Hola hacketones! En este capítulo de TryHackMe – Data Encoding Aprenda cómo la computadora codifica caracteres, desde ASCII hasta UTF de Unicode.
De ASCII a Unicode
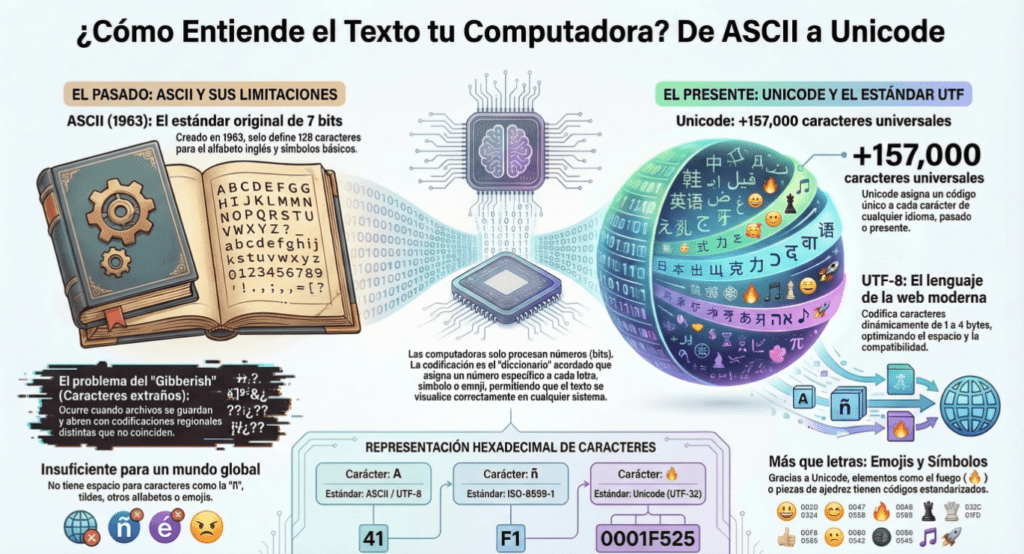
Las computadoras no entienden letras, palabras ni idiomas de la forma en que lo hacen las personas. Para una máquina, todo se reduce a números representados en bits. Cada carácter que aparece en una pantalla —ya sea una letra, un número, un símbolo o incluso un emoji— está asociado a un código numérico específico. Este sistema de correspondencias funciona como un diccionario digital que permite convertir texto humano en datos que el hardware puede procesar.
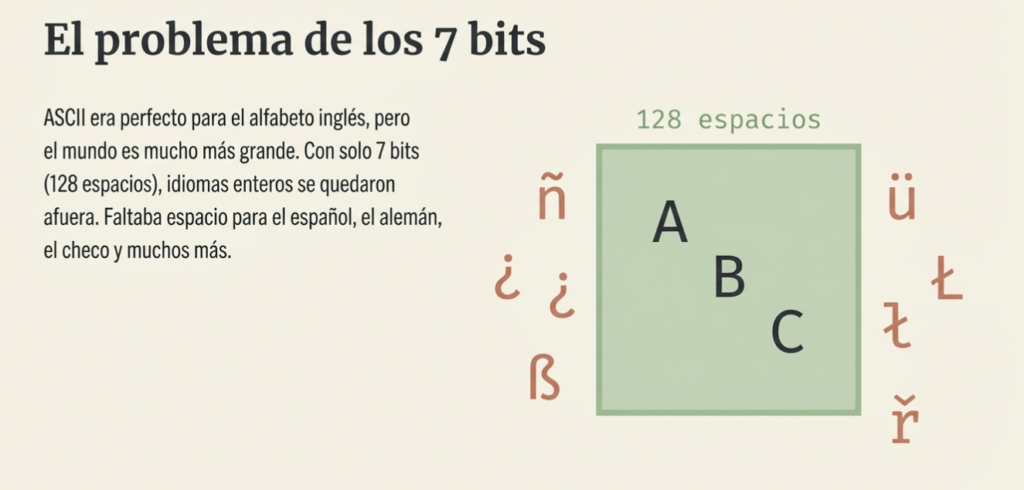
Durante los primeros años de la informática surgió ASCII, un estándar creado en 1963 que utilizaba 7 bits para representar caracteres. Esto permitía codificar únicamente 128 símbolos, suficientes para el alfabeto inglés, números y algunos signos de puntuación básicos. Sin embargo, este sistema pronto mostró sus limitaciones. No tenía espacio para letras con acentos, caracteres de otros alfabetos ni símbolos utilizados en distintos idiomas del mundo. Cuando diferentes sistemas intentaban interpretar archivos usando codificaciones incompatibles aparecía el conocido problema del “gibberish”, donde el texto se convertía en una serie de caracteres extraños e incomprensibles.
