
En este capítulo entenderás qué es El protocolo HTTP, cómo fluye una petición–respuesta entre navegador y servidor, qué papel juegan métodos, cabeceras, URLs y versiones del protocolo (HTTP/1.1 vs HTTP/2), y por qué HTTP es sin estado. También verás proxies y cómo inspeccionar tráfico con Wireshark.
Esto es clave para tu carrera como hacker/pentester porque te permite interceptar, leer y manipular tráfico de forma controlada, detectar fallos de configuración (p. ej., Content-Type incorrecto), comprender vectores de ataque basados en parámetros de URL/cabeceras y distinguir limitaciones de HTTP que justifican el uso de HTTPS/TLS.
El protocolo HTTP
HTTP es el protocolo que se utiliza al visitar un sitio web, desarrollado por Tim Berners-Lee y su equipo entre 1989 y 1991. HTTP es el conjunto de reglas que se utilizan para comunicarse con servidores web y transmitir datos de páginas web, ya sean HTML, imágenes, vídeos, etc.
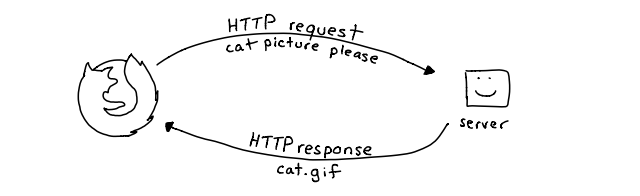
La imagen muestra de forma sencilla cómo funciona una comunicación básica entre un navegador web y un servidor usando el protocolo HTTP. A la izquierda se representa un navegador (Firefox) y a la derecha un servidor con una cara sonriente.
El proceso se divide en dos partes: primero, el navegador realiza una petición HTTP (HTTP request) al servidor solicitando un recurso, en este caso una “cat picture please” o “una imagen de gato, por favor”. Luego, el servidor recibe esa petición, la procesa y responde con una respuesta HTTP (HTTP response) que contiene el recurso solicitado, identificado aquí como “cat.gif”.
Este intercambio representa el flujo básico de cómo funciona la web: el cliente (navegador) pide información y el servidor la entrega. Es un ciclo simple pero fundamental para entender cómo se comunican los dispositivos en Internet y cómo se cargan las páginas y los archivos en el navegador.
- HTTP (Protocolo de transferencia de hipertexto) es un protocolo de capa de aplicación sin estado que se utiliza para la transmisión de recursos como datos de aplicaciones web y se ejecuta sobre TCP.
- Fue diseñado específicamente para la comunicación entre navegadores web y servidores web.
- HTTP utiliza la arquitectura típica cliente-servidor para la comunicación, donde el navegador es el cliente y el servidor web es el servidor.
- Los recursos se identifican de forma única con una URL/URI.

Peticiones web y cabeceras HTTP
La imagen muestra una situación común cuando se trabaja con peticiones web y cabeceras HTTP. A la izquierda aparece un servidor que dice “here’s an HTTP response!”, indicando que ha enviado una respuesta al cliente. A la derecha, una persona analiza esa respuesta y piensa: “that response has the wrong Content-Type header, that’s why the website isn’t working!”, es decir, “esa respuesta tiene un encabezado Content-Type incorrecto, por eso el sitio web no funciona”.
El dibujo ilustra la importancia de las cabeceras HTTP, en especial la de Content-Type, que le indica al navegador o cliente qué tipo de contenido está recibiendo (por ejemplo, texto HTML, una imagen, o un archivo JSON). Si esta cabecera está mal configurada, el navegador puede interpretar los datos de forma incorrecta y provocar errores en la visualización o funcionamiento del sitio. Es un ejemplo claro de cómo pequeños detalles en la configuración del servidor pueden afectar el comportamiento completo de una aplicación web.
HTTPS es la versión segura de HTTP . Los datos HTTPS están cifrados, lo que no solo impide que otros vean los datos que recibes y envías, sino que también te garantiza que te estás comunicando con el servidor web correcto y no con alguien que lo suplanta.
No te preocupes si no comprendes todo ahora todo esto tendrá más sentido en los próximos capítulos en donde profundizaremos en arquitectura, HTTP y HTML. Las aplicaciones web utilizan muchos protocolos diferentes, el más común de los cuales es HTTP. Este curso presupone que tienes conocimientos básicos sobre los protocolos de Internet y su uso, pero este módulo y el siguientes profundizan en los componentes de protocolos como HTTP que encontrarás en casi todas las aplicaciones web.
Veamos algunos datos y definiciones antes de pasar a los detalles sobre HTTP:
- El protocolo HTTP 1.1 está definido en los RFC 7230-7235.
- En los ejemplos de este módulo, cuando nos referimos a un servidor HTTP , básicamente nos referimos a un servidor web .
- Cuando nos referimos a clientes HTTP , hablamos de navegadores, servidores proxy, clientes API y otros programas clientes HTTP personalizados.
- HTTP es un protocolo muy simple, lo cual es al mismo tiempo bueno y malo.
- En la mayoría de los casos, HTTP se clasifica como un protocolo sin estado que no depende de una conexión persistente para la lógica de comunicación.
- Una transacción HTTP consiste en una única solicitud de un cliente a un servidor, seguida de una única respuesta del servidor al cliente.
