En este capítulo, OWASP TOP 10 – A09:2025 Security Logging and Monitoring Failures, vas a adentrarte en uno de los pilares menos glamorosos pero más decisivos de toda la ciberseguridad moderna: la capacidad de ver lo que realmente está ocurriendo dentro de tus sistemas. No habla de una vulnerabilidad que permite entrar, sino de algo más peligroso: una falla que impide darte cuenta de que ya entraron.
En un entorno donde las aplicaciones se distribuyen en microservicios, contenedores, nubes públicas, APIs y SaaS, el registro y monitoreo es el sistema nervioso central de la plataforma. Sin él, operás a ciegas. Y en seguridad, estar ciego es estar comprometido, aunque todavía no lo sepas.
A lo largo del capítulo vas a comprender:
- Por qué la ausencia de logs completos y monitoreo activo convierte ataques triviales en brechas masivas prolongadas.
- Cómo una fuerza bruta, un fraude bancario o un movimiento lateral pueden ocurrir durante días sin que nadie lo detecte.
- Cómo piensan los atacantes: borrar trazas, saturar logs, manipularlos, explotarlos para obtener información sensible o inyectar contenido malicioso.
- Qué eventos deben registrarse realmente y cómo estructurar esos logs para auditoría, SIEM, correlación y análisis forense.
- El rol crítico de la integridad: cómo proteger logs contra borrado, edición, falsificación y manipulación interna.
- Por qué un log “Error” sin IP, usuario o timestamp no sirve absolutamente para nada.
- Cómo diseñar una arquitectura moderna de observabilidad: pipelines (ELK, Splunk, Datadog), alertas inteligentes, UEBA, honeytokens y playbooks.
- Cómo usar un vocabulario estandarizado de eventos de seguridad (authn, authz, sensitive_read, malicious, etc.) para lograr detección real, no intuición.
- Cómo probar este control desde pentesting: desde intentos de login fallidos que no se registran, hasta logs expuestos públicamente o sin monitoreo.
Este capítulo no trata sobre “loggear más”. Trata sobre loggear mejor, con propósito, con semántica, con integridad y con capacidad de reacción. Vas a aprender que el logging no es un agregado técnico: es una herramienta estratégica para detectar intrusiones, responder incidentes, cumplir regulaciones, investigar brechas y proteger tu infraestructura.
En seguridad, la pregunta no es si te van a atacar. La pregunta es:cuando ocurra, ¿vas a enterarte a tiempo?
A09 te da la respuesta técnica y conceptual para que la respuesta sea “sí”.
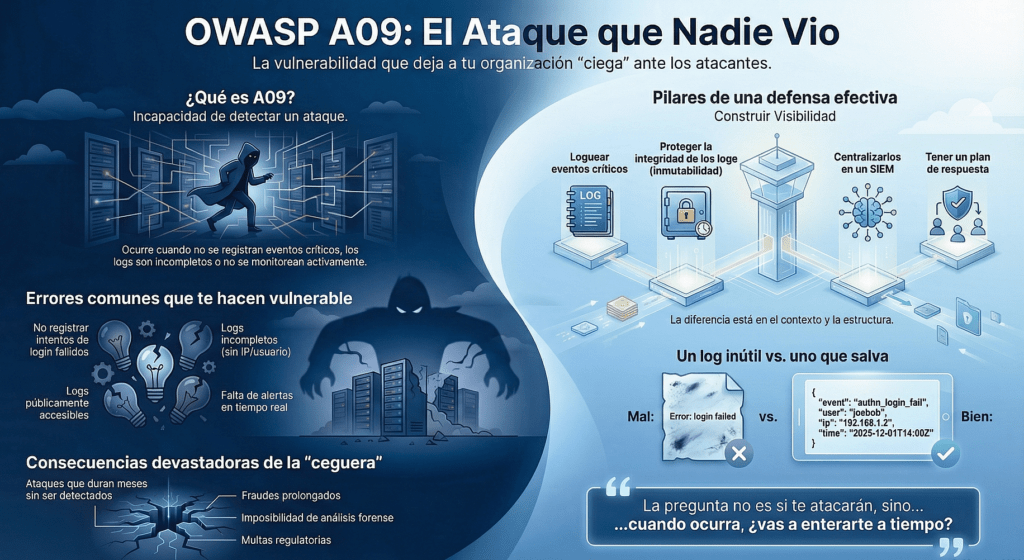
Fallos de Registro y Monitoreo de Seguridad (A09)
Una de las diferencias más brutales entre una arquitectura madura y un sistema que parece seguro pero está ciego es esta: el sistema sí habló… pero nadie lo escuchó. Bienvenido a A09, el tipo de vulnerabilidad que no impide un ataque, pero que decide si alguna vez lo vas a detectar. Y si no lo hacés a tiempo, el costo puede ser devastador.
Las Fallas de Registro y Monitoreo no son errores técnicos aislados. Son fallas culturales. Son consecuencia de pensar que el logging es para developers y no para seguridad. Que el monitoreo es algo que se ve “más adelante”. Que si algo explota, después se ve. Pero cuando llega ese después, ya tenés cuentas vaciadas, información filtrada y ningún rastro confiable de qué ocurrió, cuándo ni cómo.
El Ataque Que Nadie Vio
Un atacante no necesita vulnerar tu aplicación si puede borrar sus huellas. Si después de hacer login con credenciales robadas no hay logs. Si puede acceder a /logs/app.log desde el navegador. Si fuerza 1000 intentos de login y no hay ni una alerta. Eso es A09. Y en seguridad ofensiva, eso es territorio libre para moverse sin miedo.
Esta categoría es brutal porque actúa en silencio. En muchos entornos financieros, sanitarios o corporativos, los registros están, pero son superficiales. Los logs muestran «Error» sin IP, sin usuario, sin contexto. O peor: se registran cosas sensibles como contraseñas, tokens o PII… en texto plano. ¿El resultado? Ni podés defenderte, ni podés explicar qué pasó. El incidente existe, pero la trazabilidad no.
¿Por qué A09 es tan crítico?
Porque el registro y el monitoreo son los únicos sensores internos que tenés para saber si algo raro pasa. No se trata solo de “guardar logs”. Se trata de que esos logs:
- Sean detallados (quién, qué, cuándo, desde dónde).
- Sean seguros (inalterables, protegidos, centralizados).
- Sean accionables (alimenten alertas reales, no falsas positivas).
- Sean persistentes (cumplan políticas regulatorias como PCI, GDPR, HIPAA).
- Sean estructurados (formato JSON o similar, con metadatos clave).
- Estén correlacionados (mismo formato en todos los servicios, trazabilidad global).
Si no hacés todo eso, estás construyendo sistemas sordos, mudos y ciegos.
Cómo se explota A09 (desde el lado ofensivo)
Como pentester, sabés que A09 es una mina de oro:
- Fuerza un login fallido. ¿Queda log? ¿Alerta?
- Accedé a /logs/. ¿Hay archivos públicos?
- Hacé un ataque lento (password spraying). ¿Nadie lo detecta?
- ¿Podés borrar logs desde un usuario común? ¿Modificar registros?
- Iniciá sesiones desde múltiples países. ¿Hay detección de viajes imposibles?
- Usá un token revocado. ¿Genera log o alerta crítica?
- ¿El SIEM está integrado? ¿O los logs mueren localmente?
Si nada de eso genera respuesta, A09 está más que presente. Y si atacás, podés operar por días o semanas sin que nadie lo note. O peor, sin que después puedan probar lo que hiciste.
El lenguaje secreto del sistema: logs bien hechos
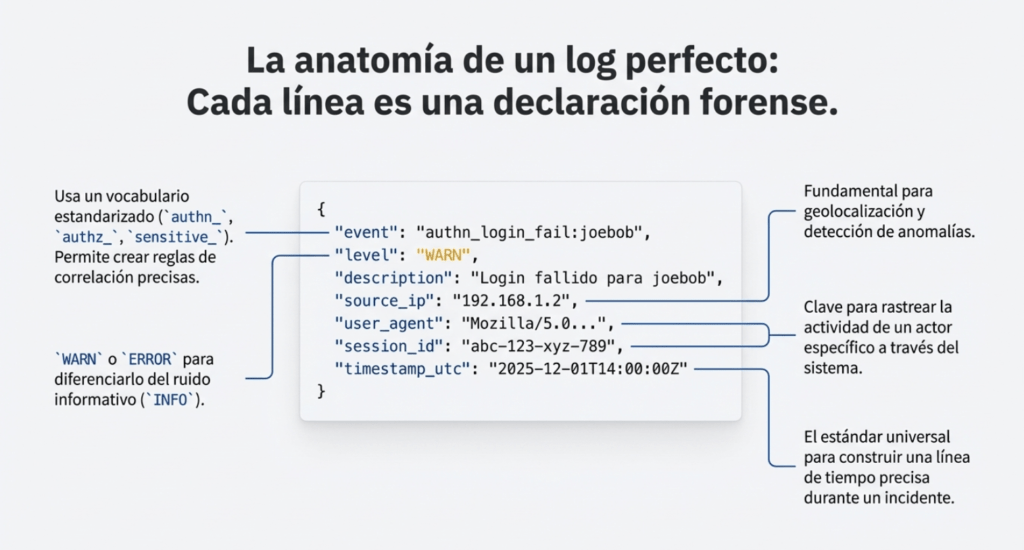
El verdadero poder está en darle estructura al caos. Usar un vocabulario común para loguear eventos críticos cambia todo. Ejemplo:
{ «event»: «authn_login_fail:joebob», «level»: «WARN», «description»: «Login fallido para joebob», «ip»: «192.168.1.2», «time»: «2025-12-01T14:00:00Z» }
Ese evento, combinado con otros similares, puede activar una alerta de fuerza bruta. Pero si el log fuera simplemente «Error: login failed», sin contexto, nadie puede hacer nada.
Estructurá tus eventos con prefijos claros: authn_, authz_, sensitive_, session_, input_validation_, malicious_. Y agregales metadata como timestamp UTC, IP, user-agent, ID de sesión, región cloud. Convertí cada línea de log en una declaración forense.
