En este capítulo, OWASP TOP 10 A10:2025 Mishandling of Exceptional Conditions, vas a explorar una de las categorías más nuevas y, paradójicamente, una de las más antiguas en la historia de la ingeniería de software: cómo fallan los sistemas cuando las cosas no salen como se esperaba. A10:2025 —Manejo Inadecuado de Condiciones Excepcionales— no es solo un problema técnico: es una falla estructural, lógica y arquitectónica que se manifiesta en bugs silenciosos, fugas de información, DoS, corrupción de datos, transacciones rotas, estados inconsistentes y comportamientos impredecibles.
Este capítulo te va a mostrar que la seguridad no depende solo de lo que haces cuando todo funciona bien, sino de lo que tu sistema hace cuando algo falla. Un error mal gestionado no es un detalle menor: es una puerta abierta al reconocimiento ofensivo, a la explotación inteligente, o incluso al colapso controlado del sistema.
A lo largo del capítulo vas a comprender:
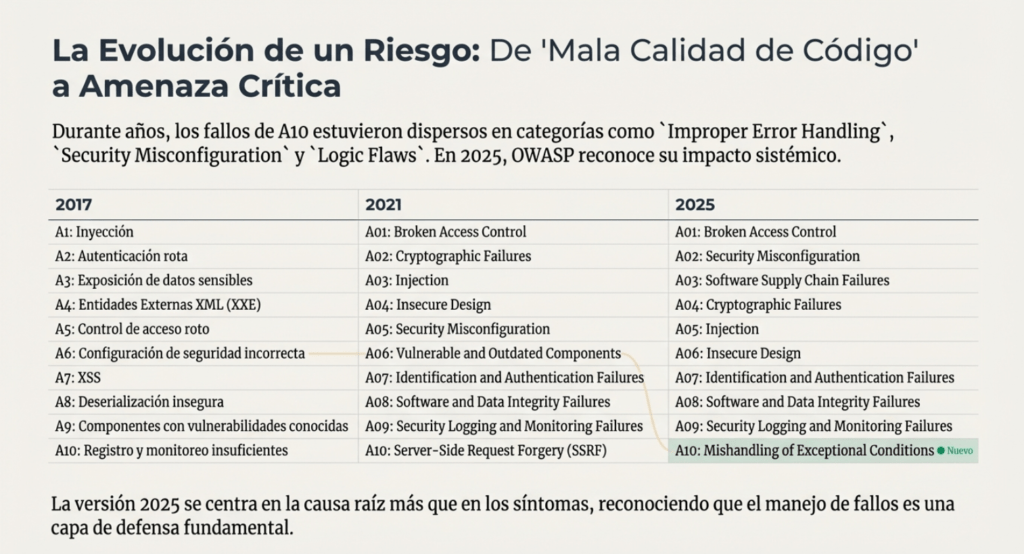
- Por qué OWASP incorporó A10 como categoría específica en 2025, separándola finalmente de la genérica “mala calidad de código”.
- Cómo fallos comunes como null pointers, errores de parámetros faltantes, overflows, fallas de apertura y desbordes de recursos son, en realidad, vulnerabilidades.
- Cómo los errores expuestos sin sanitización revelan frameworks, rutas internas, SQLs, arquitectura, servicios y lógica de negocio.
- Qué ocurre cuando una transacción falla a mitad de camino y no existe rollback ni fail-safe.
- Por qué los programas deben fallar rápido pero fallar seguro: fail-fast y fail-safe como principios de ingeniería.
- Cómo diseñar manejadores globales de errores en Java, .NET, Node.js, Python y frameworks modernos.
- Cómo estructurar respuestas de error seguras con RFC 7807 sin filtraciones al cliente.
- Cómo validar entradas, limitar recursos, anticipar estados anormales y prevenir errores antes de que ocurran.
- Cómo los ataques DoS, las condiciones de carrera y los errores lógicos aparecen cuando el manejo de errores es deficiente.
- La relación directa entre A10 y otras categorías como A09 (si fallás pero no logueás, estás ciego) y A07 (excepciones mal manejadas en flujos de autenticación).
Este capítulo no te enseña a evitar errores —eso es imposible—; te enseña a diseñar sistemas que sobreviven a los errores sin romper la seguridad. Vas a aprender a construir software que no oculta fallos, no filtra información, no queda inconsistente, no se corrompe y no deja rastros que el atacante pueda explotar. Software resiliente, seguro y preparado para fallar con elegancia.
Prepárate: este capítulo cambia tu forma de pensar el error. Deja de ser un accidente y se convierte en una capa más de defensa.
OWASP TOP 10
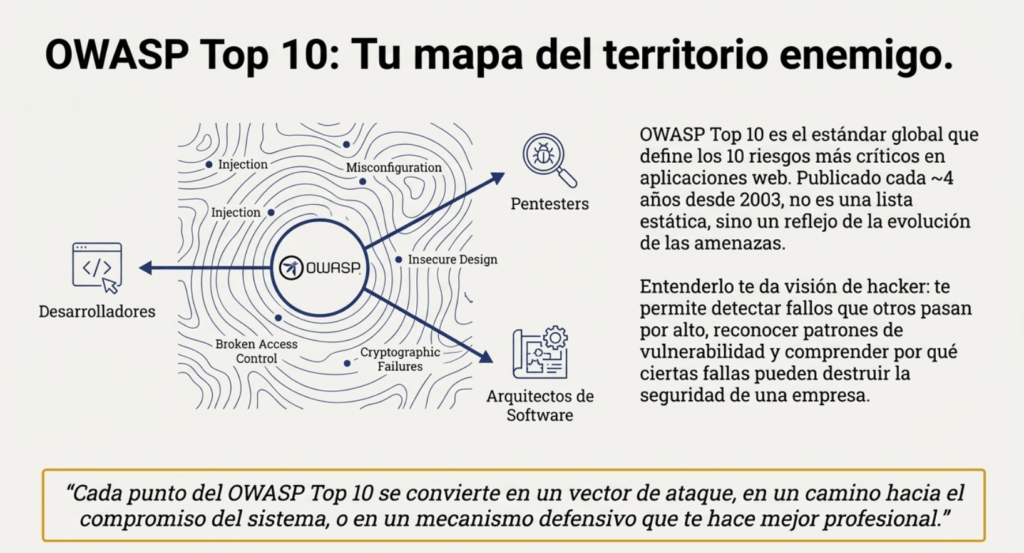
OWASP es popular por publicar el TOP 10 Owasp Web cada cuatro años. Este es un documento que lista los diez riesgos más críticos en aplicaciones web, con el objetivo de ayudar a las organizaciones a identificar y mitigar las vulnerabilidades asociadas con estos riesgos. https://owasp.org/Top10/es/ Cada uno de estos riesgos representa una debilidad común y significativa que a menudo se puede explotar para comprometer la seguridad de una aplicación web. OWASP proporciona información detallada sobre posibles vulnerabilidades y técnicas de ataque para cada riesgo.
El Top 10 de OWASP es una lista que se actualiza periódicamente de los riesgos de seguridad de las aplicaciones web más críticos. Lo mantiene el Proyecto Abierto de Seguridad de Aplicaciones Web (OWASP), una organización sin fines de lucro centrada en mejorar la seguridad de las aplicaciones web. Sirve como una valiosa guía para que los desarrolladores, los expertos en pruebas de penetración de aplicaciones web y las organizaciones comprendan y prioricen los riesgos de seguridad comunes en las aplicaciones web.
El Top 10 de OWASP es una lista conocida de los diez riesgos de seguridad de aplicaciones web más críticos. Se actualiza periódicamente para garantizar que refleje el panorama actual de amenazas y los desafíos de seguridad en constante evolución que enfrentan las aplicaciones web. La primera versión del Top 10 de OWASP se publicó en 2003. Su objetivo era crear conciencia sobre los riesgos comunes de seguridad de las aplicaciones web y ayudar a los desarrolladores a priorizar los esfuerzos de seguridad. La lista incluía riesgos como secuencias de comandos entre sitios (XSS), inyección de SQL y problemas de gestión de sesiones. Cada lanzamiento del Top 10 de OWASP se basa en las versiones anteriores, mejorando su precisión, relevancia y practicidad.
A10:2025 – Mishandling of Exceptional Conditions
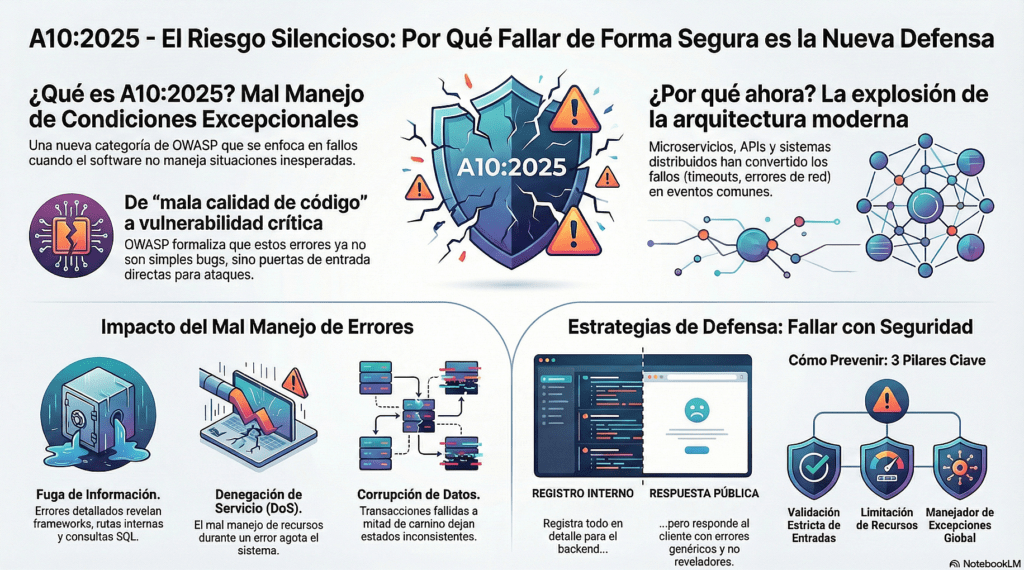
La aparición de A10:2025 – Mishandling of Exceptional Conditions en el OWASP Top 10 marca un cambio tremendo en cómo la industria entiende las vulnerabilidades modernas. A diferencia de categorías clásicas como Injection o Fallos Criptográficos, esta nueva categoría no se centra en una técnica específica de ataque, ni en un error de implementación fácilmente identificable. Se trata de un conjunto de fallas profundas, sutiles y muchas veces invisibles, que ocurren cuando las aplicaciones no manejan adecuadamente comportamientos inesperados, entradas anómalas, estados límite o condiciones excepcionales.
Este nuevo riesgo de OWASP 2025 surge como respuesta al manejo deficiente de errores y fallos del sistema. A diferencia de categorías anteriores demasiado genéricas, A10 se enfoca específicamente en situaciones donde una aplicación no anticipa, detecta o maneja correctamente condiciones excepcionales —es decir, situaciones inusuales, impredecibles o que alteran el flujo esperado.
Estas fallas pueden ser errores lógicos, desbordamientos, corrupción de estado, fallos en transacciones, problemas con memoria, red o privilegios. Cuando una app no sabe cómo actuar ante un estado inesperado, deja abierta una ventana crítica para ataques, interrupciones y fugas de datos. Lo peor: muchas veces estos errores pasan desapercibidos porque no se loguean bien o no se monitorean, amplificando el impacto de forma silenciosa.
En este artículo se detalla cómo un atacante puede explotar estas debilidades para provocar DoS, interferir con transacciones financieras o recolectar información a través de mensajes de error mal diseñados. También se explican patrones modernos de defensa: uso de excepciones personalizadas, interceptores globales, logs estructurados, respuesta genérica hacia el cliente (como la RFC 7807) y registro detallado en backend.
