sirvan como guías prácticas para quienes diseñan o implementan.
7. Construcción final del patrón
Ya con todos los mapeos hechos (amenazas → activos → controles), generás una vista por activo. Cada activo tiene su lista de controles, su justificación, y una pequeña personalización de la implementación.

A esto le sumás:
- Descripción del patrón.
- Principios aplicados.
- Casos de uso si querés.
- Un diagrama general.
Tenés un patrón que se puede aplicar en proyectos nuevos, migraciones, o auditorías.
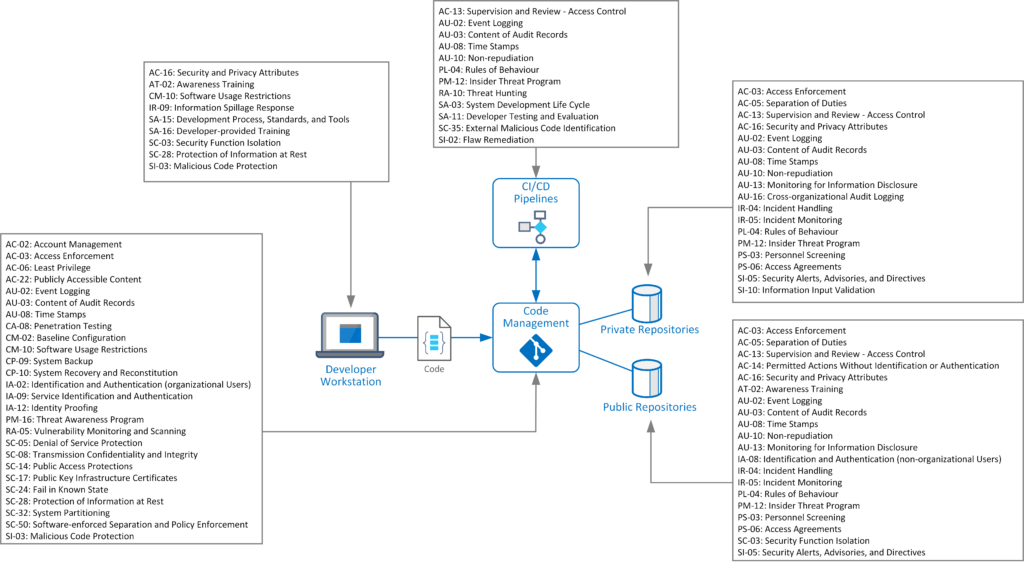
Revisión final
En esta etapa siempre vuelvo para atrás a corregir cosas. Me doy cuenta que un control se repite, o que un activo puede fusionarse con otro.
Es normal. El patrón madura a medida que lo refinás. Lo importante es que no se convierta en una lista genérica de todo lo que podrías hacer. El patrón debe ser práctico, preciso, y alineado al problema real que intentaste resolver.
Escribir un patrón de seguridad no es un ejercicio académico. Es una inversión en diseño reutilizable. Bien hecho, te ahorra horas de discusión, errores y riesgo técnico. Te permite alinear desarrollo, seguridad, arquitectura y negocio en una misma narrativa.
No hace falta hacer 100 patrones para cubrir todo. Pero con 10 bien pensados, podés cubrir el 80% de las superficies críticas de ataque en una organización.
Y si lográs que otros usen esos patrones, los mejoren, y aporten su experiencia, habrás construido una cultura de seguridad real, no una lista de controles copiados de una norma.
Cómo usar un patrón de seguridad en un entorno Agile (y sobrevivir en el intento)
Este artículo es la segunda parte de la serie:
🔧 Cómo escribir un patrón de seguridad reutilizable
📘 Esta entrega: cómo aplicarlo de forma pragmática dentro de un ciclo ágil, sin perder foco técnico, ni tiempo.
Patrones de seguridad: de la teoría al backlog
Una vez que tenés un patrón de seguridad armado, probablemente te estés haciendo tres preguntas incómodas:
- ¿Por dónde arranco en un proyecto real?
- ¿Qué controles aplico primero?
- ¿Cómo hago seguimiento de los controles a lo largo de los sprints?
Lo que sigue no es una receta mágica. Es una hoja de ruta flexible basada en experiencia directa aplicando patrones en proyectos Agile, especialmente en contextos con múltiples equipos, proveedores cloud y entornos cambiantes.
Contexto base: Agile, seguridad y arquitectura
Agile (Scrum, Kanban, SAFe…) es iterativo, rápido y cambia constantemente. Por eso, los patrones de seguridad deben ser livianos, incrementales y adaptables, no bloques rígidos de cumplimiento.
Olvidate del enfoque waterfall de seguridad que intenta definir toda la arquitectura desde el día 0.
En Agile, la seguridad también se entrega sprint a sprint.
Aplicar un patrón de seguridad paso a paso
1. Aterrizá el patrón al alcance del producto
El patrón debe estar ligado a una necesidad tangible del proyecto. No importa si fue escrito como parte de una iniciativa empresarial; al usarlo en un proyecto específico, se recorta al contexto y a los activos del backlog actual.
Ejemplo:
Un proyecto busca consolidar herramientas de gestión de código fuente. El patrón de seguridad para repositorios Git se recorta para enfocarse en:
- Exposición de secretos.
- Accesos de colaboradores externos.
- Validación de pipelines y CI/CD.
Tip:
Usá la sección de «Problema / Alcance» del patrón como punto de partida para conversar con el Product Owner y los stakeholders.
