
En este capítulo, OWASP TOP 10 A01 2025 Broken Access Control, vas a entrar en uno de los pilares más importantes del hacking moderno: el OWASP Top 10, el estándar global que define las vulnerabilidades más críticas en aplicaciones web. Entenderlo no es opcional: es una herramienta fundamental para cualquier hacker, pentester o profesional de seguridad que quiera operar a nivel real, en escenarios reales y contra sistemas reales.
OWASP TOP 10
OWASP es popular por publicar el TOP 10 Owasp Web cada cuatro años. Este es un documento que lista los diez riesgos más críticos en aplicaciones web, con el objetivo de ayudar a las organizaciones a identificar y mitigar las vulnerabilidades asociadas con estos riesgos. https://owasp.org/Top10/es/ Cada uno de estos riesgos representa una debilidad común y significativa que a menudo se puede explotar para comprometer la seguridad de una aplicación web. OWASP proporciona información detallada sobre posibles vulnerabilidades y técnicas de ataque para cada riesgo.
El Top 10 de OWASP es una lista que se actualiza periódicamente de los riesgos de seguridad de las aplicaciones web más críticos. Lo mantiene el Proyecto Abierto de Seguridad de Aplicaciones Web (OWASP), una organización sin fines de lucro centrada en mejorar la seguridad de las aplicaciones web. Sirve como una valiosa guía para que los desarrolladores, los expertos en pruebas de penetración de aplicaciones web y las organizaciones comprendan y prioricen los riesgos de seguridad comunes en las aplicaciones web.
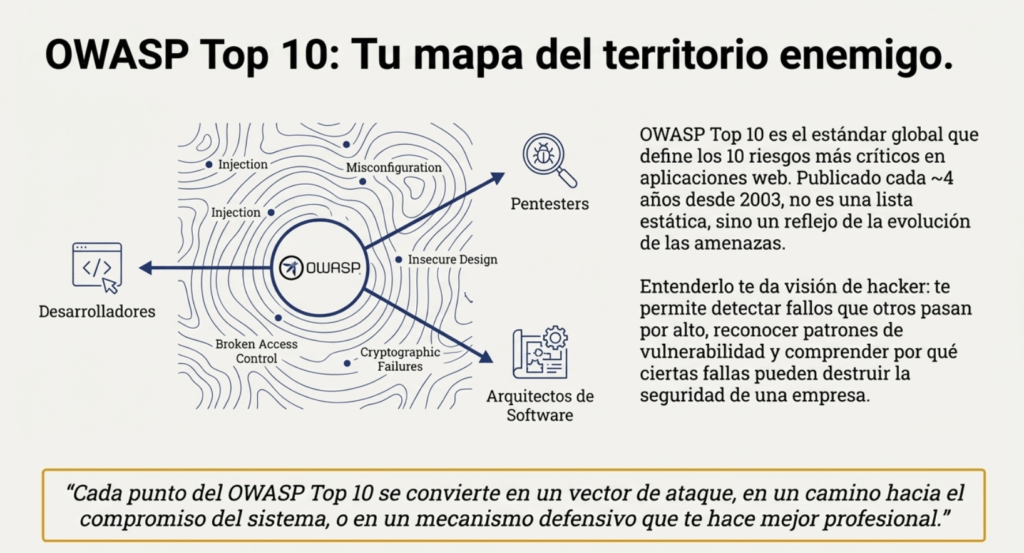
El Top 10 de OWASP es una lista conocida de los diez riesgos de seguridad de aplicaciones web más críticos. Se actualiza periódicamente para garantizar que refleje el panorama actual de amenazas y los desafíos de seguridad en constante evolución que enfrentan las aplicaciones web. La primera versión del Top 10 de OWASP se publicó en 2003. Su objetivo era crear conciencia sobre los riesgos comunes de seguridad de las aplicaciones web y ayudar a los desarrolladores a priorizar los esfuerzos de seguridad. La lista incluía riesgos como secuencias de comandos entre sitios (XSS), inyección de SQL y problemas de gestión de sesiones. Cada lanzamiento del Top 10 de OWASP se basa en las versiones anteriores, mejorando su precisión, relevancia y practicidad.

Evolución de OWASP TOP 10
En el momento de crear este artículo coexiste las dos versiones 2021/2025.
⚪No cambia
🟡Fusionado
🔵Cambia de posición
🟢Nuevo

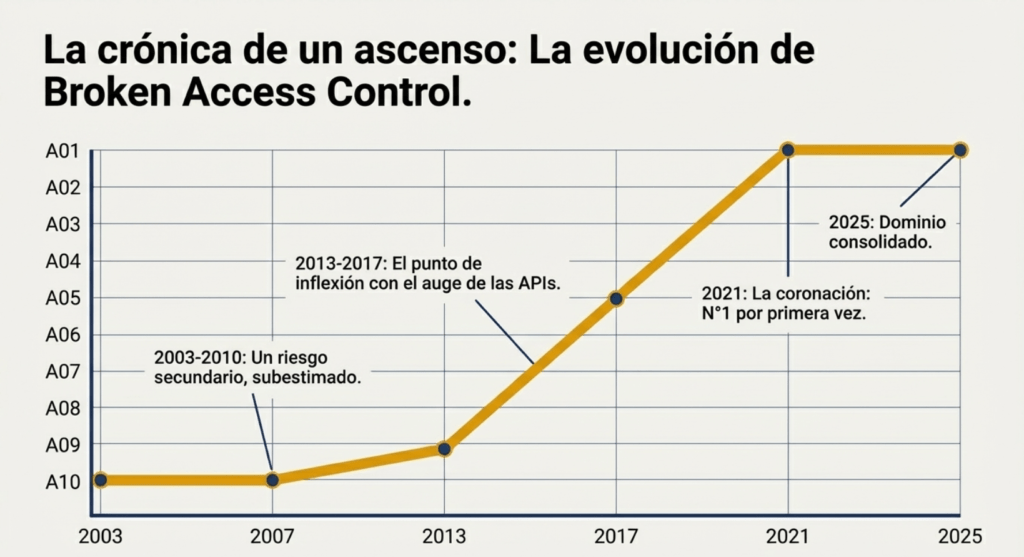
La aparición y evolución histórica de Broken Access Control en el OWASP Top 10: del viejo A10 al dominio en 2025
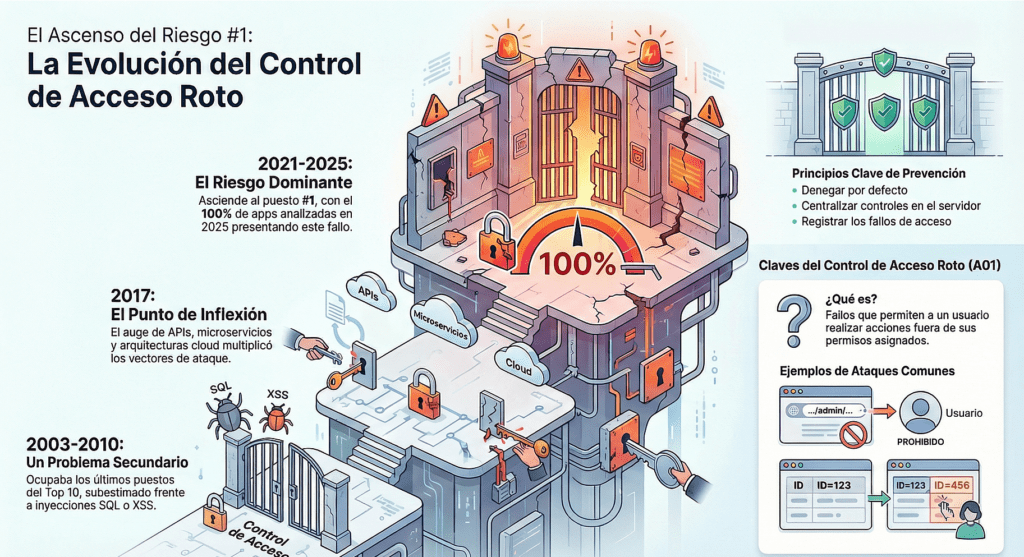
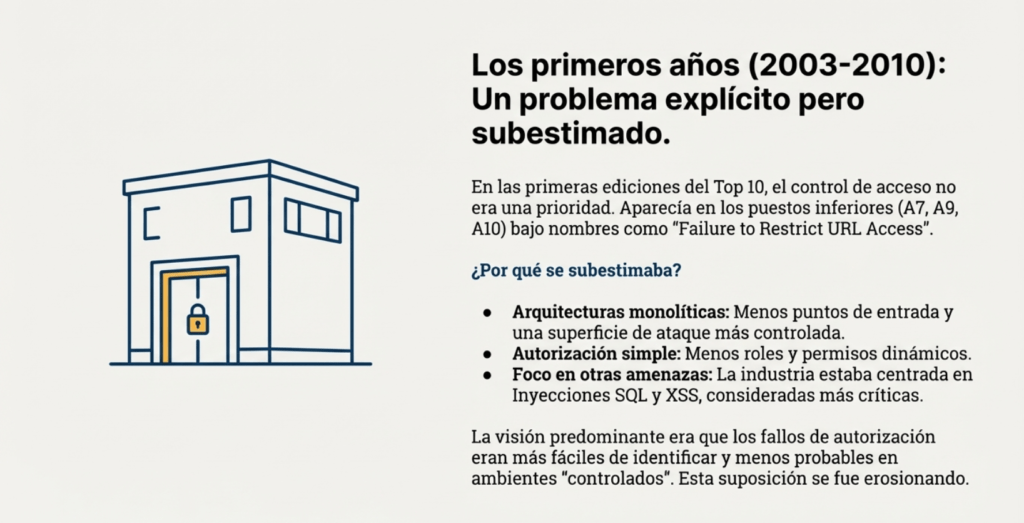
A lo largo de dos décadas, pocas categorías de OWASP han sufrido una transformación tan profunda, tanto conceptual como práctica, como Broken Access Control. Lo que hoy conocemos como uno de los mayores riesgos de la seguridad web tuvo, en su origen, un papel secundario dentro del panorama de vulnerabilidades más reconocidas. Durante los primeros años del OWASP Top 10 —específicamente entre 2003 y 2010— este riesgo no ocupaba un lugar particularmente destacado: su presencia fluctuaba, con diferentes nombres, y generalmente aparecía como un problema “explícito pero subestimado”.
No fue hasta finales de la década de 2010 que la comunidad comenzó a reconocer su impacto real, transformando lo que antes era un riesgo que aparecía al final de la lista en una de las amenazas más graves y recurrentes en entornos modernos. Entender esta transición exige analizar la evolución del desarrollo web, los cambios en la arquitectura de aplicaciones y el crecimiento de tecnologías que incrementaron de forma exponencial la superficie de ataque.
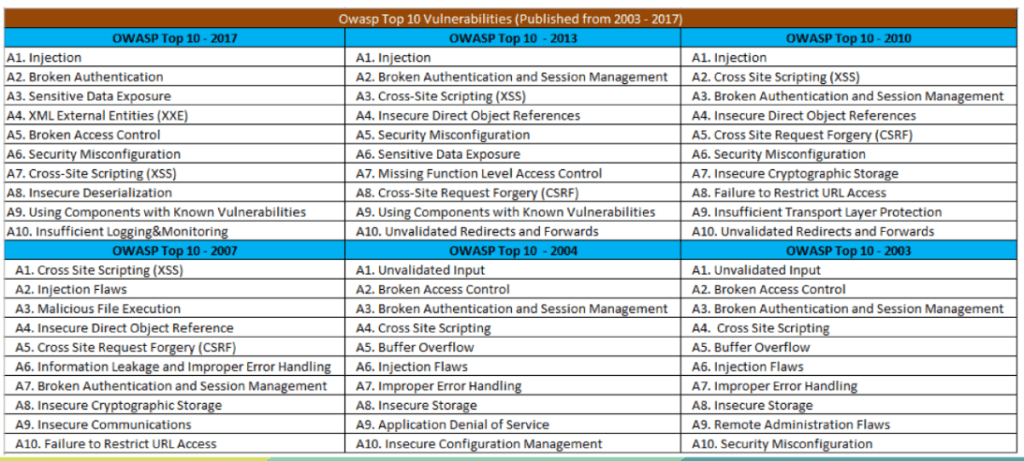
Durante los primeros años del OWASP Top 10 (2003–2010), el control de acceso era visto como un problema más dentro de una constelación mucho mayor de riesgos centrados en fallos de entrada, errores criptográficos o problemas de sesión. La cultura del desarrollo en ese momento era distinta: las aplicaciones seguían modelos monolíticos, los sistemas de autenticación eran más simples, y los patrones de autorización eran menos complejos.
Cuando aparecía, el riesgo se describía como “Broken Access Control” o “Failure to Restrict URL Access”, ocupando normalmente el puesto A7, A8, A9 o incluso A10, lo que dejaba claro que no se lo consideraba un riesgo tan crítico como las inyecciones SQL, XSS o las fallas de autenticación. La visión predominante era que la mayoría de los ataques explotaban validaciones deficientes o manipulaciones directas de entrada, y que los fallos de autorización eran más fáciles de identificar manualmente y menos probables en ambientes “controlados”. Esta suposición se fue erosionando a medida que la web se volvió más interactiva y distribuida.
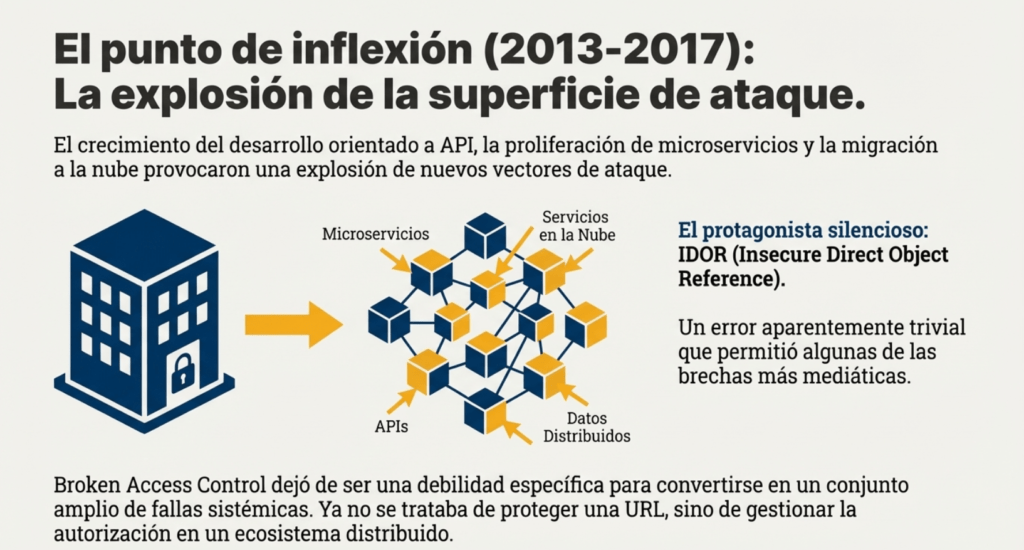
El punto de inflexión comenzó a gestarse entre 2013 y 2017, cuando OWASP registró un aumento notable en la frecuencia de incidentes relacionados con accesos indebidos.
El crecimiento del desarrollo orientado a API, junto con la proliferación de microservicios y la migración masiva a arquitecturas cloud —todas tecnologías que introducen puntos adicionales donde se debe verificar quién puede hacer qué— provocó una explosión de nuevos vectores de ataque centrados en la autorización.
En particular, los fallos del tipo IDOR (Insecure Direct Object Reference) fueron uno de los protagonistas silenciosos en este cambio: un error aparentemente trivial, que permitía a un usuario cambiar un identificador para acceder a recursos ajenos, derivó en algunas de las brechas más mediáticas a nivel global. Esto impulsó a OWASP a reorganizar la categoría en 2017, integrando en un mismo paraguas una larga lista de fallos relacionados con el control de acceso que hasta ese momento se trataban como problemas separados.
Broken Access Control dejó de ser una debilidad específica para convertirse en un conjunto amplio de fallas sistémicas.
OWASP TOP 10 2021

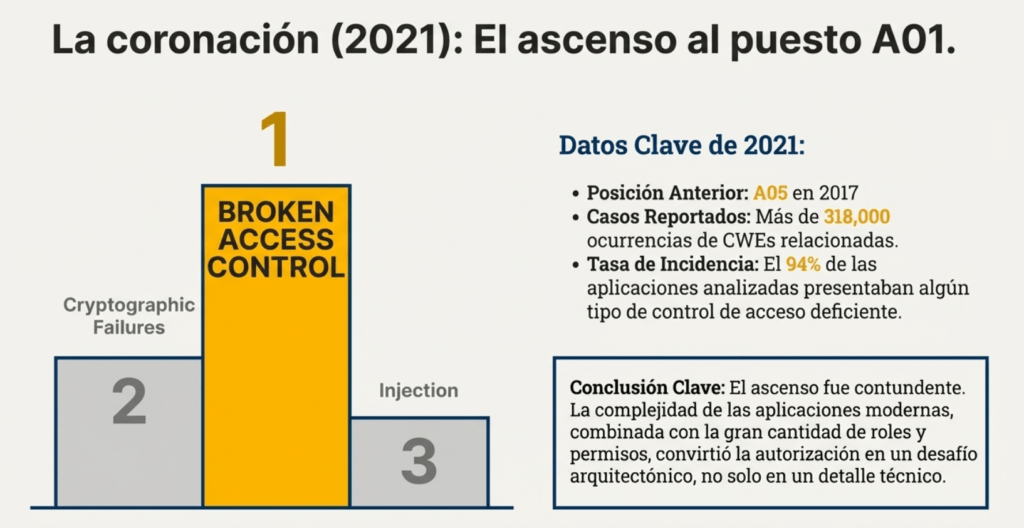
El salto definitivo ocurrió en 2021, cuando Broken Access Control ascendió —por primera vez en la historia del Top 10— al puesto A01, convirtiéndose oficialmente en la vulnerabilidad más crítica reportada a nivel mundial.
