
En este capítulo aprenderás cómo funcionan las solicitudes HTTP, en el capitulo anterior aprendiste qué es y cómo funciona la línea de solicitud y los métodos, en este capítulo aprenderás qué es y cómo funciona la ruta (URL/path) en una petición HTTP y por qué entenderla es fundamental para cualquier hacker ético o pentester. Verás cómo la request line (METHOD /path HTTP/x.x) y la combinación Host + path determinan qué recurso pide el cliente; cómo los encabezados (Host, User-Agent, Accept, Accept-Encoding, Connection, etc.) influyen en la respuesta; y por qué versiones del protocolo (HTTP/1.1, HTTP/2, HTTP/3) y la correcta separación headers/body (\r\n) afectan tanto al rendimiento como a la seguridad. Esto te sirve porque muchas vulnerabilidades reales (path traversal, IDOR, Host header injection, request smuggling, cache poisoning, fugas por compresión) se descubren manipulando rutas, métodos y encabezados con precisión.
URL/Ruta de la solicitud HTTP
La dirección del recurso/URI al que el cliente desea acceder. La página de inicio de un sitio web siempre es «/». Se pueden solicitar otras páginas, por supuesto, por ejemplo: /descargas/index.php. Su solicitud siempre se refiere a la carpeta raíz para especificar el archivo solicitado (de ahí el «/» inicial). La ruta URL indica al servidor dónde encontrar el recurso solicitado por el usuario. Por ejemplo, en la URL https://laprovittera.com/api/users/123, la ruta /api/users/123identifica a un usuario específico.
Los atacantes a menudo intentan manipular la ruta URL para explotar vulnerabilidades, por lo que es crucial:
- Validar la ruta URL para evitar acceso no autorizado
- Desinfectar el camino para evitar ataques de inyección
- Proteja los datos confidenciales mediante la realización de evaluaciones de privacidad y riesgos
Seguir estas prácticas ayuda a proteger su aplicación web de ataques comunes.
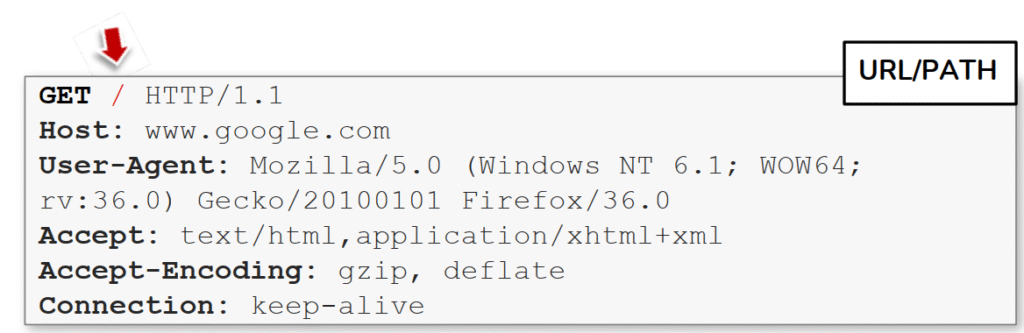
La imagen muestra la estructura de una petición HTTP, destacando específicamente el URL o path solicitado dentro de la línea inicial. En este caso, el navegador envía una solicitud GET / HTTP/1.1 al dominio www.google.com. El símbolo / indica que el cliente está pidiendo el recurso raíz del servidor, es decir, la página principal.
En la parte superior se ve la request line, compuesta por tres elementos: el método HTTP (GET), la ruta del recurso o path (/) y la versión del protocolo (HTTP/1.1). Esta línea define qué acción se desea realizar sobre el recurso. Después aparecen los encabezados HTTP, que incluyen información adicional sobre el cliente y su entorno:
- Host: www.google.com especifica el dominio al que se dirige la petición.
- User-Agent: Mozilla/5.0… identifica el navegador o cliente que realiza la solicitud.
- Accept y Accept-Encoding comunican los formatos y tipos de compresión que el cliente puede manejar.
- Connection: keep-alive indica que la conexión TCP debe mantenerse abierta para futuras solicitudes.
El punto clave que resalta la imagen es el path (/), que junto con el dominio forma la URL completa que el cliente solicita al servidor. Cambiar este valor modifica directamente el recurso al que se accede: por ejemplo, /login, /admin o /images/logo.png apuntarían a diferentes rutas dentro del mismo servidor.
En el ámbito del pentesting y la seguridad web, entender y manipular el path es fundamental, ya que muchos ataques se basan en modificar rutas o parámetros dentro de la URL. Errores de validación pueden conducir a vulnerabilidades como path traversal (cuando se intenta acceder a archivos fuera del directorio permitido), fuzzing de rutas (descubrir recursos ocultos o restringidos) o incluso exposición de archivos sensibles. Además, durante las pruebas de seguridad, herramientas como Burp Suite o curl permiten interceptar y alterar el path para observar cómo responde el servidor ante solicitudes anómalas o no documentadas.
En resumen, el path en una petición HTTP indica la ubicación exacta del recurso solicitado dentro del servidor, y comprender su funcionamiento es esencial tanto para el desarrollo seguro de aplicaciones web como para la identificación de posibles fallos de acceso o configuración.
Protocolo de solicitud HTTP – Versión HTTP:
Pero para una experiencia web mucho más completa, también necesitará enviar otros datos. Estos se envían en encabezados, que contienen información adicional para el servidor web con el que se comunica.
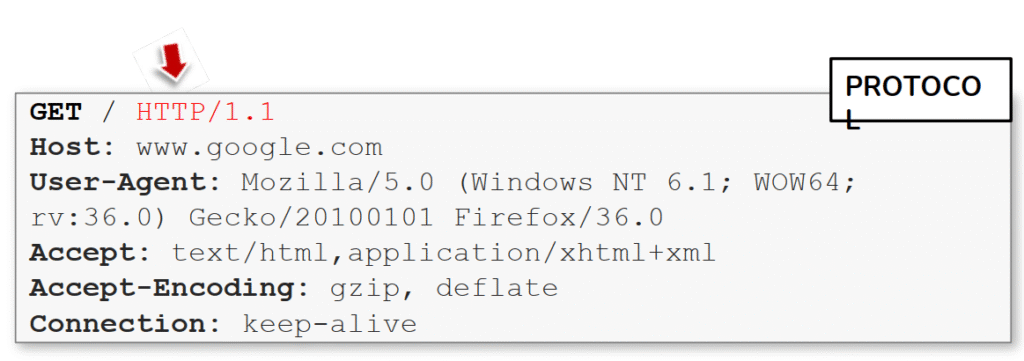
La imagen muestra una petición HTTP destacando específicamente la parte del protocolo, señalada en rojo: HTTP/1.1. Esta sección aparece al final de la primera línea de la solicitud, conocida como request line, que está compuesta por tres elementos: el método (GET), el recurso solicitado (/) y la versión del protocolo (HTTP/1.1).
