En este capítulo, A03:2025 Fallas en la cadena de suministro de software, aprenderás a dominar uno de los temas más críticos y complejos de la seguridad moderna: las fallas en la cadena de suministro de software. Entenderás por qué hoy los ataques ya no se enfocan solo en las aplicaciones, sino en todo lo que las rodea: librerías, frameworks, repositorios, pipelines, imágenes de contenedores, proveedores y hasta los entornos de los desarrolladores.
A lo largo del capítulo verás:
🔹 Qué es realmente una cadena de suministro y por qué es el objetivo principal de atacantes avanzados.
🔹 Cómo una dependencia vulnerable, una imagen desactualizada o un build comprometido pueden destruir un sistema completo.
🔹 El rol del SBOM, la procedencia, las firmas, SLSA y los controles de integridad.
🔹 Cómo pensar como atacante para encontrar fallas ocultas.
🔹 Prácticas defensivas para blindar cada fase del ciclo de vida del software.
🔹 Técnicas reales como parcheo virtual, análisis de dependencias, auditoría de repositorios, verificación de imágenes y control de builds.
🔹 Y finalmente, cómo diferenciar correctamente entre misconfigurations (A02) y componentes vulnerables (A03).
Al terminar este capítulo tendrás no solo el conocimiento teórico, sino también la mentalidad ofensiva y defensiva para proteger sistemas modernos del vector de ataque más utilizado hoy: la cadena de suministro.
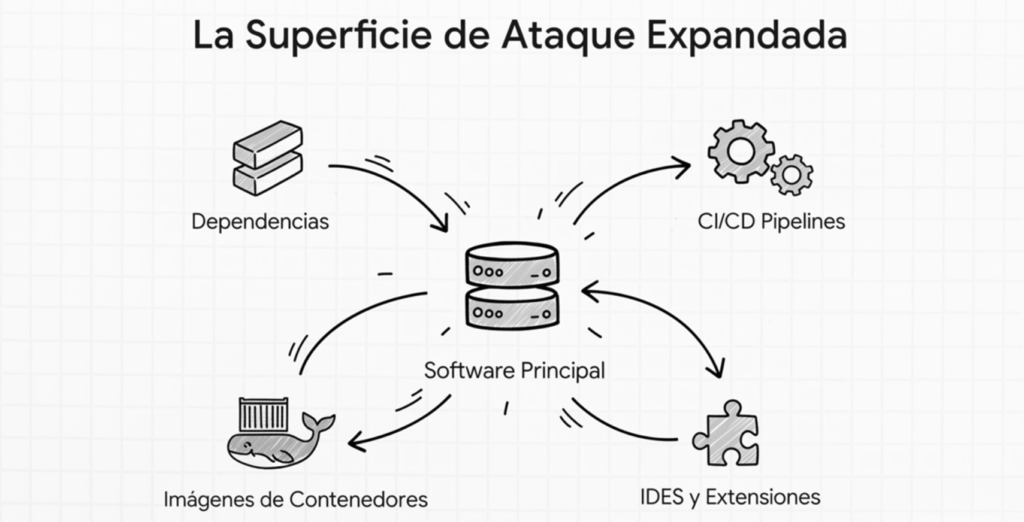
El artículo profundiza en el riesgo A03:2025 – Fallas en la cadena de suministro de software, un problema que ha crecido enormemente debido al uso masivo de dependencias externas, pipelines complejas y entornos de desarrollo conectados.

¿Qué es una falla en la cadena de suministro?
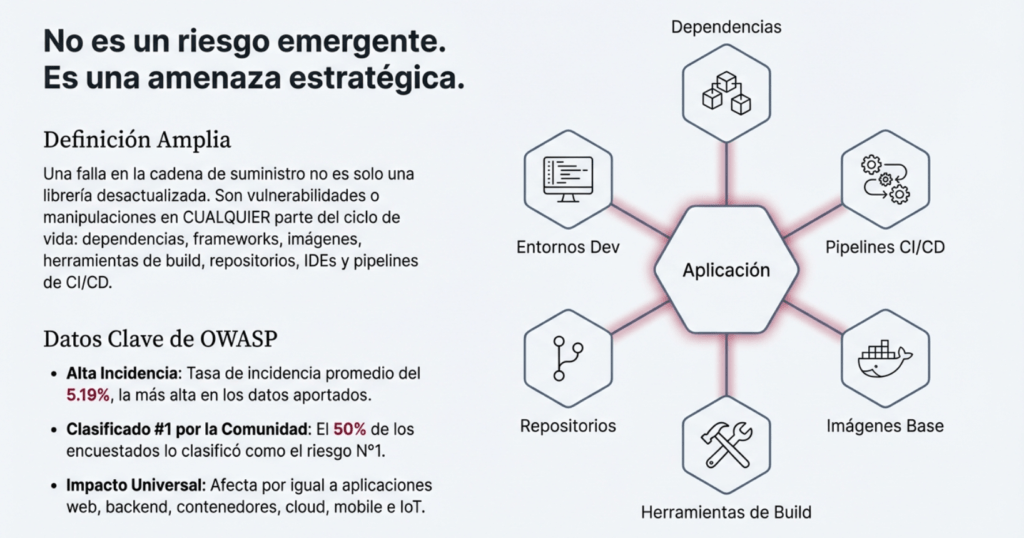
Son vulnerabilidades o manipulaciones maliciosas en cualquier parte del ciclo de vida del software: dependencias, librerías, frameworks, imágenes, herramientas de build, repositorios, IDEs, CI/CD, etc.
No se trata solo de una librería desactualizada: es todo aquello que interviene en crear, compilar, distribuir o ejecutar software.
Por qué es un problema crítico
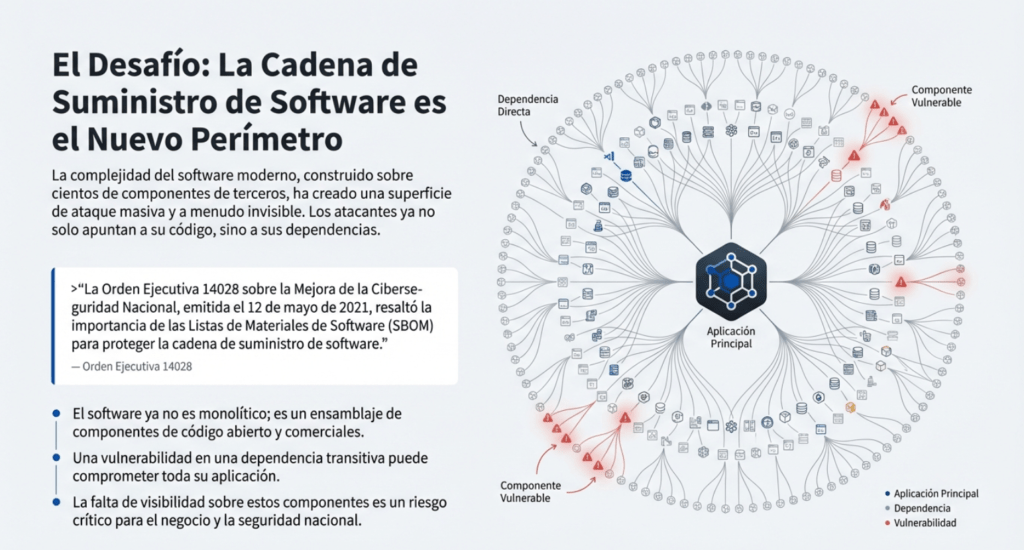
La mayoría del software moderno depende de cientos o miles de componentes que no controla. Una vulnerabilidad en una librería transitiva o un repositorio comprometido puede impactar a miles de organizaciones (casos: SolarWinds, Log4Shell, ataques en VS Code Marketplace, Bybit 2025).
Los datos de OWASP muestran que:
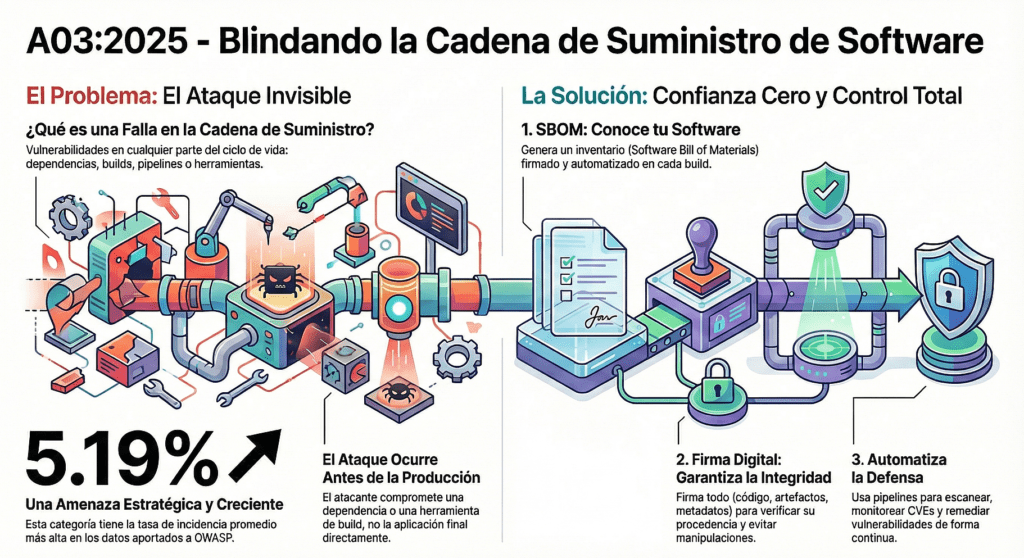
- Es una categoría con alta incidencia (5.19%).
- Afecta aplicaciones modernas por igual: web, backend, contenedores, cloud, mobile, IoT.
Señales de que una organización es vulnerable
Incluye prácticas como:
- No llevar inventario de dependencias.
- No monitorear CVEs.
- Usar paquetes sin mantenimiento.
- Pipelines sin control, sin firma y sin separación de funciones.
- Descarga de librerías de fuentes no confiables.
- Entornos de desarrollador inseguros.
Fallas en la cadena de suministro de software: el nuevo vector de ataque que pone en jaque a todo el ecosistema
La seguridad del software moderno ya no se rompe por un XSS mal escapado o una SQLi clásica. Se rompe por la confianza ciega en todo lo que consumís. Y esa confianza —en librerías, en repos, en pipelines, en herramientas— es lo que hoy explotan los ataques más sofisticados del mundo. Hablamos de la cadena de suministro de software. Y si no la asegurás, te va a explotar en la cara.
El OWASP Top 10 2025 lo dice claro: la categoría A03:2025 – Fallas en la cadena de suministro de software ya no es un problema “emergente” o “técnico”. Es una amenaza estratégica. Está rankeada altísima por la comunidad, tiene una tasa de incidencia creciente y un impacto que ya no se puede ignorar. Pero esto no es algo que apareció de la nada. Es el resultado de una evolución brutal en cómo se construye y entrega software.
Cuando yo empecé, compilabas todo a mano. Hoy, un solo npm install baja 600 paquetes. Un build en CI/CD automatizado puede ejecutar scripts, descargar imágenes de contenedor, interactuar con sistemas externos, todo sin que nadie lo revise. Y ahí está el problema: ya no controlamos el software que usamos. Lo ensamblamos desde partes que no escribimos, no auditamos y muchas veces ni entendemos. Esa es la cadena de suministro. Y cada eslabón es un punto de ataque.
OWASP no está improvisando. Viene alertando desde 2013 con “componentes vulnerables o desactualizados” (A09). Pero recién ahora, con A03:2025, reconoce la verdadera dimensión del riesgo. Porque ya no se trata solo de versiones viejas. Se trata de ataques a repositorios públicos, typosquatting, builds contaminados, CI/CD mal configurados, herramientas dev comprometidas, firmas falsificadas, falta de SBOM, y updates automáticos que instalan malware en silencio.
Casos como SolarWinds, el ataque a Bybit por SafeWallet, el gusano GlassWorm en el marketplace de VSCode, lo confirman: el punto de entrada ya no es la aplicación, es todo lo que se usó para construirla.
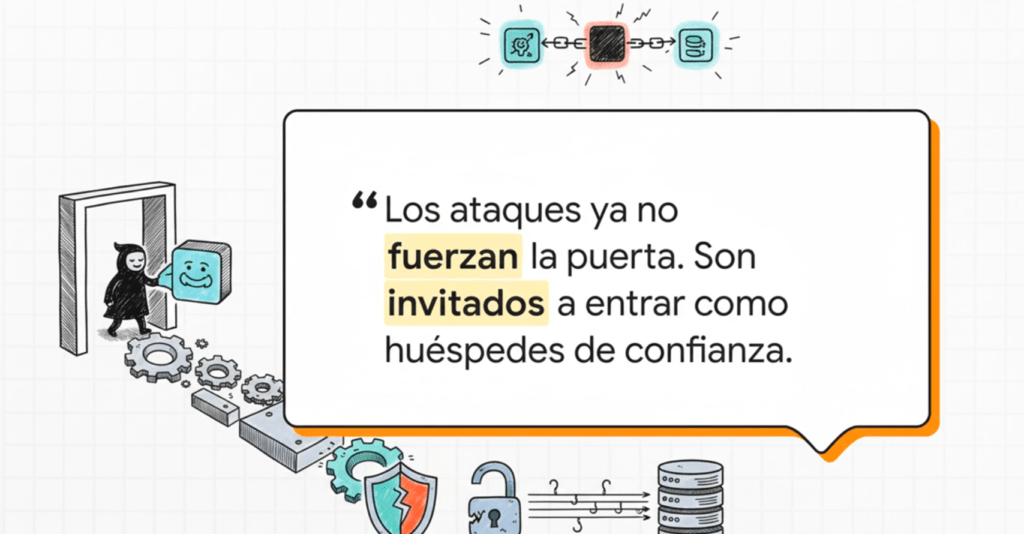
Y la gravedad está en que el atacante nunca toca tu servidor. Se mete antes: en una dependencia, en el plugin del IDE, en una imagen Docker o en una herramienta de build. Y cuando llega a producción, lo hace con firma válida, sin alertas, como parte legítima del sistema. Esa es la genialidad (y el terror) de los ataques a la cadena de suministro.
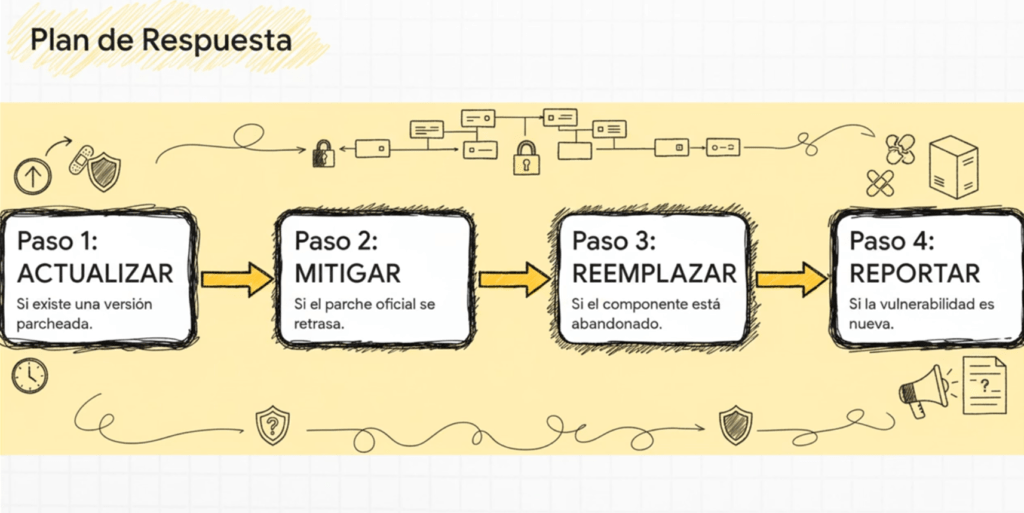
Ahora, ¿cómo lo evitás?
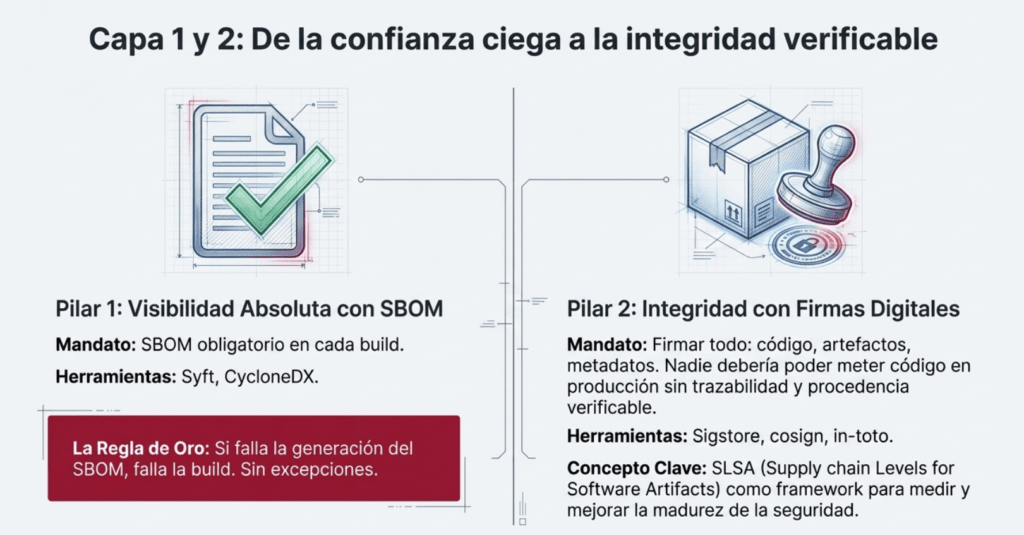
Primero: entendé que tu software no es tuyo si no sabés con qué lo hiciste. Ahí entra el SBOM (Software Bill of Materials). No es compliance, es defensa. Es saber exactamente qué metiste en cada build, qué versión, con qué hash, de dónde vino, y cuándo se usó. Y si no lo firmás, no sirve. Si no lo vinculás al artefacto, no sirve. Si no lo generás en el build, no sirve. Porque la única verdad es la que se produce en el momento de la compilación.
Yo uso Syft, CycloneDX y cosign en cada pipeline. Y si falla la generación del SBOM, falla la build. Sin excepciones. ¿Por qué? Porque no podés defender lo que no podés ver.
Después viene la parte crítica: firmar todo. Código, artefactos, metadatos. Usá SLSA, sigstore, in-toto, lo que funcione con tu stack. La idea es una sola: nadie debería poder meter código en producción sin trazabilidad y sin procedencia verificable.