La razón de este ascenso fue contundente: OWASP detectó más de 318 000 casos de CWE relacionadas, además de una tasa de incidencia promedio extremadamente alta. Esto reveló que muchos equipos de desarrollo, incluso experimentados, seguían implementando controles de acceso de manera inconsistente, parcial o directamente inexistente. La complejidad de las aplicaciones modernas, combinada con la gran cantidad de roles, permisos dinámicos y recursos expuestos, generó un ecosistema en el que la autorización dejó de ser un detalle técnico y pasó a ser un desafío arquitectónico. Los proxies inversos, las gateway APIs, los sistemas de federación de identidades y los modelos Zero Trust reforzaron esta tendencia: cuanto más complejas eran las aplicaciones, mayor era la probabilidad de errores en la autorización.
OWASP TOP 10 2025
En la lista de los Diez Principales para 2025, se han incorporado dos categorías nuevas y una consolidada. Esta versión según OWASP está centrada en la causa raíz, más que en los síntomas, en la medida de lo posible. Dada la complejidad de la ingeniería y la seguridad del software, resulta prácticamente imposible crear diez categorías sin cierto grado de superposición.
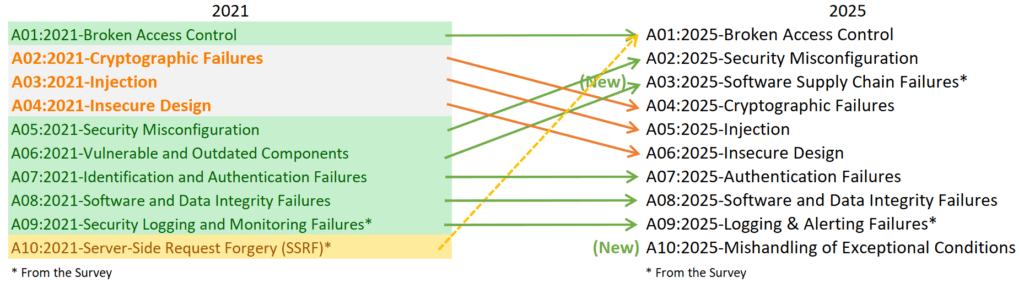
Con la llegada del OWASP Top 10 – 2025, el panorama vuelve a reordenarse, no porque Broken Access Control haya disminuido su importancia —al contrario, continúa como el puesto A01— sino porque su ubicación dominante refleja la madurez de la industria en entender que este problema no es un incidente aislado, sino una falla estructural que atraviesa todo el ciclo de vida del software.
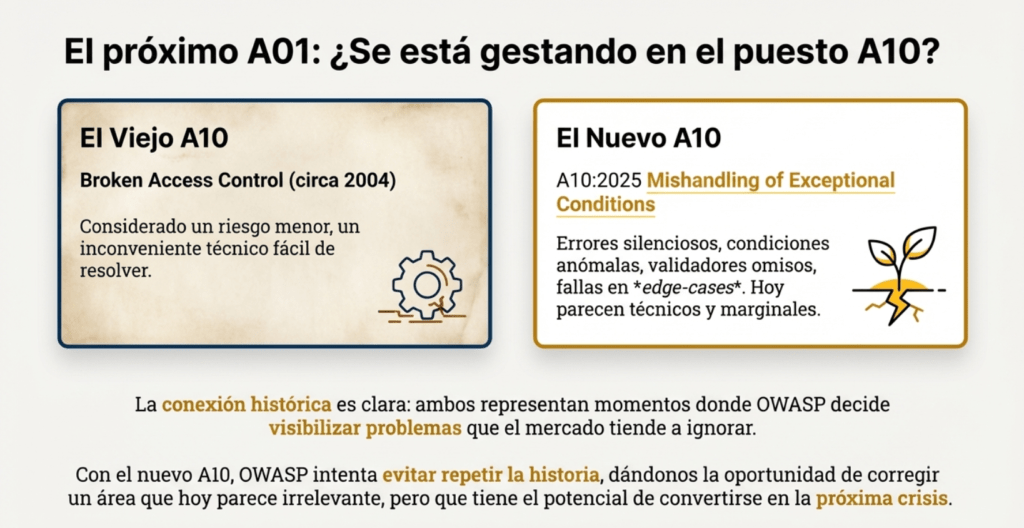
Sin embargo, su historia está íntimamente conectada al puesto 10 de 2025, «Mishandling of Exceptional Conditions». El nuevo A10 es un heredero conceptual de varios errores que antes se consideraban secundarios, tal como le ocurrió a Broken Access Control en su momento. En 2025, el Top 10 agrupa este tipo de fallos —errores silenciosos, condiciones anómalas, validadores omisos, fallas en edge-cases— que muchas veces generan bypasses de autorización, comportamientos inesperados y, en última instancia, vulnerabilidades que pueden convertir aplicaciones seguras en sistemas completamente comprometidos.
La conexión histórica entre el viejo “Broken Access Control en A10” y el nuevo “A10 en 2025” es clara: ambos representan momentos donde OWASP decide visibilizar problemas que el mercado ignoraba. En su momento, Broken Access Control era visto como un error menor, casi un inconveniente que podía resolverse con buenas prácticas básicas. Sin embargo, la evolución demostró que estos fallos eran el origen de algunas de las brechas más devastadoras. Con “Mishandling of Exceptional Conditions”, OWASP intenta evitar repetir el patrón histórico: darle al sector la oportunidad de corregir un área que hoy parece técnica, marginal o incluso irrelevante, pero que puede transformarse en el próximo A01 si la industria no actúa a tiempo.
La evolución del control de acceso dentro del OWASP Top 10 —desde un puesto marginal como A10 en sus primeros años hasta consolidarse como el riesgo n.º 1 en 2021 y 2025— es un reflejo directo de cómo creció la complejidad del software moderno. Lo que antes se consideraba un error obvio hoy es una disciplina multidimensional que requiere reglas de negocio claras, controles centralizados, servicios de autorización distribuidos y arquitecturas Zero Trust robustas. Su ascenso también sirve como una advertencia: las debilidades que hoy ocupan los últimos lugares, como el nuevo A10 de 2025, pueden convertirse en los problemas críticos del futuro si no se les presta atención. Broken Access Control, que alguna vez fue un riesgo pequeño, nos demostró que las vulnerabilidades más subestimadas suelen ser las que más impacto terminan teniendo.
A01:2025 Control de acceso roto
Manteniendo su posición número 1 en el Top Ten, el 100% de las aplicaciones analizadas presentaron algún tipo de control de acceso deficiente. Entre las CWE más destacadas se encuentran CWE-200: Exposición de información confidencial a un agente no autorizado , CWE-201: Exposición de información confidencial a través de datos enviados , CWE-918: Falsificación de solicitud del lado del servidor (SSRF) y CWE-352: Falsificación de solicitud entre sitios (CSRF) . Esta categoría presenta el mayor número de incidencias en los datos aportados y la segunda mayor cantidad de CVE relacionados.

Tabla de puntuación.
| CWE mapeados | Tasa máxima de incidencia | Tasa de incidencia promedio | Cobertura máxima | Cobertura promedio | Exploit ponderado promedio | Impacto ponderado promedio | Total de ocurrencias | Total de CVEs |
| 40 | 20,15% | 3,74% | 100.00% | 42,93% | 7.04 | 3.84 | 1.839.701 | 32.654 |

Descripción.
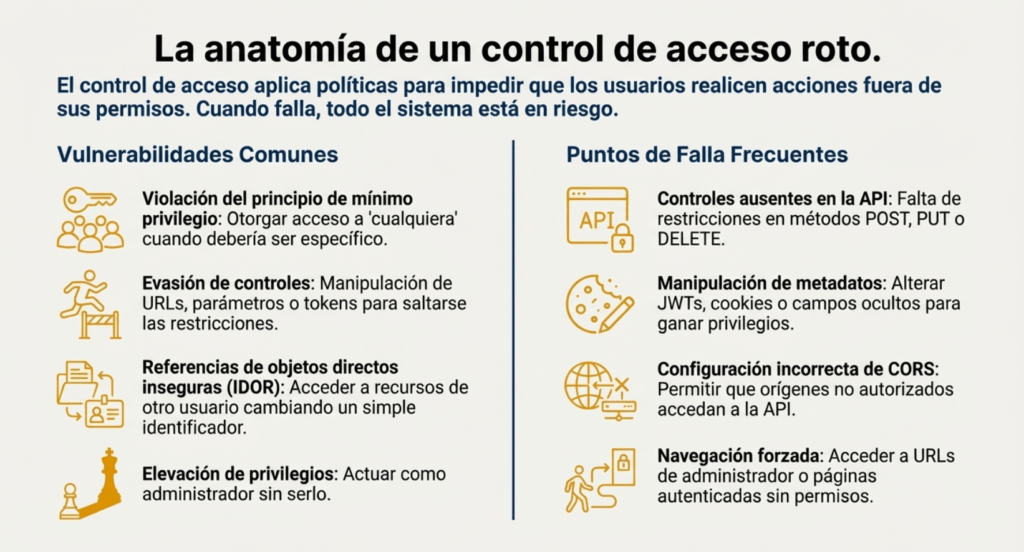
El control de acceso aplica políticas diseñadas para impedir que los usuarios realicen acciones fuera de sus permisos asignados. Cuando este control falla, puede provocar la divulgación, modificación o destrucción no autorizada de información, o la ejecución de funciones empresariales fuera de los límites establecidos. Entre las vulnerabilidades más comunes del control de acceso se encuentran:
- Violación del principio de mínimo privilegio o denegación por defecto: el acceso debería concederse únicamente a usuarios, roles o capacidades específicas, pero se otorga a cualquiera.
- Evasión de controles de acceso: mediante la manipulación de URLs, parámetros, estados internos de la aplicación o solicitudes de API.
- Referencias de objetos directos inseguras (IDOR): permitir acceder o modificar la cuenta de otro usuario proporcionando su identificador único.
- Controles ausentes en la API: falta de restricciones adecuadas para operaciones POST, PUT o DELETE.
- Elevación de privilegios: actuar como un usuario autenticado sin iniciar sesión o como administrador sin los permisos correspondientes.
- Manipulación de metadatos: alterar tokens JWT, cookies o campos ocultos para obtener privilegios o abusar del mecanismo de invalidación.
- Configuraciones incorrectas de CORS: permiten que orígenes no autorizados accedan a la API.
- Navegación forzada: acceder a páginas autenticadas o privilegiadas sin los permisos necesarios.
Cómo prevenir.
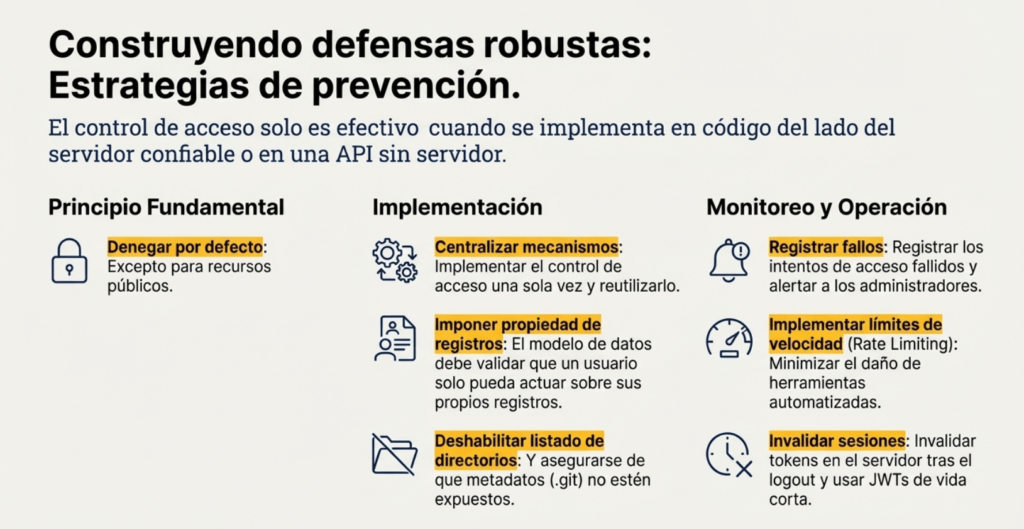
El control de acceso solo es efectivo cuando se implementa en código del lado del servidor confiable o en API sin servidor, donde el atacante no puede modificar la verificación de control de acceso ni los metadatos.
- Excepto para recursos públicos, denegar por defecto.
- Implemente mecanismos de control de acceso una sola vez y reutilícelos en toda la aplicación, lo que incluye minimizar el uso de recursos compartidos de origen cruzado (CORS).
- Los controles de acceso al modelo deben imponer la propiedad de los registros en lugar de permitir que los usuarios creen, lean, actualicen o eliminen cualquier registro.
- Los modelos de dominio deben imponer requisitos de límites de negocio de aplicaciones únicas.
- Deshabilite la lista de directorios del servidor web y asegúrese de que los metadatos de los archivos (por ejemplo, .git) y los archivos de respaldo no estén presentes en las raíces web.
- Registrar los fallos de control de acceso y alertar a los administradores cuando corresponda (por ejemplo, fallos repetidos).
- Implemente límites de velocidad en el acceso a API y controladores para minimizar el daño de las herramientas de ataque automatizadas.
- Los identificadores de sesión con estado deben invalidarse en el servidor tras cerrar la sesión. Los tokens JWT sin estado deben tener una vida útil corta para minimizar la ventana de oportunidad para un atacante. Para los JWT de larga duración, se recomienda encarecidamente seguir los estándares de OAuth para revocar el acceso.
- Utilice kits de herramientas o patrones bien establecidos que proporcionen controles de acceso simples y declarativos.
Los desarrolladores y el personal de control de calidad deben incluir control de acceso funcional en sus pruebas unitarias y de integración.
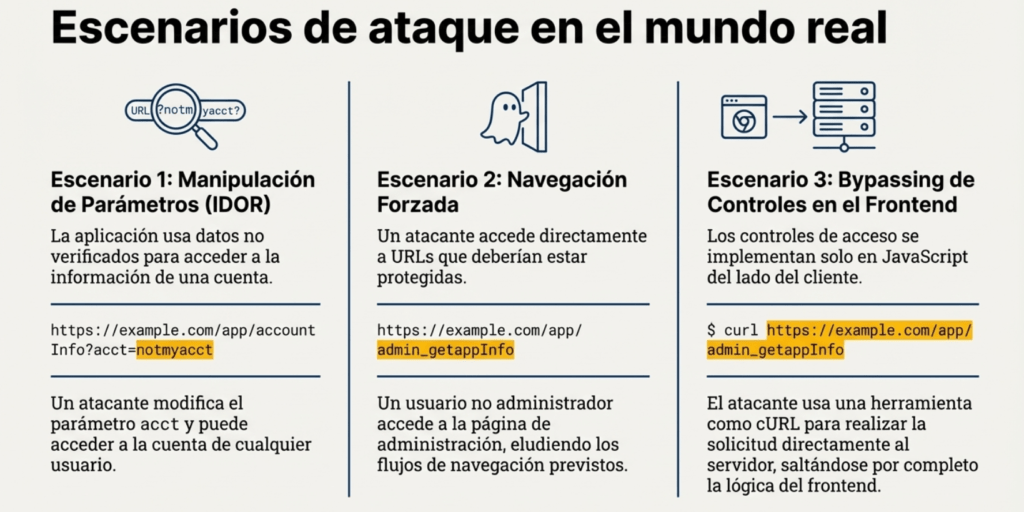
Ejemplos de escenarios de ataque.
Escenario n.° 1:
La aplicación utiliza datos no verificados en una llamada SQL que accede a la información de la cuenta:
pstmt.setString(1, request.getParameter(«acct»));
ResultSet results = pstmt.executeQuery( );
Un atacante puede simplemente modificar el parámetro «acct» del navegador para enviar cualquier número de cuenta. Si no se verifica correctamente, el atacante puede acceder a la cuenta de cualquier usuario.
https://example.com/app/accountInfo?acct=notmyacct
Escenario n.° 2
Un atacante simplemente fuerza a los navegadores a acceder a las URL objetivo. Se requieren derechos de administrador para acceder a la página de administración.
https://example.com/app/getappInfo
https://example.com/app/admin_getappInfo
Si un usuario no autenticado puede acceder a cualquiera de las páginas, se trata de una falla. Si un usuario no administrador puede acceder a la página de administración, se trata de una falla.
Escenario n.° 3
Una aplicación establece todo su control de acceso en su frontend. Aunque el atacante no puede acceder a él https://example.com/app/admin_getappInfodebido al código JavaScript que se ejecuta en el navegador, puede simplemente ejecutar:
$ curl https://example.com/app/admin_getappInfo
desde la línea de comandos.