El protocolo HTTP define las reglas de comunicación entre el cliente (por ejemplo, un navegador) y el servidor. En este caso, la versión 1.1 introdujo mejoras respecto a HTTP/1.0, como el uso de conexiones persistentes mediante Connection: keep-alive, lo que permite reutilizar la misma conexión TCP para múltiples peticiones. También añadió la obligatoriedad del encabezado Host, lo que hizo posible alojar varios sitios web en un mismo servidor (virtual hosting).
En el contexto del pentesting y la seguridad web, la versión del protocolo puede revelar detalles importantes sobre la infraestructura del servidor. Por ejemplo, si un servidor solo acepta HTTP/1.0 o no soporta HTTP/2, puede tratarse de un sistema antiguo o mal configurado. Además, entender cómo maneja las conexiones persistentes o el encabezado Host es clave para detectar vulnerabilidades como Host Header Injection o comportamientos inconsistentes entre versiones del protocolo.
En resumen, el campo HTTP/1.1 no solo indica la versión del protocolo utilizada, sino que define el conjunto de características y comportamientos esperados en la comunicación. Conocer sus particularidades permite a los pentesters ajustar sus pruebas, interpretar respuestas de forma precisa y descubrir posibles debilidades en la configuración de los servidores o proxies intermedios.
Versión HTTP:
Esta es la versión del protocolo HTTP con la que su navegador desea comunicarse (HTTP 1.0/HTTP 1.1). La versión HTTP muestra la versión del protocolo utilizado para la comunicación entre el cliente y el servidor. A continuación, se presenta un breve resumen de las más comunes:
HTTP /0.9 (1991) La primera versión, sólo admitía solicitudes GET.
HTTP /1.0 (1996) Se agregaron encabezados y mejor soporte para diferentes tipos de contenido, mejorando el almacenamiento en caché.
HTTP /1.1 (1997)
Introdujo conexiones persistentes, codificación de transferencia fragmentada y mejor almacenamiento en caché. Su uso sigue siendo generalizado. La Figura muestra un ejemplo de un intercambio HTTP 1.1 entre un cliente web y un servidor web.
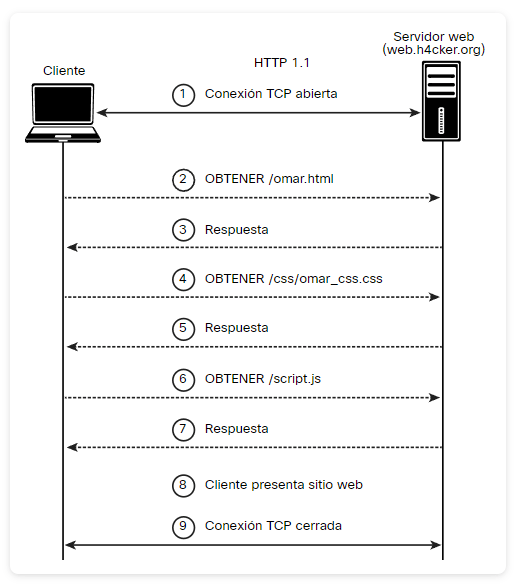
La imagen muestra un diagrama de secuencia HTTP 1.1 (by Omar Santos), donde se explica paso a paso cómo un cliente (navegador) se comunica con un servidor web para solicitar y cargar una página. Este flujo representa el proceso típico que ocurre cada vez que un usuario visita un sitio web.
En el primer paso, el cliente abre una conexión TCP con el servidor, lo que establece el canal de comunicación necesario para intercambiar datos. Luego, en el paso 2, el navegador realiza una petición HTTP GET para obtener el archivo principal del sitio, en este caso /omar.html. El servidor responde con el contenido solicitado (paso 3), que contiene el código HTML de la página.
Después, el navegador analiza ese HTML y detecta que necesita más recursos, como hojas de estilo y scripts. Por eso, en el paso 4 envía otra petición GET para obtener el archivo /css/omar_css.css, a la que el servidor responde nuevamente con el archivo solicitado (paso 5). De manera similar, en los pasos 6 y 7, el cliente pide el archivo /script.js y recibe su respuesta correspondiente.
Una vez descargados todos los recursos necesarios, el cliente procesa y presenta el sitio web al usuario (paso 8), mostrando la página completa con su estructura, estilos y funcionalidades. Finalmente, en el paso 9, la conexión TCP se cierra, concluyendo la comunicación entre el navegador y el servidor.
Este diagrama ilustra claramente cómo funciona el protocolo HTTP/1.1, donde cada recurso se solicita de forma secuencial dentro de una misma conexión. Es un proceso esencial para entender el flujo de carga de páginas web y la forma en que los navegadores interactúan con los servidores.
HTTP 2.0 (2015)
Se introdujeron características como multiplexación, compresión de encabezado y priorización para un rendimiento más rápido.
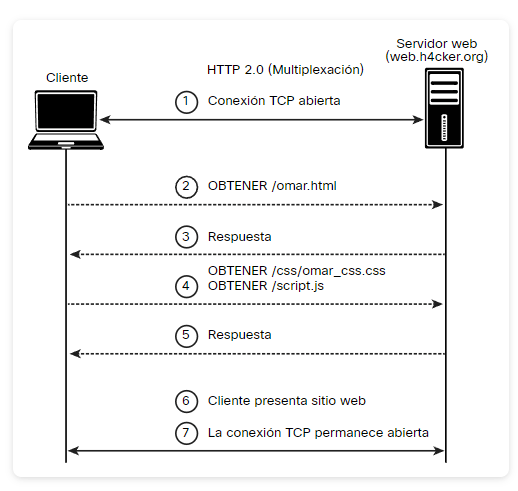
Multiplexación HTTP 2.0 (by Omar Santos). Ejemplo de un intercambio HTTP 2.0 entre un cliente web y un servidor web. La imagen muestra un diagrama de secuencia de comunicación con el protocolo HTTP/2.0, destacando las mejoras que introduce respecto a la versión anterior (HTTP/1.1). Este flujo representa cómo el cliente (navegador) y el servidor web intercambian información de manera más eficiente gracias a la multiplexación.