Se hace hincapié en que no se trata solo de capturar errores, sino de hacerlo bien: distinguir errores operativos de bugs reales, no ocultar problemas con try/catch innecesarios, evitar relanzar mal las excepciones (como throw ex en .NET), usar un sistema centralizado de logging y validar entradas para prevenir estados inválidos.
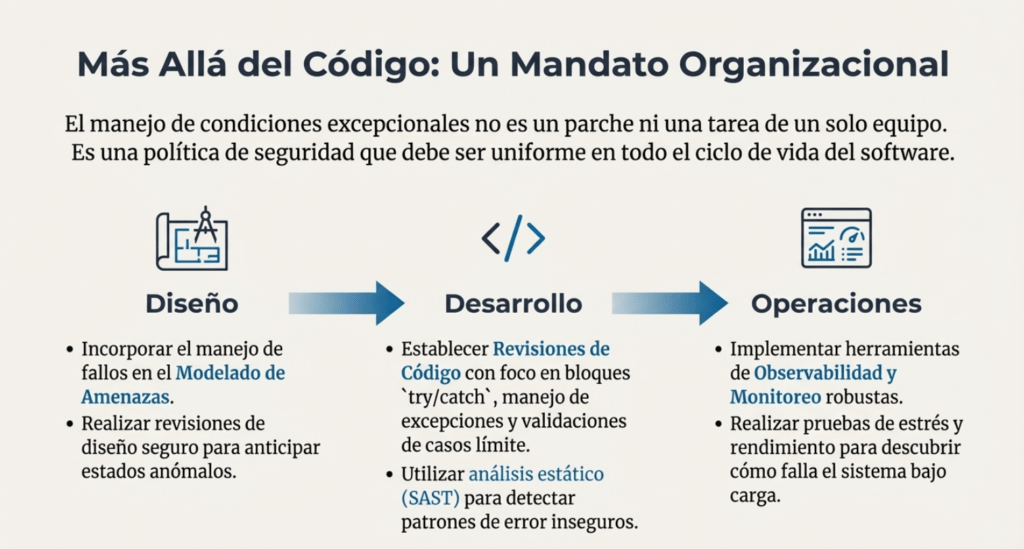
Además, se resalta la importancia de que toda la organización maneje los errores de forma uniforme. Desde el diseño hasta la producción, el manejo de condiciones excepcionales debe formar parte de la arquitectura de seguridad: modelado de amenazas, validación de entradas, rollback de transacciones, protección de logs y uso de herramientas de observabilidad.
Conclusión: El manejo de errores no es un parche, es una capa de defensa. Una app segura no es la que no falla, sino la que falla con control. Este riesgo OWASP exige diseñar sistemas que detecten, reaccionen y se recuperen de lo inesperado —sin exponerse, sin corromperse y sin darle ventaja al atacante.
la nueva frontera del OWASP Top 10 y el riesgo silencioso que puede romper incluso el software mejor construido
Su inclusión en el Top 10 —y su crecimiento respecto de ediciones anteriores— refleja que la seguridad moderna ya no depende solo de “evitar errores evidentes”, sino de construir aplicaciones capaces de resistir fallos y comportamientos inesperados. La complejidad del software, la naturaleza distribuida de los sistemas y la dependencia masiva en automatización, APIs y microservicios han hecho que los escenarios excepcionales sean ahora parte habitual del flujo normal. Cuando un sistema no está preparado para manejar lo inesperado, el resultado no es simplemente un error: es una vulnerabilidad.
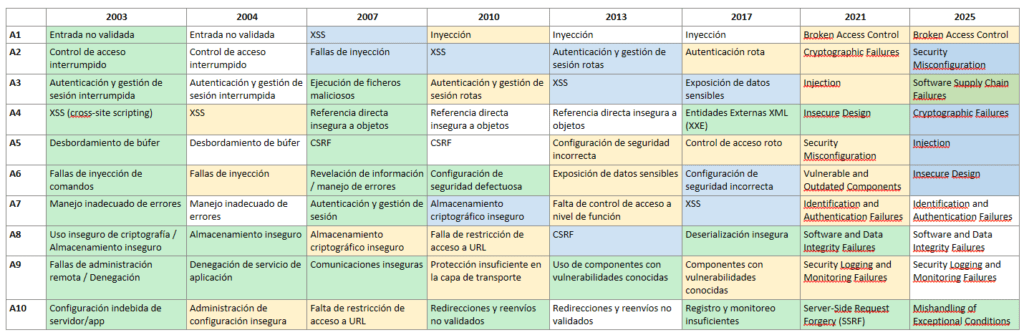
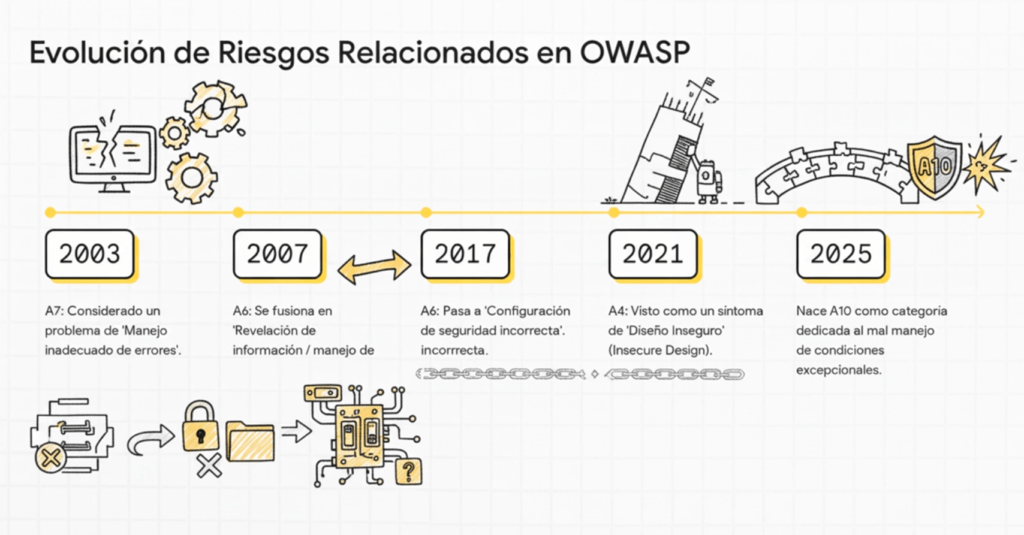
Evolución de OWASP TOP 10
En el momento de crear este artículo coexiste las dos versiones 2021/2025.
⚪No cambia
🟡Fusionado
🔵Cambia de posición
🟢Nuevo
Origen histórico: el riesgo que OWASP veía, pero que el mercado ignoraba
Durante las primeras dos décadas del OWASP Top 10, este tipo de fallas aparecían dispersas en categorías más amplias, como:
- Improper Error Handling
- Security Misconfiguration
- Insecure Design
- Logic Flaws
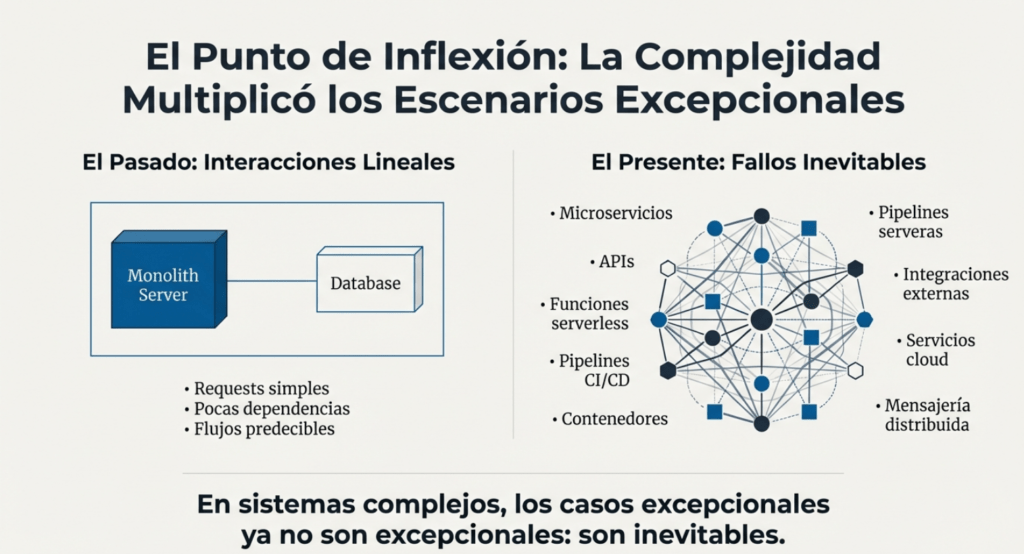
El origen de la categoría A10:2025 se remonta a estos “rincones” del Top 10: aquellos errores que nadie sabía dónde ubicar pero que claramente generaban riesgos graves. Durante años, estos problemas se consideraron anomalías poco frecuentes, fallas que ocurrían solo en situaciones límite o como consecuencia de malas prácticas generales. Pero la realidad demostró lo contrario: las condiciones excepcionales son la norma en sistemas complejos, y su mal manejo abrió puertas que los atacantes aprendieron a aprovechar mejor que nadie.
Aunque estos problemas existían desde los años 2000, no aparecieron como categoría formal porque OWASP buscaba agrupar vulnerabilidades de alto impacto y alta frecuencia. En ese entonces, la web era más simple: requests lineales, interacciones básicas, pocas dependencias internas. Los escenarios excepcionales eran escasos y, cuando ocurrían, normalmente el sistema simplemente devolvía un error genérico. Con el tiempo, la arquitectura del software cambió y los fallos que antes eran anecdóticos pasaron a convertirse en problemas sistémicos.
El punto de inflexión: la arquitectura moderna aumenta exponencialmente los casos excepcionales
Entre 2015 y 2025, todo cambió. Las aplicaciones dejaron de ser monolíticas para convertirse en ecosistemas de:
- Microservicios
- APIs
- Funciones serverless
- Pipelines CI/CD
- Contenedores
- Integraciones externas
- Servicios cloud
- Mensajería distribuida (Kafka, RabbitMQ)
- Almacenamientos híbridos
En este contexto, los casos excepcionales —timeouts, fallos en cadena, interrupciones, errores de parseo, datos incompletos, respuestas inesperadas, saturación, fallos en terceros, retrasos en red, desbordes lógicos— ya no son excepcionales: son inevitables.

Los sistemas ahora deben lidiar con:
- Respuestas de APIs que fallan de forma intermitente
- Estados de red impredecibles
- Datos corruptos o parciales
- Latencias fluctuantes
- Desincronización entre servicios
- Errores silenciosos en dependencias externas
- Casos límite matemáticos o lógicos
- Entradas inesperadas pero válidas según los estándares
Cuando el software no contempla estos escenarios, los atacantes encuentran oro: pueden activar condiciones inesperadas para lograr acceso indebido, corromper información, saltarse validaciones o provocar fallas que comprometan la seguridad global.