ANTERIORMENTE A01:2021 –Broken_Access_Control
| CWE asignados | Tasa de incidencia máxima | Tasa de incidencia promedio | Explotación media ponderada | Impacto medio ponderado | Cobertura máxima | Cobertura promedio | Ocurrencias totales | ECV totales |
| 34 | 55,97% | 3,81% | 6.92 | 5.93 | 94,55% | 47,72% | 318,487 | 19,013 |
Desde la quinta posición, el 94 % de las aplicaciones se analizaron para detectar algún tipo de control de acceso deficiente, con una tasa de incidencia promedio del 3,81 %, y presenta la mayor incidencia en el conjunto de datos aportado, con más de 318 000. Entre las Enumeraciones de Debilidades Comunes (CWE) más destacadas se incluyen CWE-200: Exposición de información confidencial a un agente no autorizado , CWE-201: Inserción de información confidencial en los datos enviados y CWE-352: Falsificación de solicitud entre sitios .
Los sitios web tienen páginas protegidas contra visitantes habituales. Por ejemplo, solo el administrador del sitio debería poder acceder a una página para gestionar a otros usuarios. Si un visitante del sitio web accede a páginas protegidas que no debería ver, los controles de acceso están dañados.
Un visitante habitual que pueda acceder a páginas protegidas puede provocar lo siguiente:
- Poder ver información confidencial de otros usuarios
- Acceso a funcionalidad no autorizada
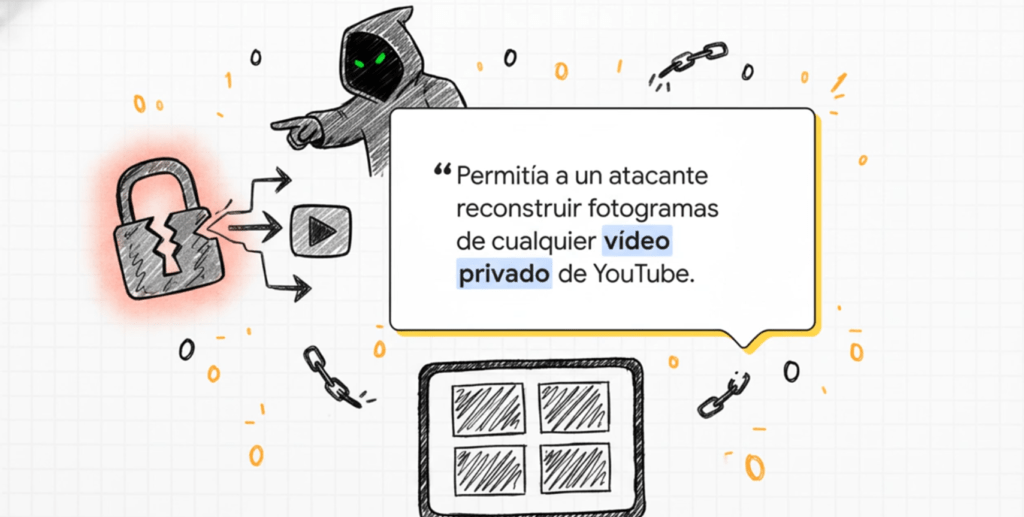
En pocas palabras, el control de acceso roto permite a los atacantes eludir la autorización , lo que les permite ver datos confidenciales o realizar tareas que no deberían. Por ejemplo, en 2019 se descubrió una vulnerabilidad que permitía a un atacante obtener cualquier fotograma de un vídeo de YouTube marcado como privado. El investigador que la descubrió demostró que podía solicitar varios fotogramas y, en cierta medida, reconstruir el vídeo. Dado que la expectativa de un usuario al marcar un vídeo como privado era que nadie tuviera acceso a él, esto se aceptó como una vulnerabilidad de control de acceso deficiente.
ANTERIORMENTE A10:2021 – Falsificación de solicitud del lado del servidor (SSRF)
Factores
| CWE mapeados | Tasa máxima de incidencia | Tasa de incidencia promedio | Exploit ponderado promedio | Impacto ponderado promedio | Cobertura máxima | Cobertura promedio | Total de ocurrencias | Total de CVEs |
| 1 | 2,72% | 2,72% | 8.28 | 6.72 | 67,72% | 67,72% | 9.503 | 385 |
Descripción general
Esta categoría se añade a partir de la encuesta comunitaria Top 10 (n.º 1). Los datos muestran una tasa de incidencia relativamente baja, con una cobertura de pruebas superior a la media y unas calificaciones de potencial de explotación e impacto superiores a la media. Dado que es probable que las nuevas entradas consistan en una sola o un pequeño grupo de Enumeraciones de Debilidades Comunes (EDC) para su atención y concientización, se espera que se les preste atención y se puedan integrar en una categoría más amplia en una próxima edición.
Descripción
Las fallas de SSRF ocurren cuando una aplicación web obtiene un recurso remoto sin validar la URL proporcionada por el usuario. Esto permite a un atacante obligar a la aplicación a enviar una solicitud manipulada a un destino inesperado, incluso estando protegida por un firewall, una VPN u otro tipo de lista de control de acceso a la red (ACL).
A medida que las aplicaciones web modernas ofrecen a los usuarios finales funciones prácticas, obtener una URL se ha convertido en algo habitual. Como resultado, la incidencia de SSRF está aumentando. Además, la gravedad de SSRF es cada vez mayor debido a los servicios en la nube y la complejidad de las arquitecturas.
Cómo prevenir
Los desarrolladores pueden prevenir SSRF implementando algunos o todos los siguientes controles de defensa en profundidad:
Desde la capa de red
- Segmentar la funcionalidad de acceso a recursos remotos en redes separadas para reducir el impacto de SSRF
- Aplique políticas de firewall de «denegación predeterminada» o reglas de control de acceso a la red para bloquear todo el tráfico de intranet, excepto el esencial.
Consejos:
~ Establezca una propiedad y un ciclo de vida para las reglas de firewall según las aplicaciones.
~ Registre todos los flujos de red aceptados y bloqueados en los firewalls (consulte A09:2021 – Registro y monitoreo de fallas de seguridad ).
Desde la capa de aplicación:
- Desinfecte y valide todos los datos de entrada proporcionados por el cliente
- Aplicar el esquema de URL, el puerto y el destino con una lista de permitidos positiva
- No envíe respuestas sin procesar a los clientes
- Deshabilitar redirecciones HTTP
- Tenga en cuenta la consistencia de la URL para evitar ataques como la revinculación de DNS y las condiciones de carrera de “tiempo de verificación, tiempo de uso” (TOCTOU).
No mitigue la SSRF mediante listas de denegación ni expresiones regulares. Los atacantes cuentan con listas de carga útil, herramientas y habilidades para eludir las listas de denegación.
Medidas adicionales a considerar:
- No implemente otros servicios relevantes para la seguridad en sistemas front-end (p. ej., OpenID). Controle el tráfico local en estos sistemas (p. ej., localhost).
- Para frontends con grupos de usuarios dedicados y manejables, utilice cifrado de red (por ejemplo, VPN) en sistemas independientes para considerar necesidades de protección muy altas.
Ejemplos de escenarios de ataque
Los atacantes pueden usar SSRF para atacar sistemas protegidos detrás de firewalls de aplicaciones web, firewalls o ACL de red, utilizando escenarios como:
Escenario n.° 1: escaneo de puertos en servidores internos: si la arquitectura de red no está segmentada, los atacantes pueden mapear las redes internas y determinar si los puertos están abiertos o cerrados en los servidores internos a partir de los resultados de la conexión o el tiempo transcurrido para conectarse o rechazar las conexiones de carga útil SSRF.
Escenario n.° 2: Exposición de datos confidenciales: los atacantes pueden acceder a archivos locales o servicios internos para obtener información confidencial, como file:///etc/passwdy http://localhost:28017/.
Escenario n.° 3: Acceso al almacenamiento de metadatos de los servicios en la nube: la mayoría de los proveedores de servicios en la nube cuentan con almacenamiento de metadatos como [nombre del proveedor http://169.254.169.254/]. Un atacante podría leer los metadatos para obtener información confidencial.
Escenario n.° 4: Comprometer servicios internos: el atacante puede abusar de los servicios internos para realizar otros ataques, como ejecución remota de código (RCE) o denegación de servicio (DoS).
C10: Detener la falsificación de solicitudes del lado del servidor
Mientras que los ataques de inyección suelen dirigirse al propio servidor víctima, los ataques de falsificación de solicitud del lado del servidor (SSRF) intentan obligar al servidor a realizar una solicitud en nombre del atacante. La SSRF se produce cuando un atacante puede engañar a un servidor para que realice solicitudes no deseadas a servicios internos o externos, lo que podría eludir los controles de seguridad.
¿Por qué esto es beneficioso para el atacante? La solicitud saliente se realizará con la identidad del servidor víctima, por lo que el atacante podría ejecutar operaciones con privilegios elevados.
Amenazas
Ejemplos de esto incluyen:
- Si es posible un ataque SSRF en un servidor dentro de la DMZ, un atacante podría acceder a otros servidores dentro de la DMZ sin pasar un firewall perimetral.
- Muchos servidores tienen servicios locales ejecutándose en localhost, a menudo sin autenticación ni autorización como localhost. Esto puede ser objeto de abuso por ataques SSRF.
- Si se utiliza SSO, se puede utilizar SSRF para extraer tokens/tickets/hashes de servidores, etc.
Implementación
Existen múltiples formas de prevenir la SSRF:
- Validación de entrada
- Si se deben realizar solicitudes salientes, verifique el destino con una lista de permitidos
- Si utiliza XML, configure el analizador de forma segura para evitar XEE
Tenga en cuenta Unicode y otras transformaciones de caracteres al realizar la validación de entrada.
Anteriormente 10. Server-Side Request Forgery (SSRF) Falsificación de solicitud del lado del servidor (SSRF)
Este tipo de vulnerabilidad ocurre cuando un atacante puede obligar a una aplicación web a enviar solicitudes en su nombre a destinos arbitrarios, mientras controla el contenido de la solicitud. Las vulnerabilidades SSRF suelen surgir de implementaciones donde nuestra aplicación web necesita usar servicios de terceros. Imagine, por ejemplo, una aplicación web que utiliza una API externa para enviar notificaciones SMS a sus clientes. Para cada correo electrónico, el sitio web debe realizar una solicitud web al servidor del proveedor de SMS para enviar el contenido del mensaje. Dado que el proveedor de SMS cobra por mensaje, requiere que añada una clave secreta, preasignada, a cada solicitud que realice a su API . La clave API funciona como un token de autenticación y permite al proveedor saber a quién facturar cada mensaje. La aplicación funcionaría así:
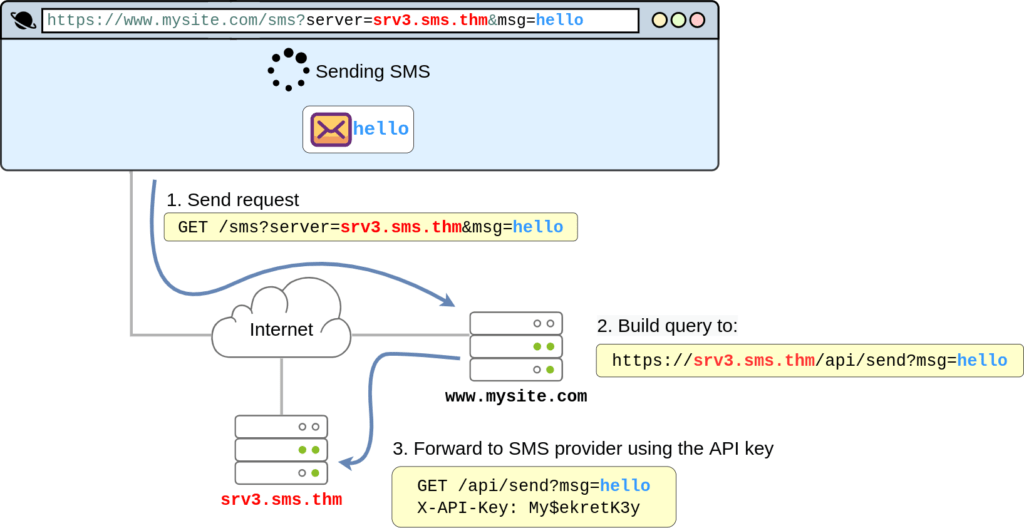
Falsificación de solicitud del lado del servidor
Al observar el diagrama anterior, es fácil ver dónde reside la vulnerabilidad. La aplicación expone server a los usuarios el parámetro que define el nombre del servidor del proveedor de servicios SMS. Si el atacante quisiera, podría simplemente cambiar el valor de para serverque apunte a una máquina que controle, y su aplicación web reenviaría la solicitud SMS al atacante en lugar de al proveedor de SMS. Como parte del mensaje reenviado, el atacante obtendría la clave API, lo que le permitiría usar el servicio SMS para enviar mensajes a su costa. Para lograrlo, el atacante solo necesitaría realizar la siguiente solicitud a su sitio web:
https://www.mysite.com/sms?server=attacker.thm&msg=ABC
Esto haría que la aplicación web vulnerable realice una solicitud a:
https://attacker.thm/api/send?msg=ABC
Luego podrías simplemente capturar el contenido de la solicitud usando Netcat

Autenticación rota y gestión de sesiones
Cuando las funciones de autenticación relacionadas con la aplicación no se implementan correctamente, esto permite a los ciberdelincuentes comprometer contraseñas o identificaciones de sesión o explotar otras fallas de implementación utilizando las credenciales de otros usuarios. Comprendamos los agentes de amenaza, los vectores de ataque, la debilidad de seguridad, el impacto técnico y los impactos comerciales de esta falla con la ayuda de un diagrama simple.
Los sitios web generalmente crean una cookie de sesión y un ID de sesión para cada sesión válida, y estas cookies contienen datos confidenciales como nombre de usuario, contraseña, etc. Cuando se finaliza la sesión, ya sea por cierre de sesión o por cierre abrupto del navegador, estas cookies deben invalidarse, es decir, para cada sesión debe haber una nueva cookie.
Si las cookies no se invalidan, los datos confidenciales permanecerán en el sistema. Por ejemplo, si un usuario utiliza una computadora público (un cibercafé), las cookies del sitio vulnerable permanecerán en el sistema y quedarán expuestas a un atacante. Si un atacante utiliza el mismo equipo público después de un tiempo, los datos confidenciales se verán comprometidos.
De la misma manera, un usuario que utiliza un dispositivo público, en lugar de cerrar sesión, cierra el navegador de forma abrupta. Un atacante utiliza el mismo sistema, cuando navega por el mismo sitio vulnerable, se abrirá la sesión anterior de la víctima. El atacante puede hacer lo que quiera, desde robar información del perfil, datos de la tarjeta de crédito, etc.
Se debe realizar una verificación para determinar la solidez de la autenticación y la gestión de sesiones. Las claves, los tokens de sesión y las cookies deben implementarse correctamente sin comprometer las contraseñas.
Objetos vulnerables
- Los ID de sesión expuestos en la URL pueden provocar un ataque de fijación de sesión.
- Los ID de sesión son los mismos antes y después de cerrar sesión e iniciar sesión.
- Los tiempos de espera de sesión no se implementan correctamente.
- La aplicación asigna el mismo ID de sesión para cada nueva sesión.
- Las partes autenticadas de la aplicación están protegidas mediante SSL y las contraseñas se almacenan en formato hash o cifrado.
- La sesión puede ser reutilizada por un usuario con pocos privilegios.
Implicación
- Al aprovechar esta vulnerabilidad, un atacante puede secuestrar una sesión y obtener acceso no autorizado al sistema, lo que permite la divulgación y modificación de información no autorizada.
- Las sesiones pueden ser secuestradas utilizando cookies robadas o sesiones que utilizan XSS.
Ejemplos
- La aplicación de reservas de aerolíneas admite la reescritura de URL, colocando los identificadores de sesión en la URL: http://Examples.com/sale/saleitems;jsessionid=2P0OC2oJM0DPXSNQPLME34SERTBG/dest=Maldives (Venta de boletos a Maldivas) Un usuario autenticado del sitio desea informar a sus amigos sobre la venta y les envía un correo electrónico. Los amigos reciben el identificador de sesión y pueden usarlo para realizar modificaciones no autorizadas o hacer un uso indebido de los datos de la tarjeta de crédito guardados.
- Una aplicación es vulnerable a XSS, mediante el cual un atacante puede acceder al ID de la sesión y puede usarse para secuestrar la sesión.
- Los tiempos de espera de las aplicaciones no están configurados correctamente. El usuario utiliza una computadora pública y cierra el navegador en lugar de cerrar sesión y se marcha. El atacante utiliza el mismo navegador algún tiempo después y la sesión se autentica.
Recomendaciones
- Todos los requisitos de autenticación y gestión de sesiones deben definirse según el Estándar de verificación de seguridad de aplicaciones OWASP.
- Nunca exponga ninguna credencial en URL o registros.
- También se deben realizar grandes esfuerzos para evitar fallas XSS que puedan usarse para robar identificaciones de sesión.
Enforce Access Controls – Hacer cumplir los controles de acceso
El control de acceso (o autorización) consiste en permitir o denegar solicitudes específicas de un usuario, programa o proceso. En cada decisión, un sujeto solicita acceso a un objeto, y el sistema evalúa si la política definida le otorga ese permiso. Este proceso no solo determina si se concede o no el acceso, sino que también abarca la concesión y revocación de privilegios. El control de acceso debe aplicarse en múltiples niveles. Por ejemplo, una aplicación con un backend de base de datos debe implementar controles tanto en la lógica de negocio como en el nivel de datos. Asimismo, cuando una aplicación ofrece distintas formas de interactuar (por ejemplo, una API y una interfaz web), todos los puntos de entrada deben compartir las mismas comprobaciones de control de acceso.