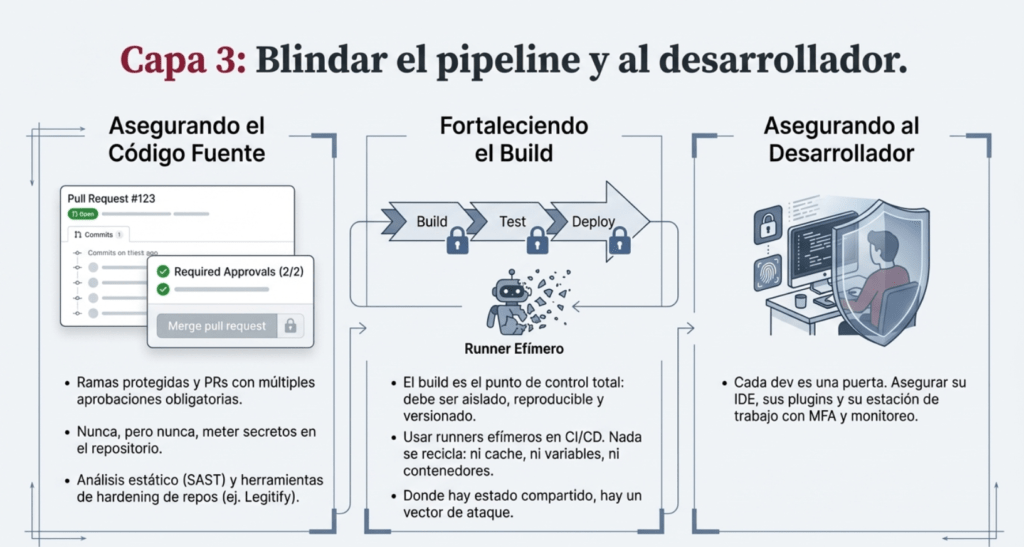
Tercero: el código fuente no se toca sin revisión. Usá ramas protegidas, pull requests con múltiples aprobaciones, análisis estático, herramientas como Legitify, y nunca, pero nunca, metas secretos al repo. Cada dev es una puerta. Su IDE, sus plugins, sus configuraciones. Asegurá esa puerta.
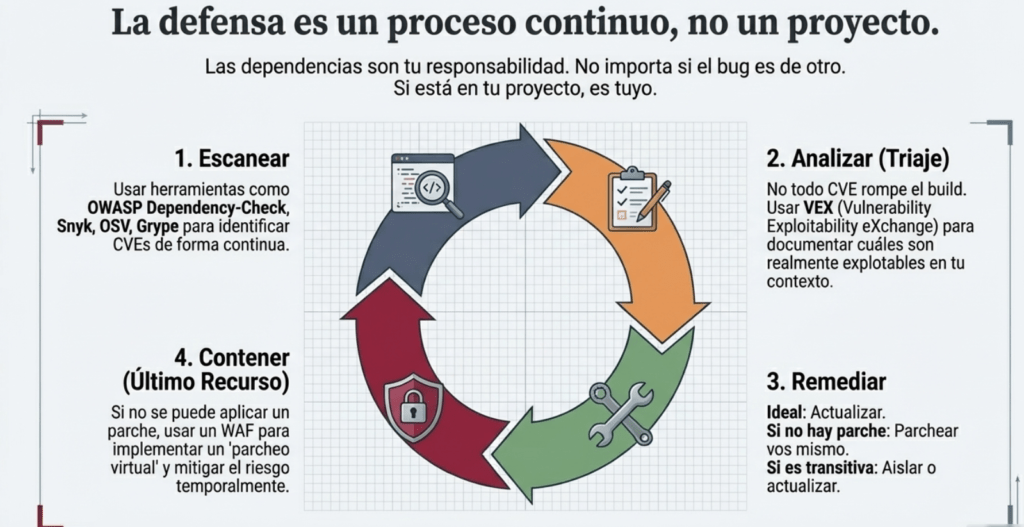
Cuarto: las dependencias son tu responsabilidad. No me importa si el bug es de otro. Si lo tenés en tu proyecto, es tuyo. Escaneá con OWASP Dependency-Check, Snyk, OSV, Grype, y después hacé triaje con VEX. No todo CVE rompe la build, pero todo CVE se analiza. Si no hay parche, parcheás vos. Si el proveedor no responde, lo forkeás. Si es transitive, lo aislás. Y si no podés, lo envolvés. Así se hace seguridad en serio.
Quinto: tu build es el punto de control total. Aislado, reproducible, versionado, con imágenes verificadas. No aceptes compilaciones que no podés replicar. Si usás GitHub Actions, firmá todo. Si tenés runners propios, que sean efímeros. Y nada se recicla: ni cache, ni variables, ni contenedores. Porque donde hay estado compartido, hay vector de ataque.
Sexto: escaneá tus artefactos antes de ejecutar. El binario final puede traer código que nunca viste en el código fuente. Y si lo firmaste mal, o usaste un compilador contaminado, te lo comiste igual. Usá análisis de composición binaria, SBOM enriquecidos, validación de firmas y políticas de autorización. Nada se despliega sin verificación.
Y por último: automatizá todo. Desde la generación del SBOM hasta el escaneo y la remediación. Porque si dependés de humanos para esto, ya perdiste. Necesitás pipelines inteligentes, alertas en tiempo real, métricas, dashboards, trazabilidad y respuesta coordinada. Y necesitás cultura. Equipos que entiendan que cada decisión en el código impacta en la cadena.
Cómo prevenir
El artículo desarrolla tácticas avanzadas como:
✔ SBOM obligatorio y generado en el build.
✔ Eliminación de dependencias no usadas.
✔ Firma de artefactos, procedencia y SLSA.
✔ Pipelines efímeros, reproducibles y auditados.
✔ Actualizaciones continuas y monitoreo automático de CVEs.
✔ Revisión de código, ramas protegidas, MFA, least privilege.
✔ Fortalecimiento de repositorios, IDEs y estaciones de trabajo.
✔ Uso de WAF o parcheo virtual como medida temporal.
Mentalidad ofensiva del hacker
El artículo también enseña cómo piensa un atacante:
- Buscan dependencias olvidadas.
- Cazan versiones con CVEs conocidos.
- Insertan malware en builds, imágenes o extensiones.
- Atacan estaciones de trabajo de desarrolladores.
- Explotan pipelines permisivos o repositorios mal configurados.
SBOM como arma principal de defensa
El SBOM permite saber qué está instalado, su versión, hash y procedencia.
Pero solo sirve si:
- Se genera durante el build.
- Se firma.
- Se versiona y se guarda históricamente.
- Se analiza de forma continua.
OWASP lo dejó claro en A03: el enemigo no ataca lo que vos ves. Ataca lo que integrás sin mirar. Y si no dominás tu cadena de suministro, entonces no dominás tu software. Esto no es opcional. Es la base del software moderno. Porque ya no estamos peleando contra exploits de hace 20 años. Estamos peleando contra cadenas de confianza quebradas, builds contaminados, dependencias zombis y pipelines vulnerables.
Parcheo virtual
Se explica cómo mitigar vulnerabilidades mediante reglas de WAF sin modificar el código fuente, algo esencial cuando no se puede aplicar un parche real de forma inmediata.
Evaluación de software open source
Incluye una guía profesional para analizar proyectos OSS con mentalidad hacker:
- Autenticidad y riesgo de typosquatting.
- Mantenedores activos.
- Seguridad interna.
- Dependencias transitivas ocultas.
- Comportamientos sospechosos en builds e instaladores.
- Calidad del código y del diseño de la API.
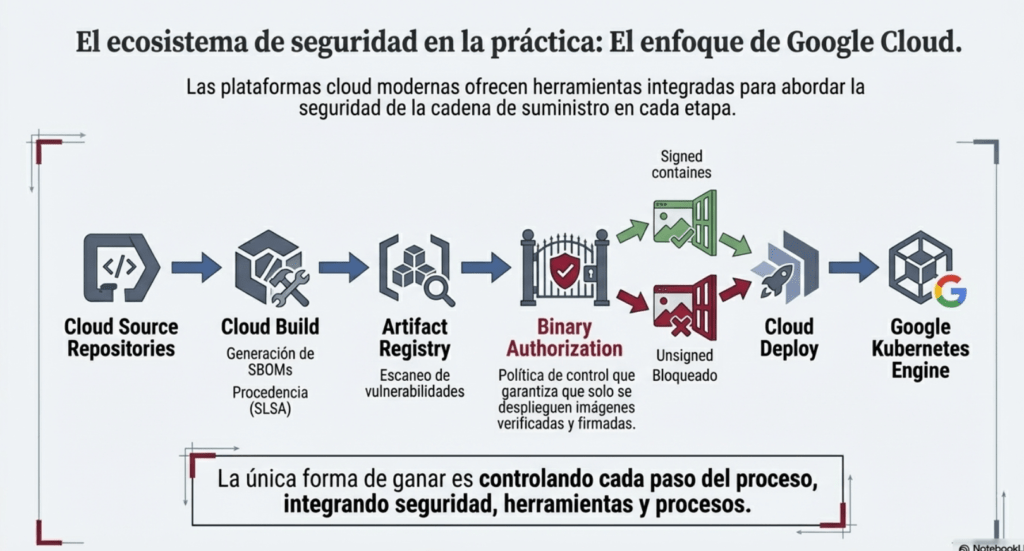
Seguridad en GCP y CI/CD moderno
Explica cómo Google Cloud aborda supply chain security:
- Artifact Registry
- Cloud Build
- Cloud Deploy
- Paneles de seguridad
- SBOM
- SLSA
- Autorización Binaria
Y sugiere rutas distintas según el nivel de complejidad del proyecto.
La única forma de ganar es controlando cada paso del proceso. Y para eso, necesitás mentalidad de hacker, herramientas bien configuradas y procesos que no perdonen el error humano. Porque si vos no asegurás tu cadena de suministro, te aseguro que otro la va a explotar.
OWASP TOP 10
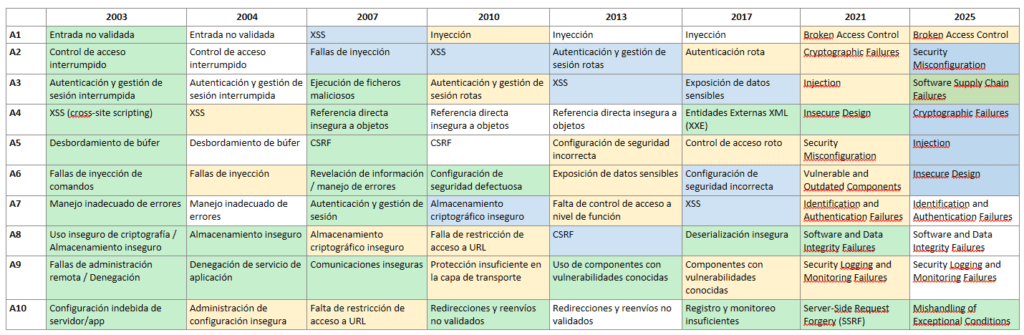
OWASP es popular por publicar el TOP 10 Owasp Web cada cuatro años. Este es un documento que lista los diez riesgos más críticos en aplicaciones web, con el objetivo de ayudar a las organizaciones a identificar y mitigar las vulnerabilidades asociadas con estos riesgos. https://owasp.org/Top10/es/ Cada uno de estos riesgos representa una debilidad común y significativa que a menudo se puede explotar para comprometer la seguridad de una aplicación web. OWASP proporciona información detallada sobre posibles vulnerabilidades y técnicas de ataque para cada riesgo.
El Top 10 de OWASP es una lista que se actualiza periódicamente de los riesgos de seguridad de las aplicaciones web más críticos. Lo mantiene el Proyecto Abierto de Seguridad de Aplicaciones Web (OWASP), una organización sin fines de lucro centrada en mejorar la seguridad de las aplicaciones web. Sirve como una valiosa guía para que los desarrolladores, los expertos en pruebas de penetración de aplicaciones web y las organizaciones comprendan y prioricen los riesgos de seguridad comunes en las aplicaciones web.
El Top 10 de OWASP es una lista conocida de los diez riesgos de seguridad de aplicaciones web más críticos. Se actualiza periódicamente para garantizar que refleje el panorama actual de amenazas y los desafíos de seguridad en constante evolución que enfrentan las aplicaciones web. La primera versión del Top 10 de OWASP se publicó en 2003. Su objetivo era crear conciencia sobre los riesgos comunes de seguridad de las aplicaciones web y ayudar a los desarrolladores a priorizar los esfuerzos de seguridad. La lista incluía riesgos como secuencias de comandos entre sitios (XSS), inyección de SQL y problemas de gestión de sesiones. Cada lanzamiento del Top 10 de OWASP se basa en las versiones anteriores, mejorando su precisión, relevancia y practicidad.
Evolución de OWASP TOP 10
En el momento de crear este artículo coexiste las dos versiones 2021/2025.
Diferencia entre A02 y A03
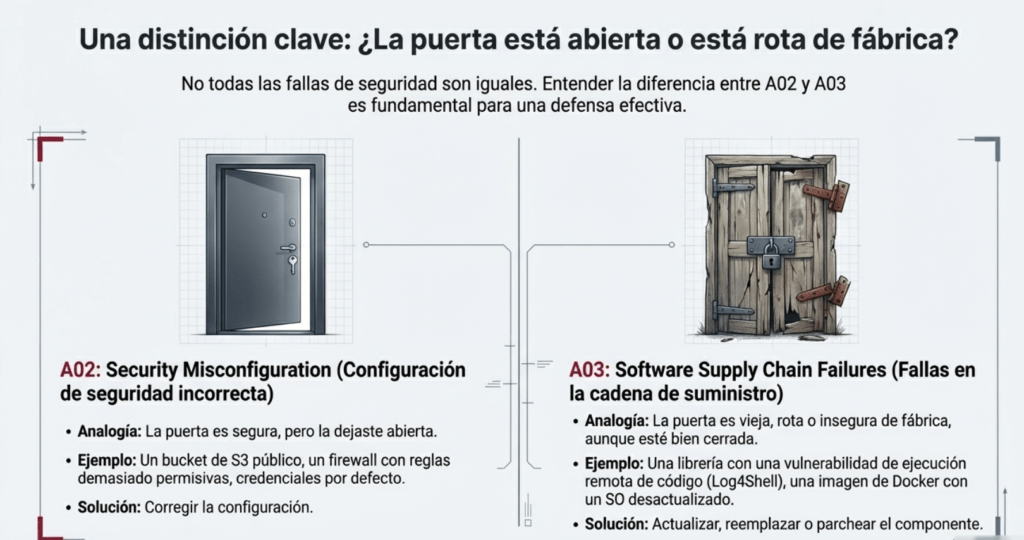
- A02 – Misconfiguración: la puerta está abierta por mala configuración.
- A03 – Componentes vulnerables: la puerta es vieja, rota o insegura de fábrica, aunque esté configurada correctamente.
⚪No cambia
🟡Fusionado
🔵Cambia de posición
🟢Nuevo
La evolución de A03:2025 – Fallas en la cadena de suministro de software: el riesgo más moderno y uno de los más peligrosos del ecosistema actual
La incorporación de Fallas en la cadena de suministro de software como el puesto A03:2025 del OWASP Top 10 marca un punto de quiebre histórico en la seguridad de aplicaciones. Aunque el concepto de “cadena de suministro” no es nuevo, su presencia formal como categoría en los rankings más influyentes del mundo refleja un cambio profundo en la forma en que el software es construido, distribuido, integrado y desplegado. Durante las primeras décadas del OWASP Top 10, los riesgos se concentraban en fallas generadas por el propio código de las aplicaciones: inyecciones, errores de autenticación, validación de entradas, configuración insegura. Sin embargo, el ecosistema moderno ya no depende exclusivamente del código que una empresa desarrolla internamente. Hoy, cada aplicación se compone de cientos de librerías externas, paquetes, dependencias, contenedores, servicios cloud, pipelines automatizados y herramientas de terceros. La cadena de suministro del software es tan vasta, distribuida y dinámica que una sola falla en uno de sus eslabones puede comprometer a miles o millones de sistemas en todo el mundo. OWASP reconoce esta realidad y eleva esta categoría al puesto A03 para representar el nivel crítico de riesgo que representa.
Para comprender su evolución, es importante analizar cómo OWASP trató esta problemática antes de que existiera como categoría formal. Desde 2003 hasta 2017, el riesgo asociado a componentes externos se encontraba parcialmente representado bajo nombres como “Uso de componentes con vulnerabilidades conocidas” (A9 en varias ediciones). En esa época, el foco principal estaba en librerías obsoletas, frameworks sin mantenimiento o software de terceros con vulnerabilidades públicas. Era un problema grave, pero aún se lo percibía como un aspecto limitado, casi un apéndice del desarrollo, que requería simplemente actualizar dependencias o hacer escaneos periódicos de CVEs. Aun así, OWASP advertía que este era un riesgo subestimado, ya que miles de aplicaciones reutilizaban código vulnerable sin saberlo. Sin embargo, todavía no existía la comprensión moderna de “cadena de suministro” como un sistema complejo, distribuido y con múltiples puntos de ataque.
El verdadero punto de inflexión comenzó a fines de la década de 2010 y principios de 2020, cuando ocurrieron incidentes globales que revelaron una realidad inquietante: los atacantes ya no necesitaban vulnerar directamente una aplicación para comprometerla; podían infiltrarse a través de un proveedor, una dependencia o incluso a través del pipeline de construcción. El caso de SolarWinds (2020) fue un símbolo de este cambio: una intrusión en el proceso de compilación de un producto ampliamente utilizado permitió comprometer a agencias gubernamentales y empresas en todo el mundo. Incidentes similares se multiplicaron en GitHub, PyPI, NPM, RubyGems y otros ecosistemas donde repositorios libres y automatizados se convirtieron en objetivos críticos. Se observó un aumento en técnicas como typosquatting, suplantación de paquetes, dependencias contaminadas, ataques a herramientas DevOps y manipulación de imágenes de contenedores. Por primera vez, la industria entendió que la cadena de suministro era un objetivo y que su complejidad hacía imposible mantener un control manual completo.