En el primer paso, el cliente abre una conexión TCP con el servidor. A diferencia de HTTP/1.1, donde cada recurso podía requerir una conexión adicional o esperas secuenciales, en HTTP/2.0 todas las solicitudes y respuestas se manejan simultáneamente dentro de una sola conexión.
El cliente inicia el proceso enviando una petición GET /omar.html (paso 2), a la que el servidor responde con el contenido HTML solicitado (paso 3). Luego, el navegador detecta que necesita otros recursos, como hojas de estilo y scripts, pero ahora puede enviar múltiples peticiones en paralelo dentro de la misma conexión: en el paso 4, se solicitan /css/omar_css.css y /script.js al mismo tiempo.
El servidor responde con los archivos requeridos (paso 5), y el cliente finalmente presenta el sitio web al usuario (paso 6). Una diferencia importante es que, en lugar de cerrar la conexión, HTTP/2.0 la mantiene abierta (paso 7), lo que permite reutilizarla para futuras solicitudes, reduciendo la latencia y mejorando el rendimiento general de la web.
Este diagrama ilustra claramente la ventaja principal de HTTP/2.0: la multiplexación de peticiones y respuestas sobre una única conexión TCP, lo que hace que la carga de las páginas sea mucho más rápida y eficiente en comparación con HTTP/1.1.
Diferencias entre HTTP/1.1 y HTTP/2
La imagen explica de manera visual las diferencias entre HTTP/1.1 y HTTP/2, tanto en la estructura de las peticiones como en la forma en que se transmiten los datos entre el cliente, la CDN y el servidor.
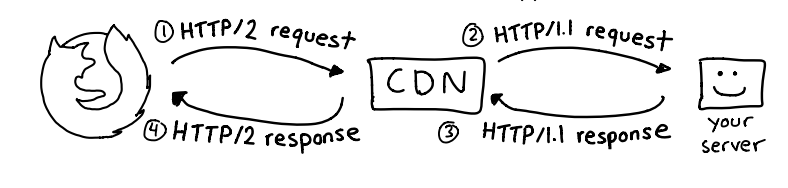
Se muestra el flujo de comunicación: el navegador envía una petición HTTP/2 a la CDN (1), la CDN traduce esa solicitud a HTTP/1.1 para contactar con el servidor de origen (2), recibe la respuesta del servidor (3) y finalmente devuelve la respuesta HTTP/2 al cliente (4). Esto ilustra cómo las CDNs actúan como intermediarias, permitiendo a los clientes usar HTTP/2 incluso cuando los servidores aún trabajan con HTTP/1.1.

Se comparan las peticiones antes y después de HTTP/2. En HTTP/1.1, la cabecera principal es Host: examplecat.com, mientras que en HTTP/2 se reemplaza por :authority examplecat.com. El resto de los encabezados, como User-Agent, permanecen iguales. Este cambio forma parte de la normalización de campos en el nuevo estándar, que mejora la eficiencia del intercambio de datos.
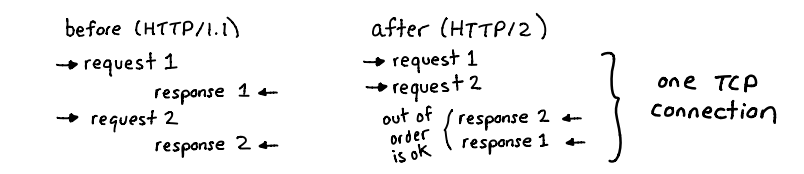
Una diferencia clave
El manejo de las conexiones TCP. En HTTP/1.1, cada petición y respuesta viajan de forma secuencial —la segunda no puede procesarse hasta que la primera haya terminado—, lo que genera latencia. En cambio, HTTP/2 permite multiplexar varias solicitudes sobre una sola conexión TCP, lo que significa que se pueden enviar múltiples peticiones simultáneamente y recibir las respuestas en cualquier orden, optimizando así la velocidad y el uso de recursos.
Desde el punto de vista del pentesting y la seguridad web, este cambio también tiene implicaciones importantes. HTTP/2 mejora la eficiencia, pero introduce complejidad en el análisis del tráfico: las herramientas de interceptación deben ser compatibles con el protocolo para poder ver las cabeceras y cuerpos correctamente. Además, los mecanismos de multiplexación pueden ocultar patrones de ataque tradicionales (por ejemplo, inyecciones o manipulación de cabeceras), por lo que las pruebas deben realizarse tanto con HTTP/1.1 como con HTTP/2 para asegurar que no existan diferencias de comportamiento entre ambos protocolos.
En resumen, la imagen resume tres ideas fundamentales: el rol de las CDNs como traductoras entre protocolos, el cambio estructural en las cabeceras HTTP/2, y la gran mejora de rendimiento gracias al envío simultáneo de múltiples peticiones en una única conexión TCP.
HTTP /3 (2022)
Construido sobre HTTP /2, pero utiliza un nuevo protocolo (QUIC) para conexiones más rápidas y seguras. Aunque HTTP /2 y HTTP /3 ofrecen mayor velocidad y seguridad, muchos sistemas aún usan HTTP /1.1 porque es compatible con la mayoría de las configuraciones existentes. Sin embargo, actualizar a HTTP /2 o HTTP /3 puede proporcionar mejoras significativas en el rendimiento y la seguridad a medida que más sistemas los adopten.
Encabezados de solicitud HTTP
Se inicia una solicitud HTTP a www.google.com. Lo que ves aquí son los encabezados (encabezados de solicitud HTTP) para esta solicitud. Ten en cuenta que se inicia una conexión a www.google.com en el puerto 80 antes de enviar comandos HTTP al servidor web. Se trata de encabezados que se envían desde el cliente (normalmente su navegador) al servidor. Los encabezados son bits de datos adicionales que puedes enviar al servidor web cuando realizas solicitudes. Aunque no se requieren encabezados estrictamente al realizar una solicitud HTTP , resultará difícil ver un sitio web correctamente. Recuerden esta imagen que lo explica claramente.