⚠️ Nota: La autenticación (verificar la identidad del usuario) no es lo mismo que la autorización (verificar qué acciones puede realizar).
Amenazas
- Políticas mal configuradas: un atacante podría acceder a datos o funcionalidades que la organización no pretendía exponer.
- Componentes inconsistentes: si la aplicación tiene varios módulos de control de acceso, el atacante podría explotar el más débil.
- Cuentas olvidadas: una cuenta antigua no deshabilitada puede ser reutilizada por un atacante.
- Ausencia de denegación predeterminada: si no se aplica la regla de “denegar por defecto”, el atacante podría acceder a datos al no encontrar una restricción explícita.
Control de acceso
- El control de acceso discrecional (DAC) es un medio para restringir el acceso a objetos (archivos, entidades de datos) en función de la identidad y la necesidad de saber de los sujetos (usuarios, procesos) y/o grupos a los que pertenece el objeto. .
- El control de acceso obligatorio (MAC) es un medio para restringir el acceso a los recursos del sistema en función de la confidencialidad (representada por una etiqueta) de la información contenida en el recurso del sistema y la autorización formal (es decir, autorización) de los usuarios para acceder a la información de dicho recurso. sensibilidad.
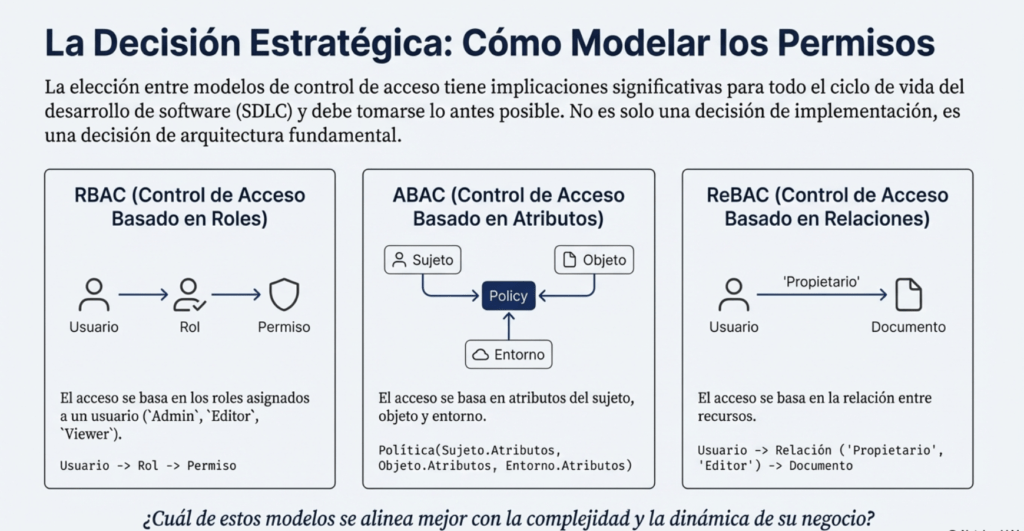
- El control de acceso basado en roles (RBAC) es un modelo para controlar el acceso a los recursos donde las acciones permitidas en los recursos se identifican con roles en lugar de con identidades de sujetos individuales.
- El control de acceso basado en atributos (ABAC) otorgará o denegará las solicitudes de los usuarios en función de los atributos arbitrarios del usuario y los atributos arbitrarios del objeto, y las condiciones ambientales que pueden ser reconocidas globalmente y más relevantes para las políticas en cuestión.
Principios de diseño de control de acceso
Los siguientes requisitos de diseño de control de acceso «positivos» deben considerarse en las etapas iniciales del desarrollo de la aplicación.
1 Diseñar el control de acceso a fondo desde el principio
El diseño del control de acceso debe planificarse cuidadosamente desde las primeras etapas del desarrollo. Rediseñarlo más adelante suele ser costoso y complejo. Es esencial definir cómo se manejarán los casos de multi-tenencia y acceso horizontal (dependiente de los datos). Existen dos enfoques principales:
- RBAC (Role-Based Access Control): asigna permisos según roles predefinidos (por ejemplo, admin, usuario, auditor).
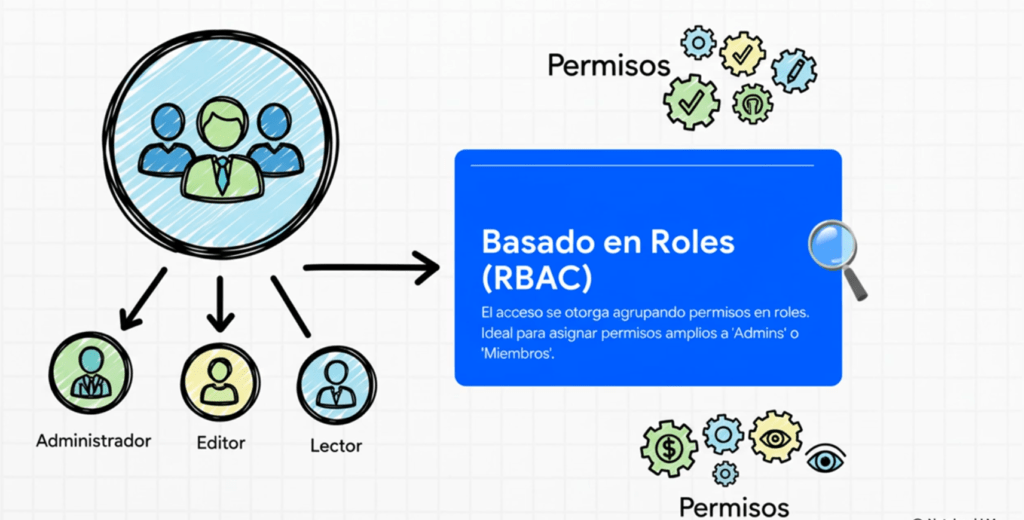
- ABAC (Attribute-Based Access Control): concede o deniega el acceso basándose en atributos del usuario, del recurso y del entorno (por ejemplo, hora del día, ubicación, tipo de dispositivo).

Aunque el modelo RBAC es más simple, ABAC ofrece mayor flexibilidad y granularidad.
2. Verificar todas las solicitudes de acceso
Todas las peticiones deben pasar por una capa de verificación centralizada. Esto puede lograrse mediante filtros (como Java Filters) u otros mecanismos automáticos que aseguren que cada solicitud sea evaluada antes de procesarse. A este punto se lo conoce como el Punto de Aplicación de Políticas (Policy Enforcement Point), según la RFC 2904.
3. Consolidar la lógica de verificación
Centralizar la verificación de control de acceso en un único procedimiento o biblioteca evita inconsistencias entre módulos. De esta forma, es posible auditar, revisar y mejorar una sola función de seguridad reutilizable en toda la organización.
4. Denegar por defecto
Toda solicitud debe ser rechazada por defecto, a menos que una política explícita la permita. Ejemplos:
- Si el sistema lanza una excepción o error durante la validación, el acceso debe denegarse automáticamente.
- Cuando se crea un nuevo usuario, debe tener acceso mínimo o nulo hasta que se configure manualmente.
- Al incorporar una nueva función, debe estar deshabilitada por defecto hasta asignar los permisos adecuados.
5. Principio de Mínimo Privilegio y Acceso Justo a Tiempo (JIT/JEA)
Asigne a cada usuario o proceso solo los permisos estrictamente necesarios para cumplir su función. Evite el uso habitual de cuentas globales con privilegios totales.
- JIT (Just-In-Time): el acceso se concede temporalmente solo cuando se necesita.
- JEA (Just Enough Access): el acceso es limitado al mínimo indispensable para realizar una tarea específica.
Estas estrategias reducen el riesgo de abuso y exposición en caso de compromiso.
6. Evitar roles codificados de forma rígida
El código rígido basado en roles predefinidos es una práctica riesgosa y poco flexible:
if (user.hasRole(«ADMIN») || user.hasRole(«MANAGER»)) {
deleteAccount();
}
Problemas comunes:
- Propenso a errores e inconsistencias.
- No permite multi-tenencia (distintas reglas por cliente).
- Dificulta la auditoría de políticas en grandes bases de código.
- Puede generar puertas traseras si se descubren roles con privilegios excesivos.
7. Ejemplo de punto de cumplimiento de políticas (ABAC)
Una implementación más segura es verificar permisos específicos en lugar de roles genéricos:
if (user.hasPermission(«DELETE_ACCOUNT»)) {
deleteAccount();
}
Este enfoque permite construir sistemas más granulares, auditables y adaptables, facilitando su evolución con el tiempo.
Revocar el acceso
Existen varias razones por las cuales puede ser necesario revocar el acceso de una aplicación a una cuenta:
- El usuario decide retirar permisos de una aplicación que ya no usa.
- El desarrollador desea revocar todos los tokens asociados a su aplicación.
- La aplicación fue eliminada.
- El proveedor del servicio detecta que la aplicación es maliciosa o comprometida.
El método para revocar tokens depende de cómo se gestionen:
a) Tokens almacenados en base de datos
Si los tokens se guardan en una base de datos, pueden revocarse fácilmente eliminándolos. El servidor de recursos, al intentar validar el token, no lo encontrará y negará el acceso.
b) Tokens autocodificados (sin estado)
Cuando los tokens son autoverificables, la revocación inmediata no es posible:
- Se debe esperar a que caduquen naturalmente.
- Se deben bloquear las solicitudes de renovación para ese cliente o usuario.
Una alternativa es mantener una lista de revocación distribuida entre los servidores de recursos, que permita invalidar tokens específicos identificados por su jti (JWT ID). También se deben invalidar los tokens de actualización (refresh tokens) para evitar que se soliciten nuevos accesos después de la revocación.
En Resumen: El control de acceso debe diseñarse de forma centralizada, con denegación por defecto, mínimo privilegio y revisiones constantes. La revocación de permisos y tokens debe ser parte del proceso de mantenimiento, garantizando que los accesos concedidos sean siempre temporales, justificados y auditables.
OWASP Cheat Sheet: Authorization – Guía de referencia de autorización
La autorización puede definirse como «el proceso de verificación de que una acción o servicio solicitado está aprobado para una entidad específica» ( NIST). La autorización es distinta de la autenticación, que es el proceso de verificar la identidad de una entidad.
Al diseñar y desarrollar una solución de software, es importante tener en cuenta estas distinciones. Un usuario que ha sido autenticado (quizás proporcionando un nombre de usuario y una contraseña) a menudo no está autorizado para acceder a todos los recursos y realizar todas las acciones que son técnicamente posibles a través de un sistema. Por ejemplo, una aplicación web puede tener usuarios regulares y administradores, y los administradores pueden realizar acciones que el usuario promedio no tiene privilegios para hacerlo, aunque se hayan autenticado. Además, no siempre se requiere autenticación para acceder a los recursos; un usuario no autenticado puede estar autorizado para acceder a ciertos recursos públicos, como una imagen o una página de inicio de sesión, o incluso una aplicación web completa.
El objetivo de esta guia es ayudar a los desarrolladores a implementar una lógica de autorización que sea robusta, apropiada para el contexto comercial de la aplicación, mantenible y escalable. La guía proporcionada debe ser aplicable a todas las fases del ciclo de vida del desarrollo y lo suficientemente flexible para satisfacer las necesidades de diversos entornos de desarrollo.
Las fallas relacionadas con la lógica de autorización son una preocupación notable para las aplicaciones web. Broken Access Control se clasificó como la vulnerabilidad de seguridad web más preocupante en el Top 10 de 2021 de OWASP y se afirmó que tiene una probabilidad «alta» de ser explotada por el programa CWE de MITRE . Además, según el Estado del software de Veracode, vol. 10 , el control de acceso se encontraba entre los 10 riesgos principales más comunes de OWASP que se involucran en exploits e incidentes de seguridad a pesar de estar entre los menos frecuentes de los examinados.
El impacto potencial resultante de la explotación de fallas de autorización es muy variable, tanto en forma como en gravedad. Los atacantes pueden leer, crear, modificar o eliminar recursos que debían protegerse (poniendo así en peligro su confidencialidad, integridad y/o disponibilidad); sin embargo, el impacto real de tales acciones está necesariamente ligado a la criticidad y sensibilidad de los recursos comprometidos.
Por lo tanto, el costo comercial de una falla de autorización explotada con éxito puede variar de muy bajo a extremadamente alto. Tanto los usuarios externos completamente no autenticados como los usuarios autenticados (pero no necesariamente autorizados) pueden aprovechar las debilidades de autorización.
Si bien los errores honestos o el descuido por parte de entidades no maliciosas pueden permitir eludir la autorización, normalmente se requiere una intención maliciosa para que las amenazas de control de acceso se realicen por completo. La elevación de privilegios horizontales (poder acceder a los recursos de otro usuario) es una debilidad especialmente común que un usuario autenticado puede aprovechar.
Las fallas relacionadas con el control de autorización pueden permitir que personas internas y externas malintencionadas vean, modifiquen o eliminen recursos confidenciales de todas las formas (registros de bases de datos, archivos estáticos, información de identificación personal (PII), etc.) o realicen acciones, como crear una nueva cuenta o iniciar un pedido costoso, que no deberían tener el privilegio de hacer. Además, si el registro relacionado con el control de acceso no está configurado correctamente, tales violaciones de autorización pueden pasar desapercibidas o, al menos, no ser atribuibles a un individuo o grupo en particular.

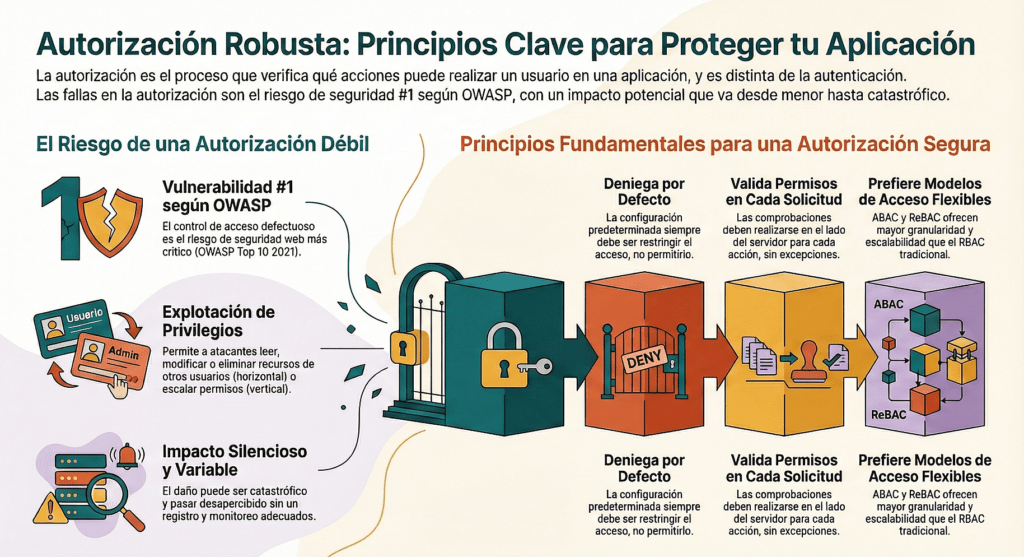
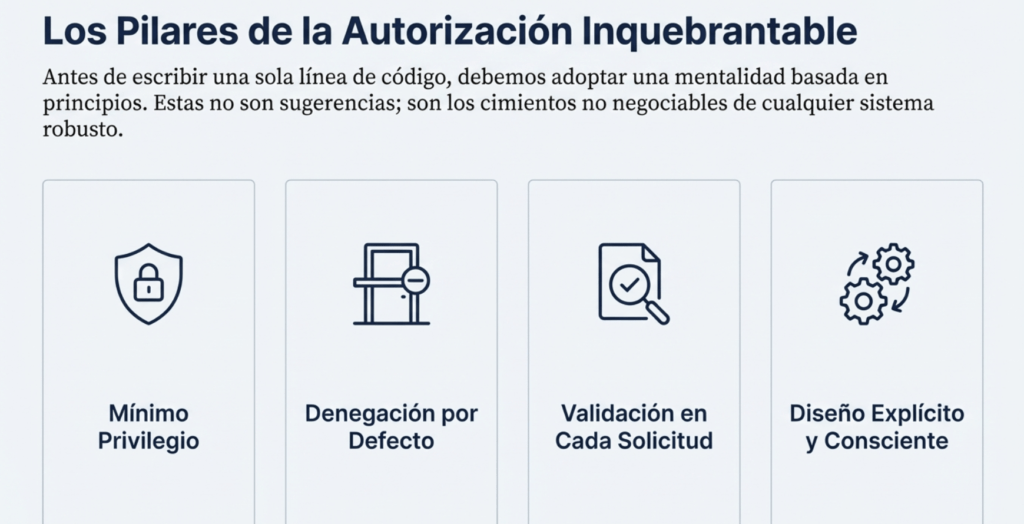
Hacer cumplir los privilegios mínimos
La autorización es verificar que una acción o servicio solicitado está permitido para una entidad concreta (NIST). Es distinta de la autenticación, que establece la identidad. Un usuario puede estar autenticado y no estar autorizado para todo. También puede haber recursos públicos accesibles sin autenticación (por ejemplo, una imagen o la página de login).
Esta guía ayuda a diseñar una lógica de autorización robusta, alineada con el negocio, mantenible y escalable, aplicable durante todo el SDLC.
Los fallos de autorización son frecuentes y de alto impacto: permiten leer/crear/modificar/eliminar recursos protegidos y realizar acciones no permitidas. Tanto usuarios externos no autenticados como internos autenticados (p. ej., elevación horizontal) pueden explotarlos. Sin registro adecuado, estos incidentes pueden pasar inadvertidos.