A medida que la informática se volvió global, surgió la necesidad de un sistema mucho más amplio y universal. Así nació Unicode, un estándar diseñado para asignar un código único a prácticamente cualquier carácter utilizado por la humanidad. Actualmente incluye más de 157,000 caracteres que abarcan alfabetos modernos, escrituras históricas, símbolos matemáticos, musicales y hasta emojis.
Cómo las Computadoras Interpretan el Texto
Para que este enorme catálogo de caracteres pueda utilizarse de forma eficiente, se emplean diferentes métodos de codificación como UTF-8, que es el más común en la web moderna. UTF-8 tiene la ventaja de usar entre uno y cuatro bytes por carácter, lo que permite mantener compatibilidad con ASCII mientras amplía enormemente la cantidad de símbolos disponibles. Gracias a esto, un mismo sistema puede representar sin problemas texto en español, chino, árabe o japonés dentro del mismo documento.
Cada carácter dentro de Unicode posee también una representación numérica que puede expresarse en formatos como hexadecimal. Por ejemplo, una letra simple, un carácter acentuado o incluso un emoji tienen códigos únicos que las computadoras interpretan internamente. Esto permite que el mismo texto pueda almacenarse, transmitirse y visualizarse correctamente en distintos sistemas y plataformas.
La comunicación digital moderna depende completamente de estos estándares. Cada mensaje, cada página web y cada línea de código que se escribe pasa por este proceso de traducción entre símbolos humanos y números que las computadoras pueden procesar. Gracias a esta evolución, hoy es posible que el texto digital sea verdaderamente universal.
Estándares y Ejemplos de Codificación de Caracteres
| Carácter o Símbolo | Descripción | Código Decimal | Código Hexadecimal / Punto de Código | Codificación Binaria | Estándar de Codificación |
| 0 | Cero | 48 | 30 | 00110000 | ASCII |
| 9 | Nueve | 57 | 39 | 00111001 | ASCII |
| A | A mayúscula | 65 | 41 | 01000001 | ASCII |
| T | T mayúscula | No en la fuente | 54 | 01010100 | ASCII |
| X | X mayúscula | 88 | 58 | 01011000 | ASCII |
| Y | Y mayúscula | 89 | 59 | 01011001 | ASCII |
| Z | Z mayúscula | 90 | 5A | 01011010 | ASCII |
| [ | Corchete de apertura | 91 | 5B | 01011011 | ASCII |
| \ | Barra invertida | 92 | 5C | 01011100 | ASCII |
| ] | Corchete de cierre | 93 | 5D | 01011101 | ASCII |
| ^ | Caret – acento circunflejo | 94 | 5E | 01011110 | ASCII |
| _ | Guion bajo | 95 | 5F | 01011111 | ASCII |
| ` | Acento grave | 96 | 60 | 01100000 | ASCII |
| a | a minúscula | 97 | 61 | 01100001 | ASCII |
| b | b minúscula | 98 | 62 | 01100010 | ASCII |
| c | c minúscula | 99 | 63 | 01100011 | ASCII |
| z | z minúscula | 122 | 7A | 01111010 | ASCII |
| DEL | Borrar (Delete) | 127 | 7F | 01111111 | ASCII |
| Ω | Letra griega Omega | No en la fuente | U+03A9 | No en la fuente | Unicode |
| あ | Hiragana japonés ‘a’ | No en la fuente | U+3042 | No en la fuente | Unicode |
| 🔥 | Emoji de fuego | No en la fuente | U+1F525 | No en la fuente | Unicode (UTF-8, UTF-16, UTF-32) |
| 龍 | Carácter chino para ‘dragón’ | No en la fuente | U+9F8D / U+00009F8D | No en la fuente | Unicode (UTF-16 / UTF-32) |
| 😊 | Cara sonriente | No en la fuente | U+0001F60A | 0000 0000 0000 0001 1111 0110 0000 1010 | UTF-32 |
| ツ | Letra japonesa ‘tsu’ | No en la fuente | U+30C4 / U+000030C4 | No en la fuente | Unicode (UTF-16 / UTF-32) |
| ت | Letra árabe ‘taa’ | No en la fuente | U+062A | No en la fuente | Unicode |
| ♞ | Caballo negro de ajedrez | No en la fuente | U+265E | 0010 0110 0101 1110 | Unicode |
En la clase anterior, aprendieron cómo se representan los números en la computadora como dígitos binarios (bits) y cómo estos bits se pueden agrupar en dígitos hexadecimales. También exploramos cómo expresar colores con números. Ahora bien, si todo se almacena como números, ¿cómo los convertimos en letras, signos de puntuación y emojis?