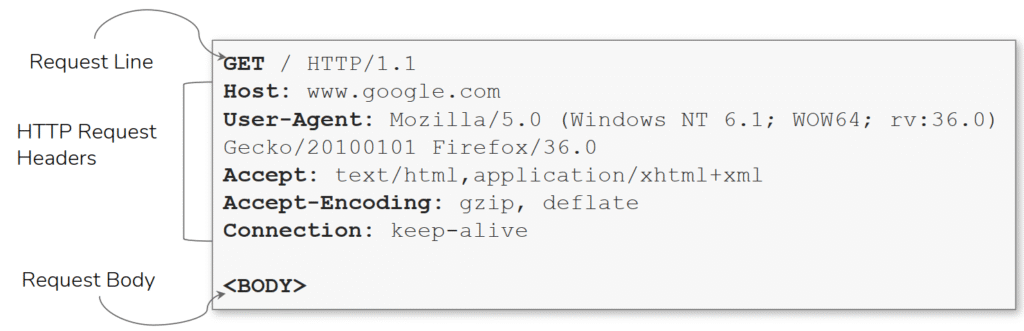
Los encabezados de solicitud permiten enviar información adicional al servidor web sobre la solicitud. Debajo de la request line, los encabezados (headers) proporcionan información adicional que guía la interacción:
- Host: indica el dominio de destino. Especifica el nombre del servidor web al que va dirigida la solicitud. www.google.com
- User-Agent describe el cliente o navegador que realiza la solicitud. User-Agent: Mozilla/5.0
- Accept especifica los tipos de contenido que el cliente puede manejar.
- Accept-Encoding comunica los algoritmos de compresión admitidos.
- Connection: keep-alive solicita mantener la conexión abierta para futuras solicitudes.
Pueden haber otros como:
- Referer: https://www.google.com/ Indica la URL de donde proviene la solicitud.
- Cookie: user_type=student; room=introtowebapplication; room_status=in_progress La información que el servidor web solicitó previamente al navegador que almacenara se guarda en cookies.
- Content-Type: application/json Describe qué tipo o formato de datos hay en la solicitud.
Encabezado de host de solicitud HTTP
Este es el comienzo de los encabezados de solicitud HTTP. Los encabezados HTTP tienen la siguiente estructura:
Nombre del encabezado: Valor del encabezado.
El encabezado Host permite que un servidor web aloje varios sitios web en una sola dirección IP. Nuestro navegador especifica en el encabezado Host qué sitio web le interesa. Después de cada encabezado de solicitud, encontrará su valor correspondiente. En este caso, queremos acceder al host www.google.com. El valor del host + la ruta se combinan para crear la URL completa que está solicitando: la página de inicio de www.google.com/
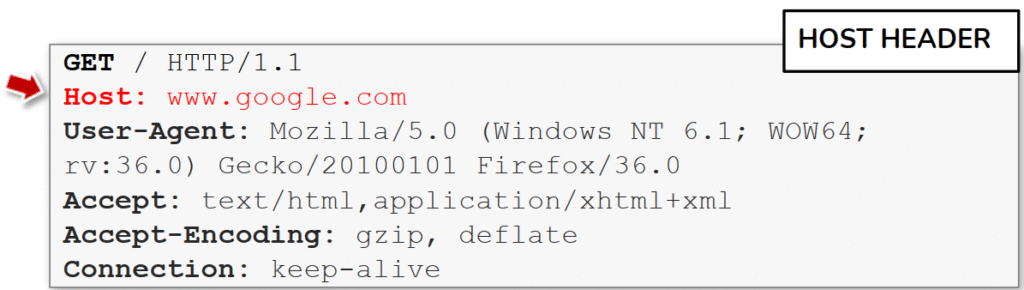
La imagen muestra una petición HTTP en la que se resalta el encabezado Host, indicado en rojo: Host: www.google.com. Este campo es fundamental en el protocolo HTTP/1.1, ya que especifica el dominio o nombre del servidor al que el cliente (como un navegador o una herramienta como curl) desea acceder.
Antes de HTTP/1.1, las peticiones no incluían este encabezado, lo que implicaba que cada sitio debía tener una dirección IP dedicada. Con la llegada de Host, un mismo servidor puede alojar múltiples sitios o aplicaciones (lo que se conoce como virtual hosting), diferenciándolos según el dominio recibido en la petición. Por ejemplo, una misma IP puede responder de manera diferente a Host: www.google.com y a Host: mail.google.com.
En la parte superior, la línea de solicitud (GET / HTTP/1.1) indica el método, el recurso solicitado y la versión del protocolo. Debajo, otros encabezados como User-Agent, Accept o Connection completan la información que el cliente envía al servidor para recibir una respuesta adecuada.
Desde la perspectiva del pentesting y la seguridad web, el encabezado Host tiene especial relevancia, ya que puede ser manipulado para descubrir vulnerabilidades de Host Header Injection. Si una aplicación web confía ciegamente en el valor de este campo (por ejemplo, al generar enlaces, redirecciones o correos electrónicos), un atacante podría modificarlo y provocar comportamientos maliciosos como:
- Redirecciones a dominios falsos.
- Enlaces de restablecimiento de contraseña que apuntan a un sitio controlado por el atacante.
- Falsificación de URLs en cabeceras o respuestas.
Además, probar diferentes valores en el Host puede revelar subdominios internos, entornos de desarrollo o configuraciones de proxy incorrectas. Por eso, una buena práctica en seguridad es que las aplicaciones validen siempre el valor del encabezado Host contra una lista blanca de dominios permitidos.
En resumen, el Host Header no solo es un elemento técnico obligatorio en HTTP/1.1, sino también un vector importante a analizar en auditorías de seguridad. Comprender su función y cómo manipularlo correctamente permite detectar configuraciones inseguras y proteger aplicaciones web frente a ataques de envenenamiento de encabezados o redirecciones maliciosas.
Encabezado de agente de usuario de solicitud HTTP
El agente de usuario se utiliza para especificar y enviar su navegador, versión del navegador, sistema operativo e idioma al servidor web remoto. Todos los navegadores web tienen su propia cadena de identificación de agente de usuario. Así es como la mayoría de los sitios web reconocen el tipo de navegador en uso.
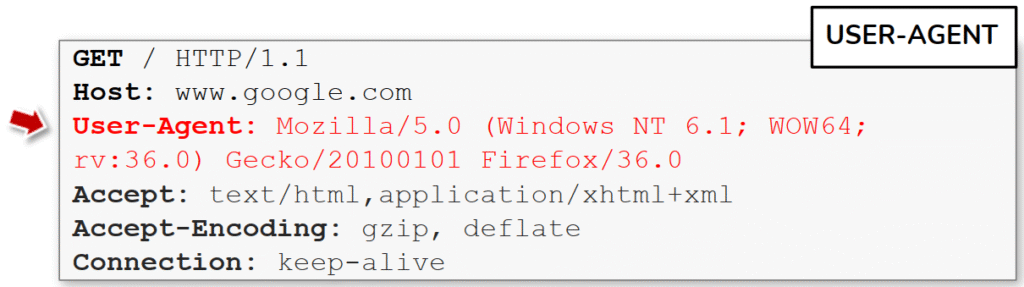
La imagen muestra una petición HTTP en la que se resalta el encabezado User-Agent, señalado en rojo. Este campo identifica el software que realiza la solicitud, en este caso:
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:36.0) Gecko/20100101 Firefox/36.0.
