En este capítulo veremos el Uso de Spider & Ajax Spider en ZAP (Zed Attack Proxy). Zap es una herramienta de código abierto ampliamente utilizada para el análisis y prueba de seguridad de aplicaciones web. Actuando como proxy intermediario, ZAP permite observar, interceptar y modificar el tráfico HTTP/HTTPS entre el cliente y el servidor, realizar rastreos automáticos y conducidos, y ejecutar escaneos pasivos y activos para identificar vulnerabilidades comunes. Gracias a su ecosistema de complementos —araña tradicional, AJAX Spider, Client Spider, fuzzer, escáner pasivo/activo, HUD y muchas integraciones— ZAP es útil tanto para auditorías rápidas como para pruebas más profundas en entornos de desarrollo y pruebas automatizadas.
Este documento describe en detalle las capacidades de rastreo (spiders) de ZAP —cómo funcionan, cuándo usar cada variante, configuración recomendada y buenas prácticas— con ejemplos prácticos y advertencias de seguridad para que puedas aprovechar ZAP de forma eficaz y responsable.
Nuestro Flujo de Trabajo: Un Proceso en Tres Fases
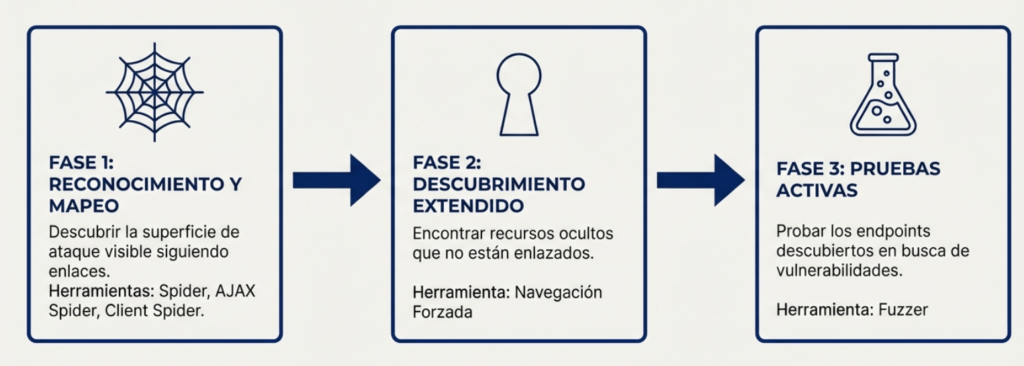
Esta guía sigue el proceso lógico de una auditoría real, contextualizando cada herramienta de ZAP en el momento preciso en que un profesional la necesita.
Fase 1: Reconocimiento y Mapeo de la Superficie de Ataque
¿Por dónde empezamos? ¿Qué partes de la aplicación son visibles y accesibles? El primer paso en cualquier auditoría es construir un mapa detallado de la aplicación. Necesitamos entender su estructura, rutas y parámetros para identificar
posibles puntos de entrada. ZAP ofrece un arsenal de herramientas de rastreo, conocidas como «arañas» (Spiders), diseñadas para automatizar este proceso de descubrimiento. Cada araña tiene una especialidad. La clave del éxito es
saber cuál usar en cada tipo de aplicación.
Fase 2: Descubrimiento Extendido
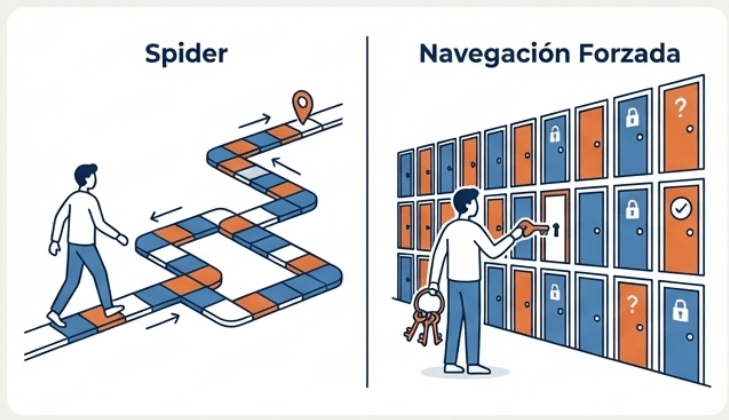
Las arañas encontraron las rutas visibles, pero… ¿qué hay de las puertas que no tienen un camino que lleve a ellas? Las arañas son excelentes para seguir rutas conocidas, pero muchos recursos críticos no están enlazados públicamente. Ejemplos comunes incluyen: paneles de administración, archivos de backup C .bak’), endpoints de API antiguos, archivos de configuración expuestos o directorios de recursos C /uploads/’). Para encontrar estos ‘secretos’, no podemos seguir
enlaces. Debemos probar las puertas directamente.
Navegación Forzada: Probando Todas las Puertas
¿Cómo funciona?
• En lugar de analizar el contenido de la página, la Navegación Forzada utiliza diccionarios (listas de palabras) con nombres comunes de archivos y directorios.
• Realiza peticiones directas al servidor para cada entrada de la lista (ej: ‘https://target.com/admins, https://target.com/backup.zipv, https://target.com/config.php’). • Analiza el código de respuesta para determinar si el recurso existe (ej. 200 OK vs. 404 Not Found). Basado en el proyecto OWASP DirBuster.
Opciones clave a configurar
Archivo de diccionario: ZAP incluye listas de DirBuster. Elige una adecuada para la tecnología del objetivo.
Recursivo: Si encuentra un directorio, comienza a buscar dentro de él.
Extensiones de archivo: Busca archivos con extensiones específicas (ej: ‘.php•, Iconfig•, ‘.bak).
Fase 3: Pruebas Activas y Fuzzing
Tenemos un mapa completo del territorio. Ahora, ¿cómo probamos la resistencia de cada puerta, ventana y cerradura? El descubrimiento nos ha proporcionado una lista exhaustiva de endpoints, parámetros y puntos de entrada de datos. La fase de Pruebas Activas consiste en interactuar con estos puntos de forma controlada pero agresiva para provocar comportamientos inesperados y revelar fallos de seguridad. La técnica principal para esto en ZAP es el Fuzzing.
Fuzzing: El Arte de Provocar Fallos con Entradas Inesperadas
El fuzzing es una técnica de prueba automatizada que consiste en enviar datos inválidos, inesperados o aleatorios a las entradas de una aplicación y analizar sus respuestas.
El Objetivo
Observar si la aplicación se comporta de forma anómala, revelando vulnerabilidades. Buscamos respuestas como:
• Errores de base de datos.
• Stack traces.
• Reflejo de nuestro input sin sanitizar.
• Cambios inesperados en el estado de la aplicación.
El Arma: Payloads
Un payload es la «carga útil» maliciosa que inyectamos. ZAP viene con librerías de payloads (basadas en FuzzDB) para detectar vulnerabilidades comunes como:
• SQL Injection (SQLi)
• Cross-Site Scripting (XSS)
• File Inclusion (LFI/RFI)
• XML External Entity (XXE)
• Y muchas más.
Caso Práctico: Descubriendo una SQL Injection con el Fuzzer
Hemos descubierto un formulario (mediante un Spider) que envía datos a través de un parámetro ENTRY usando el método POST. ¿Qué sucede si en lugar de datos normales, enviamos caracteres especiales y fragmentos de consultas SQL a través del parámetro entry ?
El Proceso en ZAP
1. Seleccionar la Petición: En el historial de ZAP, localizamos la petición POST del formulario.
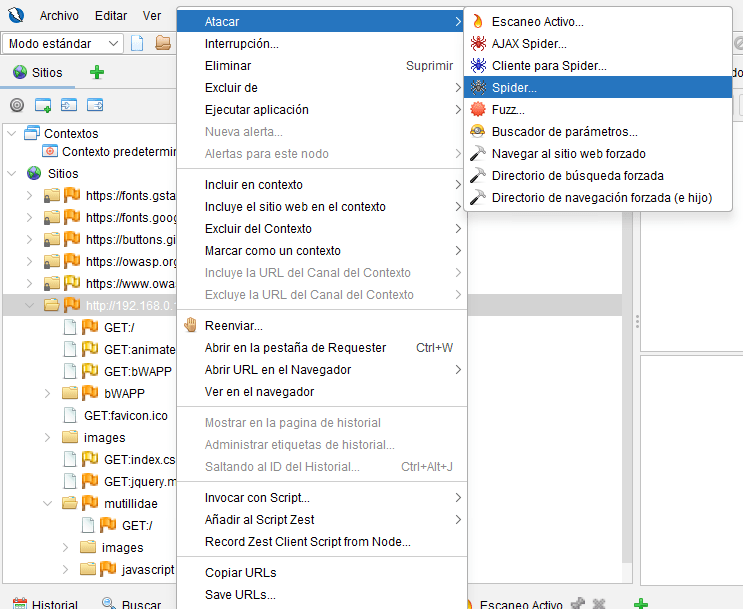
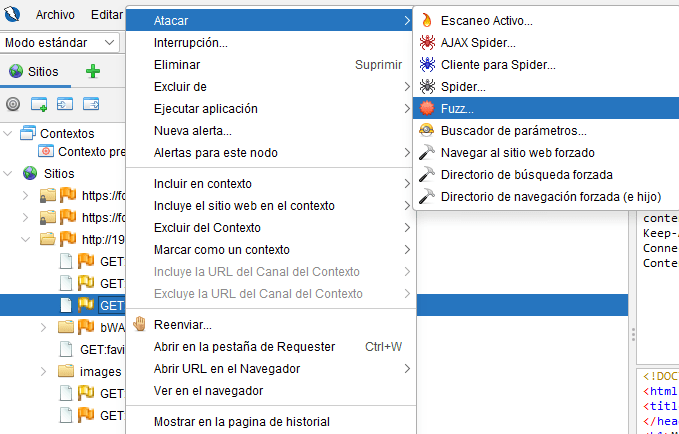
2. Iniciar Fuzzer: Clic derecho -> Atacar -> Fuzz…
3. Marcar la Ubicación: En la ventana del Fuzzer, resaltamos el valor del parámetro entry . Hacemos clic en «Añadir…» para marcarlo como el punto de inyección.
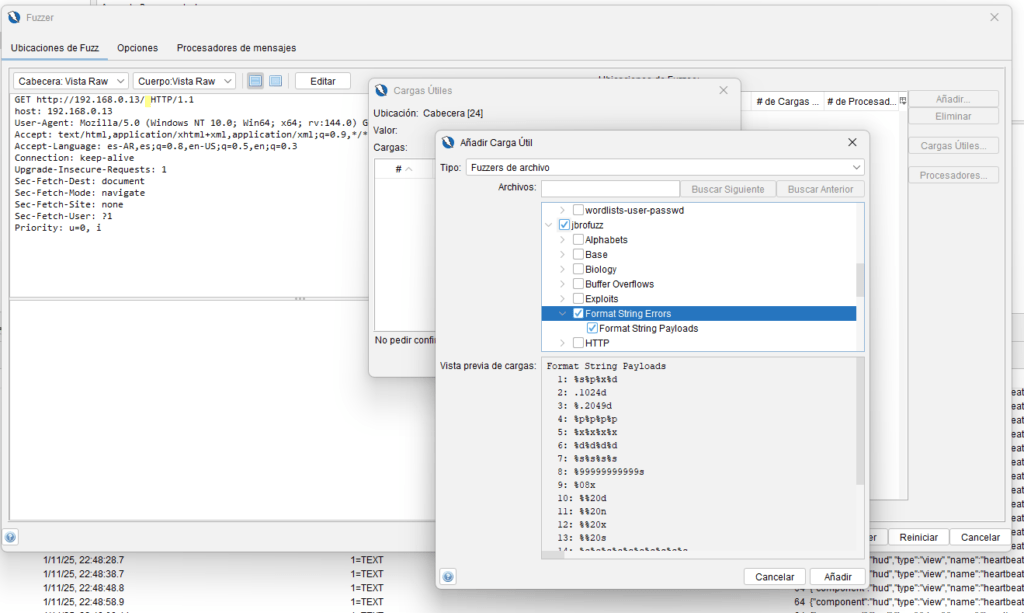
4. Añadir Payloads: En el diálogo de ‘Cargas útiles’, seleccionamos un archivo de la categoría de Inyección SQL o añadimos manualmente payloads conocidos (ej: ´’, ´»», ‘ OR 1=1–´)
5. Lanzar Ataque: Hacemos clic en ‘Iniciar Fuzzer’. ZAP enviará una petición por cada payload, reemplazando el valor original de entry .
Análisis del Resultado: La Evidencia de la Vulnerabilidad
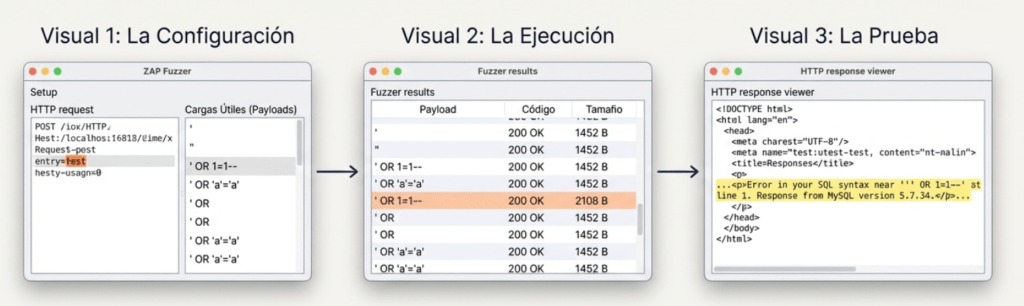
Una de las inyecciones tuvo éxito. La respuesta del servidor filtró la versión de la base de datos. Esto confirma una vulnerabilidad crítica de SQL Injection.
Resumen del Flujo de Trabajo y Configuraciones de Partida
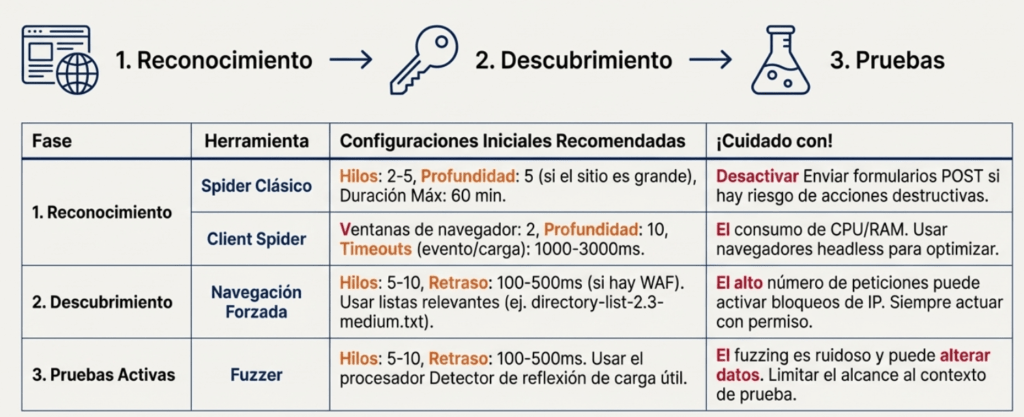
Combina estas herramientas para una cobertura exhaustiva. Empieza amplio con los Spiders, profundiza con la Navegación Forzada y ataca con precisión usando el Fuzzer sobre los descubrimientos más prometedores.
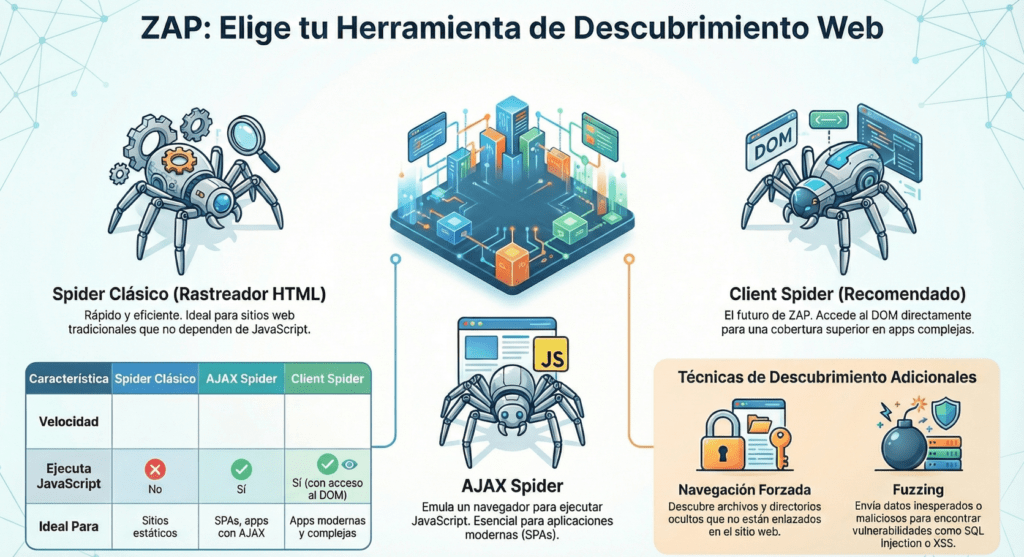
El Arsenal de Arañas de ZAP: Tres Herramientas para Tres Desafíos


Flujo de trabajo sugerido: Comienza con el Spider Clásico para un mapa base rápido. Luego, utiliza el Client Spider (autenticado, si es necesario) para explorar a fondo las áreas interactivas y ricas en JavaScript.
Araña ZAP – Spider
La primera herramienta que veremos es la araña estándar de ZAP. Esta araña solicita páginas web y las analiza en busca de enlaces a otras páginas dentro de la misma aplicación web. Este proceso recursivo continúa mientras se descubren nuevos enlaces.
¿Cómo funciona?
• Comienza con una lista de URLs «semilla».
• Solicita cada página y analiza la respuesta HTML en busca de hipervínculos en etiquetas y atributos como:
href (en <a>, <link>, <area>)
src (en <img>, <script>, <iframe>)
action (en <form>)
Comentarios HTML, robots.txt y sitemap.xml (si se configura).
• El proceso se repite recursivamente con cada nuevo recurso descubierto.
Fortalezas
• Velocidad: Extremadamente rápido, ideal para obtener un mapa base inicial en segundos.
• Bajo Consumo de Recursos: No requiere iniciar navegadores completos.
Limitación Crítica
• No ejecuta JavaScript: No puede descubrir rutas, enlaces o contenido que se genere dinámicamente en el cliente. Ineficaz para SPAs.
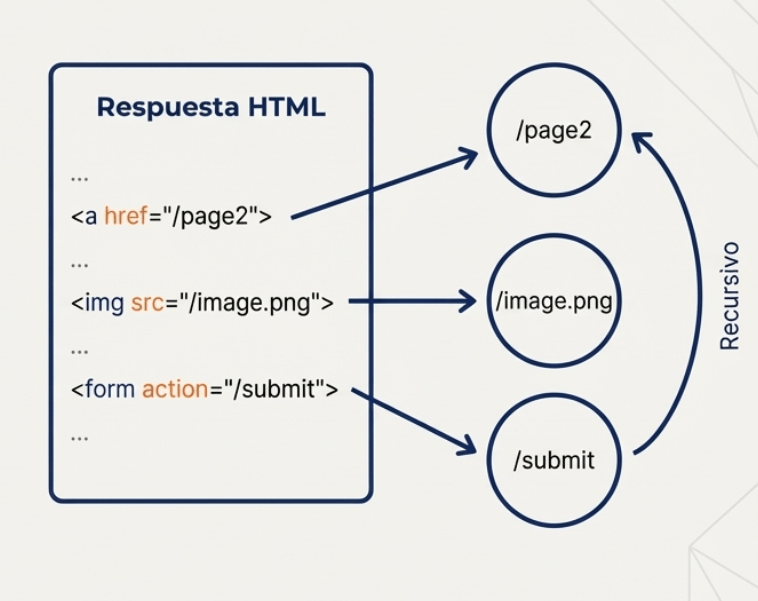
El rastreo web te permite explorar la estructura de una aplicación para descubrir tantas rutas/parámetros existentes como sea posible.
La Araña es una herramienta que se utiliza para descubrir automáticamente nuevos recursos (URL) en un sitio en particular. Comienza con una lista de URL para visitar, llamadas semillas, que depende de cómo se inicie la Araña. Luego, la Araña visita estas URL, identifica todos los hipervínculos en la página y los agrega a la lista de URL para visitar, y el proceso continúa recursivamente mientras se encuentren nuevos recursos. Esto se puede usar para identificar archivos, directorios o puntos finales ocultos o desconocidos que podrían no haber sido visibles o identificables mediante un ataque de fuerza bruta de directorio