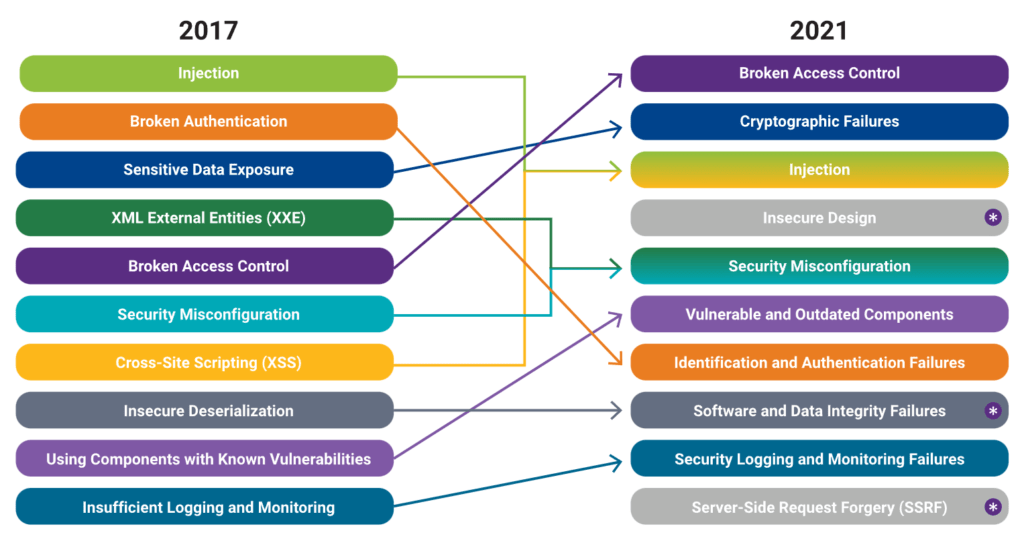
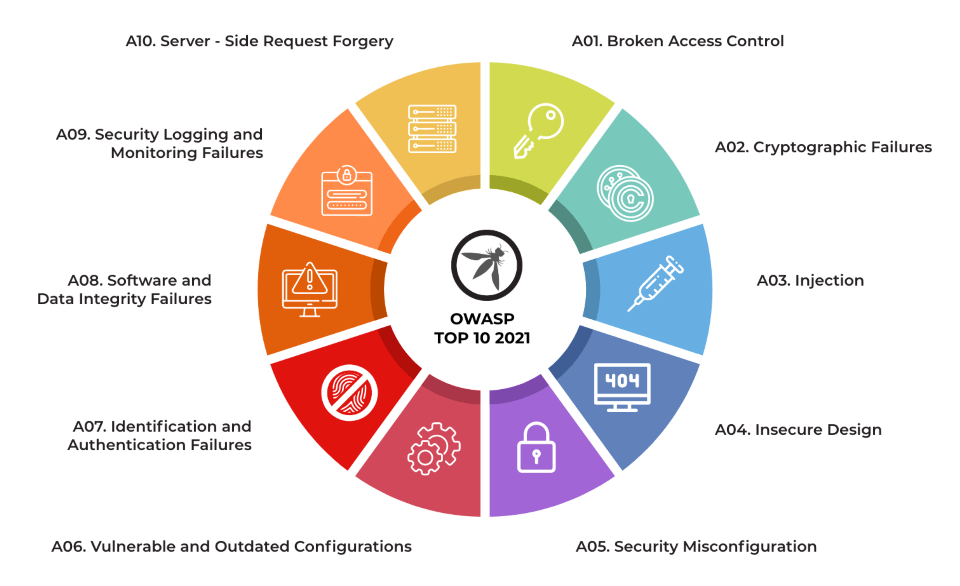
Este escenario llevó a OWASP a incluir por primera vez esta categoría en 2021 bajo el nombre de Vulnerable and Outdated Components (A06:2021), aunque todavía representaba solo una parte del riesgo. Sin embargo, ese año debutó una nueva categoría experimental extraída por encuesta: A08:2021 – Software & Data Integrity Failures. Allí, OWASP comenzó a reconocer explícitamente fallas en el pipeline de construcción, confianza excesiva en proveedores y validaciones inadecuadas de integridad, prefigurando lo que se consolidaría en ediciones posteriores. No obstante, el término “cadena de suministro de software” todavía no aparecía como categoría independiente. El ecosistema aún estaba asimilando el cambio cultural hacia DevSecOps, SBOMs (Software Bill of Materials), firmas digitales, automatización de builds y controles de integridad en la entrega de software. La industria comenzaba a comprender el riesgo, pero OWASP aún clasificaba estas fallas dentro de otras categorías más amplias.
OWASP TOP 10 2021
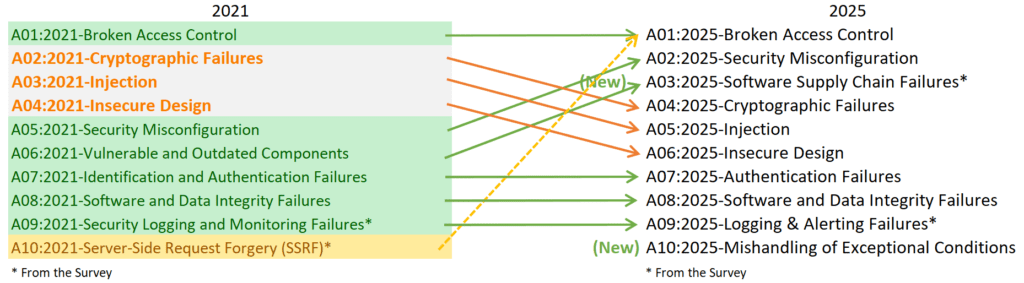
Finalmente, OWASP Top 10 – 2025 introduce de forma oficial la categoría A03: Software Supply Chain Failures, elevándola a uno de los primeros lugares. Esta decisión no surge por moda ni por un caso aislado, sino por años de evidencia acumulada. OWASP reconoce que las aplicaciones modernas dependen masivamente de componentes que no controla: paquetes, imágenes Docker, contenedores Alpine o Ubuntu, servicios externos, repositorios públicos, CDNs, herramientas de compilación, plataformas de CI/CD y proveedores cloud. Cada uno de estos elementos introduce un punto único de falla que puede ser explotado antes incluso de que el software llegue a producción. La categoría A03:2025 engloba así un espectro de riesgos que va mucho más allá de simples librerías vulnerables: incluye corrupción de dependencias, manipulación de pipelines, configuraciones inseguras en repositorios, falta de verificación criptográfica, builds no reproducibles, actualizaciones maliciosas, supply chain attacks indirectos y cualquier manipulación que pueda ocurrir antes de que el software esté disponible para los usuarios.
Lo una de las características más notables de esta categoría es que el atacante puede comprometer una organización sin interactuar jamás con sus sistemas de producción. El vector de ataque se desplaza hacia etapas previas del ciclo de vida del software: desarrollo, integración, empaquetado o distribución. Esto crea un problema inmenso porque muchos equipos no tienen controles adecuados en esas fases, o confían ciegamente en proveedores externos, repositorios públicos o pipelines automatizados. OWASP subraya que la complejidad de las cadenas de suministro creció más rápido que la madurez de los mecanismos de seguridad. Si un atacante logra contaminar una dependencia NPM con un malware, o infiltrarse en un proceso de build, o comprometer la firma digital de un paquete, puede distribuir código malicioso a miles de aplicaciones sin levantar sospechas.
OWASP TOP 10 2025
En la lista de los Diez Principales para 2025, se han incorporado dos categorías nuevas y una consolidada. Esta versión según OWASP está centrada en la causa raíz, más que en los síntomas, en la medida de lo posible. Dada la complejidad de la ingeniería y la seguridad del software, resulta prácticamente imposible crear diez categorías sin cierto grado de superposición.
El ascenso de A03 en 2025 también refleja la madurez de las organizaciones al reconocer que ya no basta con proteger lo visible: es necesario asegurar cada eslabón de la cadena, desde el commit inicial hasta la imagen final desplegada. El auge de SBOMs, firmas digitales, validación de integridad, control de versiones, monitoreo de repositorios externos y herramientas de escaneo de dependencias no es casual: son respuestas necesarias a un problema que creció sin control. Pero OWASP advierte que la mayoría de las organizaciones aún no han implementado estas medidas, y que las cadenas de suministro libres y abiertas (como NPM, PyPI, Docker Hub, Maven Central) siguen siendo extremadamente vulnerables a ataques sofisticados.
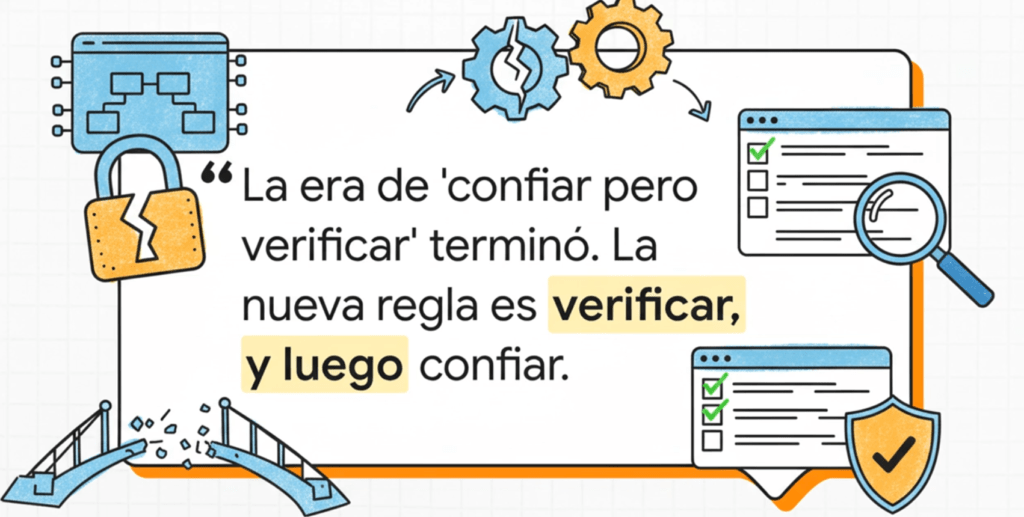
Lo más importante es que A03:2025 no solo identifica vulnerabilidades técnicas: también expone fallas de confianza. Uno de los elementos más profundos de esta categoría es que obliga a repensar el modelo de confianza en el software. La industria pasó de crear software de forma aislada a integrar miles de piezas externas, confiando en que esos componentes son seguros porque “todos los usan”. En 2025 OWASP deja claro que la confianza ciega es un error fatal. El futuro de la seguridad depende de verificar, auditar y asegurar cada dependencia, cada pipeline y cada proveedor involucrado.
En resumen, la evolución de las Fallas en la cadena de suministro de software desde su origen conceptual en 2003 hasta su reconocimiento oficial como A03:2025 simboliza una transformación cultural y tecnológica. El ecosistema moderno dejó de ser un entorno monolítico controlado y se convirtió en un entramado complejo donde fallos invisibles pueden tener impactos globales. El puesto A03 no es simplemente un ranking: es una alerta estratégica que muestra que el punto más débil de un sistema puede no estar dentro del sistema mismo, sino en los componentes que lo componen. OWASP nos recuerda, con esta categoría, que la seguridad del software no puede ser más fuerte que la seguridad de su cadena de suministro. Y en 2025 ese eslabón se volvió uno de los más atacados, más difíciles de controlar y más críticos para el futuro de la ciberseguridad.
A03:2025 Fallas en la cadena de suministro de software
Esto fue clasificado alto en la encuesta de la comunidad Top 10 con exactamente el 50% de los encuestados clasificándolo en el n.º 1. Desde que apareció inicialmente en el Top 10 de 2013 como «A9 – Uso de componentes con vulnerabilidades conocidas», el riesgo ha crecido en alcance para incluir todas las fallas de la cadena de suministro, no solo las que involucran vulnerabilidades conocidas. A pesar de este mayor alcance, las fallas de la cadena de suministro siguen siendo un desafío para identificar con solo 11 vulnerabilidades y exposiciones comunes (CVE) que tienen las CWE relacionadas. Sin embargo, cuando se prueba e informa en los datos aportados, esta categoría tiene la tasa de incidencia promedio más alta en 5,19%. Las CWE relevantes son CWE-477: Uso de función obsoleta, CWE-1104: Uso de componentes de terceros sin mantenimiento , CWE-1329: Dependencia de componente que no es actualizable y CWE-1395: Dependencia de componente de terceros vulnerable .
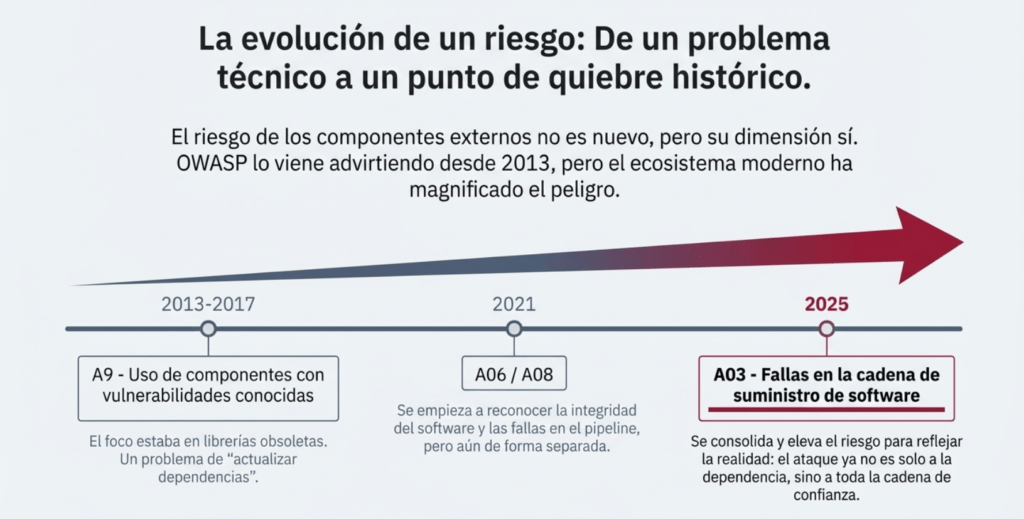
Tabla de puntuación.
| CWE mapeados | Tasa máxima de incidencia | Tasa de incidencia promedio | Cobertura máxima | Cobertura promedio | Exploit ponderado promedio | Impacto ponderado promedio | Total de ocurrencias | Total de CVEs |
| 5 | 8,81% | 5,19% | 65,42% | 28,93% | 8.17 | 5.23 | 215.248 | 11 |
Descripción.
Las fallas en la cadena de suministro de software son averías u otros problemas en el proceso de desarrollo, distribución o actualización de software. Suelen deberse a vulnerabilidades o cambios maliciosos en código, herramientas u otras dependencias de terceros de las que depende el sistema.
Es probable que usted sea vulnerable si:
- Si no realiza un seguimiento cuidadoso de las versiones de todos los componentes que utiliza (tanto del lado del cliente como del lado del servidor). Esto incluye los componentes que utiliza directamente, así como las dependencias anidadas (transitivas).
- Si el software es vulnerable, no tiene soporte o está desactualizado. Esto incluye el sistema operativo, el servidor web/de aplicaciones, el sistema de gestión de bases de datos (SGBD), las aplicaciones, las API y todos los componentes, los entornos de ejecución y las bibliotecas.
- Si no escanea periódicamente en busca de vulnerabilidades y no se suscribe a boletines de seguridad relacionados con los componentes que utiliza.
- Si no cuenta con un proceso de gestión de cambios o seguimiento de cambios dentro de su cadena de suministro, incluido el seguimiento de IDE, extensiones y actualizaciones de IDE, cambios en el repositorio de código de su organización, entornos sandbox, repositorios de imágenes y bibliotecas, la forma en que se crean y almacenan los artefactos, etc. Cada parte de su cadena de suministro debe estar documentada, especialmente los cambios.
- Si no ha endurecido cada parte de su cadena de suministro, con un enfoque especial en el control de acceso y la aplicación del mínimo privilegio.
- Si sus sistemas de cadena de suministro no tienen separación de funciones, ninguna persona debería poder escribir código y promoverlo hasta la producción sin la supervisión de otra persona.
- Si a los desarrolladores, profesionales de DevOps o de infraestructura se les permite descargar y usar componentes de fuentes no confiables para su uso en producción.
- Si no se reparan o actualizan la plataforma, los marcos y las dependencias subyacentes de forma oportuna y teniendo en cuenta los riesgos. Esto suele ocurrir en entornos donde la aplicación de parches es una tarea mensual o trimestral bajo control de cambios, lo que deja a las organizaciones expuestas a días o meses de exposición innecesaria antes de corregir las vulnerabilidades.
- Si los desarrolladores de software no prueban la compatibilidad de las bibliotecas actualizadas, mejoradas o parcheadas.
- Si no protege las configuraciones de cada parte de su sistema (consulte A02:2025-Configuración incorrecta de seguridad ).
- Si tiene una canalización CI/CD compleja que utiliza muchos componentes pero tiene una seguridad más débil que el resto de su aplicación.
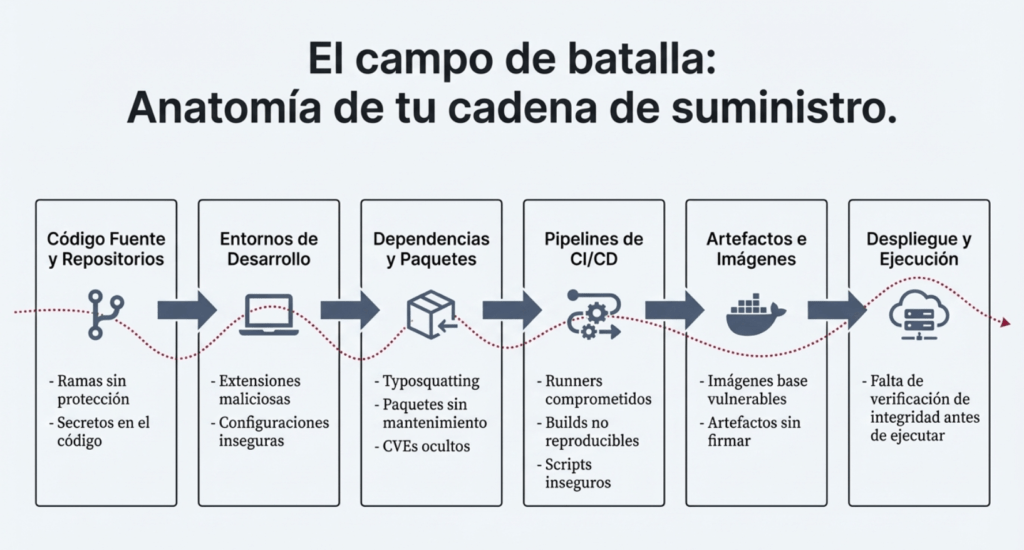
Cómo prevenir.
Debería existir un proceso de gestión de parches para:
- Conozca la lista de materiales de software (SBOM) de todo su software y administre el diccionario SBOM de forma centralizada.
- Realice un seguimiento no sólo de sus propias dependencias, sino también de sus dependencias (transitivas), y así sucesivamente.
- Elimina dependencias no utilizadas, funciones, componentes, archivos y documentación innecesarios. Reduce la superficie de ataque.
- Inventariar continuamente las versiones de los componentes del lado del cliente y del lado del servidor (por ejemplo, marcos, bibliotecas) y sus dependencias utilizando herramientas como versiones, OWASP Dependency Check, retire.js, etc.
- Monitoree continuamente fuentes como Vulnerabilidades y Exposiciones Comunes (CVE) y la Base de Datos Nacional de Vulnerabilidades (NVD) para detectar vulnerabilidades en los componentes que utiliza. Utilice análisis de composición de software, la cadena de suministro de software o herramientas SBOM centradas en la seguridad para automatizar el proceso. Suscríbase para recibir alertas por correo electrónico sobre vulnerabilidades de seguridad relacionadas con los componentes que utiliza.