En esta sala, aprenderá que los caracteres son simplemente números con significados acordados. Este acuerdo se denomina codificación . ¿Alguna vez ha abierto un documento, visitado una página web o descargado subtítulos de películas y ha visto que el archivo aparece como un galimatías extraño? Una razón es que el usuario que guardó el archivo y el que lo abrió usan codificaciones diferentes.
La representación es la idea de que los datos residen en la memoria como bits y números. A su vez, la codificación es la correspondencia específica y acordada entre números y significados, como qué número corresponde al carácter «A». En un texto, a cada carácter, como q, 5o !, se le asigna un código numérico, de modo que una cadena se convierte en una secuencia de números que la computadora almacena y procesa como cualquier otro dato.
Objetivos de aprendizaje
Al finalizar esta sala, aprenderá sobre:
- ASCII
- Unicode
- UTF-8, UTF-16 y UTF-32
- Cómo se codifican los emojis
- ¿Y qué causa los extraños caracteres sin sentido?
Requisitos previos de la habitación
Para aprovechar al máximo esta sala es imprescindible haber finalizado la sala de Representación de Datos .

ASCII
Ya aprendimos que las computadoras digitales solo entienden ceros y unos. A partir de 0y 1, ¿cómo podemos guardar y mostrar texto? Por ejemplo, ¿cómo podemos guardar el texto «TryHackMe» en un archivo? ¿Qué contendrá dicho archivo?
Para poder responder a esta pregunta, necesitamos acordar qué bits representan T, qué bits representan r, qué bits representan y, etc. Supongamos que todos acordamos representar Tcon el siguiente flujo de bits: 01010100. Entonces, todos los sistemas informáticos deberían almacenar Tde la misma manera y, más adelante, cuando un ordenador encuentre 01010100, lo reconocerá como T. Por supuesto, necesitamos hacer esto para todas las letras del alfabeto, dígitos y caracteres especiales. Este enfoque requiere un estándar que los fabricantes, diseñadores y programadores de computadoras acuerden cumplir. Uno de los primeros estándares para las letras del inglés fue ASCII.

ASCII significa Código Estándar Americano para el Intercambio de Información (American Standard Code for Information Interchange) y es una codificación de caracteres temprana de 1963 que utiliza los números del 0 al 127 para representar letras, dígitos, signos de puntuación y algunos caracteres de control del inglés. Recuerde que la A significa «American», ya que le será útil más adelante. Como habrá notado, el ASCII original estaba limitado a siete bits. ASCII funciona como un pequeño diccionario bilingüe entre texto y códigos numéricos. Considere los siguientes ejemplos de la tabla ASCII original. Dado que la tabla tiene 128 entradas, solo hicimos una breve selección para darle una idea de cómo se representan los elementos en ASCII.
| Decimal | Hexadecimal | Binario | Símbolo | Descripción |
| … | … | … | … | … |
| 48 | 30 | 00110000 | 0 | Cero |
| … | … | … | … | … |
| 57 | 39 | 00111001 | 9 | Nueve |
| … | … | … | … | … |
| 65 | 41 | 01000001 | A | A mayúscula |
| … | … | … | … | … |
| 88 | 58 | 01011000 | incógnita | X mayúscula |
| 89 | 59 | 01011001 | Y | Y mayúscula |
| 90 | 5A | 01011010 | Z | Z mayúscula |
| 91 | 5B | 01011011 | [ | Soporte de apertura |
| 92 | 5C | 01011100 | \ | Barra invertida |
| 93 | 5D | 01011101 | ] | Corchete de cierre |
| 94 | 5E | 01011110 | ^ | Signo de intercalación – circunflejo |
| 95 | 5F | 01011111 | _ | Guión bajo |
| 96 | 60 | 01100000 | ` | acento grave |
| 97 | 61 | 01100001 | a | A minúscula |
| 98 | 62 | 01100010 | b | B minúscula |
| 99 | 63 | 01100011 | do | C minúscula |
| … | … | … | … | … |
| 122 | 7A | 01111010 | z | Z minúscula |
| … | … | … | … | … |
| 127 | 7F | 01111111 | DEL | Borrar |
Hay varias cosas que puedes observar. Primero, las letras están en orden. Si conoces el número hexadecimal o decimal de b, puedes calcular el número decimal de a, cy posteriormente de las letras minúsculas. Por ejemplo, a , b y c se les asignan los números hexadecimales 61, 62y 63, respectivamente. Lo mismo ocurre con las letras mayúsculas Aa Zy los dígitos 0a 9. Al usar la codificación ASCII, un sistema informático lee 41un archivo y lo muestra A en la pantalla; cuando lee 42, muestra B, y así sucesivamente.
En segundo lugar, cada carácter tiene su propio código ASCII, por ejemplo, [está representado por el número hexadecimal 5B.