2. Definí la talla del patrón: S, M o L
No todos los patrones requieren el mismo esfuerzo. Adaptá la profundidad del análisis según el tipo de proyecto:
| Talla | Uso | Modelado | Controles | Tiempo estimado |
| S | MVP, prototipos | STRIDE básico | NIST genérico | 2–3 días |
| M | Proyecto formal | STRIDE + PASTA lite | NIST adaptado | 5–7 días |
| L | Crítico o regulado | ATT&CK, CAPEC, PASTA full | NIST avanzado | 10+ días |
Usá la talla M como base por defecto. Solo escalá si lo requiere el riesgo o el apetito del negocio.
3. Convertí los controles del patrón en historias de usuario
No dejes los controles en una wiki estática. Integralos en el backlog como user stories de seguridad, priorizadas junto al equipo técnico.
Ejemplo de historia:
Como responsable de CI/CD, quiero escanear automáticamente los commits para evitar que secretos lleguen al repositorio, mitigando TE-09.
Cada historia puede mapear:
- La amenaza (con ID).
- El control asociado (ej: SC-28).
- El artefacto de validación (evidencia esperada).
- La responsabilidad (Scrum team vs equipo de seguridad vs proveedor).
4. Priorizá los controles que realmente bajan el riesgo
Hay muchas razones para priorizar un control: impacto, facilidad de implementación, costo, madurez tecnológica…
Pero si no sabés por dónde arrancar, usá este enfoque:
- Chequeá las líneas base del NIST SP 800-53B (tienen prioridad sugerida).
- Validá contra los riesgos actuales del entorno.
- Dimensioná con el equipo Scrum el esfuerzo y la dependencia con otras tareas.
Consejo:
Priorizá controles que mitigan amenazas de alto impacto con baja fricción. Son los de mejor ROI en seguridad.
5. Insertá los controles en la hoja de ruta del producto
Los controles priorizados deben entrar explícitamente en el Product Backlog. No como notas aparte ni ítems invisibles.
- Si el producto va a lanzar acceso externo a repositorios, el control de autenticación MFA debe estar en el backlog antes del sprint de publicación.
- Si se va a usar BitBucket en AWS, definí los controles como parte del hardening inicial del stack.
Refactorizar seguridad después es más caro que incluirla desde el vamos.
6. Delegá y goberná sin ahogar a los equipos
No todos los controles deben ser implementados por seguridad. El modelo de Gobernanza + Barandillas te permite delegar sin perder visibilidad.
- 🔒 Controles centrales (barandillas) → Se aplican globalmente (ej. MFA, repos públicos).
- 🛠 Controles delegados → Cada equipo los implementa según su stack, pero siguen las guías del patrón.
Esto reduce la fricción y evita que el equipo de seguridad se transforme en cuello de botella.
7. Medí la efectividad de los controles (garantía)
No alcanza con escribir y planear. Hay que validar que los controles funcionen.
- Controles técnicos: se prueban con escáneres, pipelines, pruebas automatizadas.
- Controles procesales: entrevistas, evidencia documental, revisión entre pares.
🧪 Nunca permitas que el mismo equipo que implementa sea el que evalúa.
Usa revisión cruzada o equipos independientes. Confianza ≠ garantía.

8. Cuando algo falla, volvé al patrón y usa controles compensatorios
Spoiler: algunos controles van a fallar. O se van a postergar. O se romperán en producción.
El patrón te da alternativas. Si un control no funciona, podés:
- Reforzar otros controles que mitigan la misma amenaza.
- Agregar evidencias o monitoreo para reducir el riesgo residual.
- Escalar el análisis al área de riesgos del negocio si el impacto lo justifica.
Y sí, ese control pendiente es ahora deuda técnica de seguridad. Dejala registrada, no escondida.
Para facilitar la evaluación, revisamos el patrón original donde se requirió este control. Identificamos los siguientes controles compensatorios que ayudan a mitigar esa amenaza original.
9. Evaluá el riesgo residual antes del go-live
Ningún producto va a producción con “riesgo cero”. El patrón te ayuda a:
- Mapear qué amenazas siguen activas.
- Qué controles están pendientes o semi-implementados.
- Qué compensaciones existen.
La decisión final de ir a producción con riesgo abierto es del negocio, no de seguridad. Pero vos tenés que darles el mapa.
Seguridad usable, no perfecta
El objetivo de un patrón de seguridad no es cubrirlo todo. Es construir una referencia reusable, técnica y flexible que:
- Se adapta sprint a sprint.
- Permite gobernar sin bloquear.
- Prioriza sin improvisar.
- Mide sin sobrecargar.
En entornos reales, con múltiples equipos, proveedores, deadlines y errores humanos, esto es lo más cercano que tenemos a una arquitectura segura viva.
Hemos analizado muchas consideraciones sobre el uso de patrones de seguridad, con especial atención a Agile. Como se mencionó al principio, el uso de patrones de seguridad no es exclusivo de Agile, pero es donde creo que ofrecen mayor valor.
La última nota de esta guía es comprender que los Patrones de Seguridad son un punto de referencia para los controles necesarios para proteger los activos. Es probable que nunca los implemente todos. El objetivo de los patrones de seguridad es proporcionar un proceso para aplicar controles de forma incremental para mitigar las amenazas a la seguridad (sabiendo que nunca las eliminará por completo).
Será necesario reajustar, replanificar y repriorizar constantemente los controles para abordar los cambios en el panorama de amenazas. Otros factores, como el ritmo de cambio dentro de los proveedores de la nube, también implican que las organizaciones seguirán adoptando nuevas tecnologías u ofertas de servicios.