- Obtenga componentes únicamente de fuentes oficiales (confiables) a través de enlaces seguros. Prefiera los paquetes firmados para reducir la posibilidad de incluir un componente modificado y malicioso (consulte A08:2025 – Fallos de integridad de software y datos ).
- Elegir deliberadamente qué versión de una dependencia utilizar y actualizarla solo cuando sea necesario.
- Monitoree bibliotecas y componentes sin mantenimiento o que no generen parches de seguridad para versiones anteriores. Si no es posible aplicar parches, considere implementar un parche virtual para monitorear, detectar o protegerse contra el problema detectado.
- Actualice su CI/CD, IDE y cualquier otra herramienta de desarrollo periódicamente
- Trate los componentes en su canalización de CI/CD como parte de este proceso; fortalézcalos, monitoréelos y documente los cambios según corresponda.
Debe haber un proceso de gestión de cambios o un sistema de seguimiento para rastrear los cambios en:
- Su configuración de CI/CD (todas las herramientas de compilación y canalización)
- Su repositorio de código
- Áreas de pruebas
- IDE de desarrollador
- Sus herramientas SBOM y artefactos creados
- Sus sistemas de registro y registros
- Integraciones de terceros, como SaaS
- Repositorio de artefactos
- Registro de contenedores
Fortalezca los siguientes sistemas, lo que incluye habilitar MFA y bloquear IAM:
- Su repositorio de código (que incluye no registrar secretos, proteger ramas, copias de seguridad)
- Estaciones de trabajo de desarrollador (parches regulares, MFA, monitoreo y más)
- Su servidor de compilación y CI/CD (separación de tareas, control de acceso, compilaciones firmadas, secretos de alcance ambiental, registros a prueba de manipulaciones, más)
- Sus artefactos (garantice la integridad a través de la providencia, la firma y el sellado de tiempo, promueva artefactos en lugar de reconstruir para cada entorno, asegúrese de que las compilaciones sean inmutables)
- La infraestructura como código se administra como todo el código, incluido el uso de PR y control de versiones
Toda organización debe garantizar un plan continuo para monitorear, clasificar y aplicar actualizaciones o cambios de configuración durante la vida útil de la aplicación o la cartera.
Ejemplos de escenarios de ataque.
Escenario n.° 1: Un proveedor de confianza se ve comprometido con malware, lo que pone en riesgo sus sistemas informáticos al actualizar. El ejemplo más conocido es probablemente el siguiente: El ataque a SolarWinds en 2019 que comprometió a unas 18.000 organizaciones. https://www.npr.org/2021/04/16/985439655/a-worst-nightmare-cyberattack-the-untold-story-of-the-solarwinds-hack
Escenario n.° 2: Un proveedor confiable se ve comprometido de tal manera que se comporta de manera maliciosa solo bajo una condición específica. El robo de $1.5 mil millones de Bybit en 2025 fue causado por un ataque a la cadena de suministro en el software de billetera que solo se ejecutó cuando se usaba la billetera objetivo. https://thehackernews.com/2025/02/bybit-hack-traced-to-safewallet-supply.html
Escenario n.° 3: El ataque a la cadena de suministro de GlassWorm en 2025 contra el marketplace de VS Code hizo que actores maliciosos implementaran código invisible y autorreplicante en una extensión legítima del Marketplace de VS, así como en varias extensiones del Marketplace de OpenVSX, que se actualizaban automáticamente en los equipos de los desarrolladores. El gusano extrajo inmediatamente secretos locales de los equipos de los desarrolladores, intentó establecer un control total y, si era posible, vació sus monederos de criptomonedas. Este ataque a la cadena de suministro fue extremadamente avanzado, de rápida propagación y dañino, y al dirigirse a los equipos de los desarrolladores, demostró que ahora son los propios desarrolladores los principales objetivos de los ataques a la cadena de suministro.
Escenario n.° 4: Los componentes suelen ejecutarse con los mismos privilegios que la propia aplicación, por lo que las fallas en cualquier componente pueden tener consecuencias graves. Dichas fallas pueden ser accidentales (p. ej., un error de codificación) o intencionadas (p. ej., una puerta trasera en un componente). Algunos ejemplos de vulnerabilidades explotables de componentes descubiertas son:
- CVE-2017-5638, una vulnerabilidad de ejecución remota de código en Struts 2 que permite la ejecución de código arbitrario en el servidor, ha sido señalada como la causa de importantes infracciones.
- Si bien la Internet de las cosas (IoT) suele ser difícil o imposible de parchar, la importancia de hacerlo puede ser grande (por ejemplo, en el caso de los dispositivos biomédicos).
Existen herramientas automatizadas que ayudan a los atacantes a encontrar sistemas sin parches o mal configurados. Por ejemplo, el motor de búsqueda Shodan IoT puede ayudar a encontrar dispositivos que aún sufren la vulnerabilidad Heartbleed, parcheada en abril de 2014.
ANTES: A06 – Vulnerable and Outdated Components (Componentes vulnerables o desactualizados)
| CWEs mapeadas | Tasa de incidencia máx | Tasa de incidencia prom | Explotabilidad ponderada prom | Impacto ponderado prom | Cobertura máx | Cobertura prom | Incidencias totales | Total CVEs |
| 3 | 27.96% | 8.77% | 51.78% | 22.47% | 5.00 | 5.00 | 30,457 | 0 |
Resumen
Era el segundo de la encuesta de la comunidad Top 10, pero también tuvo datos suficientes para llegar al Top 10 a través del análisis de datos. Los componentes vulnerables son un problema conocido que es difícil de probar y evaluar el riesgo. Es la única categoría que no tiene enumeraciones de debilidades comunes (CWE) asignadas a las CWE incluidas, por lo que se utiliza un peso de impacto/exploits predeterminado de 5,0. Las CWE notables incluidas son CWE-1104: Uso de componentes de terceros no mantenidos y las dos CWE del OWASP Top 10 2013 y 2017.
SBOM y Gráficos de Dependencia: Seguridad de la Cadena de Suministro Desde la Compilación
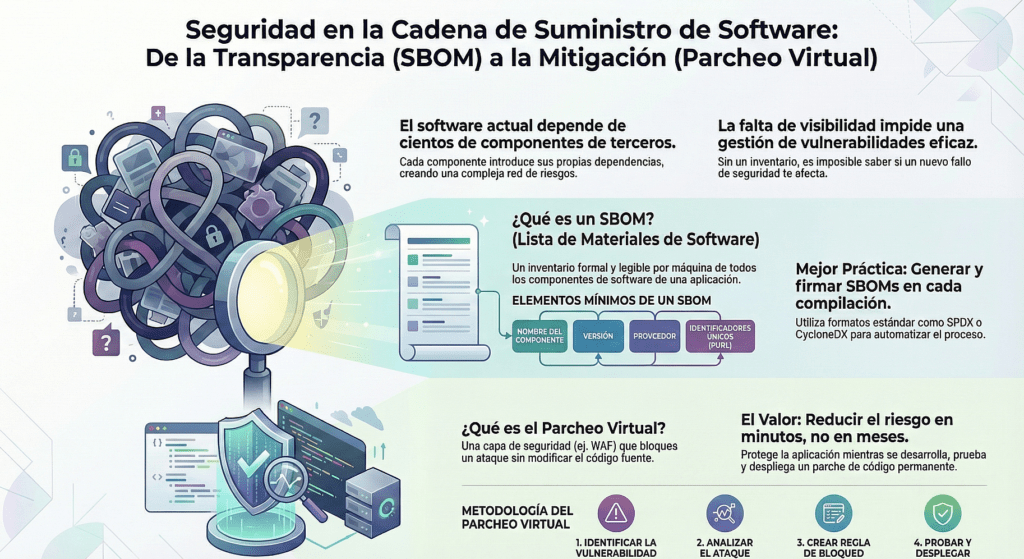
Hoy, la conversación no gira en torno a exploits en ensamblador o rootkits en kernel space. El nuevo campo de batalla es la cadena de suministro de software. Y el arma más potente que tenemos —si se sabe usar— es el SBOM: la Lista de Materiales de Software. Pero, como toda herramienta poderosa, si no se usa bien, es un chiche inútil.
Un SBOM no es un documento de compliance, ni un Excel con dependencias. Es una snapshot técnica, legible por máquina, que captura exactamente qué librerías, versiones, hashes, licencias y fuentes fueron incluidas en una build. Es el equivalente a firmar una bomba nuclear: sabés qué pusiste, cómo lo ensamblaste y quién fue responsable. Y si después algo explota —un CVE, una violación de política, un paquete malicioso—, podés actuar con precisión quirúrgica.
SBOM en la Build o No Sirve
Esto es clave: el SBOM tiene que generarse en el build, no después. Tiene que formar parte del pipeline CI/CD. No se hace «a mano», ni se reconstruye con scripts externos. ¿Por qué? Porque el único momento donde tenés la resolución exacta de dependencias, metadatos, checksums y contexto de compilación es en el build. Todo lo demás es interpretación, y la seguridad no se basa en suposiciones.
Tenés que usar herramientas como Syft, SPDX o CycloneDX. Formatos estándar, interoperables. Ejecutá esos comandos justo después de resolver las dependencias, antes de empaquetar el artefacto. Y no alcanza con generar el archivo: tenés que firmarlo, con cosign, sigstore o in-toto. SBOM sin firma es SBOM falsificable.

Vinculá el SBOM al Artefacto o No Hay Prueba
El truco es unir el artefacto y su SBOM con una firma. Esa unión es lo que te permite confiar en que el artefacto fue generado de esa compilación. ¿Qué firmás? El binario, el SBOM, y si querés ir más allá, la procedencia completa (firmás el proceso). Todo eso lo hacés dentro del pipeline. Nada de firmar después. Usá GitHub Actions, CI runners, contenedores reproducibles. Si falla la generación del SBOM, frená el build. Fail-fast o viví con riesgo.
No es Solo un JSON: Es Mapa de Ataque y Defensa
Con el SBOM en mano, ya podés cruzarlo con fuentes de vulnerabilidades. CVEs, OSS Index, Grype, Snyk. Asignás el riesgo a cada componente. Pero no te podés quedar ahí. Hay que diferenciar si una dependencia es directa o transitiva. Si es una lib que usás vos o algo que te cayó por NPM como cuarta capa. Y para eso necesitás análisis real. Podés visualizarlos con herramientas como Dependency-Track, o enriquecerlos con VEX (Vulnerability Exploitability eXchange), que te dicen si una CVE realmente es explotable en tu contexto.
El SBOM como Auditoría Continua
Guardá todos los SBOMs. Versionalos como si fueran código fuente. Necesitás poder decir: “el release de tal día usó tal dependencia vulnerable”. Y necesitás ese dato rápido, para responder ante auditorías, tickets de seguridad, incidentes o demandas legales. No esperes a que te lo pidan: integralo como parte del proceso. Usá un registro de artefactos con soporte SBOM, o un gestor como Dependency-Track. El punto es tener trazabilidad.

Gestión de Vulnerabilidades en Base al SBOM: Triaje con Contexto
Tener un CVE asignado no significa automáticamente que estás en riesgo. Ahí entra VEX. Con VEX podés marcar que ese CVE no aplica, que no es explotable, o que ya está mitigado. Así no desperdiciás tiempo parando el mundo por cosas que no importan. Pero para eso necesitás VEX automatizado, ya sea generado por vos o consumido de proveedores. Esta integración es el santo grial del triaje moderno. Ves el componente vulnerable, su contexto y su impacto real.
Cadena de Suministro Profunda: El Riesgo Oculto
Muchas veces, los paquetes más vulnerables no los ves. Vienen por debajo, en capas de imágenes, en dependencias de dependencias, o en binarios que alguien metió sin pasar por el build formal. Esas son las amenazas fantasmas. Ahí entra el grafo de dependencia: te permite ver por qué y cómo se incluyó cada cosa. Y eso te da herramientas para remediar. A veces, no podés parchear directamente. Pero podés subir una dependencia para que resuelva otra transitiva. O podés reemplazar, aislar, o incluso aplicar mitigaciones a nivel de ejecución.

Errores Comunes en SBOM: Te Exponés Sin Saberlo
Si tu SBOM no incluye checksums, estás ciego ante modificaciones no autorizadas. Si no lo firmás, no podés demostrar autenticidad. Si no está versionado, no podés hacer rollback. Si no guardás el histórico, perdés evidencia ante auditorías. Todo esto es fácil de automatizar. Pero la mayoría ni lo intenta. Y después, cuando pasa algo, no tienen cómo reconstruir lo que se desplegó.
Política SBOM: Establecé Reglas Claras o Va Todo a la Deriva
Tenés que definir formatos aceptados (CycloneDX, SPDX), campos obligatorios, políticas de firma, tiempos de retención y control de acceso. Tenés que forzar que todo release público tenga SBOM firmado, y que todos los proveedores que integrás te entreguen SBOM compatibles. Es una política de supervivencia, no de compliance.
CI/CD con SBOM: Ejemplo Real de Acción
En un pipeline real, después de compilar, ejecutás:
– name: Build and SBOM
run: |
./build.sh
syft dir:. -o cyclonedx-json > sbom.json
cosign sign-blob –key ${{ secrets.COSIGN_KEY }} –output-signature sbom.sig sbom.json
Después subís todo como artefacto. Y podés verificar en otro paso si el SBOM está presente y firmado. Si no, fallás la build. Esa es la forma. No hay excusas para no tener esto ya en producción.
Fail-Fast o Warn: Elegí el Nivel de Reacción Correcto
No todo CVE debe romper una build. Un hallazgo menor puede ir a un panel de triaje y esperar. Pero si tenés un CVE crítico en una lib directa, eso tiene que romper el proceso. La política tiene que estar codificada en tu pipeline, con reglas claras. Cosas como:
- Si hay un CVE sin parche y sin mitigación → falla la build
- Si es una licencia incompatible → notificación
- Si es una dependencia vieja no mantenida → warning, pero registrado
El SBOM No es Compliance, Es Defensa Activa
Si no tenés SBOM, no sabés qué desplegaste. Si no lo firmás, no podés demostrar confianza. Si no lo analizás, no podés anticipar riesgos. Y si no lo integrás al pipeline, estás a merced de tus propios errores. La cadena de suministro es hoy uno de los vectores de ataque más usados por grupos avanzados. No te van a explotar por lo que escribiste vos, sino por lo que integraste sin revisar.
El SBOM no es opcional. Es el pasaporte de tu software. Y si no tenés uno, no deberías ni pensar en pasar a producción. En la próxima entrega voy a meterme de lleno en cómo escalar esto a múltiples equipos, con firmas distribuidas, políticas centralizadas y escaneo continuo. Porque tener SBOM en un proyecto es fácil. Tenerlo en 300 repos, en 3 clouds y en 2 idiomas, eso es lo que separa a los amateurs de los que hacemos esto en serio.
Hacking la Cadena de Suministro: Seguridad del Código al Binario Final
Desde hace más de dos décadas, vengo trabajando con sistemas complejos y atacando superficies que muchos ni sabían que eran vulnerables. Y si hay algo que se convirtió en mi obsesión los últimos años, es la seguridad de la cadena de suministro de software. Porque te lo digo así, sin vueltas: el software moderno no falla por bugs. Falla por la confianza ciega en todo lo que consume. Y lo que consume —librerías, herramientas, proveedores, sistemas de CI/CD, artefactos de terceros— es tan vulnerable como tu peor eslabón.
Hablar de Supply Chain Security hoy no es opcional. Es parte del ciclo de desarrollo. Desde el momento que tipeás npm install ya estás abriendo tu sistema a cientos de dependencias que no escribiste, que no auditaste, que no entendés y que, si mañana cambian silenciosamente, nadie en tu equipo se entera. Lo mismo pasa con el código fuente, los sistemas de compilación, los pipelines, los entornos de ejecución y los binarios que publicás. Es una cadena larga, compleja, y cada eslabón puede romperse. El punto es: ¿cómo evitamos que eso pase?

Cadena de Suministro: No Es Teoría, Es Superficie de Ataque
Hay cuatro puntos clave donde se rompen las cosas: código fuente, entorno de build, dependencias y tiempo de ejecución. Y cada uno tiene su propio juego de amenazas. Te doy ejemplos reales que vi explotarse en producción:
- Repos mal configurados: alguien con permisos para hacer push directo a main, sin revisiones, sin firmas, sin alertas. Una inyección en un commit y chau, te infectaron el release.
- Build comprometido: pipelines de CI con secretos en texto plano, sin aislamiento, ejecutando scripts externos sin verificar procedencia. Podés firmar el binario, pero si lo generaste con una herramienta contaminada, es como sellar un paquete de veneno con una sonrisa.
- Dependencias podridas: una librería con CVE conocida en tu package-lock. Nadie la revisa porque es transitive y ni sabés de dónde vino. El atacante sí sabe.
- Entornos inseguros: implementás una app que nunca fue escaneada como binario final. Nadie revisó el resultado real. Y ahora corre como root expuesto en internet.
Todo esto no es paranoia. Es real. Lo veo en empresas grandes, medianas, y en proyectos open source todo el tiempo.
El Build Es el Punto de Control Total: Firmalo o Sos Ciego
La compilación es tu único momento de control absoluto. Ahí sabés qué entra, cómo se transforma y qué se produce. Si en ese punto no generás provenance, si no firmás el binario y su metadata (con SLSA, cosign, Sigstore o lo que uses), después no tenés cómo demostrar que ese binario es confiable.
Y no alcanza con generar un hash. Necesitás:
- Procedencia: ¿cuándo, cómo, dónde y con qué se compiló?
- Firma del resultado: binario, SBOM, logs.
- Repositorio controlado: que nadie pueda reemplazar el binario o el release después.
Tenés que forzar builds efímeros, aislados, que no compartan caché, ni variables, ni contenedores. Nada se recicla. Todo se destruye después. Porque si no, el ataque de contaminación de build es trivial.
Código Fuente: Nunca Confíes en Lo Que No Revisaste
Acá entra algo simple pero poderoso: revisiones por pares. Leé el código. Revisá los cambios. Implementá ramas protegidas, merge requests con aprobación múltiple, herramientas como Legitify para asegurar la configuración de GitHub/GitLab. Y jamás, pero jamás, subas secretos al repo. No hay excusa. Usá pre-commit, usá truffleHog, usá GitGuardian, usá lo que sea, pero que no se filtren.
Además, el entorno del desarrollador es parte del ataque. Si tu dev tiene un plugin de VSCode con malware, listo. Se jodió todo. Fortificá los endpoints. Verificá IDEs. Auditá plugins. Si no podés controlar las estaciones de trabajo, no estás seguro.
Dependencias: La Puerta de Entrada Más Común al Infierno
Acá tenés que ser paranoico. Cada paquete, cada update, cada lib que metés puede traer el caos. Así que evaluá a tus proveedores como si fueran contratistas que entran a tu casa con mochilas que no podés revisar.