OWASP TOP 10 2021
La consolidación en OWASP Top 10 – 2025: el nacimiento de una categoría global
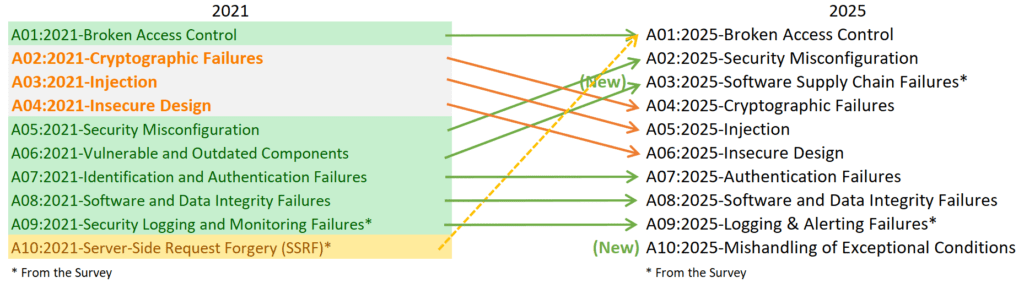
En la lista de los Diez Principales para 2025, se han incorporado dos categorías nuevas y una consolidada. Esta versión según OWASP está centrada en la causa raíz, más que en los síntomas, en la medida de lo posible. Dada la complejidad de la ingeniería y la seguridad del software, resulta prácticamente imposible crear diez categorías sin cierto grado de superposición.
La aparición formal de A10:2025 – Mishandling of Exceptional Conditions representa el reconocimiento de OWASP de que este tipo de errores merece una categoría propia. A diferencia de los riesgos tradicionales, los fallos en condiciones excepcionales no suelen ser detectados por scanners automáticos. No aparecen como CVEs tradicionales ni como vulnerabilidades obvias. Son fallos emergentes que surgen del comportamiento dinámico del sistema ante inputs o estados no anticipados.
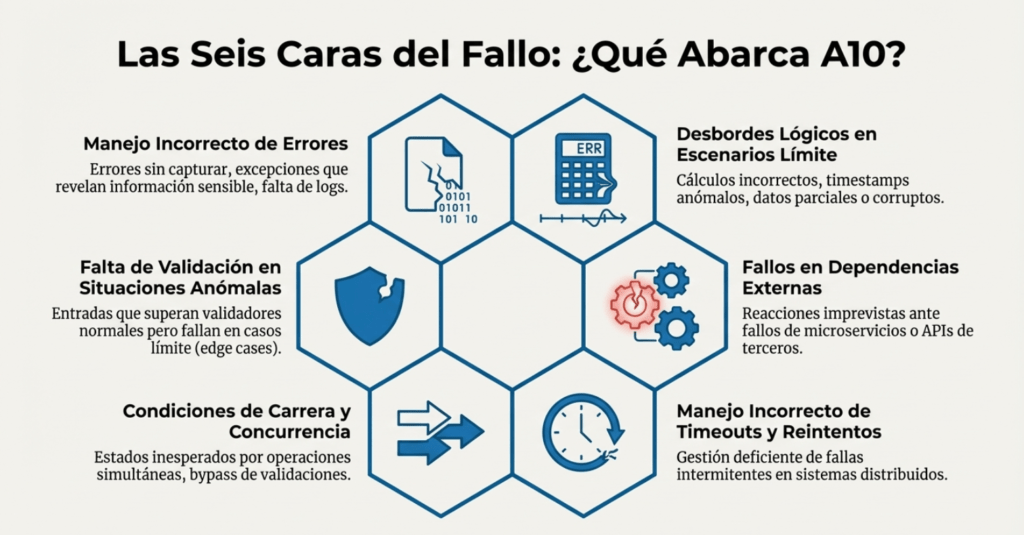
OWASP destaca que esta categoría abarca:
1. Manejo incorrecto de errores
- Errores sin capturar
- Excepciones que revelan información sensible
- Errores que interrumpen flujos críticos
- Falta de logs adecuados en situaciones excepcionales
2. Desbordes lógicos en escenarios límite
- Cálculos incorrectos en límites numéricos
- Timestamps anómalos
- Deserializaciones incompletas
- Datos parciales o corruptos
3. Falta de validación en situaciones anómalas
- Entradas que no rompen el validador normal, pero sí el edge case
- Estados internos inconsistentes
- Flujos inesperados
4. Fallos en dependencias externas
- Un microservicio falla → la app no sabe cómo reaccionar
- Un API externo devuelve respuestas anómalas
- Esperar un formato rígido cuando la realidad es más caótica
5. Condiciones de carrera y concurrencia
- Operaciones simultáneas que generan estados inesperados
- Bypass de validaciones por desincronización
- Repeticiones, duplicados o saltos de estado indebidos
6. Manejo incorrecto de timeouts, reintentos y fallas intermitentes
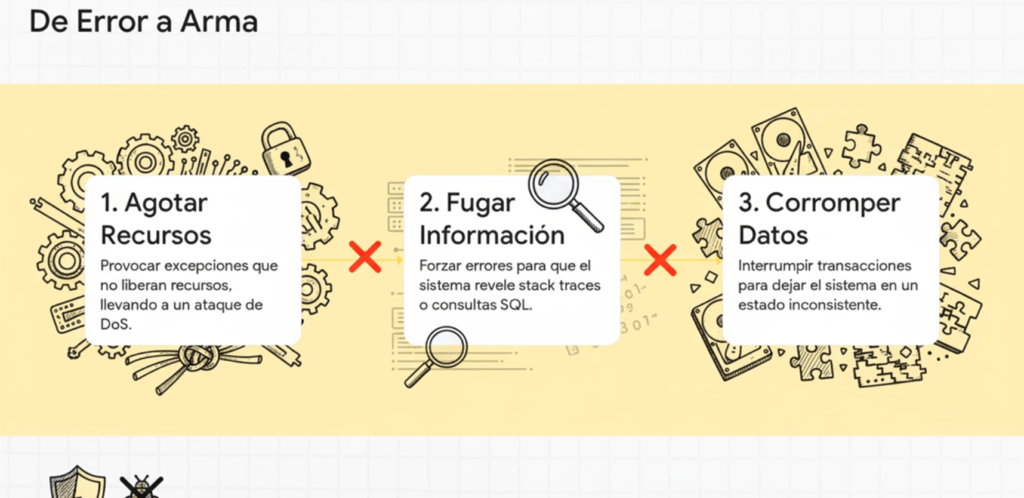
Los atacantes explotan estos escenarios para:
- Denegar servicio
- Corromper estados
- Forzar inconsistencias
- Encontrar caminos no previstos
¿Por qué A10:2025 es una de las categorías más modernas y más difíciles?
Porque apunta al corazón del problema: la complejidad.
En 2025, la superficie de ataque dejó de ser solamente el código que el desarrollador escribe. Ahora incluye:
- El comportamiento emergente de múltiples servicios
- El tiempo de respuesta de APIs externas
- El desfasaje entre componentes distribuidos
- El tratamiento incorrecto de fallas internas
- El comportamiento anómalo en condiciones extremas
- Errores en el control de flujo del sistema entero
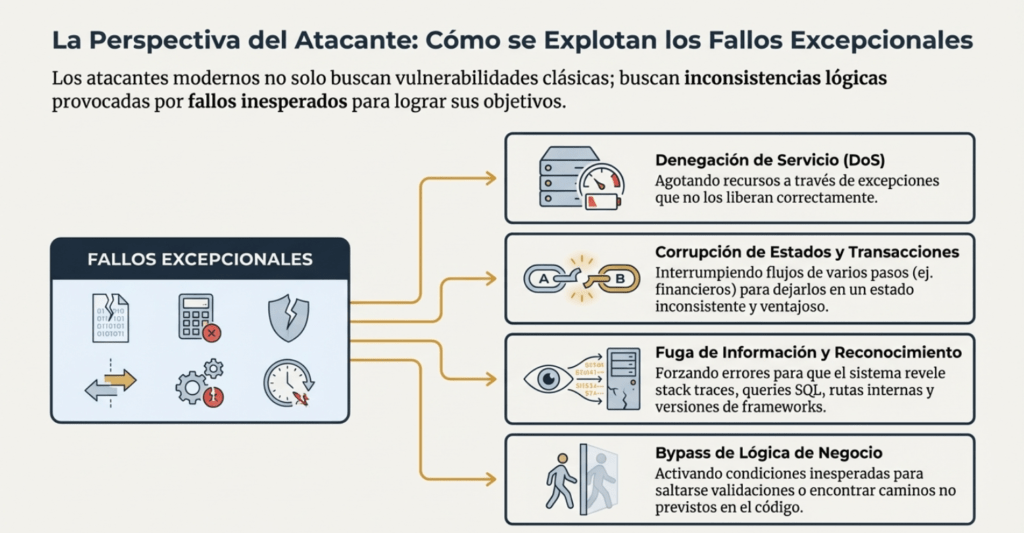
Los atacantes modernos no solo buscan vulnerabilidades clásicas: buscan inconsistencias lógicas provocadas por fallos inesperados.
Y lo logran explotando:
- Mensajes interrumpidos
- Respuestas incompletas
- Formatos alterados
- Condiciones de carrera
- Timeouts manipulados
- Reintentos automatizados
- Saturación en puntos débiles
- Estados internos corruptos
Un sistema moderno puede pasar de “perfectamente funcional” a “completamente inseguro” por una simple condición que el diseño no contempló.

El mensaje de OWASP: esta categoría será CRÍTICA en los próximos 10 años
A10:2025 no es un cierre decorativo del Top 10. Es una advertencia estratégica. OWASP entiende que en la próxima década la mayor parte de los incidentes no vendrán por fallas tradicionales, sino por:
- Interacciones imprevistas
- Errores silenciosos
- Estados internos corruptos
- Casos límite no contemplados
- Fallos en condiciones de saturación
- Bugs emergentes del comportamiento distribuido
El software moderno ya no falla por ataques simples: falla por complejidad.
Y A10:2025 lo deja muy claro.
Mishandling of Exceptional Conditions se convierte en la categoría que sintetiza el mensaje más importante del OWASP Top 10 – 2025:
“No importa cuán seguro sea tu código, si tu sistema no sabe manejar lo inesperado, ya es vulnerable.”
En un mundo donde todo es distribuido, automatizado, asincrónico y dependiente de terceros, la capacidad de una aplicación para manejar condiciones excepcionales se vuelve tan importante como la validación de entrada, el cifrado o la autenticación.
A10:2025 es, paradójicamente, la categoría más moderna porque refleja la realidad del software actual: lo que te rompe no es el flujo normal, sino lo que ocurre cuando algo no sale como esperabas.
A10:2025 Mal manejo de condiciones excepcionales
Manejo Inadecuado de Condiciones Excepcionales es una nueva categoría para 2025. Esta categoría contiene 24 CWE y se centra en el manejo inadecuado de errores, errores lógicos, fallos de apertura y otros escenarios relacionados derivados de condiciones y sistemas anormales. Esta categoría incluye algunos CWE que anteriormente se asociaban con una calidad de código deficiente. Esto era demasiado general para nosotros; en nuestra opinión, esta categoría más específica ofrece una mejor orientación.
CWE notables incluidos en esta categoría: CWE-209 Generación de mensaje de error que contiene información confidencial, CWE-234 Error al manejar parámetros faltantes, CWE-274 Manejo inadecuado de privilegios insuficientes, CWE-476 Desreferencia de puntero nulo y *CWE-636 No falla de forma segura (‘Fallo de apertura’), *
Tabla de puntuación.
| CWE mapeados | Tasa máxima de incidencia | Tasa de incidencia promedio | Cobertura máxima | Cobertura promedio | Exploit ponderado promedio | Impacto ponderado promedio | Total de ocurrencias | Total de CVEs |
| 24 | 20,67% | 2,95% | 100.00% | 37,95% | 7.11 | 3.81 | 769.581 | 3.416 |
Descripción.
La gestión inadecuada de condiciones excepcionales en el software ocurre cuando los programas no logran prevenir, detectar ni responder a situaciones inusuales e impredecibles, lo que provoca fallos, comportamientos inesperados y, en ocasiones, vulnerabilidades. Esto puede implicar una o más de las siguientes tres fallas: la aplicación no previene la ocurrencia de una situación inusual, no la identifica en el momento en que ocurre o responde de forma deficiente o nula a la situación posteriormente.