- HTTP es diferente de los protocolos con estado, como FTP, SMTP, IMAP y POP. Cuando un protocolo es con estado, las secuencias de comandos relacionados se tratan como una única interacción.
- Un servidor debe mantener el estado de su interacción con el cliente durante la transmisión de comandos sucesivos hasta que finalice la interacción.
- Una secuencia de comandos transmitidos y ejecutados a menudo se denomina sesión.
Comprender el protocolo es muy importante para comprender bien las pruebas de seguridad. Podrá apreciar la importancia del protocolo cuando interceptemos los datos de los paquetes entre el servidor web y el cliente. El Protocolo de transferencia de hipertexto (HTTP) es un protocolo de nivel de aplicación para sistemas de información hipermedia distribuidos y colaborativos. Es la base de la comunicación de datos para la World Wide Web desde 1990. HTTP es un protocolo genérico y sin estado que también se puede utilizar para otros fines mediante la ampliación de sus métodos de solicitud, códigos de error y encabezados. Básicamente, HTTP es un protocolo de comunicación basado en TCP/IP que se utiliza para enviar datos como archivos HTML, archivos de imágenes, resultados de consultas, etc. a través de la web. Proporciona una forma estandarizada para que las computadoras se comuniquen entre sí. La especificación HTTP especifica cómo se envían los datos solicitados por los clientes al servidor y cómo responden los servidores a estas solicitudes.
Caracteristicas basicas
Hay tres características básicas que hacen de HTTP un protocolo simple pero poderoso:
- HTTP no tiene conexión: el cliente HTTP, es decir, el navegador, inicia una solicitud HTTP. Después de realizar la solicitud, el cliente se desconecta del servidor y espera una respuesta. El servidor procesa la solicitud y restablece la conexión con el cliente para enviar la respuesta.
- El protocolo HTTP es independiente del medio: se puede enviar cualquier tipo de datos mediante HTTP siempre que tanto el cliente como el servidor sepan cómo manejar el contenido de los datos. Esto es necesario tanto para el cliente como para el servidor para especificar el tipo de contenido utilizando el tipo MIME adecuado.
- HTTP no tiene estado: HTTP no tiene conexión y esto es un resultado directo de que HTTP es un protocolo sin estado. El servidor y el cliente solo se conocen durante una solicitud actual. Después, ambos se olvidan el uno del otro. Debido a esta naturaleza del protocolo, ni el cliente ni el navegador pueden retener información entre diferentes solicitudes en las páginas web.
URL, URI & URN
Al acceder a un sitio web, el navegador deberá solicitar recursos como HTML e imágenes a un servidor web y descargar las respuestas. Antes de eso, debe indicarle al navegador cómo y dónde acceder a estos recursos; para ello son útiles las URL.
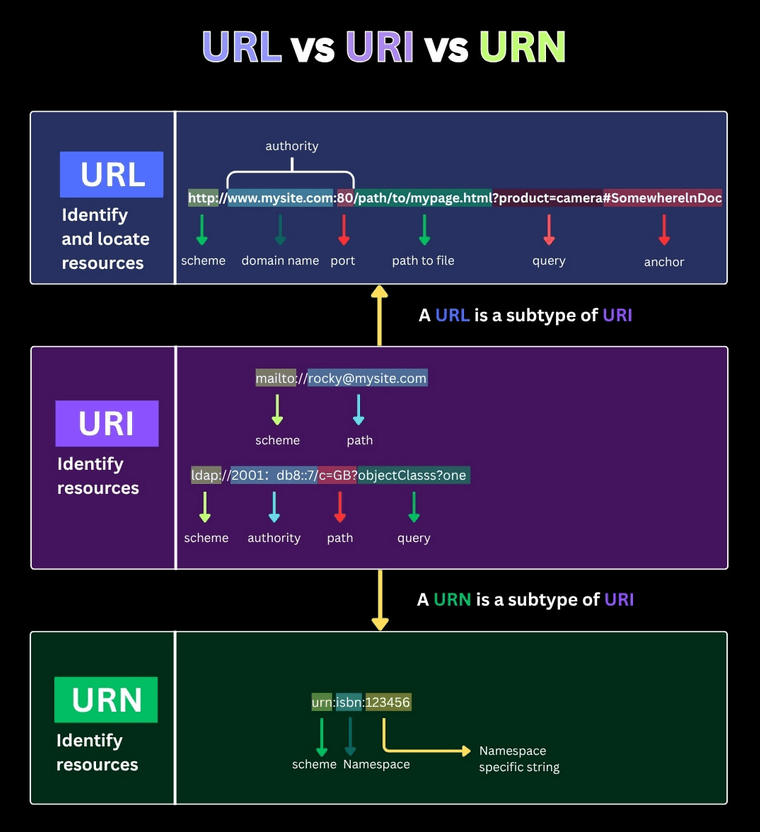
La imagen explica de manera visual y clara la diferencia entre URL, URI y URN, tres conceptos fundamentales en la identificación de recursos dentro de la web.