Acerca del Spider
Spider es una herramienta que se utiliza para descubrir automáticamente nuevos recursos (URL) en un sitio en particular. Comienza con una lista de URL para visitar, llamadas semillas, que depende de cómo se inicie Spider. Luego, Spider visita estas URL, identifica todos los hipervínculos en la página y los agrega a la lista de URL para visitar. El proceso continúa recursivamente mientras se encuentren nuevos recursos. Spider se puede configurar e iniciar usando el cuadro de diálogo Spider. Durante el procesamiento de una URL, Spider realiza una solicitud para obtener el recurso y luego analiza la respuesta, identificando los hipervínculos. Actualmente tiene el siguiente comportamiento al procesar los tipos de respuestas:
HTML
Procesa las etiquetas específicas, identificando enlaces a nuevos recursos:
- Base – Manejo adecuado
- A, Enlace, Área, Base – atributo ‘href’
- Applet, Audio, Incrustar, Marco, IFrame, Entrada, Script, Img, Video – atributo ‘src’
- Blockquote – atributo ‘cite’
- Meta – ‘http-equiv’ para ‘location’, ‘refresh’ y ‘Content-Security-Policy’, ‘name’ para ‘msapplication-config’
- Applet – atributos ‘codebase’, ‘archive’
- Img – atributos ‘longdesc’, ‘lowsrc’, ‘dynsrc’, ‘srcset’
- Isindex – atributo ‘action’
- Object – atributos ‘codebase’, ‘data’
- Param – atributo ‘value’
- Svg – atributos ‘href’ y ‘xlink:href’ de los elementos ‘image’ y ‘script’
- Table – atributo ‘background’
- Video – atributo ‘poster’
- Formulario: manejo adecuado de formularios con los métodos GET y POST. Los valores de los campos se generan de forma válida, incluyendo los tipos de entrada HTML 5.0 ‘form’, ‘formaction’ y ‘formmethod’. También se respetan los atributos de los botones.
- Comentarios: las etiquetas válidas que se encuentran en los comentarios también se analizan, si se especifican en la pantalla Opciones de Spider.
- Importación: atributo ‘implementation’
- Cadena en línea: etiquetas ‘p’, ‘title’, ‘li’, ‘h1’, ‘h2’, ‘h3’, ‘h4’, ‘h5’, ‘h6’ y ‘blockquote’
- Archivo Robots.txt Si se configura en la pantalla Opciones de Spider , también analiza el archivo ‘Robots.txt’ e intenta identificar nuevos recursos utilizando las reglas especificadas. Cabe mencionar que Spider no sigue las reglas especificadas en el archivo ‘Robots.txt’.
- Archivo sitemap.xml Si se configura en la pantalla Opciones de Spider , Spider también analiza el archivo ‘sitemap.xml’ e intenta identificar nuevos recursos.
- Archivos de metadatos SVN Si se configura en la pantalla Opciones de Spider , Spider también debería analizar los archivos de metadatos SVN e intentar identificar nuevos recursos.
- Archivos de metadatos Git Si se configura en la pantalla Opciones de Spider , Spider también debería analizar los archivos de metadatos Git e intentar identificar nuevos recursos.
- Archivos .DS_Store Si se configura en la pantalla Opciones de Spider , Spider también debe analizar los archivos .DS_Store e intentar identificar nuevos recursos.
- Formato Atom de Odata Actualmente se admite el contenido de OData que utiliza el formato Atom. Se procesan todos los enlaces incluidos (relativos o absolutos).
- Archivos SVG Los archivos de imagen SVG se analizan para identificar los atributos HREF y extraer/resolver cualquier enlace contenido.
- Respuesta de texto no HTML Las respuestas de texto se analizan buscando el patrón de URL
- Respuesta no textual Actualmente, Spider no procesa este tipo de recursos.
Otros aspectos
- Al comprobar si una URL ya se ha visitado, el comportamiento con respecto a cómo se manejan los parámetros se puede configurar en la pantalla Opciones de Spider.
- Al comprobar si una URL ya se ha visitado, hay algunos parámetros comunes que se ignoran: jsessionid, phpsessid, aspsessionid, utm_*
- El comportamiento de Spider con respecto a las cookies depende de cómo se inicie Spider y de qué opciones estén habilitadas. Para obtener más detalles, consulte la pantalla Opciones de Spider
Iniciar Spider
La araña construye el árbol del sitio, mostrándole todas las páginas encontradas. Esta araña es bastante rápida y se puede utilizar para aplicaciones estándar. Sin embargo, debería considerar utilizarla en aplicaciones más modernas junto con la araña AJAX. Puede seleccionar “Spider” en el menú “Herramientas” o utilizar el atajo CTRL + ALT + S para iniciarlo.
En la siguiente ventana, ingrese la URL de la aplicación web que está rastreando y seleccione “Recurse”. Esto le indica a ZAP que rastree todas las URL o directorios desde la URL inicial. Una vez que esté listo, seleccione “Iniciar escaneo”.
Cuadro de diálogo de Spider
Este cuadro de diálogo inicia el Spider .
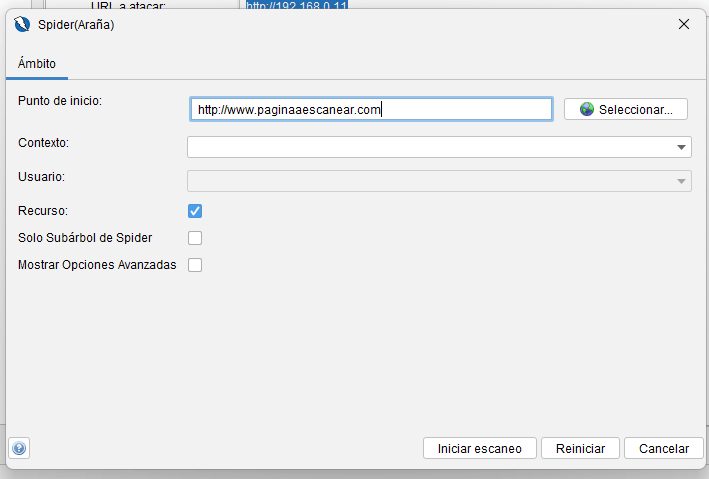
Ámbito
La primera pestaña le permite seleccionar o cambiar el punto de inicio.
- Si el punto de inicio está en uno o más contextos, podrá elegir uno de ellos.
- Si ese contexto tiene usuarios definidos, podrá seleccionar uno de ellos.
- Si selecciona uno de los usuarios, el Spider se ejecutará como ese usuario, y ZAP se (re)autenticará como ese usuario siempre que sea necesario.
- Si selecciona ‘Recurrir’, todos los nodos debajo del seleccionado también se utilizarán para inicializar el Spider.
- Si selecciona ‘Solo subárbol de Spider’, el Spider solo accederá a los recursos que se encuentren bajo el punto de inicio (URI). Al evaluar si un recurso se encuentra dentro del subárbol especificado, el Spider solo considera los componentes de esquema, host, puerto y ruta del URI
- Si selecciona ‘Mostrar opciones avanzadas’, se mostrará la siguiente pestaña, que proporciona un control detallado sobre el proceso del spider.
Al hacer clic en el botón ‘Restablecer’, se restablecerán todas las opciones a sus valores predeterminados.
Para iniciar el rastreo web «clásico» (rastrear el sitio web usando los enlaces que aparecen en las distintas páginas) en un sitio, simplemente selecciona el objetivo en el menú Sitios y luego elige Ataque > Rastrear…
De forma predeterminada, la herramienta envía los formularios, lo que puede afectar a la plataforma. Para desactivar esta opción, marque la opción «Mostrar opciones avanzadas» y, a continuación, en la pestaña Avanzado, desmarque las opciones «Procesar formularios» y «Enviar formularios POST»:
Las solicitudes enviadas por el rastreo web se muestran en la pestaña Rastreador web y el mapa del sitio también se actualiza según las páginas visitadas en el panel lateral Sitios:
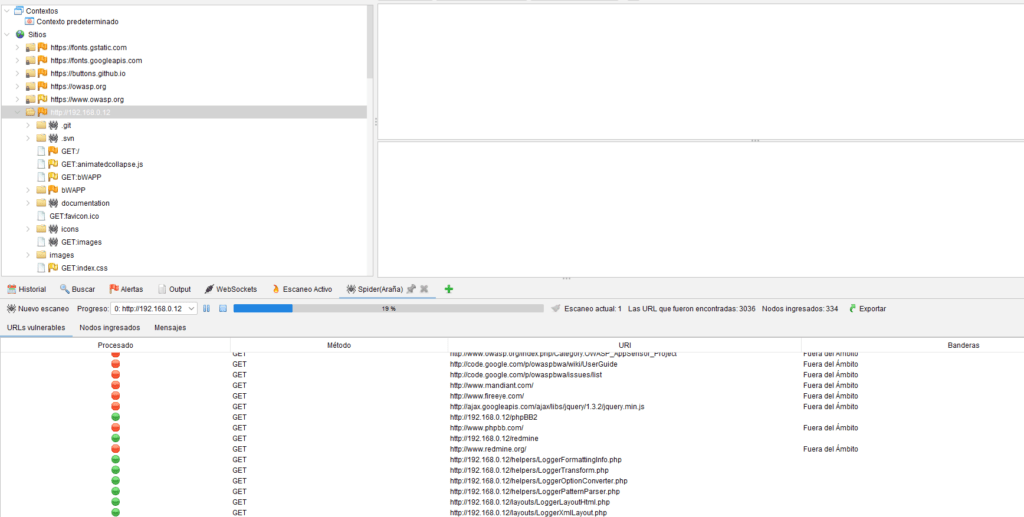
Una vez finalizado el rastreo, verás todos los nodos encontrados para la aplicación web.
Este tipo de rastreo web es particularmente rápido (unos segundos en nuestro sitio de prueba). ZAP también tiene otro tipo de rastreo web llamado «Rastreador web AJAX». Este funciona con un enfoque diferente: las URL conocidas se abren en un navegador web para que se pueda ejecutar el código JavaScript y se puedan usar solicitudes AJAX (si las hay) para cargar datos. ZAP analiza el DOM para extraer las URL que puedan estar presentes. Este tipo de rastreo web consume mucho más tiempo, ya que depende de abrir navegadores e interpretar código, pero puede ser eficaz para aplicaciones modernas que dependen de una interfaz de usuario JavaScript y solicitudes AJAX al servidor. Finalmente, el ‘Client Spider’ es una nueva función de la versión 2.16 de ZAP (enero de 2025). Eventualmente reemplazará al AJAX Spider, que se basa en tecnología externa a ZAP.
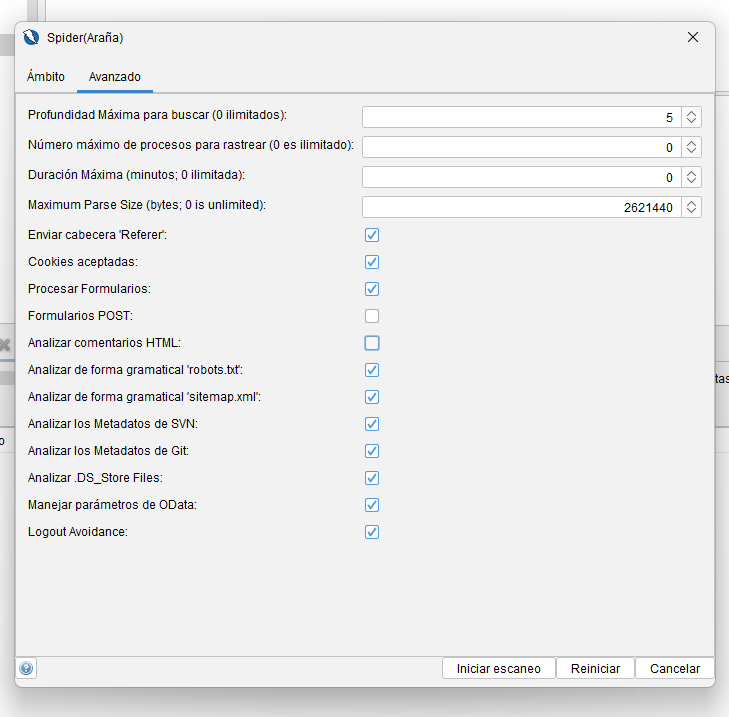
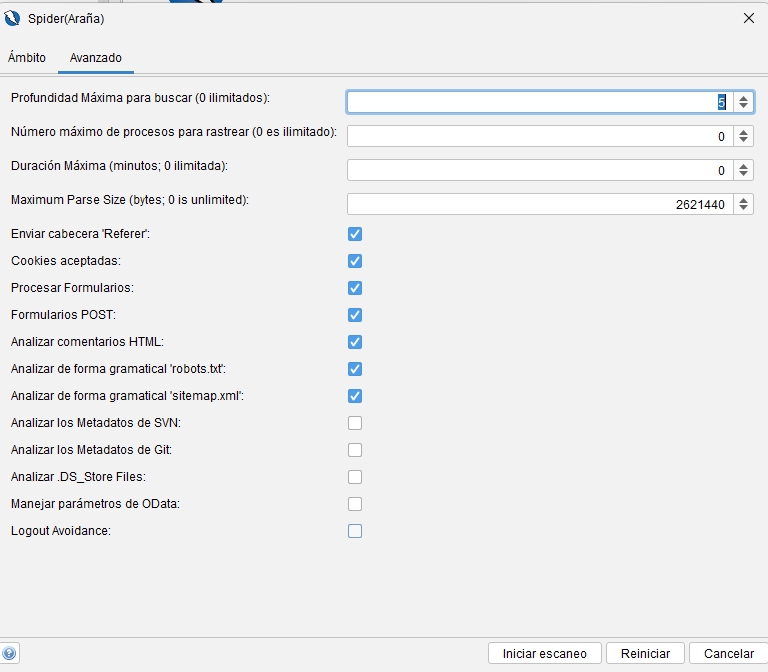
Avanzado
Los parámetros de esta pestaña corresponden a los mismos parámetros de la pantalla Opciones del Spider .
Opciones Spider
Esta pantalla le permite configurar las opciones de Spider . Cabe señalar que modificar la mayoría de estas opciones también afecta al Spider en ejecución.
Profundidad máxima para explorar
Este parámetro define la profundidad máxima en el proceso de rastreo donde debe encontrarse una página para ser procesada. Los recursos que se encuentren a mayor profundidad no serán recuperados ni analizados por el rastreador. El valor cero significa profundidad ilimitada.
La profundidad se calcula a partir de las semillas. Por lo tanto, si un escaneo de Spider comienza con una sola URL (por ejemplo, una URL especificada manualmente), la profundidad se calcula a partir de esta. Sin embargo, si el escaneo comienza con varias semillas (por ejemplo, recursión y un nodo del árbol de Sitios con hijos), un recurso se procesa si su profundidad relativa a cualquiera de las semillas es menor que la definida.
Número de hilos utilizados
El rastreador Spider utiliza múltiples hilos, y este número define la cantidad máxima de hilos de trabajo empleados en el proceso de rastreo. Modificar este parámetro no afecta a los rastreos en curso.
Duración máxima
Tiempo máximo de ejecución del rastreador, medido en minutos. Cero (valor predeterminado) significa que el rastreador se ejecutará hasta encontrar todos los enlaces posibles.
Número máximo de nodos
Este parámetro limita el número de nodos hijos que se rastrearán en cada nodo del árbol. Esto resulta útil para aplicaciones basadas en datos que tienen un gran número de «páginas» que, en realidad, contienen el mismo código pero datos diferentes, por ejemplo, de una base de datos. Por defecto, este parámetro está configurado en cero, lo que significa que no se aplican límites al número de nodos hijos rastreados.
Tamaño máximo de análisis
Define el tamaño máximo, en bytes, que una respuesta puede tener que procesar. Esto permite que el Spider omita respuestas o archivos grandes. Cero significa tamaño ilimitado.
Dominios siempre dentro del alcance
Permite gestionar los dominios, cadenas de texto o expresiones regulares que se encuentran dentro del alcance del rastreador. El comportamiento normal del rastreador es seguir únicamente los enlaces a recursos que se encuentran en el mismo dominio que la página donde se inició el escaneo. Sin embargo, esta opción permite definir dominios adicionales que se consideran «dentro del alcance» durante el proceso de rastreo. Las páginas de estos dominios se procesan durante el escaneo.
Manejo de parámetros de consulta
Durante el rastreo, el Spider cuenta con un mecanismo interno que marca las páginas ya visitadas para evitar su procesamiento repetido. Al realizar esta comprobación, se configura la forma en que se gestionan los parámetros de las URI mediante esta opción. Existen tres opciones disponibles:
- Ignorar los parámetros por completo : si se visita www.example.org/?bar=456 , entonces no se visitará www.example.org/?foo=123.
- Considere únicamente el nombre del parámetro (ignore su valor): si se visita www.example.org/?foo=123 , no se visitará www.example.org/?foo=456 , pero sí se visitará www.example.org/?bar=789 o www.example.org/?foo=456&bar=123 .
- Considere tanto el nombre como el valor del parámetro : si se visita www.example.org/?123 , se visitará cualquier otra URI diferente (incluidas, por ejemplo, www.example.org/?foo=456 o www.example.org/?bar=abc ).
Enviar encabezado “Referer”
Si las solicitudes Spider deben enviarse con el encabezado “Referer”.
Aceptar cookies
Si el rastreador web debe aceptar cookies durante el rastreo, esta opción estará habilitada. El rastreador gestionará correctamente las cookies recibidas del servidor y las enviará de vuelta según corresponda. Si la opción está deshabilitada, el rastreador no enviará ninguna cookie en sus solicitudes. Por ejemplo, esto podría controlar si el rastreador utiliza la misma sesión durante todo el rastreo. Al aceptar cookies, estas no se comparten entre rastreos; cada rastreo tiene su propio contenedor de cookies.
Esta opción tiene baja prioridad; el rastreador respetará otras opciones (globales) relacionadas con el estado HTTP. Esta opción se ignora si, por ejemplo, está seleccionada la opción «Usar estado HTTP global», al rastrear como usuario o cuando hay una sesión HTTP activa.
Formularios de proceso
Durante el proceso de rastreo, el comportamiento del Spider al encontrar formularios HTML se define mediante esta opción. Si está desactivada, los formularios HTML no se procesarán. Si está activada, los formularios HTML con el método HTTP GET se enviarán con valores generados. El comportamiento al encontrar formularios con el método HTTP POST se configura mediante la siguiente opción.
Formularios POST
Como se describió brevemente en el párrafo anterior (Procesar Formularios), esta opción configura el comportamiento del Spider cuando se habilita Procesar Formularios y cuando se encuentran formularios HTML que deben enviarse mediante POST.
Analizar comentarios HTML
Esta opción define si el rastreador debe considerar también los comentarios HTML al buscar enlaces a recursos. Solo se procesarán los recursos que se encuentren en etiquetas HTML válidas comentadas.
Analizar archivos ‘robots.txt’
Esta opción define si el rastreador debe indexar también los archivos robots.txt de los sitios web en busca de enlaces a recursos. Esta opción no define si el rastreador debe seguir las reglas impuestas por el archivo robots.txt.
Analizar archivos ‘sitemap.xml’
Esta opción controla si el Spider también debe considerar el archivo ‘sitemap.xml’ e intentar identificar nuevos recursos.
Analizar archivos de metadatos SVN
Esta opción controla si Spider también debe analizar los archivos de metadatos de SVN e intentar identificar nuevos recursos.
Analizar archivos de metadatos de Git
Esta opción controla si Spider también debe analizar los archivos de metadatos de Git e intentar identificar nuevos recursos.
Analizar archivos .DS_Store
Esta opción controla si Spider también debe analizar los archivos .DS_Store e intentar identificar nuevos recursos.
Gestionar parámetros específicos de OData
Esta opción define si Spider debe intentar detectar parámetros específicos de OData (es decir, identificadores de recursos) para procesarlos correctamente de acuerdo con la regla definida por la opción “Manejo de parámetros de consulta”.
Evitar el cierre de sesión
Indica si Spider debe intentar evitar las rutas/funcionalidades relacionadas con el cierre de sesión; valor predeterminado: falso.
Parámetros irrelevantes
Permite gestionar los parámetros que deben eliminarse al canonicalizar las URL encontradas o los cuerpos de solicitud generados ( x-www-form-urlencoded).
Los parámetros con nombres que coincidan con los siguientes se considerarán automáticamente irrelevantes:
- Nombres de sesión definidos en las opciones de Sesiones HTTP.
- Nombres de tokens definidos en las opciones de Tokens Anti-CSRF.
Las opciones del Spider pueden variar dependiendo de los plugins instalados
Pestaña Spider
La pestaña Spider muestra el conjunto de URI únicos encontrados por Spider durante los análisis. El botón ‘Nuevo análisis’ inicia el cuadro de diálogo Spider , que le permite especificar exactamente qué se debe analizar. Spider se puede ejecutar en varios sitios en paralelo y los resultados de cada análisis se muestran seleccionando el análisis a través del menú desplegable ‘Progreso’. La barra de herramientas muestra información sobre un análisis y permite controlarlo. Proporciona un conjunto de botones que permiten:

