Hola, hacketones! En este capítulo de TryHackMe – How Websites Work Veremos que para explotar un sitio web, primero es necesario saber cómo se crean. Al final de esta sala, sabrás cómo se crean los sitios web y conocerás algunos temas básicos de seguridad. En este capítulo aprenderás cómo funcionan los sitios web (qué hace el navegador y qué hace el servidor) y los fundamentos de seguridad del front-end que todo hacker o pentester debe dominar. Verás cómo dejar credenciales en el código o no limpiar entradas se convierten en vulnerabilidades explotables. Esto es útil y necesario para tu carrera porque te da la visión técnica para encontrar fallos reales, entender su impacto y proponer (o explotar) mitigaciones con criterio.
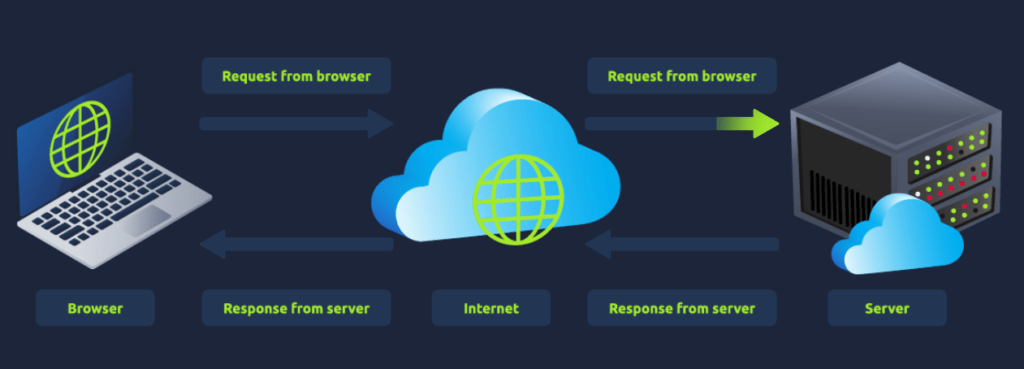
Cuando visitas un sitio web, tu navegador ( como Safari o Google Chrome ) realiza una solicitud a un servidor web solicitando información sobre la página que estás visitando. Este responderá con datos que tu navegador utiliza para mostrarte la página; un servidor web es simplemente una computadora dedicada, ubicado en otra parte del mundo, que gestiona tus solicitudes.
La imagen muestra de forma sencilla el proceso de comunicación entre un navegador web y un servidor a través de Internet. A la izquierda se observa un equipo portátil que representa el navegador (browser), el cual es el punto de inicio de la interacción. Desde ahí se genera una petición (request) que viaja a través de la red hasta llegar al servidor, representado por el equipo de la derecha.
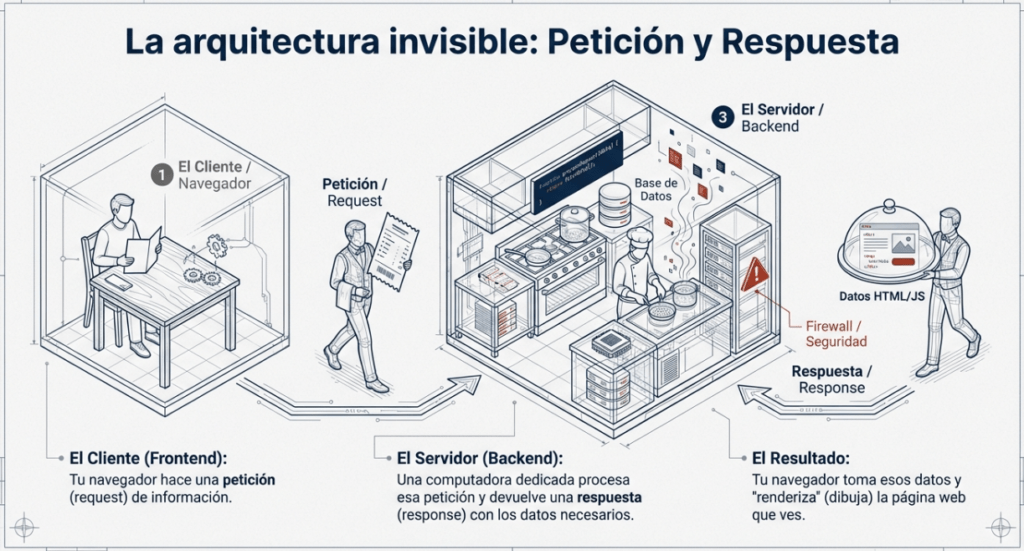
En el centro se encuentra una nube que simboliza Internet, el medio por donde se transmiten tanto las peticiones como las respuestas. El flujo se da en dos direcciones: primero, el navegador envía una solicitud al servidor pidiendo un recurso (por ejemplo, una página web o un archivo), y luego el servidor procesa esa solicitud y envía de vuelta una respuesta (response) que regresa por el mismo camino hasta el navegador.
Este esquema ilustra el modelo clásico de comunicación cliente-servidor, donde el navegador actúa como cliente que solicita información y el servidor como el sistema que la proporciona. Es un concepto fundamental para entender cómo funcionan las páginas web y es la base de muchos ataques y pruebas dentro del ámbito del hacking y el pentesting, ya que cualquier vulnerabilidad en este intercambio puede ser aprovechada para comprometer la seguridad del sistema.
Lo que experimentas como una sesión fluida de navegación es, en realidad, un ciclo incesante de peticiones y respuestas. Cada vez que ingresas a una URL, tu navegador inicia una conversación privada con una máquina remota, solicitando piezas de un rompecabezas que se ensambla en milisegundos frente a tus ojos. Pero, ¿qué tan sólida es esa construcción? La web es más parecida a un teatro con las cortinas mal cerradas que a una caja fuerte blindada.
How Websites Work (HTML/JS & Web Security) – How the web works

Hay dos componentes principales que forman un sitio web:
- Front End (lado del cliente): la forma en que el navegador representa un sitio web.
- Back End (lado del servidor): un servidor que procesa la solicitud y devuelve una respuesta.
Hay muchos otros procesos involucrados cuando el navegador realiza una solicitud a un servidor web, pero por ahora, solo necesita comprender que realiza una solicitud a un servidor y este responde con datos que el navegador utiliza para brindar la información.
A menudo hablamos de «la nube» como si fuera una entidad mística y etérea. En la práctica, la infraestructura que sostiene nuestras vidas digitales tiene una geografía mucho más terrenal. La arquitectura web se divide en dos mundos: el Client-Side (el lado del cliente, es decir, tu navegador) y el Server-Side (el lado del servidor, donde vive la información).
«Un servidor web es simplemente una computadora dedicada en algún otro lugar del mundo que maneja tus peticiones.»
Esta es la primera gran lección de la web: toda la complejidad de internet se reduce a un intercambio básico de datos. Tú haces una petición (request) y una computadora —que podría estar en un sótano en Berlín o en un centro de datos en Virginia— te envía una respuesta. No hay magia, solo hardware remoto entregando instrucciones a tu dispositivo local.
Responda la pregunta a continuación
¿Qué término describe mejor el componente de una aplicación web representada por su navegador?
