
En este capítulo: Solicitud HTTP y Métodos de solicitud HTTP, aprenderás cómo funciona el protocolo HTTP/HTTPS —la columna vertebral de la web— y por qué cada parte de una request y una response (línea de inicio, encabezados, línea vacía y cuerpo) es esencial para entender seguridad web. Veremos los métodos HTTP más importantes (GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS, CONNECT, TRACE) y qué significan los encabezados y el body para rendimiento y vulnerabilidades. Esto es fundamental para cualquier hacker ético o pentester: muchas fallas reales (Host header injection, XSS, CSRF, request smuggling, IDOR, fugas por compresión, etc.) se descubren manipulando exactamente este intercambio de mensajes.
HTTP Protocol Basics
Durante la comunicación HTTP, el cliente y el servidor intercambian mensajes, normalmente clasificados como solicitudes y respuestas HTTP. Esta imagen representa el flujo básico de comunicación entre un navegador (cliente) y un servidor web mediante los protocolos HTTP o HTTPS, que son la base del funcionamiento de la web.
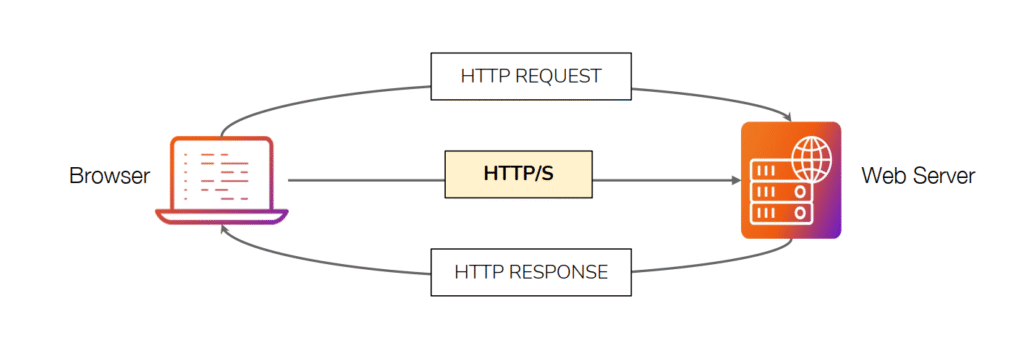
La imagen muestra de manera clara el proceso de comunicación entre un navegador (Browser) y un servidor web (Web Server) utilizando el protocolo HTTP o HTTPS. Este esquema es la base de cómo funcionan las páginas web en Internet y explica el intercambio de información entre el cliente y el servidor.
El flujo comienza cuando el navegador envía una petición HTTP (HTTP Request) al servidor. Esta solicitud puede ser, por ejemplo, pedir una página web, una imagen o un archivo. El servidor recibe esa petición, la procesa y devuelve una respuesta HTTP (HTTP Response) que contiene los datos solicitados, como el código HTML de una página o el resultado de una búsqueda.
En el centro del diagrama aparece el protocolo HTTP/S, que es el encargado de establecer la comunicación entre ambas partes. La “S” de HTTPS indica que la conexión está cifrada mediante SSL/TLS, ofreciendo una capa de seguridad que protege la información que viaja entre el navegador y el servidor.
Este intercambio continuo de peticiones y respuestas es lo que permite la navegación web. Entenderlo resulta esencial en pentesting y hacking ético, ya que muchos ataques o pruebas de seguridad —como la manipulación de cabeceras, inyección de datos o robo de cookies— se basan precisamente en interceptar o modificar este tipo de tráfico entre el cliente y el servidor.
La comunicación HTTP
El proceso comienza cuando el navegador realiza una solicitud HTTP (HTTP Request) al servidor. Esta solicitud puede ser, por ejemplo, para acceder a una página web, enviar datos de un formulario o descargar un recurso como una imagen o un archivo JavaScript. El mensaje incluye información como la dirección del recurso solicitado, los encabezados del navegador y, en algunos casos, datos del usuario.
Una vez que el servidor web recibe la solicitud, la procesa internamente —por ejemplo, ejecutando un script, accediendo a una base de datos o sirviendo un archivo estático— y genera una respuesta HTTP (HTTP Response). Esta respuesta incluye un código de estado (como 200 OK, 404 Not Found o 500 Internal Server Error) y, generalmente, el contenido solicitado (como una página HTML o un archivo JSON).
En el centro del diagrama se destaca HTTP/S, que representa la capa de comunicación.
- Cuando se usa HTTP, los datos se transmiten en texto plano, lo que permite que puedan ser interceptados.
- En cambio, HTTPS añade una capa de cifrado mediante SSL/TLS, garantizando que la información viaje de forma segura entre el navegador y el servidor.
En resumen, esta imagen simplifica el intercambio fundamental que ocurre cada vez que visitamos un sitio web: el navegador solicita un recurso, el servidor lo entrega y la comunicación viaja a través de HTTP o HTTPS, dependiendo de si está cifrada o no.
Esquemá el intercambio de información
La imagen representa de manera esquemática el intercambio de información entre un cliente y un servidor a través del protocolo HTTP, mostrando la estructura básica de una petición (request) y una respuesta (response). Este flujo es esencial para comprender cómo funciona la comunicación web y cómo se transmiten los datos entre un navegador o herramienta y un servidor.

En la parte izquierda se muestra la request, que comienza con una línea de solicitud (request line). En este caso, el cliente realiza una petición GET a la raíz del sitio examplecat.com usando el protocolo HTTP/1.1. Debajo se incluyen los headers (encabezados), que aportan información adicional como el dominio del servidor (Host), el tipo de cliente que realiza la petición (User-Agent: curl) y el tipo de contenido que acepta (Accept: */*). Estos encabezados ayudan al servidor a interpretar correctamente la solicitud y preparar la respuesta adecuada.
En la parte derecha aparece la response, que inicia con una línea de estado (status line) indicando que la solicitud fue exitosa (HTTP/1.1 200 OK). A continuación se listan los encabezados de respuesta, donde el servidor proporciona metadatos sobre el contenido, como el tipo (Content-Type: text/html), el tamaño (Content-Length), información de caché (Cache-Control), entre otros. Finalmente, en el body (cuerpo) se encuentra el contenido solicitado, en este caso un fragmento de código HTML que incluye el título de la página.
Este esquema es clave en el estudio del hacking ético y el pentesting, ya que cada parte de la petición y respuesta HTTP puede ser analizada o manipulada para descubrir vulnerabilidades, interceptar información sensible o probar la configuración del servidor. Comprender la estructura de estos mensajes es el primer paso para realizar auditorías web efectivas.
Hay dos tipos de mensajes HTTP
- Solicitudes HTTP : enviadas por el usuario para activar acciones en la aplicación web.
- Respuestas HTTP : enviadas por el servidor en respuesta a la solicitud del usuario.