Recomendaciones
Aplicar privilegios mínimos
Asigne solo los permisos imprescindibles (principio de mínimo privilegio) en sentido horizontal (diferentes funciones acceden a distintos recursos) y vertical (niveles jerárquicos).
Buenas prácticas:
- Diseño: defina límites de confianza, tipos de usuarios, recursos y operaciones permitidas por tipo/atributo (en ABAC incluya atributos de sujeto, recurso y entorno: horario, red, dispositivo).
- Pruebas: cree tests que verifiquen los permisos definidos.
- Revisión continua: detecte “creep” de privilegios frente al diseño aprobado.
- Planificación: es más fácil conceder permisos adicionales que retirarlos después.

Denegar por defecto
La aplicación debe decidir siempre y, por seguridad, negar por defecto cuando no haya una regla aplicable.
- Justifique explícitamente cada permiso concedido.
- Prefiera configuraciones explícitas a confiar en valores por defecto de frameworks, que pueden cambiar.
Validar los permisos en cada solicitud
Compruebe permisos en cada request, sin excepción, y de forma global/centralizada:
- Tecnologías útiles: Java/Jakarta Filters (p. ej., Spring Security), middleware de Django, filtros de .NET Core, middleware de Laravel.
- Una sola vía omitida compromete la seguridad: “casi siempre” no sirve.

Revise exhaustivamente la lógica de autorización de las herramientas y tecnologías elegidas, implementando una lógica personalizada si es necesario
- Suponga que cualquier componente de terceros puede tener fallos de autorización.
- Procese vulnerabilidades: inventario, advisories, NVD; integre herramientas (p. ej., Dependency-Check).
- Aplique defensa en profundidad: no dependa de un único control.
- Configure (no use defaults) y pruebe la configuración en su entorno.
- Defina requisitos de autorización antes de elegir framework; compleméntelo con lógica propia si es insuficiente.
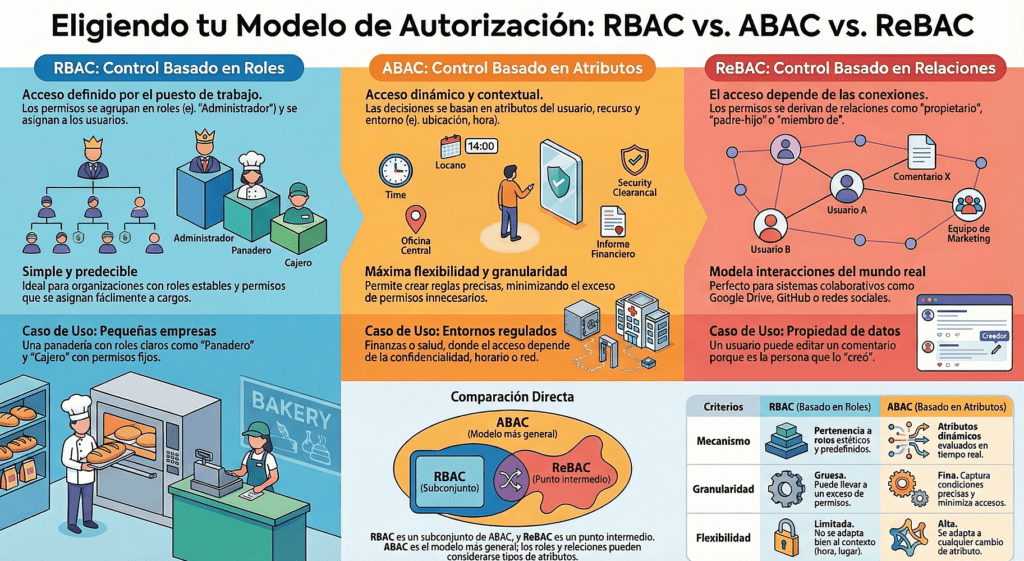
Preferir el control de acceso basado en atributos y relaciones en lugar de RBAC
- RBAC: permisos por rol; simple pero limitado ante decisiones finas u horizontales.
- ABAC: decisiones por atributos de sujeto/objeto/entorno (hora, dispositivo, ubicación, formación, etc.); más expresivo y apto para mínimo privilegio.
- ReBAC: decisiones por relaciones (p. ej., “solo el autor puede editar su post”), esencial en escenarios sociales.
- Ventajas de ABAC/ReBAC: granularidad, menos errores por “explosión de roles”, mejor rendimiento/gestión a escala y multi-tenant/interorganizacional más natural.

Aunque RBAC tiene una larga historia y sigue siendo popular entre los desarrolladores de software en la actualidad, ABAC y ReBAC suelen ser los preferidos para el desarrollo de aplicaciones.
ABAC y ReBAC. Sus ventajas sobre RBAC incluyen:
Admite lógica booleana compleja y detallada
En RBAC, las decisiones de acceso se toman en función de la presencia o ausencia de funciones; es decir, la característica principal de una entidad solicitante considerada es el rol o roles que se le asignan. Esta lógica simplista hace un mal trabajo al respaldar las decisiones de control de acceso horizontal o a nivel de objeto y aquellas que requieren múltiples factores.
- ABAC amplía enormemente tanto el número como el tipo de características que se pueden considerar. En ABAC, un «rol» o función de trabajo ciertamente puede ser un atributo asignado a un sujeto, pero no es necesario considerarlo de forma aislada (o en absoluto si esta característica no es relevante para el acceso particular solicitado). Además, ABAC puede incorporar atributos ambientales y otros atributos dinámicos, como la hora del día, el tipo de dispositivo utilizado y la ubicación geográfica. Negar el acceso a un recurso confidencial fuera del horario comercial normal o si un usuario no ha recibido una capacitación completamente obligatoria recientemente son solo algunos ejemplos en los que ABAC podría cumplir con los requisitos de control de acceso que RBAC tendría dificultades para cumplir. Por lo tanto, ABAC es más efectivo que RBAC para abordar el principio de privilegios mínimos.
- ReBAC, dado que admite la asignación de relaciones entre objetos directos y usuarios directos (y no solo un rol), permite permisos detallados. Algunos sistemas también admiten operadores algebraicos como Y y NO para expresar políticas como «si este usuario tiene una relación X pero no una relación Y con el objeto, entonces conceda acceso».
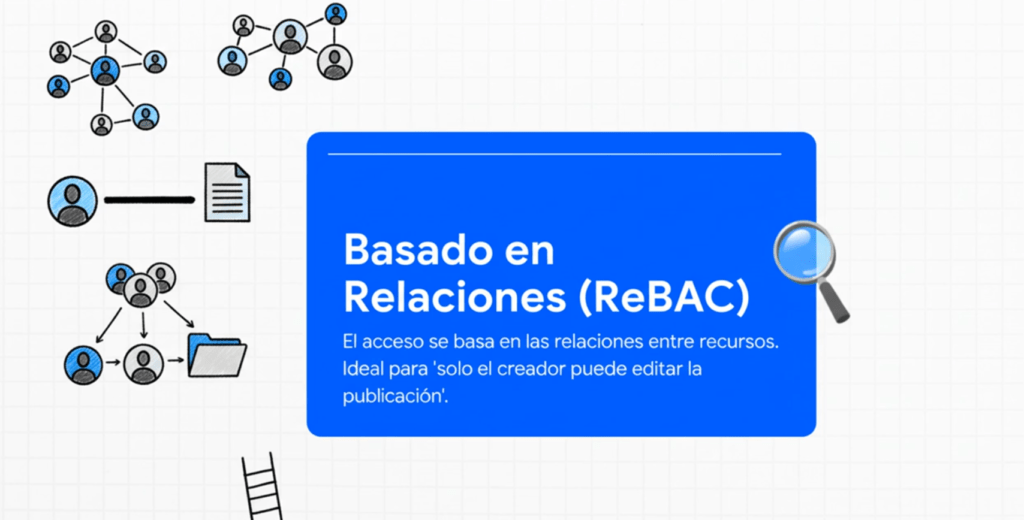
Robustez
En proyectos grandes o cuando hay numerosos roles presentes, es fácil pasar por alto o realizar incorrectamente las comprobaciones de roles ( OWASP C7: Enforce Access Controls ). Esto puede resultar en demasiado o muy poco acceso. Esto es especialmente cierto en las implementaciones de RBAC en las que no existe una jerarquía de roles y se deben encadenar varias verificaciones de roles para lograr el impacto deseado (es decir, ( if(user.hasAnyRole(«SUPERUSER», «ADMIN», «ACCT_MANAGER»)))).
Velocidad
En RBAC, la «explosión de roles» puede ocurrir cuando un sistema define demasiados roles. Si los usuarios envían sus credenciales y funciones a través de medios como encabezados HTTP, que tienen límites de tamaño, es posible que no haya suficiente espacio para incluir todas las funciones del usuario. Una solución viable a este problema es enviar solo la identificación del usuario y luego la aplicación recupera los roles del usuario, pero esto aumentará la latencia de cada solicitud.
Admite solicitudes multiusuario y entre organizaciones
RBAC no es adecuado para casos de uso en los que distintas organizaciones o clientes necesitarán acceso al mismo conjunto de recursos protegidos. Cumplir con dicho requisito con RBAC requeriría métodos muy engorrosos, como configurar conjuntos de reglas para cada cliente en un entorno de múltiples inquilinos o requerir el aprovisionamiento previo de identidades para solicitudes entre organizaciones ( OWASP C7 ; NIST SP 800-162 ). Por el contrario, siempre que los atributos se definan de manera consistente, las implementaciones de ABAC permiten que las decisiones de control de acceso se «ejecuten y administren en la misma infraestructura o en infraestructuras separadas, manteniendo niveles adecuados de seguridad» ( NIST SP 800-162 , pág. 6]).
Facilidad de manejo
Aunque la configuración inicial de RBAC suele ser más sencilla que la de ABAC, este beneficio a corto plazo se desvanece rápidamente a medida que crece la escala y la complejidad de un sistema. Al principio, un par de roles simples, como Usuario y Administrador, pueden ser suficientes para algunas aplicaciones, pero es muy poco probable que esto sea cierto durante un período prolongado en las aplicaciones de producción.
A medida que los roles se vuelven más numerosos, tanto las pruebas como las auditorías, los procesos críticos para establecer la confianza en la base de código y la lógica de uno, se vuelven más difíciles ( OWASP C7). Por el contrario, ABAC y ReBAC son mucho más expresivos, incorporan atributos y lógica booleana que refleja mejor las preocupaciones del mundo real, son más fáciles de actualizar cuando cambian las necesidades de control de acceso y fomentan la separación de la gestión de políticas de la aplicación y el aprovisionamiento de identidades ( NIST SP 800-162 ; consulte también XACML-V3.0 para conocer un estándar que destaca estos beneficios))
Asegúrese de que las ID de búsqueda no sean accesibles incluso cuando se adivinen o no se puedan manipular
Asegúrese de que los ID de búsqueda no sean accesibles incluso cuando se adivinen o no se puedan manipular
- No confíe en IDs “opacos” o aleatorios como única defensa.
- Medidas:
- Evite exponer identificadores; derive recursos desde identidad/atributos del usuario (p. ej., sesión/JWT seguros).
- Use referencias indirectas por sesión/usuario (p. ej., ESAPI).
- Aplique control de acceso por objeto en cada solicitud (un permiso sobre un tipo ≠ permiso sobre todos sus objetos).
Aplicar comprobaciones de autorización en recursos estáticos
- Incluya estáticos (p. ej., buckets S3, GCS, Azure Storage) en la política.
- Clasifique datos y proteja según sensibilidad y contexto.
- Use controles/operativas del proveedor cloud y, cuando sea posible, la misma lógica de autorización que para el resto de la app.
Verifique que las comprobaciones de autorización se realicen en la ubicación correcta
- Nunca confíe en controles del cliente; son solo UX.
- Evalúe en servidor, API gateway o funciones serverless.
Salir de forma segura cuando fallan las comprobaciones de autorización
- Gestione todas las excepciones y fallos de autorización de forma controlada.
- Centralice el manejo de fallos; pruébelo (incluidas rutas raras).
- Evite filtrar datos sensibles en errores (p. ej., stack traces, consultas).
Implementar un registro adecuado
- Registre con formatos consistentes y analizables.
- Equilibre cantidad de logs: ni insuficiente (pierde señales) ni excesivo (ruido o exposición de datos).
- Sincronice relojes/zona horaria.
- Considere centralizar en un SIEM.
Crear casos de prueba unitarios y de integración para la lógica de autorización
- Automatice tests de autorización (unitarios/integración) para detectar regresiones:
- ¿Se niega por defecto?
- ¿El fail termina en estado seguro?
- ¿Se aplican correctamente políticas ABAC/ReBAC?
- No sustituyen pentests, pero reducen fallos que llegan a producción y aceleran correcciones.
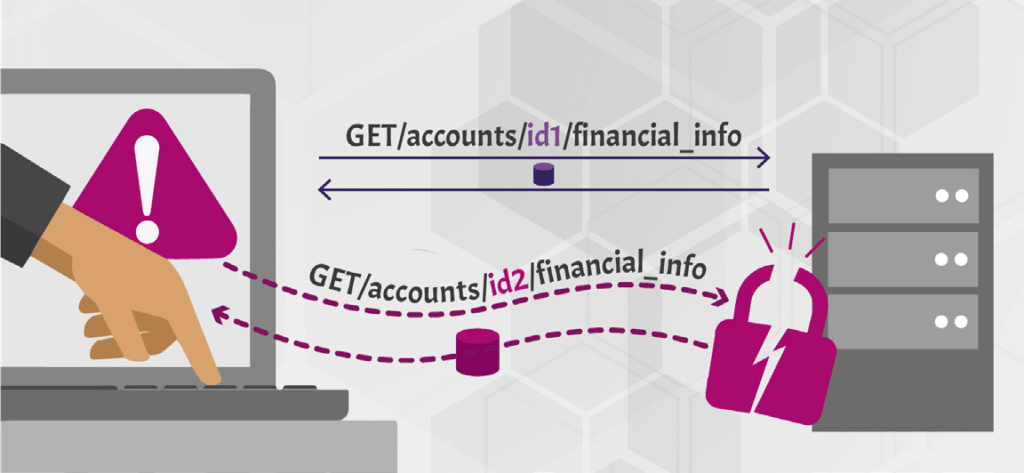
Hoja de trucos para prevenir referencias a objetos directos inseguros
La Referencia Directa a Objetos Insegura (IDOR) es una vulnerabilidad que surge cuando los atacantes pueden acceder o modificar objetos manipulando los identificadores utilizados en las URL o parámetros de una aplicación web. Se produce debido a la falta de comprobaciones de control de acceso, que no verifican si un usuario debe tener acceso a datos específicos.
Ejemplos
Por ejemplo, cuando un usuario accede a su perfil, la aplicación podría generar una URL como esta:
El 123 en la URL es una referencia directa al registro del usuario en la base de datos, a menudo representado por la clave principal. Si un atacante cambia este número a 124 y obtiene acceso a la información de otro usuario, la aplicación es vulnerable a una Referencia Directa a Objetos Insegura. Esto ocurre porque la aplicación no verificó correctamente si el usuario tenía permiso para ver los datos del usuario 124 antes de mostrarlos.
En algunos casos, el identificador puede no estar en la URL, sino en el cuerpo del POST, como se muestra en el siguiente ejemplo:
<form action=»/update_profile» method=»post»>
<!– Other fields for updating name, email, etc. –>
<input type=»hidden» name=»user_id» value=»12345″>
<button type=»submit»>Update Profile</button>
</form>
En este ejemplo, la aplicación permite a los usuarios actualizar sus perfiles enviando un formulario con su ID de usuario en un campo oculto. Si la aplicación no realiza un control de acceso adecuado en el servidor, los atacantes pueden manipular el campo «user_id» para modificar los perfiles de otros usuarios sin autorización.
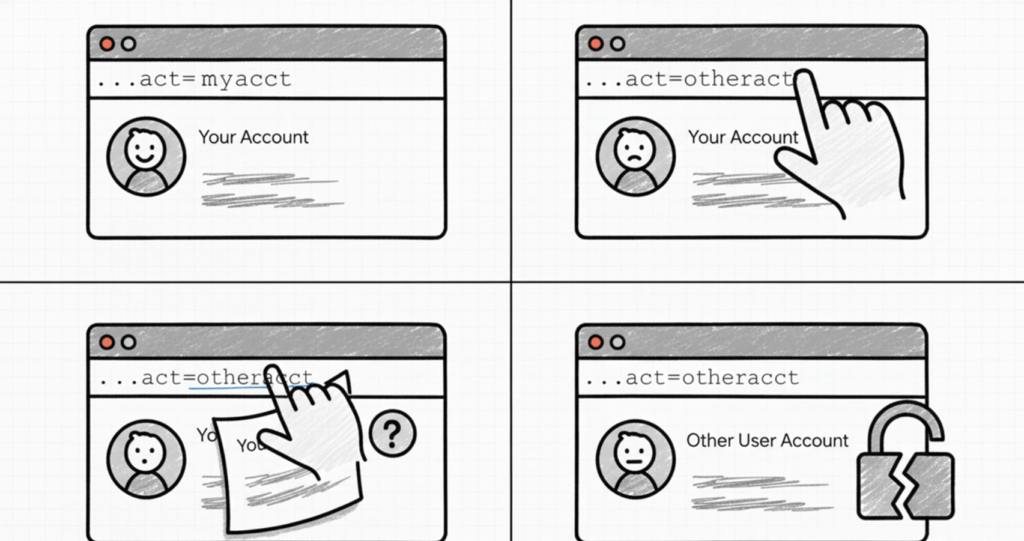
Complejidad del identificador
En algunos casos, el uso de identificadores más complejos, como los GUID, puede hacer prácticamente imposible que los atacantes adivinen valores válidos. Sin embargo, incluso con identificadores complejos, las comprobaciones de control de acceso son esenciales. Si los atacantes obtienen URL de objetos no autorizados, la aplicación debería bloquear sus intentos de acceso.