Las condiciones excepcionales pueden deberse a una validación de entrada incompleta, deficiente o faltante, a un manejo tardío de errores de alto nivel en las funciones donde ocurren, o a estados ambientales inesperados, como problemas de memoria, privilegios o red, manejo inconsistente de excepciones o excepciones que no se manejan en absoluto, lo que permite que el sistema caiga en un estado desconocido e impredecible. Cada vez que una aplicación no está segura de su siguiente instrucción, se ha manejado incorrectamente una condición excepcional. Los errores y excepciones difíciles de encontrar pueden amenazar la seguridad de toda la aplicación durante mucho tiempo.
Pueden ocurrir muchas vulnerabilidades de seguridad diferentes cuando gestionamos mal las condiciones excepcionales,
Como errores lógicos, desbordamientos, condiciones de carrera, transacciones fraudulentas o problemas con la memoria, el estado, los recursos, la sincronización, la autenticación y la autorización. Este tipo de vulnerabilidades puede afectar negativamente la confidencialidad, la disponibilidad o la integridad de un sistema o de sus datos. Los atacantes manipulan la gestión de errores defectuosa de una aplicación para aprovechar esta vulnerabilidad.
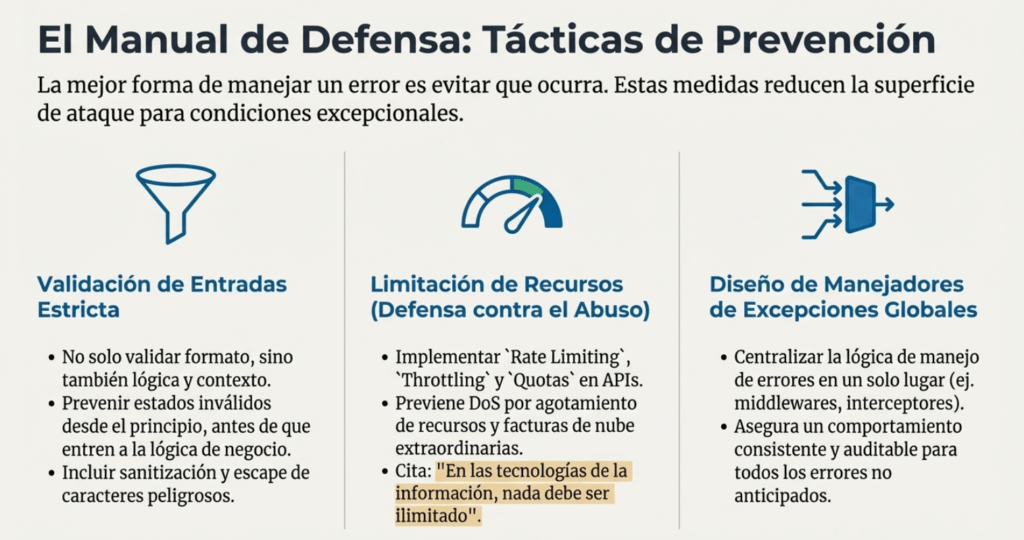
Cómo prevenir.
Para gestionar adecuadamente una condición excepcional, debemos planificar para tales situaciones (esperar lo peor). Debemos detectar cada posible error del sistema directamente donde ocurre y gestionarlo (lo que significa tomar medidas significativas para resolver el problema y asegurarnos de recuperarnos). Como parte del control, debemos incluir el lanzamiento de un error (para informar al usuario de forma comprensible), el registro del evento y la emisión de una alerta si lo consideramos justificado. También deberíamos contar con un gestor de excepciones global por si alguna vez se nos ha pasado por alto algo. Idealmente, también deberíamos contar con herramientas o funcionalidades de monitorización y/u observabilidad que detecten errores o patrones repetidos que indiquen un ataque en curso, que podría emitir una respuesta, defensa o bloqueo de algún tipo. Esto puede ayudarnos a bloquear y responder a scripts y bots que se centran en nuestras debilidades en el control de errores.
Detectar y gestionar condiciones excepcionales garantiza que la infraestructura subyacente de nuestros programas no se vea obligada a lidiar con situaciones impredecibles. Si se encuentra en medio de una transacción, es fundamental que la revierta por completo y la vuelva a iniciar (lo que se conoce como cierre fallido). Intentar recuperar una transacción a mitad de proceso suele ser el origen de errores irrecuperables.
Siempre que sea posible, agregue limitaciones de velocidad, cuotas de recursos, limitación y otros límites para evitar condiciones excepcionales desde el principio. En las tecnologías de la información, nada debe ser ilimitado, ya que esto conlleva falta de resiliencia de las aplicaciones, denegación de servicio, ataques de fuerza bruta exitosos y facturas de nube extraordinarias. Considere si los errores repetidos idénticos, por encima de una tasa determinada, solo deben mostrarse como estadísticas que muestren su frecuencia y el período de tiempo en que ocurrieron. Esta información debe adjuntarse al mensaje original para no interferir con el registro y la monitorización automatizados (véase A09:2025 Registro y alertas de fallos TJ).
Además, queremos incluir una validación de entrada estricta (con sanitización o escape para caracteres potencialmente peligrosos que debemos aceptar), gestión de errores, registro, monitorización y alertas centralizadas , y un gestor de excepciones global. Una aplicación no debería tener múltiples funciones para gestionar condiciones excepcionales; debe ejecutarse en un solo lugar y de la misma manera cada vez. También debemos crear requisitos de seguridad del proyecto para todos los consejos de esta sección, realizar modelado de amenazas o actividades de revisión de diseño seguro en la fase de diseño de nuestros proyectos, realizar revisiones de código o análisis estático, así como realizar pruebas de estrés, rendimiento y penetración del sistema final.
Si es posible, toda la organización debería manejar las condiciones excepcionales de la misma manera, ya que esto facilita la revisión y auditoría del código para detectar errores en este importante control de seguridad.
Ejemplos de escenarios de ataque.
Manejo de errores como defensa: blindaje ante fallos y vectores de reconocimiento
Uno de los pilares invisibles de la seguridad ofensiva y defensiva en aplicaciones modernas no es el cifrado, ni los headers HTTP, ni siquiera la autenticación multifactor. Es el manejo de errores. Y no porque sea glamoroso o esté de moda, sino porque cada error sin controlar es una mina de oro para el atacante en la fase de reconocimiento.
En la vida real, la mayoría de los ataques no arrancan con una shell remota. Empiezan con algo mucho más aburrido: fuzzers, requests malformadas, inputs inesperados y respuestas del servidor que vomitan más información de la que deberían. Stack traces, versiones de frameworks, rutas internas, fallas SQL, errores de conversión de tipos, respuestas 500 con detalles exquisitos. Todo eso son migas de pan que alimentan al atacante para preparar el plato principal.
El siguiente esquema muestra el enfoque objetivo:
El error como vector de enumeración
Cada vez que una aplicación lanza un error sin sanitizar, está entregando su carta de presentación al atacante. En muchos escenarios —sobre todo en APIs REST— esto significa:
- Exponer el tipo de framework (Spring Boot, Express.js, Django).
- Develar estructuras de clase internas, nombres de controladores y métodos.
- Mostrar SQLs con parámetros inyectables.
- Indicar rutas de instalación (D:\xampp\htdocs\app\index.php).
- Incluir stack traces de errores Java, .NET o PHP.
En entornos empresariales, ese tipo de filtraciones no solo rompe el modelo de seguridad por capas, sino que puede acelerar el time-to-exploit de un atacante con experiencia.
Responder sin hablar: la estrategia del error genérico
El enfoque moderno de manejo de errores seguro se puede resumir en una frase: «logar como si fueras paranoico, responder como si fueras sordo».
El objetivo es que el cliente (incluso si es malicioso) nunca obtenga un byte más de lo necesario, mientras que el equipo de seguridad pueda auditar cada detalle en backend para analizar lo que ocurrió. Es aquí donde entra el patrón de respuesta genérica + logging detallado, comúnmente implementado con middlewares globales o interceptores en cada stack tecnológico.
RFC 7807: la estructura para APIs que fallan con estilo
Para APIs REST modernas, la RFC 7807define un formato estándar para representar errores en JSON (application/problem+json). Esto permite que incluso los errores sigan siendo estructurados, predecibles y amigables para clientes legítimos, sin revelar detalles internos.
Un ejemplo básico:
{
«type»: «https://httpstatuses.com/500«,
«title»: «Internal Server Error»,
«status»: 500,
«detail»: «An unexpected error occurred. Please try again later.»,
«instance»: «/api/orders/checkout»
}
Este enfoque puede combinarse con cabeceras como X-ERROR: true para permitir que clientes reconozcan que la respuesta fue una excepción, sin necesidad de parsear todo el contenido.
Implementación práctica por stack
Dependiendo del lenguaje y framework, las estrategias cambian, pero el principio es siempre el mismo: interceptar excepciones globales, evitar filtraciones al cliente, registrar el error y devolver una respuesta neutral.
Java Web (Servlets tradicionales)
Se puede usar web.xml para capturar cualquier excepción no gestionada y redirigirla a una página específica:
<error-page>
<exception-type>java.lang.Exception</exception-type>
<location>/error.jsp</location>
</error-page>
Y dentro de error.jsp:
response.setStatus(500);
response.setHeader(«X-ERROR», «true»);
{«message»: «An error occurred, please retry»}
Spring Boot / Spring MVC
Uso de @RestControllerAdvice con @ExceptionHandler:
@RestControllerAdvice
public class GlobalErrorHandler extends ResponseEntityExceptionHandler {
@ExceptionHandler(Exception.class)
public ProblemDetail handleGlobalError(RuntimeException ex, WebRequest request) {
// log ex…
return ProblemDetail.forStatusAndDetail(HttpStatus.INTERNAL_SERVER_ERROR, «An error occurred»);
}
}
Compatible con application/problem+json de RFC 7807.
ASP.NET Core
Se define un controlador dedicado a errores:
[ApiController]
[Route(«api/error»)]
public class ErrorController : ControllerBase {
[Route(«»)]
public IActionResult Handle() {
var error = HttpContext.Features.Get<IExceptionHandlerFeature>()?.Error;
// log error…
return StatusCode(500, new { message = «An error occurred, please retry» });
}
}
Y se registra en Startup.cs:
if (!env.IsDevelopment()) {
app.UseExceptionHandler(«/api/error»);
}
ASP.NET Web API (Framework .NET clásico)
Uso de ExceptionLogger y ExceptionHandler:
public class GlobalErrorHandler : ExceptionHandler {
public override void Handle(ExceptionHandlerContext context) {
var result = new {
message = «An error occurred, please retry»
};
context.Result = new JsonResult(result, HttpStatusCode.InternalServerError);
}
}
Configurado en WebApiConfig.cs para interceptar todo.
Buenas prácticas para un manejo de errores seguro
- Nunca incluir stack traces, paths internos o mensajes crudos en la respuesta.
- Usar logs centralizados (en texto plano estructurado o JSON) para registrar detalles internos.
- Aplicar rate limiting en endpoints que devuelvan errores frecuentes.
- Clasificar errores 4xx vs 5xx correctamente. Los primeros implican errores del cliente, los segundos del servidor.
- No permitir que errores inesperados rompan el flujo general de la app: usar controladores de “último recurso” para capturar lo no gestionado.
Logging: el otro lado de la moneda
Este manejo de errores no es útil si los detalles no se registran correctamente. Asegurate de incluir en los logs:
- Timestamp UTC
- Endpoint accedido
- IP del cliente
- ID de sesión o usuario (si aplica)
- Stack trace completo (solo para backend)
- ID de correlación (para trazabilidad entre servicios)
Los logs deben ir a un sistema aislado, protegido y con retención adecuada para fines forenses.