Los patrones de seguridad tienen como objetivo proporcionar un punto de referencia común a lo largo del tiempo. Es necesario mantenerlos actualizados, pero requieren cambios menos frecuentes.
Escribir patrones de seguridad requiere cierto esfuerzo e inversión. Esperamos que esta guía haya demostrado el valor de dicha inversión.
Gestión del Código Fuente como Pilar de Seguridad: Arquitectura, Controles y Amenazas Reales
Si alguien compromete tu SCM, no importa cuántos firewalls tengas, cuántos WAFs estén configurados ni qué tanto ruido hagan tus SIEMs. Todo puede caer con un simple push. La gestión de código fuente hoy gira en torno a Git y plataformas distribuidas como GitHub, GitLab, Bitbucket o CodeCommit. Son herramientas increíbles desde la perspectiva del desarrollo, pero peligrosas si no se entienden las amenazas reales y los vectores de explotación que estas plataformas exponen.
A continuación, se representan los activos para la gestión del código fuente (SCM) en diferentes dominios de confianza y sus interacciones. Los repositorios Git públicos y privados tienen diferentes consideraciones de seguridad y requieren políticas y configuraciones de seguridad independientes.
Los proveedores externos, socios comerciales y desarrolladores temporales aún pueden acceder a los repositorios privados. Los repositorios SCM y Git principales pueden sincronizarse o replicarse en ubicaciones externas para que los socios accedan a las versiones en caché de los repositorios designados.
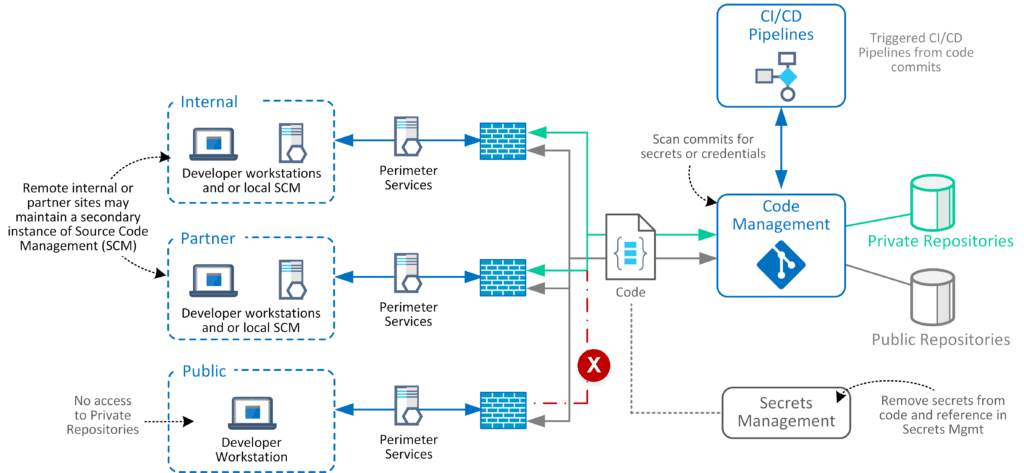
Notas adicionales
- La conectividad a SCM para colaboradores internos es la del mismo socio o público.
- Establecer altos niveles de confianza para los contribuyentes a través de la gestión de identidad y acceso.
- Todos los propietarios y colaboradores con acceso permanecen autenticados a través de un proveedor de identidad confiable.
- Validar la identidad de todas las aplicaciones que acceden al SCM y, cuando sea posible, establecer confianza mutua.
- SCM garantiza la integridad y el no repudio de cualquier cambio en el código fuente (incluidas confirmaciones, envíos, extracciones, ramificaciones o fusiones).
- Las diferentes interfaces expuestas por SCM (línea de comandos, interfaces de API Rest, webhooks) están protegidas independientemente de la ubicación de origen de los contribuyentes (internos, socios, públicos).
- Se consideran controles de acceso para diferentes tipos de desarrolladores para clonación, bifurcación de repositorios, ramificación, solicitudes de extracción y fusión.
- La secuenciación considera diferentes requisitos de acceso durante las fases de desarrollo, prueba y lanzamiento de producción.
- Todos los flujos de trabajo de Git permiten identificar y/o bloquear secretos durante las confirmaciones en los repositorios de Git.
- Los propietarios de repositorios se aseguran de que sean responsables de que se implementen políticas apropiadas en todas las contribuciones en materia de seguridad.
Principios de diseño
Los siguientes principios de diseño se aplican a este patrón, según los requisitos.
- Nunca almacene secretos en el código o la configuración.
- Escanear el código en busca de secretos y credenciales durante las confirmaciones de código
- Habilitar la autenticación multifactor para los colaboradores cuando esté disponible
- Validar cualquier aplicación de cliente o de terceros que solicite acceso
- Agregue pruebas de seguridad en sus pipelines de CI/CD para detectar vulnerabilidades
- Rote periódicamente las credenciales, como claves SSH y tokens de acceso, utilizadas por los desarrolladores.
- Mantener límites de confianza y políticas de acceso claramente separados entre los repositorios GIT públicos y privados
Modelo de amenazas y vectores reales
Esta arquitectura analiza más de una docena de amenazas, y créeme, todas las he visto explotadas en ambientes reales. Algunas críticas que vale la pena destacar:
- TE-09: Fugas accidentales de secretos. En cada pentest donde tengo acceso al repo, lo primero que corro es un escaneo de .env, config.js, settings.py, secrets.json… y bingo.