Front End
HTML
Los sitios web se crean principalmente utilizando:
- HTML, para construir sitios web y definir su estructura
- CSS, para hacer que los sitios web se vean bonitos agregando opciones de estilo
- JavaScript, implementa funciones complejas en páginas usando interactividad
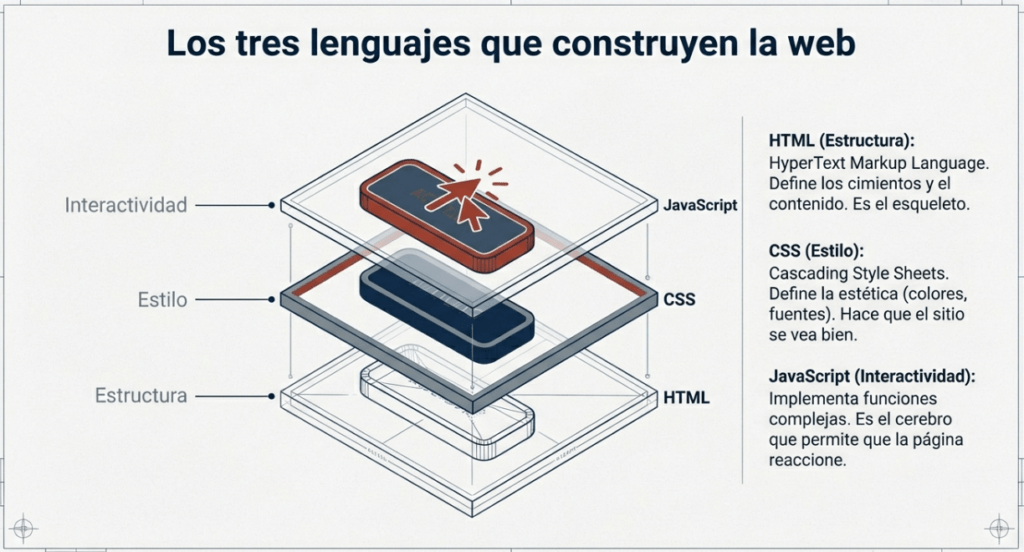
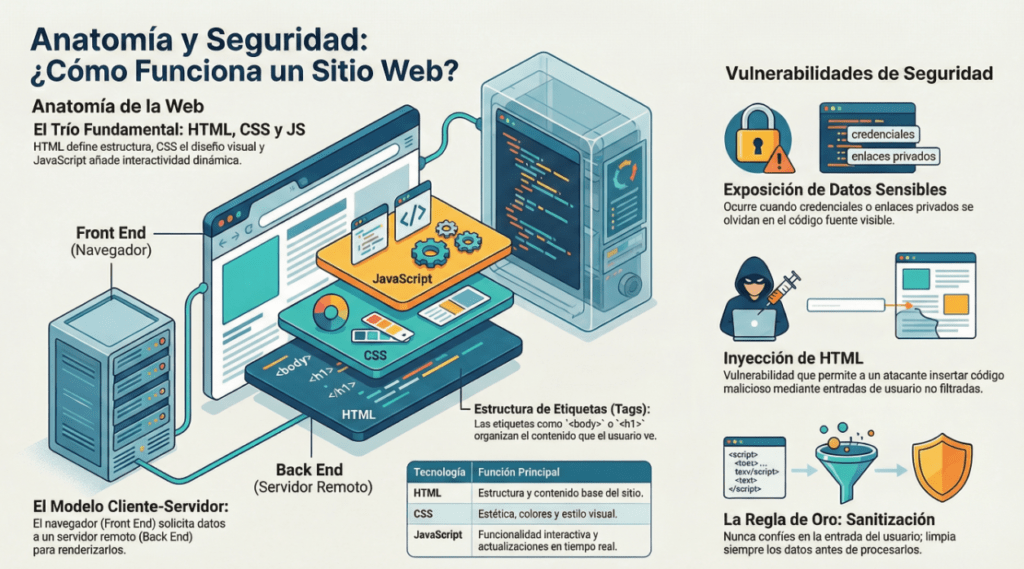
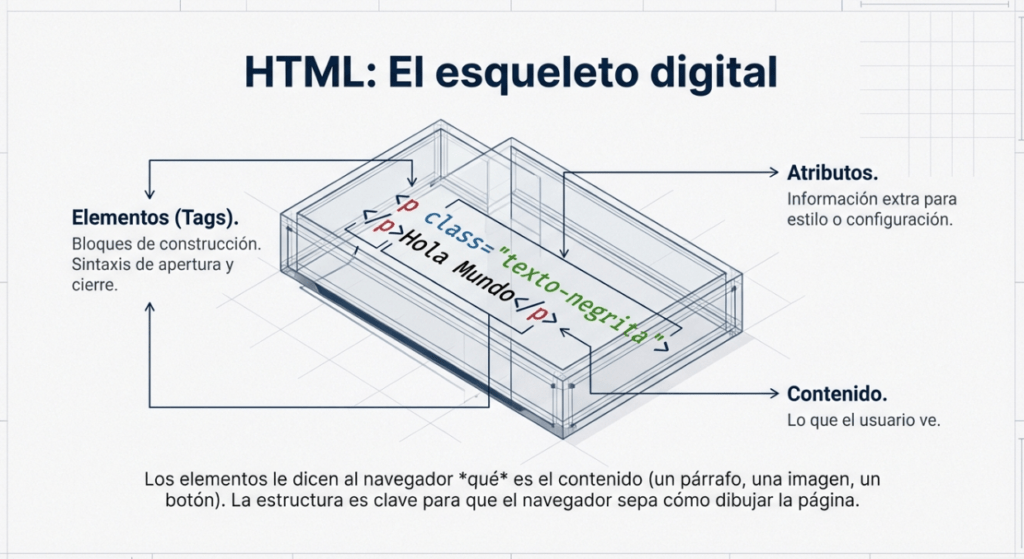
Para que tu navegador sepa qué mostrarte, recibe un paquete de instrucciones basado en tres pilares fundamentales. Si pensamos en una página web como un organismo vivo, su anatomía se divide así:
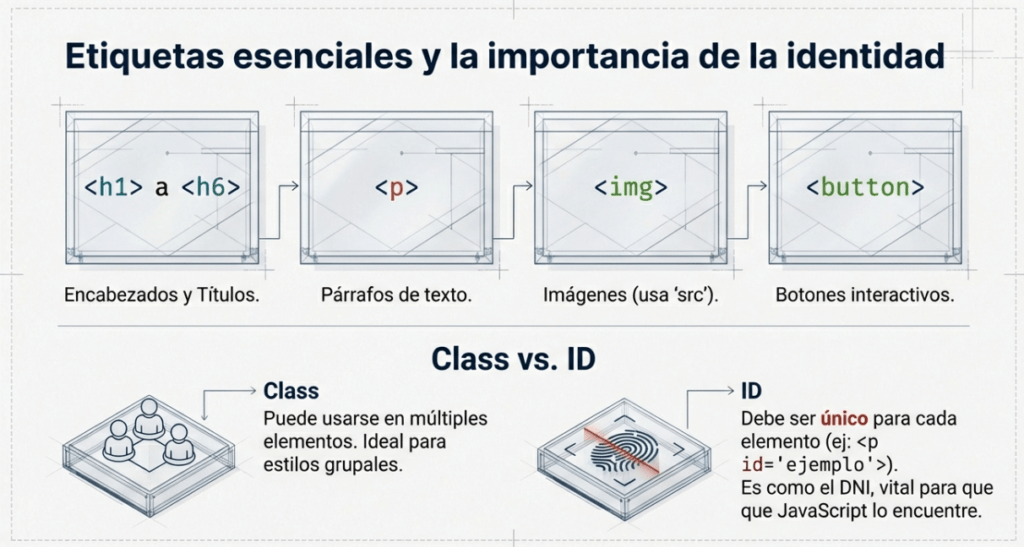
• HTML (El Esqueleto): Es el lenguaje de marcado que define la estructura. Elementos como <!DOCTYPE html> le dicen al navegador que está ante un documento moderno, mientras que etiquetas como <html>, <body>, <h1> (títulos) o <p> (párrafos) establecen los huesos sobre los que se sostiene todo.
• CSS (La Piel): Es la capa estética. A través de atributos de class o id, el desarrollador le indica al navegador cómo debe «vestirse» cada hueso: de qué color, con qué fuente y en qué posición. Es lo que hace que una web sea visualmente atractiva.