Mitigación
Para mitigar el IDOR, implemente controles de acceso para cada objeto al que los usuarios intenten acceder. Los frameworks web suelen ofrecer métodos para facilitar esto. Además, utilice identificadores complejos como medida de defensa, pero recuerde que el control de acceso es crucial incluso con estos identificadores.
Si es posible, evite exponer identificadores en URL y cuerpos POST. En su lugar, determine el usuario autenticado a partir de la información de la sesión. Al usar flujos de varios pasos, pase los identificadores en la sesión para evitar manipulaciones.
Al buscar objetos según claves primarias, utilice conjuntos de datos a los que los usuarios tengan acceso. Por ejemplo, en Ruby on Rails:
// vulnerable, searches all projects
@project = Project.find(params[:id])
// secure, searches projects related to the current user
@project = @current_user.projects.find(params[:id])
Verifique el permiso del usuario cada vez que intente acceder. Implemente esto estructuralmente utilizando el enfoque recomendado para su framework web.
Como medida adicional de defensa a fondo, reemplace los identificadores numéricos enumerables por identificadores aleatorios más complejos. Puede lograrlo añadiendo una columna con cadenas aleatorias en la tabla de la base de datos y usando dichas cadenas en las URL en lugar de claves primarias numéricas. Otra opción es usar UUID u otros valores aleatorios largos como claves primarias. Evite cifrar identificadores, ya que hacerlo de forma segura puede ser complicado.
C1: Implementar el control de acceso
El control de acceso (o autorización) consiste en permitir o denegar solicitudes específicas de un usuario, programa o proceso. Con cada decisión de control de acceso, un sujeto solicita acceso a un objeto determinado.
- El control de acceso es el proceso que considera la política definida y determina si un sujeto tiene permiso para acceder a un objeto determinado.
- El control de acceso también implica el acto de conceder y revocar esos privilegios.
- El control de acceso suele aplicarse en múltiples niveles; por ejemplo, en una aplicación con un backend de base de datos, se aplica tanto a nivel de lógica de negocio como a nivel de fila de la base de datos. Además, las aplicaciones pueden ofrecer múltiples maneras de realizar operaciones (por ejemplo, a través de API o del sitio web). Todos estos diferentes niveles y rutas de acceso deben estar alineados, es decir, utilizar las mismas comprobaciones de control de acceso, para protegerse contra vulnerabilidades de seguridad.
- La autorización (verificar el acceso a funciones o recursos específicos) no es equivalente a la autenticación (verificar la identidad).
Amenazas
- Un atacante podría aprovechar una política de control de acceso mal configurada para acceder a datos que la organización no tenía intención de hacer accesibles.
- Un atacante podría descubrir múltiples componentes de control de acceso dentro de una aplicación y explotar el más débil.
- Un administrador podría olvidarse de deshabilitar una cuenta antigua y un atacante podría descubrirla y usarla para acceder a los datos.
- Un atacante podría acceder a datos cuya política permitiera el acceso hasta el último paso (falta la denegación predeterminada).
Implementación
A continuación se muestra un conjunto mínimo de requisitos de diseño de control de acceso que deben tenerse en cuenta en las etapas iniciales del desarrollo de la aplicación.
1) Diseñe el control de acceso minuciosamente desde el principio
Una vez elegido un patrón de diseño de control de acceso específico, suele ser difícil y lento rediseñar el control de acceso en la aplicación con un nuevo patrón. El control de acceso es una de las principales áreas del diseño de seguridad de aplicaciones que debe diseñarse minuciosamente desde el principio, especialmente al abordar requisitos como la multi-tenencia y el control de acceso horizontal (dependiente de los datos).
Se deben considerar dos tipos principales de diseño de control de acceso.
- El control de acceso basado en roles (RBAC) es un modelo para controlar el acceso a los recursos donde las acciones permitidas sobre los recursos se identifican con roles en lugar de con identidades de sujetos individuales.
- El Control de Acceso Basado en Atributos (ABAC) otorga o deniega el acceso de usuarios según atributos arbitrarios del usuario y del objeto, así como condiciones del entorno que pueden ser reconocidas globalmente y más relevantes para las políticas en cuestión. El diseño del control de acceso puede comenzar siendo simple, pero a menudo puede volverse complejo y requerir un control de seguridad con muchas funciones. Al evaluar la capacidad de control de acceso de los marcos de software, asegúrese de que su funcionalidad permita la personalización según sus necesidades específicas.
2) Obligar a que cada solicitud de acceso pase por una comprobación de control de acceso
Asegúrese de que todas las solicitudes de acceso pasen obligatoriamente por una capa de verificación de control de acceso. Tecnologías como los filtros Java u otros mecanismos de procesamiento automático de solicitudes son componentes de programación ideales que garantizan que todas las solicitudes pasen por una verificación de control de acceso. Esto se conoce como Punto de Aplicación de Políticas en la RFC 2904 .
3) Consolidar la verificación del control de acceso
Utilice un único procedimiento o rutina de control de acceso. Esto evita tener múltiples implementaciones de control de acceso, donde la mayoría son correctas, pero algunas presentan fallas. Al usar un enfoque centralizado, puede concentrar los recursos de seguridad en revisar y corregir una biblioteca o función central que realiza la verificación de control de acceso, y luego reutilizarla en todo su código fuente y organización.
4) Denegar por defecto
Asegúrese de que, por defecto, se denieguen todas las solicitudes, a menos que se permitan específicamente. Esto también incluye el acceso a la API (REST o webhooks) sin controles de acceso. Esta regla se manifiesta de muchas maneras en el código de la aplicación. Algunos ejemplos son:
- El código de la aplicación puede generar un error o una excepción al procesar las solicitudes de control de acceso. En estos casos, siempre se debe denegar el control de acceso.
- Cuando un administrador crea un nuevo usuario o un usuario se registra para una nueva cuenta, esa cuenta debe tener acceso mínimo o nulo de manera predeterminada hasta que se configure dicho acceso.
- Cuando se agrega una nueva función a una aplicación, se debe negar a todos los usuarios su uso hasta que esté configurada correctamente.
5) Principio del Mínimo Privilegio / Justo a Tiempo (JIT), Acceso Suficiente (JEA)
Un ejemplo de implementación de ese principio es crear roles y cuentas privilegiados dedicados para cada función de la organización que requiera actividades altamente privilegiadas y evitar usar un rol o cuenta de “administrador” que tenga todos los privilegios a diario.
Para mejorar aún más la seguridad, puede implementar acceso justo a tiempo (JIT) o acceso justo a tiempo (JEA): asegúrese de que todos los usuarios, programas o procesos solo tengan el acceso necesario para cumplir su misión. Este acceso debe proporcionarse justo a tiempo, cuando el sujeto realiza la solicitud, y debe concederse por un período breve. Tenga cuidado con los sistemas que no ofrecen funciones de configuración de control de acceso granular.
6) No codifique roles de forma rígida
Muchos frameworks de aplicaciones utilizan de forma predeterminada un control de acceso basado en roles. Es frecuente encontrar código de aplicación repleto de comprobaciones de este tipo.
if (user.hasRole(«ADMIN»)) || (user.hasRole(«MANAGER»)) { deleteAccount();}
Tenga cuidado con este tipo de programación basada en roles en el código. Presenta las siguientes limitaciones o peligros:
- La programación basada en roles de esta naturaleza es frágil. Es fácil crear comprobaciones de roles incorrectas o inexistentes en el código.
- Los roles predefinidos no permiten la multi-tenencia. Se requerirán medidas extremas, como bifurcar el código o añadir comprobaciones para cada cliente, para que los sistemas basados en roles tengan reglas diferentes para cada cliente.
- Las bases de código grandes con muchas verificaciones de control de acceso pueden dificultar la auditoría o verificación de la política general de control de acceso de la aplicación.
- Los roles codificados de forma rígida también pueden considerarse una puerta trasera cuando se descubren durante auditorías.
7) Ejemplo de punto de cumplimiento de políticas de ABAC
Tenga en cuenta los siguientes puntos de aplicación del control de acceso utilizando la siguiente metodología de programación:
if (user.hasPermission(«DELETE_ACCOUNT»)) { deleteAccount();}
Las comprobaciones de control de acceso basadas en atributos o características de esta naturaleza son el punto de partida para construir sistemas de control de acceso bien diseñados y con abundantes funciones. Este tipo de programación también permite una mayor capacidad de personalización del control de acceso con el tiempo.
Autorización en aplicaciones: el verdadero campo de batalla del acceso
Cuando hablamos de seguridad en software, muchos creen que basta con autenticar correctamente a los usuarios. Que si alguien entra con su nombre de usuario y contraseña, ya está todo resuelto. Craso error. La verdadera complejidad arranca justo después de validar la identidad: la autorización. Porque saber quién sos no significa automáticamente saber qué podés hacer. Y ahí es donde todo se vuelve pantanoso. No importa cuán fuerte sea tu login, si la lógica que decide qué recursos puede tocar ese usuario es frágil, tu sistema es un colador. Y eso es lo que muchos subestiman. A lo largo de mi carrera, he visto desde microservicios mal protegidos hasta APIs completas sin control de acceso real, creyendo que con un simple token de sesión estaba todo cubierto.
La diferencia entre autenticación y autorización no es académica, es práctica y letal
En entornos reales, podés tener a un usuario legítimo accediendo a recursos que jamás debería haber podido ver, solo porque alguien asumió que «si está logueado, debe poder ver esto». Esto es ignorar las bases del control de acceso. ¿El resultado? Escalamiento horizontal de privilegios, filtración de PII, registros de transacciones accesibles desde IDs predecibles en la URL, y lo peor: sin dejar huella si nadie se tomó el trabajo de registrar bien los accesos. Las vulnerabilidades de control de acceso no son bugs menores. Están en la cima del OWASP Top 10 por algo. No porque suenen cool, sino porque se explotan todo el tiempo. Y eso ocurre por negligencia o desconocimiento.
El principio de privilegios mínimos no es una sugerencia, es una obligación
Este principio debería estar tatuado en la mente de todo dev. Cada línea de código que permite acceso a un recurso debería responder la pregunta: «¿Este usuario realmente necesita hacer esto?». Pero no. A menudo se codifica al revés: «¿Hay alguna razón para denegarlo?». Eso es una bomba de tiempo. En diseño de software, asumir que el acceso es el estado por defecto es tan peligroso como dejar un servidor expuesto con root:root. La lógica de autorización debe comenzar desde la negación absoluta, y abrirse solo con justificaciones explícitas, revisadas, aprobadas y testeadas. No se trata solo de proteger recursos internos. Incluso un formulario de contacto puede ser una vía de ataque si no se controla quién puede interactuar con él, en qué condiciones y con qué restricciones.
Negar por defecto: la única política que tiene sentido cuando el riesgo es la integridad del sistema
La lógica por omisión debe ser una muralla, no una puerta abierta. Asumir que todo está permitido hasta que algo lo niegue es jugar a la ruleta rusa con el código. Y este error se repite tanto en pequeños proyectos como en plataformas críticas. Cada nueva feature debe construirse bajo la premisa de que nadie tiene acceso a nada hasta que lo demuestre. Lo que muchos devs no entienden es que los atacantes no necesitan entrar por la puerta principal. Solo tienen que encontrar una función mal validada, una ruta sin protección, un recurso accesible por ID predecible. Y si tu código no está validando cada acceso con lógica clara, robusta y desacoplada del front-end, el resto de tus controles valen cero.
No confíes en frameworks ni librerías mágicas: entendé cómo implementan la autorización
He auditado demasiados proyectos donde el control de acceso se delega ciegamente a una librería. “Spring Security lo maneja” o “Laravel ya valida eso”. No, viejo. No es así. Ninguna librería es infalible si la configurás mal o si asumís que su lógica cubre tus reglas de negocio. Muchos frameworks tienen valores por defecto inseguros o asumen una estructura simple que no se aplica a tu dominio. El rol de un dev no es importar cosas y rezar. Es entender, cuestionar, testear y adaptar. Y cuando eso no alcanza, escribir lógica propia que cumpla con el modelo de seguridad que tu aplicación necesita. Porque cuando explotás una vulnerabilidad de autorización, no atacás al framework. Atacás al sistema, al negocio y a la confianza de los usuarios.
Validar permisos en cada solicitud: cada endpoint es una puerta que puede ser forzada
Cada request que llega a tu sistema debe pasar por un filtro de autorización. No importa si viene de un botón del front o si fue fabricada por un curl malicioso. La lógica de control no puede vivir en el cliente, ni depender de que la UI haga lo correcto. En mi experiencia, los ataques más efectivos siempre aprovechan una sola validación que se omitió. Una función en un controlador, una ruta en una API, un archivo mal expuesto. Validar solo el 99% de las rutas es igual a dejar una ventana abierta en una bóveda. Por eso el control debe ser centralizado, global, desacoplado de las vistas y resistente a bypass. No podés permitir que la lógica de acceso dependa del contexto visual del usuario.
Los identificadores predecibles son una invitación al desastre si no hay control detrás
¿Quién no ha visto URLs con parámetros como user_id=123? A simple vista, parecen inofensivas. Pero si detrás de eso no hay una verificación que asegure que ese ID pertenece al usuario logueado, tenés una exposición directa de datos. Es uno de los fallos más antiguos y aún sigue presente. Cambiar un ID en una URL y acceder a la cuenta de otro usuario es el equivalente moderno de forzar una cerradura con un alfiler. Usar UUIDs o hashes no es suficiente si no hay una política clara de control de acceso. Lo que se necesita es verificar que el usuario que hace la petición tiene realmente el derecho de acceder a ese recurso, no importa cómo llegó a ese identificador.
ABAC y ReBAC: el futuro del control de acceso no está basado en roles, está basado en contexto
Durante años el RBAC fue la norma. Roles como “admin”, “user”, “editor” se convirtieron en el estándar. Pero la realidad de las aplicaciones modernas es mucho más compleja. Los permisos no dependen solo del rol, sino del contexto, la relación entre usuarios y objetos, la hora del día, la ubicación, incluso el estado del dispositivo. Ahí es donde ABAC y ReBAC entran en juego. Con ABAC, podés construir políticas de acceso tan precisas como “solo si el usuario es supervisor del equipo X y está conectado desde la red interna en horario laboral”. Con ReBAC, podés restringir acciones según relaciones explícitas: “solo el autor de una publicación puede editarla, y sus amigos pueden verla”. Este nivel de granularidad no se puede lograr con RBAC sin caer en la pesadilla de la explosión de roles.
El registro de accesos es tu caja negra, tu defensa forense, tu alerta temprana
Si tu sistema no registra cada intento de acceso y su resultado, estás ciego. Y si no lo registrás de forma centralizada, sincronizada y auditable, estás aún peor. No se trata solo de registrar “login failed”. Cada recurso sensible debe tener su propio log de acceso, exitoso o fallido. Los logs deben ser inmutables, protegidos y analizados. De lo contrario, cuando alguien accede a datos que no debía, nunca lo sabrás. Y si lo descubrís, será tarde. Un buen sistema de control de acceso no está completo sin monitoreo y alertas. Porque incluso el mejor código puede fallar, pero si lo monitoreás, podés reaccionar. Si no, sos solo otra víctima más en los titulares de la próxima fuga de datos.
Las pruebas no son opcionales: cada control de acceso debe ser testeado como si fuera un endpoint crítico
La autorización no es algo que se prueba al final. Se prueba desde el inicio y en cada entrega. Cada política ABAC debe tener pruebas unitarias que verifiquen su aplicación en escenarios válidos e inválidos. Y no se trata solo de probar que se permita el acceso correcto, sino de asegurarse de que se deniegue el acceso incorrecto. Los tests deben ser automatizados, cubrir casos extremos, simular ataques. Porque la única forma de garantizar que una puerta resiste es intentar abrirla por todos los medios posibles. Y si no tenés tests, tu puerta nunca fue puesta a prueba. En ese caso, solo es cuestión de tiempo hasta que alguien la cruce.
La autorización es más que un control, es una filosofía de diseño
La seguridad no se implementa como un parche, se diseña desde el principio. Y dentro de todo el ecosistema de seguridad en aplicaciones, la autorización es probablemente la parte más subestimada y más crítica. Se trata de entender que cada acción posible debe estar justificada, controlada y validada. Se trata de construir un sistema donde cada acceso sea un privilegio ganado, no un derecho asumido. Y sobre todo, se trata de escribir software como un hacker: con paranoia, con precisión y con la certeza de que alguien, en algún lugar, ya está intentando romperlo.
El arte del registro como pilar de la seguridad en aplicaciones
Cuando escuchás hablar de seguridad en software, probablemente pienses en autenticación fuerte, cifrado de datos o control de acceso. Todo eso es vital, sí. Pero hay una capa silenciosa, menos glamorosa pero absolutamente clave: el registro de eventos. Y no hablo de los logs genéricos del sistema operativo o los registros del servidor web que nadie mira. Hablo del registro de eventos de seguridad en la aplicación, que son tu única fuente real de verdad cuando todo se va al carajo.