Cada mensaje sigue un formato específico que ayuda tanto al usuario como al servidor a comunicarse sin problemas.
Línea de salida: La línea de inicio es como la introducción del mensaje. Indica qué tipo de mensaje se envía: si se trata de una solicitud del usuario o de una respuesta del servidor. Esta línea también proporciona detalles importantes sobre cómo debe gestionarse el mensaje.

Encabezados: Los encabezados se componen de pares clave-valor que proporcionan información adicional sobre el mensaje HTTP . Proporcionan instrucciones tanto al cliente como al servidor que gestiona la solicitud o respuesta. Estos encabezados abarcan diversos aspectos, como la seguridad, los tipos de contenido y más, garantizando así una comunicación fluida. Los encabezados proporcionan información adicional sobre la solicitud. Los encabezados incluyen:
- Agente de usuario: Información sobre el cliente que realiza la solicitud (por ejemplo, tipo de navegador).
- Host: El nombre de host del servidor.
- Aceptar: Los tipos de medios que el cliente puede manejar en la respuesta (por ejemplo, HTML, JSON).
- Autorización: Credenciales para la autenticación, si es necesario. O
- Cookie: Información almacenada en el lado del cliente y enviada de vuelta al servidor con O cada solicitud
Línea vacía: La línea vacía es un pequeño separador que separa el encabezado del cuerpo. Es esencial porque indica dónde terminan los encabezados y dónde comienza el contenido real del mensaje. Sin esta línea vacía, el mensaje podría generar errores y el cliente o el servidor podrían malinterpretarlo, causando errores.
Cuerpo: El cuerpo es donde se almacenan los datos. En una solicitud, el cuerpo puede incluir datos que el usuario desea enviar al servidor (como datos de formulario). En una respuesta, es donde el servidor coloca el contenido solicitado por el usuario (como una página web o datos de API ). Algunos métodos HTTP (como POST o PUT) incluyen un cuerpo de solicitud donde se envían los datos al servidor, normalmente en formato JSON o de datos de formulario
HTTP Requests – Componentes de la solicitud HTTP
Una solicitud HTTP es lo que un usuario envía a un servidor web para interactuar con una aplicación web y lograr que algo suceda. Dado que estas solicitudes suelen ser el primer punto de contacto entre el usuario y el servidor web, comprender su funcionamiento es fundamental, especialmente si te dedicas a la ciberseguridad. Examinemos una solicitud HTTP en detalle. Los siguientes son los datos contenidos en una solicitud que enviamos cuando navegamos a www.google.com con un navegador web.
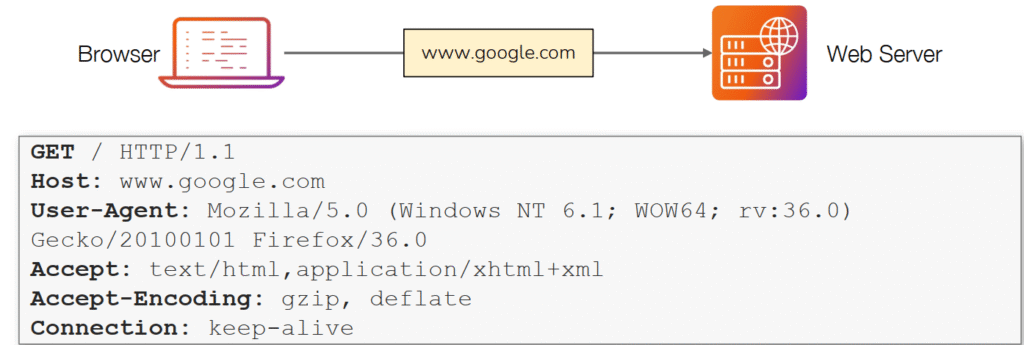
La imagen muestra una petición HTTP típica que un navegador envía a un servidor web —en este caso ilustrado hacia www.google.com— y desglosa la línea de solicitud seguida de varios encabezados HTTP. En la request line aparece GET / HTTP/1.1, que indica que el cliente solicita el recurso raíz / usando la versión HTTP/1.1; justo después se listan encabezados como Host, que especifica el dominio destino (www.google.com), y User-Agent, que identifica el software cliente (aquí un Firefox). Esto refleja el flujo habitual: el navegador resuelve el nombre, abre una conexión y envía esa petición al servidor correspondiente.
Los encabezados visibles (Accept, Accept-Encoding, Connection) aportan metadatos que ayudan al servidor a decidir qué respuesta enviar. Accept indica qué tipos de contenido acepta el cliente (por ejemplo text/html), Accept-Encoding: gzip, deflate comunica que el cliente puede manejar contenido comprimido para ahorrar ancho de banda, y Connection: keep-alive sugiere mantener la misma conexión TCP abierta para futuras peticiones, lo que mejora rendimiento pero cambia la gestión de recursos en el servidor. Estos detalles no son solo informativos: condicionan cómo el servidor genera y optimiza la respuesta.
Desde el punto de vista del pentesting y la seguridad web, cada encabezado es una superficie de análisis. El Host es crítico para virtual hosting y puede explotarse en ataques de Host Header Injection si la aplicación confía en él para construir URLs o manejar redirecciones. El User-Agent sirve para fingerprinting y también para evadir controles (por ejemplo, probar si reglas del WAF se comportan distinto ante distintos agentes). Accept-Encoding y la compresión pueden abrir vectores de canal lateral (ataques ligados a compresión como ciertos escenarios de BREACH) si no se gestionan correctamente los datos sensibles. Además, manipular Connection y otros encabezados puede ayudar a reproducir problemas de configuración o incluso a agotar recursos en tests controlados.
Para quien enseña o practica hacking ético, esta imagen es útil porque resume qué enviar o modificar cuando se construyen peticiones con curl, proxys interceptores o scripts. Comprender la función y el efecto de cada encabezado facilita desde la simple enumeración y fingerprinting de servicios hasta la identificación de malas prácticas de seguridad (cabeceras expuestas, inconsistencias entre intermediarios, respuestas distintas según encabezados). En resumen, la estructura que muestra la imagen es la base para explorar cómo las aplicaciones web interpretan las peticiones y por qué una manipulación cuidadosa de los encabezados suele ser la primera herramienta en una auditoría de seguridad.
Para desglosar cada línea de esta solicitud:
Línea 1: Esta solicitud envía el método GET, solicita la página de inicio con / y le dice al servidor web que estamos usando el protocolo HTTP versión 1.1.
Línea 2: Le decimos al servidor web que queremos el sitio web google.com
Línea 3: Le decimos al servidor web que estamos usando el navegador Firefox versión 36
RECUERDA: HTTP siempre terminan con una línea en blanco para informar al servidor web que la solicitud ha finalizado.