• JavaScript (Los Músculos): Es el pilar de la interactividad. Si el HTML define qué hay y el CSS cómo se ve, el JavaScript (JS) controla la funcionalidad. Permite que la página reaccione a eventos —como un onclick en un botón—, permitiendo que el sitio se mueva y cambie en tiempo real sin ser una estatua digital.
El lenguaje de marcado de hipertexto ( HTML) es el lenguaje en el que se escriben los sitios web. Los elementos (también conocidos como etiquetas) son los componentes básicos de las páginas HTML e indican al navegador cómo mostrar el contenido. El siguiente fragmento de código muestra un documento HTML simple, cuya estructura es la misma para todos los sitios web:
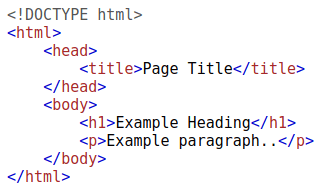
La estructura HTML (como se muestra en la captura de pantalla) tiene los siguientes componentes:
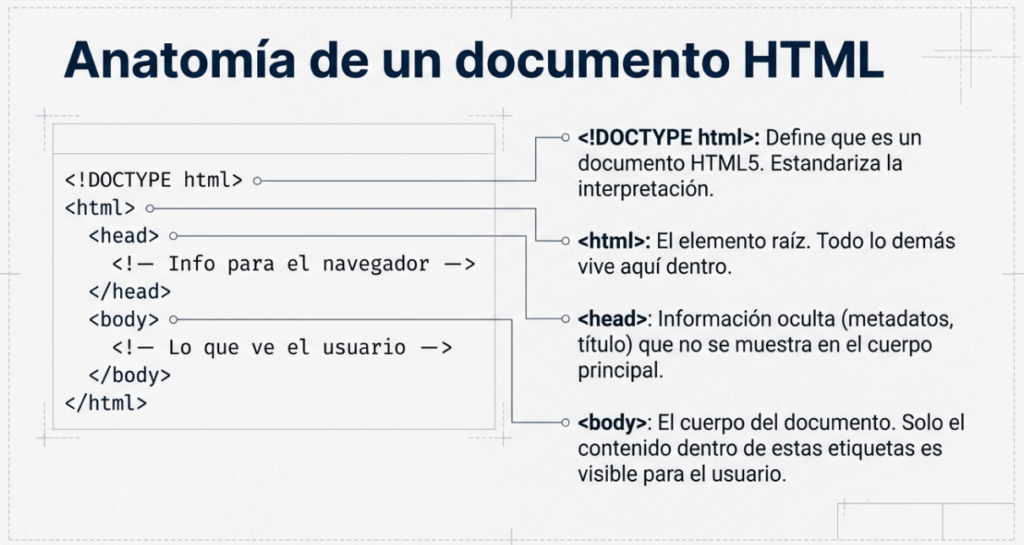
- <!DOCTYPE html> Define que la página es un documento HTML5. Esto facilita la estandarización en diferentes navegadores e indica al navegador que use HTML5 para interpretar la página.
- <html> El elemento es el elemento raíz de la página HTML: todos los demás elementos vienen después de este elemento .
- <head> El elemento contiene información sobre la página (como el título de la página)
- <body> El elemento define el cuerpo del documento HTML; solo el contenido dentro del cuerpo se muestra en el navegador.
- <h1> El elemento define un encabezado grande
- <p> El elemento define un párrafo
- <button><img> Existen muchos otros elementos (etiquetas) que se utilizan para diferentes propósitos. Por ejemplo, existen etiquetas para botones ( ), imágenes ( ), listas y mucho más.
Las etiquetas pueden contener atributos como el atributo de clase, que se puede usar para darle estilo a un elemento (por ejemplo, hacer que la etiqueta tenga un color diferente) , o el atributo src , que se usa en imágenes para especificar la ubicación de una imagen: Un elemento puede tener múltiples atributos, cada uno con su propósito único, por ejemplo, <p attribute1=»value1″ attribute2=»value2″> . <p class=»bold-text»><img src=»img/cat.jpg»>.
Los elementos también pueden tener un atributo id ( ), que es único para cada elemento. A diferencia del atributo class, donde varios elementos pueden usar la misma clase, un elemento debe tener diferentes id para identificarse de forma única . Los id de elemento se utilizan para el estilo y para su identificación mediante JavaScript. <p id=»example»>
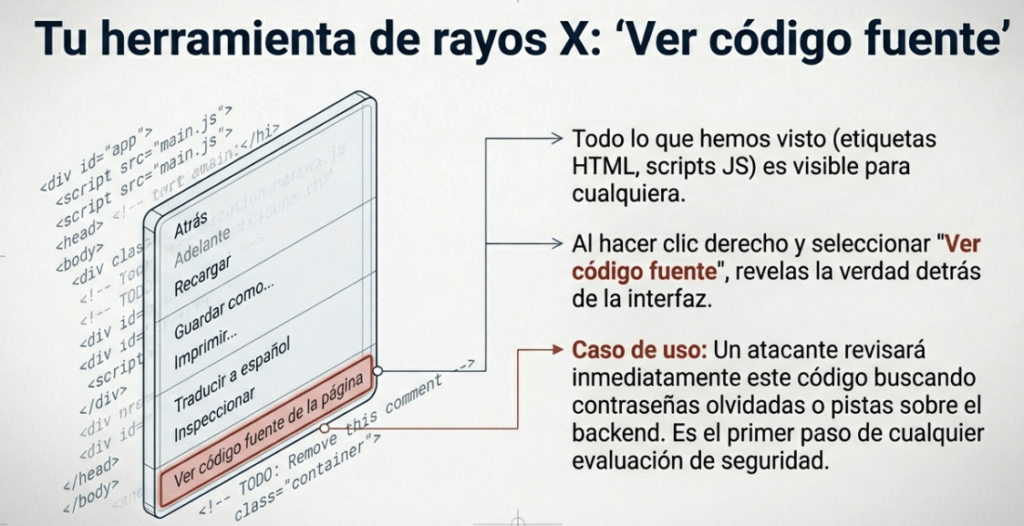
Puede ver el HTML de cualquier sitio web haciendo clic derecho y seleccionando «Ver código fuente de la página» (Chrome) / «Mostrar código fuente de la página» (Safari).
Estructura de la página HTML
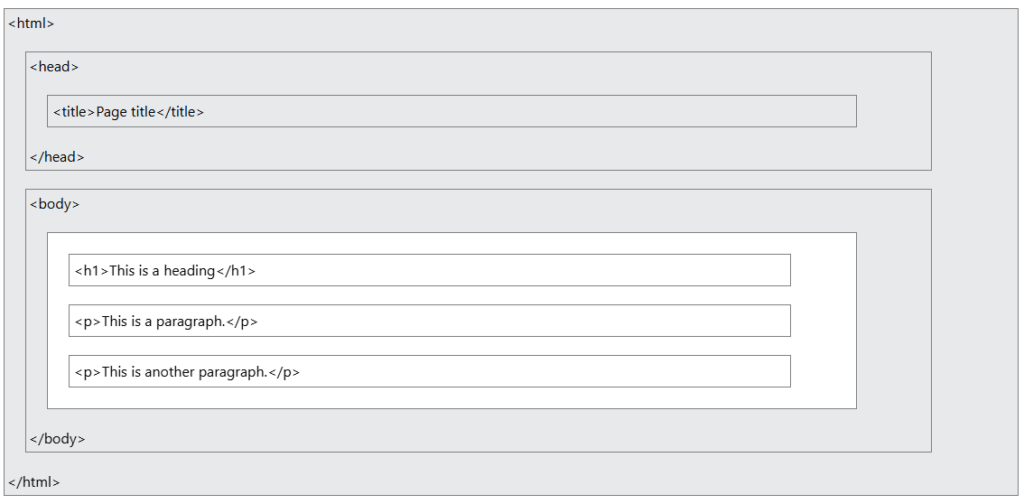
La imagen muestra la estructura básica de un documento HTML, el lenguaje fundamental para crear páginas web. Está organizada en dos grandes secciones: el head y el body, que representan respectivamente la parte informativa y la parte visible del sitio.