El encabezado User-Agent permite que el servidor conozca qué tipo de cliente está haciendo la petición —por ejemplo, un navegador, un bot o una aplicación automatizada— y adaptar la respuesta según esa información. Los servidores pueden usar este dato para entregar contenido diferente dependiendo del dispositivo (por ejemplo, una versión móvil o de escritorio), aplicar compatibilidad con navegadores antiguos o incluso bloquear clientes específicos.
En el ejemplo, el valor indica que el cliente es el navegador Firefox 36 ejecutándose en Windows 7 (WOW64). Esta cadena sigue un formato tradicional en el que se mezclan identificadores históricos (como “Mozilla”) y detalles técnicos del entorno del cliente.
Desde una perspectiva de seguridad y pentesting, el encabezado User-Agent es especialmente interesante porque puede ser manipulado fácilmente. Los atacantes o pentesters pueden modificarlo para:
- Evadir filtros o firewalls que bloquean ciertos agentes conocidos (como curl o sqlmap).
- Simular distintos dispositivos o navegadores y observar cómo el servidor cambia su comportamiento.
- Realizar fingerprinting inverso, es decir, identificar cómo responde el servidor a diferentes User-Agents para descubrir versiones específicas de frameworks o CMS.
- Detectar vulnerabilidades en lógica de negocio, ya que algunas aplicaciones asumen que solo los navegadores legítimos interactúan con ciertas rutas.
Por otro lado, algunos sistemas de análisis y registro utilizan el User-Agent para detectar tráfico automatizado o bots. Sin embargo, confiar únicamente en este encabezado no es seguro, ya que puede falsificarse sin dificultad.
En resumen, el User-Agent es un campo informativo que revela el entorno del cliente y que los desarrolladores usan para ofrecer compatibilidad, pero también es una herramienta de gran valor en auditorías de seguridad. Analizar y modificar este encabezado permite descubrir diferencias de comportamiento, probar validaciones deficientes y simular distintos escenarios de ataque o navegación dentro de una aplicación web.
Encabezado de aceptación de solicitud HTTP
El encabezado de aceptación lo utiliza su navegador para especificar qué tipos de documentos/archivos se espera que se devuelvan desde el servidor web como resultado de esta solicitud.
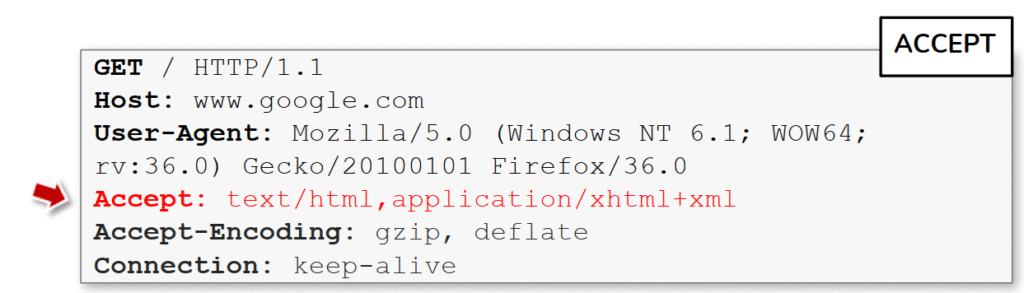
La imagen destaca el encabezado Accept dentro de una petición HTTP, mostrándolo en rojo para subrayar su función: comunicar al servidor qué tipos de contenido (MIME types) acepta el cliente. En el ejemplo aparece Accept: text/html,application/xhtml+xml, es decir, el cliente está indicando preferencia por HTML o XHTML; el servidor usará esa información para decidir si devuelve una página HTML, JSON, un archivo de imagen u otro tipo de respuesta, o incluso para seleccionar una plantilla distinta según el cliente. Técnicamente Accept puede llevar varios tipos separados por comas y parámetros q= para definir prioridades, y junto con cabeceras como Accept-Language forma parte de la negociación de contenido (content negotiation).
Este encabezado es importante porque cambiarlo puede provocar respuestas distintas del servidor que revelen información o mal configuraciones. Por ejemplo, pedir Accept: application/json a un endpoint que normalmente entrega HTML puede exponer una API oculta o hacer que la aplicación devuelva datos en bruto; enviar Accept: */* puede forzar al servidor a ofrecer la primera representación disponible; y usar valores incorrectos o raros puede provocar que el servidor caiga en rutas de error distintas. Además, diferencias en la respuesta según Accept pueden usarse para fingerprinting (detectar frameworks o versiones) o para evadir filtros que solo inspeccionan respuestas HTML.
Hay también efectos colaterales relevantes para la seguridad: el header Vary en las respuestas suele incluir Accept si el servidor varía el contenido según ese campo, y una gestión incorrecta de Vary + cachés/CDNs puede llevar a problemas de cache poisoning (diferentes usuarios viendo respuestas que no les corresponden). Otro riesgo es la llamada “MIME confusion” —si el servidor devuelve un contenido con un Content-Type distinto al real o permite que un atacante fuerce una representación peligrosa, el navegador podría interpretar el contenido de forma insegura y abrir vectores como XSS o descarga/exposición de datos.
Como ejercicio práctico (en entornos controlados) vale la pena interceptar peticiones con un proxy (Burp/ZAP) y modificar Accept para observar cambios: pedir JSON donde normalmente hay HTML, forzar Accept: text/plain para ver si la app “cae” en un fallback, o probar combinaciones con Accept-Language. Recuerda siempre realizar estas pruebas únicamente en objetivos con autorización; manipular encabezados en sistemas ajenos sin permiso es ilegal y dañino.