“TryHackMe” en ASCII
Supongamos que abres un archivo de texto, escribes «TryHackMe» y lo guardas como file.txt. ¿Cómo se verá el archivo a nivel de bits? Averigüémoslo.
Si está interesado en ver el almacenamiento en el disco, bit a bit, y asumiendo que está usando ASCII, verá algo similar a lo siguiente:
01010100 01110010 01111001 01001000 01100001 01100011 01101011 01001101 01100101 00001010
Obviamente, esto no es legible para ningún ser humano. Estas son las representaciones binarias exactas de todas las letras de «TryHackMe» seguidas de una nueva línea. Al abrir este archivo, el editor leerá estos bits y mostrará los siguientes caracteres: T r y H a c k M e \n; \n es una nueva línea que se obtiene al pulsar Enter.

Dado que leer números binarios es engorroso y propenso a errores, preferimos usar dígitos hexadecimales. Como recordarán de la sala anterior, agrupamos 4 bits en un solo dígito hexadecimal. Nuestro archivo se ve así en hexadecimal:54 72 79 48 61 63 6b 4d 65 0a
Si desea consultar la representación decimal, sería así: 124 162 171 110 141 143 153 115 145 012; sin embargo, no es común usar dígitos decimales. Es más común usar dígitos hexadecimales cuando queremos mostrar los bits.
Puede utilizar el sitio estático adjunto para experimentar más.
Lenguas europeas
ASCII proporcionó una forma de codificar el alfabeto inglés; sin embargo, necesitamos una codificación compatible con otros idiomas europeos como el español (ñ, ¿), el alemán (ß, ü), el polaco (ł, ń), el checo (č, ř) y el rumano (ș, ț), por nombrar algunos. ASCII utiliza 7 bits, y con un octavo bit, obtenemos 128 caracteres adicionales que cubrir. Sin embargo, la realidad es más compleja: los 128 caracteres adicionales no son suficientes para cubrir todas las letras de los idiomas europeos. La serie ISO/IEC 8859 (Normas Internacionales) creó varias normas; cada norma abarcaba un conjunto de idiomas:
- ISO-8859-1 (Latin-1) : Cubre idiomas de Europa Occidental como alemán (ß, ü), francés (é, ç), español (ñ, ¿), italiano, portugués, catalán y lenguas nórdicas (p. ej., islandés ð/Ð). Consulta este enlace .
- ISO-8859-2 (Latin-2) : Idiomas de Europa Central y Oriental compatibles , como polaco (ł, ń), checo (č, ř), húngaro (ő, ű), croata (đ), rumano (ș, ț) y eslovaco. Consulta este enlace .
En otras palabras, si su documento se guarda utilizando ISO-8859-1 y luego se lee y se muestra como si se hubiera guardado utilizando ISO-8859-2, es probable que las letras que no estén en inglés se muestren de forma diferente.
Haga clic en el botón Ver sitio a continuación y utilícelo para responder las siguientes preguntas.
Responda las preguntas a continuación
¿Cuál es el código ASCII en decimal para el carácter @?
64
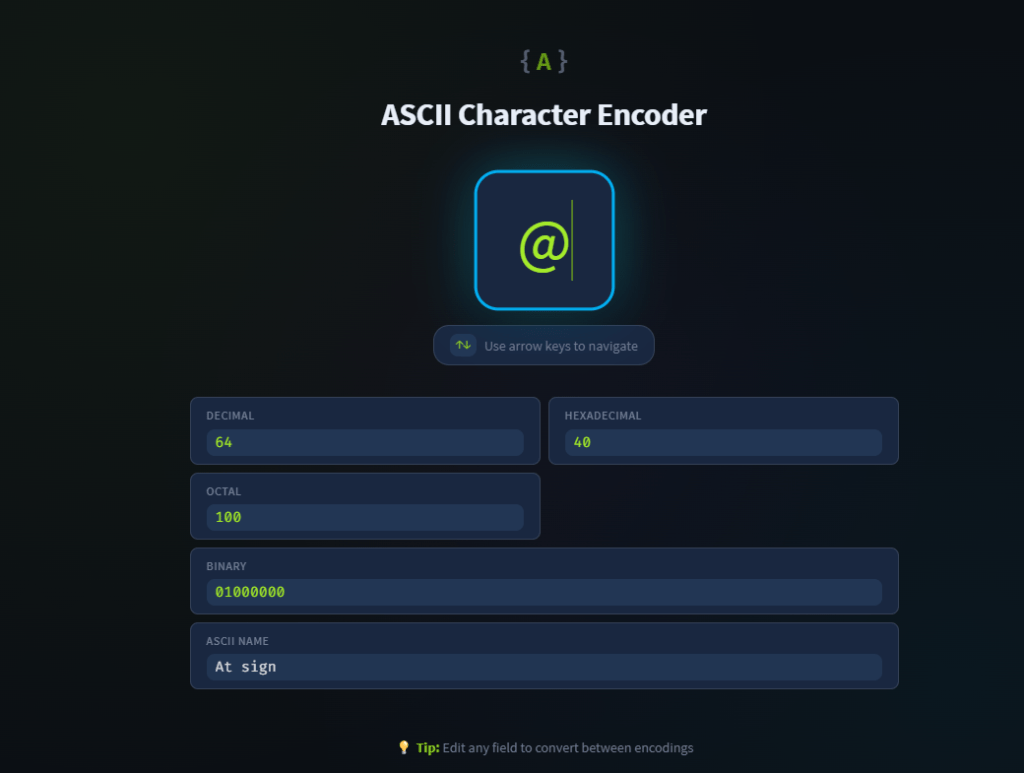
¿Cuál es el caracter que tiene el código ASCII de 35 en decimal?