La linea de solicitud HTTP
La línea de solicitud (o línea de inicio) es la primera parte de una solicitud HTTP e indica al servidor el tipo de solicitud que está procesando. Consta de tres partes principales: el método HTTP , la ruta URL y la versión HTTP .
La línea de solicitud es la primera línea de una solicitud HTTP y contiene los siguientes tres componentes:
- El método HTTP (p. ej., GET, POST, PUT, DELETE, etc.): indica el tipo de solicitud que se realiza.
- La URL (Localizador Uniforme de Recursos): la dirección del recurso al que el cliente desea acceder.
- Versión HTTP: la versión del protocolo HTTP que se utiliza (p. ej., HTTP/1.1).
Ejemplo: METHOD /path HTTP/version.
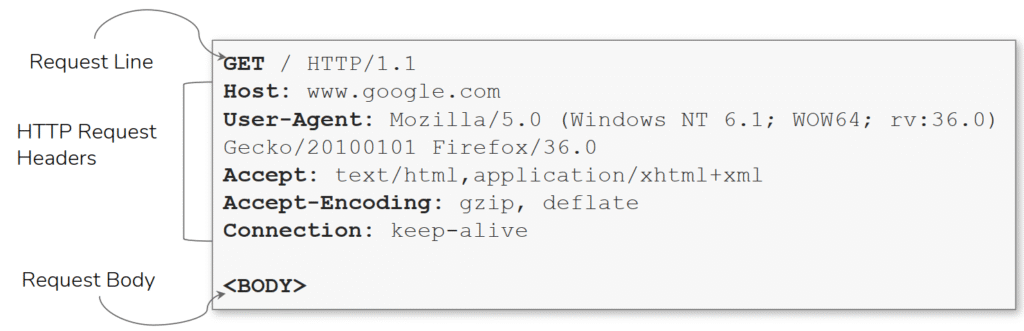
La imagen descompone una petición HTTP en sus tres partes principales: la request line en la parte superior, que aquí aparece como GET / HTTP/1.1 indicando el método (GET), el recurso solicitado (/) y la versión del protocolo (HTTP/1.1); a continuación los encabezados (headers), donde aparecen pares nombre:valor como Host, User-Agent, Accept, Accept-Encoding y Connection; y por último el cuerpo (body), que en esta ilustración queda indicado en la parte inferior y que normalmente se usa en métodos como POST, PUT o PATCH para enviar datos al servidor.
Los encabezados proporcionan metadatos esenciales para que el servidor procese correctamente la petición: Host especifica el dominio objetivo (crítico en entornos con virtual hosts), User-Agent permite identificar y adaptar respuestas según cliente, Accept y Accept-Encoding comunican los tipos de contenido y las codificaciones que el cliente entiende, y Connection: keep-alive sugiere mantener la conexión TCP abierta para mejorar rendimiento. La request line dicta la intención del cliente y la versión del protocolo condiciona cómo se interpretan ciertas características (por ejemplo pipelining, keep-alive o cabeceras específicas de HTTP/1.1).
Desde la perspectiva del pentesting, comprender y poder manipular cada una de estas partes es fundamental: modificar la línea de petición o el Host puede revelar virtual hosts o permitir pruebas de host header injection; cambiar User-Agent o Accept ayuda a identificar diferencias de comportamiento o a evadir reglas; y enviar cuerpos malformados o inesperados (junto con encabezados como Content-Length o Transfer-Encoding) es la base para reproducir errores de parsing entre intermediarios (como smuggling) o para detectar fallos en el manejo de entrada.
En resumen, esta imagen es una guía visual sencilla que ayuda a entender qué enviar y dónde mirar cuando se construyen pruebas de seguridad sobre aplicaciones web.
Métodos de solicitud HTTP
Los métodos de solicitud HTTP (verbos HTTP) proporcionan una forma estandarizada para que los clientes y servidores se comuniquen e interactúen con los recursos en la web. La elección del método apropiado depende del tipo de operación que se deba realizar en el recurso. GET es el método de solicitud predeterminado que se utiliza cuando se realiza una solicitud a una aplicación web; en este caso, intentamos conectarnos a www.google.com.
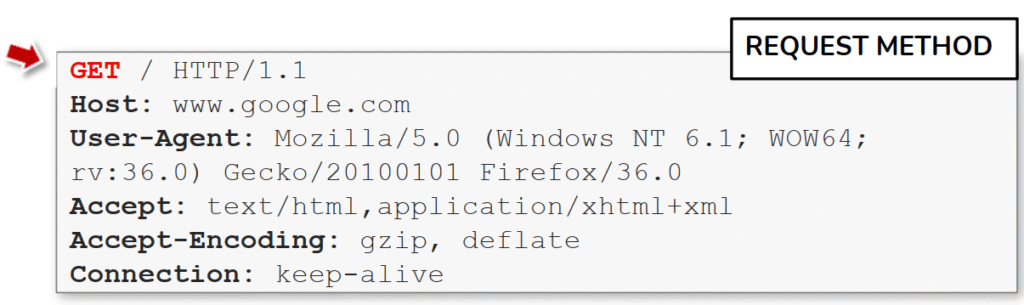
Es posible realizar una solicitud a un servidor web con solo una línea GET / HTTP /1.1
Entonces: El método HTTP indica al servidor qué acción desea realizar el usuario en el recurso identificado por la URL. Los métodos HTTP permiten al cliente mostrar la acción prevista al realizar una solicitud HTTP . Existen muchos métodos HTTP , pero cubriremos los más comunes, aunque principalmente se trabajará con los métodos GET y POST. A continuación, se presentan algunos de los métodos más comunes y sus posibles problemas de seguridad:
La imagen destaca de forma directa y visual la línea inicial de una petición HTTP —aquí GET / HTTP/1.1— y la sitúa como el elemento clave que indica la acción que pide el cliente (el método), el recurso solicitado (el path) y la versión del protocolo. Ese fragmento en rojo con la flecha señala que el método (GET) es lo primero que el servidor lee para decidir cómo procesar la petición; en contraste, métodos como POST, PUT o DELETE cambiarían tanto la semántica de la petición como la presencia esperada de un cuerpo (body).
Debajo de la request line aparecen los encabezados HTTP (Host, User-Agent, Accept, Accept-Encoding, Connection), mostrados de forma realista con valores típicos. El Host indica el dominio al que se dirige la solicitud y es fundamental en servidores con virtual hosting; User-Agent identifica el cliente y se usa para fingerprinting o para servir contenido adaptado; Accept y Accept-Encoding comunican al servidor qué formatos y codificaciones (por ejemplo gzip) puede manejar el cliente; y Connection: keep-alive sugiere mantener la conexión TCP abierta para optimizar peticiones sucesivas. Visualmente la imagen enfatiza que esos headers forman la metadata necesaria para que el servidor construya la respuesta adecuada.