- TE-14: Errores en procesos de desarrollo. Cuando el flujo de trabajo no está bien definido, los errores vuelven a aparecer en branches que deberían estar bloqueadas. La seguridad sin control de flujo es humo.
- TE-31: Commits maliciosos intencionales. El insider con acceso a main puede arruinarte un release entero con una sola línea. Y esto no es paranoia: ha pasado muchas veces, y la mayoría ni siquiera lo detecta.
- TE-37: Accesos no autorizados y exfiltración. Repos públicos con secretos, tokens, o datos de clientes por error. Cuando escaneás GitHub con dorks avanzados, lo encontrás.
Estas amenazas están alineadas con objetivos concretos de control, basados en los estándares más fuertes del sector (NIST, OWASP, CIS, etc.). Cada uno de estos eventos está mapeado a controles específicos que ayudan a mitigar, detectar y responder antes de que sea tarde.
Patrón de seguridad
Vista de patrones: gestión del código fuente
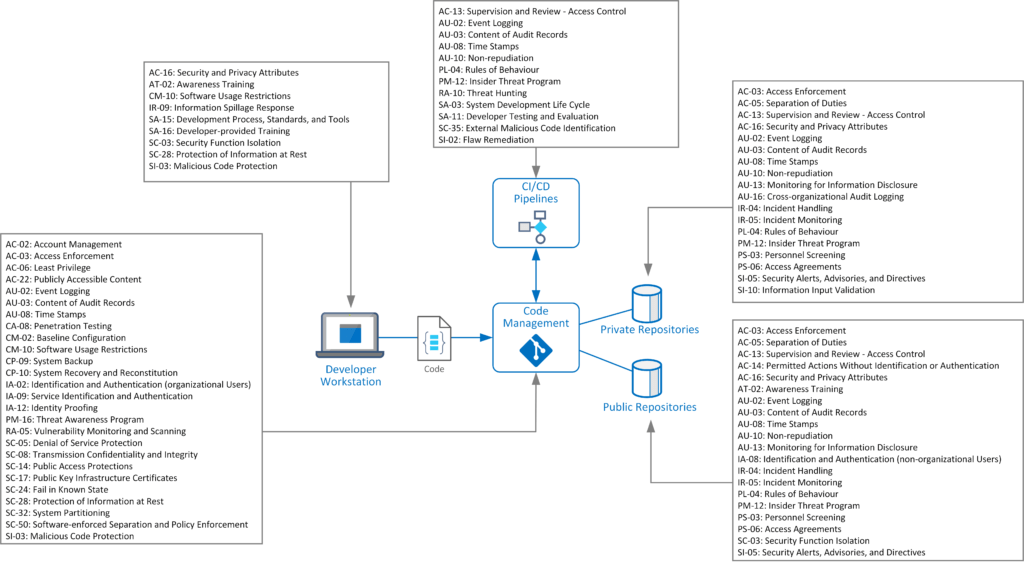
Integración con flujos de trabajo reales
Una de las claves del patrón es que no rompe la agilidad, pero sí introduce seguridad en cada fase. El diseño soporta flujos simples y complejos (con múltiples ramas, forks, PRs, etc.), y propone controles adaptativos según:
- La fase (desarrollo, testing, producción).
- El tipo de contribuyente (interno, externo, temporal).
- El tipo de repo (público o privado).
- El acceso (sólo lectura, escritura, fusión).
Por ejemplo, para los repositorios públicos, se fuerza:
- Registro de auditoría completo.
- Análisis de secretos en cada commit.
- Confirmaciones firmadas.
- Control de acceso granular con 2FA obligatorio.
Y para los privados:
- Supervisión de ramas sensibles.
- Evaluación continua de código para detectar insiders maliciosos.
- Gestión de acceso temporal con expiración automática.
Controles técnicos alineados a amenazas
Los controles están divididos por dominio, y son muy precisos. Algunos que uso y recomiendo siempre:
- AC-06: Privilegio mínimo. Todo lo que no sea explícitamente permitido, está prohibido. No hay espacio para “accesos por si acaso”.
- AU-10: No repudio. Confirmaciones firmadas digitalmente. Sin esto, no hay trazabilidad real.
- SC-28: Cifrado en reposo. Obligatorio. Tus backups no valen nada si están en texto plano.
- SC-03: Separación de funciones. Seguridad y desarrollo no pueden ser la misma persona. Jamás.
- IR-04: Manejo de incidentes. Si se detecta una clave expuesta, no hay debate: se revoca, se rota y se audita.
Automatización y DevSecOps real
Lo interesante de este patrón es que integra seguridad en la pipeline de CI/CD:
- Scans automáticos de secretos (como truffleHog).
- Validación de commits con GPG.
- Análisis estático y dinámico antes de permitir una fusión.
- Escaneo de dependencias (SCA).
- Honeypots de secretos para detectar comportamientos anómalos.
Además, incluye controles en estaciones de trabajo y en CI/CD para garantizar que todo el ecosistema está protegido. No solo el servidor Git. Esa es una visión moderna y robusta.
Roles y responsabilidades claras
Otro punto fuerte es la definición de roles:
- Propietarios del repo tienen responsabilidad completa, y deben aprobar políticas de seguridad.
- Colaboradores confiables tienen permisos limitados según su función.
- Acceso temporal para terceros con expiración automática.
- Usuarios anónimos solo en lectura y solo cuando está explícitamente permitido.
Esto no es burocracia: es control real. Es saber en cada momento quién tiene acceso, a qué, y por qué.