#
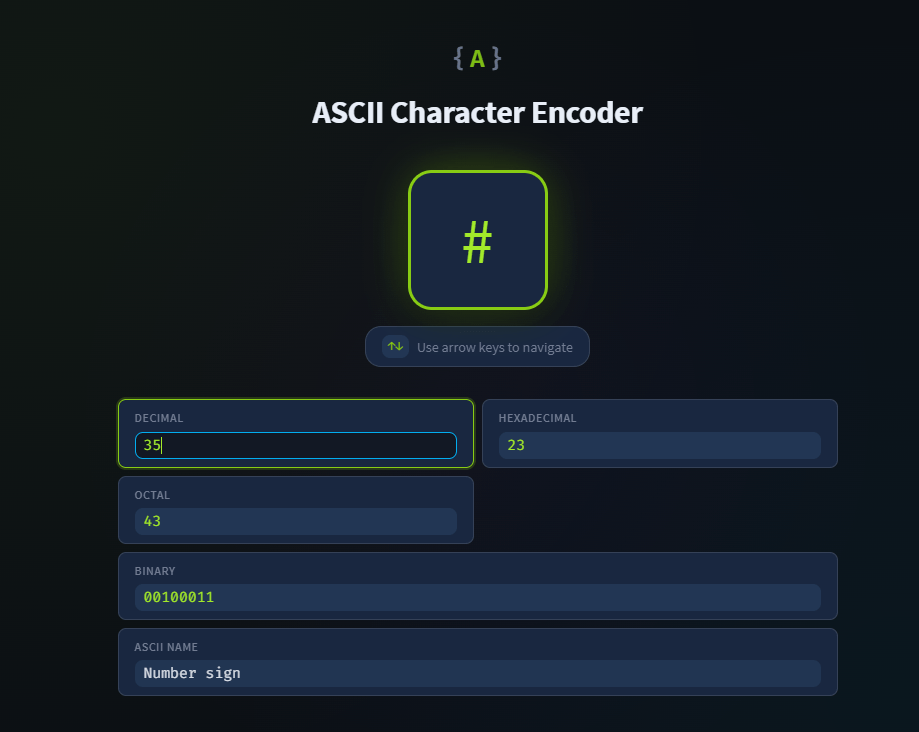
¿Cuál es el nombre del carácter que tiene el código ASCII de 7?