Desde la perspectiva de hacking y pentesting cada uno de esos elementos es una superficie de prueba. Manipular el Host permite buscar virtual hosts o probar host header injection si la aplicación confía en ese valor para construir redirecciones o URLs. Cambiar el User-Agent ayuda tanto a evadir reglas de seguridad como a detectar diferencias de comportamiento en el servidor o en filtros intermedios. Forzar o modificar Accept-Encoding explora riesgos ligados a la compresión (posibles fugas por compresión en escenarios concretos) y jugar con Connection o abrir muchas conexiones es una técnica útil para probar la robustez frente a agotamiento de recursos. En conjunto, la imagen es una buena base visual para que comprendas qué campos puede editar con un proxy (Burp/ZAP), curl o scripts, y por qué mirar la request line y los headers es uno de los primeros pasos en una auditoría web.
GET
El método GET se utiliza para recuperar datos del servidor. Solicita el recurso especificado en la URL y no modifica el estado del servidor. Es un método seguro e idempotente, lo que significa que realizar la misma solicitud GET varias veces no debería tener efectos secundarios. Asegúrate de exponer únicamente los datos que el usuario puede ver. Evita incluir información confidencial como tokens o contraseñas en las solicitudes GET, ya que pueden aparecer como texto plano.
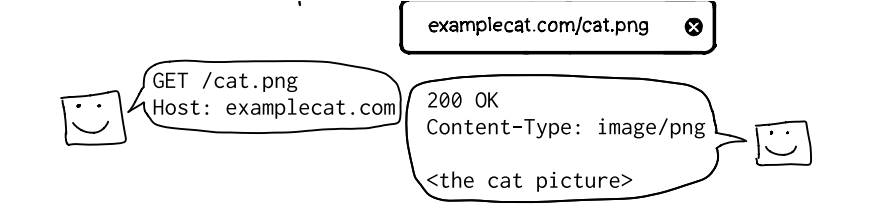
La ilustración es un esquema muy simple del intercambio HTTP para conseguir una imagen: a la izquierda un cliente (navegador) hace una petición GET /cat.png con el encabezado Host: examplecat.com, y a la derecha el servidor responde 200 OK con Content-Type: image/png y en el cuerpo va la imagen del gato. Visualmente resalta las tres piezas esenciales de la comunicación: la línea de petición (método + recurso), los encabezados que identifican el destino y al cliente, y la línea de estado más los encabezados de respuesta que describen el tipo de contenido seguido por el body binario (la imagen).
Primero, aunque una petición de imagen parece inocua, cualquier recurso accesible por URL puede ser objetivo de pruebas: nombres de archivos predecibles, rutas sensibles o directorios mal configurados pueden permitir descubrir ficheros no públicos (insecure direct object references, path traversal, listado de directorios). Segundo, el Content-Type es crucial: si el servidor devuelve el contenido con un MIME incorrecto (por ejemplo text/html en lugar de image/png) se pueden abrir vectores como cross-site scripting o content sniffing. Tercero, las peticiones GET a recursos estáticos se pueden aprovechar para técnicas de reconocimiento y exfiltración: etiquetas <img> o peticiones desde CSS/JS generan solicitudes cross-origin que el navegador hará aunque no permita leer la respuesta, lo cual se puede usar para triggers, timing attacks o comprobar la existencia de recursos sin permiso directo.
Además, las imágenes pueden contener metadatos (EXIF) con información confidencial o permitir técnicas de esteganografía; la compresión y cabeceras de caché (Cache-Control, ETag, Content-Length) afectan la forma en que proxies y navegadores almacenan y reutilizan esos recursos, algo relevante si se intenta explotar inconsistencias entre intermediarios (por ejemplo cache poisoning). En prácticas de pentest conviene inspeccionar la petición con un proxy interceptador (Burp/ZAP), probar nombres y rutas, verificar respuestas y cabeceras, comprobar el manejo de errores (404 vs 500), y validar que los tipos MIME y permisos sean los adecuados.
En resumen, la imagen es una buena puerta de entrada para explicar que incluso una simple solicitud de cat.png es una pieza del puzzle de seguridad web y merece atención en una auditoría.
POST
El método POST se utiliza para enviar datos para que los procese el servidor y potencialmente crear nuevos registros. Normalmente incluye datos en el cuerpo de la solicitud, y el servidor puede realizar acciones basadas en esos datos. Las solicitudes POST pueden causar cambios en el estado del servidor y no son idempotentes. Siempre valida y limpia la entrada para evitar ataques como inyección SQL o XSS .
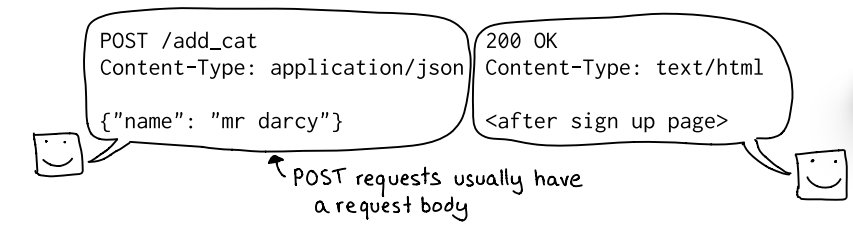
La imagen representa de forma esquemática una típica interacción HTTP donde el cliente envía una petición POST con un cuerpo en JSON y el servidor devuelve una respuesta HTML. A la izquierda se ve la request line POST /add_cat seguida del encabezado Content-Type: application/json y el body {«name»:»mr darcy»}. A la derecha aparece la respuesta 200 OK con Content-Type: text/html y el contenido de la página que se muestra después de registrarse o crear el recurso. Visualmente la ilustración subraya la regla práctica: las peticiones POST suelen llevar un cuerpo y obligan al servidor a parsearlo antes de actuar.
Desde el punto de vista funcional y de pentesting, este escenario contiene varios puntos importantes. Primero, el Content-Type sirve para que el servidor sepa cómo interpretar el body; si la aplicación no valida ni fuerza el tipo de contenido, puede procesar entradas inesperadas (por ejemplo form-encoded, multipart o incluso contenido malicioso) y abrir vectores de ataque. Segundo, los datos JSON que llegan al backend suelen pasar por parsers y ORMs: si no se validan con un esquema (JSON Schema, validadores en el servidor) se pueden producir problemas como inyección (SQL, NoSQL), mass assignment (asignación masiva de campos que no deberían poder modificarse), o incluso ejecución de código al deserializar objetos inseguros.

Además es importante considerar control de autenticación y autorización: ¿quién puede llamar a /add_cat? Si la ruta permite crear recursos sin comprobar permisos ni tokens, un atacante puede automatizar peticiones para crear contenido no deseado o escalar privilegios. También conviene revisar protecciones contra CSRF cuando la petición provenga de navegadores, aplicar límites de tamaño al body para evitar DoS por cargas enormes, y asegurarse de que la respuesta no refleja sin escapar los datos del usuario (para evitar XSS reflejado si el nombre se muestra directamente en la página de confirmación).