Los errores más comunes que te hacen vulnerable
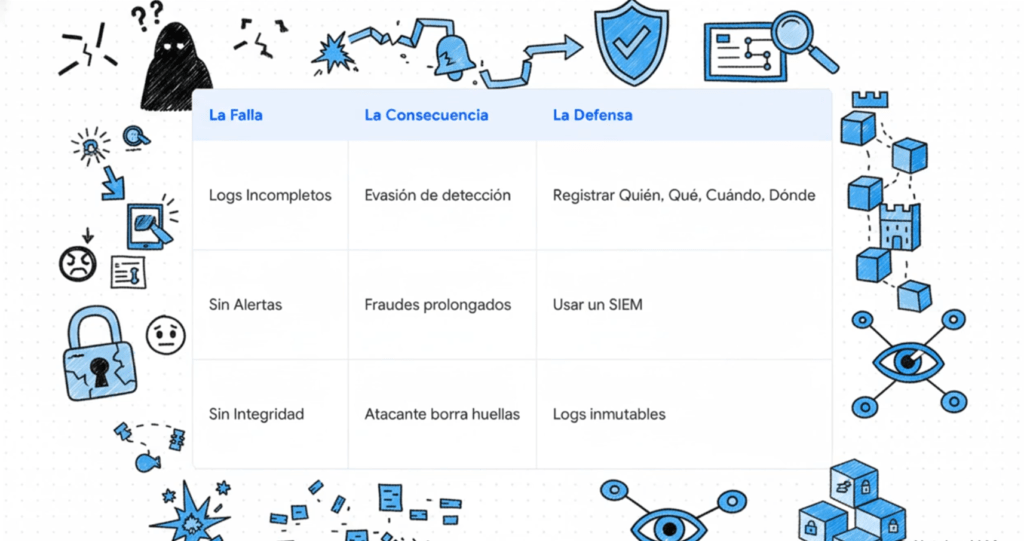
- No logueás fallos de login: sin esto, los ataques de fuerza bruta pasan sin ser vistos.
- Logs incompletos: sin IP, sin usuario, sin timestamp. ¿Quién, cuándo, desde dónde?
- Logs públicos: si /logs/ está abierto en producción, el atacante ve TODO.
- Sin integridad: logs editables = logs inútiles. Usá WORM, firmas digitales o almacenamiento inmutable.
- No tenés SIEM: logs que nadie lee = no existen. Sin alertas en tiempo real, no hay defensa activa.
- Falsos positivos: si todo genera alarma, nadie escucha nada. Ajustá umbrales, usá UEBA.
- No tenés plan de respuesta: ¿qué pasa si salta una alerta? ¿Quién actúa? ¿En cuánto tiempo?
El impacto real de no tenerlo
- Ataques prolongados sin detección.
- Fraudes que duran meses.
- Filtraciones de datos sin pruebas para defensa legal.
- Multas regulatorias por no retener logs o no tener trazabilidad.
- Imposibilidad de hacer análisis forense post-incidente.
- Pérdida total de confianza y reputación.
¿Cómo te blindás?
- Logueá todos los eventos críticos: login, logout, cambios de credenciales, transferencias, fallos de autorización.
- Protegé la integridad: logs inmutables, firmados, cifrados.
- Centralizá: todos los logs a un SIEM o sistema seguro.
- Alertas en tiempo real: detección de anomalías, token reuse, accesos sospechosos.
- Cumplí normativas: PCI exige 1 año mínimo de retención.
- Probá tu plan de respuesta: tabletop exercises, simulacros, detección real de ataques simulados.
- Evitá registrar información sensible (PII, contraseñas, tokens) sin protección.
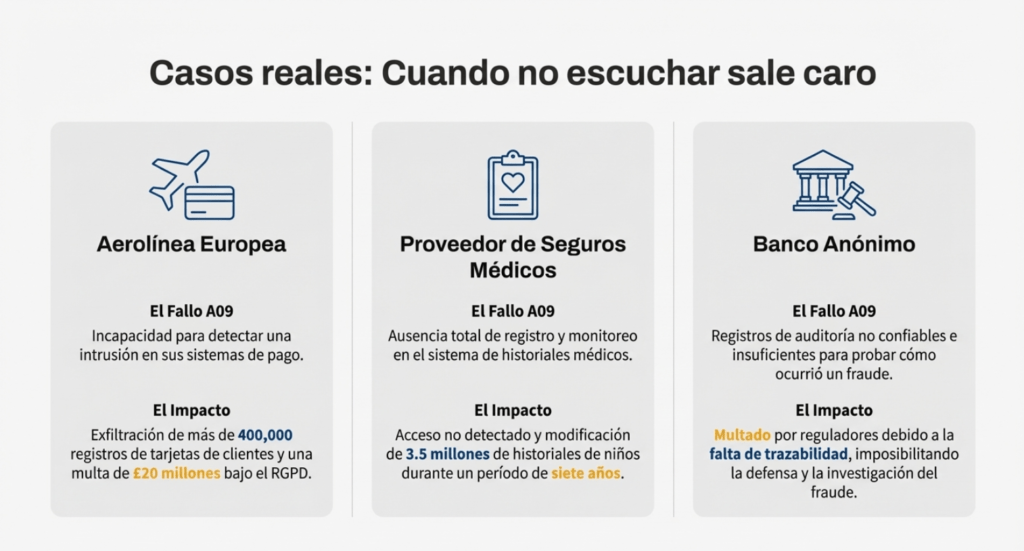
Casos reales: cuando no escuchar sale caro
Una aerolínea europea perdió 400.000 datos de tarjetas de clientes porque nadie detectó la intrusión. Otra almacenó historiales médicos sin monitoreo por 7 años. Un banco fue multado porque sus registros no eran confiables y no pudo probar cómo ocurrió un fraude. Todo por no tener registro y monitoreo de seguridad en condiciones.
Si no registrás, no monitoreás. Si no monitoreás, no detectás. Y si no detectás, estás expuesto.A09 no se trata de evitar ataques. Se trata de darte las herramientas para enterarte cuando ocurren, responder con rapidez, y reconstruir la historia con precisión quirúrgica. Sin logs bien hechos, no hay seguridad, no hay análisis, no hay defensa legal. La conciencia situacional es la habilidad de saber lo que pasa en tu sistema, en tiempo real. Y eso, solo se construye con registro seguro, monitoreo activo, alertas bien calibradas y un equipo que sepa leer la voz del sistema.
OWASP TOP 10
OWASP es popular por publicar el TOP 10 Owasp Web cada cuatro años. Este es un documento que lista los diez riesgos más críticos en aplicaciones web, con el objetivo de ayudar a las organizaciones a identificar y mitigar las vulnerabilidades asociadas con estos riesgos. https://owasp.org/Top10/es/ Cada uno de estos riesgos representa una debilidad común y significativa que a menudo se puede explotar para comprometer la seguridad de una aplicación web. OWASP proporciona información detallada sobre posibles vulnerabilidades y técnicas de ataque para cada riesgo.
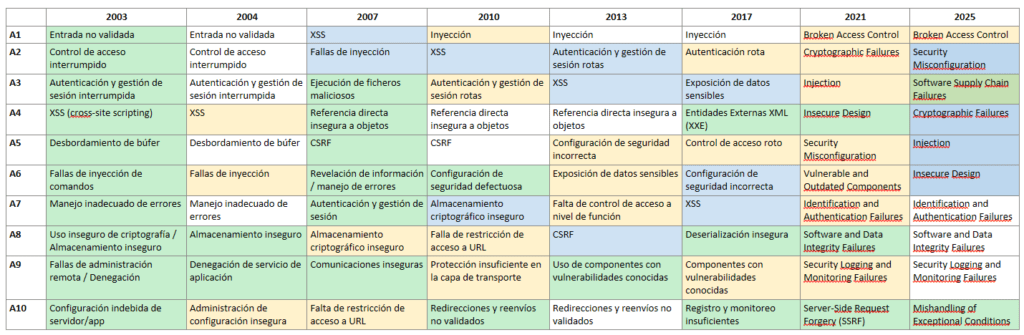
El Top 10 de OWASP es una lista que se actualiza periódicamente de los riesgos de seguridad de las aplicaciones web más críticos. Lo mantiene el Proyecto Abierto de Seguridad de Aplicaciones Web (OWASP), una organización sin fines de lucro centrada en mejorar la seguridad de las aplicaciones web. Sirve como una valiosa guía para que los desarrolladores, los expertos en pruebas de penetración de aplicaciones web y las organizaciones comprendan y prioricen los riesgos de seguridad comunes en las aplicaciones web.
El Top 10 de OWASP es una lista conocida de los diez riesgos de seguridad de aplicaciones web más críticos. Se actualiza periódicamente para garantizar que refleje el panorama actual de amenazas y los desafíos de seguridad en constante evolución que enfrentan las aplicaciones web. La primera versión del Top 10 de OWASP se publicó en 2003. Su objetivo era crear conciencia sobre los riesgos comunes de seguridad de las aplicaciones web y ayudar a los desarrolladores a priorizar los esfuerzos de seguridad. La lista incluía riesgos como secuencias de comandos entre sitios (XSS), inyección de SQL y problemas de gestión de sesiones. Cada lanzamiento del Top 10 de OWASP se basa en las versiones anteriores, mejorando su precisión, relevancia y practicidad.

La evolución de A09:2025 – Security Logging and Monitoring Failures: el eslabón perdido de la seguridad operacional
De todas las categorías del OWASP Top 10, Security Logging and Monitoring Failures es probablemente la que más revela la distancia entre cómo las organizaciones imaginan la seguridad y cómo funciona realmente en la práctica. Mientras que las categorías clásicas como Injection, Broken Access Control o Fallos Criptográficos apuntan a vulnerabilidades técnicas, A09:2025 expone un problema mucho más profundo: la incapacidad de detectar, registrar y responder a los ataques antes de que sea demasiado tarde. Esta categoría, que parece menos “técnica” que las demás, es en realidad una de las principales responsables de que los ataques modernos tengan éxito.