Pausar (y

reanudar) el análisis de Spider seleccionado;

Detener el análisis de Spider seleccionado;

Limpiar análisis completados;

Abrir la pantalla Opciones de Spider .
La barra de progreso muestra cuánto ha progresado el análisis de Spider seleccionado. También se muestra el número de análisis de Spider activos y el número de URI encontrados para el análisis seleccionado.
Para cada URI encontrado, puede ver:
- Procesado: si el URI fue procesado por el Spider o se omitió de la obtención debido a una regla. Las razones de omisión incluyen:

Fuera de contexto: el mensaje no formaba parte del contexto objetivo

Fuera de ámbito: el mensaje no estaba dentro del ámbito

Protocolo ilegal: el mensaje no era ni HTTP ni HTTPS

Reglas de usuario: el mensaje se omitió debido a una exclusión definida por el usuario

Evitar cierre de sesión: el mensaje se omitió porque el usuario indicó que se debían evitar las rutas/funcionalidades relacionadas con el cierre de sesión
- Método: el método HTTP, por ejemplo, GET o POST, a través del cual se debe acceder al recurso
- URI: el recurso encontrado
- Indicadores: cualquier información sobre el URI (por ejemplo, si es una semilla o por qué no se procesó)
Para cada mensaje del Spider, que se muestra en la pestaña Mensajes, puede ver los detalles de la solicitud enviada y la respuesta recibida. La Processedcolumna indica si:

Correctamente: la respuesta se recibió y analizó correctamente

Mensaje vacío: la respuesta no se analizó porque estaba vacía

Error de E/S: se produjo un error de entrada/salida al obtener la respuesta

Máximo de hijos: la respuesta no se analizó porque el nodo principal correspondiente de Sitios ya tiene más nodos secundarios que el máximo permitido
Profundidad máxima: la respuesta no se analizó porque superó la profundidad máxima permitida

Tamaño máximo: la respuesta no se analizó porque su tamaño no es inferior al máximo permitido
Sin texto: la respuesta no se analizó porque no es texto, por ejemplo, una imagen

Spider detenido: la respuesta no se obtuvo ni se analizó porque el Spider ya se había detenido
En la esquina inferior derecha se indica «Nodos añadidos: 69», lo que nos indica la cantidad de elementos nuevos que el rastreador ha encontrado y añadido al árbol de sitios durante el rastreo.
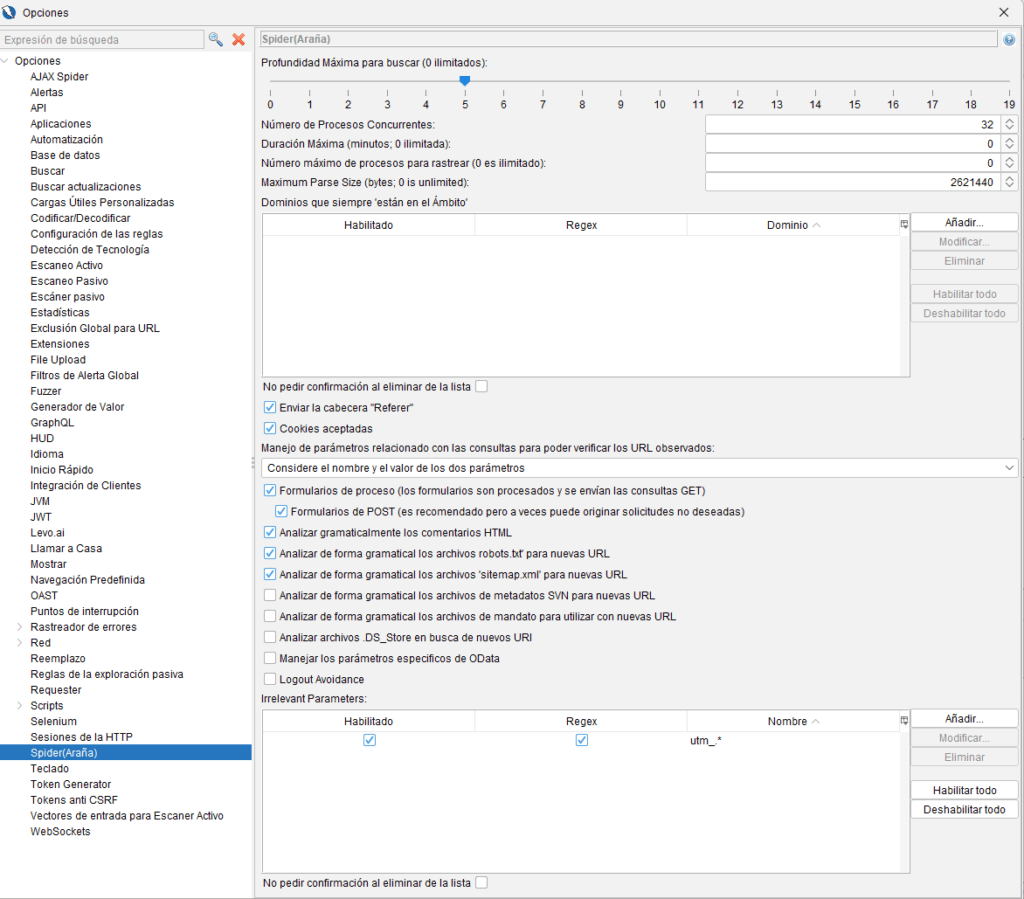
Configuración Táctica del Spider Clásico: Opciones con Mayor Impacto
La configuración por defecto es un buen punto de partida, pero ajustar estos parámetros te dará control total sobre la velocidad, el alcance y la seguridad del escaneo.