Para pruebas prácticas recomiendo interceptar la petición con un proxy (Burp/ZAP) y experimentar con variantes: cambiar Content-Type, enviar JSON mal formado, intentar incluir campos adicionales, enviar cargas que provoquen inyección en el motor de persistencia, o forzar tipos distintos (arrays, objetos anidados) para observar cómo lo maneja el servidor. También probar respuestas de error y códigos distintos (400/422 para validaciones), comprobar headers de seguridad en la respuesta y verificar que el servidor aplica saneamiento antes de renderizar el contenido en HTML.
En resumen, aunque el diagrama es sencillo, contiene todas las piezas clave que hay que revisar en una auditoría de endpoints que reciben JSON: validación estricta, control de acceso, saneamiento de salida y límites/tiempos para mitigar abuso.
PUT
El método PUT se utiliza para actualizar o crear un recurso en el servidor en la URL especificada. Reemplaza todo el recurso con la nueva representación proporcionada en el cuerpo de la solicitud. Si el recurso no existe, PUT puede crearlo. Asegúrese de que el usuario esté autorizado para realizar cambios antes de aceptar la solicitud.
DELETE
El método DELETE se utiliza para eliminar del servidor el recurso especificado por la URL. Después de una solicitud DELETE exitosa, el recurso ya no estará disponible en esa URL. Al igual que con PUT, asegúrese de que solo los usuarios autorizados puedan eliminar recursos.

La imagen ilustra de forma muy simple el uso del método HTTP DELETE: un cliente envía una petición con la línea DELETE /v1/customers/cus_12345 pidiendo “eliminar este cliente” y el servidor responde con 200 OK confirmando la eliminación. Visualmente se enfoca en la semántica: DELETE se emplea para borrar recursos y en muchas APIs RESTful (por ejemplo Stripe u otras APIs públicas) suele mapearse a una acción irreversible o a una marca de eliminado sobre un recurso identificado por su ID.
Desde el punto de vista funcional y de diseño hay matices que tus debes conocer: las APIs pueden implementar borrados “duros” que eliminan físicamente datos, o borrados “lógicos” (soft delete) que solo cambian un flag en la base de datos; además DELETE debería ser idempotente, es decir, repetir la misma petición debería producir el mismo resultado (el recurso ya no existe). Estos comportamientos condicionan cómo se prueban y cómo se protegen los endpoints que aceptan DELETE, porque la acción afecta datos reales y, si no hay controles adecuados, puede traer consecuencias importantes.
En un contexto de pentesting, los vectores más comunes a revisar son la autenticación y la autorización a nivel de objeto. ¿Puede cualquier usuario autenticado borrar cualquier recurso cambiando el identificador en la URL? Si la API confía únicamente en la presencia de un token y no comprueba que el token pertenece al propietario del recurso, aparece una vulnerabilidad de Insecure Direct Object Reference o Broken Access Control. También conviene probar la ausencia de autenticación: endpoints públicos con DELETE activos son un fallo crítico. Otro aspecto relevante es la protección contra CSRF en escenarios donde navegadores están involucrados: si un endpoint DELETE acepta cookies de sesión sin mecanismos anti-CSRF, una página maliciosa podría inducir a un usuario legítimo a ejecutar borrados involuntarios.
Además hay consideraciones operativas que a menudo se explotan en auditorías: falta de logging o logs insuficientes que impiden rastrear quién borró qué y cuándo; respuestas poco diferenciadas que permiten enumerar recursos (por ejemplo, un 200 para recursos inexistentes frente a un 404 que confirma presencia); manejo inadecuado de parámetros (inyecciones en IDs, path traversal si el backend construye rutas de archivos a partir de la entrada); y ausencia de límites o de protección contra automatización que permitirían campañas masivas de borrado. También es aconsejable revisar la lógica posterior al borrado: si se borran objetos referenciados en otras tablas sin restricciones, puede generarse corrupción de datos o errores en cascada.
Para pruebas prácticas recomiendo interceptar las peticiones con un proxy (Burp/ZAP), modificar el ID del recurso en la URL, probar con tokens de distintos usuarios y observar códigos de respuesta y mensajes. Es útil comprobar también variantes como enviar el DELETE con y sin Content-Type, intentar métodos alternativos (POST con _method=DELETE) si el servidor admite métodos “simulados”, y verificar si el comportamiento cambia según cabeceras como Accept o Authorization.
Muy importante: realiza estas pruebas exclusivamente en entornos controlados o con autorización explícita. No intentes borrar datos en sistemas ajenos sin permiso. Para practicar de forma segura usa laboratorios, máquinas intencionalmente vulnerables (por ejemplo OWASP Juice Shop, DVWA o plataformas educativas como TryHackMe) o entornos aislados que te permitan experimentar sin riesgo.
PATCH
El método PATCH se utiliza para aplicar modificaciones parciales a un recurso. Es similar al método PUT, pero solo actualiza partes específicas del recurso en lugar de reemplazarlo por completo. Es útil para realizar pequeños cambios sin reemplazarlo por completo, pero siempre valida los datos para evitar inconsistencias.
HEAD
El método HEAD es similar al método GET, pero solo recupera los encabezados de respuesta y no el cuerpo de la respuesta. Se suele utilizar para comprobar los encabezados en busca de elementos como la existencia del recurso o las fechas de modificación. Resulta útil para comprobar metadatos sin descargar la respuesta completa.
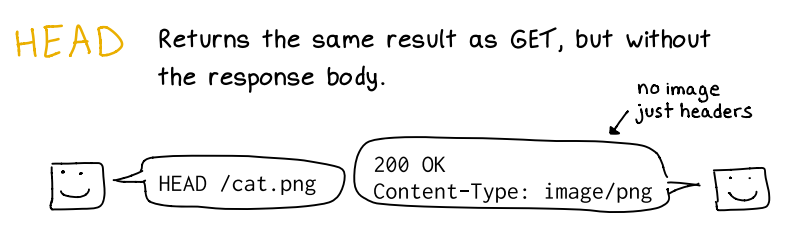
La imagen ilustra de forma sencilla el método HEAD: a la izquierda un cliente pide HEAD /cat.png y a la derecha el servidor responde 200 OK con el encabezado Content-Type: image/png, pero sin enviar el cuerpo (la imagen). Visualmente se enfatiza la diferencia clave frente a un GET: con HEAD se recibe únicamente la metadata (headers) que describen la respuesta, sin transferir el contenido binario.