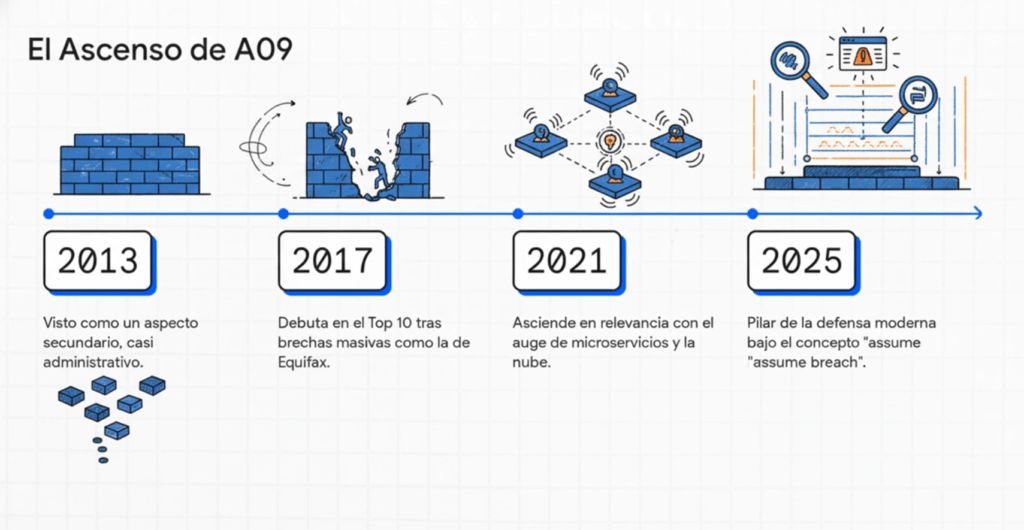
La historia de esta categoría dentro del OWASP Top 10 es interesante, porque no siempre estuvo presente como una vulnerabilidad independiente. Durante los primeros años (2003–2013), OWASP mencionaba la falta de logs y monitoreo dentro de otras categorías, especialmente en “Improper Error Handling” o en fallas generales de configuración. La industria veía el logging como un aspecto secundario, casi administrativo, sin comprender su impacto en la seguridad. Se asumía que si el código era seguro, el monitoreo era un bonus. Sin embargo, con el paso de los años, los incidentes demostraron que las brechas no se pueden prevenir completamente, y que la capacidad de detectarlas puede determinar si un ataque se convierte en un incidente menor o en un desastre.
Evolución de OWASP TOP 10
En el momento de crear este artículo coexiste las dos versiones 2021/2025.
⚪No cambia
🟡Fusionado
🔵Cambia de posición
🟢Nuevo
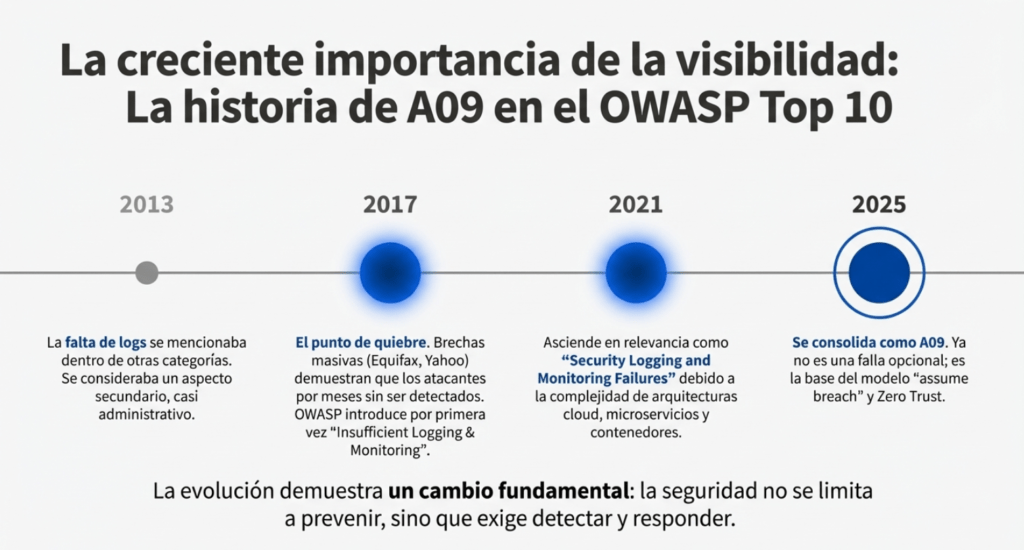
El punto de quiebre apareció alrededor de 2017, cuando grandes violaciones de seguridad —como las de Equifax, Yahoo, Uber y Marriott— revelaron que los atacantes estuvieron dentro de las redes durante meses sin ser detectados. Esto iluminó un problema crítico: no solo estaban explotando vulnerabilidades técnicas, sino que nadie los había detectado. Los logs eran incompletos, estaban mal configurados o simplemente no existían; los sistemas de monitoreo eran fragmentados, carecían de correlación o no tenían alertas efectivas. OWASP observó que las organizaciones no eran capaces de identificar ataques porque no tenían visibilidad del comportamiento anómalo dentro de sus sistemas.
Por eso, en OWASP Top 10 – 2017, se introdujo por primera vez la categoría “Insufficient Logging & Monitoring”. Aunque ocupaba el último puesto, su presencia era un reconocimiento explícito de que el monitoreo deficiente es un riesgo crítico. Representaba el comienzo de una nueva era en la seguridad de aplicaciones: la comprensión de que la seguridad no se limita a prevenir vulnerabilidades, sino también a detectarlas y responder a ellas. La categoría generó un impacto inmediato, ya que por primera vez se discutía abiertamente que la falta de logs también era una vulnerabilidad.
Con OWASP Top 10 – 2021, esta categoría regresó bajo el nombre “Security Logging and Monitoring Failures” y ascendió en relevancia. Esto se debió a que la industria adoptó arquitecturas complejas como microservicios, contenedores, orquestadores y cloud híbrido, donde los logs ya no estaban centralizados y donde la fragmentación hacía que el monitoreo fuera todavía más difícil. OWASP reconoció que, incluso con controles técnicos impecables, una organización puede sufrir brechas catastróficas si no detecta y responde a los ataques rápidamente. Además, el auge del ransomware entre 2020 y 2021 mostró que las organizaciones que no tenían detección temprana estaban condenadas a perder datos.
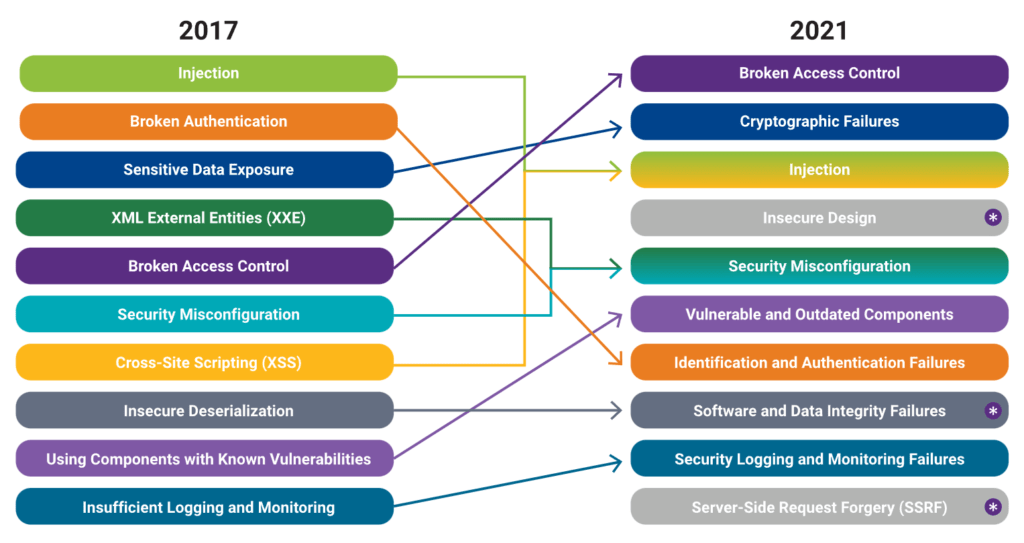
La evolución continúa con fuerza en OWASP Top 10 – 2025, donde esta categoría aparece como A09:2025, consolidando su importancia a pesar de la aparición de nuevas amenazas modernas. Aunque ocupa el noveno puesto, esto no refleja baja gravedad; por el contrario, significa que es una falla compleja, profunda y transversal a todas las demás. A09:2025 reconoce que las fallas de logging y monitoreo tienen un impacto directo en la capacidad de detectar, parar o mitigar ataques de:
- Inyección
- Acceso indebido
- SSRF
- Fallos criptográficos
- Fallos de diseño
- Vulnerabilidades en cadenas de suministro
- Movimientos laterales internos
- Ataques a APIs o microservicios
- Compromisos en pipelines CI/CD
El monitoreo deficiente convierte cada ataque técnico en un ataque exitoso.
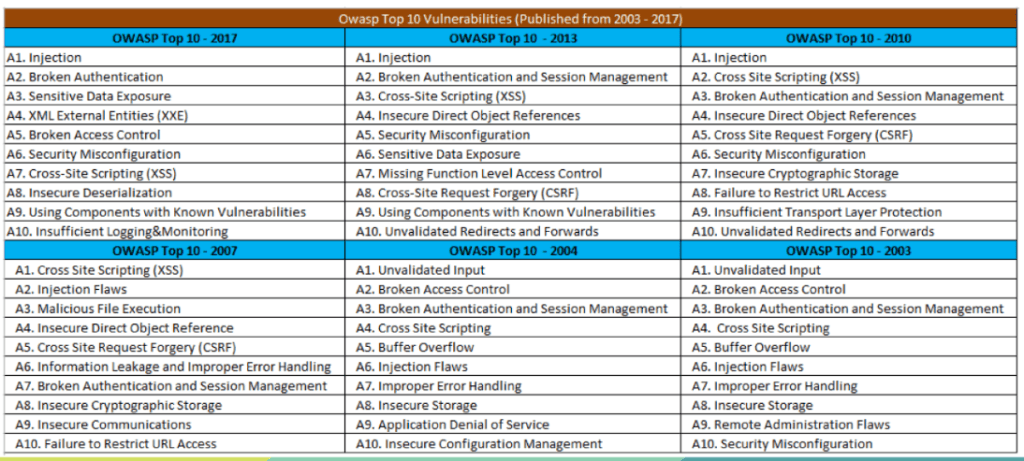
OWASP TOP 10 2021
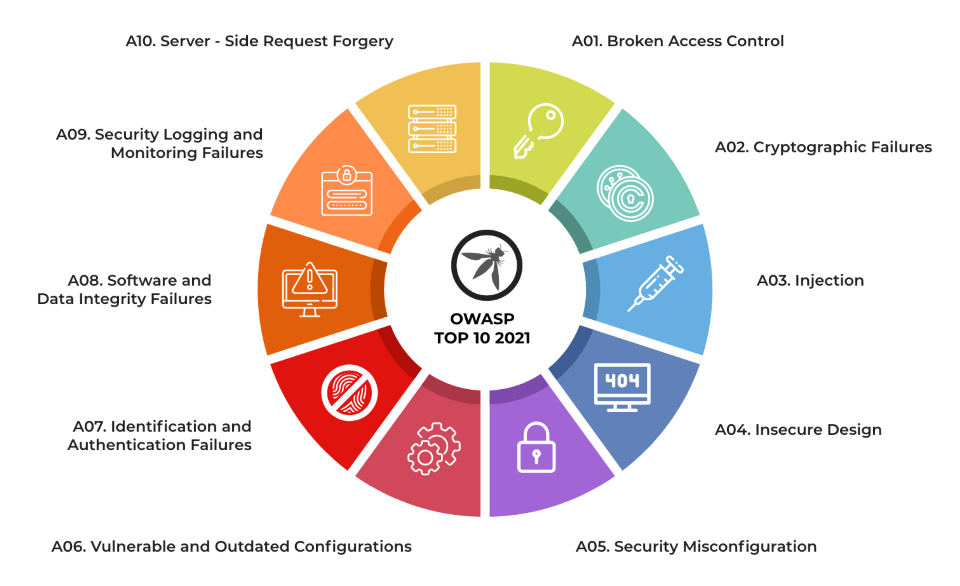
En la lista de los Diez Principales para 2025, se han incorporado dos categorías nuevas y una consolidada. Esta versión según OWASP está centrada en la causa raíz, más que en los síntomas, en la medida de lo posible. Dada la complejidad de la ingeniería y la seguridad del software, resulta prácticamente imposible crear diez categorías sin cierto grado de superposición.