Encabezado de codificación de aceptación de solicitud HTTP
El encabezado de codificación de aceptación es similar a Accept y se utiliza para restringir la codificación de contenido aceptable en la respuesta. La codificación de contenido se utiliza principalmente para permitir que un documento se comprima o transforme sin perder el formato original ni información
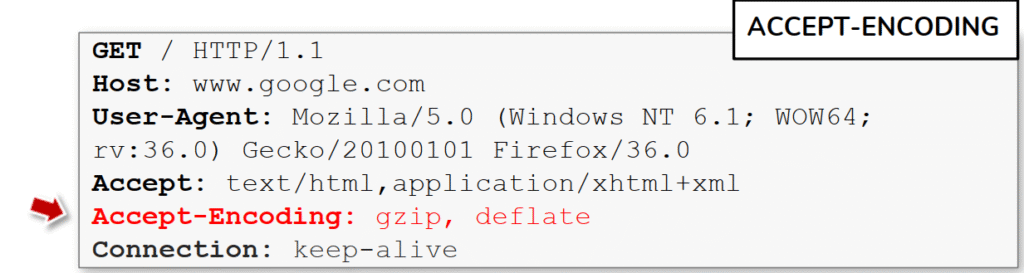
La imagen resalta el encabezado Accept-Encoding dentro de una petición HTTP (Accept-Encoding: gzip, deflate) y muestra su papel: el cliente le indica al servidor qué algoritmos de compresión puede entender. Esa información permite al servidor devolver el contenido comprimido (por ejemplo gzip) para ahorrar ancho de banda y acelerar la transferencia, y por consiguiente el Content-Encoding de la respuesta deberá reflejar la selección usada.{
Desde el punto de vista práctico y de pentesting, Accept-Encoding tiene varias implicaciones útiles para tus alumnos. Cambiar o forzar distintos valores puede alterar cómo el servidor empaqueta la respuesta y revelar comportamientos distintos en la lógica de entrega; además, la compresión introduce vectores sutiles de filtrado lateral y fuga de información en ciertos escenarios (ataques relacionados con la compresión han sido usados para recuperar datos sensibles cuando se combinan con mecanismos de cifrado y respuestas comprimidas). También es habitual que proxies, CDNs o WAFs manejen la compresión de manera distinta al servidor final, de modo que diferencias entre Accept-Encoding y el Content-Encoding real pueden delatar inconsistencia en la cadena de entrega.
Para pruebas prácticas en entornos controlados, interceptar la petición con un proxy y modificar Accept-Encoding es un buen ejercicio: prueba a quitarlo, a solicitar valores no soportados, o a forzar gzip para ver si la respuesta cambia en headers, tamaño o estado. Observa además las cabeceras relacionadas (Vary, Content-Encoding, Content-Length) y comprueba si la app aplica saneamiento de datos sensibles antes de comprimirlos. Como siempre, realiza estas pruebas únicamente en objetivos con autorización; manipular encabezados y explotar diferencias de compresión en sistemas ajenos sin permiso puede ser ilegal.
Encabezado de conexión de solicitud HTTP
Al usar HTTP 1.1, puede mantener/reutilizar la conexión al servidor web remoto durante un período de tiempo no especificado utilizando el valor «keep-alive». Esto indica que todas las solicitudes al servidor web continuarán enviándose a través de esta conexión sin iniciar una nueva conexión cada vez (como en HTTP 1.0).
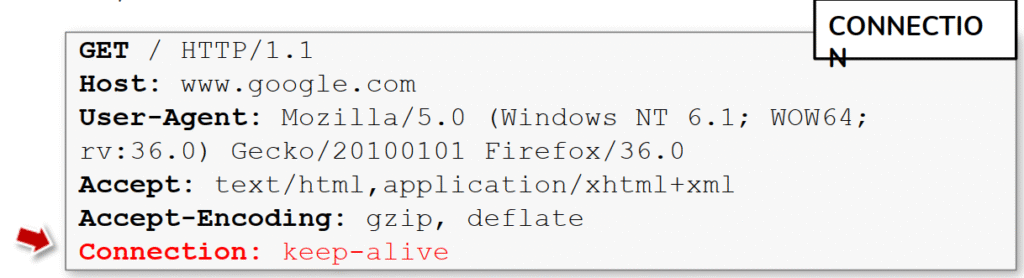
La imagen destaca el encabezado Connection dentro de una petición HTTP (Connection: keep-alive) y lo sitúa como una de las cabeceras que controlan el comportamiento de la conexión TCP entre cliente y servidor. En HTTP/1.1 el uso de keep-alive permite reutilizar la misma conexión para varias peticiones/respuestas, reduciendo la latencia y la sobrecarga de establecimiento de nuevos sockets; en contrapartida, Connection: close indicaría que el servidor debe cerrar la conexión tras servir la respuesta.
Desde el punto de vista operativo y de rendimiento, mantener conexiones persistentes mejora la eficiencia en navegadores y APIs, pero también cambia la forma en que se gestionan recursos en servidores, proxies y balanceadores. En cadenas con intermediarios es común que cada componente tenga sus propios timeouts y límites de conexiones simultáneas, y las discrepancias entre ellos pueden producir efectos inesperados (p. ej. conexiones que el cliente cree abiertas y el servidor ya ha cerrado), lo que a veces se traduce en fallos de disponibilidad o comportamiento errático.
Para pentesting y seguridad el encabezado Connection es relevante porque interviene en varios vectores prácticos: manipularlo puede ayudar a reproducir problemas de agotamiento de recursos (simulando muchas conexiones persistentes para saturar pools), probar diferencias de parsing entre intermediarios (por ejemplo, ciertos ataques de request smuggling explotan cómo se tratan cabeceras relacionadas con la conexión), o detectar configuraciones que permiten mantener túneles indefinidos. También conviene observar si proxies o WAFs respetan o reescriben ese header; comportamientos inconsistentes pueden ser indicio de mala configuración o de espacios para evadir filtros.
Como recomendación práctica: intercepten peticiones con un proxy (Burp/ZAP) y prueben variaciones (Connection: keep-alive, Connection: close, eliminar el header) para ver cómo cambia la respuesta y el estado de la conexión, y monitoricen timeouts y límites en el servidor/intermediarios. Siempre haz estas pruebas en entornos controlados o con autorización, ya que forzar conexiones masivas o manipular cabeceras en sistemas ajenos puede causar interrupciones y es ilegal sin permiso.
Línea vacía: \r\n

\r (Retorno de carro): mueve el cursor al principio de la línea
\n (Salto de línea): mueve el cursor hacia abajo a la siguiente línea
\r\n: es lo mismo que presionar la tecla Enter en tu teclado
La imagen representa de forma muy simple y visual la estructura fundamental de un mensaje HTTP: primero los headers terminados por la secuencia \r\n, a continuación una línea en blanco (\r\n) que actúa como separador, y por último el message body que también termina con \r\n. Ese pequeño cuadro resalta la regla básica del protocolo HTTP: los encabezados se envían línea a línea y una línea vacía (dos caracteres de control: carriage return + line feed) indica al receptor que ya no vienen más encabezados y que ahora empieza el cuerpo del mensaje.