En un entorno donde cada línea de código puede tener consecuencias de millones de dólares, no hay lugar para “la seguridad después”. La gestión del código fuente es la columna vertebral de toda la cadena de suministro de software. Este patrón representa uno de los enfoques más completos que he visto: mapea amenazas reales, propone controles tangibles, y se adapta a la dinámica moderna del desarrollo. Pero como hacker te lo digo claro: nada de esto sirve si no se implementa, si no se automatiza, y si no hay una cultura que respalde estos principios. La herramienta sola no te salva. El mindset sí.
Si estás armando tu modelo de seguridad para gestión de código, este patrón es el blueprint que tenés que seguir. Y si querés llevarlo al siguiente nivel, agregale threat hunting, detección de anomalías con IA, o zero trust en pipelines.
Pero el primer paso es simple: hacé que el código sea seguro desde el momento en que alguien lo escribe.
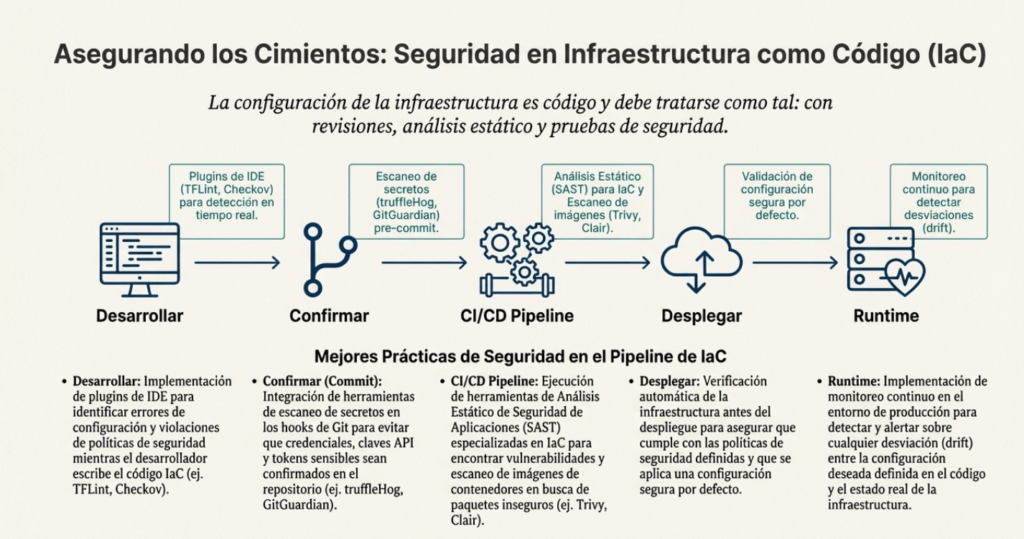
A06:2025 – Diseño Inseguro (Insecure Design)
En 2025, Diseño Inseguro baja del puesto #4 al #6, pero no porque el riesgo haya disminuido, sino porque la industria ha avanzado en modelado de amenazas y arquitecturas seguras.
A06 abarca todo fallo conceptual, no de implementación: lógica de negocio débil, flujos mal pensados, ausencia de reglas, permisos mal definidos, validaciones que “nunca se diseñaron”, arquitecturas que permiten abuso, etc.
No es un bug: es una mala decisión de arquitectura o lógica.
🧩 Ejemplos típicos (2025)
- Flujos que permiten saltarse pasos importantes (ej: completar un pago sin validar fondos).
- Falta de límites o controles de tasa (rate limiting).
- APIs que asumen “que nadie probara eso”.
- Reglas de negocio mal diseñadas (ej: modificar saldo vía API “de prueba”).
- Operaciones críticas sin MFA ni reconfirmación.
- Falta de separación de roles en acciones sensibles.
- Lógica inconsistente: un endpoint valida, otro no.
- Funciones críticas accesibles sin validación secundaria.
- No considerar abuso de funciones legítimas (Business Logic Abuse).
- Sistemas de workflow donde se puede cambiar de estado sin permisos.
- Endpoint que permite subir cualquier archivo sin analizar su tipo real.
🔍 Mini-guía de explotación (Pentesting 2025)
- Entender la lógica del negocio. Todo está ahí.
- Buscar qué pasa si haces lo “incorrecto”:
- saltar pasos
- repetir pasos
- invertir flujos
- mandar parámetros faltantes
- Manipular estados (“pending” → “approved”).
- Repetir operaciones idempotentes para duplicar efectos.
- Abusar funciones legítimas (pago parcial múltiples veces).
- Ver inconsistencias entre endpoints / políticas.
- Probar race conditions: simultaneidad y doble-gasto.
- Manipular permisos en objetos críticos.
- Cargar archivos y manipular extensiones.
- Buscar falta de MFA o reconfirmación en operaciones críticas.