Este comportamiento tiene usos prácticos y legítimos: permite comprobar si un recurso existe, conocer su tipo MIME, tamaño o directivas de caché sin bajar el archivo completo, lo que ahorra ancho de banda y es útil para sincronizaciones, verificaciones de integridad y decisiones de caching en proxies o CDNs. En servidores bien configurados la respuesta a HEAD debe coincidir en headers relevantes con la que produciría un GET, salvo por la ausencia del body.
Desde la perspectiva de pentesting, HEAD es una herramienta de reconocimiento ligera y valiosa. Al no descargar el contenido, facilita la enumeración de rutas y la comprobación de la existencia de recursos (ficheros, endpoints, imágenes privadas) sin levantar tanta traza de descarga, y puede acelerar automatizaciones que buscan archivos interesantes. También es útil para detectar inconsistencias entre intermediarios: diferencias en las cabeceras o en los códigos de estado entre HEAD y GET (por ejemplo, HEAD devuelve 200 y GET 403/404) pueden revelar fallos en proxies, reglas de seguridad o lógica del servidor que un atacante podría explotar. Además, cabeceras reveladas en la respuesta a HEAD (como X-Powered-By, Server, Cache-Control, Content-Length, ETag) pueden aportar información de fingerprinting o pistas sobre configuraciones erróneas.
Por otro lado, hay riesgos y checks concretos que conviene realizar durante una auditoría: comprobar que HEAD no devuelve más información de la necesaria ni ignora controles de acceso aplicados a GET, verificar que la cabecera Content-Length y otras coincidan con lo esperado, revisar que no se puedan abusar de HEAD para evadir filtros (por ejemplo algunos WAFs filtran GET pero permiten HEAD) y evaluar si el endpoint está protegido contra automatización masiva (rate limits, autenticación).
También es importante validar el logging: aunque HEAD no descarga el cuerpo, debe registrarse igual que otras peticiones para trazabilidad. Como siempre, estas pruebas deben ejecutarse en entornos autorizados o controlados; realizar escaneos sin permiso puede ser ilegal, y en nuestro camino, vamos a evitar de estar a un bit de ir en cana.
OPTIONS
El método OPTIONS se utiliza para recuperar información sobre las opciones de comunicación disponibles para el recurso de destino. Permite a los clientes determinar los métodos y encabezados compatibles con un recurso en particular. Muchos servidores lo deshabilitan por seguridad.
TRACE
Similar a OPCIONES, muestra los métodos permitidos, generalmente para depuración. Muchos servidores lo deshabilitan por seguridad.
CONECT
Se utiliza para crear una conexión segura, como HTTPS. No es tan común, pero es fundamental para la comunicación cifrada.
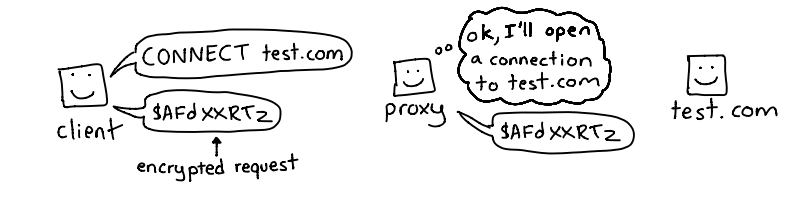
La imagen muestra de manera muy clara cómo funciona el método CONNECT del protocolo HTTP, usado normalmente cuando un cliente necesita establecer una conexión segura (como HTTPS) a través de un proxy. En el dibujo, el cliente envía la instrucción CONNECT test.com, pidiéndole al proxy que abra un canal directo hacia el servidor de destino (test.com). Una vez el proxy acepta, el cliente y el servidor pueden comunicarse directamente, intercambiando datos cifrados (como el flujo TLS/SSL que se representa con los caracteres aleatorios).
El paso clave es que, a diferencia de otros métodos como GET o POST, el CONNECT no transporta datos de aplicación en texto claro; en su lugar, le dice al proxy que “tunele” la comunicación. A partir de ese momento, el proxy deja de interpretar el tráfico —simplemente lo reenvía— y el cliente inicia el cifrado con el servidor remoto. Este mecanismo es lo que permite navegar por HTTPS cuando se está detrás de un proxy corporativo o un firewall.
Desde la perspectiva de pentesting y seguridad, el método CONNECT tiene un papel interesante. Por un lado, es esencial en entornos donde se inspecciona o restringe el tráfico HTTPS: si el proxy permite CONNECT libremente, un atacante podría aprovecharlo para establecer túneles a servidores externos y evadir políticas de filtrado, cortafuegos o sistemas de detección. Por otro lado, en pruebas de seguridad, entender cómo funciona este método ayuda a detectar configuraciones inseguras de proxies (por ejemplo, cuando permiten CONNECT a cualquier puerto o dominio) o vulnerabilidades de proxy tunneling y proxy chaining, que pueden ser explotadas para eludir restricciones de red.
En resumen, el método CONNECT no transfiere directamente contenido web, sino que crea un canal cifrado entre el cliente y el servidor a través del proxy. Es una pieza clave del tráfico HTTPS y un punto de atención importante en auditorías de redes y controles de salida, ya que un proxy mal configurado podría convertirse en una puerta de escape para conexiones no autorizadas.
Cada uno de estos métodos tiene su propio conjunto de reglas de seguridad. Por ejemplo, las solicitudes PATCH deben validarse para evitar inconsistencias, y las opciones OPTIONS y TRACE deben desactivarse si no se necesitan para evitar posibles riesgos de seguridad.
Clasificación de los métodos HTTP
La imagen presenta una clasificación clara de los principales métodos HTTP, explicando qué función cumple cada uno dentro de las comunicaciones entre un cliente (como un navegador o una API) y un servidor. Está dividida en dos grandes grupos: los métodos seguros, que no modifican el estado del servidor, y los métodos que envían datos o generan cambios, es decir, aquellos que incluyen un cuerpo (body) en la solicitud.

En el primer grupo aparecen GET y HEAD, considerados safe methods porque solo leen información sin realizar alteraciones. GET se utiliza para solicitar recursos, mientras que HEAD devuelve solo los encabezados de la respuesta, sin incluir el contenido. Estos métodos son los más comunes y deben estar implementados en cualquier servidor compatible con HTTP/1.1.
El segundo bloque muestra los métodos que envían información al servidor y pueden modificar datos o el estado de un recurso. PUT deposita o reemplaza información en una ubicación específica, actuando como el inverso de GET; POST envía datos para su procesamiento, como formularios o registros en una base de datos; y PATCH permite modificar parcialmente un recurso existente sin reemplazarlo por completo. A estos se suman TRACE, que devuelve el mismo mensaje enviado por el cliente (útil para depuración), y OPTIONS, que indica las capacidades o métodos que un servidor soporta. Finalmente, DELETE intenta eliminar un recurso, aunque su éxito no está garantizado si el servidor impone restricciones o validaciones.