En la parte superior se muestra la URL (Uniform Resource Locator), que se utiliza para identificar y localizar recursos en Internet. Un ejemplo es http://www.mysite.com:80/path/to/mypage.html?product=camera#SomewhereInDoc. Esta estructura se compone de varios elementos: el esquema (http), el nombre de dominio (www.mysite.com), el puerto (80), la ruta al archivo, los parámetros de consulta (product=camera) y el ancla (#SomewhereInDoc). La URL no solo identifica el recurso, sino que también indica dónde encontrarlo.
Debajo aparece la URI (Uniform Resource Identifier), que sirve para identificar recursos sin necesariamente indicar su ubicación física. Por ejemplo, mailto://rocky@mysite.com o ldap://2001:db8::7/c=GB?objectClass?one. Aquí vemos que una URI puede contener un esquema, autoridad, ruta y parámetros, pero su propósito principal es identificar, no localizar. La imagen resalta que una URL es un subtipo de URI, lo que significa que toda URL es una URI, pero no todas las URI son URLs.
Finalmente, en la parte inferior se muestra la URN (Uniform Resource Name), otro subtipo de URI. Una URN, como urn:isbn:123456, también identifica un recurso, pero de forma única y persistente, sin depender de su ubicación. Utiliza un esquema (urn) y un espacio de nombres (por ejemplo, isbn) que permite referirse al recurso incluso si su dirección cambia.
En conjunto, la imagen resume que URI es el concepto general para identificar recursos, mientras que URL y URN son tipos específicos de URI que cumplen funciones distintas: localizar o nombrar recursos, respectivamente.
Estructura de URL HTTP (URL – Localizador Uniforme de Recursos)
HTTP y otros protocolos utilizan URL, y seguramente esté familiarizado con ellas porque las utiliza todos los días. En esta sección se explican los elementos de una URL para que pueda comprender mejor cómo abusar de algunos de estos parámetros y elementos desde una perspectiva de seguridad ofensiva. Considere la URL https://theartofhacking.org:8123/dir/test;id=89?name=omar&x=true . Desglosemos esta URL en sus partes componentes:
Esquema / Scheme
El esquema es el protocolo utilizado para acceder al sitio web. Los más comunes son HTTP (Protocolo de Transferencia de Hipertexto) y HTTPS (Protocolo Seguro de Transferencia de Hipertexto). HTTPS es más seguro porque cifra la conexión, por lo que los navegadores y los expertos en ciberseguridad lo recomiendan. Los sitios web suelen implementar HTTPS para mayor protección. También podría ser FTP (Protocolo de transferencia de archivos). Entonces el esquema es la parte de la URL que designa el protocolo subyacente que se utilizará (por ejemplo, HTTP, FTP); va seguida de dos puntos y dos barras diagonales ( // ). En este ejemplo, el esquema es http.
Usuario / User
Algunos servicios requieren autenticación para iniciar sesión, puedes poner un nombre de usuario y contraseña en la URL para iniciar sesión. Esto ocurre principalmente en URL que requieren credenciales para acceder a ciertos recursos. Sin embargo, hoy en día es poco común, ya que incluir los datos de inicio de sesión en la URL no es muy seguro y puede exponer información confidencial, lo cual supone un riesgo para la seguridad.
Host
Esta es la dirección IP (numérica o basada en DNS) del servidor web al que se accede; generalmente, aparece después de dos puntos y dos barras diagonales. En este caso, el host es theartofhacking.org .
Cada nombre de dominio debe ser único y se registra a través de registradores de dominios. Desde el punto de vista de la seguridad, busque nombres de dominio que se parezcan a los reales, pero que presenten pequeñas diferencias (esto se denomina typosquatting ). Estos dominios falsos se utilizan a menudo en ataques de phishing para engañar a los usuarios y conseguir que proporcionen información confidencial.
Puerto / Port
El puerto al que se va a conectar, normalmente 80 para HTTP y 443 para HTTPS, pero puede estar alojado en cualquier puerto entre 1 y 65535. Es como indicarle al servidor qué puerta de enlace usar para la comunicación.
Ruta / path:
El nombre del archivo o la ubicación del recurso al que intenta acceder. Esta es la ruta desde el directorio “raíz” del servidor hasta el recurso deseado. En este caso, puede ver que hay un directorio llamado dir . (Tenga en cuenta que, en realidad, los servidores web pueden usar alias para señalar documentos, puertas de enlace y servicios a los que no se puede acceder explícitamente desde el directorio raíz del servidor).
Cadena de consulta / path-segment-params
Información adicional que se puede enviar a la ruta solicitada. Por ejemplo, /blog? id=1 indicaría a la ruta del blog que se desea recibir el artículo con el id 1. La cadena de consulta es la parte de la URL que empieza con un signo de interrogación (?). Se suele usar para términos de búsqueda o entradas de formularios. Dado que los usuarios pueden modificar estas cadenas de consulta, es importante gestionarlas de forma segura para evitar ataques como inyecciones , donde se podría añadir código malicioso.
Esta es la parte de la URL que incluye pares de nombre/valor opcionales (es decir, parámetros de segmento de ruta). Un parámetro de segmento de ruta suele ir precedido de un punto y coma (según el lenguaje de programación utilizado) y aparece inmediatamente después de la información de la ruta. En este ejemplo, el parámetro de segmento de ruta es id=89 . Los parámetros de segmento de ruta no se utilizan habitualmente. Además, cabe mencionar que estos parámetros son diferentes de los parámetros de cadena de consulta (a menudo denominados parámetros de URL ).