He visto despliegues complejos, con firewalls de última generación y controles RBAC bien implementados, pero sin un solo log útil cuando había que investigar un incidente. ¿Resultado? Un agujero negro en la línea de tiempo del ataque. Y no hay parche ni firewall que tape eso. Porque cuando no logueás, no sabés. Y si no sabés, no reaccionás. Punto.
Logging para seguridad: no es opcional, es obligatorio
Muchos sistemas registran lo mínimo. Algunos desarrolladores ni siquiera habilitan los logs de su propia app, confiando ciegamente en que los logs del servidor o del reverse proxy van a contar toda la historia. Spoiler: no lo hacen. El verdadero contexto, el que vincula usuarios con acciones, rutas, payloads y resultados, está en tu código. Vos sos el único que lo puede registrar con el nivel de detalle que hace falta para entender qué pasó, cuándo, con quién y por qué.
Y no es solo para cazar a los malos. El logging sirve para detectar anomalías, diagnosticar errores lógicos, auditar decisiones, probar cumplimiento normativo y reconstruir flujos de negocio. Es la caja negra del sistema. Pero solo si la construís bien.
Qué registrar: eventos relevantes, ni más ni menos
La obsesión por loguear todo es tan mala como no loguear nada. He visto sistemas donde cada request generaba cientos de líneas inútiles que ocultaban lo importante. Y también he visto sistemas sin un solo log de error cuando fallaba una autenticación. El equilibrio está en entender qué eventos tienen valor de seguridad y cuál es el mínimo de información que los hace útiles. Autenticaciones fallidas, errores de validación, acciones administrativas, cambios de privilegios, accesos a datos sensibles. Todo eso tiene que estar en tus logs.
¿Un input inválido en un campo que solo acepta cinco valores predefinidos? Eso no es un error de usuario, eso es un ataque. ¿Una deserialización fallida con stacktrace? Eso puede ser un RCE en progreso. ¿Un token malformado? Eso es un intento de spoofing o tampering. Pero si no lo registrás, nunca te enterás.
Dónde registrar: centralizado, protegido y resiliente
Loguear en un archivo local y esperar lo mejor no es estrategia. Tenés que pensar como un atacante. Si un log puede ser manipulado o eliminado, no sirve. Si podés escribirle encima, no sirve. Si depende del disco donde también están tus datos productivos, te estás armando tu propia DoS. Lo correcto es loguear en un sistema externo, con mecanismos de detección de manipulación, acceso restringido, y preferentemente inmutable. Y si no lo podés hacer ahora, al menos separá los logs en su propia partición y cifralos. No lo dejes para mañana.
Y nunca, jamás, expongas logs por la web. Un log con errores internos puede revelar rutas, estructuras, datos de sesión y hasta contraseñas si sos de los que loguean todo el request body sin filtro. Eso no es observabilidad, es autodestrucción.
Cómo registrar: formato estructurado, detallado y coherente
Cada entrada de log debe responder las preguntas básicas: cuándo, dónde, quién y qué. ¿Querés correlacionar eventos? Usá un identificador de interacción que una todo lo que pasa en una misma request. ¿Querés analizar ataques? Usá un nivel de severidad, tipo de evento, resultado de la acción y motivo del fallo. ¿Querés usar un SIEM o una solución de análisis? Usá formatos estándar como CEF o JSON sobre syslog. No inventes tus propios formatos raros. Que tu log lo pueda leer una máquina y no solo un humano en pánico a las 3 AM.
Registrar sin coherencia es como escribir sin gramática: nadie lo va a entender. Usá campos claros, homogéneos y completos. Y pensá desde el principio en lo que podés necesitar en una investigación. No después.
Qué evitar: no registres lo que no deberías ni lo que no podés proteger
Los logs son una fuente de filtración tan peligrosa como cualquier endpoint vulnerable. Por eso, hay cosas que jamás deberías loguear: contraseñas, tokens, claves, datos bancarios, PII sensible, cadenas de conexión, secretos en general. Y si los necesitás para debugging, enmascaralos o hashéalos. Pero lo ideal es que ni aparezcan. Porque todo log puede ser leído, interceptado o exfiltrado. Y si eso pasa, mejor que no contenga nada que te arruine.
También cuidá el acceso a los logs. No basta con tenerlos. Tenés que auditar quién los lee, cómo los consulta, y si los borra o modifica. Y que todo eso también quede registrado.
Protegé tus logs: en tránsito y en reposo
Nunca mandes logs por redes inseguras sin cifrado. Usá TLS, autenticación mutua, lo que sea. Pero no los dejes viajar como texto plano. Y una vez almacenados, hacelos inmutables. Usá permisos estrictos, registrá el acceso a ellos, y aplicá integridad si podés (hash, firma digital, etc.). Porque los logs son evidencia. Y la evidencia contaminada no vale nada.
Automatización, monitoreo y alertas
No sirve tener logs si nadie los ve. Y no, no me refiero a mirar los archivos a mano. Integralos con tus sistemas de detección, SIEM, dashboards. Creá reglas de alertas para eventos críticos. Si tenés un WAF, correlacionalo. Si hay errores de validación repetidos en una ruta sensible, que se dispare una alarma. Si un admin accede a medianoche desde otro país, que alguien lo sepa. El valor del registro no está solo en el archivo, está en lo que hacés con él.
Logging robusto: no debe fallar, y si falla, que no caiga el sistema
Una aplicación no puede romperse si no puede escribir en un log. Eso tiene que ser tolerable. Pero al mismo tiempo, si un log falla, eso también debe registrarse en algún lado. Y si el sistema detecta que dejó de registrar por completo, debe alertar. Porque si no hay logs durante un ataque, no hay forma de saber qué pasó. Eso es inaceptable. Asegurate de tener fallback, colas, buffers, y sobre todo: pruebas que simulen fallos de logging.
Logs como vector de ataque: inyección, abuso, denegación
Nunca olvides que los logs pueden ser usados en tu contra. Inyección de logs es real, y con un simple CRLF alguien puede manipular el archivo y hacerte creer cosas que no pasaron. También pueden usar los logs para llenar el disco, saturar el sistema o atacar el parser. Validá la entrada, limpiá los datos, y cuidá que los logs no sean una puerta trasera.
El registro es un arma: usala como tal
En resumen, el logging bien hecho es tanto una defensa activa como una herramienta de análisis forense. Es tu aliado más confiable cuando todo se vuelve incierto. Pero solo si lo tratás con el respeto que merece. No es un print, no es un consola.log, no es un accesorio de debugging. Es una herramienta crítica de seguridad. Y si sabés cómo usarla, puede ser la diferencia entre contener un incidente o quedar completamente ciego ante él.
ABAC en Spring Security: control de acceso con inteligencia contextual
Una de las cosas que más frustración genera cuando trabajás con aplicaciones empresariales grandes es darte cuenta de que el sistema de roles clásico no te alcanza. RBAC está bien cuando tenés 2 o 3 perfiles, tipo “admin” y “user”. Pero cuando tenés que decir cosas como «el usuario puede modificar sus propios datos«, o «el tester puede reportar bugs sólo en su proyecto«, te empezás a encontrar con condiciones que RBAC simplemente no puede modelar sin hacer un spaghetti de roles que no escala ni se entiende. Ahí es donde entra ABAC: Attribute-Based Access Control.
ABAC te permite dejar de pensar en roles como la única fuente de verdad y empezar a usar información real del contexto: quién sos, qué recurso estás tocando, en qué momento, desde dónde, bajo qué condiciones. Es el nivel de granularidad que necesitás cuando estás trabajando en software serio.
Y sí, Spring Security soporta esto. Pero no viene listo de fábrica. Tenés que armar tu arquitectura ABAC, y eso es lo que vamos a destripar acá.
¿Qué es ABAC realmente?
ABAC parte de una idea simple pero poderosa: para tomar una decisión de acceso, necesitás conocer cuatro elementos clave: sujeto, recurso, acción y entorno. Con esos cuatro, podés definir reglas lógicas tipo:
“Permitir si subject.project.id == resource.project.id” o
“Permitir si action == ‘CREATE_ISSUE’ && subject.role == ‘PM’”.
Lo interesante es que podés representar todo como una expresión booleana. Y si usás Spring, podés usar SpEL (Spring Expression Language) para eso. SpEL tiene la flexibilidad que necesitás y se integra muy bien con el motor de autorización de Spring Security.
Diagrama real del flujo de decisiones
Lo primero que tenés que entender es cómo fluye una autorización en Spring. Cuando hacés algo como @PreAuthorize(«hasPermission(…)»), Spring no evalúa eso directamente. Lo que hace es pasar esa expresión al AccessDecisionManager, que a su vez delega en el PermissionEvaluator. Es en ese punto donde vos metés tu lógica ABAC.
Pero si necesitás hacer una verificación dentro de un servicio y no podés usar @PreAuthorize porque no tenés aún todos los datos (por ejemplo, actualizás una entidad pero necesitás validar el estado anterior), entonces creás un componente separado que puedas invocar directamente. Eso también está cubierto en esta implementación.
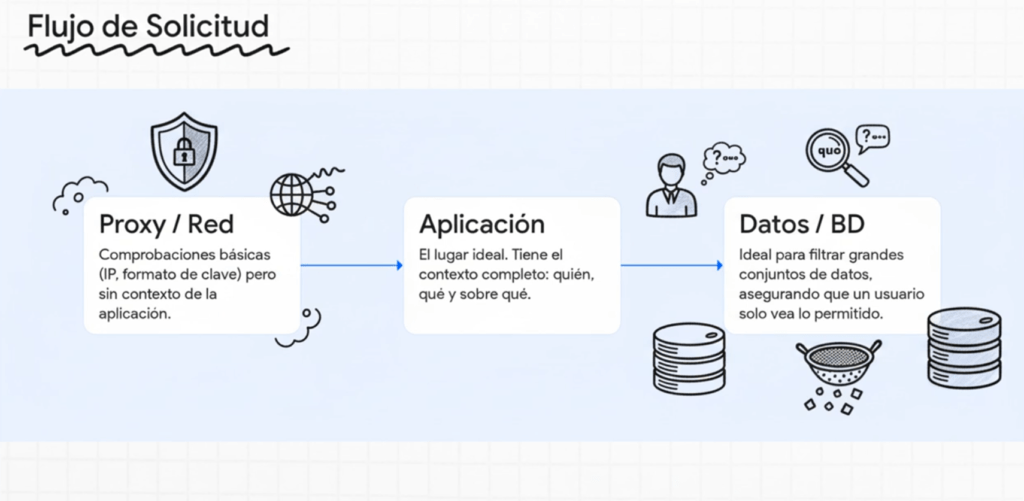
La siguiente figura describe el flujo de secuencia para cada llamada de método protegida por control de acceso:
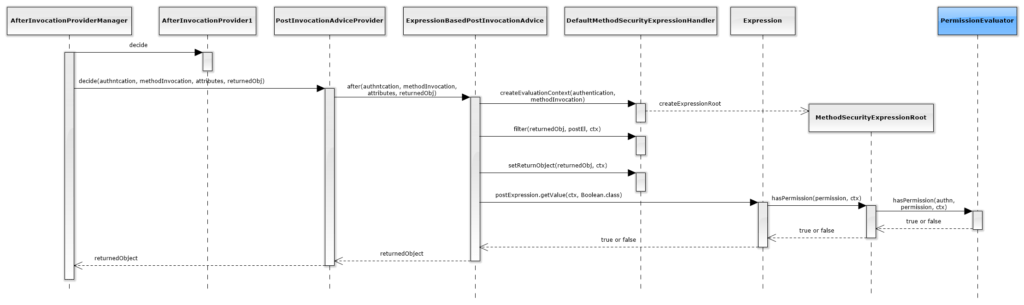
Dentro de AccessDecisionManager se lleva a cabo la siguiente secuencia:
Y dentro del AfterInvocationManager se lleva a cabo la siguiente secuencia:
Como se muestra en estos diagramas, las decisiones de acceso se delegan (eventualmente) a un componente llamado PermissionEvaluator (coloreado en azul arriba), y aquí es donde estará la lógica ABAC.
Cómo se implementa un evaluador de políticas en Spring
La arquitectura propuesta se divide en varias piezas clave:
- PermissionEvaluator personalizado: intercepta todas las expresiones hasPermission(…) y delega en un componente PolicyEnforcement.
- PolicyEnforcement: carga todas las reglas (desde memoria, archivo o DB), filtra las que aplican en ese contexto (basado en el target), y evalúa las condiciones. Si alguna condición es verdadera, se concede el acceso.
- PolicyDefinition: interfaz que expone las reglas de política. Puede tener múltiples implementaciones: JSON, base de datos, LDAP, lo que sea. Todo desacoplado.
- PolicyRule: objeto que representa una regla de política. Tiene dos expresiones: target (cuando aplica) y condition (cuándo permite).
- AccessContext: clase que contiene el contexto completo para la evaluación: sujeto, recurso, acción, entorno.
Ejemplo real: aplicación de seguimiento de problemas
La app de ejemplo modela un sistema de gestión de bugs y tareas por proyecto. Tenés usuarios con roles: ADMIN, PM, TESTER, DEV. Cada uno tiene acceso restringido a las entidades de su proyecto. Los issues tienen tipo, estado y se pueden asignar.
Algunas reglas de acceso reales que aplicás con ABAC serían:
- El PM puede crear issues en su proyecto:
target: subject.role == ‘PM’ && action == ‘ISSUES_CREATE’
condition: subject.project.id == resource.project.id - El tester puede crear bugs, pero no tareas:
target: subject.role == ‘TESTER’ && action == ‘ISSUES_CREATE’
condition: subject.project.id == resource.project.id && resource.type == ‘BUG’ - Cualquier usuario puede cerrar un issue asignado a él:
target: action == ‘ISSUES_STATUS_CLOSE’
condition: subject.name == resource.assignedTo
Y todas estas reglas están en un JSON que podés actualizar sin tener que recompilar nada. Eso es clave en entornos corporativos donde la lógica de acceso puede cambiar sin previo aviso.
Mejoras y desafíos
Esto funciona muy bien, pero como todo sistema que se vuelve dinámico, hay desafíos:
- Performance: Evaluar reglas dinámicas con SpEL puede ser costoso. Podés mitigar esto cacheando las reglas o incluso compilando las expresiones SpEL.
- Reglas complejas: Si necesitás reglas más potentes, podés extender el modelo para permitir conjuntos de reglas (PolicySet) con condiciones anidadas al estilo XACML.
- Validación de expresiones: En producción, no podés permitir cualquier SpEL. Tenés que validar que las expresiones no accedan a cosas fuera del AccessContext. Este paso es obligatorio para evitar inyecciones.
- Editor de reglas: En algún punto vas a necesitar una interfaz para que un usuario no técnico cree estas reglas. Esa parte no está implementada, pero es fácilmente integrable.
ABAC te da poder real sobre la autorización
RBAC está muerto para sistemas modernos. No podés seguir codificando lógica de acceso con if(user.getRole() == …). Tampoco podés pretender que un solo rol defina lo que alguien puede hacer. Lo que importa hoy es el contexto. Lo que importa es el estado del recurso, la relación con el usuario, la hora, el canal, la política vigente.
Con ABAC podés decir: “sólo permitime esta acción si cumple con esta lógica”, y que esa lógica sea tan rica como necesites. Y con Spring Security y SpEL, lo podés hacer sin reinventar la rueda.
Lo más importante es que esto no es teórico. Es código que podés usar hoy, que escala, que podés probar y auditar. Así se hace seguridad moderna. Así se hace control de acceso cuando sabés que la lógica es tan crítica como el backend que la ejecuta.
A01:2025 – Control de Acceso Vulnerado (Broken Access Control)
Cuando un usuario accede a datos o funciones que no debería poder ver o usar.
En 2025 sigue siendo el puesto #1 porque es la causa más frecuente y crítica de compromisos reales.
Incluye: IDOR, BOLA, Insecure Direct Object Reference, fuerza bruta de recursos, privilegios mal validados, bypass de controles de frontend, APIs malas, diseño inseguro de permisos, etc.
🧩 Ejemplos típicos (2025)
- Cambiar el ID de /api/v2/users/321 por otro y ver datos ajenos (IDOR clásico).
- Llamar endpoints ocultos de API (v1, v2, legacy) que no tienen autorización.
- Editar precios, saldos, claves o recursos enviando un PUT/POST modificado.
- Escalada vertical: un usuario básico accede a /admin/*.
- Escalada horizontal: un usuario accede a cosas de otros usuarios.
- Bypass de controles por frontend mal implementado.
- Roles mal definidos: oculto en UI pero permitido en backend.
- Token mal validado que permite “convertirse” en otro usuario.
- Servidores sin política “deny-by-default”.
🔍 Mini-guía de explotación (2025)
- Enumerar rutas, IDs, tokens, parámetros “sospechosos”.
- Probar secuencias numéricas: /api/v2/client/100, 101, 102…
- Cambiar métodos HTTP: GET → POST, PUT → PATCH, DELETE.
- Probar versiones antiguas de API: /v1/, /v2/, /mobile/.
- Probar combinación de tokens (session + JWT + cookies).
- Eliminar controles del lado cliente (JS, botones ocultos, HTML deshabilitado).
- Saltar validaciones débiles (CORS permisivo, parámetros ignorados).
- Validar filtraciones: responder diferente según usuario → diferencia de comportamiento.
🎯 Consecuencias
- Exposición de información sensible (PII, tarjetas, IBAN, transacciones).
- Robo de identidad y toma de cuentas (ATO).