Por qué esta categoría es tan crítica en 2025?
Porque la sofisticación actual de los atacantes supera ampliamente la velocidad de reacción de las organizaciones. Los ataques modernos ya no dependen solo de un exploit técnico, sino de permanecer invisibles el mayor tiempo posible. En un entorno donde los sistemas generan terabytes de logs por día, la falta de correlación, de alertas adecuadas y de visibilidad centralizada hace que los atacantes puedan moverse libremente dentro de una red sin ser detectados.
OWASP destaca que los fallos en esta categoría ocurren por:
- Logs incompletos o inexistentes
- Ausencia de registro en componentes críticos (auth, API, DB, admin)
- Logs generados pero no monitoreados
- Sistemas SIEM mal configurados o saturados
- Alertas inexistentes o demasiado ruidosas (alert fatigue)
- Falta de correlación entre eventos distribuidos
- Ausencia de monitoreo en microservicios y contenedores
- Falta de retención adecuada de logs
- Desconexión entre equipos de desarrollo y SOC
- No registrar casos de uso maliciosos (abuse cases)
En 2025, el ecosistema cloud agravó el problema: cada microservicio genera logs en un formato diferente, almacena información con semánticas distintas, y utiliza su propio agente de monitoreo. La falta de estandarización convierte al logging en un rompecabezas difícil de auditar.

El gran problema de A09: la visibilidad cero
Cuando una aplicación carece de logging adecuado, vive en la oscuridad. OWASP insiste en que una vulnerabilidad sin logging es una vulnerabilidad que se explotará sin que nadie lo note. Toda intrusión pasa por estas fases: exploración, explotación, pos-explotación, persistencia, movimiento lateral y exfiltración. Sin monitoreo, estas actividades quedan completamente invisibles.
A09:2025 es, en realidad, el síntoma de una falla aún más profunda:
la falta de una cultura de seguridad operacional.
Las organizaciones invierten millones en firewalls, WAFs y herramientas de análisis, pero descuidan los fundamentos: registrar, estandarizar, centralizar y reaccionar.
El futuro: el monitoreo como la columna vertebral de la defensa
OWASP deja claro que Security Logging and Monitoring Failures seguirá siendo una categoría crítica incluso en la próxima década. A medida que aumentan las arquitecturas distribuidas y los ataques impulsados por IA, la capacidad de detectar comportamientos anormales será más importante que nunca. En 2025, logging y monitoreo ya no son opcionales: son la base del modelo Zero Trust y del concepto de “assume breach”, donde las organizaciones aceptan que los atacantes eventualmente entrarán y deben detectarlos lo antes posible.
La evolución de A09:2025 – Security Logging and Monitoring Failures muestra que la seguridad no termina cuando se corrigen vulnerabilidades técnicas: recién empieza. La ausencia de logs y monitoreo convierte incluso pequeñas vulnerabilidades en desastres. Esta categoría, que alguna vez fue vista como un aspecto secundario, hoy es fundamental para cualquier estrategia de defensa moderna. Sin visibilidad, no hay seguridad.
A09:2025 Errores de registro y alertas
Los fallos de registro y alertas mantienen su puesto número 9. Esta categoría ha cambiado ligeramente de nombre para enfatizar la función de alerta necesaria para inducir la acción sobre eventos de registro relevantes. Esta categoría siempre estará subrepresentada en los datos y, por tercera vez, ha sido incluida en la lista por los participantes de la encuesta de la comunidad. Esta categoría es extremadamente difícil de probar y tiene una representación mínima en los datos de CVE/CVSS (solo 723 CVE); sin embargo, puede tener un gran impacto en la visibilidad, las alertas de incidentes y el análisis forense. Esta categoría incluye problemas con la correcta gestión de la codificación de salida a archivos de registro (CWE-117), la inserción de datos confidenciales en archivos de registro (CWE-532) y el registro insuficiente (CWE-778).
Tabla de puntuación.
| CWE mapeados | Tasa máxima de incidencia | Tasa de incidencia promedio | Cobertura máxima | Cobertura promedio | Exploit ponderado promedio | Impacto ponderado promedio | Total de ocurrencias | Total de CVEs |
| 5 | 11,33% | 3,91% | 85,96% | 46,48% | 7.19 | 2.65 | 260.288 | 723 |
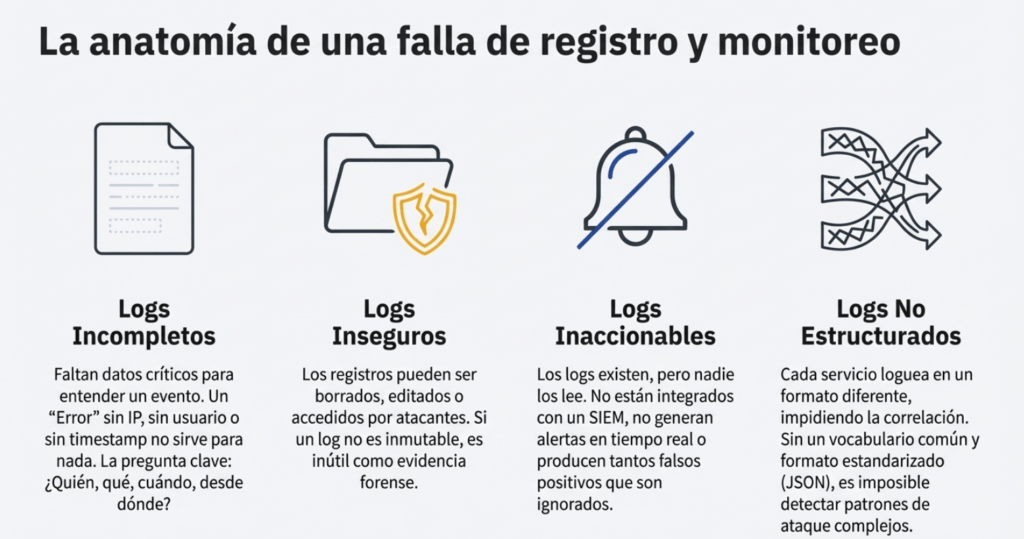
Descripción.
Sin registro ni monitorización, no se pueden detectar ataques ni infracciones, y sin alertas es muy difícil responder con rapidez y eficacia ante un incidente de seguridad. La insuficiencia de registro, monitorización continua, detección y alertas para iniciar respuestas activas ocurre en cualquier momento:
- Los eventos auditables, como inicios de sesión, inicios de sesión fallidos y transacciones de alto valor, no se registran o se registran de manera inconsistente (por ejemplo, solo se registran los inicios de sesión exitosos, pero no los intentos fallidos).
- Las advertencias y los errores no generan mensajes de registro, estos son inadecuados o poco claros.
- La integridad de los registros no está protegida adecuadamente contra manipulaciones.
- Los registros de aplicaciones y API no se monitorean para detectar actividad sospechosa.
- Los registros solo se almacenan localmente y no se realizan copias de seguridad adecuadas.
- No se han establecido umbrales de alerta adecuados ni se han implementado procesos de escalamiento de respuestas eficaces. Las alertas no se reciben ni se revisan en un plazo razonable.
- Las pruebas de penetración y los análisis realizados mediante herramientas de pruebas de seguridad de aplicaciones dinámicas (DAST) (como Burp o ZAP) no activan alertas.
- La aplicación no puede detectar, escalar ni alertar sobre ataques activos en tiempo real o casi en tiempo real.
- Usted es vulnerable a la fuga de información confidencial si hace que los eventos de registro y alerta sean visibles para un usuario o un atacante (consulte A01:2025-Broken Access Control ) o si registra información confidencial que no debería registrarse (como PII o PHI).
- Usted es vulnerable a inyecciones o ataques a los sistemas de registro o monitoreo si los datos de registro no están codificados correctamente.
- La aplicación no detecta o no gestiona correctamente los errores y otras condiciones excepcionales, por lo que el sistema no sabe que hubo un error y, por lo tanto, no puede registrar que hubo un problema.
- Faltan ‘casos de uso’ adecuados para emitir alertas o están desactualizados para reconocer una situación especial.
- Demasiadas alertas falsas positivas hacen que sea imposible distinguir las alertas importantes de las que no lo son, y como resultado, se las reconoce demasiado tarde o no se las reconoce en absoluto (sobrecarga física del equipo SOC).
- Las alertas detectadas no se pueden procesar correctamente porque el manual para el caso de uso está incompleto, desactualizado o falta.
Cómo prevenir.
Los desarrolladores deben implementar algunos o todos los siguientes controles, según el riesgo de la aplicación:
- Asegúrese de que todos los fallos de inicio de sesión, control de acceso y validación de entrada del lado del servidor se puedan registrar con suficiente contexto de usuario para identificar cuentas sospechosas o maliciosas y se puedan conservar durante el tiempo suficiente para permitir un análisis forense retrasado.
- Asegúrese de que cada parte de su aplicación que contenga un control de seguridad quede registrada, independientemente de si tiene éxito o falla.
- Asegúrese de que los registros se generen en un formato que las soluciones de gestión de registros puedan consumir fácilmente.