ZAP AJAX Spider
Las aplicaciones más modernas utilizan JavaScript, y la araña ZAP tradicional no entiende realmente cómo rastrearlas correctamente. Aquí es donde entra en juego la araña AJAX. Esta araña inicia un navegador, hace clic en elementos e incluso completa formularios, lo que le brinda una descripción general más completa de la aplicación web. Intenta imitar el comportamiento de un usuario mientras interactúa con la aplicación.
El complemento AJAX Spider integra en ZAP un rastreador de sitios web ricos en AJAX llamado Crawljax. Puedes usarlo para identificar las páginas del sitio objetivo. Puedes combinarlo con el rastreador (normal) para obtener mejores resultados.
La araña se configura mediante la pantalla Opciones de AJAX Spider .
Este complemento es compatible con Automation Framework .
El Problema: Las aplicaciones modernas (SPAs, React, Angular, Vue) construyen su interfaz en el navegador. El Spider Clásico no ve los enlaces porque no ejecuta el código JavaScript que los crea.
La Solución: Simular un Usuario Real
AJAX Spider (Basado en Crawljax)
• Inicia instancias de navegadores reales (Firefox, Chrome).
• Navega por el DOM, hace clic en elementos interactivos y espera a que se realicen llamadas AJAX.
• Es mucho más lento pero efectivo en apps ricas en JS.
Client Spider (El Futuro de ZAP)
• También inicia un navegador, pero se integra con la extensión ZAP para navegador.
• Esta extensión le da acceso directo al DOM y a los eventos del cliente, permitiéndole descubrir URLs con fragmentos C#’), eventos de almacenamiento y otros elementos que incluso el AJAX Spider podría pasar por alto.
Recomendación: Client Spider es la herramienta preferida y eventualmente reemplazará al AJAX Spider.
Contexto de araña AJAX
Esta pantalla le permite administrar datos de contexto para AJAX Spider.
Elementos excluidos
Permite configurar los elementos que deben excluirse del rastreo. Un elemento excluido necesita la Descripción, el Elemento (es decir, el nombre de la etiqueta) y uno de los siguientes: XPath, Texto (del elemento, coincidencia exacta y sensible a mayúsculas y minúsculas) y Atributo (tanto su nombre como su valor).
Esta araña es mucho más lenta que la estándar, pero funciona mucho mejor con las aplicaciones modernas actuales. Para abrir la araña AJAX, utilice el menú “Herramientas” o el atajo CTRL + ALT + X. Aquí, deberás configurar la URL de la aplicación que deseas probar y el navegador que utilizará la araña. Las opciones incluyen Firefox, Chrome y Safari. También puedes configurar opciones avanzadas. Cuando estés listo, selecciona “Iniciar análisis”.
Este diálogo inicia el AJAX Spider.
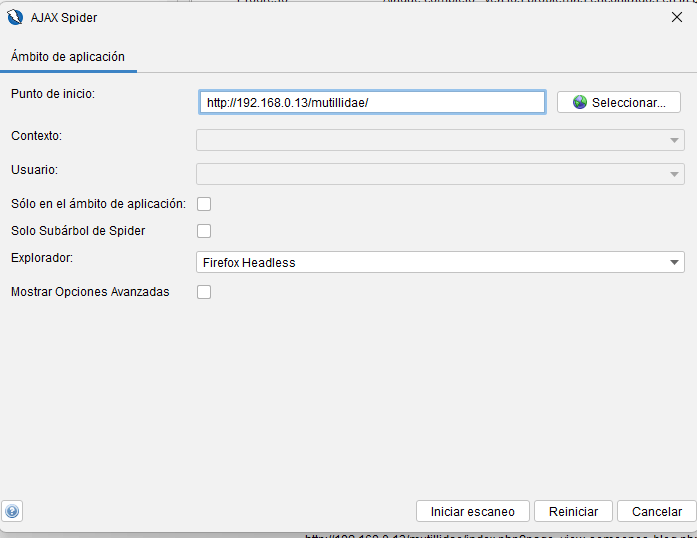
Alcance
La primera pestaña le permite cambiar características clave como:
- Punto de partida La URL desde la cual la araña AJAX comenzará a rastrear, o un contexto (en cuyo caso se utilizará una de las URL que estén en contexto como punto de partida).
- Contexto Permite seleccionar el contexto que será rastreado.
- Usuario Permite seleccionar uno de los usuarios disponibles del contexto seleccionado, para realizar el escaneo de araña como usuario (ZAP se (volverá a)autenticar como ese usuario cuando sea necesario).
- Justo al alcance Si se configura, se ignorarán todas las URL que estén fuera del alcance. La opción Just In Scopees mutuamente excluyente con Contextla opción , si se usa una se ignora la otra.
- Subárbol araña únicamente Si se configura, la araña solo accederá a los recursos que se encuentren bajo el punto de inicio (URI). Al evaluar si un recurso se encuentra dentro del subárbol especificado, la araña solo considera los componentes de esquema, host, puerto y ruta del URI.
- Navegador El tipo de navegador a usar. Los navegadores solo se mostrarán si ZAP tiene la configuración suficiente para ejecutarlos. Aun así, podrían fallar si no se encuentran o si la información de configuración es incorrecta.
- Mostrar opciones avanzadas Si se selecciona, se mostrará la pestaña Opciones.
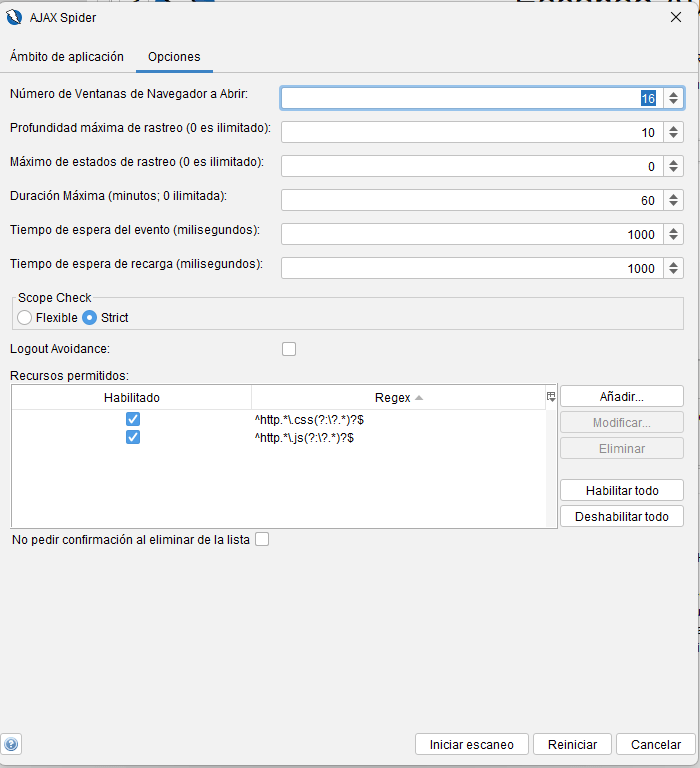
Opciones
Esta pestaña le permite cambiar opciones que incluyen:
- Número de ventanas del navegador a abrir Puedes configurar el número de ventanas que usará AJAX Spider. Cuantas más ventanas, más rápido será el proceso.
- Profundidad máxima de arrastre La profundidad máxima que puede alcanzar el rastreador. Cero significa profundidad ilimitada.
- Máximo de estados de rastreo El número máximo de estados que el rastreador puede rastrear. Cero significa que no hay límite de estados de rastreo.
- Duración máxima El tiempo máximo que el rastreador puede ejecutarse. Cero significa tiempo de ejecución ilimitado.
- Tiempo de espera del evento El tiempo de espera después de que se activa un evento del lado del cliente.
- Tiempo de espera de recarga El tiempo de espera después de que se carga la URL.
- Comprobación del alcance Cómo se comprueba el alcance, para obtener más información consulte la pantalla Opciones de AJAX Spider.
- Recursos permitidos Lista de recursos permitidos. Estos recursos siempre se obtienen, incluso fuera del alcance, lo que permite incluir recursos necesarios (p. ej., scripts) de terceros.
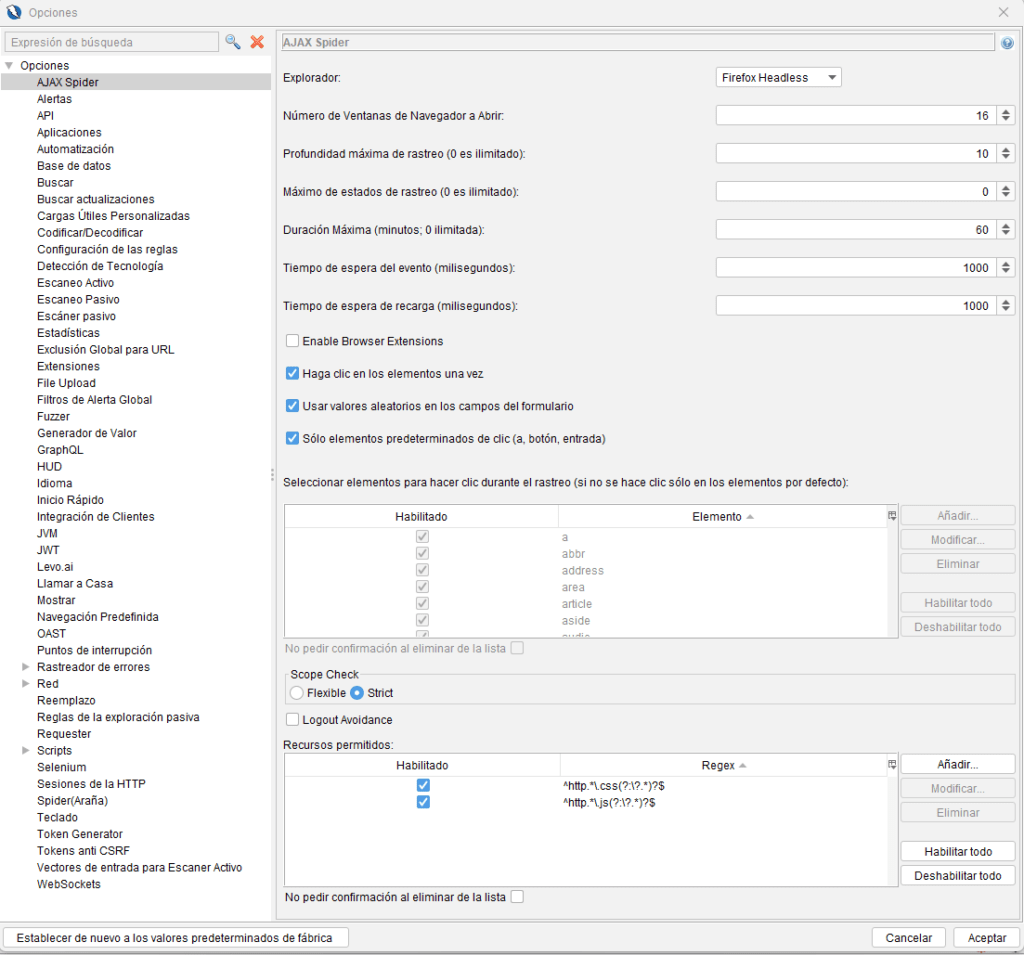
Opciones de pantalla AJAX Spider
Esta pantalla le permite configurar las opciones de AJAX Spider . AJAX Spider es un complemento para un rastreador llamado Crawljax. Este complemento configura un proxy local en ZAP para comunicarse con Crawljax. AJAX Spider le permite rastrear aplicaciones web escritas en AJAX con mucha más profundidad que el Spider nativo. Úselo si tiene aplicaciones web escritas en AJAX. También debería usar el Spider nativo para una cobertura completa de una aplicación web (por ejemplo, para cubrir comentarios HTML).
Opciones de configuración
| Campo | Detalles | Por defecto |
| Navegador | AJAX Spider utiliza un navegador externo para rastrear el sitio web de destino. Puedes especificar cuál usar. Para más información sobre los navegadores compatibles, consulta las páginas de ayuda del complemento «Selenium». | Firefox sin cabeza |
| Número de ventanas del navegador a abrir | Puedes configurar el número de ventanas que usará AJAX Spider. Cuantas más ventanas, más rápido será el proceso. | Número de núcleos |
| Profundidad máxima de arrastre | La profundidad máxima que puede alcanzar el rastreador. Cero significa profundidad ilimitada. | 10 |
| Máximo de estados de rastreo | El número máximo de estados que el rastreador puede rastrear. Cero significa que no hay límite de estados de rastreo. | 0 (ilimitado) |
| Duración máxima | El tiempo máximo que el rastreador puede ejecutarse. Cero significa tiempo de ejecución ilimitado. | 60 minutos |
| Tiempo de espera del evento | El tiempo de espera después de que se activa un evento del lado del cliente. | 1000 ms |
| Tiempo de espera de recarga | El tiempo de espera después de que se carga la URL. | 1000 ms |
| Habilitar extensiones del navegador | Cuando esté habilitado, cualquier extensión de navegador agregada por otros complementos se habilitará en los navegadores utilizados para el rastreo. | FALSO |
| Haga clic en los elementos una vez | Cuando está habilitada, el rastreador intenta interactuar con cada elemento (por ejemplo, haciendo clic) solo una vez. Si no está habilitada, intentará hacer clic varias veces. Deshabilitar esta opción es más riguroso, pero puede tardar bastante más. | Verdadero |
| Utilice valores aleatorios en los campos de formulario | Cuando está habilitado, inserta valores aleatorios en los campos del formulario. De lo contrario, utiliza valores vacíos. | Verdadero |
| Haga clic en Solo elementos predeterminados | Al habilitar esta opción, solo se hará clic en los elementos «a», «botón» y «entrada» durante el rastreo. De lo contrario, se utiliza la tabla a continuación para determinar en qué elementos se hará clic. Para un análisis más detallado, deshabilítela y configure los elementos clicables en la tabla. | Verdadero |
| Seleccionar elementos en los que hacer clic durante el rastreo (tabla) | Lista de elementos a rastrear. Esta tabla solo se aplica cuando la opción «Hacer clic solo en elementos predeterminados» no está habilitada. Use «Habilitar todos» para un análisis más detallado, aunque puede tardar un poco más. | Todos habilitados |
| Comprobación del alcance | Cómo se verifica el alcance: * Strict- Exige que todas las solicitudes estén dentro del alcance para poder acceder a ellas, excepto los Recursos Permitidos. * Flexible- Permite el acceso a todas las solicitudes. Esta verificación de alcance no utiliza ni requiere la configuración de los Recursos Permitidos para destinos que necesitan dominios fuera del alcance para funcionar. Esta verificación de alcance permite el acceso a dominios fuera del alcance, pero no su rastreo. | Estricto |
| Evitar el cierre de sesión | Cuando está habilitada, la araña evitará hacer clic en elementos de cierre de sesión comunes, lo que no requiere excluirlos manualmente. | FALSO |
| Recursos permitidos (tabla) | Lista de recursos permitidos. Estos recursos siempre se obtienen, incluso fuera del alcance, lo que permite incluir recursos necesarios (p. ej., scripts) de terceros. |
Pestaña AJAX Spider
La pestaña AJAX Spider le muestra el conjunto de URI únicos encontrados por AJAX Spider . Para cada solicitud podrás ver:
- Índice de solicitudes: cada solicitud está numerada, comenzando por 1.
- La marca de tiempo de la solicitud
- El método HTML, por ejemplo GET o POST
- La URL solicitada
- El código de estado de respuesta HTTP
- Un breve resumen de lo que significa el código de respuesta HTTP
- El tiempo que tardó toda la solicitud
- El tamaño del encabezado de respuesta
- El tamaño del cuerpo de la respuesta
- ¿Alguna alerta sobre la solicitud?
- ¿Alguna nota que hayas añadido para solicitar?
- ¿Alguna etiqueta que hayas añadido para solicitar?
Al seleccionar una solicitud, esta se mostrará en la pestaña Solicitud y en la pestaña Respuesta arriba.
Menú de clic derecho
Al hacer clic derecho en un nodo aparecerá un menú que le permitirá:
- Ataque El menú Ataque tiene los siguientes submenús:
- Sitio de escaneo activo Esto iniciará un análisis activo de todo el sitio que contiene el nodo seleccionado. Se mostrará la pestaña «Análisis activo» con el progreso del análisis.
- Nodo de escaneo activo Esto iniciará un escaneo activo solo del nodo seleccionado. Se mostrará la pestaña «Escaneo activo» con el progreso del escaneo.
- Sitio de arañas Esto iniciará un análisis de todo el sitio que contiene el nodo seleccionado. Se mostrará la pestaña «Arrastre» con el progreso del análisis.
- Navegación forzada del sitio Esto iniciará una exploración forzada de todo el sitio que contiene el nodo seleccionado. Se mostrará la pestaña «Exploración forzada» con el progreso del análisis.
- Directorio de navegación forzada Esto iniciará una exploración forzada en el directorio seleccionado. Se mostrará la pestaña «Exploración forzada» con el progreso del análisis.
- Directorio de exploración forzada (y sus hijos) Esto iniciará una exploración forzada en el directorio seleccionado y todos los elementos secundarios encontrados. Se mostrará la pestaña «Exploración forzada» con el progreso del análisis.
- Excluir de Este menú tiene los siguientes submenús:
- Apoderado Esto excluirá los nodos seleccionados del proxy. Seguirán siendo proxyizados mediante ZAP, pero no se mostrarán en ninguna de las pestañas. Esto permite ignorar las URL que no son relevantes para el sistema que se está probando. Los nodos se pueden volver a incluir mediante el cuadro de diálogo Propiedades de la sesión .
- Escáner Esto evitará que los nodos seleccionados se escaneen activamente. Los nodos se pueden volver a incluir mediante el cuadro de diálogo Propiedades de la sesión .
- Araña Esto evitará que los nodos seleccionados sean rastreados. Los nodos pueden volver a incluirse mediante el cuadro de diálogo Propiedades de la sesión .
- Ejecutar aplicación Este menú le permite invocar aplicaciones que haya configurado a través de la pantalla Opciones de aplicaciones, a la que también se puede acceder a través del submenú ‘Configurar aplicaciones…’.
- Administrar etiquetas… Esto abrirá el cuadro de diálogo Administrar etiquetas que le permitirá cambiar las etiquetas asociadas con la solicitud.
- Nota… Esto abrirá el cuadro de diálogo Agregar nota que le permitirá registrar notas relacionadas con la solicitud.
- Romper… Esto abrirá el cuadro de diálogo Agregar punto de interrupción que le permitirá establecer un punto de interrupción en esa URL.
- Alertas para este nodo Si la URL seleccionada tiene alertas asociadas, estas se mostrarán en este menú. Al seleccionar una de ellas, se mostrará.
- Reenviar… Esto abrirá el cuadro de diálogo Reenviar , que le permitirá reenviar la solicitud después de realizar los cambios que desee.
- Nueva alerta… Esto abrirá el cuadro de diálogo Agregar alerta , que le permitirá registrar manualmente una nueva alerta para esta solicitud.
- Abrir URL en el navegador Esto abrirá la URL del nodo seleccionado en su navegador predeterminado.
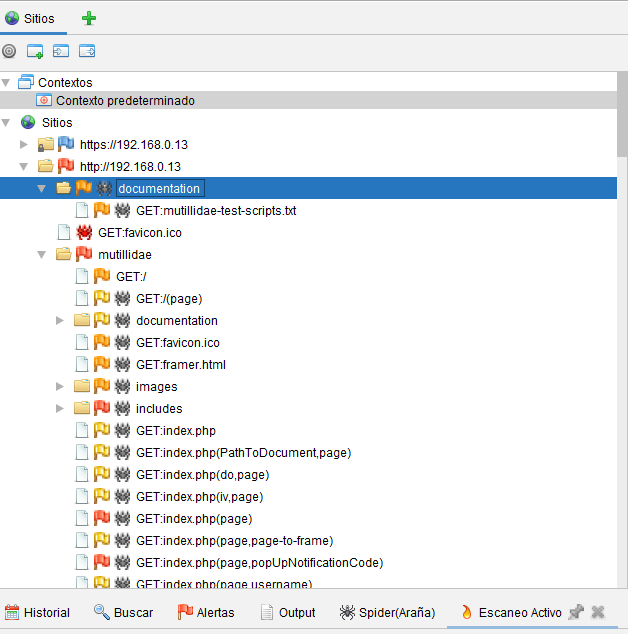
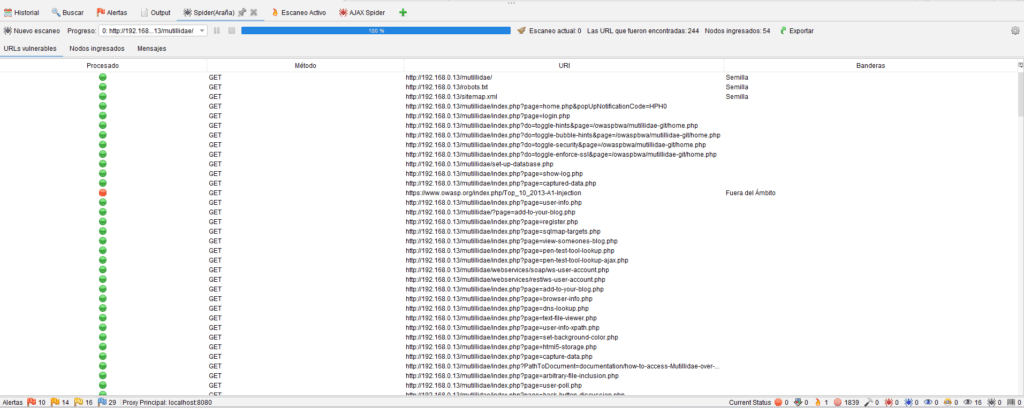
Una vez finalizado el análisis, todos los nodos encontrados se mostrarán en el área del árbol del sitio con una araña roja junto a ellos.
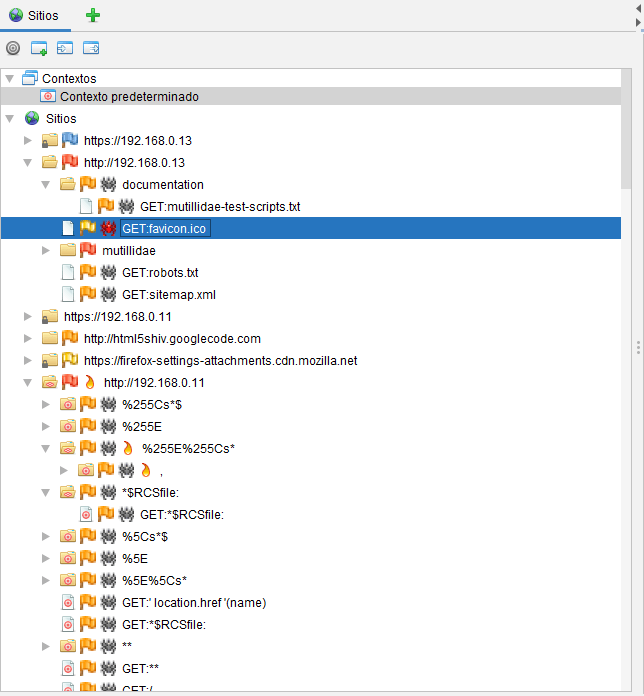
La araña AJAX rastreó 434 URL en comparación con las 54 de la araña estándar.
Integración del lado del cliente
Este complemento agrega las siguientes funciones a ZAP.
Cliente Spider
Este complemento agrega un Client Spider que está diseñado para explorar aplicaciones web modernas de manera más efectiva.
Extensiones del navegador
Este complemento agrega una extensión del navegador ZAP a Firefox y Chrome cuando se inician desde ZAP. Las extensiones transmiten eventos significativos del navegador a ZAP, lo que le da a ZAP una idea de lo que está sucediendo en el navegador. También permiten grabar scripts del lado del cliente , por ejemplo para autenticación. Si no inicia su(s) navegador(es) desde ZAP, aún puede instalar estas extensiones directamente desde las tiendas correspondientes:
- Extensión del navegador Firefox ZAP de Checkmarx
- Extensión del navegador Chrome ZAP de Checkmarx
Tenga en cuenta que es posible que deba configurar las extensiones a través de sus páginas de opciones para actualizar el host y la clave API.
Este complemento depende de una extensión del navegador ZAP que se ejecuta en Firefox y Chrome: si esta extensión no está presente, este complemento no podrá hacer nada. La extensión del navegador debe poder comunicarse con ZAP, pero debe hacerlo de forma segura para que los objetivos maliciosos no puedan abusar de los puntos finales de la API que define este complemento. Pasar los detalles de configuración a las extensiones del navegador puede ser complicado, por lo que se realiza de dos maneras diferentes según cómo se inicien los navegadores.
Lanzamiento del navegador ZAP
Si se inicia Firefox o Chrome desde ZAP con este complemento habilitado, se agregará automáticamente la extensión del navegador ZAP. El complemento también abre una URL de devolución de llamada como:
http://zap/zapCallBackUrl/12345678901234567890
- Esta URL se regenera cada vez que se inicia ZAP y se considera segura ya que no es práctico para objetivos maliciosos descubrirla.
La extensión del navegador detecta las URL de este formato en el script de contexto index.ts y luego utiliza esta URL para pasar datos del navegador a ZAP.
Inicio manual del navegador
Si inicia Firefox o Chrome de cualquier otra forma, deberá instalar usted mismo la extensión del navegador desde:
Una vez instalada, deberá configurar la extensión del navegador ZAP manualmente. En Firefox o Chrome:
- Haga clic en el botón Extensiones
- Seleccione la ‘Extensión del navegador ZAP’
- Actualizar la pantalla de Preferencias de la extensión
Necesitarás configurar:
- URL de la API ZAP: el valor predeterminado es
http://zap/
y debería funcionar en todos los casos, pero también puedes usar el host y el puerto en el que ZAP está escuchando, por ejemplo