- Modificación directa de datos.
- Escalada de privilegios total.
- Compromiso completo de APIs y microservicios.
- Fraude financiero.
- Acceso a funciones administrativas no destinadas a usuarios normales.
- Filtración de archivos internos u objetos de almacenamiento.
- Acceso transversal entre tenants (multi-tenant inseguro).
🛡 Defensas modernas (2025)
- Deny-by-default en TODA API y backend.
- Autorización por objeto (object-level authorization) en cada endpoint.
- Autorización por recurso y por acción (RBAC + ABAC).
- Validar siempre en backend, nunca confiar en frontend.
- ID no predecibles (UUID, Snowflake IDs, hashes).
- Separar autenticación de autorización (AuthN vs AuthZ).
- API Gateway con políticas por método y por path.
- Revisiones de diseño inseguro (Threat Modeling).
- Pruebas automatizadas de autorización por cada endpoint.
- Multi-tenant seguro: nunca mezclar datos entre usuarios/organizaciones.
- Límites estrictos de CORS (no wildcard).
- Logs de acceso a recursos sensibles.
📚 Subtipos/patrones modernos (2025)
| Subtipo 2025 | Definición | Ejemplo bancario | Pentesting (qué probar) | Ataque / PoC | Consecuencia | Defensa | Tips examen |
| IDOR / BOLA / OLaP | Cambiar ID y acceder a objetos ajenos | Ver cuenta X cambiando /1234 por /1235 | Cambiar IDs numéricos, UUID, tokens | GET /account/0002 con token de 0001 | Exposición de PII, fraude | Chequeo por objeto | “Si el usuario cambia un ID y accede, es IDOR/BOLA” |
| BAC en funciones (FLoA) | Acceso a funciones no permitidas | Usuario básico accede a /admin/payments | Probar rutas ocultas | GET /admin/… | Escalada vertical | RBAC/ABAC | Buscar palabras “admin”, “manage”, “config” |
| Mass Assignment | Backend asigna más campos de los esperados | Cambiar “role”: “user” → “admin” | Enviar JSON con campos ocultos | {“role”:”admin”} | Escalada total | DTOs estrictos | Si un campo oculto cambia rol → Mass Assignment |
| Forced Browsing | Acceder a rutas ocultas sin permiso | /exports/2024/data.csv | Enumerar /backup/, /old/ | /secret/report.pdf | Filtración | Whitelist de rutas | Si la ruta existe sin rol → forced browsing |
| Métodos HTTP inseguros | Permitir DELETE/PUT sin control | DELETE /users/13 | Cambiar método | DELETE /users/44 | Borrado/modificación | Autorizar por método | Atención a “DELETE permitido” |
| Multi-tenant inseguro | Usuarios acceden a datos de otro tenant | Banco A ve datos de Banco B | Cambiar tenant_id | /tenant/2/cards | Exposición masiva | Aislamiento por tenant | “Si mezcla datos entre clientes → 0/10” |
| CORS inseguro | CORS abierto permite robar datos | Origin mal configurado | Probar con origin arbitrario | CORS con * | Robo de tokens, CSRF | Políticas estrictas | “Si CORS acepta todo → falso seguro” |
🧪 Check-list rápida para pentesting A01:2025
- Probar IDOR en TODOS los endpoints que tengan IDs.
- Verificar vertical: /admin/*, /superuser/*.
- Verificar horizontal: recursos de otros usuarios.
- Cambiar método HTTP.
- Enumerar rutas ocultas, backups, endpoints viejos.
- Probar versiones v1/v2/mobile/internal/legacy.
- Probar parámetros ocultos: role, isAdmin, balance, price.
- Probar tokens mezclados (session + JWT).
- Revisar CORS y bypasses.
- Revisar multi-tenant.
- Revisar mass assignment.
- Revisar APIs GraphQL (schema abierto).
🧾 Resumen ejecutivo (1 párrafo para slides o curso)
A01:2025 Broken Access Control sigue siendo el riesgo más crítico del OWASP Top 10 porque ocurre cuando una aplicación no valida correctamente lo que un usuario puede ver o hacer. Esto permite acceder a datos de otros usuarios, editar información sensible, escalar privilegios y acceder a funciones administrativas. Incluye IDOR/BOLA, rutas ocultas accesibles, métodos HTTP inseguros, mass assignment, fallas multi-tenant y bypass de controles de frontend. La mitigación exige autorización estricta por objeto, políticas deny-by-default, RBAC/ABAC, validación siempre en backend, CORS seguro, aislamiento por tenant y pruebas automatizadas de permisos para cada endpoint. Es el problema más común y el más explotado en APIs modernas.
Cuadro práctico AMPLIADO
| Subtipo / patrón | Definición (en una línea) | Ejemplo bancario | Pentesting (qué probar) | Ataque / PoC | Consecuencia | Defensa | Tips de examen |
| IDOR / BOLA (API) | Acceso a objetos cambiando identificadores sin verificar propiedad. | Cambiar GET /api/accounts/1234/tx a …/1235/tx y ver transacciones de otro cliente. | Comparar peticiones de Usuario A vs B (Burp Repeater). Cambiar account_id, customerId, IBAN, número de tarjeta, loanId. | Editar el path/body: GET /api/accounts/0002/tx con token del cliente 0001. | Exposición de PII, fraude, movimientos ajenos. | Chequeo de autorización por objeto (owner check en servidor), IDs no predecibles (UUID), deny-by-default. | Si el enunciado dice “cambiar el ID en URL/body” → marca IDOR/BOLA. |
| Falta de control a nivel de función | Acceso a funciones que el rol no debería tener. | Usuario estándar puede entrar a /admin/users o POST /api/admin/limit-increase. | Fuerza de navegación a rutas admin, probar menús ocultos, revisar OpenAPI/JS para endpoints. | GET /admin con token de usuario normal devuelve 200. | Elevación vertical, cambios de límites, borrado de usuarios. | RBAC/ABAC consistente en servidor, gatekeepers por endpoint, pruebas automáticas de autorización. | “Usuario normal accede a admin” = vertical escalation. |
| Controles solo en el cliente | Autorización delegada al front (flags, ocultar botones). | JS oculta “Aprobar transferencias”, pero el endpoint existe. | Repetir la request capturada aunque el UI no lo permita. | Reenviar POST /approveTransfer desde Repeater. | Acción crítica sin permisos. | Validar siempre en servidor, no confiar en el cliente. | Si mencionan “botón oculto” o “campo deshabilitado” → no es control válido. |
| Mass assignment | El servidor acepta y aplica campos sensibles enviados por el cliente. | En PUT /users/me se puede mandar role=admin o limit=1000000. | Fuzzear claves en JSON: isAdmin, role, status, tenantId, creditLimit. | Enviar { «role»: «admin» } y observar cambio. | Escalada de privilegios, fraude. | Whitelist de campos, DTOs estrictos, ignorar campos sensibles. | Si el caso dice “el servidor acepta campos extra” → mass assignment. |
| Fuerza de navegación (Direct Request) | Acceso directo a URL/acción sin verificación. | Acceder a /statements.pdf?uid=… adivinando la ruta. | Enumerar rutas “ocultas” (robots.txt, JS, mapas), probar respuesta sin sesión y con sesión de otro usuario. | Abrir URL directa a PDF de extracto ajeno. | Filtración de extractos/boletas. | Autorización por recurso en cada request; no basta “estar logueado”. | “URL conocida pero oculta” ≠ seguro; debe autorizarse. |
| Confusión AuthN vs AuthZ | Solo se verifica autenticación, no autorización. | “Si estás logueado puedes ver cualquier customerId”. | Cambiar objeto manteniendo el mismo token válido. | Repetir operación sobre recursos de terceros. | Acceso horizontal a datos. | Separar claramente AuthN (quién eres) de AuthZ (qué puedes); políticas centrales. | Palabras clave: “solo verifica que haya sesión”. |
| Multi-tenant sin scoping | Falta de filtro por tenant/empresa. | Usuario de Banco-X ve datos de Banco-Y en plataforma compartida. | Añadir/alterar tenantId en headers/body; quitarlo; probar inyección en filtros. | Enviar X-Tenant: other y obtener datos. | Exposición masiva entre clientes. | Filtros obligatorios por tenant en todas las consultas. | Si aparece “multi-tenant” y “falta de aislamiento”, es BAC. |
| Método HTTP inconsistente | Autorizas GET, pero no validas PUT/DELETE. | GET /loans/123 chequea permisos; PUT /loans/123 no. | Probar todos los métodos permitidos por CORS/Allow. | Enviar DELETE /users/45 y observar 200. | Modificación/borrado no autorizado. | Política por método y endpoint; pruebas unitarias de autorización. | Si mencionan “solo GET tiene check”, marca BAC. |
| CORS mal entendido (ojo de examen) | Creer que CORS autoriza. (CORS es del navegador, no tu control de acceso). | Permiten origenes amplios y asumen “seguridad”. | N/A (es más de configuración), pero aclara en teoría. | N/A | Robo de tokens vía XSS/CSRF facilitado. | No confundir CORS con authz; usa tokens/roles/ABAC server-side. | Si el distractor dice “CORS resuelve autorizaciones” → falso. |
1. ¿Qué significa «Broken Access Control»?
Es cuando un usuario puede acceder a recursos o realizar acciones que deberían estar restringidas. Esto ocurre porque los controles de autorización no están implementados o son débiles.
2. ¿Cuál es la diferencia entre escalada horizontal y escalada vertical de privilegios?
- Horizontal: acceder a recursos de otro usuario con el mismo rol (ej. leer la cuenta de otro cliente cambiando un ID en la URL).
- Vertical: obtener privilegios mayores (ej. un usuario normal accede a funciones de administrador).
3. ¿Qué es un IDOR (Insecure Direct Object Reference)?
Es una vulnerabilidad en la que la aplicación expone un identificador directo (ej: user?id=100) sin verificar si el usuario tiene permisos para acceder. Cambiando el ID se puede acceder a información de otros usuarios.
4. ¿Cómo detectarías Broken Access Control en un pentest?
- Revisando parámetros de requests (IDs, roles, tokens).
- Manipulando URLs (/user/1 → /user/2).
- Usando Burp Suite para modificar cookies y headers.
- Probando accesos sin autenticación o con cuentas de distinto rol.
5. ¿Qué impacto puede tener esta vulnerabilidad en una aplicación bancaria?
- Exposición de datos sensibles de clientes.
- Transferencias de dinero no autorizadas.
- Escalada a cuenta de administrador y control completo del sistema.
6. ¿Qué controles se recomiendan para prevenir Broken Access Control?
- Validar la autorización en el backend para cada request.
- Usar roles y permisos definidos (RBAC/ABAC).
- Principio de denegar por defecto.
- Revisiones de seguridad y pruebas automáticas de acceso indebido.
7. Dame un ejemplo real de Broken Access Control explotado en producción.
En 2018, un bug en Facebook “View As” permitió a atacantes robar tokens de acceso de usuarios. Resultado: ~50 millones de cuentas comprometidas.
8. ¿Cómo probarías un control de acceso en una API REST?
- Llamando a los endpoints con usuarios de distinto rol y viendo si cambia la respuesta.
- Manipulando tokens JWT (ej. cambiando role:user a role:admin).
- Quitando el token o cambiándolo por uno de otro usuario.
9. ¿Qué significa «Deny by default» en controles de acceso?
Es un principio de seguridad que indica que, por defecto, toda acción o recurso debe estar bloqueado. Solo se permiten accesos que estén explícitamente autorizados.
10. ¿Cómo explicarías Broken Access Control a alguien no técnico?
Imagina que entras a tu cuenta bancaria en línea y, cambiando un número en la URL, puedes ver la cuenta de otro cliente. Eso es un error de control de acceso: el sistema no verifica si realmente eres dueño de lo que intentas ver. Es cuando un usuario puede ver o hacer algo que no debería (por ejemplo, mirar movimientos de otra cuenta o aprobar una transferencia sin permisos). Es el riesgo #1 del Top 10 2021 por su frecuencia e impacto. Si la app no valida en el servidor que el sujeto tenga permiso sobre el objeto/acción, hay BAC.
Mas Preguntas
¿Qué ocurre si un usuario cambia el parámetro accountId=123 por accountId=124 y accede a la cuenta de otro cliente?
Es un caso de Broken Access Control, específicamente un IDOR/BOLA (Insecure Direct Object Reference / Broken Object Level Authorization).
¿Cómo se llama la vulnerabilidad cuando un usuario común logra acceder a /admin/usuarios sin tener rol de administrador?
Escalada de privilegios vertical por Broken Access Control (falta de control de función).
¿Qué pasa si el front oculta el botón de “Aprobar transferencias”, pero el endpoint del backend sigue accesible y el usuario lo llama manualmente?
Controles de acceso aplicados solo en el cliente → Broken Access Control.
¿Qué vulnerabilidad ocurre si una API acepta parámetros extra como role=admin en un JSON y los aplica directamente?
Broken Access Control por Mass Assignment (asignación masiva de atributos).
¿Qué tipo de fallo es si un usuario puede acceder a un PDF de extractos bancarios conociendo la URL directa /files/statement123.pdf sin estar autorizado?
Acceso directo a recursos (Forceful Browsing / Broken Access Control).
¿Qué ocurre si el sistema solo verifica que el usuario esté autenticado pero no valida si tiene permiso sobre el objeto solicitado?
Confusión entre autenticación y autorización → Broken Access Control.
¿Qué tipo de vulnerabilidad existe si en un entorno multi-tenant un cliente puede cambiar el tenantId en la request y ver datos de otra empresa?
Broken Access Control por falta de aislamiento de tenants (multi-tenant horizontal privilege escalation).
¿Qué pasa si el servidor valida permisos en GET, pero no en PUT o DELETE, permitiendo acciones no autorizadas?
Broken Access Control por falta de validación de métodos HTTP.
¿Por qué confiar en CORS como control de autorización es un error?
Porque CORS solo controla qué navegadores pueden hacer requests cross-origin; no implementa autorización → ejemplo de Broken Access Control.
¿Qué falla ocurre si un usuario mantiene acceso a datos después de haber sido deshabilitado?
Broken Access Control por falta de invalidación de permisos.
¿Qué ocurre si una aplicación permite a un cajero cambiar límites de crédito aunque debería ser solo rol de gerente?
Escalada vertical de privilegios por Broken Access Control.
¿Qué tipo de vulnerabilidad es si la app solo confía en parámetros ocultos del formulario (isAdmin=false) para controlar acceso?
Broken Access Control, porque los parámetros pueden manipularse en el cliente.
¿Cuál es la principal diferencia entre autenticación y autorización, y cómo se relaciona con Broken Access Control?
Autenticación = quién eres, Autorización = qué puedes hacer; Broken Access Control ocurre cuando la autorización no se valida correctamente en el servidor.
¿Qué consecuencia práctica puede tener un Broken Access Control en una aplicación bancaria?
Acceso a cuentas de otros clientes, robo de información sensible, ejecución de operaciones financieras no autorizadas.
¿Qué controles debe implementar un banco para prevenir Broken Access Control?
Verificación server-side de permisos por objeto y acción, deny-by-default, RBAC/ABAC, testing automatizado de autorización.
¿Qué técnicas usarías en Burp Suite para detectar controles de acceso débiles?
- Usar Burp Proxy para manipular peticiones y cambiar IDs de usuario, roles o tokens.
- Con Burp Repeater, repetir las mismas peticiones autenticadas con diferentes credenciales o sin ellas.
- Usar Burp Intruder para automatizar pruebas de IDOR (Insecure Direct Object Reference).
- Revisar las diferencias en las respuestas para detectar acceso indebido.
¿Cómo mitigarías este problema en una API REST?
- Implementar autorización basada en roles/atributos en el backend, no solo en el frontend.
- Validar siempre el usuario propietario de los recursos (ej. user_id en DB).
- Usar tokens JWT/OAuth2 con claims que limiten el acceso.
- Aplicar principio de mínimo privilegio y pruebas de seguridad continuas.
- IDOR/BOLA (cambiar account_id en la URL/body para ver otra cuenta) // “Al cambiar user_id en la URL se accede a datos de otro usuario”
- salto de rol (usuario normal accede a endpoints de admin) // “Usuario sin permisos accede a /admin” ⇒ Escalada vertical / falta de control a nivel de función.
- forzar navegación a URLs “ocultas”
- mass assignment (enviar role=admin en el JSON)
- controles solo en el cliente (flag isAdmin en el front) // “El front oculta botones pero el endpoint existe” ⇒ Controles en el cliente (inadecuado).
- falta de scoping multi-tenant (tenantId).
- Acceder directo a un PDF sin validación → Forceful Browsing.
- Confundir autenticación con autorización → BAC.
- “CORS abierto significa que cualquiera puede usar los endpoints” ⇒ Distractor: CORS ≠ autorización. “Solución” correcta casi siempre menciona chequeos server-side, deny-by-default, RBAC/ABAC, verificación por objeto y tests automatizados de autorización.
Ejemplo de código
Pseudocódigo “malo” vs “bueno” (para explicar en vivo)
Malo (solo AuthN):
def get_account(account_id, user):
if not user.is_authenticated:
raise Forbidden()
return db.accounts.find(account_id) # ❌ no verifica dueño/rol
Bueno (AuthZ por objeto + deny-by-default):
def get_account(account_id, user):
acct = db.accounts.find(account_id)
if not acct or acct.owner_id != user.id and not user.has_role(«analyst»):
raise Forbidden()
return acct
(La idea: siempre validar en servidor la propiedad/rol sobre cada recurso.)