- Asegúrese de que los datos de registro estén codificados correctamente para evitar inyecciones o ataques a los sistemas de registro o monitoreo.
- Asegúrese de que todas las transacciones tengan un registro de auditoría con controles de integridad para evitar la manipulación o eliminación, como tablas de bases de datos de solo anexión o similares.
- Asegúrese de que todas las transacciones que generen un error se reviertan y se reinicien. Siempre se cierran con error.
- Si su aplicación o sus usuarios se comportan de forma sospechosa, emita una alerta. Cree una guía para sus desarrolladores sobre este tema para que puedan codificar en consecuencia o adquirir un sistema para ello.
- Los equipos de seguridad y DevSecOps deben establecer casos de uso de monitoreo y alerta efectivos, incluidos manuales de estrategias, de modo que el equipo del Centro de Operaciones de Seguridad (SOC) detecte y responda rápidamente a las actividades sospechosas.
- Agregue «honeytokens» como trampas para atacantes en su aplicación, por ejemplo, en la base de datos, como identidades de usuario reales o técnicas. Dado que no se utilizan en la actividad empresarial habitual, cualquier acceso genera datos de registro que pueden alertarse con casi ningún falso positivo.
- El análisis del comportamiento y el soporte de IA podrían ser opcionalmente una técnica adicional para respaldar tasas bajas de falsos positivos en las alertas.
- Establezca o adopte un plan de respuesta y recuperación ante incidentes, como el del Instituto Nacional de Estándares y Tecnología (NIST) 800-61r2 o posterior. Enseñe a sus desarrolladores de software cómo se presentan los ataques e incidentes de aplicaciones para que puedan reportarlos.
Existen productos comerciales y de código abierto para la protección de aplicaciones, como el conjunto de reglas básicas de OWASP ModSecurity, y software de correlación de registros de código abierto, como Elasticsearch, Logstash y Kibana (ELK), que incluyen paneles de control personalizados y alertas que pueden ayudarle a combatir estos problemas. También existen herramientas comerciales de observabilidad que pueden ayudarle a responder o bloquear ataques prácticamente en tiempo real.
Ejemplos de escenarios de ataque.
Escenario n.° 1: El operador del sitio web de un proveedor de seguros médicos infantiles no pudo detectar una filtración debido a la falta de monitoreo y registro. Un tercero informó al proveedor de seguros médicos que un atacante había accedido y modificado miles de historiales médicos confidenciales de más de 3,5 millones de niños. Una revisión posterior al incidente reveló que los desarrolladores del sitio web no habían abordado vulnerabilidades significativas. Al no existir registro ni monitoreo del sistema, la filtración de datos podría haber estado ocurriendo desde 2013, un período de más de siete años.
Escenario n.° 2: Una importante aerolínea india sufrió una filtración de datos que afectó a más de diez años de datos personales de millones de pasajeros, incluyendo datos de pasaportes y tarjetas de crédito. La filtración se produjo en un proveedor externo de alojamiento en la nube, quien notificó a la aerolínea la filtración después de un tiempo.
Escenario n.° 3: Una importante aerolínea europea sufrió una infracción notificable del RGPD. La infracción se debió, según se informa, a vulnerabilidades de seguridad en aplicaciones de pago explotadas por atacantes que obtuvieron más de 400 000 registros de pago de clientes. Como resultado, la aerolínea recibió una multa de 20 millones de libras por parte del regulador de privacidad.

A09:2021 – Fallas en el Registro y Monitoreo
| CWE mapeados | Tasa de incidencia máx | Tasa de incidencia prom | Explotabilidad ponderada prom | Impacto ponderado prom | Cobertura máx | Promoción de cobertura | Incidencias totales | Total de CVEs |
| 4 | 19,23% | 6,51% | 6.87 | 4,99 | 53,67% | 39,97% | 53.615 | 242 |
Monitoreo y registro de seguridad provienen de la encuesta de la comunidad (tercer lugar), subió levemente desde la décima posición en el Top 10 2017. El registro y monitoreo pueden ser desafiantes para ser testeados, implicando entrevistas o preguntar si los ataques fueron detectados durante las pruebas de penetración. No hay muchos datos de CVE/CVSS para esta categoría, pero detectar y responder a las brechas es crítico. Aún así, puede tener un gran impacto para la auditabilidad, visibilidad, alertas de incidentes y análisis forense. Esta categoría se expande más allá de CWE-117 Neutralización de salida incorrecta para registros, CWE-223 Omisión de información relevante para la seguridad, y CWE-532 Inserción de información sensible en archivo de registro.
C9: Implementar el registro y monitoreo de seguridad
Descripción
El registro es un concepto que la mayoría de los desarrolladores ya utilizan para fines de depuración y diagnóstico. El registro de seguridad es un concepto igualmente básico: registrar información de seguridad durante la ejecución de una aplicación.
La monitorización consiste en la revisión en tiempo real de los registros de aplicaciones y seguridad mediante diversas formas de automatización. Las mismas herramientas y patrones se pueden utilizar para operaciones, depuración y seguridad.
El objetivo del registro de seguridad es detectar y responder a posibles incidentes de seguridad.
Beneficios del registro de seguridad
El registro de seguridad se puede utilizar para:
- Alimentación de sistemas de detección de intrusiones
- Análisis e investigaciones forenses
- Cumplimiento de los requisitos de cumplimiento normativo
Registro para detección y respuesta a intrusiones
Utilice el registro para identificar actividades que indiquen que un usuario se comporta de forma maliciosa. Entre las actividades potencialmente maliciosas que se deben registrar se incluyen:
- Datos enviados que están fuera de un rango numérico esperado.
- Datos enviados que implican cambios en datos que no deberían ser modificables (lista de selección, casilla de verificación u otro componente de entrada limitada).
- Solicitudes que violan las reglas de control de acceso del lado del servidor.
- Una lista más completa de posibles puntos de detección está disponible aquí .
Cuando su aplicación detecte dicha actividad, debería, como mínimo, registrarla y marcarla como un problema de alta gravedad. Idealmente, también debería responder a un posible ataque identificado, por ejemplo, invalidando la sesión del usuario y bloqueando su cuenta. Los mecanismos de respuesta permiten al software reaccionar en tiempo real ante posibles ataques identificados.
Diseño de registro seguro
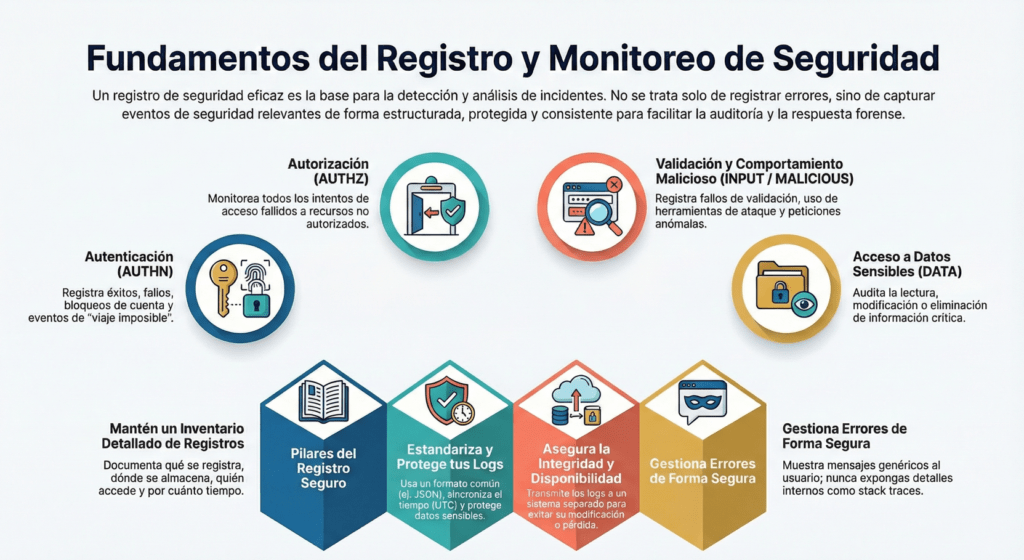
Las soluciones de registro deben construirse y gestionarse de forma segura. El diseño de un registro seguro puede incluir lo siguiente:
- Permita solo los caracteres esperados o codifique la entrada según el objetivo para evitar ataques de inyección de registros . El enfoque ideal sería que la solución de registro escape la entrada en lugar de descartar datos; de lo contrario, la solución de registro podría descartar datos necesarios para un análisis posterior.
- No registre información confidencial. Por ejemplo, no registre contraseñas, ID de sesión, tarjetas de crédito ni números de la Seguridad Social.
- Proteja la integridad de los registros. Un atacante podría intentar manipularlos. Por lo tanto, se debe considerar la autorización de los archivos de registro y la auditoría de los cambios en los registros.
- Reenvíe registros de sistemas distribuidos a un servicio de registro central y seguro. Esto garantizará que los datos de registro no se pierdan si un nodo se ve comprometido. Esto también permite una monitorización centralizada o incluso automatizada.
Amenazas
- Un atacante podría realizar ataques de inyección de registros manipulando las entradas de registro y potencialmente insertando datos o comandos maliciosos en los archivos de registro.
- Un atacante podría obtener acceso no autorizado a información confidencial mediante prácticas de registro excesivamente detalladas que capturan y almacenan inadvertidamente datos confidenciales.
- Un atacante podría alterar los registros para ocultar rastros de actividades maliciosas, borrando o modificando potencialmente la evidencia de su intrusión.
- Un atacante podría lanzar ataques de denegación de servicio saturando los sistemas de registro con una avalancha de datos, lo que podría interrumpir las operaciones normales del sistema u ocultar otras acciones maliciosas.
- Un atacante podría obtener acceso no autorizado a los archivos de registro debido a controles de acceso inadecuados, exponiendo potencialmente información confidencial del sistema o datos del usuario.
- Un atacante podría falsificar registros para crear pistas de auditoría falsas, lo que podría engañar a los investigadores o incriminar a partes inocentes en actividades maliciosas.
- Un atacante podría aprovechar prácticas de registro insuficientes para realizar actividades maliciosas sin ser detectado, prolongando potencialmente su acceso no autorizado a los sistemas.
- Un atacante podría explotar las condiciones de carrera de los archivos de registro en aplicaciones multiproceso, corrompiendo potencialmente los datos de registro u obteniendo acceso no autorizado a información confidencial.