En el contexto del pentesting y la seguridad web, esta tabla resulta muy útil porque cada método representa una posible superficie de ataque. Saber que un servidor acepta métodos como PUT, DELETE o TRACE puede revelar configuraciones peligrosas. Por ejemplo, PUT podría permitir la subida de archivos maliciosos, DELETE la eliminación de información sin control, y TRACE podría exponer cabeceras sensibles como cookies o tokens mediante ataques de tipo Cross-Site Tracing (XST). Por eso, durante una auditoría, es importante probar qué métodos están habilitados usando peticiones OPTIONS o herramientas como curl -X METHOD, y verificar si están debidamente restringidos.
En resumen, la imagen resume la lógica de interacción del protocolo HTTP, diferenciando métodos de lectura y métodos de modificación. Comprender esta estructura no solo ayuda a entender cómo se construyen las APIs modernas, sino también a detectar configuraciones inseguras que podrían ser explotadas durante pruebas de seguridad.
Resumen del capítulo (versión compacta y práctica)
Modelo básico cliente–servidor
- El navegador (cliente) envía una request al servidor.
- El servidor procesa y responde con una response.
- Si la conexión está cifrada (HTTPS) viaja sobre TLS/SSL; si no, viaja en texto claro (HTTP).
Estructura de un mensaje HTTP
- Request line / Status line: METHOD /path HTTP/1.1 — ejemplo: GET /login HTTP/1.1 / HTTP/1.1 200 OK.
- Headers: pares Nombre: Valor (Host, User-Agent, Accept, Cookie, Authorization, Content-Type, etc.).
- Línea vacía: \r\n que separa headers del body.
- Body: datos (JSON, form-data, urlencoded, XML, binario) usados por POST/PUT/PATCH.
Métodos importantes y riesgos principales
- GET / HEAD — lectura; no poner datos sensibles en la URL (tokens). Útil para reconocimiento (HEAD devuelve solo headers).
- POST / PUT / PATCH — envío/creación/actualización; validar y sanear siempre. Riesgos: inyección (SQL/NoSQL), mass assignment, deserialización insegura.
- DELETE — eliminación; requiere autorización por objeto (evitar IDOR).
- OPTIONS / TRACE / CONNECT — depuración o túneles; deshabilitar si no son necesarios por riesgo (TRACE/OPTIONS) o limitar (CONNECT en proxies).
- Request smuggling: manipulación de Content-Length / Transfer-Encoding entre intermediarios. Muy peligroso cuando hay proxies inconsistentes.
Encabezados clave (por qué importan en pentesting)
- Host — virtual hosting; manipularlo puede revelar subdominios o permitir Host Header Injection.
- User-Agent — fingerprinting / evasión WAF.
- Accept / Accept-Encoding — fuerza otra representación (JSON vs HTML) o compresión (ataques por compresión).
- Connection / Transfer-Encoding / Content-Length — fundamentos para request/response smuggling.
- Cookie / Authorization — autenticación; no deben exponerse en URLs.
Versiones del protocolo
- HTTP/1.1 — conexiones persistentes (keep-alive), secuencial.
- HTTP/2 — multiplexación, compresión de headers; más eficiente pero más complejo para interceptación.
- HTTP/3 (QUIC) — sobre UDP/QUIC; requiere herramientas compatibles para pruebas.
Vectores comunes relacionados con rutas (path)
- Path traversal (../) → acceder a archivos fuera del directorio permitido.
- IDOR → cambiar IDs en rutas (/api/users/123) para ver recursos ajenos.
- Rutas ocultas → /admin, /.git/, /backup — fuzzing para descubrirlas.
- Upload endpoints → pruebas de extensión/ejecución de archivos.
- Cache poisoning → malas combinaciones de Vary y caches según headers.
Buenas prácticas de defensa (resumen)
- Validar, normalizar y whitelist de rutas/paths.
- Autorización por objeto (comprobar que el usuario es propietario).
- No exponer secretos en URLs ni en front-end.
- Forzar Content-Type y validar schema (JSON Schema).
- Deshabilitar métodos innecesarios (TRACE, PUT, DELETE si no se usan).
- Sincronizar configuración de proxies/CDN para evitar smuggling.
- Logging, límite de tasa (rate limits) y WAF donde aplique.
Comandos y ejemplos útiles (prácticos)
Mostrar headers con curl -I (HEAD):
curl -I ‘https://example.com/secret.txt‘
GET simple con verbose:
curl -v ‘http://example.com/login‘
Forzar Host header distinto:
curl -v -H ‘Host: admin.example.internal’ ‘http://198.51.100.10/‘
POST JSON:
curl -v -X POST ‘https://api.example.com/users‘ \
-H ‘Content-Type: application/json’ \
-d ‘{«name»:»alice»,»role»:»user»}’
Probar distintos métodos:
curl -v -X OPTIONS ‘https://target.example.com/path‘
curl -v -X TRACE ‘https://target.example.com/path‘ # en entornos autorizados sólo
Checklist rápido para pentesting (orden práctico)
- Enumerar rutas públicas (robots.txt, sitemap.xml, fuzzing).
- HEAD/OPTIONS para descubrir info y métodos soportados.
- Manipular Host y User-Agent para fingerprinting y discover.
- Fuzz de IDs y parámetros para IDOR.
- Path traversal con diferentes encodings (../, %2E%2E/, %2e%2e%2f).
- Revisar Accept/Accept-Encoding y comportamiento con compresión.
- Verificar métodos habilitados (PUT/DELETE/PATCH) y si exigen auth.
- Test for request smuggling (solo en laboratorios autorizados).
- Revise respuestas y logs por información filtrada (stack traces, rutas internas).
Mini-ejercicios (hazlos solo en entornos autorizados)
- Intercepta peticiones con Burp/ZAP y modifica Host / User-Agent.
- Cambia IDs en /api/users/ID para comprobar IDOR.
- Ejecuta fuzzing de rutas con ffuf o dirb sobre un target de laboratorio.
- Prueba HEAD vs GET y compara códigos y headers.
10 preguntas clave sobre el artículo
- ¿Cuál es la función del protocolo HTTP/HTTPS en la web?
- ¿Qué partes componen una solicitud HTTP?
- ¿Qué diferencia existe entre una solicitud HTTP y una respuesta HTTP?
- ¿Qué información se incluye en los encabezados de una petición HTTP?
- ¿Qué función cumple la línea vacía en los mensajes HTTP?
- ¿Qué diferencia hay entre los métodos GET, POST y PUT?
- ¿Qué riesgos de seguridad están asociados al encabezado Host?
- ¿Qué hace el método CONNECT y por qué es relevante en entornos con proxies?
- ¿Qué mejoras trae HTTP/2 frente a HTTP/1.1?
- ¿Por qué es importante validar el contenido del cuerpo en métodos como POST, PUT y PATCH?