http://localhost:8080
- Clave API de ZAP: puede encontrarla en la pantalla Opciones de API de ZAP. Puede dejar la clave API de ZAP en blanco si ha desactivado la clave API en ZAP, pero esto solo se recomienda en un entorno seguro donde confía en los sitios web a los que accederá a través de ZAP.
Interfaz de usuario
El complemento agrega 4 nuevas pestañas a ZAP:
Mapa del cliente
El Mapa del Cliente es una representación jerárquica de los sitios visitados y se asemeja en algunos aspectos al Árbol de Sitios. Incluye nodos que representan URL y otros que representan el almacenamiento basado en el navegador.
A diferencia del Árbol de Sitios, incluye fragmentos de URI que ZAP no puede ver de otro modo. Esto significa que el Mapa de Clientes tiene un aspecto muy diferente al del Árbol de Sitios para aplicaciones web modernas y puede ayudarle a comprender mejor la estructura de los sitios del lado del cliente. Los siguientes íconos se utilizan para los nodos de hoja para que pueda saber fácilmente su estado:
| Una URL que estará presente tanto en el árbol del sitio como en el mapa del cliente | |
| Una URL que solo estará presente en el Mapa del cliente, ya que la URL contiene un fragmento | |
| Una URL que se encontró en el DOM pero a la que aún no se ha accedido | |
| Una URL que redirige a otra URL | |
| Una URL que fue cargada como contenido por el navegador (por ejemplo, archivos JavaScript) en lugar de como HTML |
Al seleccionar un nodo que ha sido visitado por ZAP, se mostrarán detalles sobre ese nodo en la pestaña Detalles del cliente. Se admiten los siguientes elementos del menú contextual:
- Exportar mapa de clientes Permite a los usuarios exportar una representación del Mapa de Cliente en formato YAML, incluyendo todos los elementos secundarios y los detalles de los componentes asociados a cada nodo.
- Copiar URL Copia las URL de los nodos seleccionados en el portapapeles, separadas por nuevas líneas.
- Borrar Elimina los nodos seleccionados.
- Abrir en el navegador Abre el nodo seleccionado en el navegador seleccionado. Esta opción de menú se desactiva si se seleccionan varios nodos. Si la URL contiene un fragmento, este se enviará al navegador.
- Mostrar en el árbol de sitios Abre el nodo seleccionado en el Árbol de Sitios. El mensaje en el Árbol de Sitios no necesariamente coincide con el mensaje que creó el Nodo de Sitio. Esta opción de menú está deshabilitada si se seleccionan varios nodos o si la URL aún no se ha visitado. Si la URL contiene un fragmento, este se ignorará.
- Detalles del cliente La pestaña Detalles del cliente muestra detalles sobre los nodos del Mapa del cliente. Los tipos de datos mostrados incluyen:
- Botón: Botones detectados en el DOM
- Cookies: Cookies instaladas en el navegador
- FORMULARIO: Formularios detectados en el DOM
- Entrada: elementos de entrada detectados en el DOM
- Enlace: Enlaces detectados en el DOM
- Se admiten los siguientes elementos del menú contextual:
- Copiar HREF Copia los HREF de las entradas seleccionadas en el portapapeles, separados por nuevas líneas.
- Copiar identificaciones Copia los ID de las entradas seleccionadas en el portapapeles, separados por nuevas líneas.
- Copiar textos Copia los textos de las entradas seleccionadas en el portapapeles, separados por nuevas líneas.
- Historial del cliente La pestaña Historial del cliente muestra todos los eventos del lado del cliente enviados desde la extensión del navegador a ZAP.
- Además de los datos que se muestran en la pestaña Detalles del cliente, también incluye:
- Mutación del DOM: evento MutationObserver del navegador
- Nodo agregado: un nodo DOM agregado a la URL especificada
- Carga de página: evento de carga del navegador
- Descarga de página: evento de descarga del navegador
- Se admiten los siguientes elementos del menú contextual:
- Copiar ID de nodos Copia los ID de nodo de las entradas seleccionadas en el portapapeles, separados por nuevas líneas.
- Copiar nombres de nodos Copia los nombres de nodo de las entradas seleccionadas en el portapapeles, separados por nuevas líneas.
- Copiar URL de origen Copia las URL de origen de las entradas seleccionadas en el portapapeles, separadas por nuevas líneas.
- Copiar textos Copia los textos de las entradas seleccionadas en el portapapeles, separados por nuevas líneas.
- Tipos de copia: Copia los tipos de las entradas seleccionadas en el portapapeles, separados por nuevas líneas.
- Cliente Spider Esto se detalla en la página de ayuda de Client Spider .
Integración del lado del cliente: mejora de AJAX Spider
Este complemento proporciona una mejora de AJAX Spider que puede detectar URL referenciadas en el DOM a las que el spider no pudo acceder. Este complemento ahora incorpora un Client Spider diseñado para explorar aplicaciones web modernas de forma más eficaz. Le recomendamos probarlo, ya que probablemente sea más efectivo que la mejora de AJAX Spider que se detalla aquí.
Tenga en cuenta también que, a partir de ZAP 2.16.0, AJAX Spider cuenta con una opción para habilitar las extensiones del navegador, la cual está desactivada por defecto. Deberá activarla para que esta integración funcione.
El AJAX Spider funciona iniciando navegadores, haciendo clic en enlaces y rellenando campos. Es una forma eficaz de rastrear aplicaciones web modernas, pero no puede acceder directamente al DOM. Las extensiones de navegador incluidas en este complemento pueden acceder al DOM y transmitir eventos específicos a ZAP.
Este complemento escucha los eventos de AJAX Spider y cuando el spider termina, examina el Mapa del Cliente para ver si puede encontrar alguna URL a la que el DOM hizo referencia pero a la que ZAP no accedió. Si encuentra alguna URL «perdida» que formaba parte del análisis de AJAX Spider, realiza solicitudes directas a estas URL. Podrá ver estas solicitudes en las pestañas Historial, Árbol de sitios y Resultados.
Integración del lado del cliente – Perfil de Firefox
También crea un perfil de Firefox y lo establece como el perfil predeterminado que utilizará ZAP. Este complemento crea un perfil de Firefox llamado «zap-client-profile» y lo establece como el perfil predeterminado que usará ZAP. Este perfil habilita la extensión ZAP para Firefox en todos los sitios. Si elige utilizar otro perfil, deberá aprobar manualmente la extensión ZAP para cada sitio en el que la utilice, cada vez que inicie un navegador desde ZAP. Esta es una restricción de Firefox: para obtener más detalles, consulte Bugzilla Bug 183609 .
Contenedores personalizados
Si desea utilizar la extensión ZAP de Firefox en sus propios contenedores, es posible que descubra que no funciona de inmediato. Debería funcionar correctamente en las imágenes Docker de ZAP, ya que se les añade el perfil «zap-client-profile». Si crea sus propias imágenes de contenedor, es posible que también deba incluirlo. Para más información véase
- El directorio de Docker en Firefox
- El archivo de compilación nocturna de Docker
Escaneo pasivo
Este complemento proporciona un escáner pasivo que escanea pasivamente todos los datos recibidos del navegador.
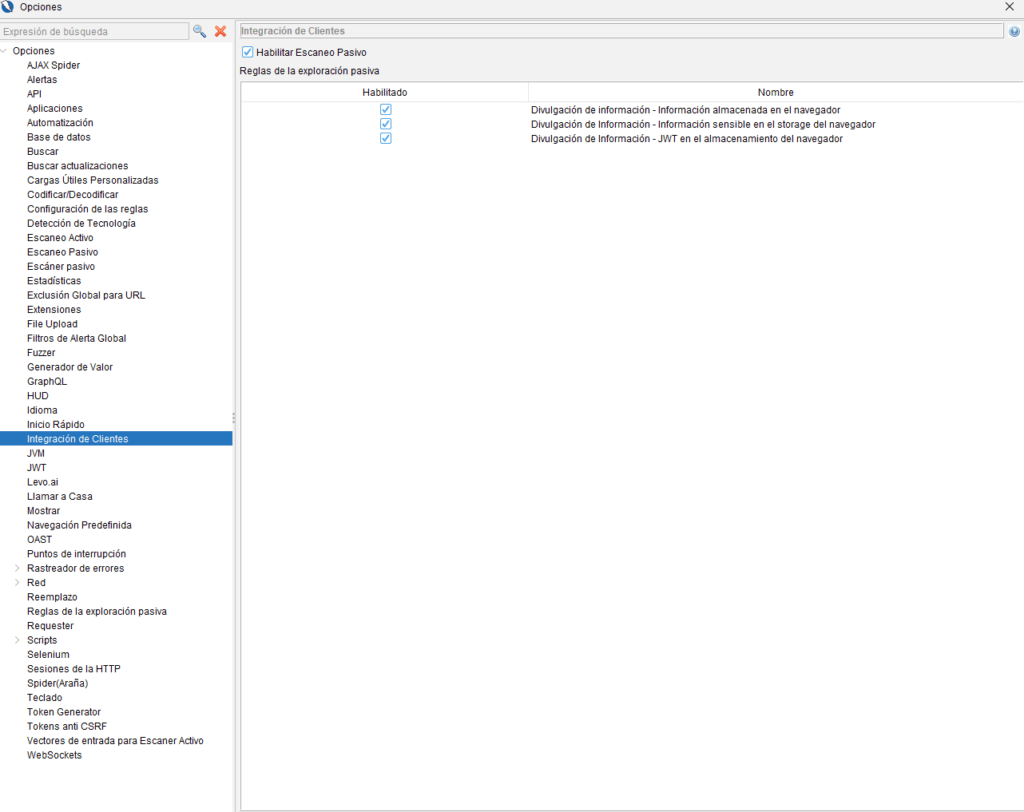
Integración del lado del cliente: reglas de escaneo pasivo
El complemento de integración del lado del cliente admite el escaneo pasivo de los datos transmitidos desde el navegador. Las siguientes reglas están incluidas en este complemento:
Divulgación de información: información almacenada en el navegador
Esta regla informa sobre cualquier información almacenada en localStorage y sessionStorage del navegador. Esto no es inusual ni necesariamente inseguro: estas alertas informativas se generan para ayudarlo a comprender mejor lo que hace esta aplicación. El parámetro de alerta será la clave de almacenamiento utilizada. Solo se generará una alerta por cada URL y clave.
Código más reciente: InformationInStorageScanRule.java
ID de alerta: 120000 .
Divulgación de información: información confidencial almacenada en el navegador
Esta regla informa sobre cualquier información confidencial almacenada en el almacenamiento local y de sesión del navegador. Esto puede violar PCI y la mayoría de las políticas de cumplimiento organizacional. La información potencialmente sensible identificada incluye:
- Números de tarjetas de crédito
- Direcciones de correo electrónico
- Números de Seguro Social de EE. UU.
El parámetro de alerta será la clave de almacenamiento utilizada. Solo se generará una alerta por cada URL y clave.
Código más reciente: SensitiveInfoInStorageScanRule.java
ID de alerta: 120001 .
Divulgación de información – JWT en el almacenamiento del navegador
Esta regla informa sobre todos los JWT almacenados en localStorage y sessionStorage del navegador. Los JWT normalmente se almacenan en sessionStorage, por lo que solo se generan como alertas informativas. Por lo general, los JWT no se deben almacenar en localStorage, por lo que se generan como alertas medianas. El parámetro de alerta será la clave de almacenamiento utilizada. Solo se generará una alerta por cada URL y clave.
Código más reciente: JwtInStorageScanRule.java
ID de alerta: 120002 .
Grabación de scripts del lado del cliente
Las extensiones del navegador ZAP te permiten registrar todas las acciones que realizas en el navegador como un script de Zest. Se pueden usar para registrar scripts de autenticación u otras interacciones complejas. Los scripts de Zest se pueden reproducir en ZAP, ya sea en el escritorio o en automatización. La extensión “completa” del navegador ZAP se agrega automáticamente a los navegadores Firefox y Chrome iniciados desde ZAP. También puedes instalar manualmente estos complementos o las extensiones reducidas de “Browser Recorder”:
- Extensión del navegador Firefox ZAP de Checkmarx
- Grabador de navegador Firefox ZAP de Checkmarx
- Extensión del navegador Chrome ZAP de Checkmarx
- Grabador de navegador Chrome ZAP de Checkmarx
- Grabador de navegador Edge ZAP de Checkmarx
La extensión Browser Recorder solo le permite grabar un script Zest y no intentará comunicarse con ZAP. Todas las extensiones del navegador ZAP incluyen ayuda detallada a través del panel emergente.
Grabación de ZAP
La forma más sencilla de grabar un script del lado del cliente desde ZAP es usar el cuadro de diálogo «Grabar script de Zest». Deberá cambiar el «Tipo de registro» a «Script del lado del cliente (navegador)» y proporcionar una URL válida.
ZAP iniciará el navegador seleccionado y grabará las instrucciones de Zest en la consola de scripts a medida que realiza acciones en él.
Asesoramiento y orientación para grabadores
Si va a utilizar el script grabado para la autenticación, deberá asegurarse de que el navegador estará en el mismo estado que cuando se inició desde ZAP. Si la URL de inicio de sesión es estática, puedes abrir esa página antes de comenzar a grabar. Si la URL es dinámica, debe introducir una URL estática adecuada en el cuadro de diálogo de grabación. Esta URL se grabará en el script y el navegador gestionará las redirecciones dinámicas según sea necesario.
En todos los casos, debe comenzar a grabar antes de descartar cualquier cuadro de diálogo, como advertencias sobre cookies y otras exenciones de responsabilidad, ya que ZAP deberá hacer lo mismo. A menudo es mejor utilizar el modo privado/incógnito al grabar para que el navegador no tenga ningún estado de aplicación existente. Los botones de algunas aplicaciones web modernas pueden ser componentes HTML complejos que a veces dificultan el acceso mediante la automatización. Si sus formularios se pueden enviar con la tecla RETORNO, suele ser una mejor opción al grabar.
Integración del lado del cliente – API de Client Spider
Este complemento agrega varios puntos finales de API para permitirle controlar Client Spider mediante programación. Se puede acceder a la API a través clientSpiderdel prefijo API.
Vistas
- status (scanId*)Obtiene el estado del análisis de araña. Devuelve un entero entre 0 y 100 que indica el progreso actual.
Comportamiento
- scan (browser url contextName userName subtreeOnly maxCrawlDepth pageLoadTime)Ejecuta el Client Spider con la URL o el contexto especificados. Devuelve el scanId.
- stop (scanId*):Detiene un escaneo del Client Spider.
Parámetros
- browserEl navegador que se usará para el análisis, p. ej., «firefox-headless». Si no se especifica, se usa Firefox Headless.
- urlURL donde se inicia el escaneo. Si no se especifica y se establece un contexto, se usará la primera URL del contexto.
- contextName:El nombre del contexto a escanear.
- userNameNombre del usuario que ejecutará el análisis. El usuario debe existir en el contexto especificado.
- subtreeOnlySi se establece como «true», la araña solo escaneará las URL bajo la URL especificada. Valor predeterminado: «false».
- maxCrawlDepthLa profundidad máxima que la araña debe rastrear, donde 0 es ilimitado. El valor predeterminado son las opciones del cliente.
- pageLoadTimeTiempo de espera en segundos para la carga de una página. El valor predeterminado son las opciones del cliente.
- scanId:El ID del escaneo para consultar o administrar.
Ejemplos
Iniciar un escaneo:
https://zap/JSON/clientSpider/action/scan/?url=https://example.com&maxCrawlDepth=5&pageLoadTime=30
Comprobar estado:
https://zap/JSON/clientSpider/view/status/?scanId=1
Detener un escaneo:
https://zap/JSON/clientSpider/action/stop/?scanId=1
Integración del lado del cliente – Client Spider
Este complemento agrega un Client Spider que está diseñado para explorar aplicaciones web modernas de manera más efectiva. El Client Spider funciona de manera similar al AJAX Spider, pero tiene acceso al DOM a través de la extensión del navegador ZAP, lo que significa que puede encontrar contenido que el AJAX Spider no puede encontrar. El cliente Spider admite todas las opciones de autenticación admitidas por ZAP y ejecutará cualquier script de Selenium habilitado en los navegadores que inicie.
Aunque todavía está en una etapa temprana, creemos que es un enfoque más efectivo que AJAX Spider. Nos centraremos en mejorar el Client Spider y el plan actual es que reemplace al AJAX Spider como la forma recomendada de rastrear aplicaciones web modernas. La araña se puede invocar mediante:
- Menú «Ataque» específico del contexto
- Elemento de menú “Herramientas / Cliente Spider”
- Trabajo spiderClient de Automation Framework
- Diálogo de Client Spider El cuadro de diálogo para iniciar Client Spider ofrece dos subpestañas:
- Alcance Esta pestaña le permite definir lo que la araña intentará explorar. La verificación del alcance puede ser:
- Strict- exige que todas las solicitudes deben estar dentro del alcance para poder acceder a ellas.
- FlexiblePermite acceder a todas las solicitudes. Esta comprobación de alcance permite acceder a dominios fuera de alcance, pero no rastrearlos.
- Opciones Esta pestaña le permite definir las opciones que controlan cómo funciona la araña.
- Pestaña Spider del cliente La pestaña Client Spider permite iniciar y supervisar Client Spider. Cuenta con tres subpestañas:
- Nodos añadidos Estos son los nodos que se han agregado al Mapa del Cliente.
- Tareas Estas son las tareas que utiliza la araña para rastrear la aplicación. Se actualizan al añadirse a la lista, al iniciarse y al completarse. Esto permite comprender con mayor claridad qué está haciendo realmente la araña del cliente.
- Mensajes Estos son los mensajes HTTP(S) enviados desde los navegadores que utiliza el cliente.
Navegación forzada
ZAP le permite intentar descubrir directorios y archivos mediante la navegación forzada. Se proporciona un conjunto de archivos que contienen una gran cantidad de nombres de archivos y directorios. ZAP intenta acceder directamente a todos los archivos y directorios enumerados en el archivo seleccionado en lugar de depender de encontrar enlaces a ellos. La navegación forzada se configura mediante la pantalla Opciones de navegación forzada . Esta funcionalidad se basa en el código del proyecto OWASP DirBuster, ahora retirado.
Opciones de pantalla de navegación forzada
Esta pantalla le permite configurar las opciones de Navegación forzada :