- Un atacante podría realizar ataques de repetición utilizando información obtenida de los registros, potencialmente reutilizando datos capturados para suplantar a usuarios legítimos o repetir acciones autenticadas.
Implementación
La siguiente es una lista de las mejores prácticas de implementación del registro de seguridad.
- Siga un formato y enfoque de registro común dentro del sistema y entre los sistemas de una organización. Un ejemplo de un marco de registro común son los Servicios de Registro de Apache, que ayudan a garantizar la coherencia del registro entre aplicaciones Java, PHP, .NET y C++.
- No registre demasiado ni muy poco. Por ejemplo, asegúrese de registrar siempre la marca de tiempo y la información de identificación, incluyendo la IP de origen y el ID de usuario, pero tenga cuidado de no registrar datos privados (como el nombre de usuario) ni confidenciales (como datos comerciales) a menos que se tomen precauciones adicionales.
- Preste mucha atención a la sincronización horaria entre los nodos para garantizar que las marcas de tiempo sean consistentes.
Vulnerabilidades prevenidas
- Ataques de fuerza bruta contra mecanismos de inicio de sesión
9. Security Logging and Monitoring Failures – Fallas de registro y monitoreo de seguridad
Al configurar aplicaciones web, se debe registrar cada acción realizada por el usuario. El registro es importante porque, en caso de incidente, se pueden rastrear las actividades de los atacantes. Una vez rastreadas sus acciones, se puede determinar su riesgo e impacto. Sin el registro, no habría forma de saber qué acciones realizó un atacante si obtuviera acceso a aplicaciones web específicas. Los impactos más significativos incluyen:
- Daño regulatorio: si un atacante ha obtenido acceso a información personal identificable del usuario y no hay registro de esto, los usuarios finales se ven afectados y los propietarios de las aplicaciones pueden estar sujetos a multas o acciones más severas dependiendo de las regulaciones.
- Riesgo de nuevos ataques: la presencia de un atacante podría pasar desapercibida sin registro. Esto podría permitirle lanzar nuevos ataques contra los propietarios de aplicaciones web mediante el robo de credenciales, ataques a la infraestructura, etc.
La información almacenada en los registros debe incluir lo siguiente:
- Códigos de estado HTTP
- Marcas de tiempo
- Nombres de usuario
- Puntos finales de API /ubicaciones de páginas
- Direcciones IP
Estos registros contienen información confidencial, por lo que es importante garantizar que se almacenen de forma segura y que se guarden varias copias de estos registros en diferentes ubicaciones.
Como habrá notado, el registro es más importante después de una brecha o incidente. Lo ideal es contar con un sistema de monitoreo para detectar cualquier actividad sospechosa. El objetivo de detectar esta actividad sospechosa es detener al atacante por completo o reducir su impacto si su presencia se detecta mucho más tarde de lo previsto. Algunos ejemplos comunes de actividad sospechosa incluyen:
- Múltiples intentos no autorizados para una acción particular (generalmente intentos de autenticación o acceso a recursos no autorizados, por ejemplo, páginas de administración)
- Solicitudes de direcciones IP o ubicaciones anómalas: si bien esto puede indicar que alguien más está intentando acceder a la cuenta de un usuario en particular, también puede tener una tasa de falsos positivos.
- Uso de herramientas automatizadas: ciertas herramientas automatizadas pueden identificarse fácilmente, por ejemplo, mediante el valor de los encabezados User-Agent o la velocidad de las solicitudes. Esto puede indicar que un atacante las está utilizando.
- Cargas útiles comunes: en aplicaciones web, es habitual que los atacantes utilicen cargas útiles conocidas. Detectar su uso puede indicar la presencia de alguien que realiza pruebas no autorizadas o maliciosas en las aplicaciones.
Detectar actividades sospechosas por sí solas no es útil. Estas actividades deben clasificarse según su nivel de impacto. Por ejemplo, ciertas acciones tendrán mayor impacto que otras. Estas acciones de mayor impacto deben responderse con mayor rapidez; por lo tanto, deben generar alertas para llamar la atención de las partes interesadas.Pon en práctica estos conocimientos analizando el archivo de registro de muestra. Puedes descargarlo haciendo clic en el Download Task Filesbotón en la parte superior de la tarea.
Integridad de los datos: recuperación tras ransomware y otros eventos destructivos
Las empresas se enfrentan a una amenaza casi constante de malware destructivo, ransomware, actividades internas maliciosas e incluso errores involuntarios que pueden alterar o destruir datos críticos. Estos eventos de corrupción de datos podrían causar una pérdida significativa en la reputación, las operaciones y los resultados de una empresa.
Este tipo de eventos adversos, que en última instancia afectan la integridad de los datos, pueden comprometer información corporativa crítica, como correos electrónicos, registros de empleados, registros financieros y datos de clientes. Es fundamental que las organizaciones se recuperen rápidamente de un ataque a la integridad de los datos y confíen en la exactitud y precisión de los datos recuperados.
El Centro Nacional de Excelencia en Ciberseguridad (NCCoE) del NIST creó un laboratorio para explorar métodos de recuperación eficaz ante un evento de corrupción de datos en diversos entornos empresariales de TI. El NCCoE también implementó sistemas de TI de auditoría e informes para apoyar la recuperación e investigación de incidentes.
Esta Guía Práctica de Ciberseguridad del NIST demuestra cómo las organizaciones pueden implementar tecnologías para tomar medidas inmediatas tras un evento de corrupción de datos. La solución de ejemplo descrita en esta guía fomenta la monitorización y detección efectivas de la corrupción de datos en componentes empresariales estándar, así como en aplicaciones personalizadas y datos compuestos por componentes de código abierto y disponibles comercialmente.
El ransomware, el malware destructivo, las amenazas internas e incluso los errores involuntarios de los usuarios representan amenazas constantes para las organizaciones. Los datos de las organizaciones, como registros de bases de datos, archivos de sistema, configuraciones, archivos de usuario, aplicaciones y datos de clientes, son objetivos potenciales de corrupción, modificación y destrucción de datos. Formular una defensa contra estas amenazas requiere dos cosas: un conocimiento profundo de los activos dentro de la empresa y la protección de estos activos contra la amenaza de corrupción y destrucción de datos. El NCCoE, en colaboración con miembros de la comunidad empresarial y proveedores de soluciones de ciberseguridad, ha desarrollado una solución de ejemplo para abordar estos desafíos de integridad de datos.
Múltiples sistemas deben trabajar en conjunto para identificar y proteger los activos de una organización contra la amenaza de corrupción, modificación y destrucción. Este proyecto explora métodos para identificar eficazmente los activos (dispositivos, datos y aplicaciones) que podrían convertirse en blanco de ataques a la integridad de los datos, así como las vulnerabilidades en el sistema de la organización que facilitan estos ataques. También explora métodos para proteger estos activos contra ataques a la integridad de los datos mediante copias de seguridad, almacenamiento seguro, mecanismos de verificación de integridad, registros de auditoría, gestión de vulnerabilidades, mantenimiento y otras posibles soluciones.
El ransomware, el malware destructivo, las amenazas internas e incluso los errores involuntarios representan una amenaza constante para las organizaciones que gestionan datos en diversos formatos. Los registros y la estructura de bases de datos, los archivos del sistema, las configuraciones, los archivos de usuario, el código de las aplicaciones y los datos de los clientes son objetivos potenciales de corrupción y destrucción de datos.
Una detección y respuesta oportuna, precisa y exhaustiva ante una pérdida de integridad de datos puede ahorrarle a una organización tiempo, dinero y dolores de cabeza. Si bien el conocimiento y la experiencia humana son esenciales para estas tareas, contar con las herramientas y la preparación adecuadas es fundamental para minimizar el tiempo de inactividad y las pérdidas causadas por eventos de integridad de datos. El NCCoE, en colaboración con miembros de la comunidad empresarial y proveedores de soluciones de ciberseguridad, ha desarrollado una solución de ejemplo para abordar estos desafíos de integridad de datos. Este proyecto detalla métodos y posibles conjuntos de herramientas que pueden detectar, mitigar y contener eventos de integridad de datos en los componentes de una red empresarial. También identifica herramientas y estrategias para facilitar la respuesta de un equipo de seguridad ante un evento de este tipo.
La incapacidad de ver lo que ocurre en los sistemas, impidiendo notar que un atacante ya está adentro.
Registro y Monitoreo de Seguridad: El Arte de Escuchar a tus Aplicaciones
Cuando pensás en compromisos de seguridad, una verdad incómoda aparece casi siempre: el sistema ya te lo estaba diciendo, pero no lo estabas escuchando. Lo que distingue a una arquitectura madura de una amateur no es solo cuánto código hay, sino cuánto se registra, cómo, dónde, y quién lo está mirando. Porque si el monitoreo no existe o es un desastre, no importa cuán “seguro” te creas: estás ciego. Y si estás ciego, estás comprometido. Solo que aún no te enteraste.
Implementar un sistema robusto de registro y monitoreo no es solo una cuestión de cumplimiento. Es el equivalente digital de poner sensores en las puertas, alarmas en los accesos, y cámaras en los pasillos. Pero, a diferencia del mundo físico, en la infraestructura digital, cada bit que se mueve puede ser auditado —si sabés dónde mirar.
Mucho más que console.log(): ¿Por qué importa?
Cada año, informes como el de IBM/Ponemon sobre el costo de una violación de datos repiten el mismo diagnóstico: 200 días en promedio para detectar una intrusión. No porque no haya alertas, sino porque nadie las configuró bien, nadie interpretó los registros, o directamente no había eventos registrados. La brecha de tiempo entre la intrusión y su detección es el infierno silencioso de muchas empresas. Y es evitable.
El objetivo del logging de seguridad no es almacenar datos porque sí. Es construir un sistema de conciencia situacional. Uno que te diga, con precisión:
- Quién accedió a qué.
- Cuándo algo raro pasó.
- Cuánto riesgo representa.
- Dónde responder.
El lenguaje oculto de las aplicaciones
Todo sistema habla. Algunos gritan errores a través de stack traces; otros susurran a través de inconsistencias sutiles. El truco es darle estructura a esos mensajes. Para eso, necesitamos un vocabulario estándar de eventos de seguridad. Una taxonomía que permita correlacionar, alertar y entender patrones, incluso en ecosistemas distribuidos o microservicios.
Afortunadamente, existe una propuesta concreta y poderosa para esto: una hoja de referencia de vocabulario de eventos de seguridad, basada en prefijos claros como authn, authz, crypt, session, user, malicious, etc.