A continuación se presentan algunas prácticas recomendadas que le ayudarán a adoptar excepciones y aprovecharlas y sus capacidades para mantener su código mantenible , extensible y legible :
- Mantenibilidad : Nos permite encontrar y corregir fácilmente nuevos errores, sin el temor de romper la funcionalidad actual, introducir más errores o tener que abandonar el código por completo debido al aumento de la complejidad a lo largo del tiempo.
- Extensibilidad : Nos permite ampliar fácilmente nuestra base de código, implementando requisitos nuevos o modificados sin afectar la funcionalidad existente. La extensibilidad proporciona flexibilidad y permite un alto nivel de reutilización de nuestra base de código.
- Legibilidad : Nos permite leer fácilmente el código y descubrir su propósito sin tener que invertir demasiado tiempo en analizarlo. Esto es fundamental para detectar errores y código no probado de forma eficiente.
Estos elementos son los factores principales de lo que podríamos llamar limpieza o calidad , que no es una medida directa en sí misma, sino que es el efecto combinado de los puntos anteriores, como se demuestra en este cómic:

El manejo de errores no es solo una cuestión de UX o estabilidad, sino de seguridad pura. Cada error mal gestionado es una oportunidad para el atacante, ya sea para recopilar datos, construir un exploit, o simplemente para inferir lógica interna del sistema. Las aplicaciones modernas deben responder con elegancia, fallar con seguridad y registrar con precisión.
Cuando un atacante provoca un error, que lo único que obtenga sea una respuesta genérica y silenciosa. Pero en tu backend, que explote una alarma.
Manejo de errores como mecanismo de defensa
En el diseño de aplicaciones seguras, el manejo de errores no es solo un problema técnico: es una estrategia de defensa. Una mala gestión de errores expone detalles internos, rompe flujos críticos y facilita ataques dirigidos, mientras que una buena implementación refuerza la resiliencia y limita el poder del atacante en la fase de reconocimiento.
Objetivo
- Evitar que los errores muestren detalles internos al cliente (como stack traces, rutas, queries SQL).
- Registrar los errores relevantes para análisis y respuesta a incidentes.
- Proteger los registros contra manipulación o acceso no autorizado.
- Asegurar que la aplicación falle de forma elegante y segura.
- Cumplir con estándares como OWASP ASVS V16y las mejores prácticas de Microsoft o NIST.
Requisitos de seguridad para manejo de errores y registros (según ASVS V16)
Los requisitos están organizados en cinco bloques principales:
| Bloque | ¿Qué exige? |
| V16.1 | Tener un inventario completo de qué eventos se registran, dónde y cómo se protegen. |
| V16.2 | Estructura coherente en los logs: metadatos, timestamps UTC, formatos comunes. |
| V16.3 | Registro obligatorio de eventos de seguridad: autenticación, autorización, bypass de controles, fallos críticos. |
| V16.4 | Protección del log: sin acceso directo, cifrado, separación de contextos, sin inyección. |
| V16.5 | Fallar de forma controlada: mensajes genéricos, capturar excepciones no gestionadas, evitar exposure de datos. |
Arquitectura de defensa: errores controlados y logueo estructurado
Toda la lógica de manejo de errores debe seguir este flujo:
[Error inesperado]
↓
[Interceptación global]
↓
[Log estructurado: UTC + ID + stack trace]
↓
[Respuesta genérica al usuario → HTTP 500]
Esto permite que los errores sirvan para monitoreo y auditoría, no para enumeración o explotación.
Errores que nunca deben exponerse al cliente
- Stack traces
- Paths del servidor (e.g., D:\inetpub\wwwroot\app\index.aspx)
- Excepciones de acceso a archivos
- Detalles de la conexión DB
- SQLs con parámetros mal construidos
- Frameworks y versiones (e.g., «Spring Boot 2.7.1»)
Diseño inteligente para prevenir errores
De acuerdo con las mejores prácticas de Microsoft:
- Evita lanzar excepciones innecesarias: usa TryParse, TryGetValue, etc.
- No abuses de excepciones para control de flujo: son costosas y ruidosas.
- Validación de argumentos antes de código asíncrono: en métodos async, valida todo antes del await.
- Usa throw correctamente: throw; conserva el stack trace; throw ex; lo pierde.
- No lances desde finally ni métodos como Equals o ToString.
- Restaurar el estado si la operación falla: uso de try/catch + rollback para transacciones parciales.
Ejemplo práctico: .NET (ASP.NET Core)
Controlador de errores global:
[ApiController]
[Route(«api/error»)]
[AllowAnonymous]
public class ErrorController : ControllerBase {
[HttpGet, HttpPost, HttpPut, HttpDelete]
public IActionResult Handle() {
var exception = HttpContext.Features.Get<IExceptionHandlerFeature>()?.Error;
// Log detallado: timestamp, IP, endpoint, usuario, stacktrace
return StatusCode(500, new { message = «An error occurred, please retry» });
}
}
Middleware en Startup.cs:
if (!env.IsDevelopment()) {
app.UseExceptionHandler(«/api/error»);
app.UseStatusCodePages(«text/plain», «Status code page: {0}»);
}
Formato estándar de error: RFC 7807
{
«type»: «https://httpstatuses.com/500«,
«title»: «Internal Server Error»,
«status»: 500,
«detail»: «An unexpected error occurred. Please try again later.»,
«instance»: «/api/user/update»
}
Ideal para APIs REST. Siempre acompañar con cabecera:
X-ERROR: true
Reglas de oro para proteger registros
- Solo loguear lo necesario. Nunca passwords, tokens ni tarjetas.
- Siempre con timestamps UTC, formato JSON y rotación diaria.
- Cifrado en tránsito (TLS) y en reposo.
- Almacenamiento en servidor independiente (mejor aún: SIEM).
- Proteger contra modificación (WORM, write-once).
- Sanitizar entradas para evitar log injection.
Checklist de implementación segura
| Ítem | Estado |
| [ ] Controlador de error global implementado | |
| [ ] Respuestas genéricas en todos los endpoints | |
| [ ] Logs estructurados con protección y rotación | |
| [ ] Excepciones controladas y mensajes localizados | |
| [ ] Validación temprana de entradas (sin excepciones innecesarias) | |
| [ ] Captura de excepciones no gestionadas (last resort handler) | |
| [ ] Pruebas de seguridad para error disclosure (ZAP, Burp) |
El manejo de errores es más que una tarea de debugging: es una capa activa de defensa que reduce la superficie de ataque, dificulta la recolección de información y mejora la resiliencia general del sistema. Una aplicación segura no es la que nunca falla, sino la que falla sin delatarse.
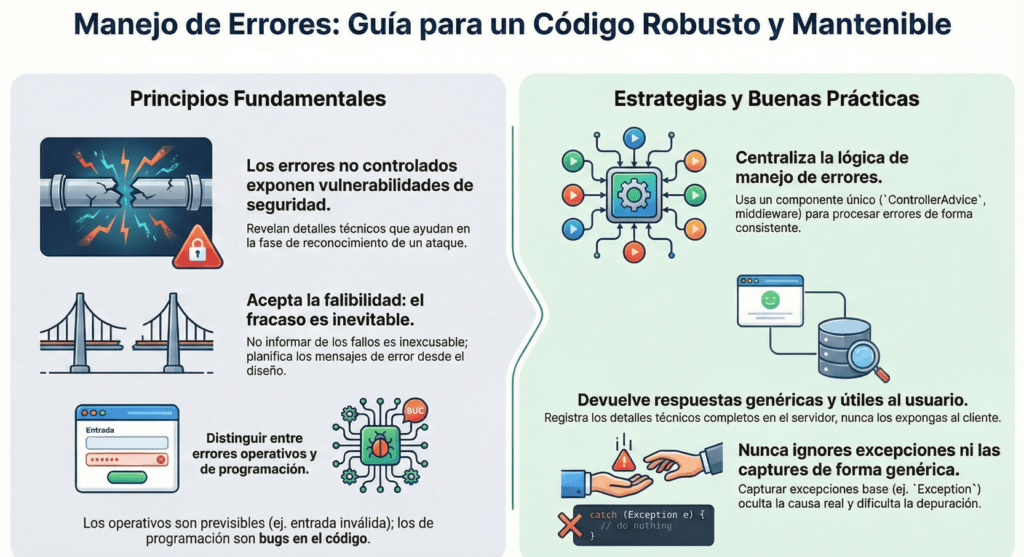
Excepciones bien diseñadas: el arte de fallar con elegancia, seguridad y control
El manejo de excepciones ha sido históricamente una de las áreas más ignoradas y maltratadas en la ingeniería de software. Muchas veces, porque “funciona”, no se cuestiona su diseño. Pero cuando ocurre un fallo real, es ahí cuando descubrimos lo frágil que puede ser todo si las excepciones están mal gestionadas.
Las excepciones no son un problema. El problema es ignorarlas, atraparlas indiscriminadamente o lanzarlas sin pensar.
Este artículo recorre una visión moderna, limpia y segura del manejo de errores y excepciones. Vamos a hablar de arquitectura, calidad de código, principios DRY, extensibilidad, e incluso seguridad. Porque en el fondo, el manejo correcto de excepciones es una defensa proactiva contra la entropía del sistema.
Excepciones: la espada de doble filo
Las excepciones existen porque los sistemas fallan. Y cuando lo hacen, necesitamos saber qué falló, por qué, cuándo y dónde. Pero también necesitamos que eso no implique romper toda la experiencia del usuario, ni exponer detalles internos.
Una excepción no gestionada:
- Puede revelar detalles sensibles (stack traces, rutas, configuración).
- Puede dejar un sistema en un estado inconsistente.
- Puede provocar fallos en cascada.
Una excepción mal atrapada:
- Puede ocultar el problema real.
- Puede romper el principio de fail-fast.
- Puede generar una falsa sensación de seguridad.
Una excepción bien diseñada:
- Comunica el fallo de forma clara y estructurada.
- Permite recuperarse o registrar el incidente.
- Mantiene el sistema íntegro, incluso cuando algo sale mal.
Arquitectura limpia: jerarquías de excepciones personalizadas
Una de las mejores prácticas que muchos ignoramos es la creación de un árbol de excepciones personalizado, propio de la aplicación. En lugar de usar sólo RuntimeException, ArgumentException o Error, deberías crear tus propias clases como:
class ApplicationError < StandardError; end
class ValidationError < ApplicationError; end
class RequiredFieldError < ValidationError; end
class AuthError < ApplicationError; end
class TokenExpiredError < AuthError; end
¿Por qué? Porque esto mejora legibilidad, mantenibilidad y extensibilidad. Basta de rescue Exception => e genéricos que capturan más de lo debido. Con una jerarquía clara, sabés exactamente qué querés capturar, dónde, y con qué semántica.
Una jerarquía bien diseñada:
- Permite capturar errores de forma más precisa y semántica.
- Hace tu código más expresivo (rescue AuthError habla más que rescue => e).
- Te permite escalar sin romper todo: agregar un nuevo tipo de error no implica cambiar 20 controladores.
DRY aplicado a excepciones: manejá errores en el lugar correcto
Otra mala costumbre común: manejar la excepción demasiado pronto, donde ocurre, y no donde corresponde.
Evitá el antipatrón del rescue inmediato. Muchos errores deben dejarse propagar para ser tratados en un lugar centralizado, especialmente en controladores, middleware o filtros.