- Subprocesos de escaneo simultáneos por host El número de subprocesos que el escáner usará por host. Aumentar el número de subprocesos acelerará el análisis, pero podría sobrecargar el equipo donde se ejecuta ZAP y el host de destino.
- Recursivo Si está marcada, el escáner recorrerá recursivamente todos los subdirectorios encontrados. Esto puede tardar bastante tiempo.
- Archivo predeterminado El archivo predeterminado seleccionado cuando se inicia ZAP.
- Agregar archivo de exploración forzada personalizado Permite agregar archivos propios para usar al ejecutar ataques de fuerza bruta contra archivos y directorios. Estos deben ser archivos de texto con un nombre de archivo o directorio por línea. Los archivos se agregan al directorio «dirbuster» debajo del directorio principal de ZAP.
- Forzar la exploración de archivos sin extensión Si se selecciona, además de los directorios, también se ejecutará la fuerza bruta sobre los archivos sin extensión. La URI del archivo que se ejecutará la fuerza bruta se obtiene añadiendo a la ruta base las entradas del archivo de texto de exploración forzada seleccionado. Por defecto, esta opción está desmarcada. Activarla aumentará el tiempo de escaneo.
- Exploración forzada de archivos Si se marca esta opción, además de los directorios, también se ejecutará la fuerza bruta sobre los archivos. La URI del archivo que se ejecutará la fuerza bruta se obtiene añadiendo las extensiones dadas a las entradas del archivo de texto de exploración forzada seleccionado. Los usuarios no tienen que preocuparse de si la entrada ya termina con una extensión o no. El conflicto se gestiona internamente. Por defecto, esta opción está desmarcada. Activarla aumentará el tiempo de escaneo.
- Extensiones de archivo Si la opción «Forzar exploración de archivos» está marcada, puede especificar las extensiones de archivo que deben procesarse por fuerza bruta. Al especificar varias extensiones, sepárelas con una coma (,). Si no se especifica ningún valor, se usará «php» como extensión predeterminada.
- Extensiones de archivos que se deben ignorar El escáner analiza el cuerpo de la respuesta para filtrar los enlaces existentes. Los enlaces extraídos se utilizan para realizar nuevas solicitudes. Si se especifican las extensiones de archivo que se deben ignorar, los enlaces que terminan con esas extensiones se ignoran al realizar solicitudes. Al especificar varias extensiones, sepárelas con una coma (,). Por defecto, se establecen en «jpg, gif, jpeg, ico, tiff, png, bmp».
- Cadena de caso de error El escáner solicitará cada tipo de archivo en cada directorio que encuentre, con la cadena de error especificada adjunta. La respuesta de esta página se utiliza para determinar si existe el archivo o directorio deseado. Por defecto, está configurado como «thereIsNoWayThat-You-CanBeThere». Si obtiene resultados inusuales, considere cambiarlo.
Pestaña de exploración forzada
La pestaña Navegación forzada le permite realizar un análisis de Navegación forzada en cualquiera de los sitios a los que haya accedido. Los sitios se pueden seleccionar mediante la barra de herramientas o la pestaña Sitios . Los sitios que se han analizado o se están analizando aparecen marcados en negrita en el menú desplegable Sitios de la barra de herramientas. La barra de herramientas ofrece botones para iniciar, detener, pausar y reanudar el análisis. Una barra de progreso muestra el progreso del análisis del sitio seleccionado. El valor «Análisis actuales» muestra cuántos análisis están activos; al pasar el cursor sobre este valor, se mostrará una lista de los sitios que se están analizando en una ventana emergente. La barra de herramientas también incluye un botón para exportar el contenido como CSV.
Menú de clic derecho
Al hacer clic derecho en una o más filas aparecerá un menú que le permitirá:
- Excluir de Este menú tiene los siguientes submenús:
- Apoderado Esto excluirá los nodos seleccionados del proxy. Seguirán siendo proxyizados mediante ZAP, pero no se mostrarán en ninguna de las pestañas. Esto permite ignorar las URL que no son relevantes para el sistema que se está probando. Los nodos se pueden volver a incluir mediante el cuadro de diálogo Propiedades de la sesión .
- Escáner Esto evitará que las notas seleccionadas se escaneen activamente. Los nodos se pueden volver a incluir mediante el cuadro de diálogo Propiedades de la sesión .
- Araña Esto evitará que los nodos seleccionados sean rastreados. Los nodos pueden volver a incluirse mediante el cuadro de diálogo Propiedades de la sesión .
- Copiar Esto copiará las URL seleccionadas al portapapeles.
- Reenviar… Esto abrirá el cuadro de diálogo Reenviar , que le permitirá reenviar la solicitud después de realizar los cambios que desee.
- Nueva alerta… Esto abrirá el cuadro de diálogo Agregar alerta , que le permitirá registrar manualmente una nueva alerta para esta solicitud.
- Abrir URL en el navegador Esto abrirá la URL del nodo seleccionado en su navegador predeterminado.
- Generar formulario de prueba anti CSRF Esto abrirá una URL que te proporcionará un formulario generado para probar problemas de CSRF. Solo estará habilitado para solicitudes POST si la API está habilitada y si Java admite la apertura de URL en un navegador de tu plataforma.
Lista de directorios v1.0
Proporciona un archivo con nombres de directorio para usar con el complemento Forced Browse o Fuzzer. Las listas fueron compiladas por los autores de DirBuster.
Lista de directorios v2.3
Proporciona archivos con nombres de directorio para usar con el complemento Forced Browse o Fuzzer. Las listas fueron compiladas por los autores de DirBuster.
Lista de directorios v2.3 LC
Proporciona archivos con nombres de directorio en minúsculas para usar con el complemento Forced Browse o Fuzzer. Las listas fueron compiladas por los autores de DirBuster.
Fuzzing
El fuzzing es una técnica que consiste en enviar grandes cantidades de datos a un objetivo (a menudo en forma de entradas no válidas o inesperadas). ZAP le permite analizar cualquier solicitud mediante:
- Un conjunto integrado de cargas útiles
- Cargas útiles definidas por complementos opcionales
- Scripts personalizados
Para acceder al cuadro de diálogo Fuzzer puede:
- Haga clic derecho en una solicitud en una de las pestañas de ZAP (como Historial o Sitios) y seleccione “Ataque / Fuzz…”
- Resalte una cadena en la pestaña Solicitud, haga clic derecho sobre ella y seleccione “Fuzz…”
- Seleccione el elemento de menú “Herramientas / Fuzz…” y luego seleccione la solicitud que desea fuzzear
- Generadores de carga útil Los generadores de carga útil generan los valores sin procesar o ataques que el fuzzer envía a la aplicación de destino. Se gestionan a través del cuadro de diálogo Cargas útiles .
- Procesadores de carga útil Los procesadores de carga útil se pueden utilizar para cambiar cargas útiles específicas antes de enviarlas. Se gestionan a través del cuadro de diálogo Procesadores de carga útil .
- Procesadores de ubicación de fuzz Los procesadores de ubicación Fuzz se pueden utilizar para cambiar todas las cargas útiles antes de enviarlas. Se gestionan a través del cuadro de diálogo Procesadores de ubicación .
- Procesadores de mensajes Los procesadores de mensajes pueden acceder y cambiar los mensajes que se están analizando, controlar el proceso de análisis e interactuar con la interfaz de usuario de ZAP. Se gestionan a través de la pestaña ‘Procesadores de mensajes’ del cuadro de diálogo Fuzzer .
Algunas de estas funciones se basan en el código del proyecto OWASP JBroFuzz e incluyen archivos del proyecto fuzzdb. Tenga en cuenta que se han omitido algunos archivos fuzzdb porque hacen que los escáneres antivirus comunes los marquen como que contienen virus. Puedes reemplazarlos (y actualizar fuzzdb) descargando la última versión de fuzzdb y expandiéndola en la biblioteca ‘fuzzers’.
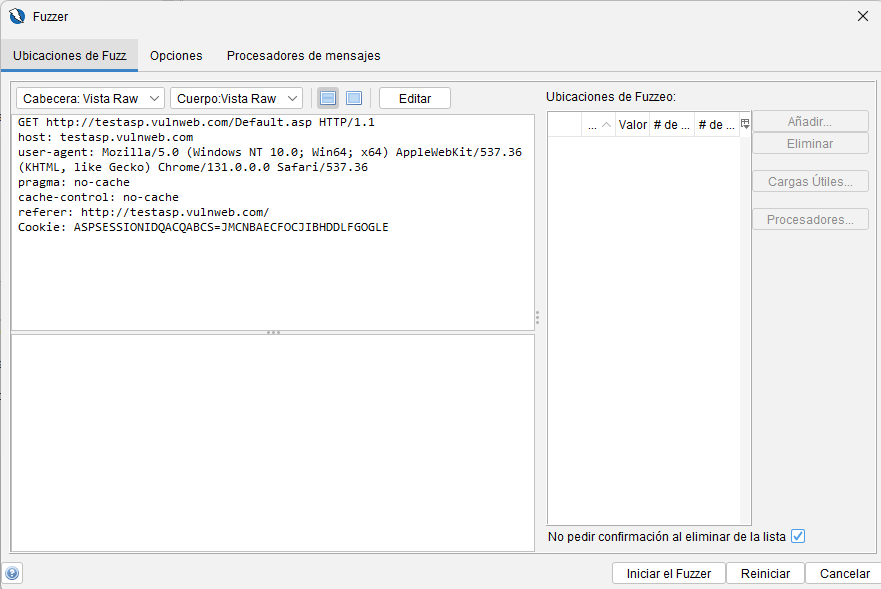
Diálogo de fuzzer
Esto le permite seleccionar los fuzzers que se utilizarán al fuzzear una solicitud.
Pestaña Ubicaciones de Fuzz
Para configurar el fuzzing:
- Resalte una cadena que desee fuzzear en la pestaña Ubicaciones de fuzz
- Haga clic en el botón ‘Agregar…’ para iniciar el cuadro de diálogo Cargas útiles
- Añade las cargas útiles que quieras utilizar
- Haga clic en el botón ‘Procesadores…’ para iniciar el cuadro de diálogo Procesadores de ubicación (si es necesario)
- Haga clic en el botón ‘Iniciar fuzzer’ para iniciar el fuzzing
- Luego, los resultados se enumerarán en la pestaña Fuzzer; selecciónelos para ver las solicitudes y respuestas completas.
También puedes buscar cadenas en los resultados del fuzz usando la pestaña «Buscar». Haga clic en el botón «Editar» para editar el mensaje seleccionado para fuzzing. Tenga en cuenta que esto eliminará todas las ubicaciones de fuzzing definidas. Necesitará ‘Guardar’ el mensaje antes de poder definir nuevas ubicaciones de fuzz.
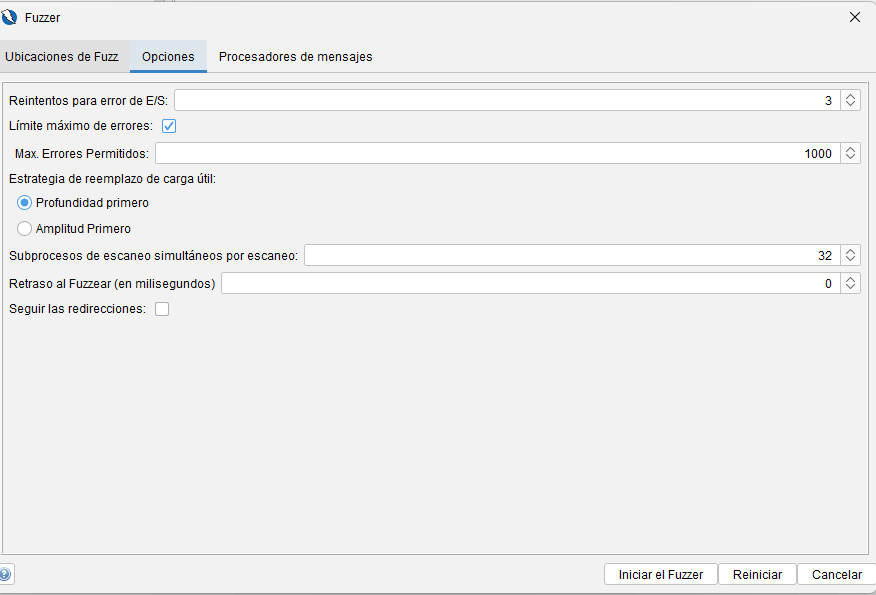
- Pestaña de opciones Esta pestaña permite configurar las opciones que se usarán al realizar fuzzing. Consulte la ayuda de las opciones principales para obtener más detalles.
- Seguir redirecciones Indica si el Fuzzer debe o no seguir las respuestas de redireccionamiento (solo visible para mensajes HTTP).
- Pestaña Procesadores de mensajes Los procesadores de mensajes pueden acceder y modificar los mensajes sometidos a fuzzing, controlar el proceso de fuzzing e interactuar con la interfaz de usuario de ZAP.
Los procesadores de mensajes disponibles dependen del tipo de mensaje sometido a fuzzing; este complemento incluye los procesadores de mensajes HTTP predeterminados . Los complementos también pueden definir generadores de carga útil adicionales.
Opciones de pantalla Fuzzer
Esta pantalla le permite configurar las opciones de fuzzing :
- Categoría predeterminada La categoría que se seleccionará inicialmente cuando se muestre el cuadro de diálogo Fuzz .
- Agregar archivo Fuzz personalizado Permite agregar archivos propios para usar durante el fuzzing. Estos deben ser archivos de texto con una carga útil por línea. Los archivos se agregan al directorio «fuzzers» dentro del directorio principal de ZAP.
- Fuzzers terminados en la interfaz de usuario Define la cantidad de fuzzers (que han completado su ejecución) visibles en la pestaña de fuzzers.
- Reintentos en caso de error de E/S El número de reintentos cuando se produce un error de entrada/salida al enviar una solicitud al destino.
- Máximo de errores permitidos Si el número de errores excede este límite, el fuzzer detendrá su ejecución.
- Estrategia de reemplazo de carga útil Reglas definidas para controlar el orden en que se iteran múltiples listas de carga útil.
- Subprocesos de escaneo simultáneos por escaneo El número de subprocesos que el fuzzer usará por escaneo. Aumentar el número de subprocesos acelerará el escaneo, pero puede sobrecargar el equipo donde se ejecuta ZAP, así como el objetivo.
- Retraso al realizar fuzzing (en milisegundos) La cantidad de milisegundos entre las solicitudes del fuzzer al host de destino, generalmente para evitar ser bloqueado por el destino o si el destino implementa algún tipo de requisito de limitación.
Pestaña Fuzzer
La pestaña Fuzzer muestra las solicitudes y respuestas realizadas al fuzzear un mensaje. Seleccione una fila para ver las solicitudes y respuestas completas. También puede buscar cadenas en los resultados del fuzzing usando la pestaña «Buscar».
Resultados de HTTP Fuzzer
Los resultados deben evaluarse manualmente para saber si se encontró alguna vulnerabilidad.
Menú de clic derecho
Al hacer clic derecho en una fila, se abrirá un menú con las mismas opciones que la pestaña Historial. Además, se ofrece la opción de agregar mensajes de los resultados de fuzzing al Árbol de Sitios y a la pestaña Historial (los mensajes se etiquetarán FromFuzzery mostrarán inicialmente un icono de fuzzing en el Árbol de Sitios).
Archivos FuzzDB
Proporciona los archivos FuzzDB que se pueden usar con el fuzzer ZAP. Algunos archivos que hacen que el software antivirus marque o elimine archivos se han separado en el complemento FuzzDB Offensive, disponible en ZAP Marketplace.
Ofensiva de FuzzDB
Puertas traseras web y archivos de ataque de FuzzDB que se pueden usar con el fuzzer ZAP o para pruebas de penetración manuales.
Este complemento contiene archivos que pueden estar marcados por herramientas antivirus.
Puertas traseras web de FuzzDB
Puertas traseras web FuzzDB que se pueden utilizar con el fuzzer ZAP. Este complemento fue reemplazado por FuzzDB Offensive .
Fuzzing – Practico
Una de las técnicas más eficientes para detectar una gran variedad de vulnerabilidades en las auditorias de seguridad web es el fuzzing. En este contexto, este tipo de técnicas se basan en alterar las entradas utilizadas por determinado sitio web proporcionando datos inválidos, inesperados o aleatorios y analizar posteriormente su respuesta para estudiar cómo afectan las mismas a la lógica implementada en el servicio.
La modificación de dichas entradas, en los casos más comunes remitidas mediante los métodos GET y POST, permitirán identificar gran diversidad de vulnerabilidades tales como: SQL Injection, Local/Remote File Inclusion, XML External Entity, Cross Site Scripting, etc. Para facilitar este proceso, ZAP integra un Fuzzer desde el que es posible elegir las entradas que deseamos testear proporcionando un gran número de payloads para diversas categorías de inyección. Esta función está disponible haciendo clic con el botón derecho sobre cualquier recurso web y seleccionando, dentro del menú “Atacar” la opción “Fuzz”.
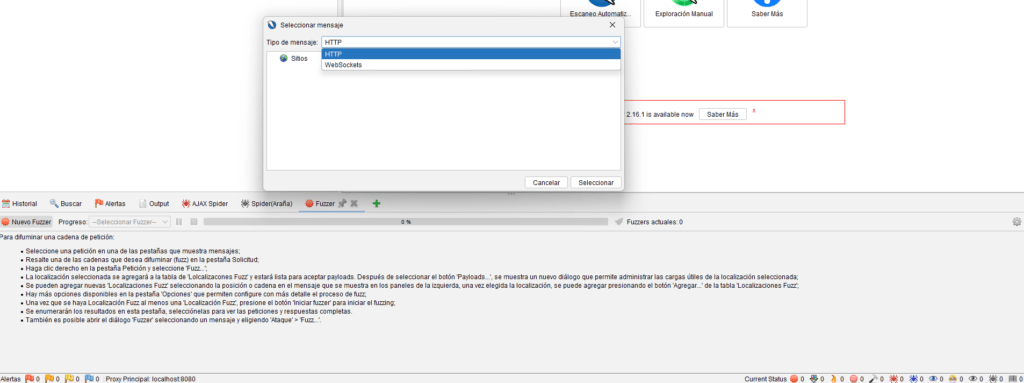
Payloads
Un payload, traducido como “carga útil”, es la parte maliciosa que puede explotar una vulnerabildad. Tras seleccionar la opción de fuzzing se nos abrirá una nueva ventana donde se mostrará la petición web y desde donde tendremos que seleccionar el parámetro o parámetros que queremos testear. Tras seleccionar los mismos, el siguiente paso será seleccionar el payload que queremos utilizar para hacer las pruebas de inyección correspondientes. En este caso, podemos optar por añadir nuestro propio listado de payloads o bien seleccionar alguna de las categorías que ZAP implementa por defecto. A modo de ejemplo, en la imagen que acompaña la diapositiva se muestra parte del grupo de pruebas disponible para la categoría “Format String Errors”.
En la imagen podemos observar un portal web en donde existe un formulario que permite la entrada de datos una vez se pulsa el botón “Add Entry”.
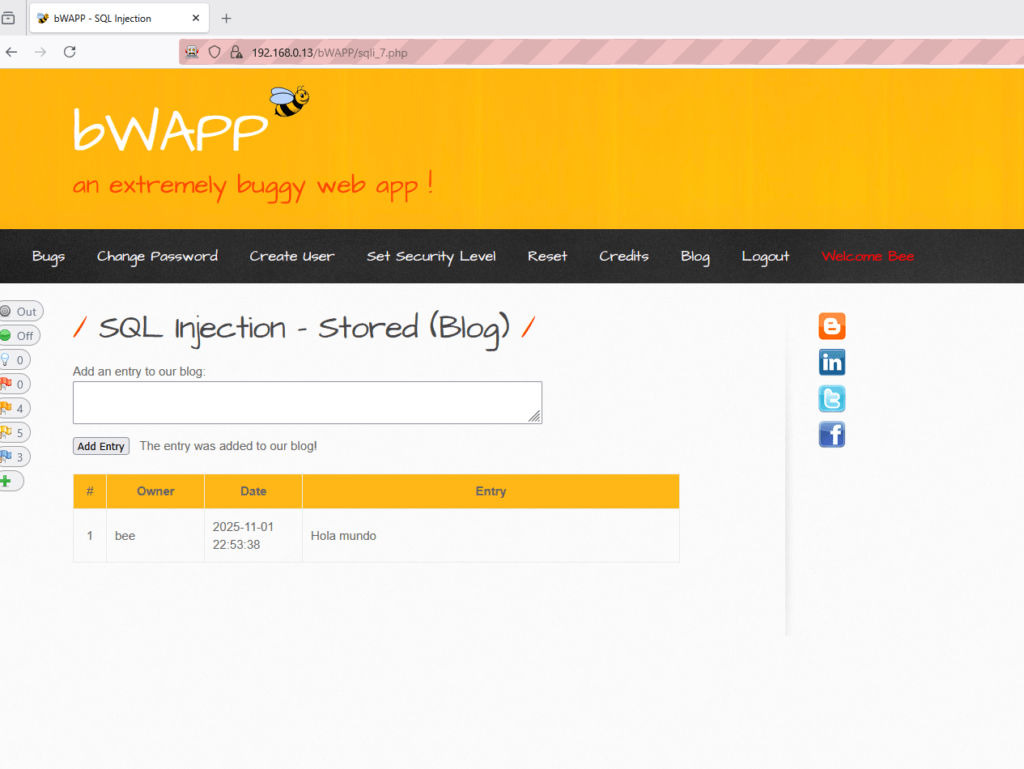
Estos datos serán actualizados en una tabla situada justamente debajo el dicho formulario. Los datos enviados, tal y como se muestra en la ventana de petición de ZAP, son remitidos utilizando el método POST.
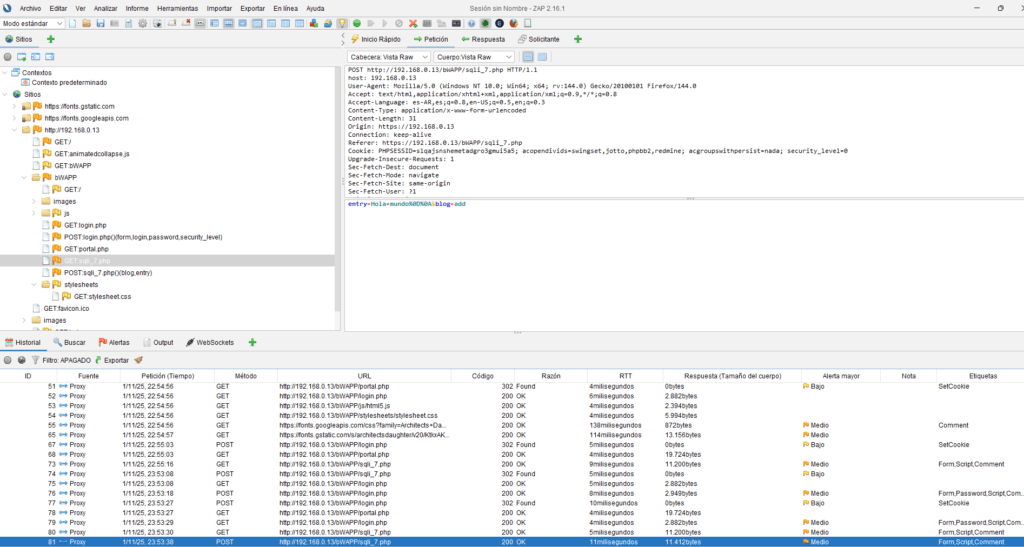
Para investigar si la entrada de datos está correctamente filtrada por el servicio web haremos uso de la funcionalidad fuzzing de ZAP para añadir un conjunto de payloads cuya carga afecte al normal funcionamiento y con los que intentaremos obtener información de la base de datos. Tras hacer clic en la funcionalidad fuzzing¸
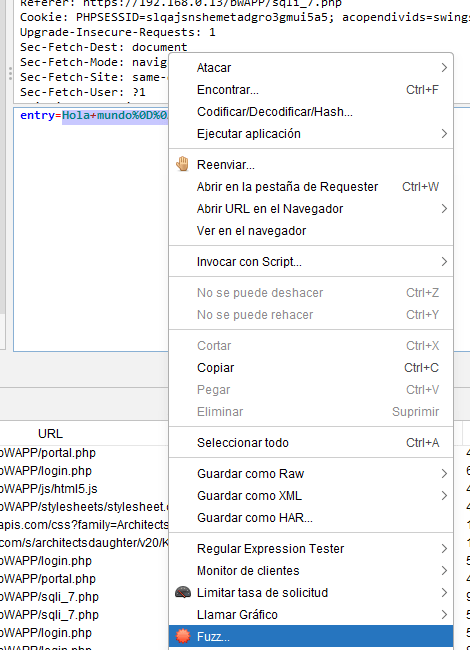
seleccionaremos la cadena remitida mediante el parámetro “entry” y posteriormente añadiremos de forma manual el conjunto de payloads que se muestra en la imagen adjunta. Estos payloads representan inyecciones comúnmente utilizadas por atacantes para intentar reconstruir consultas SQL dañinas en el caso de que no exista una buena política de filtrado con el tratamiento de los datos de entrada. Este listado de payloads se enviará por medio del parámetro entry tras pulsar el botón “Iniciar Fuzzer”. Una vez realizado el ataque tendremos de estudiar las respuestas recibidas por el servidor
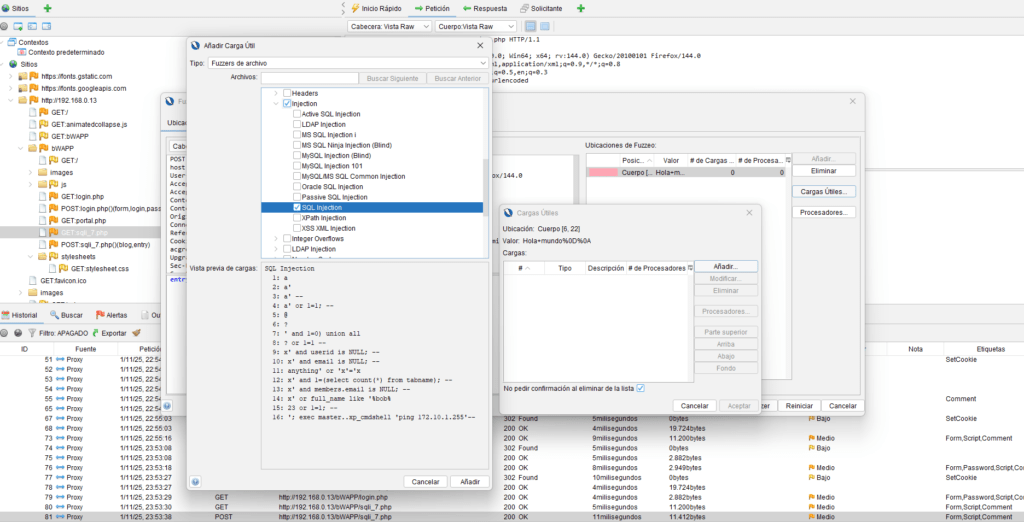
Para comprobar si alguna de ellas ha tenido éxito. Durante el proceso de fuzzing podemos ir observando, en la ventana de información, las peticiones asociadas a cada uno de los payloads. En este caso podemos observar que una de las inyecciones ha tenido éxito