Preguntate:
- ¿Quién mantiene esa lib?
- ¿Tiene historial de CVEs sin resolver?
- ¿Responde a issues de seguridad?
- ¿Tiene versión estable o está tirada hace 2 años?
- ¿La usás en algo crítico o solo para debug?
Después, usá SBOMs. Generalos. Mantenelos. Y escanealos automáticamente con OWASP Dependency Check, OSV, Snyk, Grype, lo que se integre mejor con tu stack. No es solo escanear, es priorizar. CVEs críticos y explotables van primero. Y si hay un VEX que te dice “esto no aplica en tu contexto”, lo considerás, pero lo auditás igual.
Compilación: Donde Se Filtran los Ataques Silenciosos
Los builds tienen que estar reforzados. Red aislada, herramientas versionadas y validadas, sin accesos innecesarios. La infraestructura de firma debe ser intocable. Usá políticas de firma obligatoria. Usá controles de integridad. Auditá todo. Si usás compiladores como FRSCA, y validás con SLSA Verifier, tenés mucho ganado.
Y si vas a firmar código, firmalo bien. No uses claves compartidas. No dejes tokens tirados en variables de entorno. Firmá binarios, SBOMs, y procedencia. Si alguien te entrega un artefacto sin procedencia confiable, rechazalo. No sabés quién lo tocó.
Implementación: Nunca Supongas que el Binario Está Limpio
Una vez que tenés el binario listo, escanealo. Análisis de composición binaria. ¿Qué incluye? ¿Está limpio? ¿Se coló algo? No podés asumir que porque el código era bueno, el binario lo es. Validalo.
Y después, en producción, monitoreá. Con logs, con alertas, con análisis de comportamiento. Escaneá imágenes de contenedor, sistemas operativos, libs nativas. Mantené un inventario actualizado. Es la única forma de actuar rápido cuando un 0-day explota en tu stack.
Tu Cadena de Suministro es Tan Segura Como tu Eslabón Más Olvidado
El código fuente puede estar perfecto, pero si firmás con una herramienta comprometida, si publicás sin firmar, si el build se hizo en un runner con malware, estás frito. El desafío de la seguridad moderna no está en tu código, está en lo que usás para escribirlo, compilarlo, firmarlo, desplegarlo y mantenerlo.
No podés asegurar todo, pero sí podés minimizar el riesgo al máximo. Y eso empieza por entender la cadena completa. Desde el git clone hasta el docker push, cada paso es una oportunidad para endurecer tu sistema… o para abrirlo al desastre.
Nos vemos en la próxima entrega. Voy a cubrir cómo implementar firmemente SLSA, gestionar infraestructura de firma descentralizada, y controlar entornos de build distribuidos sin perder velocidad ni agilidad. Porque el hacker real no sólo rompe sistemas: construye sistemas que otros no pueden romper.
Cómo Enfrentar Dependencias Vulnerables con Cabeza de Hacker
Llevo años escribiendo, auditando y rompiendo software. En ese camino, aprendí que una de las formas más efectivas —y a la vez más ignoradas— de comprometer una aplicación es explotar sus dependencias. No importa si tenés un código impecable, cubierto de tests, con revisiones exhaustivas: si tu proyecto arrastra una librería vulnerable, ya perdiste. La mayoría de las aplicaciones modernas no son código propio, son wrappers sobre paquetes externos. Y si ese ecosistema falla, el tuyo también cae. Así de simple.
Hoy en día, usar dependencias es una necesidad. No vas a reinventar cada algoritmo de compresión, cliente HTTP o generador de PDFs. Pero lo que sí tenés que hacer es asumir que todas esas piezas pueden fallar, y que, cuando fallan, te salpican directamente. Lo que define la diferencia entre un sistema resiliente y uno roto es cómo gestionás ese riesgo. Por eso, en este artículo te comparto cómo pienso y actúo frente a dependencias vulnerables: casos, enfoques, y, lo más importante, qué hacer cuando no hay parche a la vista.
Cuándo el Parche Existe, Pero No Es Automático
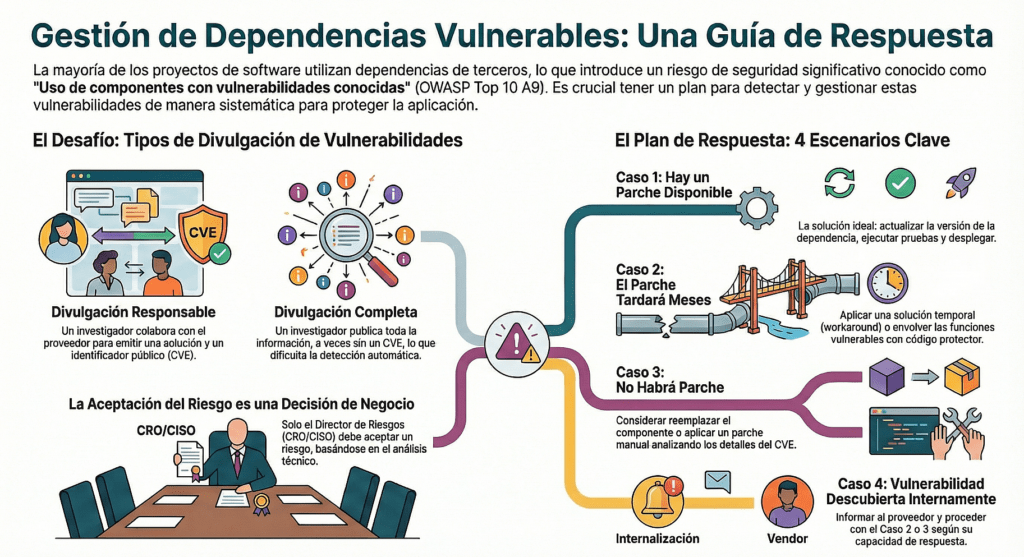
Imaginá esto: descubrís que una de tus dependencias tiene un CVE crítico. Buena noticia: hay un parche. ¿Actualizás de una? No tan rápido. Primero, verificás si tu sistema tiene tests. Tests reales. De integración, unitarios, funcionales. Si no los tenés, estás navegando a ciegas y no hay excusa. Pero si los tenés, actualizás la dependencia en un entorno de staging. Ejecutás los tests. Si todo pasa, desplegás. Si algo rompe, tenés que entender por qué. ¿Cambió la API? ¿Cambió una firma? ¿Una clase desapareció? Entonces viene el trabajo de actualizar el código y volver a testear. Esto parece básico, pero lo que más veo son equipos que actualizan sin testear, o que evitan actualizar porque les da miedo romper cosas. Eso es un caldo de cultivo perfecto para que las dependencias vulnerables vivan por años en tu código.
Cuando el Parche No Está, Pero Hay Información
Este es el terreno intermedio. Sabés que hay una vulnerabilidad, el proveedor la reconoce, pero no hay parche todavía. ¿Qué hacés? Si el proveedor colabora, lo primero que necesitás es entender la naturaleza del bug. Si te da una lista de funciones afectadas, las envolvés con validaciones. Si te da una PoC, mejor: la corrés en tu entorno para validar que la mitigación que aplicaste realmente bloquea la explotación.
Y sí, esto requiere que vos o alguien de tu equipo entienda el código, tenga skills de pentesting y sepa parchear a mano. No hay vueltas. Acá es donde la diferencia entre un equipo que sobrevive y uno que queda expuesto es clara. Los equipos que solo desarrollan features y no tienen cultura de seguridad, colapsan frente a estos casos. Por eso, documentá lo que hacés, agregá comentarios, hacé pruebas regresivas, y dejá claro que estás mitigando un CVE hasta que llegue la versión parcheada.
Cuando No Hay Parche, Ni Esperanza, Pero el Proyecto Sigue en Pie
Este es el escenario más crítico. Tenés una dependencia vulnerable. El proveedor no responde, o peor: te dice que no la va a arreglar. El CVE está ahí, público, y vos sos responsable del riesgo. ¿Qué hacés? Primero: no lo ignorás. Lo parcheás vos. Sí, aunque sea código de terceros. Forkeás la librería, arreglás el bug y hacés el merge en tu build. ¿No sabés cómo? Aprendé. Si no lo hacés, estás permitiendo que un atacante aproveche esa puerta abierta.
Después analizás todo el código que llama a esa librería. Porque no sabés si el bug está en una función que usás o no. Ahí entra el IDE, el análisis estático, el grep furioso. Buscás referencias, rastreás flujos, entendés qué inputs pueden llegar a la función vulnerable. Y parcheás a nivel de aplicación también, envolviendo llamadas, validando entradas, usando WAF si hace falta. Es un proceso tedioso, pero es mejor que estar en las noticias por haber sufrido un breach por una lib de terceros.
Vulnerabilidades Sin CVE: El Escenario Oculto
Otro escenario más peligroso todavía es cuando detectás una vulnerabilidad pero no tiene CVE. O lo detectás porque apareció en una Full Disclosure, o porque tu equipo hizo una pentest interna. En estos casos el riesgo es real, pero no lo vas a ver en ninguna herramienta de escaneo automatizado. Tenés que actuar como si fuera un 0-day. Informás al proveedor, sí, pero no esperás su respuesta. Aplicás las mismas técnicas del caso anterior: parcheo manual, validaciones, tests, mitigación y documentación.
Lo más importante acá es tener trazabilidad. Tenés que dejar registro de todo: qué se detectó, cómo lo mitigaste, qué versión del componente lo contiene, cómo se reproduce, y si tu solución es temporal o permanente. Esto no solo te salva en lo técnico: también te protege legalmente. Cuando las cosas se rompen, tener pruebas de que actuaste responsablemente hace toda la diferencia.
Las Herramientas No Piensan, Pero Te Aceleran
Acá no hay magia. Las herramientas te ayudan, pero vos tenés que pensar. Dependency Check, OWASP Dependency-Track, Snyk, Xray, Renovate, CycloneDX, todas son útiles. Pero solo si sabés cómo usarlas. Una herramienta que no está integrada al CI/CD no sirve. Una alerta que nadie lee es inútil. Un SBOM que nadie escanea es solo bloat. Integrá, automatizá, y sobre todo: analizá.
Yo uso Dependency-Check en todos los builds. En los pipelines, no local. Y no solo para Java: también lo meto con wrappers para Node, Python y C++. Y si tengo componentes críticos, uso CycloneDX para SBOMs firmadas y Dependency-Track para monitorear en producción qué versión está corriendo. No hay excusas. Todo esto es libre, gratuito y usable hoy.
Las Dependencias Son Tu Problema, No el del Proveedor
No importa si la lib es de un tercero. No importa si el bug es conocido. Si está en tu sistema, es tu problema. Vos sos responsable. Como hacker y programador, tenés que pensar siempre en cómo lo rompería yo, y cómo lo parcharía yo, aunque el código no sea tuyo. Si no asumís esa mentalidad, estás en peligro constante.
Así que la próxima vez que tu herramienta de escaneo te tire un CVE, no lo silencies. Investigalo. Atacalo. Mitigalo. Y si nadie más lo hace, arreglalo vos. Porque si tu sistema depende de una cadena, y esa cadena está podrida, el único que puede salvarla sos vos.
Parcheo virtual como contramedida táctica frente a vulnerabilidades web
Cuando se trabaja en ambientes productivos reales, donde el costo del downtime puede significar miles de dólares por minuto, las soluciones que dependan de modificar código fuente, compilar, desplegar y validar cambios son directamente inviables en el corto plazo. Por eso, una técnica que uso con frecuencia para contener vulnerabilidades conocidas mientras se planifica una solución definitiva es el parcheo virtual. A esta altura ya no lo considero una opción alternativa, sino una herramienta esencial dentro del stack de seguridad ofensiva y defensiva de cualquier infraestructura seria. Aun así, noto que muchos equipos no la aplican correctamente, o ni siquiera la conocen. Así que voy a desglosar en este artículo cómo funciona, cuándo la uso, por qué la uso y qué errores evitar.
Entendiendo el parcheo virtual desde el enfoque realista
La idea del parcheo virtual parte de un principio fundamental: no todas las organizaciones pueden modificar su código fuente en tiempos razonables. Muchas veces se trata de aplicaciones legacy sin mantenimiento, productos de terceros cerrados, código que depende de otros componentes críticos, o simplemente procesos internos que requieren semanas de QA antes de liberar algo. En esos escenarios, yo no espero. El riesgo se mitiga en tiempo real. ¿Cómo? Insertando una capa de control que actúe antes de que el tráfico llegue al backend, interceptando los vectores de ataque conocidos.
Esta capa puede ser un WAF, un reverse proxy con reglas específicas, un IDS con capacidad de bloqueo, o incluso un módulo embebido como ModSecurity. Lo importante es que actúe en la capa 7, con visibilidad completa del protocolo HTTP/HTTPS, de los parámetros y de los headers. Una vez que intercepta, debe tomar decisiones en tiempo real: bloquear, loguear, redirigir, o lo que corresponda.
No es reemplazo del parche real, pero sí es defensa de primera línea
Esto lo digo cada vez que entreno a un equipo nuevo: el parche virtual no reemplaza la solución real. Es una mitigación. Sirve para ganar tiempo, evitar que el atacante se aproveche de la ventana de exposición, y sobre todo, para proteger mientras se prepara el fix verdadero. Pero nunca se debe confiar en que esa protección es infalible o permanente. Lo veo como una defensa perimetral ajustada a contexto: se adapta al vector, al payload, al protocolo, a la versión específica vulnerable.
Ahora bien, ¿cómo se implementa? Primero hay que tener clara la vulnerabilidad. Nada de andar bloqueando por intuición o por lo que se leyó en Twitter. Me gusta tener el CVE, si está disponible, o un POC que demuestre con precisión qué se puede explotar y cómo. A partir de eso, empiezo a analizar el tráfico: cómo luce una request legítima, cómo luce una request maliciosa, qué parámetros están involucrados, qué codificaciones puede usar el atacante para evadir filtros comunes. Uso siempre herramientas que permiten inspeccionar el tráfico en crudo y con decodificación activa.
Herramientas para inspección profunda y generación de reglas
El stack varía, pero en mi flujo de trabajo personal no puede faltar Burp Suite para análisis dinámico, junto con tcpdump o Wireshark si quiero ir al bajo nivel. Para generación de reglas, uso principalmente ModSecurity con su lenguaje de reglas robusto. Tiene operadores lógicos, validación de tamaño de campos, normalización de inputs, y sobre todo, persistencia de variables por sesión. Eso me permite detectar cosas que no se ven en una sola request, como fuerza bruta, bypasses de lógica, o explotación en varias etapas.
A veces también uso un WAF comercial como F5, Imperva o Cloudflare, dependiendo del cliente, pero siempre valido que me den control granular sobre las reglas. No sirve de nada un WAF que bloquea genéricamente “todo lo que parece raro” pero no permite afinar por parámetro, path o payload.
El arte de crear reglas que no bloqueen lo que no deben
Acá es donde entra la parte que más respeto del parcheo virtual: evitar los falsos positivos. No hay nada más frustrante que una regla que bloquea tráfico legítimo. El usuario se queja, el cliente se enoja, y la seguridad pierde credibilidad. Por eso, la prioridad siempre es evitar falsos positivos, incluso por encima de evitar falsos negativos. Es mejor dejar pasar un intento de ataque que bloquear al usuario real. Esa es una regla de oro que aprendí con muchos golpes.
¿Cómo se logra? Probando. Haciendo fuzzing, variando el input, validando que la regla solo se active cuando se cumplan TODAS las condiciones del exploit. Para eso, cuando tengo un payload malicioso, lo desarmo, lo modifico campo por campo, y veo qué parte es necesaria para que el ataque tenga éxito. Ese conocimiento me permite escribir reglas específicas, no genéricas, que capturan el ataque sin afectar al tráfico normal.
Y sí, a veces hay que aplicar modelos de seguridad positiva, donde se define explícitamente lo que se acepta, y se bloquea todo lo demás. Es más costoso, pero para endpoints críticos, es lo mejor que podés hacer.
Integración con pipelines de desarrollo y seguimiento de parches
Otra práctica que siempre recomiendo es integrar el análisis de parches virtuales en el pipeline de desarrollo. Las reglas del WAF deben estar versionadas, con changelog, con control de calidad, con seguimiento de auditoría. No pueden quedar como “parches hechos en producción y olvidados en algún lugar del reverse proxy”. Cada vez que se aplica un parche real en el código, hay que revisar si las reglas del parche virtual siguen siendo necesarias. Si no, se eliminan. Mantener reglas innecesarias solo agrega complejidad y riesgo.
Además, documentar. Cada regla tiene que tener su justificación: qué vulnerabilidad mitiga, qué condiciones activa, en qué endpoints aplica. Esto es clave cuando el equipo cambia, cuando pasan los meses, o cuando hay que escalar a un proveedor.
Casos reales donde el parcheo virtual me salvó el cuello
Recuerdo un proyecto donde una biblioteca de terceros usaba una versión antigua de Apache Commons FileUpload, vulnerable a ejecución remota. No podíamos cambiar la librería sin romper compatibilidad. Tampoco había parche. La solución fue aplicar una regla en el WAF que bloqueaba cualquier multipart/form-data con boundary mal formado. Se desplegó en producción en menos de una hora, con logging agresivo y validación completa. Tres semanas después, apareció un exploit público para esa misma librería. La regla ya estaba activa. Nos salvó.
Otro caso fue con una aplicación vieja de PHP con inyección SQL en un endpoint olvidado. ModSecurity detectaba “union select” y “information_schema”, pero bastó que un atacante cambiara el casing y usara comments para evadirla. Reescribí la regla para normalizar el input antes de evaluarlo, y solo así empezó a detectar la evasión. En menos de 48 horas, bajamos los incidentes de WAF de 200 a 3 por día.
Reflexión final
El parcheo virtual no es magia, pero cuando se usa bien, puede hacer la diferencia entre ser vulnerable y tener el control. Como todo en seguridad ofensiva, se trata de conocer a fondo la aplicación, entender el riesgo real, y actuar rápido pero con precisión. No se trata de bloquear todo, se trata de saber exactamente qué bloquear y cuándo. Y si no podés tocar el código, entonces el parche virtual es tu mejor aliado.
El arte del parcheo virtual como mecanismo defensivo efectivo
En más de veinte años metido en el juego del hacking ofensivo y defensivo, he visto pasar modas, tecnologías, mitos y técnicas. Pero hay algo que sigue siendo brutalmente útil: los parches virtuales. El parcheo virtual no es una solución definitiva, ni pretende serlo. Es una forma táctica, efectiva y muchas veces urgente de contener una vulnerabilidad antes de que se convierta en una catástrofe. En ambientes reales, donde el código no se puede tocar por restricciones de tiempo, procesos burocráticos, equipos tercerizados o simplemente porque el código es basura heredada que nadie se anima a modificar, el parcheo virtual aparece como ese comodín que te permite seguir respirando sin caer fulminado por un exploit recién salido del horno. Lo uso, lo recomiendo y lo considero esencial para cualquier defensor que realmente entienda lo que es proteger una superficie expuesta 24/7 al caos de internet.