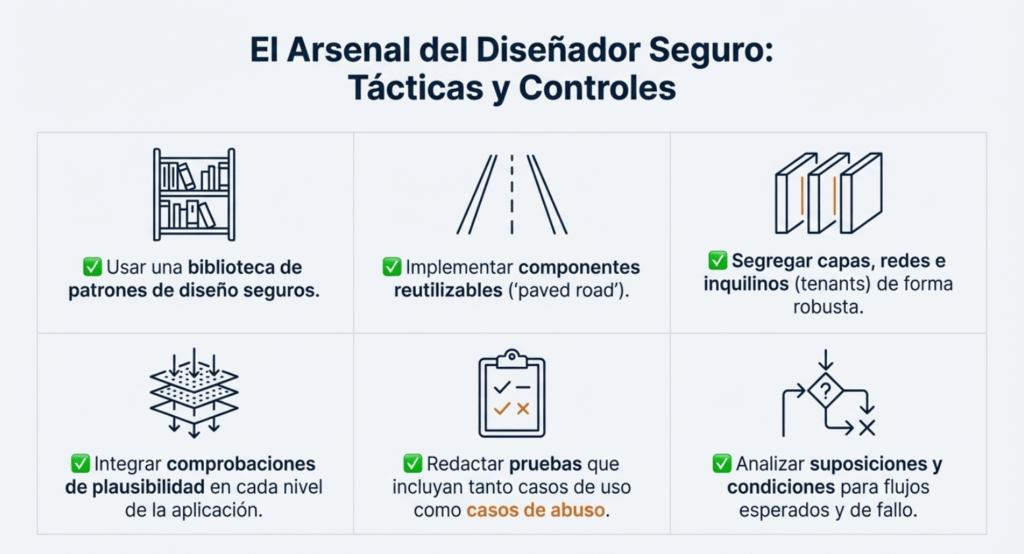
🎯 Consecuencias
- Fraude financiero (pagos duplicados, manipulación de saldos).
- Acceso indebido a acciones críticas o peligrosas.
- Manipulación de procesos internos.
- Saltos de flujo que permiten bypass de reglas de seguridad.
- Modificación de estados sin autorización.
- Creación de cuentas privilegiadas.
- Explotación de falta de rate-limiting → DoS o fuerza bruta.
- Abuso funcional sin explotar bugs técnicos.
- Exfiltración mediante flujos de trabajo débiles.
🛡 Defensas modernas (2025)
- Threat Modeling obligatorio (STRIDE, PASTA, LINDDUN) antes de escribir código.
- Documentar reglas de negocio y flujos completos.
- Validar estado/flujo en cada endpoint.
- Rate limiting / anti-automation en funciones críticas.
- Revisión de lógica de negocio por equipos mixtos (Dev + QA + AppSec).
- MFA para operaciones sensibles.
- Checks de autorización por estado (no solo por rol).
- Pruebas automáticas de flujos críticos.
- Asegurar consistencia entre endpoints que hacen lo mismo.
- Seguridad por diseño: “Si no está prohibido explícitamente, estará permitido accidentalmente.”
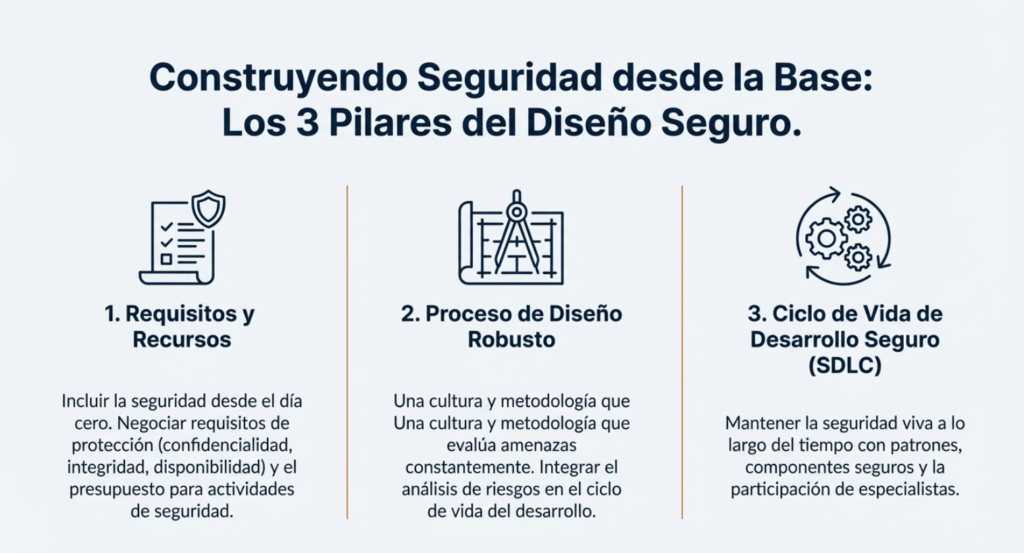
📚 Subtipos / Patrones modernos (2025)
| Subtipo / patrón | Definición | Ejemplo bancario | Pentesting (qué probar) | Ataque / PoC | Consecuencia | Defensa | Tips examen |
| Business Logic Abuse | Abusar funciones legítimas | Transferir $0.01 infinitas veces | Probar multi-acciones | Duplicar transacciones | Fraude | Validación de reglas | “No es bug técnico” |
| Missing Step Validation | Falta validar etapas | Saltar validación de saldo | Saltar pasos | Pago sin fondos | Pérdida $ | Validaciones por estado | Buscar flujos incompletos |
| Role/State Mismatch | Permisos por estado mal definidos | Aprobación de crédito sin rol | Cambiar estado | Forzar “approved” | Autorización rota | RBAC + ABAC | Mirar estados JSON |
| Weak MFA on critical ops | Sin MFA en funciones críticas | Cambiar CBU sin revalidación | Probar sin MFA | Secuestrar cuentas | Modificación crítica | MFA contextual | MFA en cambios clave |
| Workflow Manipulation | Cambiar estado vía API | Ticket pasa a “closed” sin permiso | Mandar PATCH | Saltar proceso | Manipulación interna | Validar transición | “Pending → approved = fallo” |