En la parte superior se encuentra la etiqueta <html>, que indica el inicio del documento. Dentro de ella, el bloque <head> contiene información sobre la página que no se muestra directamente al usuario, como el título, las metas o los enlaces a hojas de estilo. En este caso, se observa una etiqueta <title> con el texto Page title, que define el título que aparece en la pestaña del navegador.
Más abajo está el bloque <body>, donde se coloca todo el contenido visible de la página. Aquí se incluyen un encabezado <h1> con el texto This is a heading y dos párrafos <p> que contienen texto descriptivo. Cada uno de estos elementos representa una parte del contenido que el usuario verá cuando cargue la página en su navegador.
Este ejemplo ilustra claramente cómo se organiza el código HTML en niveles jerárquicos, donde cada etiqueta tiene una función específica. Comprender esta estructura es esencial para cualquier persona que quiera empezar a crear o analizar sitios web, y también es la base para entender cómo se pueden inyectar, modificar o manipular elementos desde el punto de vista del pentesting o la seguridad web.
Aquí es donde la web se vuelve provocativa: para que internet funcione, el Front End debe ser público. Tu navegador necesita leer las instrucciones exactas para renderizar la página; por lo tanto, esas instrucciones están a tu disposición. Con solo hacer clic derecho y seleccionar «View Page Source» (Ver código fuente), puedes acceder al plano arquitectónico de cualquier imperio digital.
Es una ironía fascinante: los imperios de miles de millones de dólares están construidos sobre código que cualquiera puede leer con dos clics. Esta transparencia es el motor del aprendizaje en la web, pero también revela que el «backstage» de internet es, por diseño, un libro abierto para quien sepa dónde mirar.
Responda las preguntas a continuación
¡Juguemos con HTML! Primero, haz clic en el botón «Ver sitio» dentro de esta tarea. A la derecha, verás un cuadro que muestra el HTML. Si introduces HTML en el cuadro y haces clic en el botón verde «Mostrar código HTML», se mostrará el HTML en la página; deberías ver una imagen de gatos.
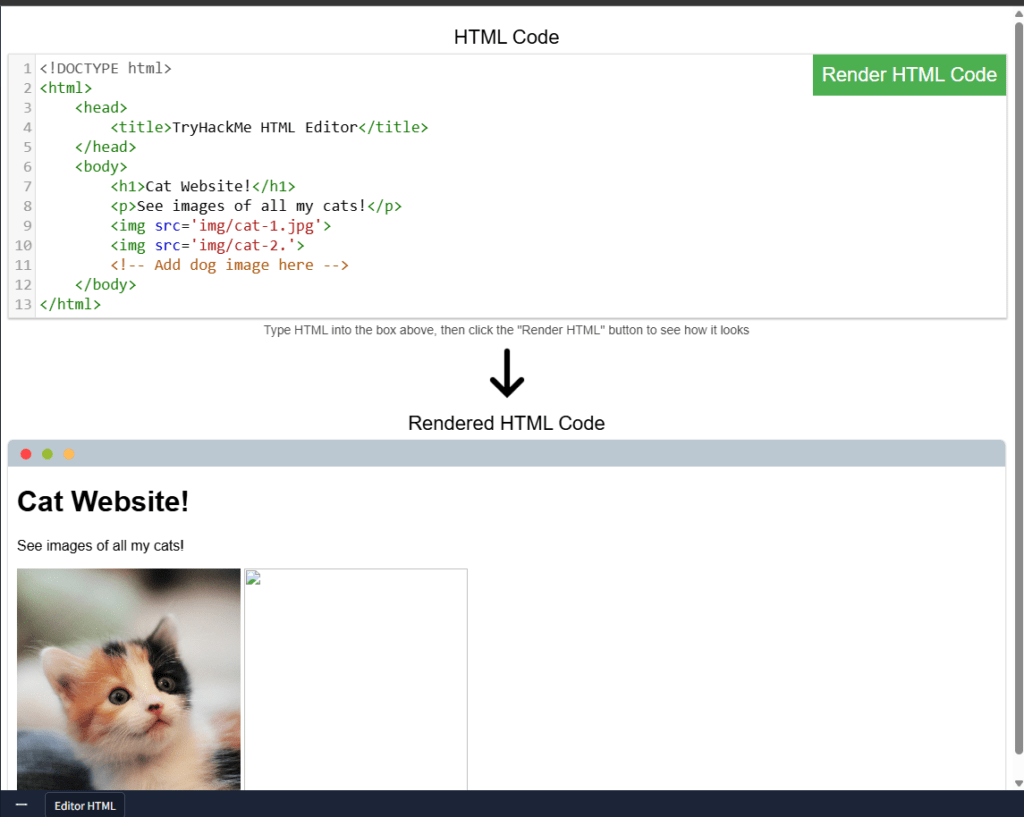
Una de las imágenes en el sitio web del gato está rota: ¡arréglela y la imagen revelará la respuesta de texto oculta!
THMLHERO
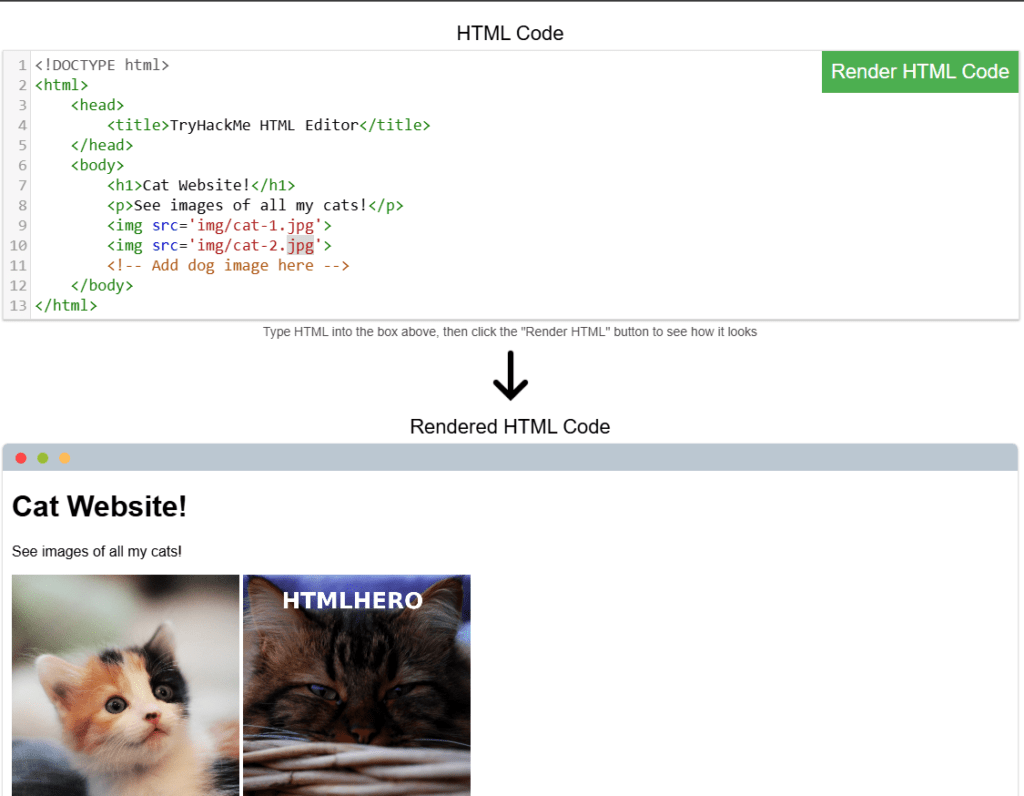
Añade la imagen de un perro a la página añadiendo otra etiqueta img (<img>) en la línea 11. La ubicación de la imagen es img/dog-1.png. ¿Qué texto contiene la imagen?