Fragmento/anchor
Esta es una referencia a una ubicación en la página solicitada. Se usa comúnmente en páginas con contenido extenso y puede tener una sección específica directamente vinculada, de modo que el usuario pueda verla en cuanto acceda a ella. El fragmento comienza con una almohadilla (#) y ayuda a dirigirse a una sección específica de una página web, como saltar directamente a un encabezado o tabla en particular. Los usuarios también pueden modificarlo, por lo que, al igual que con las cadenas de consulta, es importante revisar y limpiar los datos aquí para evitar problemas como ataques de inyección.
Esta parte opcional de la URL contiene pares de nombre/valor que representan parámetros dinámicos asociados con la solicitud. Estos parámetros se incluyen comúnmente en enlaces con fines de seguimiento y de configuración del contexto. También se pueden generar a partir de variables en formularios HTML. Normalmente, la cadena de consulta está precedida por un signo de interrogación. Los signos de igual (=) separan los nombres y los valores, y los símbolos & marcan los límites entre los pares de nombre/valor. En este ejemplo, la cadena de consulta es name=omar&x=true.
NOTA: La notación URL aquí se aplica a la mayoría de los protocolos (por ejemplo, HTTP, HTTPS y FTP).
Además, se utilizan otros protocolos, como HTML y CSS, en elementos como el Protocolo simple de acceso a objetos (SOAP) y las API RESTful. Algunos ejemplos son JSON, XML y el Servicio de procesamiento web (WPS) (que no es lo mismo que el WPS en las redes inalámbricas).
HTTP tiene diferentes versiones como HTTP 1.0, HTTP 1.1, HTTP 2.0…
HTTP 1.1 es la versión más utilizada de HTTP y tiene varias ventajas sobre HTTP 1.0, como la capacidad de reutilizar la misma conexión y la posibilidad de solicitar múltiples URI/recursos. Es decir, HTTP/1.0 utiliza una nueva conexión para cada intercambio de solicitud/respuesta, mientras que la conexión HTTP/1.1 puede usarse para uno o más intercambios de solicitud/respuesta.
Arquitectura
El siguiente diagrama muestra una arquitectura muy básica de una aplicación web y describe dónde reside HTTP. El protocolo HTTP es un protocolo de solicitud/respuesta basado en la arquitectura cliente/servidor donde el navegador web, los robots y los motores de búsqueda, etc., actúan como clientes HTTP y el servidor web actúa como servidor.
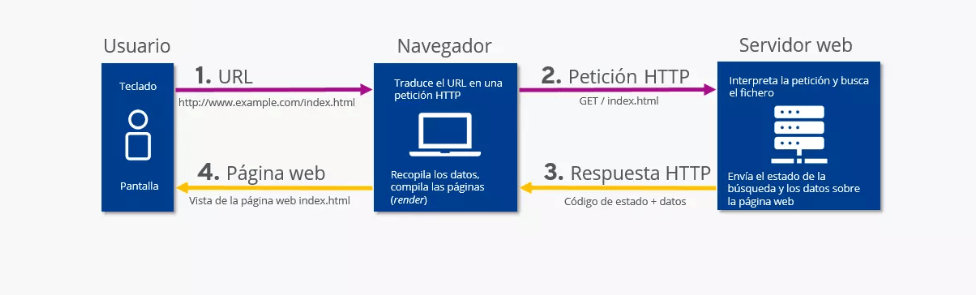
La imagen muestra de forma clara el proceso completo de cómo un usuario accede a una página web a través del navegador y cómo este se comunica con el servidor mediante el protocolo HTTP.
En el primer paso, el usuario introduce una URL (por ejemplo, http://www.example.com/index.html) en el navegador usando el teclado. Este acto es el punto de partida de toda la comunicación. A continuación, el navegador traduce esa URL en una petición HTTP, generando una solicitud al servidor donde se aloja el sitio web. Este paso se conoce como Petición HTTP (GET /index.html), y su objetivo es pedir el archivo o recurso solicitado.
El servidor web recibe esa petición, la interpreta y busca el fichero correspondiente en su sistema. Una vez localizado el recurso, genera una Respuesta HTTP que contiene el código de estado (por ejemplo, 200 si todo salió bien, o 404 si no se encontró el recurso) junto con los datos del archivo solicitado.
Finalmente, el navegador recibe la respuesta, procesa el contenido y renderiza la página web en pantalla, permitiendo al usuario visualizar index.html. Este último paso completa el ciclo de comunicación entre cliente y servidor.
En resumen, la imagen ilustra las cuatro etapas clave del funcionamiento web: el usuario solicita una URL, el navegador la convierte en una petición HTTP, el servidor responde con los datos y el navegador muestra la página. Este ciclo se repite constantemente cada vez que navegamos por Internet.
- Cliente : el cliente HTTP envía una solicitud al servidor en forma de método de solicitud, URI y versión de protocolo, seguido de un mensaje similar a MIME que contiene modificadores de solicitud, información del cliente y posible contenido del cuerpo a través de una conexión TCP/IP.
- Servidor : el servidor HTTP responde con una línea de estado, que incluye la versión del protocolo del mensaje y un código de éxito o error, seguido de un mensaje similar a MIME que contiene información del servidor, metainformación de la entidad y posible contenido del cuerpo de la entidad.