La idea es simple: si todos los componentes de una plataforma registran eventos utilizando un lenguaje común, herramientas de monitoreo pueden aplicar reglas genéricas, sin necesidad de adaptar regex a cada stack. El resultado: alertas más rápidas, menos falsos positivos, y una visión coherente del sistema.
Vocabulario de eventos: una gramática para la detección
Veamos algunos ejemplos reales de este enfoque estructurado:
- Inicio de sesión exitoso
{ «event»: «authn_login_success:joebob1», «level»: «INFO», «description»: «User joebob1 login successfully» }
- Fallo de login por intento excesivo
{ «event»: «authn_login_fail_max:joebob1,3», «level»: «WARN», «description»: «User joebob1 reached the login fail limit of 3» }
- Token revocado reutilizado
{ «event»: «authn_token_reuse:app.foobarapi.prod,xyz-abc-123-gfk», «level»: «CRITICAL», «description»: «Revoked token used again» }
- Acceso no autorizado a un recurso
{ «event»: «authz_fail:joebob1,resource», «level»: «CRITICAL», «description»: «User attempted unauthorized access» }
- Lectura de datos sensibles
{ «event»: «sensitive_read:joebob1,/vault/clients.csv», «level»: «WARN», «description»: «Sensitive file read» }
Estas estructuras pueden ser complementadas con metadata obligatoria: timestamp en ISO8601 con offset UTC, IP de origen, agente de usuario, appid, método HTTP, URI de la solicitud, geolocalización, región cloud, etc.
Logs que te protegen, no que te exponen
Una de las trampas más peligrosas en el diseño de logs es creer que más información = más seguridad. Nada más lejos. Un mal diseño de logging es un regalo envenenado para cualquier atacante. Ejemplos comunes:
- Stack traces que incluyen paths internos, nombres de tablas o estructuras de datos.
- Logs que almacenan tokens JWT, contraseñas, o secretos.
- Archivos de log accesibles sin control de permisos.
- Logs de errores que inyectan datos del usuario sin sanitizar.
El registro seguro implica:
- No loggear credenciales, tokens ni datos PII directamente.
- Escapar caracteres peligrosos para prevenir inyección (\n, ;, |, etc.).
- Asegurar integridad y confidencialidad de los logs (firmas, permisos, cifrado).
- Centralizar el almacenamiento y hacerlo redundante (enviar a SIEM, syslog remoto, cloud logging).
Arquitectura técnica: del código al SIEM
Para que esto funcione en producción real, hay que conectar todo: desde el backend, pasando por los contenedores y el sistema operativo, hasta los sistemas de observabilidad. Algunos puntos críticos:
- Estructura JSON para logs: ideal para pipelines como ELK, Datadog, Splunk o CloudWatch.
- Trazabilidad de sesión y usuario: cada evento debe correlacionarse con una sesión, IP, user-agent.
- Integración con APMs (como New Relic, Dynatrace) para contexto de rendimiento.
- Alertas automáticas sobre patrones peligrosos: tokens reutilizados, viajes imposibles, bruteforce, acceso a datos sensibles.
El rol del desarrollador: no es magia negra
Todo esto no sirve si los desarrolladores no registran los eventos relevantes. Acá entra un cambio cultural: los eventos de seguridad no se delegan al equipo de seguridad, se construyen desde el código. Escribir logger.warn(«user login failed») es seguridad.
Esto implica formación técnica: conocer ataques comunes, entender cómo se ven en logs, y capturarlos. Por ejemplo:
- Detectar cuando un campo recibió un valor fuera de las opciones esperadas (input_validation_discrete_fail).
- Registrar cuando se omite un paso de flujo lógico (sequence_fail).
- Capturar cambios en privilegios o archivos sensibles (permissions_changed, sensitive_update).
Cada equipo puede extender el vocabulario base a su contexto, pero siempre respetando la semántica: un evento authz_fail tiene el mismo significado, en cualquier microservicio.
¿Y si no registrás nada?
Te lo resumo en dos frases:
- Si no lo registrás, no lo podés monitorear.
- Si no lo podés monitorear, no lo vas a detectar.
Esto aplica tanto para ataques de password spraying como para apropiación de sesiones o movimientos laterales. Peor aún: sin logs, no podés demostrar qué pasó. Estás a oscuras, sin evidencia ni defensa.
Integración práctica: Python, Node, Java, etc.
Cada stack tiene herramientas para facilitar esto:
- Python: owasp-logger permite usar el vocabulario estandarizado con formato JSON.
- Node.js: Winston + middlewares para Express pueden generar logs con toda la metadata.
- Java: SLF4J y Logback con appenders JSON y MDC (Mapped Diagnostic Context) para contexto de usuario/sesión.
- Go: Zap o Logrus con hooks personalizados.
- Kubernetes: sidecars de logging, Fluentd, OpenTelemetry.
La clave es que los eventos deben generarse desde la lógica de negocio, no solo a nivel de infraestructura.
Checklist para saber si estás haciendo las cosas bien
- ¿Tus logs tienen formato estructurado?
- ¿Estás registrando eventos de login, cambio de privilegios, acceso a datos sensibles?
- ¿Tus logs incluyen contexto como IP, agente, método, URI?
- ¿Hay un pipeline automatizado que recoja, indexe y alerte sobre eventos clave?
- ¿Tenés reglas que detecten token reuse, viajes imposibles, accesos fuera de secuencia?
- ¿Tu equipo de desarrollo entiende cómo y cuándo loggear eventos críticos?
Loggear eventos de seguridad no es una opción. Es el mínimo necesario para no ser ciego ante un ataque. Pero hacerlo bien requiere método, semántica común, responsabilidad compartida entre desarrolladores, arquitectos, SREs y seguridad ofensiva. Significa crear una red de sensores internos, en donde cada servicio reporta su estado y alerta ante lo inesperado. Y si todo eso está conectado con un buen SIEM, capaz de alertarte en tiempo real, tenés algo que muy pocas empresas tienen: conciencia situacional digital.
Cuando eso pasa, loggeás no por cumplir. Loggeás porque querés saber. Y ese es el primer paso hacia un entorno realmente seguro.
¿Qué deberías hacer como desarrollador o equipo?
- Centralizar logs → Todos los servicios deben usar el mismo formato (ej: JSON estructurado).
- Correlacionar eventos → Incluir IDs de sesión, usuario, request y timestamp UTC.
- Auditar los logs → Validar que no estás registrando tokens, contraseñas ni datos PII sin protección.
- Automatizar detección → Los eventos del vocabulario de seguridad deben alimentar tu SIEM o herramienta de detección.
- Asegurar logs como activos críticos → Cifrado en tránsito, almacenamiento aislado, control de acceso y retención definida.
- Probar el flujo de errores → Validar qué ocurre cuando una excepción no está controlada (¿se loggea? ¿se responde al usuario?).
A09:2025 – Fallos de Registro y Monitoreo de Seguridad (Security Logging & Monitoring Failures)
Esta categoría engloba todo lo que impide detectar, registrar, responder o correlacionar actividades sospechosas.
No es solo “no loguear”: es loguear mal, loguear tarde, loguear sin contexto, no monitorear, no alertar y no proteger el pipeline de logs.
En 2025 sigue siendo una de las principales causas de detección tardía de intrusiones y de brechas masivas que pasan meses sin descubrirse.
🧩 Ejemplos típicos (2025)
- Falta de logs en endpoints críticos (login, admin, pagos).
- Logs incompletos (sin IP, user-agent, usuario, origen).
- No registrar fallos de autenticación → fuerza bruta invisible.
- No registrar cambios de configuración o privilegios.
- Alertas que nunca disparan o están mal configuradas.
- Tiempo de retención insuficiente (7 días = inútil).
- Logs almacenados localmente sin protección → manipulación.
- Logs sin integridad (sin hash o sin firma).
- Sistemas SIEM sin correlación real.
- Cargas útiles mal sanitizadas que rompen logs (“log injection”).
- Faltan auditorías de acceso a datos sensibles.
- No monitorear APIs, colas, S3, DB, contenedores o CI/CD.
- Telemetría inconsistente entre microservicios.
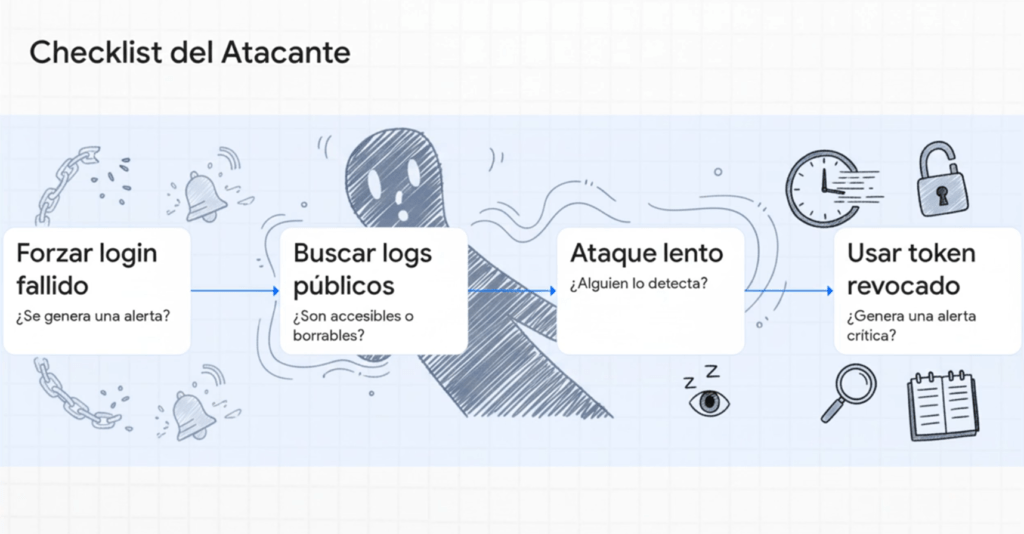
🔍 Mini-guía de explotación (Pentesting 2025)
- Realizar intentos de login fallidos → verificar si aparecen en logs.
- Probar fuerza bruta suave para ver si dispara alertas.
- Modificar varios estados/roles → revisar si hay auditoría.
- Eliminar o modificar datos → mirar si hay registro.
- Inyectar cargas en logs (\n, %0D%0A, <script>) para detectar log injection.
- Monitorear tiempo de reacción del SOC o SIEM (si es permitido).
- Cambiar configuración de aplicaciones → ver si queda registrado.