| Lógica inconsistente | Un endpoint valida, otro no | /v1/pay valida, /v1/pay2 no | Comparar endpoints | Bypass | Fraude | Uniformidad | Revisar versiones API |
| File Upload without rules | Subida sin controles | Cargar ejecutable renombrado | Cambiar MIME/ext | RCE/DoS | Toma de server | Validación MIME | Buscar upload “libre” |
| Rate Limit inexistente | No limitar solicitudes | Intentos ilimitados login | Fuerza bruta | ATO | Lockout/rate limit | “Si no hay límites → inseguro” | |
| Race Condition | Condición de carrera | Doble transferencia | Flood simultáneo | Doble gasto | Pérdidas $ | Locks transaccionales | Probar varias requests |
| Insecure Defaults in Design | Suposiciones erróneas | API abierta “para testing” | Revisar config | Acceso excesivo | Exposición | Diseño seguro | “Default = deny” |
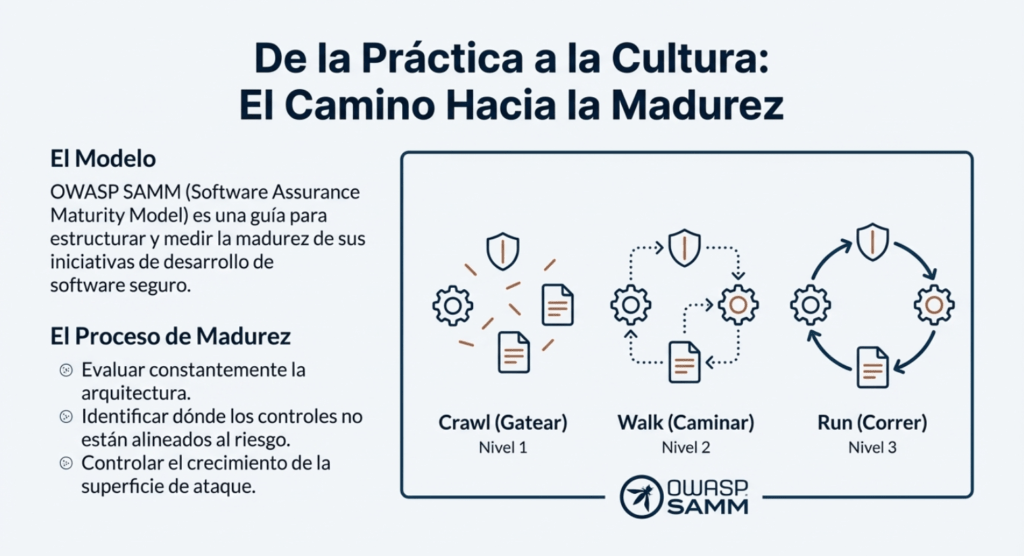
🧪 Checklist rápida de pentesting A06:2025
- Analizar flujos completos (inicio → fin).
- Probar saltar etapas.
- Probar revertir etapas.
- Probar repetir etapas.
- Probar endpoints alternativos para misma acción.
- Testear race conditions.
- Testear rate limiting.
- Testear abusos funcionales.
- Revisar consistencia entre roles, estados y acciones.
- Revisar validación de estado en endpoints críticos.
- Abuse de workflows: transiciones ilegales de estado.
🧾 Resumen ejecutivo para cursos
A06:2025 Diseño Inseguro engloba fallas que no provienen de errores de programación sino de decisiones de arquitectura, lógica de negocio o flujos mal definidos. Es un problema estructural que permite fraude, saltos de lógica, manipulación de estados, abusos funcionales y acceso a operaciones críticas sin controles adecuados. Prevenirlo requiere modelado de amenazas desde el inicio, validación estricta de flujos, controles por estado, MFA contextual, consistencia en endpoints y limitación de abuso funcional. Esta categoría refleja que el software moderno no se quiebra solo por bugs, sino por malas decisiones conceptuales.
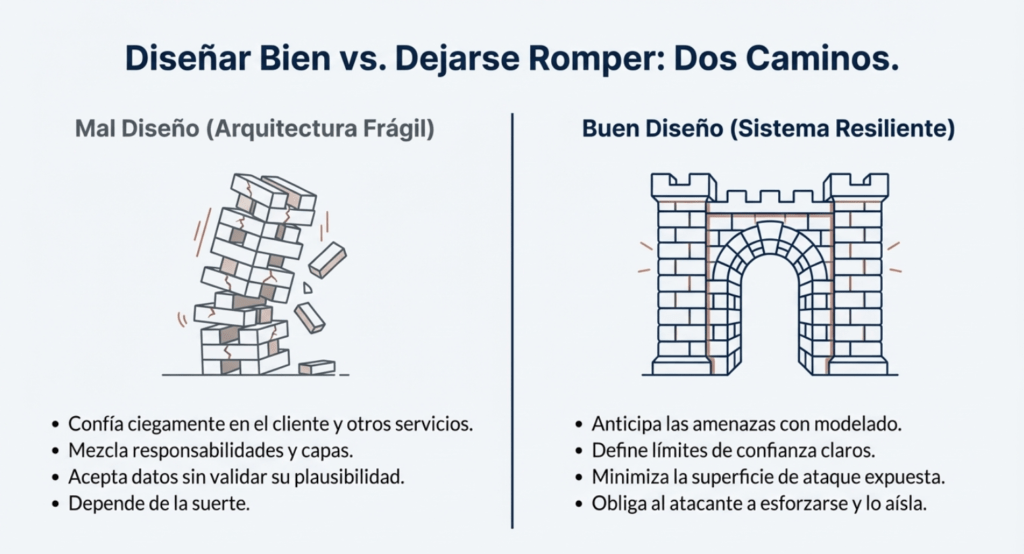
Preguntas
¿Qué ocurre si un banco permite transferencias de cualquier monto sin límite ni validación adicional? Insecure Design por falta de reglas de negocio y controles en operaciones críticas.