Los servidores proxy HTTP
Los servidores proxy HTTP actúan como servidores y clientes. Tambien realizan solicitudes a servidores web en nombre de otros clientes. Permiten transferencias HTTP a través de firewalls y también pueden proporcionar soporte para el almacenamiento en caché de mensajes HTTP. Los servidores proxy pueden realizar otras funciones en entornos complejos, como la traducción de direcciones de red (NAT) y el filtrado de solicitudes HTTP. NOTA: Más adelante en este módulo, aprenderá a utilizar herramientas como Burp Suite y el proxy ZAP para interceptar comunicaciones entre un navegador o un cliente y un servidor web.
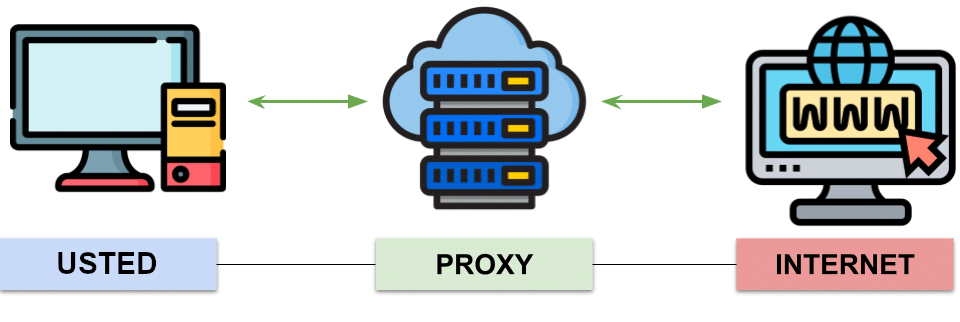
La Figura muestra una topología muy simple que incluye un cliente, un proxy y un servidor web (HTTP). Representa de manera sencilla cómo funciona un servidor proxy en la comunicación entre un usuario y el Internet.
A la izquierda se encuentra el equipo del usuario, que envía sus solicitudes de navegación o peticiones web. En lugar de conectarse directamente con los servidores de Internet, estas solicitudes pasan primero por un proxy, ilustrado en el centro con una imagen de servidores dentro de una nube. El proxy actúa como intermediario entre el usuario y la red, reenviando las peticiones hacia Internet y devolviendo las respuestas correspondientes.
A la derecha se muestra el Internet, simbolizado por un monitor con el icono del “www”. Cuando el proxy recibe la respuesta de la web solicitada, la reenvía nuevamente al usuario, completando el ciclo de comunicación.
Este proceso tiene varias ventajas: puede ocultar la dirección IP real del usuario, filtrar contenido, mejorar la seguridad y almacenar en caché recursos web para acelerar el acceso a páginas visitadas con frecuencia. En el contexto del hacking ético y el pentesting, entender cómo funciona un proxy es fundamental, ya que permite interceptar, analizar y modificar las solicitudes y respuestas HTTP, facilitando la detección de vulnerabilidades o comportamientos anómalos en las aplicaciones web.
Solicitud HTTP
HTTP es un protocolo de nivel de aplicación del conjunto de protocolos TCP/IP y utiliza TCP como protocolo de capa de transporte subyacente para transmitir mensajes. HTTP utiliza un modelo de solicitud/respuesta, lo que básicamente significa que un programa cliente HTTP envía un mensaje de solicitud HTTP a un servidor y luego el servidor devuelve un mensaje de respuesta HTTP. El cliente y el servidor primero completan el protocolo de enlace de tres vías TCP (SYN, SYN ACK, ACK). Luego, el cliente envía una solicitud HTTP GET y el servidor responde con un ACK TCP y el contenido de la página (con una respuesta HTTP 200 OK). Cada uno de estos mensajes de solicitud y respuesta contiene un encabezado y un cuerpo del mensaje. Un mensaje HTTP (ya sea una solicitud o una respuesta) tiene una estructura que consta de un bloque de líneas que comprende el encabezado del mensaje, seguido de un cuerpo del mensaje.
Detalles de la solicitud HTTP
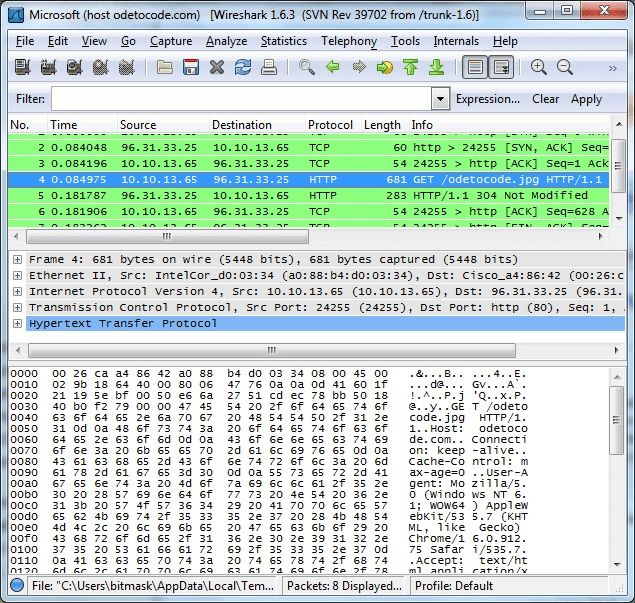
El paquete que se muestra en la Figura se recopiló con Wireshark. Como puede ver, los mensajes HTTP no están diseñados para el consumo humano y deben ser lo suficientemente expresivos para controlar servidores HTTP, navegadores y servidores proxy. Descargue Wireshark y establezca una conexión entre su navegador y cualquier servidor web. Es muy recomendable que comprenda cómo funcionan realmente los protocolos y las tecnologías detrás de escena. Una de las mejores formas de aprender esto es recopilar capturas de paquetes y analizar cómo se comunican los dispositivos.