¿Qué es un parche virtual realmente?
Muchos lo definen como una capa de políticas de seguridad que intercepta y bloquea intentos de explotación en tiempo real. Yo lo veo como una inyección de realidad en entornos donde esperar un fix en el código es un lujo. El parche virtual se planta entre el atacante y la aplicación, analiza el tráfico, busca patrones maliciosos, y actúa antes de que el payload toque una línea del backend. La ventaja es inmediata: no se modifica el código, no hay riesgo de romper nada en producción, y se implementa a velocidad de respuesta. Funciona porque analiza el tráfico HTTP/HTTPS en tránsito, detecta intentos de inyección, XSS, traversal, RCE o lo que se venga, y lo frena ahí mismo. ¿La clave? Saber escribir reglas buenas. Un parche mal hecho te bloquea usuarios reales o deja pasar ataques, y ahí sí estás frito. Este tipo de solución se puede montar con un WAF como ModSecurity, o incluso con plugins más livianos que corren embebidos en servidores web o como filtros a nivel de aplicación. En cualquier caso, se trata de ingeniería defensiva aplicada con precisión quirúrgica.
Por qué no podés depender siempre del código fuente
Mirá, arreglar el código siempre es la mejor opción. Nadie lo niega. Pero viví suficientes implementaciones para saber que eso rara vez ocurre a tiempo. Tenés equipos sobrecargados, sistemas legados escritos en lenguajes de mierda sin mantenimiento, aplicaciones compradas a terceros, desarrollos tercerizados sin contrato de soporte, y decisiones políticas que priorizan features sobre seguridad. En este contexto, corregir el código es un deseo. Aplicar un parche virtual es lo que hacemos los que estamos del lado operativo cuando suena la alarma. Y no me importa que el código no sea mío. Yo puedo ponerme entre el atacante y la app, inspeccionar su intento de ataque y desactivarlo sin tocar una línea del repo. Esa es la fuerza del parcheo virtual. Me permite proteger mientras el equipo de desarrollo juega con su ciclo de release cada seis meses.
Cómo construir un parche virtual eficaz sin morir en el intento
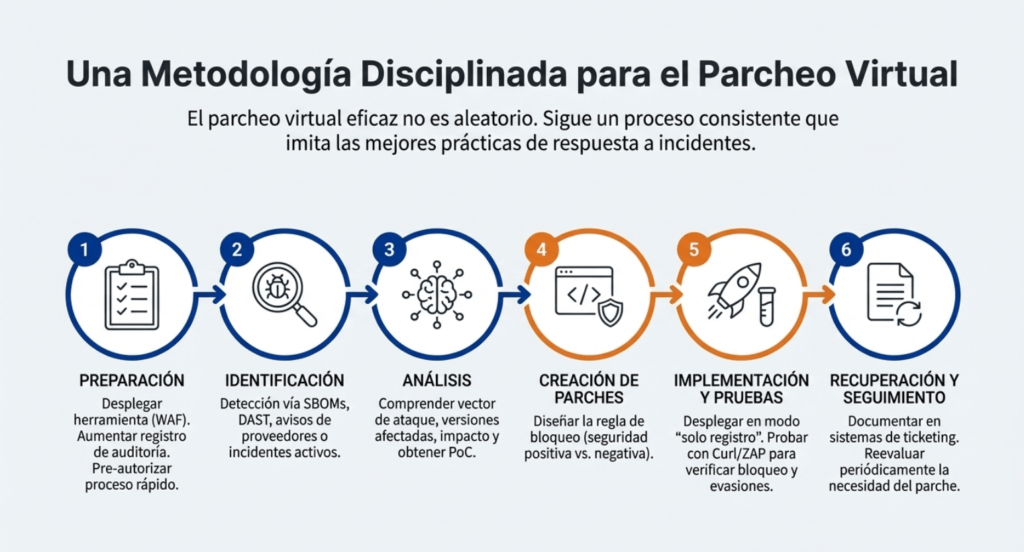
Todo parte de una metodología clara. Esto no es poner una regla de «bloquear cualquier cosa que diga SELECT» y listo. Eso lo hace un junior y termina matando media app por falsos positivos. Un parche bien construido se crea después de un proceso metódico que empieza en la preparación, sigue con la identificación y análisis de la vulnerabilidad, y termina con la creación de la regla, sus pruebas, su implementación, y su seguimiento. En la preparación tenés que tener todo armado antes de que explote la bomba: WAF instalado y listo, ModSecurity con logging completo, integración con tu sistema de tickets, alertas de CVEs, y autorización preaprobada para aplicar reglas en caliente. Si estás en producción y no tenés nada de eso, mejor rezá porque te agarre un bug menor. En la identificación, podés estar en modo proactivo (pen test, análisis de código, escaneos) o reactivo (divulgación pública, alerta del proveedor, incidente real). Cuando llega el momento, analizás la vulnerabilidad, entendés su comportamiento, su explotación, qué configuraciones la activan, qué payloads la gatillan. Y a partir de ahí, empezás a diseñar el parche.
Parche de lista blanca: el más robusto
Si me das a elegir, siempre voy por el modelo de seguridad positiva. Lista blanca. Porque me da control total. Defino qué es válido y todo lo que no encaje, se bloquea. Pero eso implica trabajo: revisar logs, entender formatos válidos, analizar cada parámetro, conocer los rangos válidos de cada input. Por ejemplo, si sé que el parámetro reqID en una URL solo acepta números enteros, entonces armo una regla que diga: si no es un número, afuera. En ModSecurity eso es simple pero poderoso. Una regla bien escrita no solo frena el ataque sino que te ayuda a detectar variaciones futuras. Pero tené cuidado: si no sabés lo que hacés, podés bloquear tráfico legítimo. Siempre implemento primero en modo “detection only” (solo log) para ver si hay falsos positivos. Recién después lo paso a “blocking”.
Parche de lista negra: rápido, pero peligroso
El modelo negativo (lista negra) también tiene su lugar, sobre todo cuando necesitás reaccionar en segundos y ya tenés el payload del exploit. Pero no es infalible. Por ejemplo, si tu regla bloquea cualquier UNION SELECT, un atacante te la puede evadir con una codificación alternativa, espacios, comentarios, fragmentación o mil técnicas que conocemos. Por eso, usalo como contención inicial, pero andá planeando algo mejor. No caigas en la trampa de escribir parches específicos para cada exploit. Eso es cortoplacismo puro. Bloquear <script>alert(‘XSS’)</script> puede frenar ese ataque puntual, pero deja abierta toda la superficie para otras variaciones. En vez de bloquear una carga específica, aprendé a reconocer patrones estructurales que definen el ataque. Eso es lo que hace un buen parche.
Parcheo automatizado: escalando como se debe
Cuando el número de vulnerabilidades crece, no hay forma de escribir cada regla a mano. Por eso existen herramientas que te automatizan parte del proceso. Por ejemplo, ThreadFix puede importar escaneos en XML y generar reglas de ModSecurity para vos. OWASP CRS también tiene scripts que hacen esto, y muchos WAF comerciales ya ofrecen integración directa con herramientas de escaneo. Lo importante acá es validar el output. Las reglas generadas automáticamente pueden servir como base, pero siempre tienen que pasar por tus ojos antes de entrar en producción. Y si no las entendés, no las uses. Un parche que no sabés cómo funciona es un riesgo peor que el exploit que intenta bloquear.
Cómo probar un parche como un profesional
Acá no alcanza con decir “ya está implementado”. Hay que testear. Siempre. Y no solo desde un navegador. Curl, Wget, ZAP, Burp, Postman… usá lo que sea para reproducir el ataque original y verificar que no pasa. Revisá los logs de ModSecurity en modo debug. Aumentá el nivel de logging solo para tu IP si querés evitar ruido. Mirá cómo la regla se ejecuta, si matchea lo que tiene que matchear, si bloquea lo que debe bloquear, y si no jode el tráfico legítimo. Un parche que bloquea todo sirve solo para una cosa: arruinarte el uptime. Por eso, siempre empiezo con la regla en modo detección, veo cómo se comporta durante unos días, y si no hay falsos positivos, la paso a modo bloqueo.
Después del parche: nunca te olvides del seguimiento
Aplicar el parche no es el final. Es el inicio de una nueva etapa. Hay que documentarlo. Crear el ticket correspondiente, asociarlo con la vulnerabilidad, registrar los IDs de las reglas, y generar métricas de tiempo de respuesta. También tenés que revisar periódicamente si esa regla sigue siendo necesaria o si el código fuente ya fue parcheado correctamente. Muchas veces el parche virtual se queda ahí por años, nadie lo toca, nadie sabe por qué existe, y termina generando conflictos innecesarios. Hay que limpiar, auditar y mejorar. Si la vulnerabilidad ya no existe, el parche debería poder eliminarse. Y si no, por lo menos deberías saber por qué sigue ahí.
La evaluación de software de código abierto con mentalidad hacker
Una de las decisiones más críticas en cualquier arquitectura moderna es elegir correctamente las dependencias de software que vamos a incorporar al sistema. En el mundo real, esto se traduce en tomar una decisión de riesgo: ¿este proyecto de GitHub que parece inofensivo va a comprometer toda tu infraestructura sin que lo veas venir? A lo largo de los años, aprendí que no basta con que algo tenga muchas estrellas, o que lo use Google o Meta. El código abierto es una caja de Pandora. Puede ser brillante, seguro, mantenido y limpio. O puede ser una trampa perfecta para que un atacante se meta en tu sistema sin disparar una sola alarma. Lo que sigue es mi propio enfoque, basado en años auditando código, desarrollando exploits y diseñando pipelines automatizados de validación de dependencias OSS, con una mirada práctica y orientada a seguridad ofensiva y defensiva.
¿Realmente necesitás esa dependencia?
Antes de incluir un proyecto externo, me pregunto si realmente lo necesito. Todo lo que agregues puede ser una puerta trasera futura. Así de simple. Cada línea de código que no escribiste vos es una línea que no entendés del todo. La primera pregunta que me hago es: ¿esto lo puedo hacer con algo que ya tengo? Si no, ¿hay una librería más minimalista? Solo después de agotar esas opciones paso a analizar el proyecto externo.
Ahí arranca la verificación de autenticidad. Nunca me fío de nombres. El typosquatting es un clásico y sigue funcionando. Los atacantes crean paquetes casi idénticos a los originales, con nombres como requet en vez de request, o expresss con una s de más. También busco bifurcaciones sospechosas o proyectos clonados con cambios mínimos y actividad reciente. El código malicioso no siempre se esconde en líneas confusas, a veces está en un simple postinstall que hace una llamada curl y se baja un binario desde un servidor random. Si te dormís, te vacían los secretos del sistema sin que te enteres.
El mantenimiento y la actividad real
No hay nada más peligroso que una dependencia muerta. Si un paquete no recibe commits en un año, ya no existe. Murió. Y si lo usás igual, estás comprometiendo todo el stack. Yo exijo señales de vida: confirmaciones, issues resueltos, releases estables, mantenedores activos, diversidad en los contribuidores. Cuando veo que todo lo mantiene un solo tipo, me pregunto: ¿qué pasa si se aburre mañana? O peor aún: ¿qué pasa si su cuenta de GitHub se compromete y un atacante mete código malicioso?
Hay que revisar también si el código está en una versión pre-1.0, si usa etiquetas como beta, si rompe compatibilidad sin anunciarlo. Todo eso me da una idea clara del nivel de madurez. Y claro, si nadie más lo usa, entonces probablemente vos vas a ser el primero en descubrir sus bugs. No es algo para festejar. La popularidad por sí sola no garantiza nada, pero la falta total de adopción me hace poner el freno.
Seguridad: la gran deuda del open source
Acá es donde me pongo más paranoico. Reviso si tienen algún tipo de badge de seguridad de OpenSSF o si siguen prácticas de desarrollo seguro. No es lo común. Muy pocos proyectos implementan validación rigurosa de entradas, o usan herramientas de análisis estático en serio. Y la mayoría no tiene una política pública de seguridad ni instrucciones para reportar vulnerabilidades. Eso es una bandera roja enorme. Un proyecto serio publica su «coordinated disclosure policy» y tiene un equipo listo para responder rápido. Si encontrás un bug crítico y te ignoran por días, ya sabés cómo va a terminar eso.
Para mí, todo lo que no tenga una auditoría de seguridad real —interna o externa— es sospechoso. No me importa si es chico o si lo usa una FAANG. Sin pruebas, sin herramientas de escaneo, sin revisión de terceros: es un riesgo, punto.
Verificación de la interfaz y su diseño seguro
En mis pruebas busco APIs que no sean trampas. Lo primero que chequeo es si forzan el uso seguro por defecto. ¿Admiten consultas parametrizadas? ¿El ejemplo de «cómo usar» incluye validación? ¿El modo por defecto deja habilitada la administración sin autenticación? Vos no deberías tener que ser un experto en seguridad para usar un paquete de forma segura. El diseño seguro se trata de eso: proteger incluso al desarrollador novato.
Si el software se comunica por red, debería cifrar por defecto. Si no lo hace, ni lo toco. Además, tiene que tener documentación clara sobre cómo usarlo sin volarte una pierna. Y si no puedo reportar un fallo fácilmente, es otra razón para descartarlo.
El infierno de las dependencias invisibles
Los árboles de dependencias son como los paquetes de muñecas rusas: nunca sabés hasta qué profundidad te están metiendo código extraño. Por eso analizo cada dependencia nueva en un entorno aislado, mido el impacto que tiene, y reviso si agrega cosas innecesarias. Muchos paquetes traen decenas de librerías indirectas, a veces hasta con código compilado que no podés auditar. No me importa si usan WebAssembly, Rust o lo que sea, si no tengo control sobre eso, me mantengo lejos. Ejecuto pruebas en sandbox, miro qué archivos toca, si abre sockets raros, si exfiltra variables de entorno como AWS_SECRET_ACCESS_KEY, y si hace llamadas sospechosas.
Cómo evalúo el código: más allá de los linter
Leo el código. Punto. No todo, pero sí lo suficiente como para ver si hay banderas rojas: muchos TODO, código ofuscado, funciones que hacen demasiado, falta de sanitización, uso de eval o exec. Me interesa ver si los tipos detrás del proyecto pensaron en la seguridad desde el principio. Valido si hay tests, si los pasan, si usan CI/CD, y si hacen análisis estático. También corro herramientas como semgrep y gosec para ver si salta algo interesante. Es raro encontrar OSS que pase todo limpio.
También reviso si el proyecto tiene historial de vulnerabilidades, si fue explotado antes, cómo reaccionaron, cuánto tardaron en arreglarlo. Todo eso me da un patrón de comportamiento. Algunos ignoran todo hasta que alguien los expone en Twitter. Otros parchean en 24 horas. Y esa diferencia puede valer millones.
Compilación segura: el nuevo mínimo
Hoy nadie debería confiar en binarios publicados si no tienen procedencia verificable. Si no podés reconstruir exactamente lo mismo a partir del código fuente, algo está mal. Acá entra todo el modelo de SLSA (Supply-chain Levels for Software Artifacts). Me fijo si el software fue compilado con plataformas seguras, como GitHub Actions, Google Cloud Build, etc. Y si su procedencia (provenance) es generada automáticamente, firmada, y aislada.
Los niveles SLSA son clave: nivel 1 asegura trazabilidad básica; nivel 2 agrega autenticidad mediante firmas; y nivel 3 exige aislamiento completo, donde nadie del equipo puede alterar los pasos de build. Esto es lo que separa un build reproducible de un binario peligroso. Lo aplico tanto en proyectos externos como en mis propios artefactos.
Confiá solo en lo que podés controlar
La seguridad en el software libre no es un derecho, es una responsabilidad. No podés asumir que todo lo que está en GitHub es seguro, ni que porque algo tenga 1000 forks es confiable. Cada dependencia es una amenaza latente. Evaluarlas no es opcional. Es un paso obligado si querés sobrevivir en un entorno donde los atacantes no duermen.
Mi proceso es paranoico, sí. Pero después de años viendo cómo entran los APT, cómo se infectan paquetes NPM y cómo se comprometen cadenas de suministro completas, te puedo asegurar que es la única forma de mantenerte un paso adelante. Y en este juego, el que se duerme, pierde.

Fortaleciendo la cadena de suministro de software como hacker
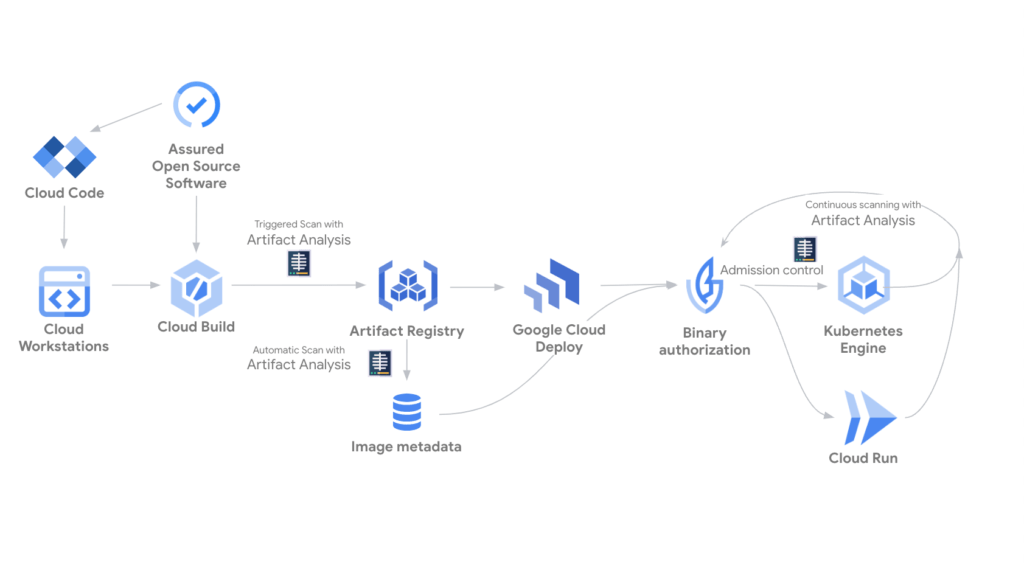
Desde mi experiencia como hacker y programador, he aprendido que asegurar una cadena de suministro de software no es solo una cuestión de buenas prácticas o cumplimiento de normas; es una necesidad crítica. El software que usamos todos los días, desde una simple librería de NPM hasta una imagen de contenedor compleja desplegada en producción, puede ser la puerta de entrada para un atacante si no se controla cada paso de su creación y distribución. Google Cloud, como muchos otros proveedores, está apostando fuerte a resolver este problema y ofrece una serie de herramientas modulares que, si se integran correctamente, pueden reforzar cada punto de la cadena.