Los caracteres \r\n son importantes porque no son texto visible sino control —\r (CR) seguido de \n (LF)— y los servidores, proxies y clientes los usan para parsear correctamente el flujo. Si el servidor espera un cuerpo, normalmente usará un encabezado como Content-Length o una codificación por fragmentos (chunked) para saber cuántos bytes leer después de esa línea vacía. Si el separador no se interpreta como corresponde, los distintos componentes en la cadena (cliente, reverse proxy, balanceador, servidor de aplicaciones) pueden quedar desincronizados al procesar peticiones y respuestas.
Desde el punto de vista de seguridad y pentesting esa separación es crítica porque un manejo incorrecto o inconsistencias en el parsing entre intermediarios pueden abrir la puerta a fallos como request/response smuggling o header injection. En términos simples, si un intermediario y el servidor final no coinciden en cómo cuentan el final del encabezado o el inicio del cuerpo, un atacante podría lograr que una parte del tráfico sea malinterpretada y que una petición “oculta” llegue donde no debería. Por eso, además de validar y sanear entradas, es buena práctica configurar y actualizar correctamente servidores y proxies, normalizar las cabeceras y comprobar que todos los componentes siguen las mismas reglas del protocolo para evitar ese tipo de fallos.
Cuerpo de la solicitud
En solicitudes HTTP como POST y PUT, donde los datos se envían al servidor web en lugar de solicitarse desde él, estos se encuentran dentro del cuerpo de la solicitud HTTP . El formato de los datos puede ser diverso, pero algunos comunes son URL Encoded, Form Data, JSONo XML.
URL codificada (application/x-www-form-urlencoded).
Un formato donde los datos se estructuran en pares de clave y valor, donde ( key=value). Los pares múltiples se separan con un &símbolo ( ), como key1=value1&key2=value2. Los caracteres especiales se codifican con porcentaje.
Datos de formulario (multipart/form-data):
Permite enviar múltiples bloques de datos, cada uno separado por una cadena de límite. Esta cadena es el encabezado definido de la solicitud. Este tipo de formato se puede usar para enviar datos binarios, como al subir archivos o imágenes a un servidor web.
JSON (application/ json ).
En este formato, los datos se pueden enviar mediante la estructura JSON (Notación de Objetos JavaScript). Los datos se formatean en pares de nombre: valor. Los pares múltiples se separan por comas, todos entre llaves { }.
XML (application/ xml ).
En el formato XML , los datos se estructuran dentro de etiquetas, que tienen una apertura y una clausura. Estas etiquetas pueden anidarse entre sí. En el ejemplo a continuación, se puede ver la apertura y la clausura de las etiquetas para enviar información sobre una usuaria llamada Aleksandra.
Resumen
- Modelo básico: Cada visita a una web es un intercambio de mensajes HTTP: el cliente envía una request y el servidor responde con una response. HTTPS añade TLS/SSL para cifrar ese intercambio.
- Estructura de mensaje:
- Request line / Status line — método, ruta/URL y versión del protocolo (ej. GET / HTTP/1.1 / HTTP/1.1 200 OK).
- Headers — pares Nombre: Valor que transportan metadatos (Host, User-Agent, Accept, Cookie, Authorization, Content-Type, etc.).
- Línea vacía (\r\n) — separador obligatorio entre headers y body.
- Body — datos enviados en métodos como POST/PUT/PATCH (form-urlencoded, multipart/form-data, JSON, XML).
- Métodos HTTP clave y seguridad asociada:
- GET/HEAD — lectura; evitar exponer datos sensibles en URLs (tokens, contraseñas).
- POST/PUT/PATCH — envío/actualización de datos; validar y sanear todo el contenido del body para prevenir inyección (SQL/NoSQL/XSS), mass assignment, etc.
- DELETE — elimina recursos; comprobar autorización y control por objeto (ID) para evitar BOLA/IDOR.
- OPTIONS/TRACE/CONNECT — depuración o túneles; normalmente limitar/deshabilitar si no son necesarios.
- Encabezados críticos para pentesting:
- Host — virtual hosting; manipularlo puede revelar subdominios o permitir Host Header Injection.
- User-Agent — útil para fingerprinting y evasión de filtros.
- Accept / Accept-Encoding — afectan representación y compresión; cambios pueden revelar APIs ocultas o vulnerabilidades por compresión.
- Connection y manejo de Transfer-Encoding/Content-Length — importantes para ataques de request smuggling.
- Versiones del protocolo y su impacto:
- HTTP/1.1 — conexiones persistentes (keep-alive), secuencialidad.
- HTTP/2 — multiplexación, compresión de headers, mejor rendimiento; complejidad para interceptación.
- HTTP/3 (QUIC) — sobre UDP/QUIC, más rápido; requiere herramientas compatibles para pruebas.
- Puntos de atención para seguridad:
- Nunca confiar en la entrada del usuario: sanear y escapar siempre.
- No dejar secretos en URLs o front-end.
- Validar métodos permitidos y deshabilitar los innecesarios.
- Coherencia entre intermediarios (CDN, proxies, balanceadores) para evitar smuggling o cache poisoning.
- Logging y control de acceso a nivel de recurso (authorization checks por ID/propietario).
- Herramientas y prácticas para pruebas: usar proxies interceptores (Burp, ZAP), curl/scripts para manipular requests, HEAD/OPTIONS para reconocimiento, y laboratorios autorizados (Juice Shop, DVWA) para practicar.
Diez preguntas clave que pueden ser respondidas con lo aprendido:
- ¿Cuál es la diferencia entre HTTP y HTTPS?
- ¿Qué tres partes componen una solicitud HTTP?
- ¿Qué función cumple la línea vacía (\r\n) en un mensaje HTTP?
- ¿Qué información suele incluir el encabezado User-Agent?
- ¿Para qué se utiliza el método HEAD y en qué se diferencia de GET?
- ¿Cuál es el propósito del encabezado Host?
- ¿Qué es un método HTTP seguro y cuáles son ejemplos de estos?
- ¿Qué tipo de vulnerabilidad puede generarse si se confía ciegamente en el encabezado Host?
- ¿Qué mejoras introduce HTTP/2 respecto a HTTP/1.1?
- ¿Qué tipo de contenido puede encontrarse en el cuerpo de una solicitud POST?
Diez ejercicios prácticos sobre el contenido:
- Clasifica los siguientes métodos HTTP como seguros o peligrosos: GET, POST, DELETE, HEAD, PATCH.