La imagen muestra la interfaz del programa Wireshark, una herramienta ampliamente utilizada en ciberseguridad, hacking ético y análisis de redes para capturar y examinar el tráfico que circula a través de una red.
En la parte superior se observa la lista de paquetes capturados, donde cada línea representa un paquete de datos con información sobre su número, tiempo de captura, dirección de origen y destino, protocolo, longitud e información adicional. En este caso, se están analizando principalmente paquetes con los protocolos TCP y HTTP, lo que indica tráfico web entre las direcciones IP 10.10.13.65 y 96.31.33.25. Por ejemplo, uno de los paquetes muestra una petición HTTP del tipo GET solicitando el archivo /odetocode.jpg.
En el panel intermedio se muestra un desglose del paquete seleccionado, donde se detallan las capas del modelo OSI: Ethernet II (nivel de enlace), IPv4 (nivel de red), TCP (nivel de transporte) y HTTP (nivel de aplicación). Cada una de estas capas contiene información técnica específica, como direcciones MAC, direcciones IP, puertos de origen y destino, así como encabezados HTTP.
En la parte inferior se encuentra la vista hexadecimal y ASCII del paquete, que permite analizar el contenido exacto de los datos transmitidos. Esta sección es muy útil para identificar cabeceras, cookies, parámetros, credenciales o cualquier otra información sensible que viaje sin cifrar.
En resumen, esta captura de Wireshark ilustra cómo los analistas y pentesters pueden inspeccionar el tráfico de red en detalle, verificar la seguridad de las comunicaciones, detectar vulnerabilidades o estudiar el comportamiento de protocolos como HTTP. Es una herramienta esencial para entender lo que realmente ocurre “detrás de escena” cuando se navega por la web.
Métodos HTTP
Cuando los servidores HTTP y los navegadores se comunican entre sí, realizan interacciones basadas en los encabezados y el contenido del cuerpo.
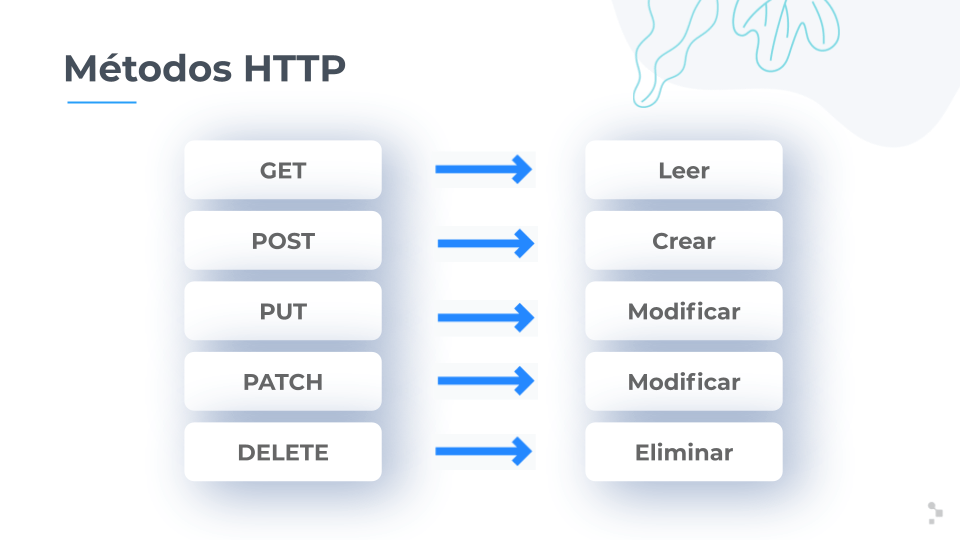
El método: En este ejemplo, el método es un HTTP GET , aunque podría ser cualquiera de los siguientes:
- GET: Recupera información del servidor
- HEAD: Básicamente lo mismo que GET pero devuelve solo encabezados HTTP y ningún cuerpo del documento
- POST: Envía datos al servidor (normalmente mediante formularios HTML, solicitudes de API, etc.)
- TRACE: Realiza una prueba de bucle de mensajes a lo largo de la ruta al recurso de destino
- PUT: Carga una representación de la URI especificada
- DELETE: Elimina el recurso especificado
- OPTIONS: Devuelve los métodos HTTP que admite el servidor
- CONNECT: Convierte la conexión de la solicitud en un túnel TCP/IP transparente.
La URI y el campo de ruta al recurso: esto representa la parte de la ruta de la URL solicitada.
El campo de número de versión de la solicitud: especifica la versión de HTTP utilizada por el cliente.