DOGHTML

JavaScript
JavaScript (JS) es uno de los lenguajes de programación más populares del mundo y permite que las páginas sean interactivas. HTML se utiliza para crear la estructura y el contenido de un sitio web, mientras que JavaScript se utiliza para controlar la funcionalidad de las páginas web. Sin JavaScript, una página no tendría elementos interactivos y siempre sería estática. JS puede actualizar la página dinámicamente en tiempo real, lo que permite cambiar el estilo de un botón cuando ocurre un evento específico (como cuando un usuario hace clic en un botón) o mostrar animaciones en movimiento.

JavaScript se agrega dentro del código fuente de la página y se puede cargar dentro de las etiquetas o se puede incluir de forma remota con el atributo src: <script><script src=»/location/of/javascript_file.js»></script>
El siguiente código JavaScript encuentra un elemento HTML en la página con el id «demo» y cambia el contenido del elemento a «Hack the Planet»: document.getElementById(«demo»).innerHTML = «Hack the Planet»;
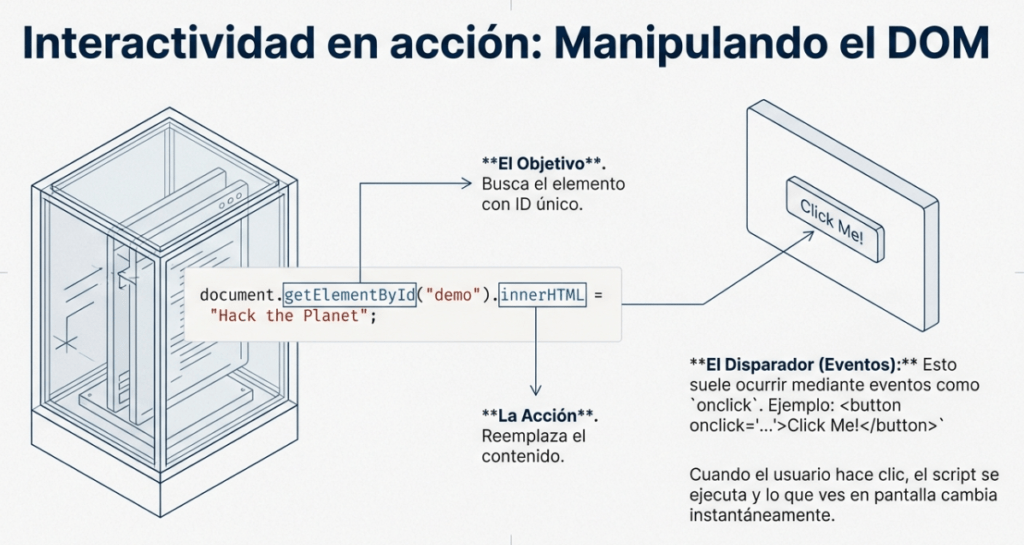
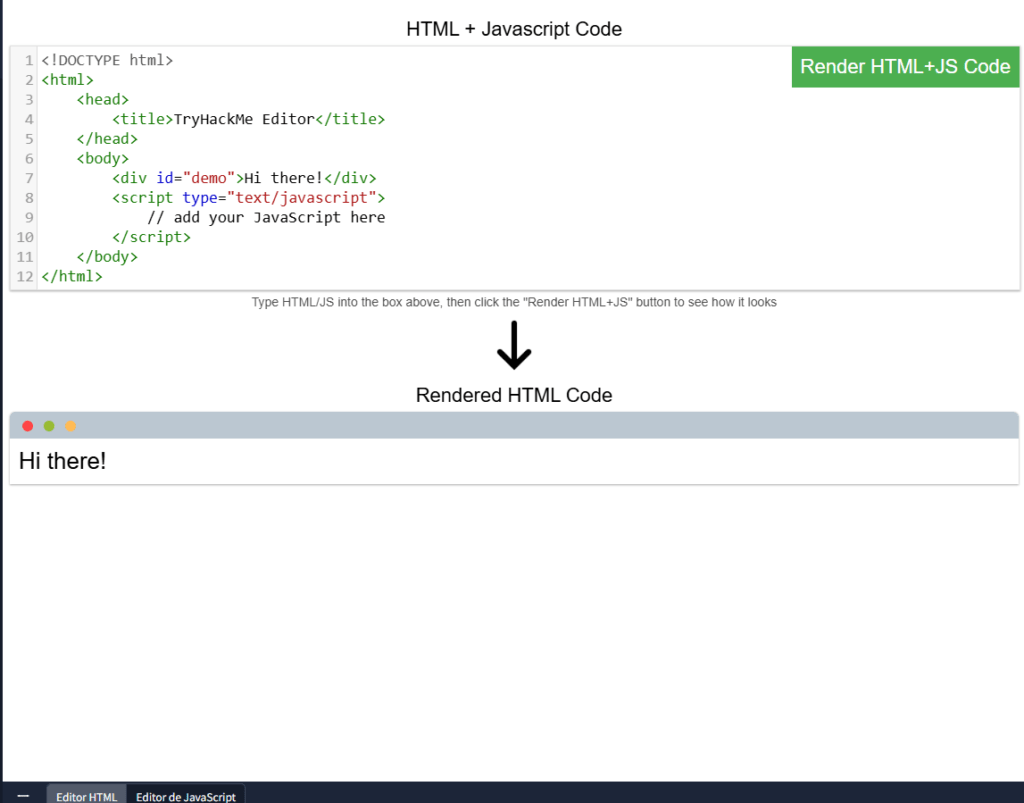
Los elementos HTML también pueden tener eventos, como «onclick» o «onhover», que ejecutan JavaScript cuando se produce el evento. El siguiente código cambia el texto del elemento con el ID de demostración a «Botón pulsado»: Los eventos «onclick» también pueden definirse dentro de las etiquetas de script de JavaScript, y no directamente en los elementos. <button onclick=’document.getElementById(«demo»).innerHTML = «Button Clicked»;’>Click Me!</button>
Responda las preguntas a continuación
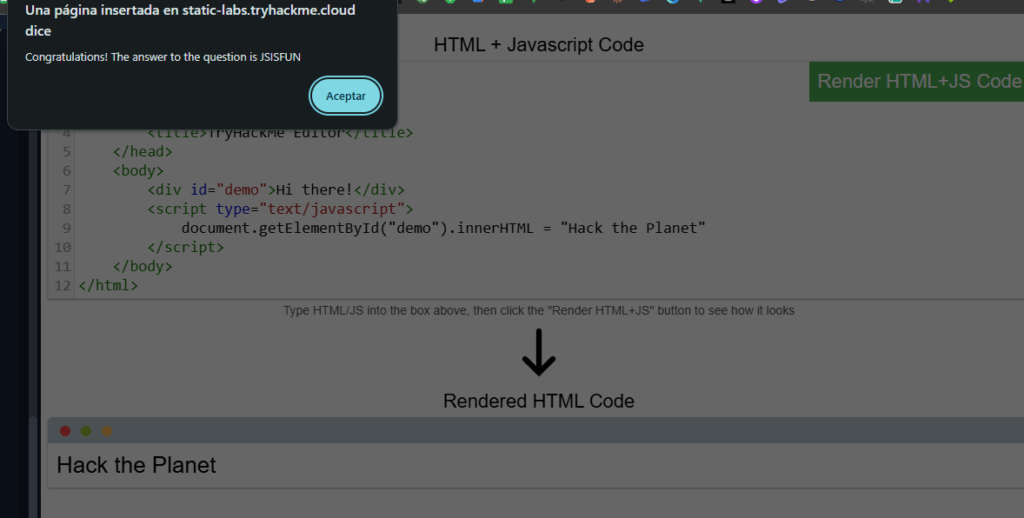
Haz clic en el botón «Ver sitio» en esta tarea. A la derecha, agrega JavaScript que cambie el contenido del elemento de demostración a «Hack the Planet».