En Rails, por ejemplo, en lugar de repetir esto:
def create
@user = User.new(params)
if @user.save
render json: @user
else
render json: @user.errors
end
end
Usás:
def create
@user = User.create!(params)
render json: @user
end
Y en ApplicationController capturás la excepción:
rescue_from ActiveRecord::RecordInvalid, with: :render_unprocessable_entity
def render_unprocessable_entity(e)
render json: { errors: e.record.errors }, status: 422
end
Este patrón centraliza la lógica de errores, mejora la coherencia y facilita los cambios futuros.
Antipatrones fatales en el manejo de excepciones
- rescue Exception
Nunca, bajo ningún motivo. Capturar Exception es como apagar la alarma de incendio para que no te moleste el sonido. No sólo atrapa errores fatales (NoMethodError, SyntaxError, SystemExit), también oculta bugs que deberían explotar. - Manejar más de lo necesario
Capturar todo, “por si acaso”, es una receta para la opacidad. Capturá sólo lo que esperás y sabés cómo manejar. Dejá que lo demás burbujee hasta un handler superior. - Re-lanzar mal (throw ex)
En .NET, por ejemplo, relanzar la excepción original con throw ex pierde el stack trace. Siempre usá throw; o ExceptionDispatchInfo si querés mantener la traza original. - Logging sin control
Registrar una excepción no implica usar Logger.log(exception.to_s) y olvidarte. Necesitás contexto, request ID, usuario, endpoint, etc. Y asegurarte de no registrar datos sensibles.
Seguridad: cómo las excepciones pueden romper tu modelo de amenazas
Una excepción mal gestionada puede convertirse en un vector de ataque:
- Information Disclosure: Mostrar el error exacto al cliente (stacktrace, SQL error, etc.).
- Inyección de logs: Si los logs no están sanitizados, un atacante puede insertar entradas maliciosas.
- Denegación de servicio: Un error silencioso puede propagarse y bloquear el sistema.
- State corruption: Una excepción que corta una transacción sin rollback explícito.
Buenas prácticas de defensa:
- Nunca expongas excepciones internas al cliente.
- Siempre sanitizá los logs.
- Aplicá rollback manual si el proceso es interrumpido.
- Usá respuestas estándar: HTTP 500 con JSON RFC 7807.
- Usá mecanismos como circuit breakers para prevenir fallas repetidas.
Filosofía del “fail fast” y “fail safe”
- Fail fast: Cuando algo va mal, fallá temprano y con fuerza. No sigas con un sistema en estado inconsistente.
- Fail safe: Aunque falle, el sistema debe seguir siendo seguro. Mejor desconectar al usuario que permitir corrupción o fuga de datos.
Tips de ingeniería avanzada
- Evitá lanzar excepciones para control de flujo normal: preferí TryParse, TryGetValue, Maybe, Either.
- No uses excepciones en finally.
- Usá métodos auxiliares para lanzar errores comunes (NewFileIOException() en .NET).
- En APIs, seguí la convención de Google para errores: estructura, códigos, mensajes localizados.
- Agregá contexto a los logs: IP, usuario, token, ID de request, etc.
- No silencies errores en producción sin registrarlos. Nunca.
Una arquitectura de excepciones bien diseñada no es opcional. Es esencial para aplicaciones que aspiran a ser mantenibles, seguras y robustas. Desde la jerarquía hasta los patrones DRY, desde la captura precisa hasta los logs estructurados, cada decisión suma o resta al control que tenés sobre tu código cuando todo se rompe.
Manejar excepciones correctamente no significa evitar que ocurran. Significa fallar de forma controlada, segura y consciente.
Los errores más comunes en Java que siguen acechando a los desarrolladores
Java es un lenguaje que ha sobrevivido generaciones enteras, desde servidores corporativos en los 2000 hasta microservicios modernos en la nube. Pero aunque la plataforma ha evolucionado —con nuevas APIs, mejoras en el recolector de basura y la introducción de características como lambdas o módulos—, los errores que cometen los desarrolladores no han cambiado tanto. De hecho, algunos siguen siendo los mismos que hace veinte años. Solo que ahora ocurren más rápido, en producción, y escalan mal.
Este artículo no es una checklist aburrida. Es un recorrido con mentalidad ofensiva y defensiva sobre los errores de Java que todavía son trampas frecuentes, incluso para equipos experimentados. Si estás metido en código todos los días, esto es para vos.
Ignorar bibliotecas existentes: reinventar la rueda, pero cuadrada
El primer error es no buscar soluciones existentes antes de escribir código. Java tiene más de 20 años de ecosistema. Hay bibliotecas para todo: registro, fechas, seguridad, concurrencia, validación, parsers, encoding, etc. Aún así, muchos programadores siguen escribiendo desde cero funciones para escapar HTML, generar UUIDs o parsear fechas. Y lo hacen mal. Y lento. Y sin tests.
Por ejemplo, crear un escaper de HTML personalizado puede parecer trivial… hasta que un input raro lo rompe, y el sistema entra en bucle infinito, acaparando todos los hilos del servidor. Eso pasó en un caso real. ¿La solución? Usar HtmlEscapers de Guava o Apache Commons Lang. Probadas, auditadas, seguras.
El consejo de hacker: Usá librerías maduras. No seas tu propia vulnerabilidad.
Switch sin break: un clásico explosivo
Otro clásico que no muere: olvidar el break en un switch. Parece menor, pero si no querés que todos los case se ejecuten en cascada, tenés que cortar el flujo. Esto en producción puede llevar a comportamientos erráticos, especialmente cuando el valor del case depende de un input del usuario.
¿La alternativa moderna? Polimorfismo. Si tenés más de dos o tres casos, probablemente tu switch esconde una oportunidad de aplicar OOP correctamente. Encapsulá la lógica en objetos. No repitas estructuras primitivas para decidir qué hacer.
El consejo de hacker: Cada vez que ves un switch, pensá si debería ser un objeto.
Olvidar cerrar recursos: fuga silenciosa y letal
Los recursos como archivos, sockets o conexiones deben cerrarse siempre. Pero muchos desarrolladores todavía dependen de los finalizers o del garbage collector. Y eso es confiar en magia negra. Porque el GC no garantiza cuándo se ejecuta (o si se ejecuta).
Desde Java 7, tenés try-with-resources, que cierra automáticamente lo que implementa AutoCloseable. No hay excusa. Incluso frameworks modernos como Spring, Micronaut o Quarkus hacen uso intensivo de este patrón. Ignorarlo es permitir fugas de memoria, locks sin liberar y errores intermitentes.
El consejo de hacker: Nunca dejes recursos abiertos. Ni siquiera por accidente.
Fugas de memoria: cuando el GC no te salva
Java tiene recolector de basura. Pero eso no te salva de hacer mal las cosas. Una fuga de memoria en Java no significa que no se libere algo. Significa que tu código mantiene referencias vivas a objetos que ya no se usan.
Las colecciones estáticas, los Executors mal cerrados o los listeners que nunca se desregistran son fuentes comunes de fugas. Un ejemplo típico: una cola que crece indefinidamente porque se usan métodos como peekLast() en lugar de pollLast(). Lo peor es que este tipo de errores no explota de inmediato: explota después de un tiempo, en producción, con el sistema colapsado.
El consejo de hacker: Monitoreá el heap. Mirá los dominadores de objetos. Si algo crece sin control, tenés un memory leak.
Generar basura: destruir el rendimiento sin darte cuenta
Java permite crear objetos sin fricción, pero eso no significa que debas hacerlo en cada iteración de un loop. El ejemplo clásico es concatenar strings en un bucle con +. Eso genera miles de objetos intermedios, porque las strings son inmutables.
Usá StringBuilder. O mejor aún: no armes strings si no las necesitás.
El consejo de hacker: Cada asignación innecesaria es una microbomba de latencia. Evitá el garbage.
Usar null como herramienta de diseño: el antipatrón silencioso
null no es un valor. Es una trampa. Invocar métodos sobre objetos null es una de las causas más comunes de fallos. ¿La solución? No devuelvas null si podés devolver una colección vacía. No pases null si podés pasar un Optional.
Y sí, Optional tiene un costo, pero es explícito. Hace visible en el código qué es opcional y qué no. Y previene bugs.
El consejo de hacker: Si tu método devuelve null, estás exponiendo a todos los que lo usan. No los traiciones.
Ignorar excepciones: matar el stacktrace y rogar por milagros
Otra mala práctica común es capturar excepciones sin manejarlas. Ver un catch (Exception e) {} vacío es como encontrar un campo minado sin señales. Todo puede explotar sin que nadie se entere.
Si una excepción no es relevante, al menos logueala. Si lo es, actuá en consecuencia. Y si es parte del flujo normal, entonces no debería ser una excepción.
El consejo de hacker: Toda excepción ignorada es un incidente sin diagnóstico.
ConcurrentModificationException: lo sabías, pero igual pasó
Modificar una colección mientras la iterás genera errores. Java no lo permite por diseño. Y sin embargo, lo sigue haciendo gente que debería saberlo.La solución es simple: usá un iterador explícito y llamá a remove() desde ahí. O armá una nueva colección filtrada. O, si realmente lo necesitás, usá estructuras thread-safe como CopyOnWriteArrayList.
¿Querés evitarlo para siempre? Usá removeIf, stream().filter() o ListIterator.set() si tenés que mutar en medio de la iteración.
El consejo de hacker: No modifiques mientras caminás. Primero observá, después actuá.
Romper contratos: equals y hashCode mal implementados
Si vas a meter objetos en un HashSet o HashMap, implementá correctamente equals() y hashCode(). De lo contrario, tu objeto puede estar en el mapa, pero nunca lo vas a encontrar. Y no, no va a tirar error. Solo va a fallar en silencio.
Regla de oro: si dos objetos son iguales, sus códigos hash deben ser iguales. Usá Objects.hash() o librerías como Lombok si te da fiaca hacerlo bien.
El consejo de hacker: Un objeto que rompe equals/hashCode es una promesa rota. Y las promesas rotas explotan.
Usar tipos sin parametrizar: herencia del pasado
Los generics existen desde Java 5. Aún así, todavía se ven List lista = new ArrayList(); en código nuevo. Eso no solo anula el sistema de tipos: lo convierte en una trampa de runtime, con ClassCastException en lugares inesperados.
Siempre usá List<String> o el tipo que corresponda. Te ahorrás bugs, te ayuda el compilador y dejás claro qué tipo de datos estás manejando.
El consejo de hacker: Si no decís el tipo, Java lo va a adivinar. Y va a fallar.
Java es poderoso. Pero como cualquier lenguaje, su fortaleza depende de cómo lo uses. Estos errores no son bugs de principiantes: son patrones que aparecen una y otra vez incluso en empresas grandes. La diferencia entre un sistema robusto y uno frágil muchas veces está en los pequeños detalles: cerrar un recurso, evitar null, respetar contratos, delegar en librerías confiables, etc.
Si escribís Java en serio, aprendé a no cometer estos errores. O aprendé a detectarlos rápido. Porque en producción, no importa si el código está «bien escrito» si falla en silencio.
Y recordá: la experiencia no es cuántas líneas escribiste, sino cuántos errores aprendiste a evitar.
HTML y CSS siguen importando
Parece una locura tener que decirlo en 2025, pero sí: escribir buen HTML y CSS sigue siendo importante. Y no solo importante, es crucial. En un ecosistema donde los frameworks dominan, donde muchos desarrolladores nunca escribieron una etiqueta <figure> o un @media a mano, se pierde algo esencial: la comprensión real del frontend.
He visto demasiadas veces a ingenieros con años de experiencia incapaces de escribir una estructura HTML semántica o de componer estilos sin contaminar todo el DOM. En proyectos grandes, eso escala mal. Muy mal. Y cuando llega el día del incidente, el problema no era React, ni Tailwind, ni Bootstrap. El problema era que nadie sabía escribir código limpio en las bases: HTML y CSS.