El agente de usuario: en este ejemplo, se utilizó Chrome para acceder al sitio web. En la captura de paquetes se ve lo siguiente:
Agente de usuario: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/66.0.3359.181 Safari/537.36 .
También aparecen otros campos: accept, accept-language, accept encoding y otros campos.
El servidor, tras recibir esta solicitud, genera una respuesta. La figura 6-4 muestra la respuesta HTTP. La respuesta del servidor incluye un código de estado de tres dígitos y una breve explicación legible del código de estado. Debajo de eso, puedes ver los datos de texto (que son el código HTML que regresa del servidor y muestra el contenido del sitio web).
API REST
Una API REST (o API RESTful ) es un tipo de interfaz de programación de aplicaciones (API) que se ajusta a la especificación del estilo arquitectónico de transferencia de estado representacional (REST) y permite la interacción con servicios web. Las API REST se utilizan para crear e integrar software de múltiples aplicaciones. En resumen, si desea interactuar con un servicio web para recuperar información o agregar, eliminar o modificar datos, una API lo ayuda a comunicarse con dicho sistema para cumplir con la solicitud.
Las API REST usan JSON como formato estándar para salida y solicitudes. SOAP es una tecnología más antigua utilizada en API heredadas que usan XML en lugar de JSON. La llamada a procedimiento remoto de lenguaje de marcado extensible (XML-RPC) es un protocolo en aplicaciones heredadas que usa XML para codificar sus llamadas y aprovecha HTTP como mecanismo de transporte. Las versiones actuales de HTTP son 1.1 y 2.0.
HTTP – Desventajas
- HTTP no es un protocolo completamente seguro.
- HTTP utiliza el puerto 80 como puerto predeterminado para la comunicación.
- HTTP opera en la capa de aplicación. Necesita crear múltiples conexiones para la transferencia de datos, lo que aumenta los costos administrativos.
- No se requieren certificados digitales ni cifrado para utilizar HTTP.
Por eso existe HTTPS (Hypertext Transfer Protocol over Secure Socket Layer) o HTTP sobre SSL. No es un protocolo en sí, sino mas bienel resultado de superponer el HTTP sobre SSL/TLS (Secure Socket Layer/Transport Layer Security). En resumen, HTTPS = HTTP + SSL
Resumen del artículo (para facilitar su comprensión)
- Qué es HTTP y cómo funciona: Protocolo de capa de aplicación, sin estado, sobre TCP. El cliente envía una solicitud y el servidor responde con código de estado + cuerpo. Los recursos se identifican por URL/URI.
- Ciclo básico request/response:
- El usuario introduce una URL.
- El navegador la convierte en HTTP GET /ruta.
- El servidor responde (200/404… + contenido).
- El navegador renderiza.
Un encabezado Content-Type incorrecto puede romper todo el flujo.
- Componentes de una URL:
- Esquema (http/https)
- usuario (obsoleto)
- host (DNS/IP)
- puerto (80/443 u otro)
- ruta, parámetros de segmento
- query string (?a=b&c=d)
- fragmento (#anchor).
Atención a typosquatting y a inputs manipulables (query/fragmento) → riesgo de inyecciones.
- Características clave de HTTP:
- Sin conexión (cada transacción es independiente).
- Independiente del medio (cualquier tipo de dato con su MIME adecuado).
- Sin estado (no recuerda contexto entre peticiones; la “sesión” la construyen capas superiores).
- Métodos HTTP principales: GET, HEAD, POST, PUT, DELETE, OPTIONS, TRACE, CONNECT. Cada método implica semánticas y superficies de ataque distintas.
- Versiones del protocolo:
- HTTP/1.1: reutiliza conexión, pero solicitudes secuenciales; múltiples recursos pueden implicar varias peticiones.
- HTTP/2: multiplexación en una única conexión TCP, menor latencia y mejor rendimiento.
- Proxies HTTP: Actúan como intermediarios (caché, filtrado, NAT, anonimización). En pentesting se usan Burp/ZAP para interceptar, modificar y repetir peticiones.
- Análisis con Wireshark: Permite ver capas (Ethernet/IP/TCP/HTTP), cabeceras, cookies, parámetros e incluso credenciales cuando el tráfico no está cifrado.
- APIs REST: Uso común de JSON sobre HTTP para CRUD. También existen SOAP/XML y XML-RPC en legados. Entender los intercambios HTTP es vital para probar APIs.
- Limitaciones y seguridad: HTTP no cifra ni autentica por sí mismo → susceptible a escucha y manipulación. De ahí HTTPS = HTTP + TLS para confidencialidad, integridad y autenticación.
10 PREGUNTAS BASADAS EN EL ARTÍCULO
- ¿Qué significa que HTTP es un protocolo sin estado?
- ¿Cuál es la principal diferencia entre HTTP/1.1 y HTTP/2.0?
- ¿Qué elementos componen una URL?
- ¿Qué función cumple un proxy HTTP?
- ¿Cuál es el propósito de los encabezados HTTP en una petición o respuesta?
- ¿Qué son los métodos HTTP y menciona al menos tres?
- ¿Qué es una API REST y con qué formato suelen intercambiar datos?
- ¿Qué diferencia hay entre una URL, una URI y una URN?
- ¿Cómo se estructura una solicitud HTTP?