BEL
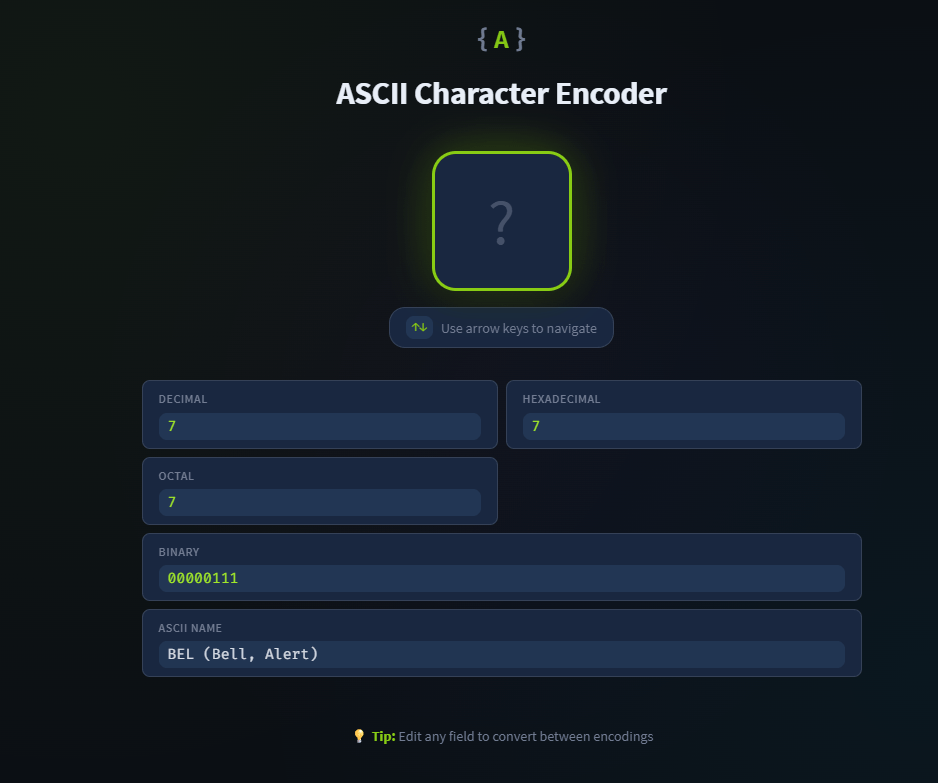
Unicode
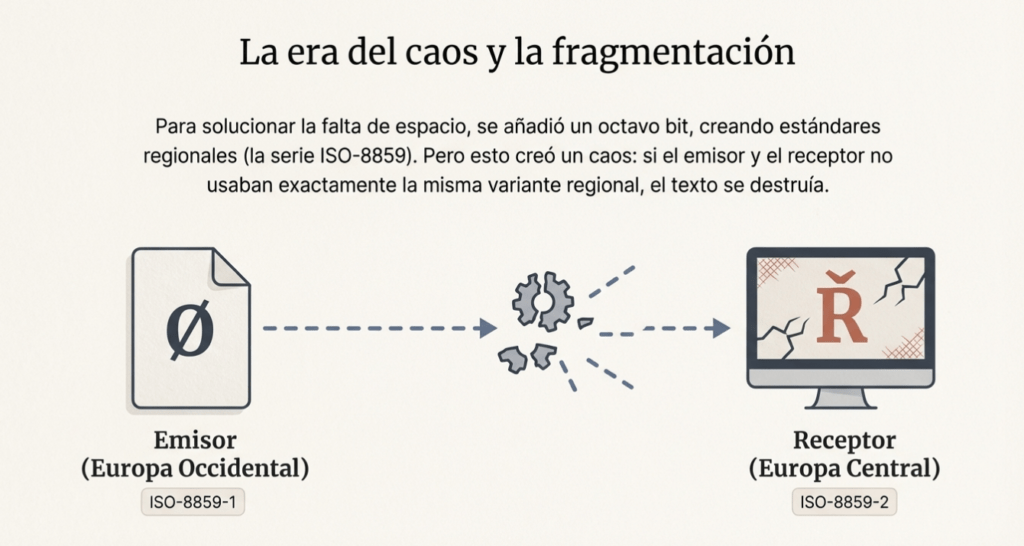
Aprendimos que ASCII es un estándar de 7 bits que define 128 caracteres que abarcan letras, dígitos y puntuación básica del inglés. También observamos cómo ASCII, con sus siete bits, no tenía espacio para caracteres como ñ, €, あo ب. Usando ocho bits, el ASCII extendido intentó parchar esto con variantes regionales (ISO-8859-1, ISO-8859-2, Windows-1252, entre muchas otras), ¡pero esto causó caos! Por ejemplo, si el remitente escribe y guarda Øusando la codificación ISO 8859-1 (Latin 1) y el destinatario abre y lee el documento usando la codificación ISO 8859-2 (Latin 2), verá Ř. Por lo tanto, es claro cómo abrir un documento requiere que usemos la misma codificación que usamos al guardarlo; de lo contrario, varios caracteres no se mostrarán correctamente, o aún más confuso, podrían ser reemplazados incorrectamente.
A diferencia del inglés, que tiene 26 letras y necesita 52 caracteres para cubrir mayúsculas y minúsculas, el árabe necesita más de 250 caracteres para cubrir sus diversas ligaduras y diacríticos. Además, el número aumenta rápidamente cuando se consideran el japonés y el chino. En japonés, 2136 kanji (caracteres logográficos) se consideran caracteres de uso diario, según lo dispuesto por el Ministerio de Educación de Japón. De hecho, el estándar JIS X 0208 define 6879 caracteres . En chino, los nativos educados reconocen alrededor de 8000 caracteres. Además, el GB 18030-2022 define más de 87 887 hanzi (caracteres chinos) . Y aún así, no hemos considerado la codificación de emoticones (emoji).
En otras palabras, es esencial que tanto el emisor como el receptor utilicen la misma codificación; además, necesitamos una codificación que incluya todos los caracteres de todos los idiomas. Esta situación nos lleva a Unicode.