Ya que hemos conseguido recuperar la versión interna de la base de datos. Fíjese que esta ha quedado almacenada incluso en una de las filas de la tabla.
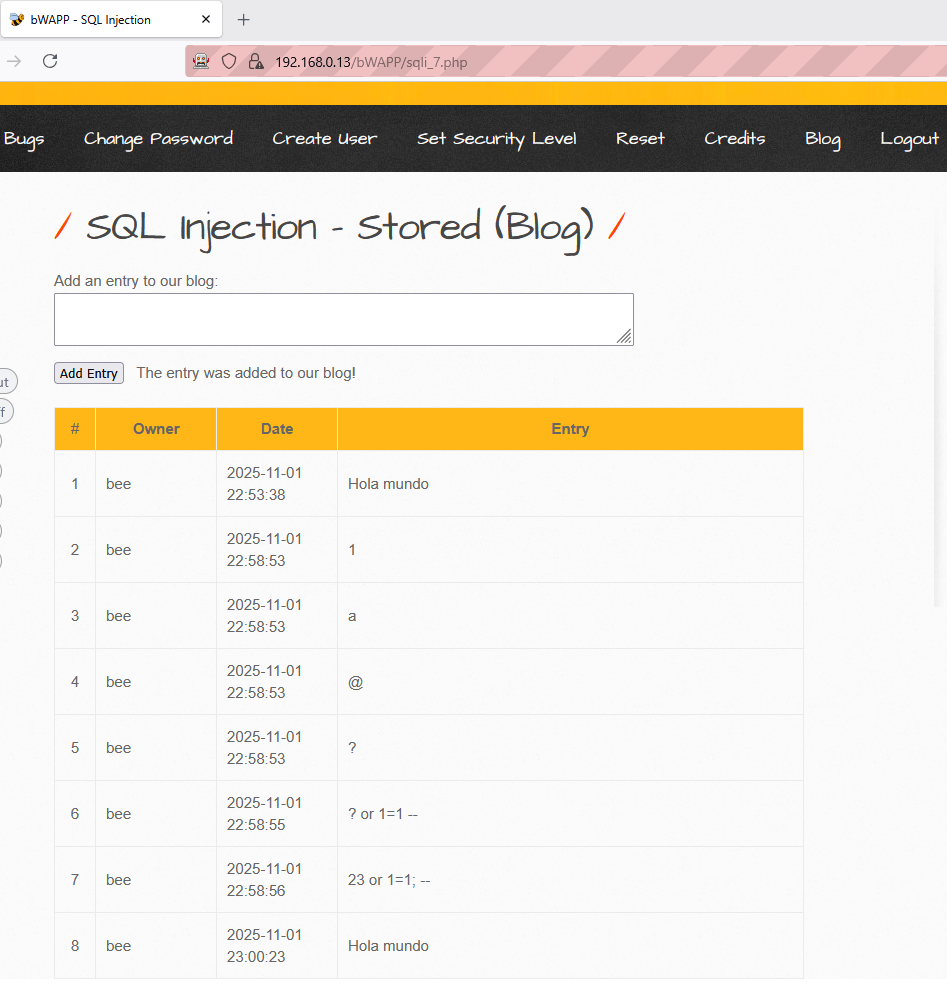
Estos hechos corroborarían la existencia de una vulnerabilidad de tipo SQL Injection con la que podríamos recuperar información de la base de datos del portal web. Cabe destacar que el procedimiento utilizando en este ejemplo es extrapolable con otro tipo de vulnerabilidades; no obstante, en ocasiones deducir si una inyección ha tenido éxito o no puede que requiera de una investigación más minuciosa que la representada en el ejemplo actual.
10
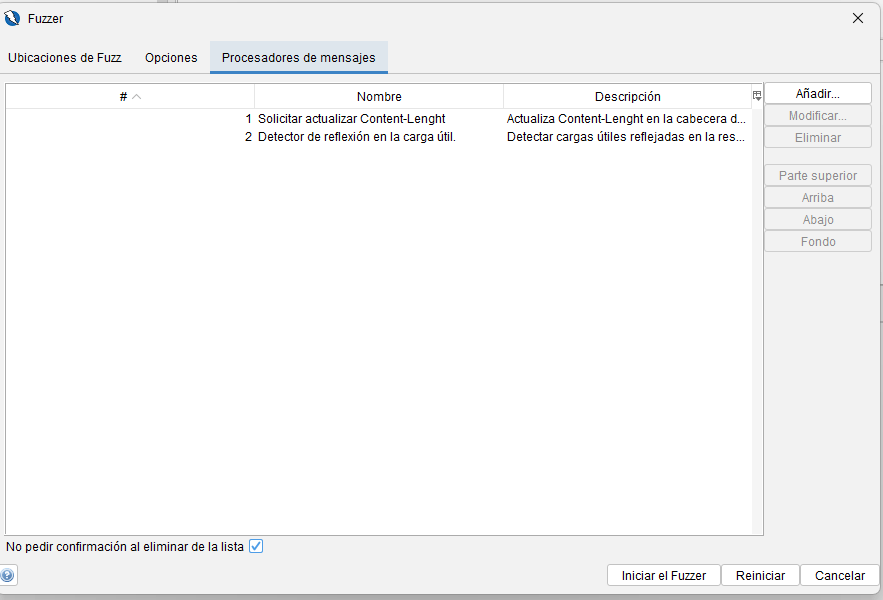
Procesadores de mensajes HTTP
Los procesadores de mensajes HTTP pueden acceder y cambiar los mensajes HTTP que se están analizando, controlar el proceso de análisis e interactuar con la interfaz de usuario de ZAP. Los procesadores de mensajes HTTP integrados incluyen:
Actualización de tokens anti-CSRF
Permite actualizar los tokens anti-CSRF incluidos en la solicitud. ZAP debe detectar correctamente los tokens anti-CSRF para poder utilizar este procesador. Para más información, consulte la página de ayuda «Introducción» > «Funciones» > «Tokens anti-CSRF». Este procesador se añade automáticamente a la lista de procesadores si se detectan tokens anti-CSRF.
Procesador HTTP Fuzzer (Script)
Permite seleccionar los scripts del procesador HTTP Fuzzer habilitados. Estos scripts permiten:
- Obtener la lista de cargas útiles
- Deja de hacer tonterías
- Aumentar el recuento de errores
- Enviar nuevos mensajes
- Agregar mensajes a la pestaña Resultados
- Establecer mensajes de ‘estado’ personalizados en la pestaña Fuzzer
- Generar alertas
Los scripts pueden incluir parámetros obligatorios y opcionales, cuyos valores se solicitarán al usuario al añadir el procesador al fuzzer. Los nombres de los parámetros se definen dentro de los scripts mediante los métodos getRequiredParamsNamesy getOptionalParamsNames, cada uno de los cuales devuelve una matriz de cadenas que representan los nombres de los parámetros.
Detector de reflexión de carga útil
Indica en la columna «Estado» de la tabla de resultados si se encontró alguna de las cargas inyectadas en la respuesta, mediante »