- Redacta una línea de solicitud HTTP válida para obtener la página /login en el dominio example.com usando HTTP/1.1.
- Dado el siguiente encabezado, identifica qué información transmite:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) - Modifica el siguiente encabezado Accept para que indique que solo se acepta contenido JSON:
Accept: */* - Enumera los pasos en que se desarrolla una petición HTTP/1.1 desde que el navegador solicita un recurso hasta que lo recibe.
- Describe con tus palabras qué hace el método POST y por qué debe validarse el contenido que envía.
- Explica cómo usarías el método OPTIONS para descubrir métodos permitidos en un servidor web.
- Dado este encabezado: Accept-Encoding: gzip, deflate, ¿qué puede hacer el servidor en la respuesta?
- Escribe un ejemplo de una solicitud HTTP PUT que reemplace el recurso /api/user/42 con un nuevo nombre «Hacker», usando formato JSON.
- ¿Por qué es importante que la línea de encabezados termine con una línea vacía antes del cuerpo del mensaje?
Respuestas a las 10 preguntas (completas y detalladas)
1. ¿Cuál es la diferencia entre HTTP y HTTPS?
- HTTP transmite los datos en texto plano, lo que los hace vulnerables a interceptaciones.
- HTTPS utiliza SSL/TLS para cifrar los datos, protegiendo la comunicación entre el cliente y el servidor.
2. ¿Qué tres partes componen una solicitud HTTP?
- Request line (línea de solicitud): indica el método, la ruta solicitada y la versión del protocolo.
- Headers (encabezados): proporcionan metadatos como el tipo de navegador, formato de respuesta aceptado, etc.
- Cuerpo (body): presente en métodos como POST o PUT, contiene datos que el cliente envía al servidor.
3. ¿Qué función cumple la línea vacía (\r\n) en un mensaje HTTP?
- Separa los encabezados del cuerpo del mensaje.
- Su ausencia puede provocar que el mensaje no se procese correctamente por el servidor o cliente.
4. ¿Qué información suele incluir el encabezado User-Agent?
- Describe el tipo de navegador, sistema operativo, y su versión.
- Ejemplo:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/95.0
5. ¿Para qué se utiliza el método HEAD y en qué se diferencia de GET?
- Se usa para obtener solo los encabezados de una respuesta, sin el cuerpo.
- Es útil para verificar la existencia de recursos o su tipo sin descargarlos.
- GET sí obtiene también el contenido.
6. ¿Cuál es el propósito del encabezado Host?
- Indica el dominio al que va dirigida la solicitud.
- Es esencial en servidores con virtual hosting para saber a qué sitio responder.
7. ¿Qué es un método HTTP seguro y cuáles son ejemplos de estos?
- Son métodos que no modifican el estado del servidor.
- Ejemplos: GET, HEAD, OPTIONS.
- Son seguros e idempotentes.
8. ¿Qué tipo de vulnerabilidad puede generarse si se confía ciegamente en el encabezado Host?
- Puede surgir una vulnerabilidad de tipo Host Header Injection.
- Ejemplos:
- Redirecciones maliciosas.
- Generación de enlaces falsos de restablecimiento de contraseña.
9. ¿Qué mejoras introduce HTTP/2 respecto a HTTP/1.1?
- Multiplexación de peticiones/respuestas (varias por la misma conexión).
- Compresión de encabezados, menor latencia, mayor rendimiento.
- Prioridades de carga para recursos.
10. ¿Qué tipo de contenido puede encontrarse en el cuerpo de una solicitud POST?
- Formatos típicos:
- application/x-www-form-urlencoded
- application/json
- multipart/form-data
- application/xml
Respuestas a los 10 ejercicios prácticos
1. Clasificación de métodos:
- GET → Seguro
- POST → Peligroso
- DELETE → Peligroso
- HEAD → Seguro
- PATCH → Peligroso
2. Línea de solicitud válida:
GET /login HTTP/1.1
Host: example.com
3. ¿Qué indica el encabezado User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)?
- Que el cliente es un navegador Mozilla/5.0 en un sistema Windows 10 de 64 bits.
4. Modifica Accept para solo aceptar JSON:
Accept: application/json
5. Pasos de una petición HTTP/1.1:
- El navegador abre una conexión TCP.
- Envía una solicitud HTTP (ej. GET /index.html HTTP/1.1).
- El servidor responde con un código y contenido (200 OK, HTML).
- El navegador renderiza el contenido y puede solicitar más recursos.
- Se cierra la conexión si no está en modo keep-alive.
6. ¿Qué hace POST y por qué debe validarse?
- Envía datos al servidor, como formularios o archivos.
- Debe validarse para evitar ataques como SQL Injection o XSS.
7. Uso de OPTIONS:
- Sirve para saber qué métodos permite un endpoint.
- Ejemplo con curl:
curl -X OPTIONS https://example.com/resource -i
8. ¿Qué hace el servidor si ve Accept-Encoding: gzip, deflate?
- Comprime la respuesta usando gzip o deflate si está disponible.
- Envía Content-Encoding: gzip en la respuesta.
9. Solicitud PUT para actualizar recurso:
PUT /api/user/42 HTTP/1.1
Host: example.com
Content-Type: application/json
Content-Length: 24
{
«name»: «Hacker»
}
10. Importancia de la línea vacía antes del cuerpo:
- Indica el fin de los encabezados.
- Permite al receptor distinguir claramente entre headers y contenido real.
Qué aprendiste
Ahora sabes leer y construir una petición HTTP completa, interpretar una respuesta y comprender el efecto de cada encabezado y método en la seguridad y el comportamiento de una aplicación. Esto te servirá para:
- Reconocimiento efectivo: identificar endpoints, recursos y comportamientos distintos según headers o métodos.
- Pruebas dirigidas: manipular Host, User-Agent, Accept-Encoding, Content-Type y bodies para reproducir vulnerabilidades reales (IDOR, request smuggling, inyecciones, fugas por compresión).
- Diagnóstico y reportes profesionales: describir el vector exacto (método, ruta, headers, payload) y proponer mitigaciones concretas (sanitización, whitelisting de Host, deshabilitar métodos innecesarios, CSP, políticas de caching, límites de tamaño).
Siguiente paso recomendado: practica interceptando solicitudes reales con un proxy en un entorno de laboratorio —modifica headers y cuerpos, prueba distintos métodos y observa cómo cambian las respuestas—. Con esa práctica aplicada, pasarás de entender teoría a encontrar fallos reales y reportables. ¡Buen trabajo y continúa explorando el protocolo —es donde comienza casi todo hallazgo en pentesting web!