JSISFUN
Agregue el botón HTML de esta tarea que cambia el texto del elemento a «Botón hecho clic» en el editor de la derecha, actualice el código haciendo clic en el botón «Renderizar código HTML+JS» y luego haga clic en el botón.
Exposición de datos confidenciales
La exposición de datos confidenciales ocurre cuando un sitio web no protege (o elimina) adecuadamente la información confidencial en texto claro para el usuario final; generalmente se encuentra en el código fuente del frontend de un sitio.
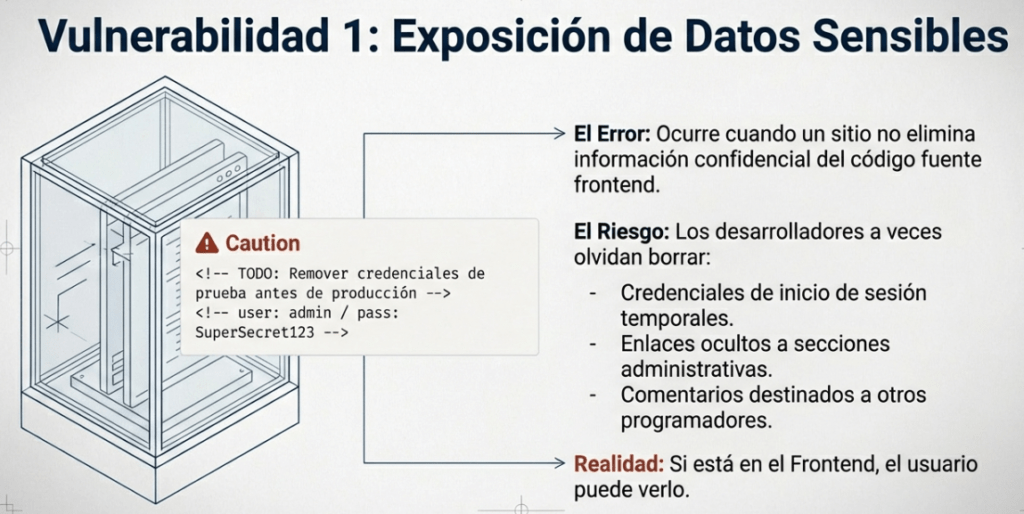
Sabemos que los sitios web se crean con muchos elementos HTML (etiquetas), todos los cuales podemos ver simplemente al ver el código fuente de la página. Es posible que un desarrollador web haya olvidado eliminar las credenciales de inicio de sesión, los enlaces ocultos a secciones privadas del sitio web u otros datos confidenciales que se muestran en HTML o JavaScript.
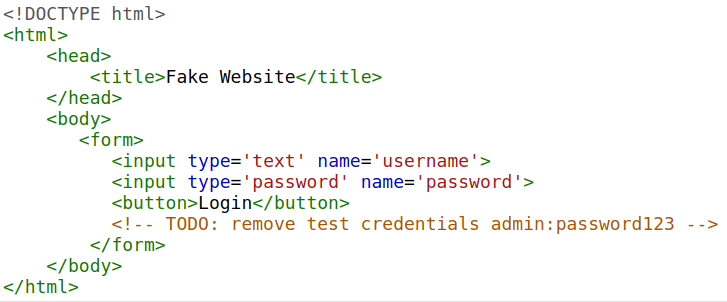
La información confidencial puede utilizarse para facilitar el acceso de un atacante a diferentes partes de una aplicación web.
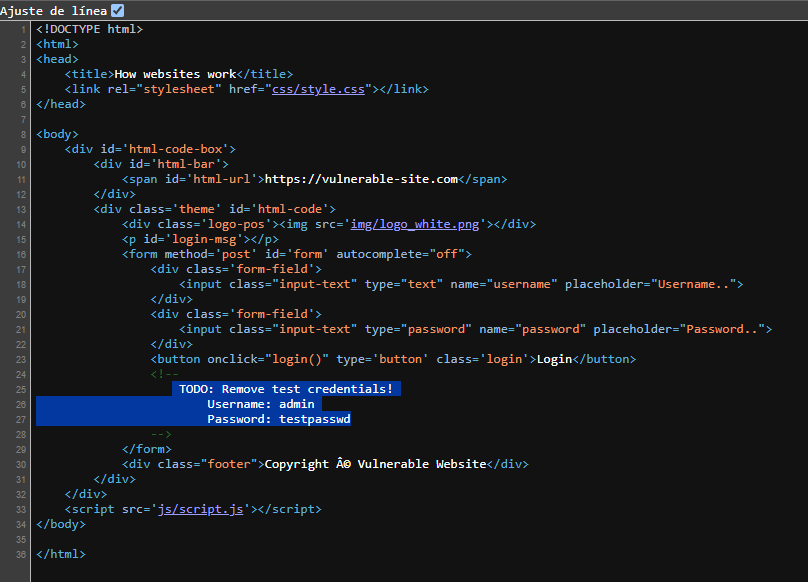
Por ejemplo, podría haber comentarios HTML con credenciales de inicio de sesión temporales, y si al consultar el código fuente de la página se encuentra esto, podría usar estas credenciales para iniciar sesión en otra parte de la aplicación (o peor aún, para acceder a otros componentes del backend del sitio). Siempre que evalúe una aplicación web en busca de problemas de seguridad, una de las primeras cosas que debe hacer es revisar el código fuente de la página para ver si puede encontrar credenciales de inicio de sesión expuestas o enlaces ocultos.
Esa misma apertura que permite la existencia de la web es la que castiga el descuido. Existe un riesgo crítico llamado Sensitive Data Exposure (Exposición de Datos Sensibles), que no es más que el resultado de la distracción humana. En la prisa por lanzar un sitio, es común que se dejen migajas de información crítica en el código que llega al usuario final.
«Un desarrollador de sitios web puede haber olvidado eliminar credenciales de inicio de sesión, enlaces ocultos a partes privadas del sitio web u otros datos confidenciales.»
Desde comentarios en el HTML con contraseñas temporales hasta etiquetas de imágenes (<img>) que revelan rutas de archivos privados, el código fuente puede ser una mina de oro para un atacante. Lo que para un desarrollador fue una nota mental olvidada, para un experto en seguridad es una puerta abierta.
Responda las preguntas a continuación
Visita el sitio web en este enlace . ¿Cuál es la contraseña oculta en el código fuente?
testpasswd
Inyección de HTML
La inyección HTML es una vulnerabilidad que se produce cuando se muestra información del usuario sin filtrar en la página. Si un sitio web no depura la información del usuario (filtra cualquier texto malicioso que este introduzca) y dicha información se utiliza en la página, un atacante puede inyectar código HTML en un sitio web vulnerable.