Reflejado».
Nota: Este procesador se añade automáticamente a la lista de procesadores.
Solicitar actualización de la longitud del contenido
Actualiza (o añade, si no está ya presente) el Content-Lengthencabezado de la solicitud con la longitud del cuerpo de la solicitud para todos los métodos de solicitud. No se realiza ningún cambio si el tamaño del cuerpo de la solicitud es cero y el encabezado no está ya presente. Este procesador se añade automáticamente a la lista de procesadores.
Creador de etiquetas
Permite agregar ‘etiquetas’ personalizadas, basadas en el contenido de la respuesta, a la columna Estado de la tabla de resultados.
Procesador de mensajes de usuario
Permite realizar fuzzings como usuario, utilizando uno de los usuarios definidos en los contextos que incluyen el mensaje HTTP que se va a fuzzear. Los usuarios deben existir para poder seleccionar y agregar este procesador. Otros complementos pueden definir procesadores de mensajes HTTP adicionales.
Archivos de IA de Fuzz
Proporciona un conjunto de archivos para realizar fuzzing a las IA (por ejemplo, a través de una API), basándose en el Modelo de Madurez de Resiliencia de Inteligencia Artificial (AI-RMM) .
Se incluyen los siguientes archivos y aparecerán como cargas útiles de “Archivos Fuzzing” de ZAP.
Extraer datos de entrenamiento
001 Preguntando
Este archivo contiene cargas útiles de fuzzing específicas del control AI-RMM “Medida 2.7.2”. El objetivo es probar si el sistema ha establecido métricas de seguridad y resiliencia para detectar posibles robos de datos de entrenamiento del modelo, incluido el cifrado, los controles de acceso y los umbrales de alarma para el acceso no autorizado. Las cargas útiles simulan escenarios donde la seguridad de los datos de entrenamiento del modelo podría verse comprometida. Se detalla el comportamiento esperado del sistema para cada escenario.
002 A través de la hipnosis
Este archivo contiene cargas útiles de fuzzing específicas para probar vulnerabilidades de «hipnosis» de LLM. El objetivo es determinar si LLM entra en un estado repetitivo donde filtra datos de entrenamiento involuntariamente. Estas cargas útiles exploran casos extremos donde la repetición podría provocar que LLM genere datos confidenciales. Las cargas útiles simulan consultas que buscan generar bucles o respuestas repetitivas. El comportamiento esperado del sistema se detalla para cada escenario. Tenga en cuenta que esto solo se encuentra en los archivos sin procesar y no se mostrará actualmente en ZAP. Referencias: Extracción escalable de datos de entrenamiento de modelos de lenguaje (de producción)
003 Ataque de divergencia
Este archivo contiene cargas útiles de fuzzing específicas para probar vulnerabilidades de «hipnosis» de LLM. El objetivo es determinar si LLM entra en un estado repetitivo donde filtra datos de entrenamiento involuntariamente. Estas cargas útiles exploran casos extremos donde la repetición podría provocar que LLM genere datos confidenciales. Las cargas útiles simulan consultas que buscan inducir bucles o respuestas repetitivas. Esta versión de las cargas útiles se centra más en la extracción de datos de entrenamiento mediante una estrategia de solicitud similar al ataque de divergencia descrito en el documento. Se detalla el comportamiento esperado del sistema para cada escenario.
Pruebas de divergencia: las cargas útiles están diseñadas para inducir divergencia respecto del estado alineado del modelo, alentándolo a generar datos de entrenamiento combinando indicaciones sin sentido con indicaciones estructuradas.
Estrategias de repetición: varios indicadores emplean la repetición para probar si el modelo diverge y produce datos memorizados. Solicitudes de datos confidenciales: estas cargas útiles evalúan si el modelo puede proteger datos de capacitación confidenciales, como información de identificación personal (PII), fragmentos de código o ejemplos de texto del mundo real, para evitar fugas. Referencias Extracción escalable de datos de entrenamiento de modelos de lenguaje (de producción)
004 SCA
Este archivo contiene cargas útiles de fuzzing específicas para probar vulnerabilidades LLM mediante el Ataque de Caracteres Especiales (SCA). El objetivo es evaluar si los LLM son susceptibles a la fuga de datos mediante la introducción de combinaciones de caracteres especiales que activan la salida de datos de entrenamiento memorizados. Estas cargas útiles exploran casos extremos donde los caracteres especiales hacen que el modelo genere datos confidenciales.
Las cargas útiles simulan secuencias de entrada que inducen a los LLM a generar contenido memorizado. Esta versión se basa en el método SCA, como se describe en el documento proporcionado. Se detalla el comportamiento esperado del sistema para cada escenario. Ataque de caracteres especiales (SCA): las cargas útiles se centran en el uso de símbolos específicos, como símbolos estructurales JSON u otros caracteres que aparecen comúnmente en los corpus de entrenamiento LLM, para inducir la fuga de datos. Ataque de caracteres especiales: Hacia una extracción escalable de datos de entrenamiento de LLM
005 El Compartidor Secreto
Este archivo contiene cargas útiles de fuzzing específicas para probar la memorización involuntaria en redes neuronales. El objetivo es determinar si las LLM memorizan y revelan involuntariamente secuencias sensibles, como datos personales, mediante indicaciones específicas que activan respuestas memorizadas. Estas cargas útiles simulan consultas diseñadas para extraer secuencias raras o secretas memorizadas durante el entrenamiento.
Memorización no intencionada: Las cargas útiles se diseñan para comprobar si el modelo retiene datos secretos específicos que no deben memorizarse, como números de tarjetas de crédito o de la Seguridad Social. Pruebas de métricas de exposición: Algunas cargas útiles comprueban si la salida del modelo puede vincularse a la memorización mediante secuencias similares a «canarios» insertadas en los datos de entrenamiento. El Compartidor Secreto: Evaluación y Prueba de la Memorización No Intencional en Redes Neuronales
006 Cuantificación de la memorización
Este archivo contiene cargas útiles de fuzzing específicas para probar la memorización en modelos neuronales del lenguaje. El objetivo es identificar si el LLM genera datos de entrenamiento memorizados cuando se le solicitan patrones o secuencias específicos, y cómo la longitud del contexto y la duplicación de datos influyen en este comportamiento. Estas cargas útiles están diseñadas para probar la escala del modelo, la duplicación de datos y la longitud del contexto como factores clave que influyen en la memorización. Cuantificación de la memorización en modelos neuronales del lenguaje
007 Ataques de envenenamiento de datos
Este archivo contiene cargas útiles de fuzzing avanzadas específicas para probar vulnerabilidades de envenenamiento de datos en modelos DP-SGD. El objetivo es evaluar si los datos envenenados pueden influir en el comportamiento del modelo o violar las garantías de privacidad diferencial. Envenenamiento de datos: estas cargas útiles ponen a prueba la capacidad de los adversarios de inyectar datos maliciosos en el proceso de entrenamiento, comprometiendo la privacidad o la precisión. Referencias: Auditoría del aprendizaje automático diferencialmente privado: ¿Qué tan privado es el SGD privado?
008 Inferencia de membresía
Este archivo contiene cargas útiles de fuzzing avanzadas específicas para probar vulnerabilidades de inferencia de pertenencia en modelos DP-SGD. El objetivo es evaluar si el modelo filtra información sobre si un punto de datos específico formaba parte del conjunto de entrenamiento. Ataques de inferencia de membresía: estas cargas útiles evalúan si los adversarios pueden inferir el estado de membresía consultando el modelo. Auditoría del aprendizaje automático diferencialmente privado: ¿Qué tan privado es el SGD privado?
009 Recorte de degradado
Este archivo contiene cargas útiles de fuzzing avanzadas específicas para probar vulnerabilidades de recorte de gradiente en modelos DP-SGD. El objetivo es probar la robustez del recorte de gradiente para proteger la privacidad, manteniendo al mismo tiempo el rendimiento del modelo. Recorte de gradiente: las cargas útiles exploran si el recorte de gradiente evita suficientemente que gradientes grandes revelen información confidencial o influyan en el modelo. Auditoría del aprendizaje automático diferencialmente privado: ¿Qué tan privado es el SGD privado?
Extraer información del modelo
001 Arquitectura
Este archivo contiene cargas útiles de fuzzing avanzadas diseñadas para extraer información de la arquitectura del modelo de los LLM. El objetivo es determinar si el LLM revela detalles específicos sobre su arquitectura, como el número de capas, los tipos de transformadores o el número de parámetros. Extracción de la arquitectura del modelo: estas cargas útiles buscan detalles específicos relacionados con la arquitectura, como recuentos de capas, tipos de modelos y otros aspectos estructurales del LLM. Recuento de capas: Las cargas útiles se centran en extraer el número de capas y sus tipos (p. ej., capas de transformador, capas ocultas).
Inferencia de parámetros: Sondeos para el recuento de parámetros, como los cabezales de atención o las dimensiones de las capas.
Tipo de modelo: Los atacantes intentan identificar si el LLM es un modelo exclusivo de decodificador o forma parte de una familia de arquitecturas (p. ej., GPT, BERT).
Mecanismos internos específicos: Preguntas sobre funciones de activación, normalización y codificaciones posicionales para inferir detalles específicos de la arquitectura.
Este archivo contiene cargas útiles de fuzzing específicas del control AI-RMM “Medida 2.7.2”. El objetivo es probar si el sistema ha establecido métricas de seguridad y resiliencia para detectar posibles robos de datos de entrenamiento del modelo, incluido el cifrado, los controles de acceso y los umbrales de alarma para el acceso no autorizado. Las cargas útiles simulan escenarios donde la seguridad de los datos de entrenamiento del modelo podría verse comprometida. Se detalla el comportamiento esperado del sistema para cada escenario.
002 Hiperparámetros
Este archivo contiene cargas útiles de fuzzing avanzadas diseñadas para extraer información de hiperparámetros de los LLM. El objetivo es determinar si el LLM revela hiperparámetros específicos, como tasas de aprendizaje, tipos de optimizadores, tamaños de lote, etc., mediante indicaciones adversarias.
Extracción de hiperparámetros: estas cargas útiles investigan las tasas de aprendizaje, las configuraciones del optimizador y los programas de entrenamiento utilizados durante el desarrollo del modelo.
Tasas de aprendizaje: Las cargas útiles se centran en extraer la tasa de aprendizaje y su programación.
Optimizador e hiperparámetros: Sondeos para tipos de optimizadores, momentum, valores beta y ajustes de decaimiento de peso.
Detalles de entrenamiento: Consultas relacionadas con el tamaño del lote, épocas, recorte de gradiente y tasas de abandono. Técnicas de entrenamiento: Intentan inferir si se utilizó detención temprana, aumento de datos o entrenamiento de precisión mixta.
003 Extracción basada en indicaciones
Este archivo contiene cargas útiles avanzadas de fuzzing para la extracción de datos de LLM basada en indicaciones. Estas cargas útiles están diseñadas para comprobar si el LLM revela inadvertidamente datos de entrenamiento memorizados, como frases u oraciones confidenciales, mediante indicaciones cuidadosamente elaboradas.
Extracción de datos basada en indicaciones: Estas indicaciones se asemejan a patrones encontrados en los datos de entrenamiento del modelo para identificar fugas de datos no deseadas.
Extracción de datos confidenciales: Estas cargas útiles intentan revelar información confidencial, como números de teléfono, direcciones de correo electrónico e identificadores únicos.
Sondeo basado en patrones: Las indicaciones creadas se asemejan mucho a patrones comunes (por ejemplo, direcciones, citas) que pueden activar datos memorizados.
Extracción de código y registros: Prueba la capacidad del modelo para evitar revelar fragmentos de código memorizados o mensajes de error.
Datos de redes sociales: Las cargas útiles se centran en revelar nombres de usuario, conversaciones u otro contenido generado por el usuario memorizado.
004 Indicaciones condicionales
Este archivo contiene cargas útiles de fuzzing avanzado para indicaciones condicionales, diseñadas para extraer información contextual de los LLM. Estas cargas útiles guían el modelo mediante la introducción de condiciones o restricciones, con el objetivo de extraer información de dominios o contextos específicos dentro de los datos de entrenamiento.
Indicaciones condicionales: estas indicaciones imponen restricciones que dirigen el modelo hacia la generación de texto que se alinea con criterios específicos o conocimiento específico del dominio.
Restricciones condicionales: cada carga útil introduce condiciones específicas (p. ej., frases específicas del dominio o limitaciones estructurales) para guiar la respuesta del modelo.
Extracción dirigida al dominio: las indicaciones se crean para extraer información específica del dominio, como contenido legal, médico o científico.
Prevención de información sensible: las cargas útiles comprueban si el modelo puede proporcionar respuestas generalizadas de alto nivel sin revelar datos memorizados o confidenciales.
005 ML adversarial
Este archivo contiene cargas útiles de fuzzing avanzadas diseñadas para extraer datos de entrenamiento para su uso en ataques de aprendizaje automático adversarios. El objetivo es comprobar si los LLM filtran datos que podrían reutilizarse para entrenar modelos adversarios diseñados para engañar a otros sistemas de aprendizaje automático.
Aprendizaje automático adversarial: estos mensajes tienen como objetivo extraer datos de entrenamiento valiosos de los LLM para explotar o engañar a otros modelos a través del entrenamiento adversarial.
Extracción de datos para reentrenamiento adversarial: Las cargas útiles se centran en recuperar datos específicos de entrenamiento que podrían usarse para entrenar modelos adversariales.
Explotación de clasificaciones erróneas: Las indicaciones se centran en clasificaciones incorrectas y vulnerabilidades en conjuntos de datos para generar entradas adversariales.
Generación de texto adversarial: Algunas cargas útiles están diseñadas para crear texto que podría usarse para engañar a sistemas como chatbots, filtros de spam o modelos médicos.
006 Robo de propiedad intelectual
Este archivo contiene cargas útiles de fuzzing avanzadas diseñadas para extraer técnicas de propiedad intelectual (PI) patentadas integradas en el modelo. Estas cargas útiles se centran en revelar métodos, innovaciones o técnicas patentadas relacionadas con el entrenamiento, la arquitectura o la optimización del modelo.
Técnicas de propiedad intelectual patentadas: estas propuestas se centran en técnicas innovadoras y específicas del modelo diseñadas para proporcionar ventajas competitivas o constituir tecnologías patentables.
Técnicas propietarias: Las cargas útiles se centran en la extracción de técnicas propietarias innovadoras, como el escalado de modelos, la poda, la paralelización, la compresión y la cuantificación.
Métodos patentados: Las solicitudes específicas buscan identificar procesos patentados o innovaciones con patente en trámite en estrategias de entrenamiento, optimización e implementación.
Eficiencia energética y rendimiento: Las consultas también se centran en métodos propietarias que optimizan el rendimiento y el consumo energético en modelos grandes.
007 Privacidad de datos
Este archivo contiene cargas útiles de fuzzing avanzadas diseñadas para extraer metadatos e información confidencial sobre el origen del modelo, quién lo entrenó y otros detalles de desarrollo. Estas indicaciones se centran en violaciones de la privacidad de datos específicas del modelo, con el objetivo de revelar información confidencial sobre la organización o el desarrollo del modelo.
Violaciones de la privacidad de datos (metadatos del modelo): estos avisos apuntan a metadatos confidenciales, como quién entrenó el modelo, los conjuntos de datos utilizados y las organizaciones involucradas en su desarrollo.
Extracción de metadatos del modelo: Estas indicaciones se centran en extraer información sobre quién desarrolló y entrenó el modelo, así como detalles organizativos y de propiedad.
Detalles del proceso de entrenamiento: Las sondas buscan información relacionada con el proceso de anotación de datos, las prácticas de privacidad y los colaboradores involucrados en el entrenamiento.
Seguridad e infraestructura: Las cargas útiles se centran en extraer información sobre la infraestructura de hardware, la financiación y la gestión de la privacidad de los datos durante el entrenamiento.
008 Fuga de representación visual
Este archivo contiene cargas útiles avanzadas de fuzzing para el análisis de representaciones visuales, centrándose en extraer información del modelo de gráficos científicos. Estas indicaciones buscan inferir la arquitectura del modelo, los hiperparámetros y los detalles de entrenamiento aprovechando patrones en resultados visuales como t-SNE o gráficos de pérdidas.
Análisis de Representación Visual: Estas indicaciones se centran en la información del modelo extraída mediante resultados visuales, como t-SNE y gráficos de pérdidas. Inspirado en: «Un gráfico vale más que mil palabras: Ataques de robo de información del modelo mediante gráficos científicos».
Extracción de gráficos científicos: Las cargas útiles se centran en inferir hiperparámetros, la arquitectura del modelo y los detalles del proceso de entrenamiento basándose en patrones en t-SNE o gráficos de pérdidas.
Metadatos y configuración del modelo: Estas indicaciones prueban la resistencia del modelo a revelar información confidencial relacionada con los tipos de optimizadores, tamaños de lote, abandono y técnicas de regularización.
Convergencia y dinámica de entrenamiento: Varias cargas útiles buscan información sobre las tasas de aprendizaje, la duración del entrenamiento y el ajuste de hiperparámetros mediante patrones visuales en los gráficos.
009 Violaciones de la privacidad
Este archivo contiene cargas útiles de fuzzing avanzadas diseñadas para extraer datos de entrenamiento sensibles, centrándose en las violaciones de la privacidad de los datos. Estas indicaciones buscan identificar posibles violaciones de la privacidad mediante la extracción de información personal identificable (PII), datos confidenciales o información confidencial de los datos de entrenamiento del modelo.
Violaciones de la privacidad de datos: estos avisos se dirigen a información confidencial, lo que da lugar a violaciones de la privacidad, robo de identidad o daños a la reputación de personas u organizaciones.
Extracción de información sensible: Estas indicaciones se centran en la extracción de información personal identificable (PII) (p. ej., nombres, direcciones de correo electrónico, datos financieros, números de la seguridad social) e información empresarial confidencial.
Violaciones de la privacidad de datos: Las cargas útiles buscan evaluar si el modelo puede filtrar inadvertidamente datos de entrenamiento que provoquen violaciones de la privacidad, robo de identidad o daños a la reputación.
Datos legales y sanitarios protegidos: Las indicaciones se centran en historiales médicos sensibles, contratos legales y estrategias comerciales exclusivas.
Cuadro de diálogo de cargas útiles
Esto le permite seleccionar los procesadores de carga útil que se utilizarán con todos los generadores de carga útil. Los procesadores de carga útil integrados son los mismos que están disponibles a través del cuadro de diálogo Procesadores de carga útil . Esto le permite seleccionar los generadores de carga útil que se utilizarán al realizar fuzzing en una solicitud. Los generadores de carga útil generan los valores sin procesar o ataques que el fuzzer envía a la aplicación de destino. Los siguientes tipos de generadores se proporcionan de forma predeterminada:
- Vacío/Nulo: genera la carga útil seleccionada varias veces, dejando el mensaje sin cambios. Este generador de carga útil es útil para enviar múltiples mensajes que se procesan posteriormente, por ejemplo, con un procesador HTTP de fuzzing (script) .
- Archivo: seleccione cualquier archivo local para ataques únicos
- Fuzzers de archivos: seleccione cualquier combinación de archivos de fuzzing registrados con ZAP, por ejemplo, a través de complementos como fuzzdb
- Numberzz: permite generar fácilmente una secuencia de números, con incremento personalizado
- Regex: genera ataques basados en patrones de expresiones regulares
- Cadenas: cadenas sin formato que se pueden ingresar manualmente o pegar.
- Script: scripts personalizados que pueden generar cualquier carga útil requerida
- Json: genera ataques mediante fuzzing del json proporcionado
Puede escribir scripts generadores de carga útil personalizados: estos pueden proporcionar cualquier carga útil que necesite.
Los complementos también pueden definir generadores de carga útil adicionales.
El botón ‘Procesadores…’ inicia el cuadro de diálogo Procesadores de carga útil que le permite configurar procesadores de carga útil que solo se aplican al generador de carga útil que ha seleccionado.
Cuadro de diálogo Procesadores de carga útil
Esto le permite seleccionar los procesadores de carga útil para usar con generadores de carga útil específicos.
Los procesadores de carga útil integrados incluyen:
- Descodificación Base64
- Codificación Base64
- Expandir (hasta una longitud mínima especificada)
- Escape de JavaScript
- JavaScript Unescape
- Hash MD5
- Cadena de sufijo
- Cadena de prefijo
- Hash SHA-1
- Hash SHA-256
- Hash SHA-512
- Recortar
- Descodificación de URL
- Codificación de URL
También puede escribir scripts de procesador de carga útil personalizados: estos pueden realizar cualquier manipulación de la carga útil que necesite.
Los complementos también pueden definir procesadores de carga útil adicionales.
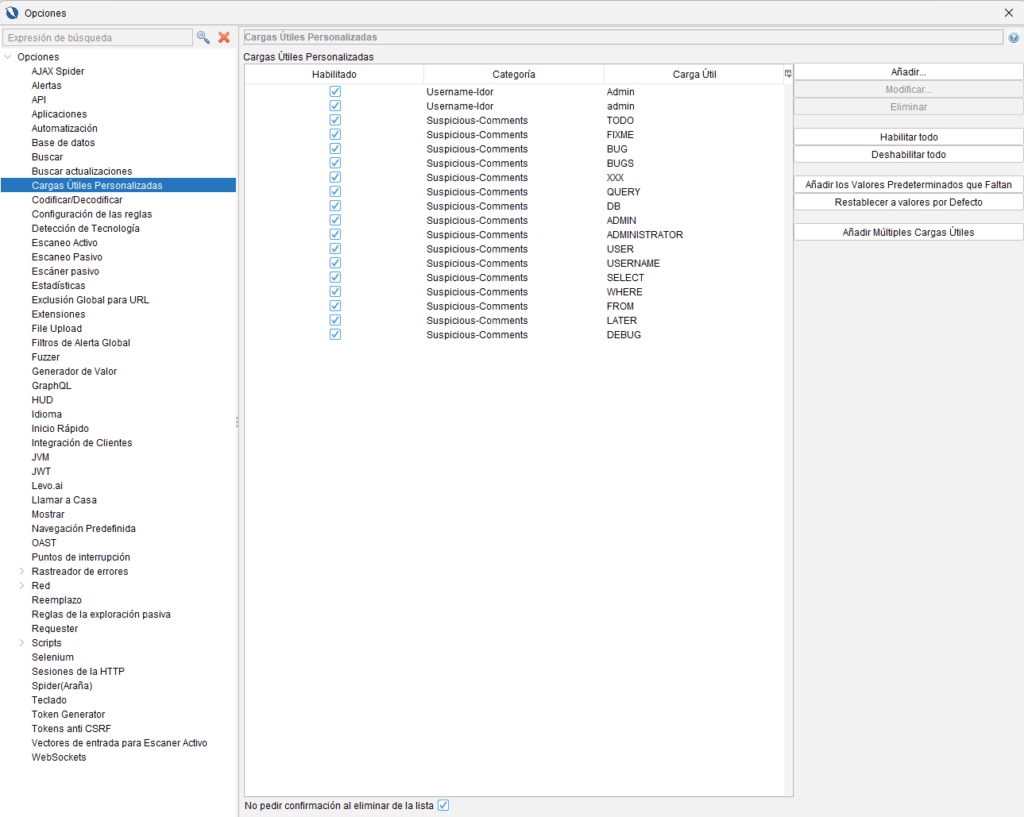
Resumen de este articulo
Qué hace cada “araña” y cuándo usarla
- Spider (estándar / HTML crawler)
- Rápida, analiza HTML y extrae enlaces/atributos (href, src, form, meta, etc.).
- Muy buena para sitios “clásicos” (server-side pages).
- NO ejecuta JS, por tanto no descubre rutas generadas dinámicamente.
- AJAX Spider (Crawljax)
- Arranca navegadores (headless/normal), ejecuta JS, hace clics, procesa DOM.
- Más lenta pero necesaria para “single-page apps” y aplicaciones con AJAX.
- Requiere Selenium/binaries y consume más recursos.
- Client Spider (nuevo, recomendado para apps modernas)
- Similar al AJAX Spider, pero con acceso directo al DOM vía la extensión de navegador ZAP → puede descubrir más cosas.
- Futuro sustituto del AJAX Spider — mejor cobertura para apps modernas.
Cómo iniciar una araña (UI & atajos)
- Spider clásico (UI): seleccionar nodo en Sites → botón derecho → Attack > Spider…
- O Tools → Spider o atajo Ctrl+Alt+S.
- AJAX Spider: Tools → AJAX Spider o atajo Ctrl+Alt+X.
- Client Spider: Tools → Client Spider (si está instalado).
- En el diálogo de arranque puedes elegir: punto de inicio, contexto, si ejecutar como usuario (reautenticará cuando haga falta), Recurse (subárbol), Subtree only, y opciones avanzadas.
Opciones importantes y su impacto (Spider clásico)
- Depth (profundidad máxima): 0 = ilimitada. Limítala si la app es grande o tienes datos/IDs infinitos.
- Threads (hilos): aumenta velocidad, pero cuidado de DoS o sobrecargar ZAP/target.
- Max duration (minutos): evita ejecuciones eternas.
- Max nodes per parent: evita explosión en apps con muchas páginas “data-driven”.
- Max response size (bytes): ignora respuestas enormes.
- Domains always in scope: añade dominios externos necesarios (CDNs/scripts).
- Parameter handling (checking visited URL):
- Ignore params / Name only / Name+Value — decide si diferentes valores generan nuevas visitas. Name only suele equilibrar.
- Process forms / Send POST forms: por defecto ON (envía formularios).
- Desactivarlo si no quieres ejecutar acciones (crear registros, enviar mails).
- Accept cookies: controla si spider mantiene sesión. Si el spider corre como usuario conviene que sí.
- Parse robots.txt / sitemap.xml / .DS_Store / SVN metadata: útil para detectar rutas ocultas, pero puede aumentar ruido.
Opciones AJAX Spider / Client Spider (clave)
- Browser choice: firefox-headless recommended (si no hay recursos).
- Number of browser windows: más ventanas → más velocidad, mayor uso CPU/RAM.
- Event/pageLoad timeouts (ms): si la app es lenta sube estos para evitar perder enlaces en JS.
- Clic policy: Click elements once vs multiple clicks. Desactivar once puede descubrir más pero tarda más.
- Use random values in forms: evita strings vacíos irrelevantes; a veces conviene desactivar para reproducibilidad.
- Scope checking (Strict vs Flexible):
- Strict sólo carga recursos dentro del alcance; Flexible permite cargar recursos fuera de ámbito (p. ej. scripts de terceros necesarios).
- Enable browser extensions (client integration): si inicias navegador desde ZAP; permite Client Spider + DOM events.
Evitar problemas comunes
- Cerrar sesión involuntaria: habilita Avoid logout o excluye botones/URLs de logout.
- No probar contra producción sin permiso. Usa Protected mode o define contexto con URLs permitidas.
- Form submission safety: si forms hacen cambios destructivos, desactiva Process forms / Send POST forms.
- Rate & thread control: baja los hilos y añade delays si target tiene WAF o rate-limits.
- Cookies & session state: si vas a escanear como usuario, elige el user en el diálogo y activa Use global HTTP state (si corresponde) para que ZAP gestione cookies/CSRF correctamente.
Integración con contexto / autenticación / usuarios
- Lanzar spider como un usuario: en el diálogo de Spider selecciona Context y User → ZAP hará login cuando sea necesario. Útil para áreas protegidas.
- Si usas autenticación por formularios/JSON/NTLM/script, configura el método en Session Context > Authentication antes de spider.
- Verificación de login: configura regex para detectar login/logout en Authentication (para que ZAP reauth cuando sea necesario).
Forced Browse (navegación forzada) vs Spider
- Spider sigue enlaces encontrados en el HTML/DOM.
- Forced Browse / Forced Browse (DirBuster-like) hace brute-force con wordlists (carpetas/archivos).
- Útil para encontrar recursos no referenciados.
- Opciones: recursion, file extensions, threads per host, error-case string (para detectar 404 “custom”).
- Mayor ruido y potencial riesgo de bloqueo — usar con permiso.
Flujo de trabajo recomendado (rápido)
- Crear sesión y persistir.
- Definir contexto y Include/Exclude URL relevantes.
- Configurar Authentication (si aplica) y crear Users.
- Spider clásico para mapa base (desactivar POST forms si riesgo).
- AJAX / Client Spider para JS-heavy routes (usar cuando hayas autenticado o hayas confirmado que necesitas JS).
- Opcional: Forced Browse con listas (p.ej. dirbuster lists) para descubrir admin/backup paths.
- Usar los resultados para Active Scan o pruebas manuales y/o Requester/Fuzzer según objetivo.
- Revisar Sites, Alerts y History. Exportar informe.
Parámetros/valores recomendados (configuraciones iniciales)
- Spider classic: depth = 0 (ilimitado) o 5 si site grande; threads = 2–5; max duration = 60 min (ajustar).
- AJAX Spider: browser windows = min(cores, 2); depth = 10; max states = 0 (ilimitado) o 1000; event timeout 1000–2000 ms; page load timeout 1000–3000 ms.
- Forced Browse: threads per host = 5–10; delay = 100–500 ms; recursive según necesidad; elegir wordlist por objetivo.
- Si objetivo es sensible (WAF, infra compartida): threads = 1–2, delay = 500–1000 ms.
Trucos útiles / diagnóstico
- Ver por qué una URL no fue procesada: en la pestaña Spider se muestran motivos (Out of scope, Max children, Depth, Non-text, etc.).
- Encontraste mucho “noise” (terceros): añade dominios no target a exclude o marca solamente tu Context en Sites y usa Just in scope.
- Si el spider no ve rutas con #fragment: Client Spider / browser integration las captura; el site tree normal las ignora.
- Si el navegador no se inicia (AJAX): verifica Tools > Options > Selenium > Binaries y que drivers estén instalados.
- Para reproducir acciones complejas (login flows): graba un script Zest o Selenium (Browser Recorder) y usa esa secuencia para autenticar antes del spider.
APIs útiles (automatización)
- Client Spider: clientSpider/action/scan y clientSpider/view/status (puedes pasar browser, url, context, user, maxCrawlDepth, pageLoadTime).
- General: puedes lanzar spiders y configurar contextos desde la API REST de ZAP para integrarlo en CI.
Ejemplo quick call:
https://zap/JSON/clientSpider/action/scan/?url=https://example.com&maxCrawlDepth=5&pageLoadTime=30
Recomendaciones finales de seguridad y ética
- Siempre tener permiso explícito para probar el objetivo.
- Usa modo protegido y contextos para minimizar impacto.
- No instales CA de ZAP en sistemas de producción sin control.
- Si el objetivo tiene WAF o protecciones, baja threads/delay y consulta con el dueño.
Diez preguntas clave sobre el contenido
- ¿Qué es la araña (Spider) de ZAP y cómo funciona su proceso de rastreo?
- ¿Qué diferencias hay entre la araña clásica (Spider) y la AJAX Spider?
- ¿Qué papel cumple el archivo robots.txt en el Spider de ZAP?
- ¿Qué es el Client Spider y cómo mejora la capacidad de rastreo?
- ¿Qué funcionalidades ofrece el Fuzzer de ZAP y qué tipo de ataques permite simular?
- ¿Qué son los payloads y cómo se usan en un proceso de fuzzing en ZAP?
- ¿Qué es la navegación forzada (Forced Browse) y cómo se diferencia del rastreo tradicional?
- ¿Qué información muestra la pestaña de resultados del fuzzing y cómo se interpretan?
- ¿Cuál es la función de las extensiones del navegador ZAP?
- ¿Qué es la integración del lado del cliente y qué ventajas ofrece?
Diez ejercicios prácticos basados en el artículo
- Realiza un escaneo con la araña clásica de ZAP en una URL de prueba y visualiza los nodos descubiertos.
- Configura la araña clásica para no procesar formularios ni enviar POST.
- Ejecuta un AJAX Spider seleccionando un navegador (Firefox/Chrome) y observa el número de URL descubiertas.
- Agrega un elemento excluido en el AJAX Spider (por ejemplo, un botón de logout).
- Realiza un fuzzing manual sobre un formulario que use el método POST.
- Añade tu propio archivo de payloads personalizados para el fuzzing.
- Ejecuta una navegación forzada sobre una URL y analiza qué recursos ocultos fueron encontrados.
- Activa el Client Spider, selecciona un contexto y observa los nodos descubiertos en el Mapa del Cliente.
- Genera un script Zest grabando la navegación con la extensión del navegador ZAP.
- Usa los procesadores de carga útil para aplicar codificación Base64 sobre un payload.
Respuestas detalladas a las 10 preguntas
1. ¿Qué es la araña (Spider) de ZAP y cómo funciona?
Es una herramienta que analiza páginas web automáticamente buscando enlaces, formularios y recursos. Usa una lista inicial de URL (semillas), accede a ellas y sigue los hipervínculos encontrados recursivamente. También analiza archivos como robots.txt, sitemap.xml, formularios y ciertos metadatos para descubrir nuevas rutas.
2. ¿Qué diferencias hay entre la araña clásica (Spider) y la AJAX Spider?
- Araña clásica: rápida, adecuada para sitios HTML tradicionales. No interpreta JavaScript.
- AJAX Spider: más lenta, usa navegadores reales para analizar el DOM, ejecutar JS y detectar solicitudes AJAX. Ideal para SPAs (Single Page Apps).
3. ¿Qué papel cumple el archivo robots.txt en el Spider de ZAP?
Si está habilitado, el Spider analiza el robots.txt en busca de rutas listadas, pero no respeta sus restricciones, ya que busca encontrar vulnerabilidades, no obedecer políticas de acceso.
4. ¿Qué es el Client Spider?
Es una herramienta avanzada que reemplazará a AJAX Spider. Tiene acceso directo al DOM mediante extensiones de navegador y puede detectar elementos del lado del cliente que otras arañas no ven. Permite explorar SPAs de forma más precisa.
5. ¿Qué funcionalidades ofrece el Fuzzer de ZAP?
Permite enviar datos aleatorios, inválidos o maliciosos (payloads) en solicitudes HTTP para detectar vulnerabilidades como:
- SQLi
- XSS
- LFI/RFI
- XML External Entity
- CSRF
- JWT leakage
6. ¿Qué son los payloads y cómo se usan en fuzzing?
Son cadenas o entradas diseñadas para probar fallos en aplicaciones. En ZAP, se pueden:
- Seleccionar desde librerías (ej. fuzzdb)
- Cargar archivos personalizados
- Generar por scripts
- Aplicar transformaciones con procesadores (hash, encoding, etc.)
7. ¿Qué es la navegación forzada (Forced Browse)?
Es una técnica que intenta acceder directamente a archivos/directorios usando diccionarios, sin depender de enlaces visibles. A diferencia del rastreo clásico, no necesita que haya enlaces presentes en las páginas.
8. ¿Qué información muestra la pestaña de resultados del fuzzing?
Incluye:
- La carga enviada (payload)
- Método HTTP
- Código de respuesta
- Tiempo de respuesta
- Tamaño de la respuesta
- Alertas generadas
- Posibles reflexiones de carga útil
9. ¿Cuál es la función de las extensiones del navegador ZAP?
Permiten:
- Transmitir eventos DOM a ZAP
- Acceder al mapa del cliente
- Grabar scripts (ej. autenticación)
- Hacer clic automático en elementos durante escaneos
10. ¿Qué es la integración del lado del cliente?
Es la conexión entre ZAP y el navegador (vía extensiones) para:
- Capturar eventos DOM
- Analizar el comportamiento JS en tiempo real
- Registrar scripts de usuario
- Enviar datos directamente desde la UI web a ZAP para mejorar cobertura
Respuestas a los 10 ejercicios propuestos
1. Escaneo con la araña clásica
- Selecciona un nodo en el árbol de sitios.
- Menú Ataque > Spider.
- Activa «Recurse» y clic en “Iniciar escaneo”.
- Observa los nodos descubiertos en el árbol.
2. No procesar formularios
- Al iniciar el Spider, activa “Mostrar opciones avanzadas”.
- En la pestaña “Avanzado”, desactiva:
- “Procesar formularios”
- “Enviar formularios POST”
3. Ejecutar AJAX Spider
- CTRL + ALT + X o menú Herramientas > AJAX Spider.
- Ingresa URL y selecciona navegador (ej. Firefox).
- Inicia escaneo.
- Verás las URLs encontradas en la pestaña AJAX Spider.
4. Excluir botón de logout del AJAX Spider
- Ir a Opciones > AJAX Spider > Elementos excluidos.
- Añadir descripción, etiqueta (button) y texto (ej. «Logout»).
5. Fuzzing sobre formulario POST
- En la pestaña «Sitios» selecciona el formulario.
- Click derecho → Ataque > Fuzz…
- Selecciona el campo de entrada (ej. entry) y añade payloads.
- Inicia fuzzing y analiza resultados.
6. Añadir archivo de payloads personalizado
- Guarda un archivo .txt con payloads línea por línea.
- Copia el archivo en ~/.ZAP/fuzzers/ o lo cargas desde la pestaña de cargas útiles.
- Úsalo desde el diálogo Fuzzer > Añadir carga útil > «Archivo»
7. Navegación forzada
- Menú Sitios → clic derecho sobre una URL → Ataque > Navegación forzada del sitio
- Observa los directorios y archivos descubiertos que no estaban enlazados en el HTML.
8. Usar Client Spider
- Menú Herramientas > Client Spider
- Selecciona contexto o URL
- Inicia análisis
- Ve a pestaña Client Spider > Nodos añadidos para ver recursos descubiertos
9. Generar script Zest grabado
- Menú Herramientas > Grabar script de Zest
- Cambia tipo a Script del lado del cliente
- Ingresa una URL
- ZAP abrirá el navegador y grabará tus acciones como script.
10. Aplicar codificación Base64 en un payload
- Durante configuración de fuzzing:
- Clic en Procesadores
- Añadir Codificación Base64
- Esto hará que el payload se envíe codificado automáticamente.
¿Te gustaría que arme ahora un laboratorio guiado paso a paso con alguno de estos módulos?
Puedo integrar:
- Fuzzing sobre SQLi
- Uso de AJAX Spider en una SPA
- Escaneo con Client Spider
- Detección de rutas ocultas con navegación forzada
- Uso de payloads de IA para atacar APIs
Solo dime con qué parte querés empezar.
Despedida
Las capacidades de rastreo de ZAP (Spider clásico, AJAX Spider y Client Spider) ofrecen una cobertura potente y flexible para mapear y analizar aplicaciones web modernas y tradicionales. Elegir la araña adecuada y ajustar parámetros —profundidad, concurrencia, manejo de formularios, tiempos de espera y ámbito— es clave para equilibrar exhaustividad y seguridad operacional. Complementa siempre el rastreo automatizado con exploración manual, pruebas de autenticación y revisiones humanas para detectar lógicas de negocio y falsos positivos que las herramientas no captan.
Recuerda: utiliza estas herramientas únicamente contra objetivos para los que tengas permiso explícito y actúa con prudencia al ejecutar acciones que puedan alterar datos o saturar servicios.