- Usar API no documentadas/legacy → ver si genera eventos.
- Realizar escaneo moderado para detectar detección de patrones.
- Acceder a S3/Storage sin permisos → ver si hay alerta.

🎯 Consecuencias
- Intrusiones que pasan meses sin detectarse.
- Falta de evidencia para incident response.
- Alteración de datos sin auditoría.
- Escaladas de privilegio invisibles.
- Explotación sostenida de vulnerabilidades sin rastros.
- Borrar logs → encubrir actividades maliciosas.
- Fraude financiero no trazable.
- Compromiso de infraestructura sin alertas.
🛡 Defensas modernas (2025)
- Logueo estructurado (JSON, ECS, OpenTelemetry).
- Logs obligatorios en:
- autenticación
- autorización
- pagos
- acciones administrativas
- almacenamiento
- API Gateway
- CI/CD
- Retención mínima de 90–180 días (según regulación).
- Integridad de logs: hashing, firma, WORM storage.
- Centralización en SIEM/SOAR (Elastic, Splunk, Sentinel, QRadar).
- Correlación de eventos entre microservicios.
- Alertas basadas en comportamiento (UEBA).
- Monitoreo real de APIs, colas, contenedores, serverless y S3.
- Alertas de anomalías:
- tasas de login
- tráfico inusual
- cambios repentinos de privilegios
- Protección ante log injection (escape y sanitización).
- Monitoreo del pipeline CI/CD.
- Dashboards en tiempo real y SLAs de respuesta.

📚 Subtipos / patrones modernos (2025)
| Subtipo / patrón | Definición | Ejemplo bancario | Pentesting (qué probar) | Ataque / PoC | Consecuencia | Defensa | Tips examen |
| Missing Auth Logs | No se registran logins | Fuerza bruta invisible | Fallar logins | Invisibilidad | ATO silencioso | Log de login | “login invisible = fail” |
| Missing Privilege Logs | Cambios no auditados | Rol admin sin registro | Cambiar rol | Escalada oculta | Robo total | Auditoría | Buscar “role change” |
| Log Injection | Inyección en logs | Inyectar saltos/JS | \n %0D%0A | Romper logs | Manipulación | Escape adecuado | Keywords: “CRLF” |
| Insufficient Retention | Retención pobre | 7 días de logs | Analizar retención | Fuga sin huellas | Sin evidencia | 90+ días | Regulaciones requieren 6 meses |
| No SIEM / No Alerts | Logs sin monitoreo | Incidentes invisibles | Generar eventos | Sin alarmas | Persistencia | SIEM real | “SIEM sin reglas = inútil” |
| No Data Access Logging | Lectura de PII no registrada | Consulta de datos cliente | Leer datos | Robo PII | Fuga | Audit logs | PII siempre auditada |
| API/Cloud Unmonitored | Sin logs de API/S3 | Bucket accesado | Acceder S3 | Robo masivo | Fuga | CloudTrail/Monitor | Buscar “S3 sin logging” |
| CI/CD Logging Failures | Pipeline sin logs | Cambiar build | Alterar código | Backdoor | Compromiso | Logs CI/CD | Pipelines son críticos |
| Microservices Uncorrelated | Eventos aislados | Cada microservicio loguea distinto | Correlación manual | Ocultar actividad | Persistencia | OpenTelemetry | Buscar “trace-id” |
| Tamperable Logs | Logs editables localmente | /var/log editable | Modificar logs | Encubrimiento | Sin evidencia | WORM | Integridad = fundamental |
🧪 Checklist rápida de pentesting A09:2025
- Revisar logs de login, logout, cambios de privilegio.
- Probar fuerza bruta controlada.
- Revisar retención de logs.
- Revisar integridad → ¿hash/sig?
- Probar log injection con CRLF y caracteres especiales.
- Revisar logs de API Gateway, WAF, NGINX, CloudTrail.
- Revisar logs de CI/CD.
- Ver si microservicios comparten trace-id.
- Revisar auditoría de lectura de datos sensibles.
- Simular anomalías: muchas requests, cambios de rol, peticiones sospechosas.
🧾 Resumen ejecutivo para cursos
A09:2025 Fallos de Registro y Monitoreo de Seguridad implica no detectar ni registrar adecuadamente eventos críticos, lo que permite ataques invisibles que pueden persistir durante meses sin ser descubiertos. Incluye falta de logs, logs incompletos, logs manipulables, ausencia de alertas, retención insuficiente, falta de correlación entre microservicios y monitoreo incompleto en APIs, storage o CI/CD. Su mitigación requiere logging estructurado, integridad y centralización de logs, retención adecuada, alertas realistas, correlación entre servicios y monitoreo continuo del comportamiento. Sin visibilidad, no hay seguridad.


Tips de examen
- Si dicen “el sistema no registra intentos fallidos de login” → A09.
- “Logs existen, pero no hay alertas” → A09.
- “Logs accesibles públicamente” → A09.
- Defensa correcta: logging completo, SIEM, alertas, integridad y retención de logs.
- Diferencia con otros:
- A07 (Auth Failures) = fallo en autenticación.
- A09 (Logging) = fallo en detectar o registrar esos intentos.
¿Qué ocurre si los intentos fallidos de login no se registran en los logs? Security Logging and Monitoring Failure, ya que no se detectan posibles ataques de fuerza bruta.
¿Qué falla existe si los logs de la aplicación solo muestran “Error” sin registrar usuario, IP ni timestamp? Security Logging and Monitoring Failure por logs incompletos.
¿Qué ocurre si el banco guarda logs de auditoría en una carpeta pública accesible por navegador? Security Logging and Monitoring Failure por exposición de logs a atacantes.
¿Qué vulnerabilidad hay si un ataque genera eventos en logs pero nunca se revisan ni hay alertas en tiempo real? Security Logging and Monitoring Failure por ausencia de monitoreo activo.
¿Qué ocurre si un atacante borra o modifica registros de logs y el banco no tiene mecanismos de integridad? Security Logging and Monitoring Failure por falta de protección de logs contra manipulación.
¿Qué falla existe si un banco no detecta 1000 intentos de login fallidos en 5 minutos? Security Logging and Monitoring Failure por falta de correlación de eventos.
¿Qué pasa si los registros críticos (transferencias, cambios de credenciales) no se auditan ni se retienen legalmente? Security Logging and Monitoring Failure por incumplimiento de retención y auditoría.
¿Qué vulnerabilidad hay si un banco no tiene plan ni pruebas de respuesta a incidentes? Security Logging and Monitoring Failure por ausencia de incident response.
¿Qué ocurre si los sistemas generan logs pero no hay integración con un SIEM o SOC? Security Logging and Monitoring Failure por falta de centralización y monitoreo.
¿Qué falla existe si los logs no diferencian entre acciones de un usuario legítimo y de un atacante? Security Logging and Monitoring Failure por registros poco detallados e inadecuados para análisis forense.
¿Cuál es la diferencia entre un fallo de A07 (Auth Failures) y A09 (Logging Failures)? A07 = el ataque ocurre por fallos en autenticación; A09 = el ataque ocurre y no se detecta ni alerta porque no hay logging/monitoreo.
¿Qué controles debe implementar un banco para evitar fallos de logging y monitoreo? Logging detallado de eventos críticos, protección de logs, SIEM con alertas en tiempo real, retención regulatoria, pruebas de incident response.
¿Qué ocurre si logs sensibles (ej. contraseñas, tokens) se guardan en texto plano? Security Logging and Monitoring Failure por mala gestión de información sensible en logs.
¿Qué pasa si un ataque DDoS ocurre y no hay métricas ni alertas configuradas? Security Logging and Monitoring Failure por ausencia de monitoreo de anomalías.
¿Qué impacto tiene un fallo de logging y monitoreo en un banco? Ataques no detectados, fraudes prolongados, falta de trazabilidad forense y multas regulatorias.
- Login fallido no registrado → A09.
- Logs incompletos (sin IP/usuario) → A09.
- Logs existen pero no se monitorean ni alertan → A09.
- Logs accesibles públicamente → A09.
- Logs manipulables (sin integridad) → A09.
- Diferencia A07 vs A09 → uno es fallo en auth, el otro en detección.
- Defensa correcta: SIEM, alertas, retención, logs protegidos.
¡Llegaste al final del capítulo A09!
Ahora tenés una comprensión clara, profunda y profesional de por qué el registro y monitoreo es uno de los controles más críticos —y más ignorados— en toda la arquitectura de seguridad moderna.
A lo largo de este capítulo aprendiste:
- Cómo A09 no evita ataques, sino que determina si vas a detectarlos y responder antes de que el daño sea irreversible.
- Qué eventos deben registrarse siempre: login fallidos, cambios de credenciales, accesos sensibles, transferencias, errores, flujos anómalos y acciones administrativas.
- Cómo un log incompleto (sin IP, sin usuario, sin timestamp) es prácticamente inútil a nivel forense y operativo.
- Cómo se explotan fallas de A09 desde el pentesting: logs públicos, sin integridad, sin monitoreo, sin correlación o directamente inexistentes.
- Cómo proteger logs contra manipulación mediante WORM, firmas digitales, controles de acceso y almacenamiento centralizado.
- Cómo funciona una arquitectura moderna de monitoreo: SIEM, SOC, correlación de eventos, UEBA, detección automática de anomalías, honeytokens y alertas en tiempo real.
- Cómo estructurar eventos de seguridad con vocabulario estándar (authn_fail, authz_fail, sensitive_read, token_reuse, malicious_payload).
- Qué significa realmente tener evidencia completa para auditoría, cumplimiento, forense y respuesta a incidentes.
- Por qué grandes brechas en bancos, aerolíneas, hospitales y gobiernos permanecen ocultas durante meses o años por fallas de A09.
Lo esencial que tenés que llevarte es esto:
si no registrás, no monitoreás; si no monitoreás, no detectás; si no detectás, no defendés.La seguridad no depende solo de evitar que entren, sino de saber inmediatamente cuando algo se sale del comportamiento esperado.Con este capítulo ya dominás uno de los componentes más estratégicos del OWASP Top 10. Aprendiste a pensar el logging no como un “detalle técnico”, sino como una fuente de verdad operacional, un sensor de ataques y una herramienta indispensable para preservar la integridad, la trazabilidad y la resiliencia de una plataforma.Seguí avanzando. Cada capítulo te vuelve más capaz de diseñar sistemas seguros que ven, entienden y responden. Esa es la diferencia entre una plataforma vulnerable y una plataforma madura.