10 ejercicios para practicar el contenido
- Analiza esta línea de solicitud:
GET /admin HTTP/1.1
Identifica el método, recurso y versión del protocolo. - Redacta una petición HTTP con método POST que envíe un JSON con nombre y email al endpoint /registro.
- Clasifica los siguientes métodos como seguros o no seguros:
- GET, POST, HEAD, DELETE, PATCH, CONNECT
- Explica qué hace este encabezado:
Accept-Encoding: gzip, deflate - Investiga con tu navegador qué encabezados HTTP se envían al visitar cualquier sitio web. (Usa pestaña «Red» en DevTools)
- Simula una petición DELETE a /api/productos/23 y explica qué debe devolver el servidor si la operación fue exitosa.
- Escribe una petición OPTIONS a un recurso /usuarios/1 y qué esperas obtener como respuesta.
- Evalúa este fragmento:
Host: malicioso.com
¿Qué tipo de ataque podría ser? - Diseña un ejemplo de petición PATCH para modificar solo el campo nombre de un usuario.
- Explica por qué el encabezado User-Agent puede ser usado por un atacante.
Respuestas detalladas a las 10 preguntas
1. ¿Cuál es la función del protocolo HTTP/HTTPS en la web?
HTTP/HTTPS permite la comunicación entre clientes (como navegadores) y servidores web. Define cómo se envían y reciben solicitudes y respuestas. HTTPS añade una capa de cifrado con SSL/TLS, protegiendo la información en tránsito.
2. ¿Qué partes componen una solicitud HTTP?
- Línea de solicitud: indica el método, el recurso solicitado y la versión HTTP.
- Encabezados (headers): envían información adicional como tipo de navegador, contenido aceptado, cookies, etc.
- Línea vacía: separa los encabezados del cuerpo.
- Cuerpo (body): opcional, contiene datos enviados (como JSON o formularios).
3. ¿Qué diferencia existe entre una solicitud HTTP y una respuesta HTTP?
- Solicitud (request): enviada por el cliente al servidor para pedir un recurso o ejecutar una acción.
- Respuesta (response): enviada por el servidor al cliente, contiene el código de estado y el recurso solicitado o el resultado de la operación.
4. ¿Qué información se incluye en los encabezados de una petición HTTP?
Entre otros:
- Host: dominio al que va dirigida la solicitud.
- User-Agent: identifica el cliente.
- Accept: tipos de contenido que el cliente puede manejar.
- Cookie: valores almacenados en el navegador.
- Authorization: credenciales si el recurso requiere autenticación.
5. ¿Qué función cumple la línea vacía en los mensajes HTTP?
Indica el final de los encabezados y el inicio del cuerpo del mensaje. Es fundamental para que cliente y servidor puedan procesar correctamente la solicitud.
6. ¿Qué diferencia hay entre los métodos GET, POST y PUT?
- GET: solicita datos, no modifica el servidor.
- POST: envía datos para crear o modificar información.
- PUT: reemplaza completamente un recurso existente o lo crea si no existe.
7. ¿Qué riesgos de seguridad están asociados al encabezado Host?
Si una aplicación confía ciegamente en este valor, puede ser vulnerable a Host Header Injection, permitiendo redirecciones maliciosas o creación de enlaces peligrosos en correos automáticos, etc.
8. ¿Qué hace el método CONNECT y por qué es relevante en entornos con proxies?
Crea un túnel TCP/IP entre el cliente y el servidor a través del proxy, usado comúnmente para conexiones HTTPS. Si no se controla, puede permitir evadir firewalls o políticas de red.
9. ¿Qué mejoras trae HTTP/2 frente a HTTP/1.1?
- Multiplexación (varias solicitudes/respuestas simultáneas en una sola conexión).
- Compresión de encabezados.
- Priorización de recursos.
Esto mejora el rendimiento general y la velocidad de carga.
10. ¿Por qué es importante validar el contenido del cuerpo en métodos como POST, PUT y PATCH?
Porque los datos pueden ser manipulados por atacantes. Si no se validan, podrían permitir ataques como:
- Inyección SQL
- Mass assignment
- Ejecución remota de código
- XSS
Respuestas a los 10 ejercicios
1. Línea de solicitud: GET /admin HTTP/1.1
- Método: GET
- Ruta o recurso: /admin
- Versión del protocolo: HTTP/1.1
2. Ejemplo de petición POST:
POST /registro HTTP/1.1
Host: example.com
Content-Type: application/json
Content-Length: 47
{
«nombre»: «Juan»,
«email»: «juan@example.com»
}
3. Clasificación de métodos:
- Seguros: GET, HEAD
- No seguros: POST, DELETE, PATCH, CONNECT
4. Encabezado Accept-Encoding: gzip, deflate
Le indica al servidor que puede comprimir la respuesta usando gzip o deflate para ahorrar ancho de banda. El servidor responderá con una cabecera Content-Encoding si usa compresión.
5. Encabezados del navegador (usando DevTools):
Ejemplo real:
GET / HTTP/2
Host: www.google.com
User-Agent: Mozilla/5.0 (…)
Accept: text/html,application/xhtml+xml
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
6. Petición DELETE a /api/productos/23:
DELETE /api/productos/23 HTTP/1.1
Host: example.com
Authorization: Bearer token123
Respuesta esperada:
HTTP/1.1 200 OK
Content-Type: application/json
{«message»: «Producto eliminado correctamente»}
7. Petición OPTIONS:
OPTIONS /usuarios/1 HTTP/1.1
Host: example.com
Respuesta esperada:
HTTP/1.1 204 No Content
Allow: GET, POST, PUT, DELETE
8. Riesgo del encabezado Host: malicioso.com:
Puede causar una vulnerabilidad de Host Header Injection si el servidor usa ese valor para construir URLs o redirecciones sin validación.
9. Ejemplo de PATCH:
PATCH /usuarios/42 HTTP/1.1
Host: example.com
Content-Type: application/json
{
«nombre»: «NuevoNombre»
}
10. Encabezado User-Agent como vector de ataque:
Un atacante puede falsificarlo para:
- Evadir reglas de seguridad.
- Detectar diferencias en comportamiento del servidor.
- Automatizar ataques sin ser detectado como bot.
Qué aprendiste y por qué te sirve como hacker
Has adquirido la capacidad de leer, construir y manipular peticiones/respuestas HTTP: saber qué enviar, dónde tocar (línea de inicio, headers, body) y qué observar en la respuesta. Eso te permite delimitar vectores reales —desde enumeración y reconocimiento hasta explotación (IDOR, path traversal, request smuggling, inyecciones)— y, sobre todo, documentar hallazgos con precisión (método, ruta, headers y payload). Ese bagaje te convierte en un pentester más eficaz: identificas riesgos reales, los reproduces de forma controlada y propones mitigaciones concretas.