¿Qué vulnerabilidad existe si el sistema de banca online permite recuperar la contraseña solo con DNI y fecha de nacimiento? Insecure Design en el flujo de recuperación de credenciales (proceso inseguro).
¿Qué ocurre si el login no requiere multifactor y solo pide usuario y contraseña? Insecure Design por falta de autenticación fuerte (MFA).
¿Qué falla de diseño existe si no hay rate-limiting en los intentos de login? Insecure Design, porque el sistema no prevé ataques de fuerza bruta.
¿Qué pasa si un mismo empleado puede iniciar y aprobar una transferencia sin revisión de otro rol? Insecure Design por falta de segregación de funciones (SoD).
¿Qué vulnerabilidad ocurre si la aplicación bancaria acepta montos en un campo del cliente y no valida integridad en el servidor? Insecure Design (falta de validación de integridad de datos).
¿Qué ocurre si un banco no tiene previsto un control adicional (OTP o token) en operaciones de alto riesgo? Insecure Design por falta de protección en transacciones críticas.
¿Qué vulnerabilidad hay si un sistema de banca móvil no considera la posibilidad de ataques automatizados por bots?Insecure Design (falta de protección contra abuso automatizado).
¿Qué pasa si la aplicación no incluye validaciones para detectar comportamientos anómalos en transacciones (ej. transferencias repetitivas sospechosas)? Insecure Design por ausencia de detección de fraude en la lógica de negocio.
¿Qué ocurre si un sistema de transferencias permite modificar datos de una operación (monto, destino) sin controles de integridad?Insecure Design (falta de validación de integridad y consistencia en procesos críticos).
¿Qué vulnerabilidad existe si no se define un flujo seguro para cierre de sesión, quedando sesiones activas indefinidamente? Insecure Design por falta de manejo seguro de sesión en el diseño.
¿Cuál es la diferencia entre Insecure Design y Broken Access Control? Insecure Design = los controles nunca se pensaron o se diseñaron mal; Broken Access Control = los controles existen pero están mal implementados.
¿Qué ocurre si un sistema bancario depende solo de validaciones en el cliente (JavaScript) y no en el servidor? Insecure Design, porque el diseño confía en el cliente en lugar del backend.
¿Qué falla hay si un banco no prevé límites diarios de transferencias por usuario? Insecure Design en reglas de negocio financieras.
¿Qué ocurre si la aplicación bancaria no prevé un plan de recuperación seguro de cuentas bloqueadas? Insecure Design en el proceso de recuperación.
¿Qué pasa si los procesos de auditoría no forman parte del diseño del sistema desde el inicio? Insecure Design por ausencia de trazabilidad y monitoreo en la arquitectura.
- Transferencias sin límite/validación adicional → falta de reglas de negocio seguras.
- Recuperar contraseña solo con datos triviales (DNI, fecha) → flujo de recuperación inseguro.
- Login sin MFA → diseño inseguro en autenticación.
- Login sin rate-limiting → no prever ataques de fuerza bruta.
- Empleado que puede iniciar y aprobar su propia transferencia → falta de segregación de funciones.
- Diferencia Insecure Design vs Broken Access Control → uno es falta de diseño, el otro es falla en implementación.
- “Solución adecuada” → siempre menciona diseño seguro desde el inicio (Secure by Design), threat modeling, MFA, rate limiting, segregación de roles, reglas de negocio fuertes.

¡Excelente trabajo!
Llegaste al final de un capítulo clave para tu formación como profesional de la seguridad y el desarrollo.
Ahora ya sabés:
- Qué significa realmente Insecure Design (A06) y por qué es un riesgo de raíz, no un simple bug.
- Cómo la evolución del OWASP Top 10 refleja la necesidad de pensar la seguridad desde la arquitectura.
- Qué decisiones de diseño —límites, flujos, reglas de negocio, validaciones, procesos críticos— pueden fortalecer o destruir la seguridad de una aplicación.
- Cómo crear diagramas de flujo de datos (DFD), definir límites de confianza y reconocer superficies de ataque.
- Cómo utilizar modelado de amenazas, desde STRIDE hasta PASTA o LINDDUN, para analizar tu sistema como lo haría un atacante.
- Cómo funcionan los patrones de seguridad, cómo se escriben y cómo se aplican realmente en proyectos Agile.
- Cómo documentar arquitecturas complejas como microservicios y prevenir fallas sistémicas.
- Cómo realizar una Evaluación Rápida de Riesgos (RRA) y entender el impacto real de las amenazas.
- Qué controles aplicar para construir productos seguros desde el primer día: autenticación fuerte, SoD, validación robusta, detección de abuso, MFA, rate limiting, diseño antifraude y más.
Aprendiste a ver la seguridad no como un agregado tardío, sino como un pilar fundamental del diseño.
Hoy entendés cómo anticiparte, planificar, modelar amenazas, reducir riesgos y crear sistemas resilientes que no dependen de la suerte, sino de decisiones de ingeniería bien fundamentadas. Este es el tipo de conocimiento que diferencia a un desarrollador… de un arquitecto seguro. Y que diferencia un software funcional… de un software confiable.