La cadena de suministro no es un concepto abstracto, es real y está bajo ataque constante. La vemos cada vez que se filtra una credencial, cuando una dependencia se introduce con código malicioso o cuando un build compromete la seguridad por una configuración negligente. Y aunque muchas veces los exploits son sofisticados, el 90% de las veces el vector es un descuido: una estación de trabajo mal protegida, un commit directo a main sin revisión o una imagen de contenedor construida con un apt install sin versión fija.
El entorno de desarrollo: primera línea de defensa
La seguridad empieza en la estación de trabajo del desarrollador. Un entorno inseguro ahí significa que cualquier código que se escriba, incluso con las mejores intenciones, puede ser manipulado o interceptado. Google propone Workstations para resolver esto, pero el concepto es más importante que la herramienta: aislar el entorno, aplicar políticas estrictas, eliminar accesos innecesarios y auditar constantemente. La clave es entender que un desarrollador no trabaja solo, y que su máquina es parte del sistema. No se puede confiar en un entorno local sin control.
Desde el punto de vista ofensivo, atacar la máquina de un desarrollador es el camino más silencioso y efectivo para infiltrarse en una empresa. No necesitas vulnerar una infraestructura gigantesca si podés meter una backdoor en una dependencia que luego se sube a producción desde el escritorio de alguien distraído. De ahí la importancia de proteger cada entorno como si fuera una entrada directa al sistema.
Artefactos, compilaciones y procedencia: control absoluto del código
Cada línea de código que llega a producción debe estar verificada, firmada y trazada. El concepto de procedencia no es nuevo en seguridad, pero con SLSA y la presión del entorno actual se volvió obligatorio. Un artefacto sin procedencia es un código sospechoso, punto. Y si no podés demostrar de forma automática cómo se compiló, con qué dependencias y en qué entorno, entonces no sabés qué estás ejecutando.
Cloud Build en combinación con Artifact Registry y las capacidades de análisis automático permiten crear un entorno donde cada paso se registra, se valida y se audita. Pero eso no sirve de nada si no se configura correctamente. He visto pipelines enteras firmadas por claves comprometidas, imágenes mal etiquetadas o builds realizados por scripts cargados desde fuentes desconocidas. Si sos un atacante, lo primero que vas a buscar es un CI/CD que confíe ciegamente en un script de build sin autenticación ni aislamiento. Y los hay a montones.
Ejecutando código con seguridad: el runtime como última barrera
El runtime es el punto final, pero no el menos importante. Ejecutar código inseguro es un error catastrófico, pero hacerlo sin control de versiones o sin políticas de ejecución lo transforma en una bomba de tiempo. En entornos como GKE o Cloud Run, la visibilidad sobre la imagen, su procedencia y sus vulnerabilidades conocidas puede marcar la diferencia entre un incidente menor y una brecha masiva. La autorización binaria no es solo una herramienta: es una política de vida. Si algo no fue auditado, no se ejecuta. Así de simple.
No podemos seguir desplegando imágenes desde Docker Hub sin control, aceptando rangos de versión abiertos o dependencias no verificadas. Cada contenedor debe ser tratado como código, con los mismos niveles de análisis, revisión y firma. Y si no tenés visibilidad sobre qué vulnerabilidades existen en tus servicios en ejecución, entonces no tenés seguridad.
Amenazas reales, ataques silenciosos
Los vectores de ataque en la cadena de suministro no son teóricos. Lo que se documenta como amenazas A, B, C o D son simplemente formas organizadas de describir técnicas que vemos en el mundo real: desde inyectar código malicioso en una dependencia transitiva hasta comprometer el sistema de control de versiones con un token robado. Y eso es solo el comienzo.
Hay amenazas más sutiles, como la inclusión de una dependencia que parece legítima pero que viene desde un fork sospechoso. O una pipeline que permite ejecución arbitraria por configuración permisiva. O una imagen firmada, pero compilada con un entorno comprometido. El atacante que entiende estas dinámicas no va a lanzar un ataque ruidoso, va a esperar a que se acumulen los errores y va a aprovechar el más débil.
Seguridad progresiva: el modelo de queso suizo
Uno de los principios más sólidos de seguridad defensiva es asumir que cada capa puede fallar. El modelo de queso suizo lo ilustra perfecto: no importa que tan fuerte sea una defensa si todas las capas tienen pequeños agujeros alineados. Lo que propone Google, y que yo aplico en todos mis proyectos serios, es un enfoque progresivo: empezás asegurando el origen (estación de trabajo, control de versiones), después la compilación (pipeline segura, procedencia), luego la distribución (artifact registry, validación de firma) y por último el entorno de ejecución (runtime con políticas estrictas).
No necesitas llegar al nivel 3 de SLSA mañana, pero sí necesitas empezar hoy. Porque el atacante ya empezó. Porque alguien ya está mirando tu repositorio público, revisando tus scripts de instalación, probando tus endpoints expuestos. Y si le dejás una puerta abierta, va a entrar.
Dominá tu cadena o te dominarán
La cadena de suministro es tu responsabilidad. No podés delegarla ni confiar en que todo lo que viene desde afuera es seguro. Como hacker, sé que la forma más efectiva de comprometer un sistema no es romperle el perímetro, sino infiltrarme en su código, su proceso o su cultura. Por eso, asegurar cada paso del ciclo de vida del software es la única forma de mantener el control.
Llevo más de dos décadas desarrollando y atacando sistemas. Y si hay algo que aprendí es que la seguridad no se improvisa. Se diseña. Se implementa. Y se audita. Porque si no lo hacés vos, lo va a hacer otro. Y no va a ser para ayudarte.
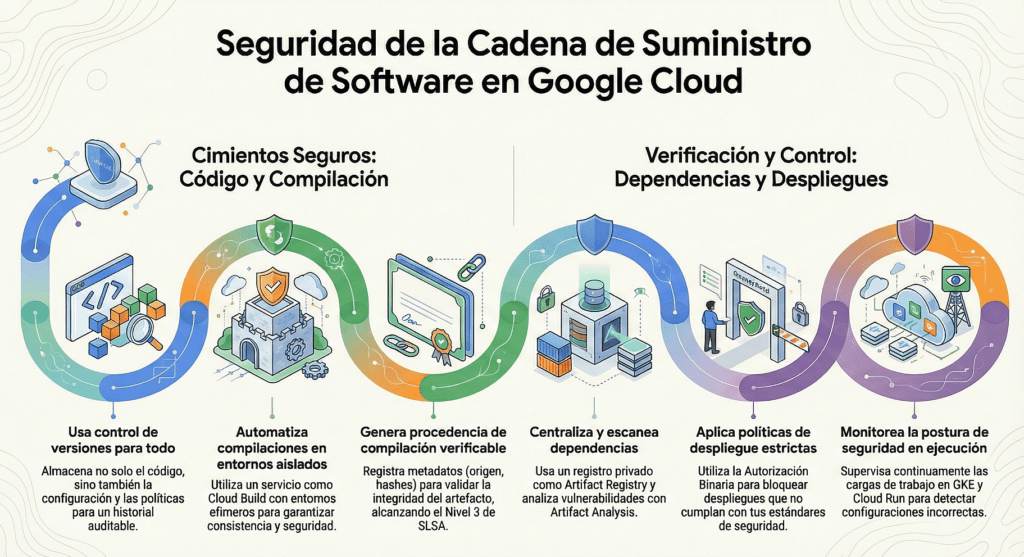
Comparativa de rutas para compilar, implementar y consultar estadísticas de seguridad
| Ruta | Entorno destino | Visibilidad de seguridad | Automatización | Nivel SLSA alcanzado | Tipo de vulnerabilidades | Dificultad |
| 1. Cloud Build + Artifact Registry (sin despliegue) | Solo compilación y contenedor en Artifact Registry | Alta: panel de seguridad post-compilación (SLSA, CVEs, SBOM, procedencia) | Media (build + análisis) | 3 | CVEs en artefactos de build | Fácil |
| 2. Cloud Run + Cloud Deploy | Cloud Run (serverless) | Alta: seguridad de imagen + entorno de ejecución (identidad, cifrado) | Alta (build, deploy y promoción automatizados) | 3 | CVEs + identidad + SBOM | Media |
| 3. GKE (Autopilot) + Cloud Deploy | GKE dev / prod | Muy alta: análisis OS-level + SBOM + procedencia + CVEs por cluster | Alta (build, deploy, promoción, panel postura) | 3 | CVEs OS-level, librerías, dependencias | Alta |
Componentes comunes en todas las rutas
- Compilación con Cloud Build: genera metadatos de procedencia automáticamente.
- Artifact Registry: almacén central de imágenes con escaneo automático.
- SBOM generada con gcloud artifacts sbom export: disponible tras cada build.
- Nivel SLSA visible en consola.
- Seguridad integrada en el panel de estadísticas.
Detalles de seguridad que puedes auditar (o atacar si fueras ofensivo)
| Elemento | Qué permite | Riesgo si está mal configurado |
| Procedencia | Demuestra que el artefacto proviene de un pipeline confiable | Sin firma → se puede suplantar el origen |
| SBOM | Muestra todos los paquetes y dependencias | Si está incompleto → ciega a herramientas de análisis |
| VEX / Vulnerabilidades | Indica si una CVE afecta o no a la app | Sin enriquecimiento → muchos falsos positivos |
| IAM mal configurado | Permite que servicios lean, publiquen o desplieguen | Escalación lateral, exfiltración o inyección |
| Cloud Build sin control | Permite builds arbitrarios desde PRs | Inyección de código en etapa de CI |
| Artifact Registry abierto | Expone imágenes a terceros | Reutilización maliciosa o análisis previo |
Comandos clave por ruta
Ruta 1: Solo compilación
gcloud builds submit –config=cloudbuild.yaml –region=us-central1
gcloud artifacts sbom export –uri=us-central1-docker.pkg.dev/$PROJECT_ID/containers/java-guestbook-backend:quickstart
Ruta 2: Cloud Run con Cloud Deploy
gcloud deploy apply –file cloudrun.clouddeploy.yaml
gcloud deploy releases create test-release-007 \
–delivery-pipeline=cloudrun-guestbook-backend-delivery \
–skaffold-file=cloudrun.skaffold.yaml \
–images=java-guestbook-backend=…:quickstart
Ruta 3: GKE + Cloud Deploy
gcloud container clusters create-auto dev-cluster …
gcloud deploy releases create guestbook-release-001 \
–delivery-pipeline=guestbook-app-delivery \
–images=java-guestbook-backend=…
Paneles de seguridad visibles
| Panel | Dónde aparece | Qué muestra |
| Security Insights (Build) | Cloud Build > Compilaciones | Nivel SLSA, vulnerabilidades, SBOM, procedencia |
| Cloud Deploy – Security Tab | Entrega > Versiones > Artefactos | CVEs en imágenes, identidad, SBOM |
| GKE Postura de seguridad | GKE > Postura de seguridad | CVEs de SO por carga, paquetes afectados |
Recomendaciones prácticas
- Build reproducible y firmado: Añade firma con Cosign a cada imagen.
- Verificación de SBOM: Haz fallar el pipeline si no se genera el SBOM.
- Auditoría en línea: Usa gcloud artifacts sbom export + análisis con Grype/Snyk.
- Permisos mínimos: Aplica least privilege entre cuentas de servicio (Build ↔ Registry ↔ Deploy).
- Split de proyectos: Usa proyectos separados para producción, builds y testing, con políticas cruzadas.
Desde el lado ofensivo: ¿Dónde buscar vulnerabilidades?
- SBOM incompleta o desactualizada → permite ocultar dependencias maliciosas.
- Imágenes sin procedencia → posibles inyecciones de malware prefirmado.
- IAM permisivo entre servicios → roles/editor, roles/owner, etc. mal asignados.
- Build pipeline sin validación de PRs o firmas → ejecución arbitraria.
- Repositorios públicos sin control de acceso → permite «supply chain poisoning».
¿qué ruta elegir?
- 🟢 Ruta 1 (solo build): Ideal para proyectos internos o como primer paso.
- 🟡 Ruta 2 (Cloud Run): Perfecto para despliegue rápido y seguro en serverless.
- 🔴 Ruta 3 (GKE): Potente para cargas complejas, pero requiere expertise y control detallado.
Pro tip: Combina todas si puedes. Usa Ruta 1 como base, Ruta 2 para despliegues ágiles y Ruta 3 para workloads críticos o legacy containerizados.
Blindando la cadena de suministro de software: el verdadero campo de batalla digital
Hoy en día, hablar de seguridad en el desarrollo de software ya no se trata solo de cerrar puertos, usar HTTPS o aplicar actualizaciones de paquetes. La verdadera guerra se libra mucho antes de que tu aplicación esté en producción. Se pelea en cada paso que da el código desde su concepción hasta que llega al usuario final. La cadena de suministro de software se ha convertido en uno de los blancos favoritos de los atacantes. ¿Por qué? Porque un eslabón comprometido basta para colapsar toda la infraestructura.
No importa si usás servicios cloud como Google Cloud, AWS o Azure. Si tus dependencias, compiladores, imágenes base o procesos de CI/CD están expuestos, entonces toda tu arquitectura es vulnerable. Por eso, desde mi experiencia, proteger la cadena de suministro requiere una combinación brutal entre automatización, control de acceso, auditoría, políticas estrictas y paranoia técnica. Cada pipeline debe estar pensado para fallar de forma segura. Cada integración tiene que pasar por fuego cruzado. El software moderno no puede depender de la buena fe de los mantenedores de proyectos open source o de configuraciones por defecto de herramientas que no entienden de seguridad.
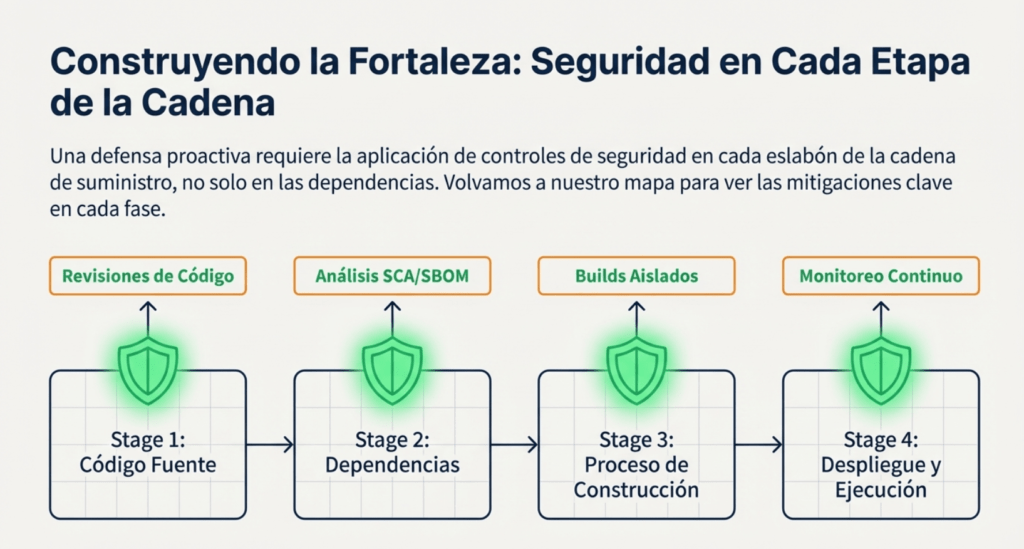
Versionado, procedencia y control de la fuente: la trinchera invisible
Una de las primeras líneas de defensa es el control de versiones. No sirve con tener todo en GitHub o GitLab si cualquiera puede fusionar sin revisión. Hay que usar flujos que incluyan revisores técnicos, expertos en la tecnología y con conocimiento del impacto del código. No estamos hablando de cumplir con un proceso burocrático, sino de poner un escudo frente a fallos, bugs o incluso sabotajes encubiertos.
El sistema debe auditarse solo. Cada commit tiene que ser trazable, y los cambios deben tener metadatos verificables. No se trata solo de saber quién cambió qué, sino de poder asegurar que ese cambio no fue alterado por alguien en medio del proceso. Ahí entra SLSA (Supply chain Levels for Software Artifacts), un estándar que vengo siguiendo de cerca. Empezar por el nivel 2 es obligatorio, pero apuntar a nivel 4 debería ser el objetivo para todo producto serio.
Además, el control de versiones no se limita al código fuente. La configuración, infraestructura como código, notebooks, políticas, todo debe versionarse. Porque todo lo que define el comportamiento de una app puede ser manipulado. Si algo afecta la disponibilidad, seguridad o estabilidad de tu sistema, entonces debe estar bajo vigilancia y trazabilidad.
Entornos de compilación: un santuario o un pozo infectado
He visto demasiadas organizaciones depender de compilaciones locales, compiladores sin control o incluso comandos ejecutados desde entornos que ni siquiera estaban monitoreados. Es un suicidio operativo. Las builds deben ser 100% automatizadas, reproducibles, ejecutadas en entornos efímeros y aislados. Cada compilación debería tener un principio y un final limpios, sin residuos que puedan contaminar el proceso.
Cloud Build, por ejemplo, permite usar YAMLs que definen todo el proceso. Pero eso no basta. Tenés que asegurar que esos YAMLs están protegidos, que los artefactos resultantes están firmados, que su procedencia se puede verificar y que nadie puede meter la mano en el medio. Los hashes, firmas digitales y certificados de compilación son fundamentales para poder confiar en que ese binario que vas a subir a producción no fue alterado ni en su código fuente ni en su proceso de construcción.
Y otra cosa: nunca uses tags como latest en dependencias o imágenes base. Usá referencias inmutables. Si no sabés exactamente qué versión estás instalando o desde dónde, ya perdiste el control de tu sistema.
El problema de las dependencias: el caballo de Troya moderno
Hoy el 90% de las apps modernas se construyen sobre software de terceros. Reutilizar código open source es lógico, eficiente y hasta inevitable. Pero cada librería que agregás, directa o transitiva, es una puerta abierta. Y el verdadero peligro no está en las dependencias directas, sino en las que están 4 o 5 niveles más abajo, que ni sabés que existen. Ahí es donde los atacantes plantan código malicioso que queda invisible hasta que se ejecuta en producción.
Por eso necesitás SBOM (Software Bill of Materials), herramientas como Artifact Analysis y control total sobre tus fuentes. No deberías confiar nunca en una imagen pública que no verificaste. Usar un Artifact Registry privado, con acceso restringido y políticas de revisión, es la única forma razonable de mantener cierto control. Ni hablar de las herramientas como sigstore, cosign y la validación binaria de Google. Sin eso, estás navegando a ciegas por aguas infestadas.
Políticas de implementación: última barrera antes del desastre
Aunque llegues al final del pipeline con todo validado, no podés confiar en que todo está bien sin una política que aplique esas reglas justo antes de que el código toque producción. Esto no es paranoia, es supervivencia digital. Definí qué se puede implementar y qué no. Establecé criterios como “solo se permite código sin vulnerabilidades críticas” o “solo artefactos firmados con certificados válidos de compilación autorizada”.