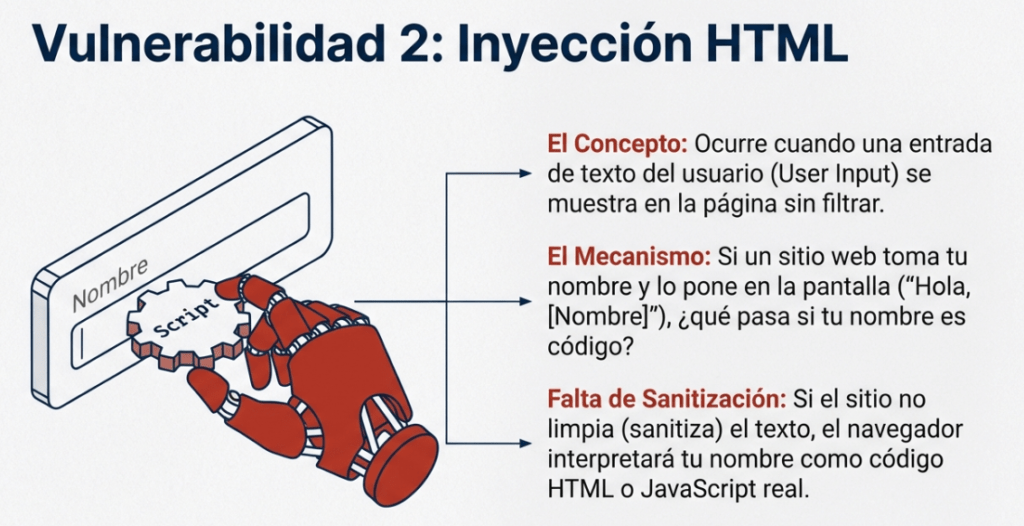
La desinfección de la entrada es fundamental para mantener la seguridad de un sitio web, ya que la información que un usuario introduce suele utilizarse en otras funciones del frontend y del backend. Una vulnerabilidad que explorarás en otro laboratorio es la inyección de bases de datos, donde se puede manipular una consulta de búsqueda en la base de datos para iniciar sesión como otro usuario controlando la entrada que se utiliza directamente en la consulta. Por ahora, centrémonos en la inyección HTML (que se realiza del lado del cliente).
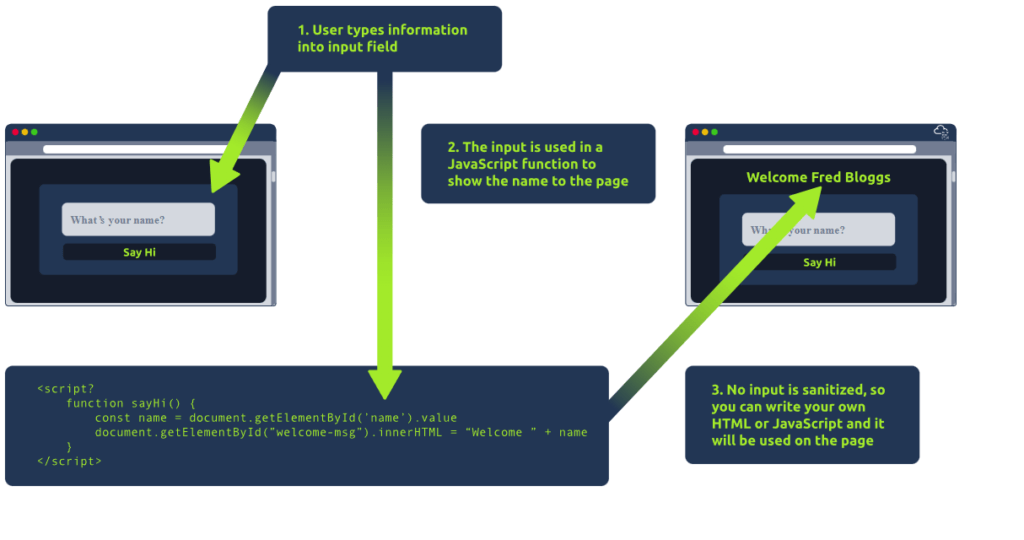
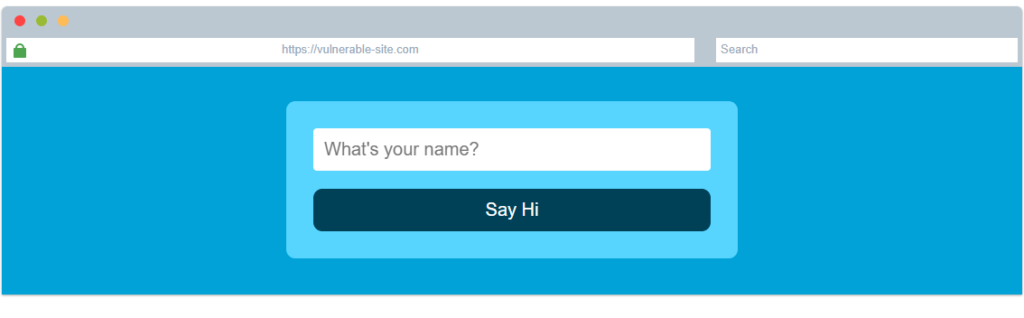
Cuando un usuario tiene control de cómo se muestra su entrada, puede enviar código HTML (o JavaScript) y el navegador lo usará en la página, lo que le permitirá controlar la apariencia y la funcionalidad de la página. La imagen de arriba muestra cómo un formulario envía texto a la página. Lo que el usuario introduce en el campo «¿Cuál es tu nombre?» se pasa a una función JavaScript y se muestra en la página. Esto significa que si el usuario añade su propio HTML o JavaScript en el campo, este se utiliza en la función sayHi y se añade a la página. Esto significa que puedes añadir tu propio HTML (como una etiqueta <h1>) y se mostrará como HTML puro.
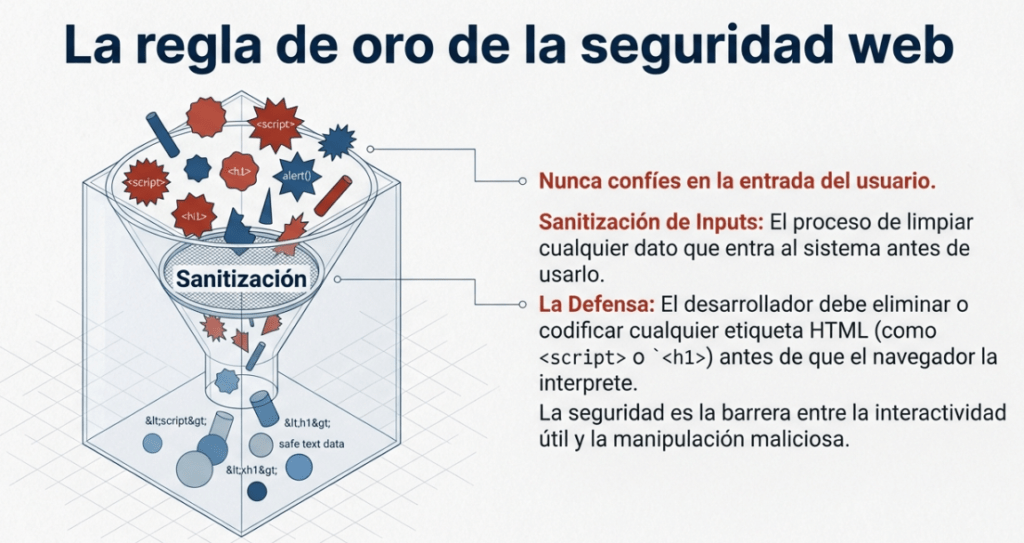
La regla general es no confiar nunca en la entrada del usuario. Para evitar entradas maliciosas, el desarrollador del sitio web debe depurar todo lo que el usuario introduzca antes de usarlo en la función JavaScript; en este caso, el desarrollador podría eliminar cualquier etiqueta HTML.