En este artículo te voy a mostrar por qué seguir estas prácticas no es anticuado ni innecesario. Es hackerismo aplicado a la interfaz: una manera de trabajar que mejora la mantenibilidad, el rendimiento, la accesibilidad y la capacidad de depurar lo que en el fondo es lo más expuesto de toda tu aplicación.
Código sucio: la deuda técnica invisible
El código fuente es como una hipoteca. No lo ves, pero lo pagás cada día. Cada div innecesario, cada clase mal nombrada, cada regla CSS global que pisa a otra, te genera una deuda invisible que crece con cada cambio, con cada nueva feature, con cada integrante nuevo del equipo que tiene que entender ese caos para poder avanzar.
No es cuestión de obsesión. Es cuestión de sobrevivir en producción sin que cada push sea una ruleta rusa.
HTML limpio empieza por entender el marcado
Uno de los errores más comunes es pensar que HTML es solo «estructura básica» y que no importa cómo se escriba porque “total, el framework lo maneja”. Grave error. HTML es la base semántica del frontend. Si la escribís mal, todo lo demás se rompe.
Un HTML bien construido usa etiquetas correctas (<main>, <article>, <figure>, <header>, <footer>, etc.), evita envoltorios innecesarios, elimina redundancia, y prioriza el contenido.
¿Para qué meter <div class=»img-wrapper»> cuando podés usar <figure> con <figcaption>? ¿Para qué un <span class=»bold»> cuando ya existe <strong>? ¿Para qué un h1 con clase .main-title dentro de un div con .title-container cuando podés estructurar correctamente con un section > h1?
Y la accesibilidad ni hablar. Si no sabés usar alt en imágenes, aria-label, o ni siquiera validás tu HTML con W3C Validator, estás dejando afuera a miles de usuarios, además de arruinar el SEO.
CSS bien escrito: precisión quirúrgica, no spray de estilos
CSS no es solo “hacerlo lindo”. Es un lenguaje de control visual del DOM. Y como tal, debe ser específico, coherente y limpio. Veo errores todos los días: usar !important como si fuera una goma de borrar, declarar margin-top, margin-right, margin-bottom, margin-left en vez de usar margin: 10px 15px, mezclar camelCase con snake_case y kebab-case, definir fuentes y colores a mano en cada componente como si no existiera la herencia.
¿Querés CSS limpio? Empezá por esto:
- No repitas reglas. Reutilizá clases.
- Escribí atómicamente. Una clase, una responsabilidad.
- Usá preprocesadores como Sass para mantener estructuras anidadas y evitar redundancia.
- Agrupá variables y mantené todo en archivos separados: colores, spacing, fuentes.
- Usá rem en vez de px para que tu sitio escale con facilidad.
- No pongas altura fija a nada que pueda variar por contenido. Usá padding, min-height, flex.
CSS no es el enemigo. El enemigo es escribirlo como si fuera opcional.
Convenciones y nombres: el código es para humanos
Tu código no lo va a leer una IA. Lo va a leer otra persona. Y posiblemente dentro de 6 meses seas vos, odiando tu yo del pasado por haber escrito .btnGreenLgSecondaryWrapper. Los nombres importan. Usá convenciones simples: text-primary, bg-secondary, btn-lg. Nombres descriptivos, consistentes y reutilizables.
Y por favor, elegí una convención y mantenela. Si usás kebab-case, que todo sea así. Si usás BEM (block__element–modifier), seguí esa lógica. Mezclar camelCase, snake_case y clases mágicas sólo rompe la legibilidad.
Bootstrap, Tailwind, frameworks: herramientas, no muletas
Usar Bootstrap no significa que puedas olvidarte del HTML. Usar Tailwind no te da permiso para ensuciar el marcado con veinte clases por elemento sin pensar. Estos frameworks son aceleradores, no reemplazos del entendimiento. Tenés que saber cómo y por qué funcionan.
Si Bootstrap ofrece una clase, usala. No sobreescribas el container con un width: 1300px cuando podés modificar la variable $container-lg. Si usás Tailwind, usá los utilities como deben usarse, pero sabiendo cuándo conviene usar un componente en lugar de repetir veinte veces text-blue-500 p-4 mb-3.
El código limpio también es saber cuándo no escribir código.
HTML semántico = SEO + accesibilidad + rendimiento
El marcado correcto hace que los motores de búsqueda entiendan mejor tu contenido. Pero también permite que los screen readers puedan leer correctamente la estructura. Y no es sólo ética: es negocio. Google prioriza sitios accesibles. Punto.Además, un HTML bien estructurado pesa menos, carga más rápido y necesita menos CSS para estilizar. Menos reglas, menos conflicto, menos bugs.
Errores comunes que siguen matando código hoy
- Usar <img> sin alt: rompe accesibilidad y SEO.
- Poner <summary> dentro de un <header>: no es válido.
- Usar 0px, 0em, 0%… cuando 0 es suficiente.
- Redefinir reglas globales cuando podés usar una clase.
- Poner bordes en <p> con CSS en lugar de usar <hr> si lo que querés es separar secciones.
- Escribir tres clases para lo mismo que podrías hacer con una variable SCSS.
Pensá en grande, escribí en chico
El frontend moderno requiere pensar en sistemas. Pero esos sistemas se construyen con líneas de código que alguien tiene que escribir. Y si esas líneas están mal escritas desde el comienzo, todo lo que construyas encima va a ser más frágil. La clave está en la base: HTML y CSS bien hechos.
Como hacker de interfaces, tu objetivo no es solo que algo “funcione”. Es que funcione, se entienda, se mantenga y se pueda escalar. Y eso se logra escribiendo limpio desde el principio.
En un mundo lleno de frameworks mágicos, animaciones asombrosas y librerías que hacen de todo, el verdadero senior es el que puede volver a lo básico y escribir un HTML perfecto, un CSS claro y un sistema que funcione sin necesidad de JavaScript.
El código limpio no es moda. Es supervivencia.
Construyendo un sistema sólido de manejo de errores en Node.js como un hacker de backend
Si trabajás con Node.js en serio, tarde o temprano vas a enfrentarte con uno de los problemas más subestimados y destructivos en backend: el mal manejo de errores. Cuando el código empieza a escalar, cuando hay múltiples puntos de entrada a la app, cuando las promesas fallan sin ser gestionadas, cuando una propiedad es undefined y explota todo en producción, es cuando entendés que manejar errores no es opcional, es supervivencia.
Y sin embargo, el código de miles de backends por ahí sigue plagado de console.log(error) y try/catch desorganizados, sin estrategia, sin distinción entre errores operativos y errores de desarrollo. Lo he visto en APIs críticas, en microservicios, en sistemas bancarios. Siempre igual: logs incompletos, errores silenciosos y sistemas que caen por una excepción que nadie esperaba.
Así que vamos a hacer esto bien. Te voy a mostrar cómo construir, desde la base, un sistema de manejo de errores robusto, modular y profesional en Node.js. No sólo para que no se rompa todo, sino para que cuando se rompa, tengas el control total del desastre.
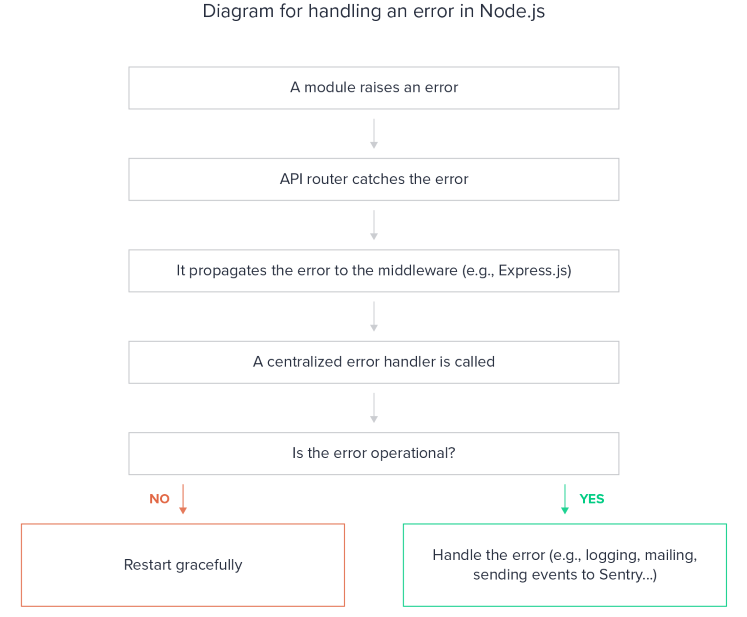
Entendé lo más importante: no todos los errores son iguales
El primer paso de cualquier sistema sólido de errores es entender que no todos los errores se manejan igual. Hay que diferenciar dos tipos:
- Errores operativos: son fallos esperables, como un archivo que no se encuentra, un request mal formado, una conexión de red perdida. No es un bug, es parte del entorno. Se pueden manejar sin pánico.
- Errores de programación: son bugs reales. Acceder a una propiedad de undefined, dividir por cero, mal uso de promesas. Acá tenés que arreglar el código, no “manejar” el error.
Si metés todo en la misma bolsa, vas a cometer dos pecados: vas a reiniciar la app cuando no hace falta, o peor, vas a dejar viva una app con un bug crítico sin darte cuenta.
El error tiene forma: definilo como un objeto real
Node.js viene con el objeto Error por defecto, pero es completamente extensible. Así que vamos a crear una clase base, bien tipada, para representar errores con más contexto:
class BaseError extends Error {
public readonly name: string;
public readonly httpCode: HttpStatusCode;
public readonly isOperational: boolean;
constructor(name: string, httpCode: HttpStatusCode, isOperational: boolean, description: string) {
super(description);
Object.setPrototypeOf(this, new.target.prototype);
this.name = name;
this.httpCode = httpCode;
this.isOperational = isOperational;
Error.captureStackTrace(this);
}
}
Y luego la extendés para crear errores comunes como:
class APIError extends BaseError {
constructor(name: string, httpCode = HttpStatusCode.INTERNAL_SERVER, isOperational = true, description = ‘Internal server error’) {
super(name, httpCode, isOperational, description);
}
}
Así podés hacer cosas como:
throw new APIError(‘USER_NOT_FOUND’, 404, true, ‘User not found in database’);
Ahora tenés errores tipados, estructurados, con HTTP status codes y flags para decidir si el sistema puede seguir corriendo o si hay que cortar todo.
El middleware de errores: tu firewall interno
Un sistema serio de manejo de errores en Node tiene que tener un middleware centralizado. Este middleware es el único punto por donde pasan todos los errores antes de responderle algo al cliente. Eso te permite:
- No repetir lógica de manejo en cada ruta
- Filtrar errores operativos de los fatales
- Loguear todo de forma uniforme
- Integrar Sentry, Rollbar, etc.
- Mandar alertas si algo grave pasa
El flujo es así: la ruta falla → lanza un error → next(error) → llega al middleware → se decide qué hacer.
app.use(async (err: Error, req: Request, res: Response, next: NextFunction) => {
if (!errorHandler.isTrustedError(err)) {
next(err); // puede llevar a process.exit()
}
await errorHandler.handleError(err);
});
El core del sistema: tu ErrorHandler
Este componente es el cerebro del sistema. Decide qué se loguea, qué se ignora, qué se notifica, y cuándo hay que matar la app.
class ErrorHandler {
async handleError(err: Error): Promise<void> {
await logger.error(‘Error from centralized handler’, err);
await sendToSentry(err);
await notifyAdmin(err);
}
isTrustedError(error: Error): boolean {
return error instanceof BaseError && error.isOperational;
}
}
Y sí, si no es un error “confiable”, salimos del proceso:
process.on(‘uncaughtException’, (error: Error) => {
errorHandler.handleError(error);
if (!errorHandler.isTrustedError(error)) {
process.exit(1);
}
});
¿Y las promesas?