Si tenés metadatos, podés aplicar políticas. Si no los tenés, ya estás en desventaja. La autorización binaria te permite bloquear la implementación de imágenes que no cumplan con tus reglas. Y una vez que el código ya está corriendo, la validación continua asegura que cualquier cambio o incumplimiento post-deploy quede registrado.
El arte de reducir la superficie de ataque
Otra batalla que se libra silenciosamente es la que tiene que ver con reducir la huella de dependencias y configuración. Muchas veces, los desarrolladores meten una dependencia porque “la necesitaban para debuggear” o “para correr un test local”. Y después esa dependencia queda viviendo en producción, cargando código innecesario, exponiendo vulnerabilidades que nadie necesita.
Por eso, en mis pipelines incluyo análisis automático de requisitos, herramientas que escanean qué dependencias están realmente en uso y qué se puede limpiar. Cuanto menos código de terceros tengas, menos superficie de ataque hay. Es simple: si no lo usás, lo eliminás. Y si lo usás, lo auditás y lo versionás.
Si no dominás tu cadena, no dominás tu software
La cadena de suministro es el esqueleto de cualquier software moderno. Cada paso, cada herramienta, cada persona que toca el proceso es un nodo de riesgo. Y si no implementás prácticas de seguridad desde el diseño hasta el despliegue, estás creando sistemas que pueden ser comprometidos sin siquiera tocar el código directamente.
Llevo más de dos décadas viendo cómo evoluciona el software, cómo se reinventan los ataques y cómo las organizaciones caen por no pensar como atacantes. Proteger la cadena de suministro no es una moda. Es la base de un desarrollo seguro y profesional. Y quien lo ignora, está condenado a ser parte de las estadísticas del próximo incidente.
Protegiendo la cadena de suministro de software como un verdadero hacker
Hoy más que nunca, proteger la cadena de suministro de software dejó de ser una opción. Es una necesidad crítica. No importa si estás desplegando microservicios en contenedores o una app web monolítica; el código, las dependencias, el entorno de compilación y hasta el proceso de deployment son puntos de ataque. Un solo eslabón débil puede ser la entrada que un atacante necesita para secuestrar tu sistema, modificar tu lógica de negocio o comprometer a tus usuarios. Y como hackers —los buenos—, tenemos la responsabilidad de asegurar cada centímetro del ciclo de vida del software.
A lo largo de los años vi cómo la industria pasaba de entregar binarios por FTP a pipelines de CI/CD con múltiples stages automatizados. Y si bien eso es un progreso, también significa que hay más superficie de ataque que nunca. La forma en que manejás tu código fuente, configurás tus repositorios, revisás tus pull requests, elegís tus imágenes base, construís tus contenedores y almacenás tus dependencias… todo eso define si tu software es resistente o está a segundos de ser vulnerado.
Todo empieza en el origen: el código fuente
Tu código es tu primer activo. Y no alcanza con versionarlo en GitHub o GitLab. Tenés que garantizar que cada commit tenga trazabilidad, que no se mezclen cambios sin revisión y que el control de acceso esté bajo política estricta. El mínimo privilegio no es solo una recomendación, es ley. Nadie fuera del scope debería tener acceso de escritura, y la autenticación multifactor es una barrera básica, no avanzada.
La seguridad de un repositorio empieza desde cómo lo inicializás. Un repositorio bien configurado impone roles, permisos y flujos de revisión. No se trata de poner trabas burocráticas, sino de crear entornos donde los cambios maliciosos no pasen desapercibidos. Desde el diseño de la API hasta la elección de una librería externa, todo debería pasar por múltiples ojos entrenados, linters automáticos y herramientas de análisis estático. Lo que no se audita, se pudre.
Repositorios, configuración, y la guerra contra el caos
En entornos empresariales es común ver miles de repositorios con configuraciones heterogéneas. Es un desastre. Si no estandarizás la forma en que tus repositorios se crean, los errores y las brechas de seguridad se multiplican. Automatizar esa creación, con templates, validaciones y reglas impuestas por seguridad centralizada, es una estrategia básica de supervivencia. No importa si usás Terraform, scripts Bash o APIs, el punto es que nadie debería hacer “setup a mano” de un repo jamás.
La administración de identidades también es clave. Cuando un dev se va, su acceso se tiene que cortar al instante. No podés depender de que alguien se acuerde de borrarlo del repo. Integrá tu control de versiones con el IAM corporativo y sincronizá los niveles de acceso con los niveles de sensibilidad de cada proyecto. Porque no todos los códigos son iguales: no es lo mismo un microservicio de logs que un backend de pagos.
Las compilaciones son el corazón expuesto
Todo lo que compila tu código debe ser automático, trazable y reproducible. No existe lugar para builds locales hechos con la laptop de un desarrollador. Esas prácticas eran tolerables hace 15 años, pero hoy son veneno puro. Cada build tiene que ejecutarse en entornos efímeros, destruidos luego de usarlos. Nada de arrastrar configuraciones viejas o archivos residuales. Un build limpio es un artefacto confiable.
Y si vamos a hablar de builds, hablemos de procedencia. ¿Podés demostrar que tu binario fue construido desde código legítimo, en un entorno seguro y con herramientas limpias? Si no podés, tenés un problema. Servicios como Cloud Build te dan esa trazabilidad, generando metadatos de procedencia firmados. Esa metadata no es opcional: es tu prueba en caso de que algo salga mal.
Las dependencias: tu peor pesadilla camuflada
Pocas cosas son tan peligrosas como confiar ciegamente en paquetes externos. Cada vez que instalás algo desde npm, PyPI o Maven Central, estás trayendo código que no escribiste, que no audistaste y que podría ser malicioso. Y eso aplica tanto a dependencias directas como a las transitivas, esas que ni siquiera sabés que estás usando.
¿Querés protegerte? Vendoreá, almacená en un repositorio privado, verificá firmas, fijá versiones, y analizá vulnerabilidades de forma automática. No hay excusas. Hoy existen herramientas como Artifact Registry, sigstore, VEX y SBOMs que te permiten tener control real sobre tus librerías. ¿Tu pipeline revisa hashes? ¿Tus archivos de lockfile están comprometidos? ¿El paquete que instalaste fue suplantado por uno malicioso con el mismo nombre? Todo eso hay que mirarlo con lupa. Y si no lo hacés vos, lo va a hacer un atacante.
Las imágenes base: una caja negra peligrosa
Los contenedores se volvieron el estándar de facto. Pero los contenedores no son mágicos. Cada vez que usás una imagen base estás heredando potencialmente miles de líneas de código que no conocés. Muchas imágenes vienen infladas, llenas de librerías obsoletas, shells innecesarios y backdoors potenciales. Usar imágenes oficiales y mínimas, como las que proporciona Google desde su cloud, es un paso en la dirección correcta.
Pero no alcanza con eso. Tenés que controlar si tienen actualizaciones, qué componentes incluye, y eliminar lo que no usás. Las imágenes base son el equivalente a construir una casa sobre cimientos desconocidos: si se caen, te arrastran.
El deployment, ese momento crítico
Deployear código debería ser una ceremonia segura, no una apuesta. No podés permitir que cualquier cosa llegue a producción. Cada cambio tiene que estar validado, firmado, escaneado por vulnerabilidades y registrado. Autorización Binaria es una herramienta brutal para esto: define políticas y bloquea implementaciones que no cumplan los criterios. ¿No está firmado? No entra. ¿Tiene vulnerabilidades críticas? No entra. Y eso no es paranoia, es sentido común.
Las políticas no deben terminar en el deploy. La validación continua es el siguiente nivel. Porque podés tener una política hoy, pero si la cambiás mañana, querés saber qué cargas actuales ya no la cumplen. Ese monitoreo post-deploy es lo que te da visibilidad real sobre tu postura de seguridad.
Supervisión, visibilidad y control de daño
No podés proteger lo que no entendés. Las plataformas modernas como Cloud Run y GKE ofrecen paneles de seguridad que muestran el estado real de tus aplicaciones. Te dicen si una carga está mal configurada, si una imagen está comprometida o si una política fue violada. Pero la clave es tener esa visibilidad integrada desde el momento cero, no como una auditoría tardía.
Las estadísticas de seguridad no son solo un dashboard bonito: son tu línea de defensa. Si algo cambia, si un hash ya no coincide, si una política se rompe, lo tenés que saber antes que lo sepa un atacante. Y con ese dato, tomar acciones.
Una cadena es tan fuerte como su eslabón más débil
A lo largo de más de dos décadas como programador y hacker, aprendí una lección que nunca falla: la seguridad no se improvisa. Se diseña, se implementa y se valida de forma obsesiva. Una cadena de suministro de software moderna puede ser una fortaleza o una trampa mortal. Vos decidís cuál construir.
No se trata solo de herramientas. Se trata de prácticas, cultura, paranoia sana y obsesión por el detalle. Desde cómo versionás hasta cómo deployás, todo tiene que estar bajo control. Porque cuando llega el momento de la verdad, solo el código que construiste como si tu vida dependiera de él va a resistir el ataque.
Y si no lo protegés vos, te lo van a romper ellos.
A03:2025 – Fallas en la Cadena de Suministro de Software (Software Supply Chain Failures)
La aplicación depende de librerías, paquetes, contenedores, servicios cloud, plugins, proveedores externos y componentes que, si están comprometidos, desactualizados, inseguros o manipulados, introducen vulnerabilidades aunque el código propio esté perfecto.
En 2025 sube porque los ataques a la cadena de suministro aumentan exponencialmente: contaminación de paquetes NPM, dependencias maliciosas, contenedores vulnerables, manipulación de pipelines y proveedores externos comprometidos.

🧩 Ejemplos típicos (2025)
- Instalar dependencias NPM/PyPI con malware oculto.
- Bibliotecas desactualizadas con CVEs críticos.
- Paquetes que cambian de dueño (“package hijacking”).
- Dependencias ocultas en transitive dependencies (árbol profundo).
- Imágenes Docker base con vulnerabilidades severas.
- Proveedores cloud que exponen tokens o credenciales.
- Scripts de build manipulados (CI/CD comprometido).
- Toolchains o compiladores adulterados.
- Dependencias con typosquatting: react-dom vs reactd0m.
- Inclusión de SDKs de terceros con tracking o backdoors.
- Falta de verificación de firma en paquetes o contenedores.
- Plugins o extensiones vulnerables en CMS o frameworks.
🔍 Mini-guía de explotación / Pentesting de cadena de suministro
- Enumerar dependencias directas y transitivas (NPM, pip, composer, gradle, maven).
- Buscar CVEs en cada una (automatizable con SCA).
- Revisar dependencias sospechosas por nombre o poca reputación.
- Validar firmas/Hashes en paquetes descargados.
- Analizar imágenes de contenedores (Trivy, Grype).
- Revisar scripts de build en CI/CD para identificar:
- descarga de recursos externos
- scripts bash sin control
- tokens hardcodeados
- Buscar inyección en pipelines (GitHub Actions mal configuradas, runners públicos).
- Revisar proveedores externos (API keys, acceso SDK).
- Probar que el servidor no descarga código en runtime sin verificación.
- Analizar uso de componentes abandonados o sin mantenimiento.

🎯 Consecuencias
- Compromiso total aunque el código propio sea seguro.
- Robo de datos mediante dependencias maliciosas.
- Exfiltración mediante SDKs de terceros.
- Introducción de backdoors en tiempo de compilación.
- Ataques a la cadena CI/CD → push de código malicioso.
- Contaminación de contenedores → RCE indirecto.
- Suplantación de paquetes (typosquatting).
- Ataques supply-chain tipo SolarWinds, Log4Shell o event-stream.
🛡 Defensas modernas (2025)
- SBOM (Software Bill of Materials) obligatorio.
- SCA (Software Composition Analysis) automático en CI/CD.
- Verificación de firmas de paquetes (sigstore, cosign).
- Instalar dependencias desde repos privados o verificados.
- Bloquear instalación de paquetes desconocidos (npm audit, pip audit).
- Endurecer contenedores base y mantenerlos actualizados.
- Escaneo de imágenes en cada build.
- Revisar scripts de build (GitHub Actions/CI) para evitar ejecución arbitraria.
- Tokens de CI/CD con least privilege.
- Habilitar verifySource, integrity y checksum en package managers.
- Control de versiones + prohibir dependencias abandonadas.
- Validación automática de CVEs antes del deploy.
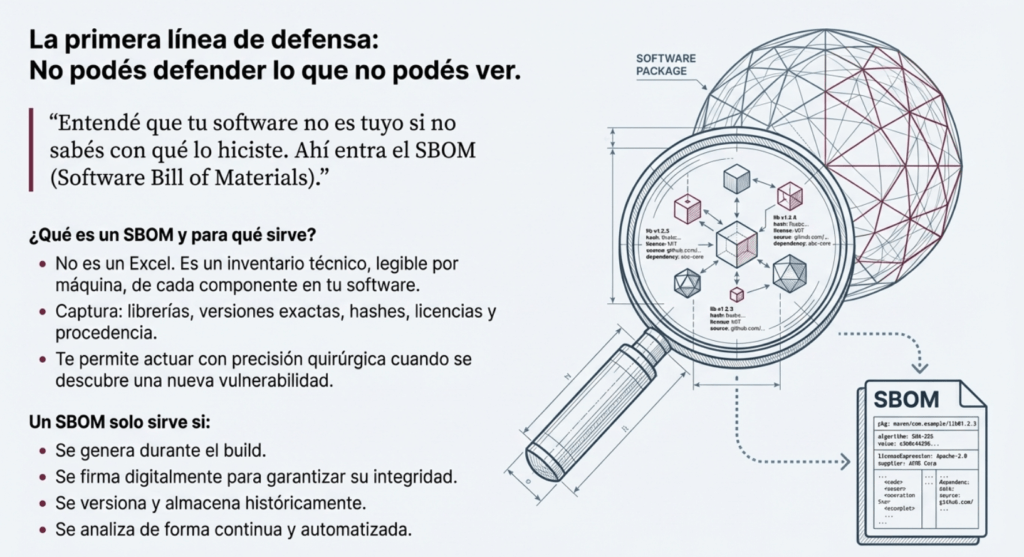

📚 Subtipos / patrones modernos (2025)
(en tu mismo formato tabular)
| Subtipo / patrón | Definición | Ejemplo bancario | Pentesting (qué probar) | Ataque / PoC | Consecuencia | Defensa | Tips examen |
| Paquete desactualizado con CVEs | Librerías vulnerables | Usan Log4J viejo | Revisar versionado | Exploit RCE | Toma total | SCA + update | “CVE = fallo supply chain” |
| Paquete malicioso (NPM/PyPI) | Dependencias infectadas | SDK fraudulento | Revisar origen/reputación | Inst. maliciosa | Robo datos | Firma + SBOM | Typosquatting = red flag |
| Typosquatting | Nombre similar | jqueery | Comparar nombres | Descargar paquete falso | Backdoor | Mgr privados | Siempre sospechar errores ortográficos |
| Dependencias transitivas inseguras | CVEs en árbol profundo | libC vulnerable | Enumerar árbol | RCE indirecto | Compromiso total | SCA automático | “Transitive dependencies” aparece siempre |
| Contenedores inseguros | Imágenes base vulnerables | Docker base sin patch | Escanear (Trivy) | Exploit dentro del contenedor | RCE / lateral | Imágenes mínimas | “Alpine, distroless = mejor” |
| Compromiso del pipeline CI/CD | Scripts manipulados | GitHub Actions sin control | Revisar permisos | Ejecutar código en pipeline | Backdoor | Hardening CI/CD | Buscar pull_request mal configurado |
| Firmas no verificadas | Falta verificación | pip sin –require-hashes | Chequear firma | Inyección | Dependencias adulteradas | Sigstore/cosign | “Verificación de firmas = obligatorio” |
| SDKs de terceros inseguros | Tracking o exfiltración | APIs fintech externas | Revisar tráfico | Interceptar API | Exfiltración | Validación SDK | Preguntas sobre SDK → supply chain |
| Repos externos no confiables | Mirrors inseguros | Instalar desde repos no oficiales | Revisar origen | Paquetes adulterados | Malware | Repos oficiales | Nunca instalar de URL desconocidas |
| Build scripts vulnerables | Ejecutan código inseguro | Bash de build baja script remoto | Leer pipeline | Inyección | Control total | IaC seguro | Palabras clave: “script remoto” |
🧪 Checklist rápida de pentesting A03:2025
- Obtener SBOM o generarlo (Syft, CycloneDX).
- Escanear dependencias con SCA.
- Revisar archivos: package.json, requirements.txt, pom.xml, go.mod.
- Revisar logs del pipeline y GitHub Actions.
- Validar si paquetes se descargan en runtime.
- Escanear contenedores (Trivy, Grype).
- Buscar typosquatting y dependencias desconocidas.
- Verificar si hay paquetes sin mantenimiento.
- Revisar firma digital de paquetes o contenedores.
- Revisar integridad de repos externos.
- Analizar SDKs de terceros (llamadas, endpoints, exfiltración).
Resumen ejecutivo (para curso o slide)
A03:2025 Fallas en la Cadena de Suministro de Software refleja un riesgo creciente: la mayoría de las aplicaciones modernas dependen de cientos de componentes externos y un solo eslabón débil puede comprometer toda la aplicación. Incluye el uso de dependencias vulnerables, paquetes maliciosos, typosquatting, imágenes de contenedores inseguras, scripts de CI/CD manipulados, SDKs inseguros y falta de verificación de firmas o integridad. La mitigación requiere SBOM, análisis de composición (SCA), verificación de firmas, hardening de pipelines, contenedores mínimos y control estricto de dependencias directas y transitivas. Es un riesgo crítico porque compromete aplicaciones aún cuando el código propio no tiene fallos.
¡Felicitaciones por llegar hasta aquí!
En este capítulo aprendiste a mirar el software moderno con una visión mucho más profunda: comprendiste que la seguridad no se trata solo del código que escribís, sino también de todo lo que consumís, instalás, compilas y despliegas.
Ahora sabés:
🔸 Qué es una falla en la cadena de suministro.
🔸 Por qué es el vector de ataque más usado hoy en día.
🔸 Cómo identificar dependencias vulnerables o mal mantenidas.
🔸 Cómo usar SBOM, firmas, procedencia y SLSA como defensas reales.
🔸 Cómo auditar repositorios, builds, pipelines y entornos de desarrollo.
🔸 Cómo aplicar parcheo virtual cuando no es posible arreglar el código.
🔸 Cómo pensar como atacante para detectar puntos débiles invisibles.
🔸 Y cómo diferenciar entre misconfiguraciones (A02) y componentes vulnerables (A03).
Con este conocimiento estás un paso más cerca de convertirte en un desarrollador —o analista de seguridad— capaz de proteger aplicaciones modernas de ataques avanzados.
Recordá: la cadena de suministro es tan fuerte como su eslabón más débil. Tu trabajo es asegurarte de que ninguno quede sin vigilancia.