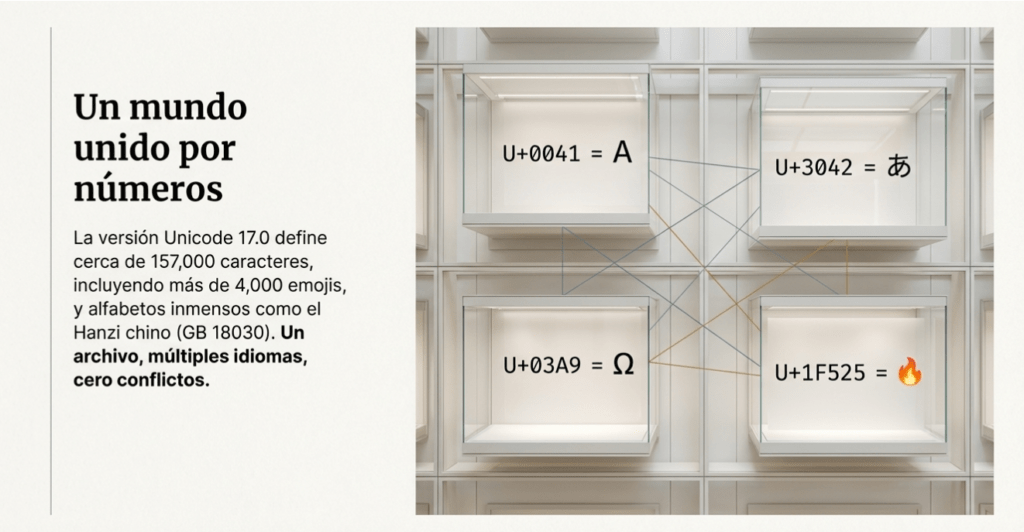
Unicode es un estándar universal de codificación de caracteres. Asigna puntos de código únicos a caracteres de todos los sistemas de escritura modernos e históricos del mundo. Unicode facilita el intercambio, el procesamiento y la visualización de texto en diversos idiomas. En otras palabras, no tenemos que preocuparnos por elegir un estándar de codificación específico que sea compatible con el idioma que utilizamos. Además, esto facilita el uso de diferentes idiomas en un mismo archivo o mensaje. Y lo más importante, al ser un estándar universal, no tenemos que preocuparnos por la codificación utilizada por el autor original, ya que este también utilizará Unicode.
Unicode es un conjunto de caracteres estándar que asigna un número único a cada carácter en todos los idiomas. Ejemplos:
- U+0041 = “A” latina
- U+03A9 = Griego “Ω”
- U+3042 = Hiragana japonés “あ”
Unicode 17.0 es la versión más reciente del estándar Unicode . Define cerca de 157 000 caracteres, de los cuales casi 4000 son secuencias de emojis.

UTF-8, UTF-16 y UTF-32
Dado que encontrará UTF-8, UTF-16 y UTF-32, los abordaremos brevemente sin profundizar demasiado. Lo que necesita saber es que UTF-8 es muy común en la web moderna. Codifica los puntos Unicode en 1 a 4 bytes dinámicamente. En otras palabras, decide la cantidad de bytes según la complejidad del carácter. Los caracteres ASCII ( U+0000a U+007F) usan exactamente 1 byte, idéntico al ASCII original, lo que garantiza una compatibilidad con versiones anteriores perfecta. Los caracteres no ASCII como Ω ( U+03A9) usan 2 bytes, mientras que las escrituras complejas o emojis como 🔥 ( U+1F525) requieren 4 bytes. Esta flexibilidad nos permite cubrir el estándar Unicode sin desperdiciar bytes.

UTF-16 toma una ruta diferente; utiliza 2 o 4 bytes por carácter. Los caracteres comunes, como la mayoría de los latinos, cirílicos o chinos hanzi, caben en 2 bytes; sin embargo, los menos comunes, como los emojis o las escrituras antiguas, requieren un par, es decir, dos unidades de 16 bits que suman 4 bytes. Por ejemplo, la letra Ase codifica como U+0041, mientras que el emoji 🔥 necesita dos y se codifica como U+D83D U+DD25.

Finalmente, UTF-32 es el más simple, pero también el que más desperdicia; cada punto de código Unicode ocupa exactamente 4 bytes. Por ejemplo, Ase codifica como U+00000041y 🔥 se codifica como U+0001F525.
Exploremos algunos ejemplos más:
- 龍: Uno de los caracteres chinos que aparecen en distribuciones de Linux ofensivas, como Kali, es “龍”, que significa “dragón”. En Unicode, es U+9F8Do U+00009F8D, dependiendo de si es UTF-16 o UTF-32.