- ¿Qué ventajas ofrece HTTP/2.0 sobre HTTP/1.1?
10 EJERCICIOS BASADOS EN EL ARTÍCULO
- Completa: HTTP es un protocolo de la capa _________ que funciona sobre ________.
- Menciona 4 partes que componen una URL estándar.
- Clasifica como “seguro” o “no seguro”:
- HTTP en Wi-Fi pública
- HTTPS con certificado
- HTTP sin autenticación
- HTTP a través de proxy
- Enumera al menos 3 características de HTTP como protocolo.
- Dibuja el flujo de una solicitud HTTP básica (GET) desde cliente a servidor.
- Indica qué protocolo o puerto corresponde a:
- HTTP
- HTTPS
- FTP
- ¿Qué hace el encabezado Content-Type en una respuesta HTTP?
- Escribe una petición HTTP tipo GET al recurso /producto?id=10 usando HTTP/1.1
- Diferencia entre GET y POST en métodos HTTP.
- ¿Qué indica un código de estado HTTP 200 y uno 404?
RESPUESTAS DETALLADAS A LAS 10 PREGUNTAS
- Protocolo sin estado:
Significa que HTTP no conserva información de solicitudes anteriores. Cada solicitud se ejecuta de manera independiente, sin recordar interacciones previas entre cliente y servidor. - Diferencia entre HTTP/1.1 y HTTP/2.0:
HTTP/1.1 utiliza una conexión por cada solicitud o múltiples solicitudes secuenciales. HTTP/2.0 permite multiplexar varias solicitudes/respuestas al mismo tiempo en una sola conexión TCP, mejorando el rendimiento. - Elementos de una URL:
- Esquema (http, https)
- Host (dominio o IP)
- Puerto
- Ruta (path)
- Parámetros de consulta
- Fragmento (anchor)
- Función de un proxy HTTP:
Actúa como intermediario entre el cliente y el servidor, permitiendo filtrado, almacenamiento en caché, ocultamiento de IP, y análisis de tráfico. - Propósito de encabezados HTTP:
Informan sobre el contenido, el navegador, el idioma, el tipo de datos, etc. Ej.: Content-Type, User-Agent, Accept. - Métodos HTTP:
- GET: Solicita información del servidor.
- POST: Envía datos al servidor.
- DELETE: Elimina un recurso.
- API REST:
Es una interfaz que permite interactuar con servicios web utilizando métodos HTTP. Suelen usar JSON como formato de intercambio de datos. - Diferencia entre URL, URI y URN:
- URI es el término general (identificador de recurso).
- URL indica dónde se encuentra el recurso.
- URN identifica el recurso de forma única, pero no indica su ubicación.
- Estructura de una solicitud HTTP:
- Línea de solicitud (método, URI, versión HTTP)
- Encabezados
- (Opcional) Cuerpo de mensaje
- Ventajas de HTTP/2.0:
- Multiplexación (varias peticiones a la vez)
- Menor latencia
- Reutilización de la misma conexión
RESPUESTAS DETALLADAS A LOS 10 EJERCICIOS
- Completa:
HTTP es un protocolo de la capa de aplicación que funciona sobre TCP. - Partes de una URL estándar:
- Esquema (https://)
- Host (www.example.com)
- Puerto (:443)
- Ruta (/pagina.html)
- Parámetros (?id=1)
- Fragmento (#seccion)
- Clasificación:
- HTTP en Wi-Fi pública → ❌ No seguro
- HTTPS con certificado → ✅ Seguro
- HTTP sin autenticación → ❌ No seguro
- HTTP a través de proxy → 🔶 Depende (mejora privacidad, pero no cifra)
- Características de HTTP:
- Sin conexión persistente
- Independiente del medio
- Sin estado
- Flujo HTTP GET:
Cliente → [GET /index.html HTTP/1.1]
Servidor → [HTTP/1.1 200 OK + contenido] - Protocolos y puertos:
- HTTP → puerto 80
- HTTPS → puerto 443
- FTP → puerto 21
- Content-Type:
Especifica el tipo de contenido que se devuelve, como text/html, application/json, etc. Sirve para que el navegador sepa cómo interpretar la respuesta. - Petición GET:
GET /producto?id=10 HTTP/1.1
Host: www.tienda.com
User-Agent: Mozilla/5.0 - Diferencias entre GET y POST:
- GET: Envía datos en la URL, es visible y se usa para obtener recursos.
- POST: Envía datos en el cuerpo, más seguro, y se usa para enviar formularios o datos sensibles.
- Código 200 vs 404:
- 200 OK → La solicitud fue exitosa.
- 404 Not Found → El recurso solicitado no existe en el servidor.
Ahora sabes….
Ahora dominas los fundamentos de HTTP: su flujo, componentes, métodos y versiones, además de cómo interceptarlo y analizarlo con proxies y Wireshark. Esto te hará más efectivo al hallar fallos de configuración, probar endpoints y explotar/mitigar vulnerabilidades ligadas a parámetros y cabeceras. En los siguientes capítulos, al añadir HTTPS/TLS, sesiones y ataques como SQLi y XSS, verás cómo este entendimiento del transporte se convierte en ventaja táctica durante tus evaluaciones de seguridad. ¡Buen trabajo!