Bienvenido al infierno moderno: promesas no gestionadas.
process.on(‘unhandledRejection’, (reason: Error, promise: Promise<any>) => {
throw reason;
});
Este patrón redirige todas las promesas no atrapadas hacia el mismo flujo que las excepciones sin capturar. Es un escudo total para bugs silenciosos.
Logging serio con Winston
Nunca, jamás, deberías depender de console.log() en producción. Un sistema serio usa Winston (o Pino) con configuración personalizada:
const logger = winston.createLogger({
level: isDev ? ‘debug’ : ‘error’,
levels: customLevels.levels,
transports: [
new winston.transports.Console({ format }),
new winston.transports.File({ filename: ‘logs/error.log’, level: ‘error’ }),
],
});
Con colores en dev, y archivos persistentes en prod. Y si querés ir más allá: integralo con herramientas de análisis, dashboards de observabilidad, o alertas por Telegram o Slack. El logging es tu único rastro post-mortem cuando todo falla.
Reinicio limpio con PM2
Cuando un error es de programación y no se puede continuar, la app debe reiniciarse. Acá entra PM2, que mantiene tu app viva sin downtime:
pm2 start app.js –watch
Y si process.exit(1) se ejecuta, PM2 revive la app automáticamente.
No solo capturar, actuar
Una app resiliente no es la que nunca falla. Es la que falla y se recupera sola. Con este sistema, vos decidís:
- Qué errores se reportan al cliente (sin filtrar stacktraces por error)
- Qué errores se loguean internamente (con contexto y trazabilidad)
- Qué errores disparan alertas (solo los graves)
- Cuándo cortar la app antes de que corrompa el estado
Este nivel de control te da poder real sobre tu backend.
Errores como arquitectura, no como accidente
La mayoría de los devs siguen tratando los errores como un accidente, como un “por si acaso”. Pero los hackers del backend sabemos que el error es una dimensión más de la arquitectura. Es parte del diseño del sistema, como el modelo de datos o el esquema de rutas.
Manejar los errores con un sistema sólido:
- Hace tu backend más mantenible
- Evita efectos en cascada por fallos inesperados
- Protege la experiencia del usuario
- Mejora los logs y la observabilidad
- Te ahorra horas de debugging en producción
Y, sobre todo, te da control total cuando todo sale mal. Y eso es lo que define a un backend bien hecho.
A10:2025 – Manejo Inadecuado de Condiciones Excepcionales
Es una nueva categoría que une varias debilidades históricas relacionadas con:
- errores en el manejo de fallos de la aplicación
- casos de borde no contemplados
- estados anormales
- fallos lógicos en condiciones inesperadas
- “fail-open” (fallar abierto)
- manejo defectuoso de errores, timeouts, retry o fallos de servicios externos
- divulgación accidental de información sensible mediante mensajes de error
Es básicamente todo comportamiento inseguro que ocurre cuando la aplicación se enfrenta a una situación no prevista.
Esta categoría incluye CWE como:
- CWE-209 (exposición de info en mensajes de error)
- CWE-234 (manejo incorrecto de parámetros faltantes)
- CWE-274 (manejo inseguro de privilegios insuficientes)
- CWE-476 (null pointer dereference)
- CWE-636: Fail-open (la más peligrosa)
🧩 Ejemplos típicos (2025)
- Autorización que falla “abierta” cuando un microservicio no responde (“si no responde, permito todo”).
- Login que queda bypasseado si un campo viene nulo o vacío.
- API que no valida parámetros faltantes y asume defaults peligrosos.
- Errores internos que devuelven stack traces completos.
- Microservicio que cae y provoca que el API Gateway deje pasar requests críticas.
- Timeouts mal manejados que permiten repetir o saltar validaciones.
- Excepción no controlada → aplicación expone framework, rutas internas, secrets en logs.
- Sistemas de verificación que, ante error, dan acceso (fail-open).
- Procesos de pago donde un fallo intermedio deja transacciones a medias o inconsistentes.
- Validación de privilegios incorrecta ante condiciones inesperadas.
- Estado inconsistente por condiciones de carrera o interrupciones.
- Lectura de archivos inexistentes → respuestas con paths internos.
🔍 Mini-guía de explotación (pentesting 2025)
- Romper flujos con valores nulos:
- null, «», undefined, {}
- Forzar timeouts (cortar la conexión a propósito).
- Enviar parámetros faltantes para ver si asume defaults peligrosos.
- Interrumpir flujos (dos requests a la vez, cancelar en medio).
- Simular caída de microservicios (si tenés acceso permitido).
- Buscar stack traces forzando errores.
- Enviar payloads inesperados: tipos incorrectos, estructuras mal formadas.
- Probar fail-open:
- borrar headers
- enviar tokens vacíos
- valores “0”, “false”, “null”
- Duplicar operaciones para encontrar estados inconsistentes.
- Provocar errores internos y ver qué revela la respuesta.

🎯 Consecuencias
- Bypass total de autenticación o autorización.
- Exposición de información sensible (secret keys, rutas internas, DB hostnames).
- Estados corruptos: pagos duplicados, datos incoherentes.
- Acceso a recursos sin permisos por fallas “silent fail”.
- RCE indirecto a partir de excepciones mal manejadas.
- Caída total de sistemas o microservicios.
- Fugas de logs con secretos o credenciales.
- Escaladas de privilegios mediante parámetros faltantes.
- Acciones críticas sin validación (si falla la lógica previa).
🛡 Defensas modernas (2025)
- Fail-secure: ante error → bloquear, nunca permitir.
- Manejo uniforme y centralizado de errores.
- Validar estrictamente parámetros faltantes o nulos.
- Timeouts bien definidos + políticas claras (retry, fallback).
- Logging seguro (sin stack traces en producción).
- API Gateway con fallback seguro (deny-by-default).
- Mecanismos de circuit breaker (Hystrix, Resilience4j).
- Validación explícita de privilegios en cada paso, incluso ante fallos.
- Sanitización estricta de mensajes de error.
- Testing de caos / chaos engineering para asegurar resiliencia segura.
- Detección de estados inconsistentes (DB + transacciones).
- Políticas claras ante fallos de sistemas externos → bloquear.


📚 Subtipos / patrones modernos (2025)
| Subtipo / patrón | Definición | Ejemplo bancario | Pentesting (qué probar) | Ataque / PoC | Consecuencia | Defensa | Tips examen |
| Fail-Open | Error que permite acceso | Microservicio Auth cae → acceso permitido | Cortar peticiones | Login bypass | ATO | Fail-secure | “si falla → bloquear” |
| Null Handling Failure | Manejo inseguro de nulos | role=null → rol admin | Enviar null/»» | Escalada | Impersonación | Validate null | Buscar null |
| Missing Parameter Handling | Parámetros faltantes → default peligroso | amount vacío = 0 → transacción | Quitar parámetros | Transacciones inconsistentes | Fraude | Validar obligatoriedad | Parámetros faltantes = alerta |
| Improper Error Message | Errores revelan información | Stack trace en /login | Forzar error | Info leakage | Robo de secrets | Mensajes genéricos | “Error detallado = peligro” |
| Timeout / Retry Issues | Timeout provoca estado inconsistente | Pago duplicado | Cortar conexión | Double spend | Pérdida $ | Transacciones atómicas | Probar interrumpir |
| Privilege Check Failure | Error lógico en roles | if(error) allow() | Forzar error | Escalada | Impersonación | Validación universal | Preguntas sobre fallback |
| Unhandled Exception | Excepción sin control | Excepción muestra ruta | Payload inválido | Info leakage | Recon interno | Catch global | “Unhandled” = crítico |
| Race Condition on Errors | Error crea ventana | Error en update | Enviar dos requests | Inconsistencia | Corrupción | Locks/transactions | Race bajo error |
| Inconsistent State | Estado incompleto por fallo | Pago pasa a “pagado” sin serlo | Romper flujo | Estados corruptos | Fraude | Checks de integridad | Buscar “partial state” |
| External Service Failure | Falla en terceros mal manejada | Falla SMS y salta MFA | Simular caída | Bypass MFA | ATO | Fallback seguro | Terceros deben bloquear |
🧪 Checklist rápida de pentesting A10:2025
- Enviar null, «», {}, arrays vacíos.
- Quitar parámetros críticos.
- Forzar errores internos y ver detalles.
- Causar timeouts intencionales.
- Cancelar requests a mitad de proceso.
- Revisar estados inconsistentes tras fallos.
- Simular caídas de microservicios (si está permitido).
- Probar fail-open cambiando headers o tokens vacíos.
- Forzar errores de terceros (SMS, mail, pagos) → ver si se abre acceso.
- Revisar mensajes de error y filtración.
- Revisar fallback en circuit breakers.
- Probar múltiples requests simultáneas en escenarios de error.
🧾Resumen
A10:2025 Manejo Inadecuado de Condiciones Excepcionales es una categoría nueva que representa todos los fallos que ocurren cuando la aplicación enfrenta errores o situaciones anómalas: fallos en parámetros, nulos, timeouts, caídas de servicios externos, errores de lógica, fallos de autorización y comportamientos “fail-open”. Cuando estos errores no se manejan correctamente, pueden provocar bypass de autenticación, exposición de información sensible, inconsistencias de datos, duplicación de transacciones y acceso indebido a recursos. La mitigación exige fail-secure, validación estricta de parámetros, manejo centralizado de errores, circuit breakers, fallback seguro y testing de caos. Si la aplicación falla abierta, falla por completo.
¡Completaste el capítulo A10!
Y ahora entendés por qué el manejo de condiciones excepcionales es mucho más que “tirar un try/catch”. Es diseño, resiliencia, seguridad, arquitectura y, en muchos casos, la diferencia entre un fallo controlado y una vulnerabilidad explotable.
Durante todo este capítulo aprendiste:
- Que A10 representa errores lógicos, estados inesperados, fallas de apertura, parámetros faltantes, nulos peligrosos, sobrecargas, saturación de recursos y transacciones mal revertidas.
- Cómo estos errores pueden ser aprovechados para DoS, enumeración, fuga de información, corrupción de datos o bypass de controles.
- Que un error expuesto al cliente es un vector de reconocimiento ofensivo que revela internals de la aplicación.
- Por qué la filosofía moderna es: “responder poco, registrar mucho”.
- Cómo implementar manejadores globales de excepciones, tanto en APIs REST (RFC 7807) como en arquitecturas backend complejas.
- Qué significa diseñar errores operativos vs errores de programación, y por qué mezclarlos destruye la resiliencia.
- Cómo Node.js, Java, .NET y otros stacks requieren mecanismos diferentes pero comparten los mismos principios de seguridad: no filtrar, no romper, no corromper, no ignorar.
- Cómo el manejo de excepciones influye en otras áreas críticas: logging, monitoreo, detección de anomalías, alertas, transacciones, flujos de negocio y pruebas de estrés.
- Por qué fallar rápido evita estados inconsistentes, y fallar seguro evita vulnerabilidades.
El gran aprendizaje es este:
Una aplicación segura no es la que nunca falla, sino la que falla sin delatarse, sin romperse y sin comprometer la integridad del sistema.
Con este capítulo completás el último eslabón del OWASP Top 10 2025. Ya entendés identidad (A07), integridad y navegador (A08), logging y monitoreo (A09), y ahora la resiliencia interna del software (A10). Tenés la visión completa de cómo construir aplicaciones modernas que no solo funcionan, sino que se mantienen íntegras bajo presión.
Seguí avanzando. Ya tenés mentalidad de arquitecto, de atacante y de defensor al mismo tiempo.