- 😊: Esta cara sonriente no es nada más que U+0001F60Aen UTF-32 para una computadora; eso es literalmente 0000 0000 0000 0001 1111 0110 0000 1010.
- ツ: La letra japonesa “tsu” que algunas personas usan como cara sonriente en algunas regiones fuera de Japón; tiene el código U+30C4 o U+000030C4 dependiendo de si es UTF-16 o UTF-32.
- ت es la letra árabe «taa», y algunas personas la usan como emoticón fuera del mundo árabe; se parece bastante a una carita feliz. Desde la perspectiva de Unicode, es U+062A…
- ♞: El caballo negro en ajedrez utiliza el código Unicode U+265E; en otras palabras, la computadora lee 0010 0110 0101 1110y te muestra un caballo negro, gracias a Unicode.
Hemos creado un sitio estático para ayudarle a buscar caracteres y explorar otros nuevos disponibles en la mayoría de las fuentes estándar.

Responda las preguntas a continuación
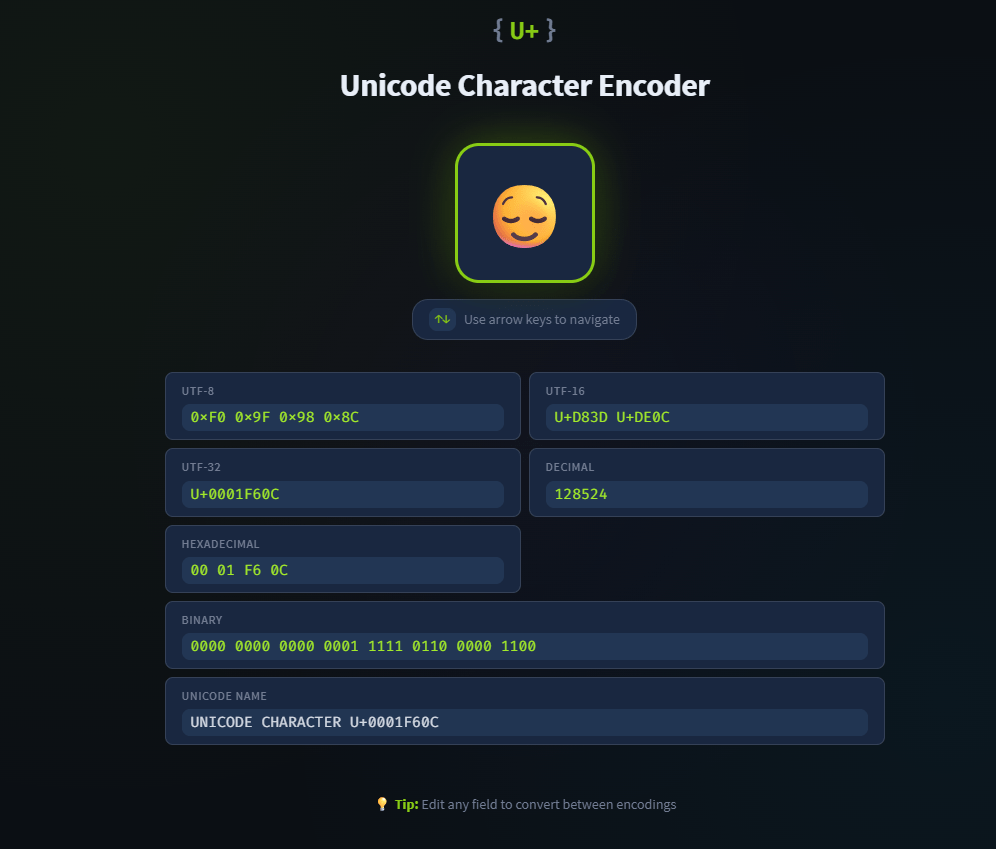
¿Cuál es la codificación UTF-32 de 😌?
U+0001F60C
¿Cuál es la codificación UTF-16 de シ? Tenga en cuenta que ツ y シ son dos caracteres diferentes.
U+30B7
¿Cuál es el carácter que tiene la siguiente codificación UTF-32 U+0001F60E?
😎
¿Cuál es el carácter que tiene la siguiente codificación UTF-16 U+2658?
♘
Conclusión
En esta sala, aprendimos sobre ASCII y sus limitaciones, así como sobre Unicode y tres estándares de codificación: UTF-8, UTF-16 y UTF-32. Exploramos cómo Unicode nos permite abarcar no solo los idiomas del mundo, sino también símbolos como piezas de ajedrez y emojis.
Si tienes curiosidad por ver cómo las computadoras manipulan los datos, únete a la sala de demostración de Python.
Sigan entrenando, Hacketones, Nos vemos en el próximo laboratorio!!!