Explicación de la imagen
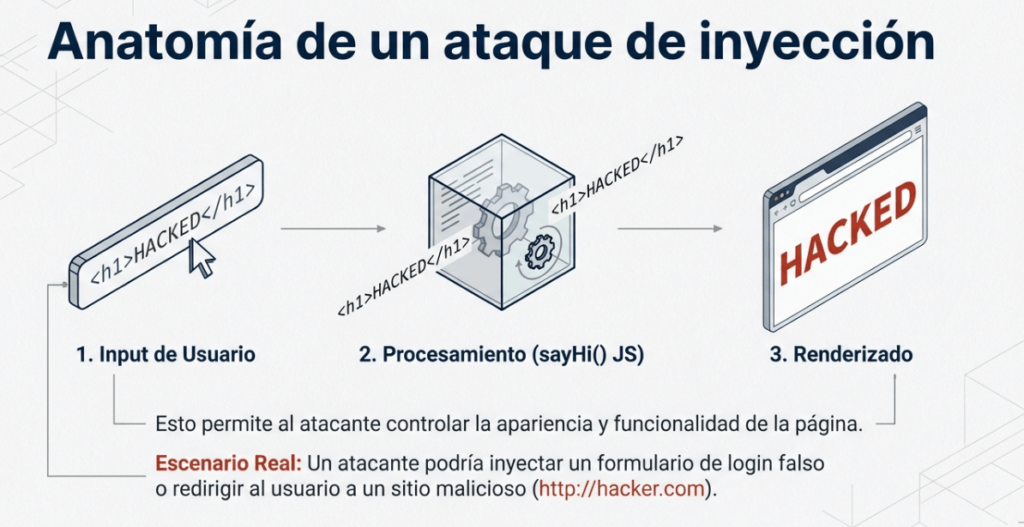
La imagen explica de forma visual cómo funciona la vulnerabilidad. Muestra el proceso paso a paso de cómo un sitio web puede ser manipulado si no valida correctamente la información que introduce el usuario.
En el primer paso, el usuario escribe su nombre en un campo de texto dentro de una página web. Este dato se almacena en una variable mediante una función en JavaScript, como se observa en el código que aparece en la parte inferior de la imagen. El segundo paso indica que esa información se utiliza directamente dentro de la página para mostrar un mensaje de bienvenida, usando la propiedad innerHTML para insertar el texto dinámicamente en el documento.
El problema surge en el tercer paso, donde se señala que no existe ningún tipo de sanitización o validación sobre la entrada del usuario. Esto significa que, si en lugar de escribir un nombre común se introduce código HTML o JavaScript, el navegador lo interpretará y ejecutará. Este comportamiento permite que un atacante inyecte código malicioso dentro de la página, lo cual podría manipular su contenido, robar cookies o ejecutar acciones en nombre del usuario.
Esta representación es perfecta para entender cómo un simple descuido en la manipulación de entradas puede abrir la puerta a un ataque XSS, resaltando la importancia de validar y escapar cualquier dato que provenga del usuario antes de mostrarlo en una aplicación web.
La vulnerabilidad más ilustrativa de la fragilidad web es la Inyección HTML. Ocurre cuando un sitio es «ingenuo» y acepta lo que el usuario escribe en un formulario como si fuera código legítimo. Si el sitio no aplica una «sanitización» (el proceso de filtrar etiquetas maliciosas), un atacante puede inyectar su propio HTML o JavaScript.
Esto es, en esencia, un secuestro de la apariencia y funcionalidad de la página. Al tratar la entrada del usuario como código, el navegador —que es obediente por naturaleza— ejecuta esas instrucciones extrañas, permitiendo desde bromas pesadas hasta el robo de información. La lección para todo desarrollador es clara: en el momento en que permites que un usuario toque tu código sin supervisión, dejas de ser el dueño de tu propio sitio.
Tarea
Responda las preguntas a continuación
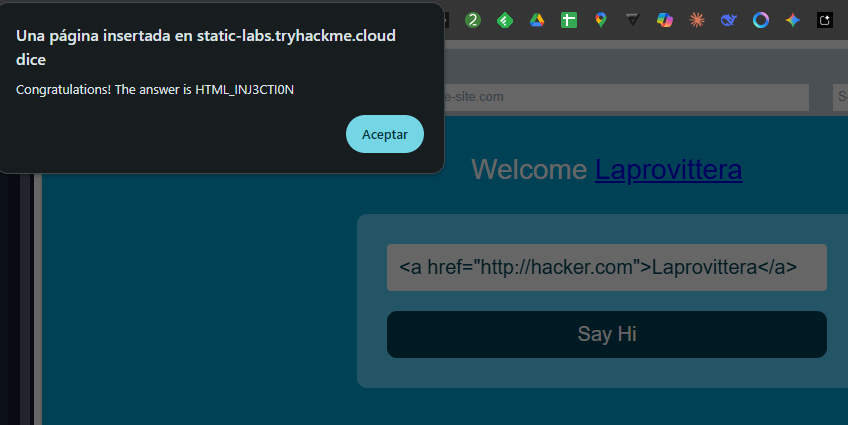
Vea el sitio web en esta tarea e inyecte HTML para que se muestre un enlace malicioso a http://hacker.com.
HTML_INJ3CTI0N
Finalizamos!
Cuando terminan toda la ruta les da un certificado

Resumen del artículo (para facilitar su comprensión)
- Modelo cliente-servidor: El navegador (cliente) hace una request y el servidor responde con datos (response).
- Componentes de un sitio:
- Front End: lo visible en el navegador —HTML (estructura), CSS (estilos) y JavaScript (interactividad).
- Back End: lógica del servidor, base de datos, APIs y control de acceso.
- HTML básico: etiquetas, <!DOCTYPE html>, <html>, <head>, <body>, atributos class e id. Puedes inspeccionar cualquier web con “Ver código fuente”.
- Prácticas interactivas del laboratorio: arreglar una imagen rota añadiendo <img>, insertar una imagen extra (ej. img/dog-1.png) y leer texto oculto en la imagen para obtener pistas.
- JavaScript y DOM: document.getElementById(…).innerHTML puede cambiar contenido dinámicamente; los eventos (onclick) disparan funciones. Entender esto te permite manipular la página durante pruebas.
- Exposición de datos confidenciales: los desarrolladores a veces dejan contraseñas, claves o enlaces ocultos en HTML/JS —buscar en el código fuente puede revelar credenciales (ej.: testpasswd).
- Inyección HTML / XSS (cliente): cuando la entrada del usuario se inserta en la página sin sanitizar, se puede inyectar HTML o JS. Ejemplo práctico del laboratorio: introducir un payload que muestre un enlace malicioso a http://hacker.com.
- Consejos de defensa (breve): eliminar secretos del frontend, validar y escapar toda entrada del usuario, usar políticas de seguridad (CSP), almacenamiento seguro de credenciales y least privilege en el backend.
- Objetivo del laboratorio: combinar teoría y ejercicios prácticos para que sepas tanto cómo construir/analizar páginas como reconocer y explotar fallos básicos de seguridad.
Qué aprendiste
Has aprendido los cimientos técnicos que todo hacker necesita: cómo el navegador y el servidor se hablan, cómo se construyen las páginas con HTML/CSS/JS y por qué errores comunes (imágenes rotas, secretos en el código, uso de innerHTML sin sanitizar) son vectores de ataque. Esto te será útil para más adelante poder:
- Auditar interfaces web de forma más eficiente (buscar credenciales expuestas, endpoints ocultos).
- Diseñar y ejecutar pruebas de inyección HTML/XSS en entorno controlado.
- Comunicar hallazgos con recomendaciones claras (qué corregir y por qué).
Entender cómo se construye la web no es solo para programadores; es una herramienta de autodefensa. Al comprender que lo que vemos es solo el resultado de un conjunto de instrucciones públicas y a veces mal protegidas, nuestra relación con la tecnología cambia. Dejamos de ser consumidores pasivos para convertirnos en observadores críticos.
Sigan practicando: inspecciona código fuente, juega con el DOM en la consola del navegador y crea payloads simples para entender el impacto. Con estos cimientos podrás avanzar a pruebas más avanzadas (autenticación, sesiones, inyección SQL, CSRF, etc.) y convertirte en un pentester más eficaz. ¡Bien hecho y a seguir aprendiendo!
Sigan entrenando, Hacketones, Nos vemos en el próximo laboratorio!!!